基于资源池的科技服务收益分配问题研究
2021-11-15赖祥宇
赖祥宇
(西南交通大学计算机与人工智能学院,成都 610031)
0 引言
随着云计算、大数据、物联网等新一代信息科学技术产业的创新发展,整个现代科技服务业的生态体系处于不断进化的过程中。由专业科技服务和综合科技服务构成科技服务解决方案也在现代产业中展现出愈发重要的地位[1]。综合科技服务云平台是国内领先的科技服务平台,它颠覆了传统供应链的线性协作关系,为客户提供极具创新型的科技服务,能够有效降低应用企业的经营成本、显著提升企业的管理水平和决策分析能力,达到增加企业经济效益的目的。
在传统的服务生产模式下,科技服务交易大多以单纯原始数据“粗加工”为主,数据挖掘预测、决策支持等服务的交易并未大规模展开,数据资源自身价值体现不明显[2]。随着基于资源池的服务交易技术的成熟和合作生产模式的形成,科技服务云平台使以上问题进行了改善,并且在利用资源池整合多个资源提供方的科技资源的基础上,有效解决了从服务产品的筛选检索、价格谈判、签约支付到实施验收、售后咨询等整个流程上的效率和管理问题[3]。研究和建立科学的、符合实际的收益分配策略,无论是对于平台还是资源提供方,都具有极为重要的现实意义。
对于合作生产模式下的收益分配问题,目前存在一些相关研究成果。如陈伟斌等人主要采用DELPHI法和AHP方法确定影响分配的指标权重,创建了基于集值统计的收益分成率计算方法[4]。李军主要在Shapley值模型的基础上,综合考虑了创新资源投入、创新创造收益和创新承担风险等因素,使用AHP方法对模型进行了改进[5],优化了协同创新联盟的利益分配问题。孙红霞等人引入三角模糊数将市场需求函数和企业单位成本模糊化,用模糊Shapley值在各局中人之间分配优先联盟在竞争中取得的最优模糊利润[6]。金明华等人在各主体的合作程度、承担风险以及技术创新能力等方面上进行思考,运用Delphi-AHP相结合方法,建立影响利益分配的指标体系,通过改进Shapley值法对产业链主体利益分配问题做出了解析[7],并证明了各主体在合作交易模式下取得更多的收益。
前人的研究成果主要具有以下特点:一是现有模型绝大多数是在Shapley值模型的基础上,采用AHP法进行改进,更偏重于定性分析,效果难以满足日益增长的企业需求;二是现有的研究对象主要是针对实体经济联盟的,即使采用定量的分配研究方法仍可能存在人为主观因素。综上所述,本文开展了基于资源池的合作生产模式下的科技服务收益分配研究,以网络平台的资源交易数据为支撑,通过人工智能方式确定各成员的资源价值投入,并对Shapley值模型进行改进,以实现对平台资源供方收益的科学合理分配。
1 基于GA-BP神经网络的资源价值评估模型
1.1 资源价值投入因素
科技服务是云平台的资源池中的各类科技资源在融合处理后所形成的一种高品质服务,因此各资源供方的资源价值投入是保证联盟收益分配公平性的一个主要因素之一。各资源供方企业由于其投入资源的特质因素和市场因素等方面的不同,导致了其对于用户使用的价值也存在差异化,每个联盟成员都有权利根据自身资源价值的投入来获取对等的回报。
在综合科技服务云平台历史运行经验的基础上,考虑到各影响因素的使用频率和相关变量的可获得性,本文基于资源的视角,将各资源供方的资源价值投入作为其收益分配方案的主要影响因素,首先采用GA-BP神经网络对其投入的资源价值进行评估,并在此基础上展开进一步研究。
1.2 BP神经网络及遗传算法
BP神经网络算法是Rumelhart于1985年在误差反向传播理论的基础上提出的学习算法,它构建于多层前馈网络的基础上,由输入层、输出层和隐藏层组成,具备强大的数据识别能力和模拟能力,在解决非线性系统问题上具有明显优势[8]。然而,随着其应用和普及的不断深入,其自身存在的缺点也逐渐暴露,主要表现为学习过程中误差收敛速度慢、容易陷入局部最优等[9]。
遗传算法(genetic algorithms,GA)是一种模拟生物在自然环境中的遗传和进化过程而形成的自适应全局优化概率搜索算法,它遵循优胜劣汰、适者生存的原则,通过选择、交叉、变异三个基本遗传算子保留适应能力强的最优个体,从而在全局搜索下寻找到最优解[10]。
由于BP神经网络的初始权值和阈值一般都设定为某个范围内的随机值,该值选取的不当,往往是导致网络学习时间过长、陷入局部最优而非全局最优的主要原因。而遗传算法的全局寻优能力正是很好地弥补了这点,因此,将遗传算法与BP神经网络相结合,通过遗传算法来优化网络隐藏层、输出层阈值以及输入层与隐藏层、隐藏层与输出层连接权值,使得它们更加逼近全局最优的初始值,可以得到更好的拟合效果。
1.3 网络模型的建立
本文以评估合作联盟中各资源供方所提供的资源价值为目标,通过以下步骤建立基于GA-BP神经网络的价值评估模型[11-12]:
(1)根据相关文献阅读和专家咨询,并结合平台可获得资源数据的方式,将影响资源价值的因素归纳为6类指标[13-14],其具体描述如表1所示。

表1 资源价值影响指标描述

续表1
将采集到的资源数据进行清洗筛选,划分训练集和测试集,并对输入输出指标作归一化处理。
(2)初始化BP神经网络的输入层、输出层、隐藏层节点个数、学习率、迭代次数以及训练目标最小误差等参数,以确定网络的拓扑结构。
(3)定义遗传算法所需参数,包括种群个体数、代沟、最大遗传代数、交叉概率、变异概率等。
(4)以二进制编码的形式初始化种群,将其作为BP神经网络的初始权值和阈值。
(5)将训练后网络获得的测试样本的误差作为适应度函数,适应度越小的个体越为优秀。
(6)在未达到最大遗传代数前,根据优胜劣汰的原则选择适应性更优的个体进行保留,并对这些个体进行交叉、变异操作。
(7)将处理好的种群重新作为BP神经网络的初始权值和阈值展开训练,根据结果重新计算每个个体的适应度。
(8)判断最优个体适应度是否达到优化终止条件或最大遗传代数,若未满足,则返回步骤(6),否则继续执行下一步。
(9)将最终得到的最优个体作为BP神经网络的初始权值和阈值,使用训练集训练神经网络,直到达到预设的期望指标。最后利用训练好的神经网络,输入测试集评估资源价值评估的准确率。
2 引入修正因子的改进Shapley值法收益分配模型
2.1 Shapley值法基本模型
由L.S.Shapley于1953年提出的Shapley值法是一种用于解决n人合作对策问题的方法模型。当一个合作联盟中的n个成员从事具有经济效益的活动后都会获得不同的利益,但是当每个成员通过不同方式组成联盟后获得的利益要大于单独工作的利益之和时,Shapley值法可以对利益联盟中各成员的利益分配按照成员对联盟总目标的贡献程度进行计算[15]。
设合作联盟N={1,2,…,n},那么根据Shapley值法得到的合作联盟收益分配策略可以表示为:
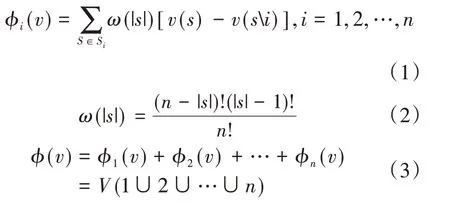
其中:ϕi(v)表示在合作联盟N下第i个成员的分配所得,Si表示集合N中所有包含了成员i的子集,S即可看作其中一个包含了成员i的子联盟,|s|表示子联盟S中所包含的成员个数,n代表合作联盟N中的成员总数,ω(|s|)所计算出来的是成员i的权重系数,v(s)是子联盟S所获得的效益,v(si)是子联盟S除去成员i后可获得的收益,ϕ(v)则是合作联盟的总收益。
从公式中可以发现,Shapley值法为强调收益分配的平等性而把合作联盟中各参与成员的边际成本都看作1/n,忽略了联盟中各企业成员在资源价值投入等方面的加权因素。
2.2 引入资源价值投入修正因子的Shapley值修正算法
在Shapley值法基本模型下,考虑的是每个联盟成员在资源价值投入均等的理想条件下所获得的收益分配为ϕi(v),也就是说各成员投入的资源价值比例为:L=1/n。假设在实际环境中各成员的资源价值投入比例为Li,则显然有合作联盟成员i在实际环境中的价值投入同理想条件下的差值∆Li,我们将其称为资源价值投入修正因子[16]:

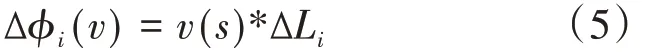
假设通过基于GA-BP神经网络的资源价值评估模型获得的各成员资源价值投入的总值为Ri(i=1,2,…,n),很容易得到:
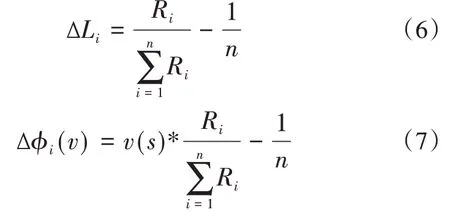
具体的修正方案可以表述为:当∆Li≥0时,表示该成员在实际合作联盟中提供的资源价值比理想条件更高,应当给予其更多的收益分配,其实际应当所得为:

否则应当扣除其部分所得:
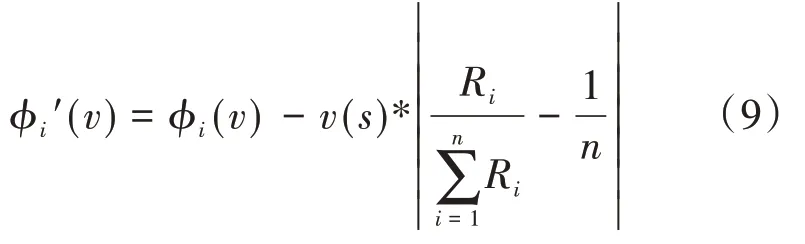
很显然地有:
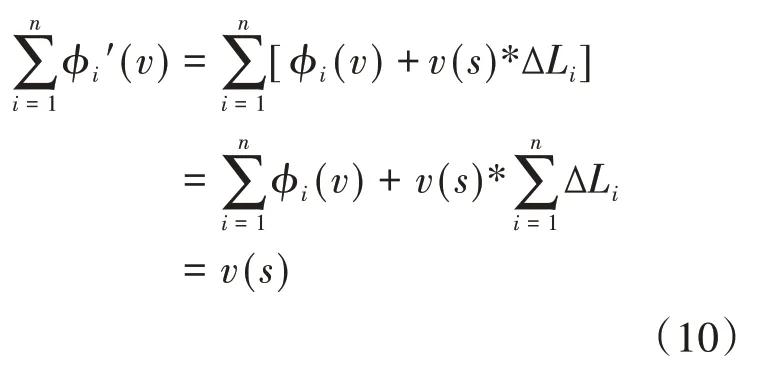
3 实验仿真与结果分析
3.1 数据来源与处理
本文实验所采用数据来源于部分国内较大的在线数据资源交易平台,采用爬虫软件采集了200余条涵盖电商运营、交通地理、金融服务、医疗卫生、知识产权、房地产等行业的用于交易的资源信息数据。每条数据包含了10类信息:交易资源数据名称、交易价格、用户浏览量、用户收藏量、用户下载量、资源数据格式、资源数据量、资源数据大小、资源数据发布时间、资源数据来源平台。对于采集到的数据,若在某个关键字段缺失数值,则直接删除;若数据大小单位为MB,则统一转换为KB。同时还将CSV、SQL、PDF等格式信息统一用数值表示,将数据发布时间转换为距今的天数。最后利用公式xi=(xixmin)/(xmax-xmin)将这些输入输出指标归一化到[0,1]范围内的数,以加快网络训练的收敛速度[17]。最终选取了200条可用实验数据,将其中160条作为训练集,40条作为测试集。
3.2 GA-BP神经网络模型设计
BP神经网络的输入层神经元节点数即数据集中影响资源价值的输入指标,这里设定为7。输出层神经元节点数为1,即资源数据的交易价格,用于评估资源价值。隐藏层只有一层,通过经验公式和实验效果确定其神经元节点数为9。设置网络的训练次数为1 000,训练目标为0.01,学习速率为0.1。用于优化神经网络的遗传算法初始种群数设定为40,最大遗传代数为50,交叉概率设定为0.7,变异概率设定为0.01。
3.3 训练结果分析
本文以MATLAB R2016a作为实验软件,为了更好评估训练模型的适用性,根据预设的参数分别进行了BP神经网络和GA-BP神经网络的构建、训练和测试,并通过均方根误差(RMSE)、平均绝对百分比误差(MAPE)等指标进行比较。
结合表2和图1可以发现,运用BP神经网络和GA-BP神经网络构建的模型都能够大致评估出资源价值及其走势变化,表明了BP神经网络是一种可以用来评估资源价值投入的有效工具。两种模型对比来看,BP神经网络的评估效果与实际值的差距更大,存在值得优化的地方;而GA-BP神经网络得到的评估值和实际值更加接近,评估效果更好。
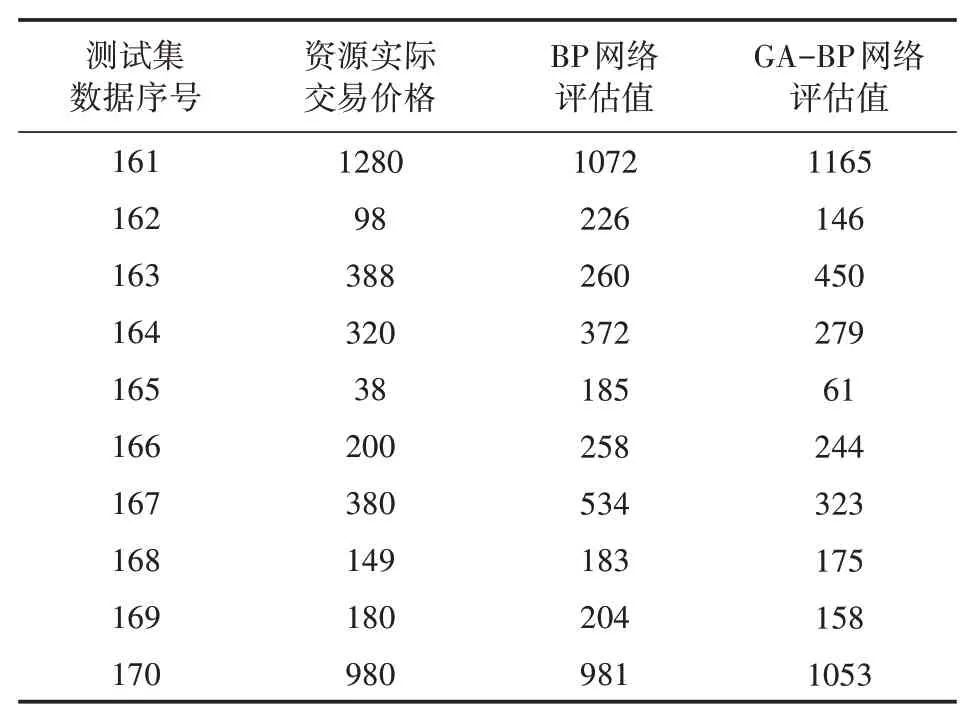
表2 部分测试集结果
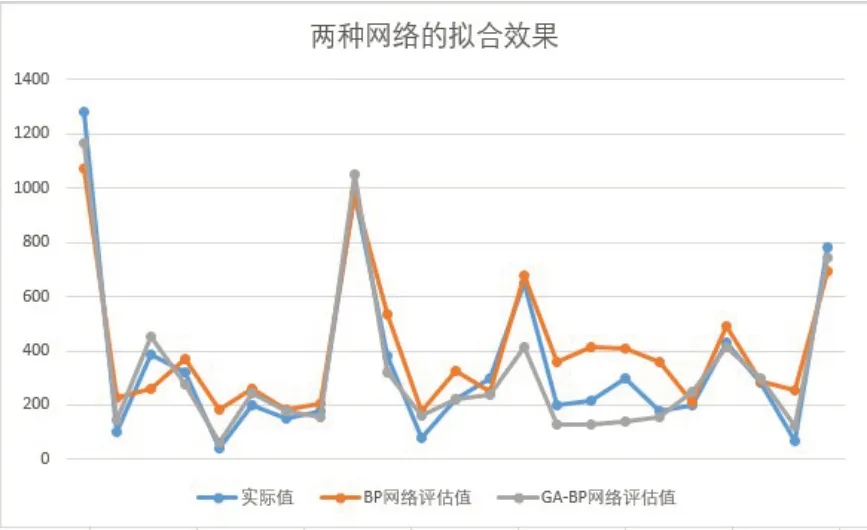
图1 两种网络的价值评估数值拟合图
本文将评估值与实际值的差值矩阵的2-范数作为误差标准,由于计算的是归一化的评估结果,因此显示误差值较小。由图2可以看出,随着遗传算法的加入和遗传代数的增加,评估结果的误差呈现出阶梯状下降的趋势,在达到最大遗传代数的停止条件时,其最小误差达到了0.2557,且仍存在继续减小的趋势。该结果证明了遗传算法能够有效优化BP神经网络的评估效果,且迭代次数越高,越容易逼近神经网络全局最优的初始权值和阈值。除此之外,BP神经网络和GA-BP神经网络均方根误差分别为250.2208和166.0310,平均绝对百分比误差分别为1.3430和0.9209。很显然这也再一次说明了遗传算法的加入使得资源价值投入评估效果得到了显著改善,训练得到的该网络可以用于评估合作联盟中各供方所提供的资源价值。
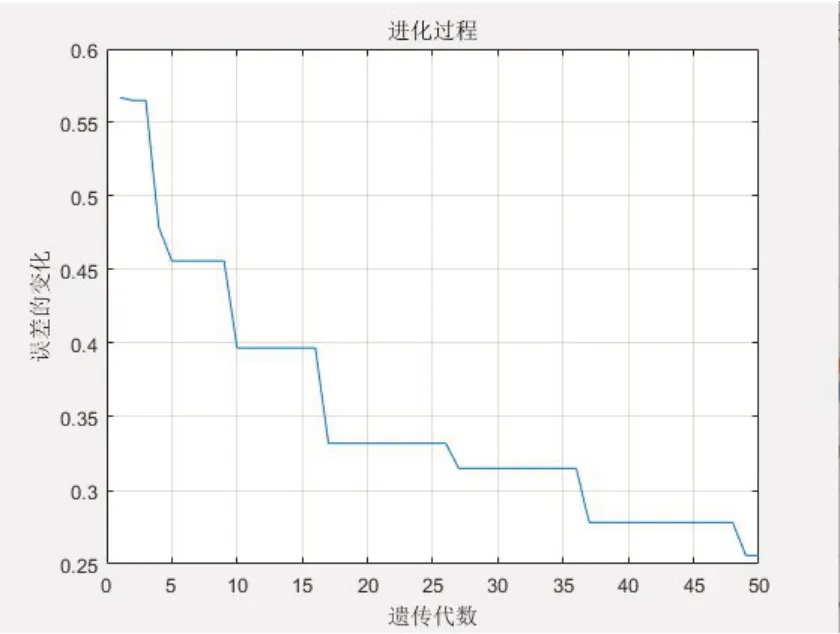
图2 遗传算法的进化过程
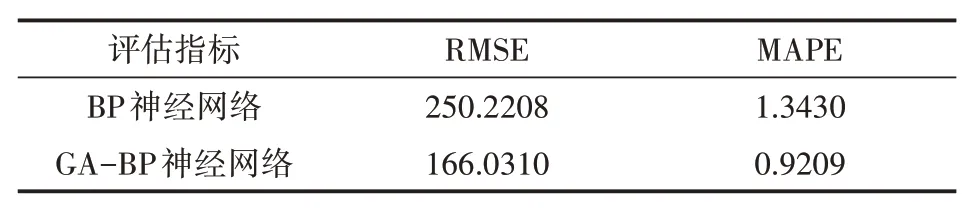
表3 神经网络效果评价
3.4 收益分配算例
目前综合科技服务云平台为用户提供科技服务所使用的资源主要来源于由A、B、C三家企业所形成的合作联盟,根据平台资源池中收集的资源信息,通过上文中训练好的神经网络评估其所提供的资源价值投入总量分别为:7.92万、9.43万、8.25万。假设在平台运行的某段时间内,由A、B、C三家资源提供服务可获得总收益v(A∪B∪C)=20万元,而仅由企业A资源提供服务可获得收益v(A)=4万元,仅由企业B资源提供服务可获得收益v(B)=7万元,仅由企业C资源提供服务可获得收益v(C)=5.5万元,由企业A、B资源提供服务可获得收益v(A∪B)=12.5万元,由企业A、C资源提供服务可获得收益v(A∪C)=10万元,由企业B、C资源提供服务可获得收益v(B∪C)=13.5万元。
由Shapley值法基本模型对A、B、C的收益分配进行计算,计算过程如下表所示。
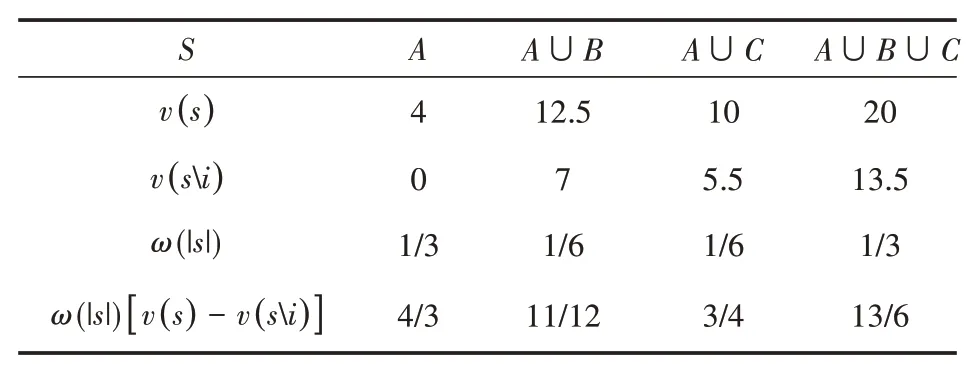
表4 Shapley值法计算过程
将最后一行相加,即可得A分配收益ϕA(v)=5.167万元。同理也可计算得ϕB(v)=8.417万元,ϕC(v)=6.417万元,将三者收益相加,忽略分数转小数时产生的误差,显然有ϕA(v)+ϕB(v)+ϕC(v)=v(A∪B∪C)=20。
上述分配结果仅考虑各成员对合作联盟所产生的基本经济效益,具有一定的片面性。接下来根据各资源供方的资源价值总投入并结合前文所总结公式,得到各成员的资源价值投入修正因子:∆LA=-0.024,∆LB=0.035,∆LC=-0.011,再进一步计算可得:
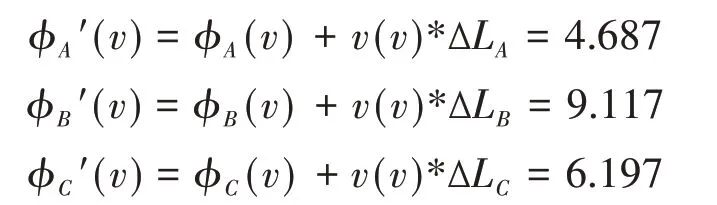
显然同样有ϕA'(v)+ϕB'(v)+ϕC'(v)=20,证明该分配方案可行。
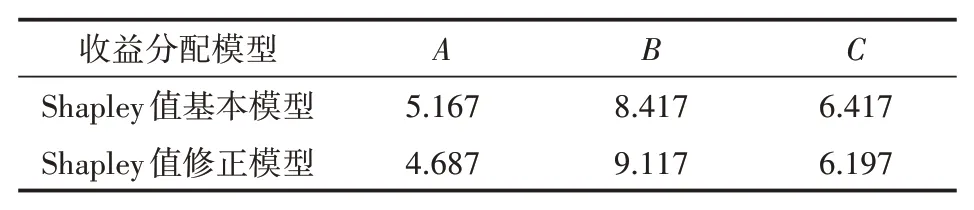
表5 两种分配方案对比
上两种方案对比可知,相较于Shapley值基本模型,引入修正因子的收益分配模型更加客观地反映了各资源供方的资源价值投入情况,对企业A和C而言,他们因为资源在价值贡献方面的不足而受到了少量的分成扣除,而企业B因为其提供的更多高价值资源而得到相应的价值投入奖励。总的来说,修正后的模型使得收益分配方案更加合理、客观和公正,同时也激励合作联盟中的各资源供方向资源池中投入更多高价值资源,为综合科技服务云平台的服务质量提升添加动力。
4 结语
基于资源池的科技服务收益分配问题是综合科技服务云平台在服务交易方面的关键问题,一个科学合理的收益分配方案既有利于加强资源提供合作联盟的协同发展,也有利于平台自身的稳定运营。本文在借鉴前人文献中提供的研究方法基础上,主要做出了以下创新研究:①基于资源的视角考虑了资源价值投入对于科技服务收益分配的影响,结合Shapley值法模型,选取可量化的评估指标进行了研究,打破了前人在模型改进过程中存在的分配影响因素主观化、难以量化的困境,为今后进一步的收益分配研究提供了参考价值。②提供了一种基于科技资源的特质因素和市场因素评估其价值的智能化方法,不仅为收益分配的调整方案提供了依据,还可为网络交易环境下的科技资源定价、高价值资源筛选提供了基础。
同样地,本文的研究也存在着一些不足:①受可获取到的实验数据的限制,只选取了7个可能影响资源价值评估的指标,实际环境中仍存在其他影响因素可用于研究。②研究所采用的数据来源于多家在线数据交易平台,数据样本依然较少,实验效果可能存在一定的误差。
未来相关研究主要可以从下面两方面来开展:一是深入优化基于神经网络的资源价值评估方法,例如对遗传算法中各参数的确定进行改进,或是尝试神经网络与模拟退火、蚁群算法等更多优化算法结合的可行性;二是继续从更多角度深入研究不同类型的因素对科技服务收益分配结果的影响,例如基于科技服务的反馈和基于资源供方的信用等,从而形成更为科学准确的收益分配方案。
