基于MobileNet V2的口罩佩戴识别研究
2021-11-15金映谷杨亚宁楚艳丽
金映谷,张 涛,杨亚宁,王 月,楚艳丽
(大连民族大学 a.机电工程学院;b.信息与通信工程学院,辽宁 大连 116605)
自新型冠状病毒肺炎(COVID-19)疫情暴发以来[1],传播迅速,严重威胁人民的生命安全,为了防止交叉感染以及疫情范围扩大,佩戴口罩且佩戴标准成为疫情防控的重要方式。但由于意识不到位、佩戴口罩不舒服等种种原因,难以实现人人自觉地标准佩戴口罩[2]。因此在公共场合对口罩是否佩戴以及佩戴是否规范进行检测就十分重要。
目前,百度、华为、海康威视等公司已完成基于视频的乘客佩戴检测,并应用于铁路交通系统。肖俊杰[3]提出了一种基于YOLOv3和YCrCb的人脸口罩检测与规范佩戴识别方法,其中YOLOv3对是否佩戴口罩进行检测,对检测到佩戴口罩的图像,利用YCrCb的椭圆肤色模型对该区域进行肤色检测,进而判断口罩是否佩戴规范,人脸口罩检测的mAP达到89.04%,口罩规范佩戴的识别率达到82.48%。管军霖等[4]提出了一种基于图片高低频成分融合YOLOv4卷积神经网络的口罩佩戴检测方法,通过网络爬虫构建数据集,并进行手动数据标注,经过Darknet深度学习框架训练,进行模拟检测,训练后模型检测精度值达到0.985,平均检测速度35.2 ms。邓黄潇[5]提出一种基于迁移学习与RetinaNet网络的口罩佩戴检测方法,训练后模型在验证集下的AP值为86.45%。王艺皓等[6]提出了一种复杂场景下基于改进YOLOv3的口罩佩戴检测算法,结合跨阶段局部网络对DarkNet53骨干网络进行了改进,在YOLOv3中引入改进空间金字塔池化结构,并结合自上而下和自下而上的特征融合策略对多尺度预测网络进行改进,选取CIoU作为损失函数,改进后方法有效提升了复杂场景下的人脸佩戴口罩检测精度和速度。
现有口罩佩戴检测算法多数需数据标注,且使用的网络模型参数量大,运算时间长,对硬件配置要求高,成本较高。为使口罩检测应用更为广泛,成本更低,同时保证检测的精度,本文提出一种基于MobileNet V2的口罩佩戴识别研究方法,使用轻量级网络减少网络模型参数量,减少运算时间,使用目标检测网络将口罩佩戴识别问题简化为分类问题。同时提出了基于数据扩充的MobileNet V2网络口罩佩戴规范性检测方法。
1 MobileNet网络模型
MobileNet网络是一种为嵌入式设备或移动端设备设计的轻量级卷积神经网络,自2017年4月MobileNet V1[7]被提出以来,逐渐发展、优化、更新迭代。MobileNet V1的核心思想是使用深度可分离卷积代替标准的卷积操作,但是这种操作会带来一些问题:一是深度卷积本身无法改变通道数量,若输入深度卷积的通道数较少,则只能工作于低维度特征,效果不好;二是无法复用特征。而MobileNet V2可以很好地解决以上问题。目前,MobileNet V2[8]已发展十分成熟且应用广泛。
1.1 激活函数
MobileNet V2继承MobileNet V1使用ReLU6[9]作为激活函数,比起ReLU激活函数,ReLU6限制后的最大输出值为6,主要目的是避免在便携式设备或移动设备上,使用低精度的float16描述大范围数值时造成的精度损失,从而影响分类特征的提取与描述,进而影响准确率。ReLU6表达式如下:
ReLU(6)=min(max(x,0),6) 。
(1)
1.2 深度可分离卷积
深度可分离卷积[10]即使用深度卷积操作和逐点卷积操作取代标准卷积操作。以F表示输入特征映射;G表示输出特征映射;K表示标准卷积,标准卷积的卷积计算公式[7]:
(2)
深度卷积的卷积公式[7]:
(3)
式中:k、l代表输出特征图大小;n代表输出通道数,数值上等于卷积核个数;m代表输入通道数,数值上等于卷积核的深度。
深度卷积操作即将卷积核拆解为单通道形式,在不改变输入特征图像深度的前提下,对每一个输入图像的通道进行卷积操作,使输入、输出的特征图通道数一致。这种情况下当输入的特征图通道数较少时,网络模型只能工作于低维度,无法确保获取足够的有效信息,需要对特征图进行升维或降维操作,本文使用逐点卷积实现。
深度可分离卷积与标准卷积对比示意图如图1。以12×12×3的输入为例,标准卷积使用256个5×5×3的卷积核,得到8×8×256的输出,而同样的输入经过深度可分离卷积操作欲得到相同尺寸的输出,需先对输入的每一个图像通道进行5×5的卷积操作,得到8×8×3的特征图,后使用256个1×1×3的卷积核进行逐点卷积操作,得到8×8×256的输出。
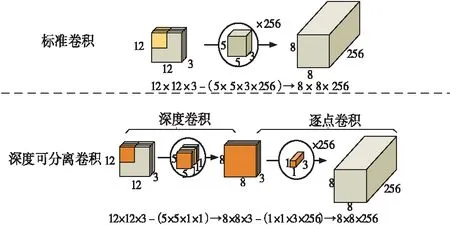
图1 深度可分离卷积与标准卷积对比示意图
假设卷积核的尺寸为Dk×Dk×M,共N个,即标准卷积的参数量是Dk×Dk×M×N,对每一个卷积核要进行DW×DH次运算,即标准卷积核要完成的计算量为Dk×Dk×M×N×DW×DH,深度卷积使用相同的卷积核尺寸,逐点卷积使用1×1×M尺寸的卷积核,共N个,即深度可分离卷积的参数量为Dk×Dk×M+M×N。两部分分别需要对每一个卷积核进行DW×DH次运算,则深度可分离卷积的计算量为Dk×Dk×M×DW×DH+M×N×DW×DH。将深度可分离卷积与标准卷积的参数量和计算量分别作比,可计算得出式(4)、式(5)。
参数量:
(4)
计算量:
(5)
1.3 逆 残 差
逆残差[8]作为MobileNet V2的核心,引入了shortcut[11]结构,实现了对于特征的复用,减小了模型的体积与计算量,与ResNet的shortcut结构对比如图2。Input表示输入数据;Output表示输出数据;input表示过程数据;PW表示逐点卷积操作;SC表示标准卷积操作;DW表示深度卷积操作。可以发现结构模式相同,但MobileNet V2将输入的特征图先升维,后进行卷积,最后降维,ResNet则相反。

图2 网络中shortcut部分结构对比图
1.4 线性瓶颈
深度可分离卷积与逆残差虽然减少了参数量但会损失特征,且激活函数ReLU6同样会产生低维度特征丢失的问题。对于高维度信息相对友好的情况下,MobileNet V2选择在降维操作之后将激活函数ReLU6替换为线性激活函数Linear,这一部分称为线性瓶颈(Linear Bottleneck)[8],如图3。
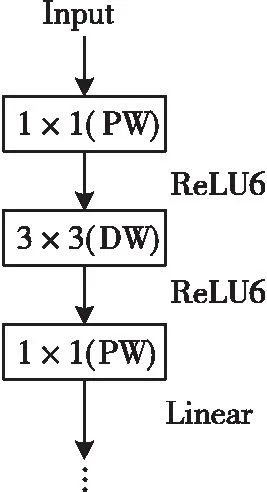
图3 线性瓶颈示意图
2 数据集构建
本文数据集采用RMFD(Real-World Masked Face Dataset)[12]中的真实口罩人脸识别数据集,筛选了3 180张人脸佩戴口罩目标和2 000张人脸目标,重新组合成本文使用的仅限于识别口罩是否佩戴的数据集1,包括佩戴口罩类(mask)和未佩戴口罩类(no_mask)。在重新组合数据集时发现数张口罩佩戴并不规范的目标,也计入佩戴口罩的人脸分类中,本文将这些不规范的图片提取出来,集合在一起划分为佩戴口罩不规范类(nonstandard),组合成识别口罩佩戴是否规范的数据集2。其中由于提取出的佩戴不规范图片较少,仅152张,与另两类数量差别较大,本文采取对图像进行添加高斯噪声[13]、均值平滑[14]的方式,将该类图片数据扩充至1 216张。其中添加高斯噪声与均值平滑操作后的图片与原图相比,肉眼难以分辨,但在像素级别上对输入数据进行了扩充,从而在分类识别时获得更多的特征进而提高准确率。
数据集包含图像类别及示例图像见表1。

表1 数据集2包含图像类别及示例一览表
3 实验结果与分析
3.1 实验配置
实验操作系统为Windows10,CPU型号为Intel Xeon E5-2623 v4 @ 2.60GHz,显卡型号为Nvidia Quadro P4000,64 G运行内存,CUDA Toolkit 9.1版本、CUDNN神经网络加速库7.1版本以及机器视觉软件HALCON。神经网络模型及训练参数如下:每次迭代训练样本数为32,分100个批次,动因子设置为0.9,正则化系数为0.000 5,初始学习率为0.001,每隔30个迭代周期,学习率减少为初始的0.1。
3.2 评价指标
本文引入准确率、召回率和精确率[15]对图像分类任务模型的性能进行评价。
准确率是预测正确的结果占所有样本的比重,其表达式为
(6)
式中:TP表示所有正样本中预测为正样本的样本;FP表示所有负样本中预测为正样本的样本;FN表示所有正样本预测为负样本的样本;TN表示所有负样本中预测为负样本的样本。
召回率是预测正确的正样本数占实际正样本数的比重,其表达式为
(7)
精确率是预测正样本中实际为正样本的概率,其表达式为
(8)
3.3 结果分析
本实验分为两个部分:第一部分为对真实人脸数据集口罩是否佩戴进行分类识别;第二部分为对真实人脸数据集口罩佩戴是否标准进行分类识别。两部分实验均采用MobileNet V2神经网络模型,MobileNet V2神经网络模型线性瓶颈块模型结构如图4。MobileNet V2神经网络模型整体结构图如图5。

图4 MobileNet V2神经网络模型线性瓶颈块

图5 MobileNet V2神经网络模型结构图
将两种数据集均以70:15:15的比例划分,数据集1的训练过程可视化如图6,数据集2的训练过程可视化如图7。

a)损失函数曲线 b)训练及验证过程误差曲线图6 数据集1训练过程

a) 损失函数曲线 b) 训练及验证过程误差曲线图7 数据集2训练过程
由图6和图7可知,MobileNet V2神经网络在两个数据集上的损失函数收敛性较好,误差函数收敛较快,训练过程平滑。将训练所得模型应用于测试集得到混淆矩阵见表2、表3。
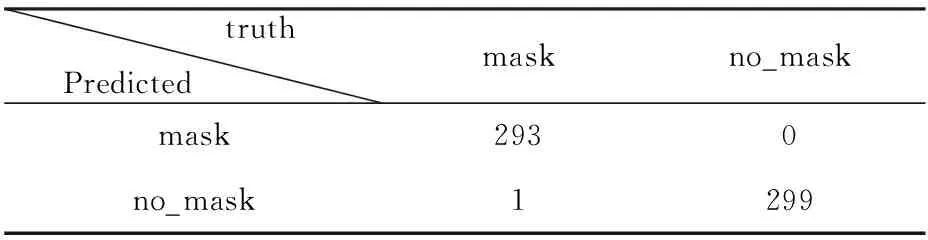
表2 数据集1测试集混淆矩阵

表3 数据集2测试集混淆矩阵
在显示结果时每个类别赋予一个数字代替,替代表见表4。

表4 数据集内不同类别数字替代表
MobileNet V2神经网络对数据集1的测试效果见表5,其中口罩部分被手部或其他物体遮挡时也可以较好地被识别。

表5 测试集1检测结果
MobileNet V2神经网络对数据集2的测试效果见表6,结果显示当被测目标佩戴反光物体使图片中有多个人脸出现时,模型也可以准确进行识别。

表6 测试集2检测结果
结合评价指标,计算两个数据集每个分类的精确率、召回率和平均准确率,评价结果见表7。
由表7的评价结果可知:MobileNet V2神经网络模型对于口罩是否佩戴以及佩戴是否标准的识别具有良好的效果,各类平均准确率、召回率和精确率均在97%以上,但是在识别佩戴是否标准时整体检测精度下降,这可能是因为佩戴不规范的图像样本较少,或佩戴不标准类与其他两类图像较为相似,模型进行了错误识别。
为了进一步验证本文算法的有效性,将本文算法与其他算法进行比较,结果见表8。其中,由于文献[6]中对于口罩的检测仅为是否佩戴,这里仅用数据集1的实验结果进行比较。

表8 算法性能比较
从表8的比较结果可知,本文算法平均准确率比YOLOV3算法提升19.3%,比改进YOLOV3算法提升4.4%,但对于多人脸目标检测,YOLOV3算法与改进YOLOV3算法均可实现多人脸同时检测,效率高于本文算法,但本文算法准确率较高,能在一定程度上满足实际检测需求。
4 结 语
本文针对已有口罩佩戴识别方法需要标注、时间成本高、硬件配置要求高等问题,提出一种基于MobileNet V2的口罩佩戴识别方法。该方法以MobileNet V2目标分类算法为基础,通过对原始数据集进行扩充,实现了高准确度、高效率的口罩佩戴识别及口罩佩戴是否规范的识别。通过RMFD数据集进行了有效性的验证,结果显示,该方法对口罩是否佩戴的检测准确率可达99.83%,对口罩佩戴是否标准的检测准确率可达98.97%,可以满足口罩佩戴检测的实际需求,具有较强的适用性。
