面向专业科技资源的服务定制推荐研究
2021-11-15邹宁郭栋
邹宁,郭栋
(1.西南交通大学制造业产业链协同与信息化支撑技术四川省重点实验室,成都 610097;2.北京机械工业自动化研究所有限公司,北京 100120)
0 引言
《国务院关于加快科技服务业发展的若干意见》(国发(2014)49号)[1]将科技服务业分为研究开发、技术转移、检验检测认证、创业孵化、知识产权、科技咨询、科技金融、科学技术普及等专业科技服务和综合科技服务[2]。而本文研究的专业科技资源主要面向研究开发、技术转移、检验检测认证、创业孵化、知识产权、科技咨询、科技金融、科学技术普及的科技资源[3],这些专业资源包括了专利、知识文献、论文、专家、企业、机构、高校等资源。
针对京津冀、长三角、成渝和哈长等城市群发展科技服务业的实际需求,本课题开发出了一个科技资源服务平台,面向各个城市群提供专业科技资源和服务,考虑到城市群的各个用户对专业资源的检索服务需求大,并结合科技资源服务平台,可以归纳出13项检索服务,分别是企业检索、中文专利检索、专家检索、机构检索、法律法规检索、科技成果检索、中文期刊检索、英文专利检索、作者检索、中文OA论文检索、外文OA论文检索、中文会议论文检索、高等院校检索服务,基于各个行业和领域,针对每个检索服务又细分子服务,有助于用户更好的检索、浏览、下载目标文章。
由于科技资源服务平台面向很多个城市群,提供检索、认证、设计、定制等服务,服务种类繁多,城市群上的用户使用服务频繁,难以快速找到自己想要的服务,同时平台也并不能基于用户的兴趣、职业等身份信息进行个性化推荐定制化服务,故为了更好的为用户提供服务,本文基于用户针对服务的使用次数、最近一次的访问时间、平均使用时间、总查看的页面数量进行综合计算出服务评分,分别再使用修正余弦相似度和融入差异因子的修正余弦相似度计算出目标用户和用户之间的相似度,找到目标用户的最近邻居集,基于最近邻居集中的各个用户对每个子服务进行打分,依次从高到底进行排序,为目标推荐相关性最大,感兴趣的服务,然后进行传统相似度计算的推荐算法和改进推荐算法的准确性验证和比较,从而选出更好的推荐算法用于系统中,进一步实现定制化服务推荐功能模块,实现用户推荐的定制化与个性化。
1 服务评分模型
针对本文研究和查阅相关文献,了解到基于用户的协同过滤算法必须要考虑用户对每个服务的打分,但传统的科技资源服务平台上并不能实现完全记录用户对每个服务的评分,存在数据稀疏性问题。为了解决该问题,本文根据用户针对服务的使用次数、最近一次的访问时间、平均使用时间、总查看的页面数量建立服务评分模型,通过具体的计算可以得到用户针对每个服务的得分情况。
用户对使用的各个服务的评分由4个关键指标—服务的使用次数、最近一次的访问时间、平均使用时间和总查看的页面数量决定,而且这4个指标是相互独立的,互不影响、互不依赖,使用这4个指标可以更好的度量用户针对服务的评分,故本文的服务评分选用这4个指标作为影响评分的主要因素,如图1所示。
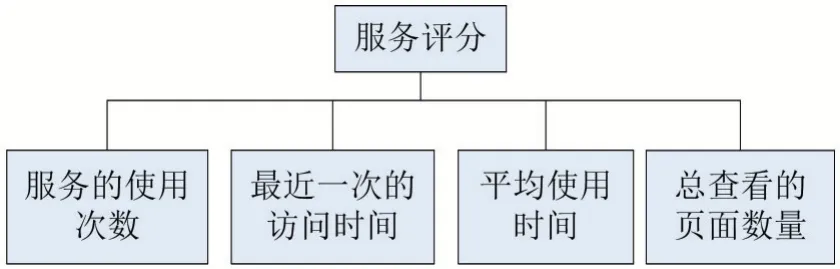
图1 服务评分的指标
服务评分的取值取决于图1的4个指标,而每个指标的取值范围不确定、取值类型也不相同,从而导致服务评分的数值也具有不确定性,因此本文给定服务评分的取值范围在0~5之间,这里5代表很喜欢、4代表较喜欢、3代表喜欢、2代表一般、1代表不喜欢。服务的使用次数、最近一次的访问时间、平均使用时间和总查看的页面数量各个指标的数量单位和取值范围都不大相同,所以不能直接进行数学计算,故在计算服务评分之前需要使用改进的Sigmoid函数[4]进行统一指标单位和取值范围,改进的Sigmoid函数即式(1)其中用h1(s)表示服务的使用次数的评分、h2(s)表示最近一次访问时间的评分、h3(s)表示平均使用时间的评分、h4(s)表示总查看的页面数量的评分,并且它们的取值范围在0~5之间。
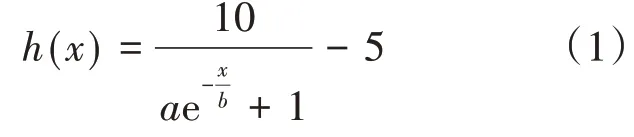
上面的式子中a和b代表阈值,可以根据实际的情况来改动。因此可以得知,服务评分实质是由服务的使用次数、最近一次的访问时间、平均使用时间和总查看的页面数量的各个评分,然后让每个评分和权重系数w1、w2、w3、w4进行相乘,并加在一起即为服务的评分:
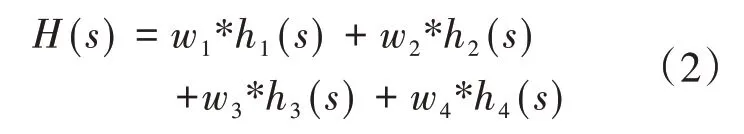
式(2)中:s表示一个服 务,h1(s)、h2(s)、h3(s)、h4(s)分别表示针对服务s,服务的使用次数的评分、最近一次访问时间的评分、平均使用时间的评分、总查看的页面数量的评分,且各个权重要满足w1+w2+w3+w4=1。
通过计算各个指标的两两比重,并对服务评分体系使用AHP层次分析法进行分析,计算得到4个指标对服务评分的影响权重[4],由此得到w1=0.4、w2=0.25、w3=0.2、w4=0.15时,服务评分H(s)度量用户的喜好程度较好,故本实验的服务评分模型采用以上权重,计算各个用户针对使用过的服务进行综合评分,计算出H(s),为下文基于用户评分来判断用户的之间的相似度,找到目标用户的最大邻居集作数据支撑。
2 面向专业科技资源的服务定制推荐研究方案
本文所研究的面向专业科技资源的服务定制推荐方案主要使用的是两种协同过滤算法进行研究和实验的,而且这里在传统算法上改进的协同过滤算法是引进了融入差异因子的修正余弦相似度的计算方法,通过对比两种算法的推荐精度和准确度,并最终选择适合的算法进行专业科技资源的服务定制推荐方案的设计。
协同过滤算法是指基于用户和基于项目的两种协同过滤算法[5]。针对用户协同过滤算法我们通常可以依据用户-项目评分矩阵,查找与目标用户有相似之处的其余用户,接着再找到所研究用户的最近邻居集,然后根据最近邻居进行项目评分预测,最后形成推荐的服务列表[6,7]。
针对上述服务评分模型的建立,可以计算用户对各个使用服务的打分,基于用户协过滤算法可以得到用户之间的相似度,并进行综合打分,将评分高的服务推荐给用户,并比较传统相似度计算的推荐算法和改进推荐算法的准确性验证和比较,从而选出更好的推荐算法用于系统中,进一步实现定制化服务推荐功能模块,实现用户推荐的定制化与个性化。本文服务推荐方案的具体设计流程如图2所示。
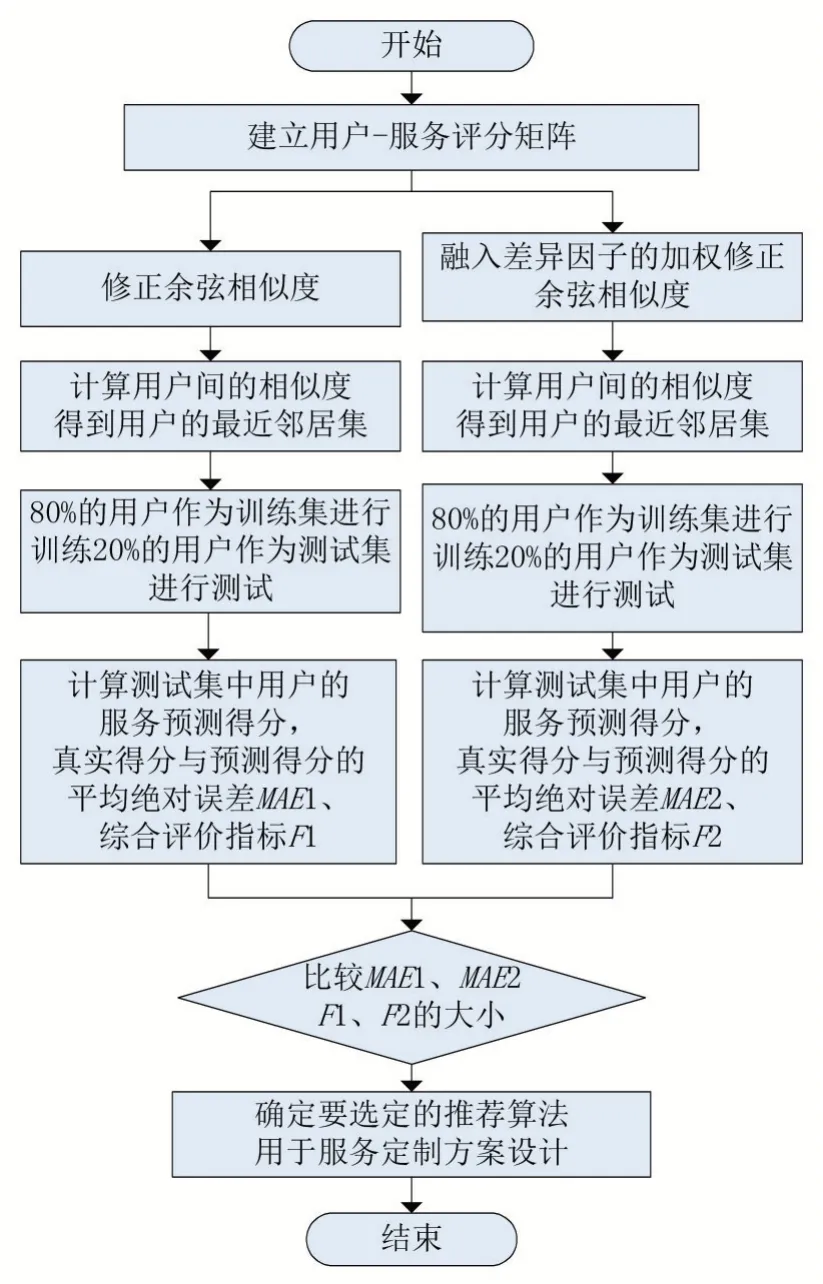
图2 面向专业科技资源的服务定制推荐研究方案设计图
首先基于用户已有的服务评分,建立用户-服务评分矩阵,使用了融入差异因子的修正余弦相似度计算的相似度和修正余弦相似度两种相似度计算方法,可以求得用户间的相似度,确定用户的最近邻居集,然后分别选取80%的用户进行训练模型,20%的用户进行测试实验,最终计算得到服务的预测评分、平均绝对误差的MAE1、MAE2、综合评价指标的F1、F2,综合比较MAE1、MAE2,F1、F2,确定最终要选定的推荐算法,用于服务定制方案的设计。
2.1 修正余弦相似度
在基于用户的协同过滤的算法中,我们经常会用到皮尔森相关系数、余弦相似度和修正余弦相似度3种方法来计算用户之间的相似度。这里的皮尔森相关系数是用来表示变量间线性关系的强弱,余弦相似度是求得两个向量夹角的余弦值,并用余弦值来表示两个向量之间的相似度,修正余弦相似度是在减去向量平均值的基础上再进行余弦相似度计算,求其对应的余弦值。定量度量问题常使用皮尔森相关系数,定性度量问题经常使用余弦相似度和修正余弦相似度[8],比如很喜欢、比较喜欢、喜欢、一般、不喜欢这一类评价就是定性问题。
因为本文研究的对象是用户对服务的评价,它属于定性度量,故可使用余弦相似度或修正余弦相似度计算用户之间的相似度。但是余弦相似度并不能很好的去考虑到用户评分过高、过低的情况,导致计算出来的余弦相似度值差别比较大,因此这里采用修正余弦相似度的计算方法,它是由用户对服务的评分减去对应的每个服务的平均得分,来克服求得相似值差异大的问题。
这里用Spq表示用户p和用户q对相同服务打分的服务评分集合,Sp表示用户p对服务打分的服务集合、Sq表示用户q对服务打分的服务集合,综上可得到用户p和q之间的修正余弦相似性度计算公式如式(3)所示[9]:
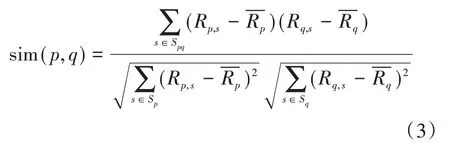
上面的式子中:我们用Rp,s代表用户p对特定服务s的打分,Rq,s代表用户q对特定服务s的打分,与表示用户p和用户q针对特定服务s的平均打分。
2.2 融入差异因子的修正余弦相似度
修正余弦相似度是基于用户的协同过滤算法中常用到的相似度计算方法,传统的修正余弦相似度在计算相似度时具有很大的缺陷,比如在数据维度比较高,数据也比较稀疏的条件下,用户之间针对相同服务进行评分的总项目数会过小,导致用户与用户之间的差异性更大,而且修正余弦相似度的计算方法容易过分的增加或者缩小用户之间的真实相似性,致使推荐算法的推荐效果不好,准确性能也不高。不仅如此,修正余弦相似度在计算时要求数据之间呈线性关系,而且残差要相互独立,均值要等于0,当这些条件不满足时,其计算准确度将会降低[10]。
本文引入一种融入差异因子的修正余弦相似度的计算方法,这种相似度的计算方法能有效解决修正余弦相似度对绝对数值不敏感的问题。改进的修正余弦相似度计算方法用差异因子作为权重和的修正余弦相似度计算方法进行结合,大大的解决了用户之间共同评分的数量对相似度的影响,以及用户评分对用户间相似度的影响。
改进的修正余弦相似度计算方法首先要计算出差异因子,这里的差异因子表示的是用户针对共同评分服务的评分差异度,差异因子越大,说明差异度就越大,即表明两个用户的相似度越低[11]。本文提出的用户间服务评分的差异因子计算过程如下:
(1)设用户u1和u2针对共同服务评分的服务集合为s={s1,s2,…,sn},u1和u2共同服务评分为和,将u1和u2共同服务评分差异d(u1,u2)定义为:
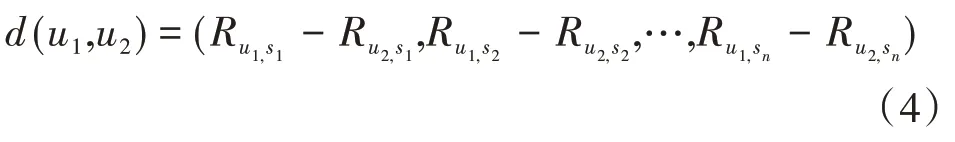
即:
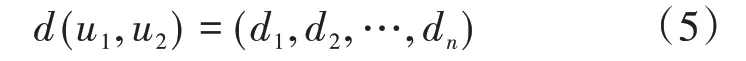
(2)欧式距离常用来计算两个向量之间的真实距离,这里使用欧式距离计算u1与u2之间的服务评分差异度,差异度dif(u1,u2)为:
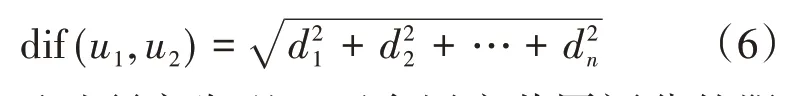
(3)通过研究发现,两个用户共同评分的服务总数n对相似度也有一定的作用,如果n的值越大,说明共同评分的服务总数就越多,两个用户之间的差异度就越小,这里使用1n作为权重系数,更新之后的差异度计算公式为:
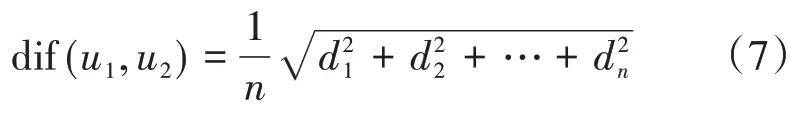
上式中:用n表示用户u1和u2共同评分的服务总数;u1和u2对第i个服务的评分,然后作差取得差值记为di。
(4)dif(u1,u2)取值范围是在0到∞,需归一化到(0,1)内。
由公式(7)可以得到,dif(u1,u2)值越大则表示两个用户之间的相似度就越低,故这里使用指数函数对dif(u1,u2)进行归一化,将其取值范围降到(0,1)内,并根据指数函数的单调性,并进一步调整差异度公式的单调性,这里控制单调性为单调增,即dif(u1,u2)对应的差异度值越大,它所表示的相似度就越高。
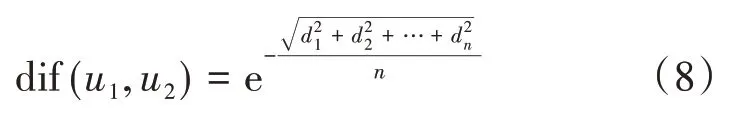
本文将评分差异度dif(u1,u2)作为差异因子来修正传统的修正余弦相似度,从而有效改善传统的修正余弦相似度对绝对值不敏感的问题,综上融入了差异因子的修正余弦相似度计算式为:
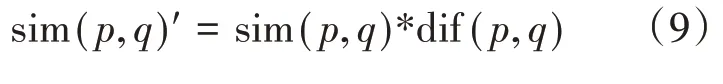
即:
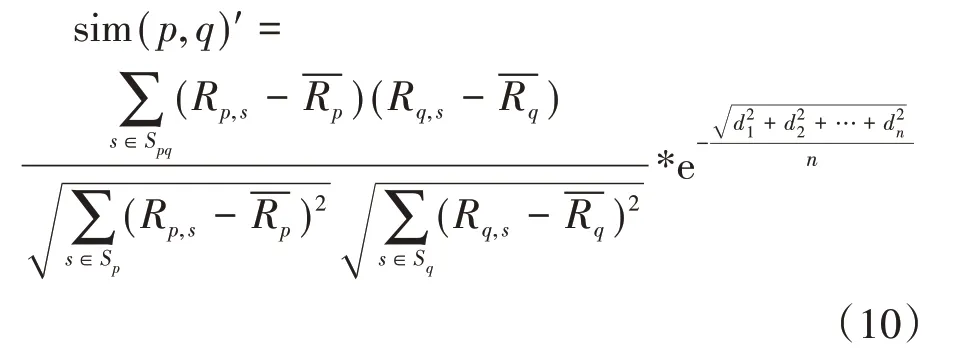
2.3 确定预测评分模型
通过以上两种相似度的计算公式,可以分别计算出各用户间的相似度,进一步确定用户的最近邻居集,而为目标用户推荐服务需要将最近邻居集中的每个用户对各个服务进行打分,即目标用户u的最近邻居集UNB对服务集合中的每个服务进行预测评分,从而可以得到预测服务评分表Pu,通过服务评分列表根据评分从高到低进行推荐[12]。这里用户u根据UNB对特定服务j的预测评分计算公式如式(11)所示。
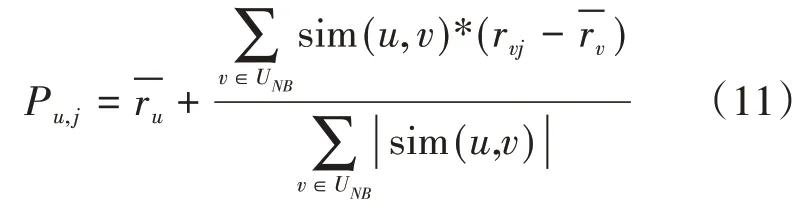
上面式子中,我们用Pu,j表示用户u对服务j的预测评分,UNB表示的是用户u的最近邻居集,sim(u,v)代表了用户u与用户v间的相似度。
3 实验和结果
本文主要基于协同过滤算法,使用修正余弦相似度和融入差异因子的修正余弦相似度两种相似度计算方法,找出目标用户的最近邻居集,依据最近邻居集中的每个用户对服务的综合评分,从而实现对专业科技资源平台上的各个服务为用户进行定制推荐,确定出两种服务定制推荐方案,依据实验得到两种推荐方案的性能,确定最佳的方案用于专业科技资源平台的服务推荐。
3.1 实验配置
本实验所用到的开发工具包括PyCharm,MySQL 5.6,硬件为Intel(R)Core(TM)i7-6500U CPU@2.50 GHz处 理 器、2.50 GHz CPU和12 G RAM,在Windows 10的操作系统环境运行。
本实验所用的数据集来自于科技资源服务平台,使用随机抽样的方法选取200个用户,13个大服务下的117个子服务进行实验,13个大服务指的是企业检索、中文专利检索、专家检索、机构检索、法律法规检索、科技成果检索、中文期刊检索、英文专利检索、作者检索、中文OA论文检索、外文OA论文检索、中文会议论文检索、高等院校检索服务,117个子服务指的是每个大服务下针对各个行业、领域细分的服务,便于用户可以更好的使用服务,快速检索、查询、下载目标文章。
本实验统计200个用户针对服务的使用情况,然后使用服务评分模型计算每个用户对使用过的服务进行评分,通过计算得到200个用户对117个子服务共有1500个评分,评分取值在1~5之间,然后在200个用户中随机选取80%用户作为实验的训练集,剩下的20%用户作为实验的测试集,每次实验在测试集中随机抽取10个用户作为推荐对象,再基于传统和改进的用户协同过滤算法进行预测,得到用户对各个服务的评分,并将服务作为候选服务集和真实的服务集进行对比,确定传统和改进算法的优劣性。
本实验使用平均绝对误差、综合评价指标来评价传统算法和改进算法的推荐性能,具体的评价指标描述如下:
(1)平均绝对偏差(MAE)指的是用户对服务进行评分的真实值与预测值进行相减,并得到差值,接下来再求差值的绝对值的平均值,计算出来的值用来表示推荐算法的预测性能,MAE的值越小,表示预测的越准确,也表示推荐的质量越高[13]。
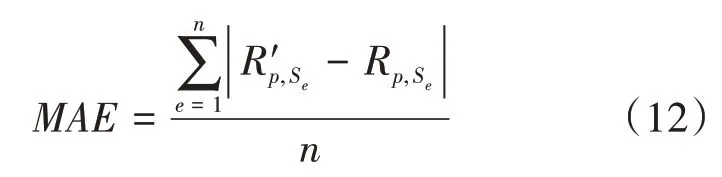
上式中:R'p,Se代表用户p针对特定服务Se评分的真实值,而Rp,Se代表用户p针对特定服务Se评分的预测值,n表示在当前测试集中用户对具体服务评分的总个数。
(2)综合评价指标 综合评价指标(F)是结合了准确率(P)(指的是在推荐结果中用户所喜欢的服务数量与所有服务数量的比值)和召回率(R)(指的是在推荐结果中用户喜欢的服务数量与用户所有喜欢的服务数量的比值)的评价指标[14],计算出来的值能够反映出推荐算法的综合能力,其中F的值越大,所表示的推荐性能越好、推荐质量越高,具体使用的公式如下所示:
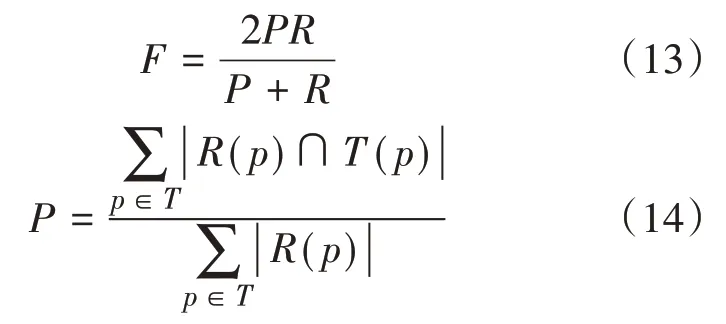
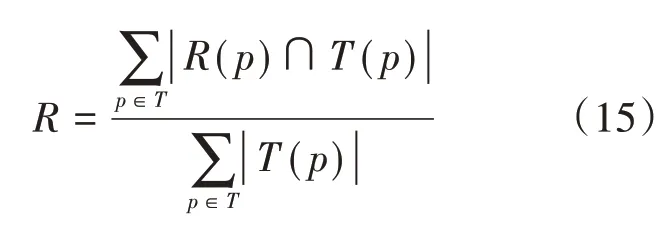
上式中:R(p)代表协同过滤算法推荐给用户p的所有的服务个数,而T(p)代表用户p所有喜欢的服务个数,p代表的是用户集合T中的用户。
3.2 实验结果
本文针对实验中的训练集进行算法训练,取用户的前30个最近邻居进行预测评分,并结合实验中的测试集进行对比,依据公式(12)计算平均误差损失率,从而可以得到MAE随着最近邻居数量的变化而变化,同时也可以看到针对数量相同的最近邻居,传统算法和改进算法对应的MAE值的大小。
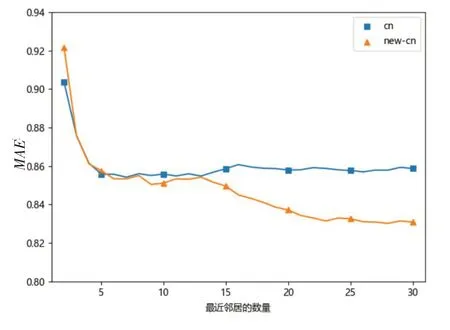
图3 MAE与最近邻居数量的变化曲线
由图3可知:当最近邻居数量大于5时,改进后的协同过滤算法的平均绝对误差MAE低于传统的协同过滤算法,其中当最近邻居数量等于30时,明显低于传统协同过滤算法的MAE,这充分说明了融入差异因子的修正余弦相似度计算公式起到了关键性的作用,提高预测评分的准确率,也大大的提高服务推荐的准确性。
在新用户推荐具体服务的实验中,在同样的实验环境下,从用户的测试数据集中随机抽取10位新用户,使用本文中的两种推荐算法分别为每位用户推荐相应服务,这里最近邻居取前30个,推荐的服务列表取前6个,新用户的顺序与计算所得到的F值对应的关系如图4所示。
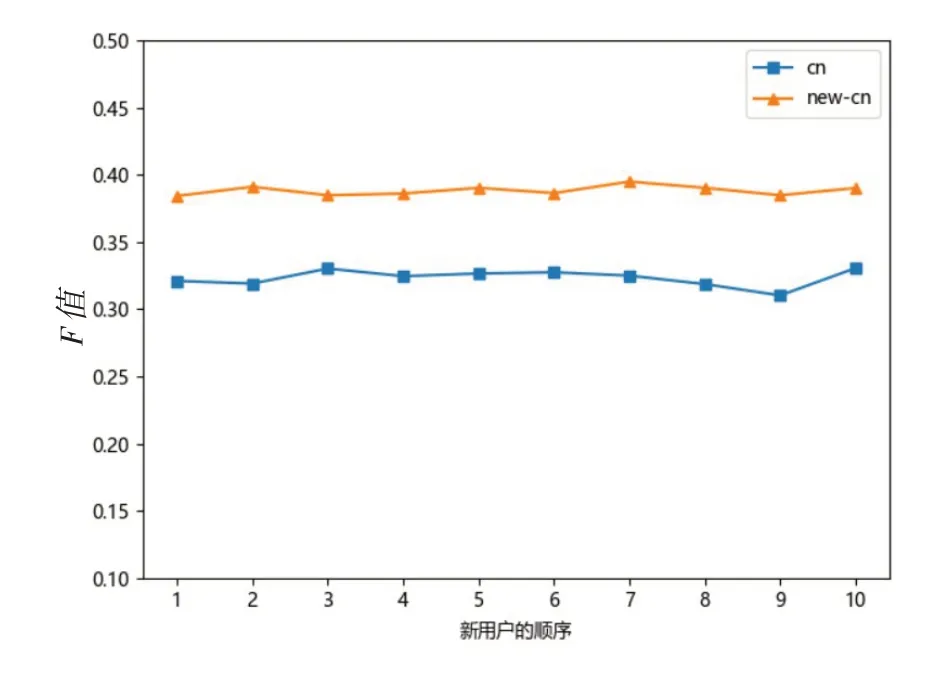
图4 针对新用户推荐的综合评价F值变化曲线
由图4可知:新用户推荐质量的综合评价指标F值在0.33~0.39之间,而且改进后的协同过滤算法F值要大于传统协同过滤算法的F值,充分说明了融入差异因子的修正余弦相似度能够提高服务推荐质量,同时可以观察到F值浮动比较小,说明改进后的协同过滤算法可以为用户感兴趣、有价值的服务。
4 结语
针对专业科技资源的服务定制推荐研究,让用户可以在科技资源服务平台上更好,更快速的使用想要的服务,即为每个用户生成特定感兴趣、有用的定制服务功能板块,供用户快速使用,为用户节省大量筛选和查询的时间,并提升用户的满意度。故本文将用户使用服务的情况,量化为具体的服务评分,并用传统的协同过滤算法和改进的协同过滤算法建立用户-服务评分矩阵,计算用户间的相似度,确定最近邻居集,并为服务进行综合打分,为用户推荐目标服务模块。通过实验表明,改进的协同过滤算法融入差异因子的修正余弦相似度计算公式,相比传统的协同过滤算法,大大的降低MAE(平均绝对误差),提高了F值(推荐质量),故面向专业科技资源的服务定制推荐研究方案可以使用改进的协同过滤算法进行设计和实现功能模块的定制推荐,这有助于为用户推荐更加有价值,更加满意的服务。
