基于信息最大化生成对抗网络的图像隐写方法
2021-11-14刘义铭过小宇牛一如
刘义铭,过小宇,牛一如
(1.保密通信重点实验室,四川 成都 610041;2.中国电子科技集团公司第三十研究所,四川 成都 610041)
0 引言
图像隐写是在图像中隐藏信息,使得隐藏信息无法被轻易检测的技术[1],常用于秘密通信,是信息安全的热门话题之一。近年来,在图像隐写技术发展的过程中出现了2个不同方向:① 对隐写算法进行优化,使隐写算法更加安全,嵌入信息更不易被检测到;② 对载体图像进行优化。基于生成对抗网络(Generative Adversarial Networks,GAN)的图像隐写正是后一种发展方向,这种图像隐写技术与生成对抗网络相结合的方法使图像隐写技术焕发出了新活力,显著提高了其安全性能,无论是载体的适用性、隐藏信息的安全性还是信息嵌入以及输出的准确性等方面都有了一定的进步[2-3],证明了基于生成对抗网络的图像隐写方法的研究具有一定的研究价值。
但是在图像隐写技术与生成对抗网络的结合中,传统对抗生成网络的生成器的输入是随机噪声,输出的是根据噪声产生的生成图像[4]。该过程不透明,无法得知噪声的每个维度分别控制着生成图像的哪些特征,又是如何控制的。而信息最大化生成对抗网络(Information Maximizing Generative Adversarial Networks,InfoGAN)[5]将生成器的输入分为两个部分,一部分是不可压缩的噪声向量,另一部分则是可以控制数据分布的语义特征的潜码。InfoGAN的这一特性可以很好地和图像隐写技术进行结合,若将潜码看作是秘密信息,便既可以实现秘密信息的隐藏又不经过信息嵌入的过程。同时,InfoGAN的这一特性使得解密过程也变得容易,只要做好秘密信息和潜码对应的码表,发送方和接收方同时持有这一份码表,都能很容易地对想要传输的秘密信息进行加密和解密。
基于上述讨论,在对深度学习和视觉关注机制的相关技术分析的基础上,使用InfoGAN实现图像隐写,通过在生成器中输入具有极大互信息的潜码与噪音,使用二者共同生成含密图像,通过真假图片判别器输出真实图像和生成图片的混合体,最后经由标签分离判别器分离出潜码。由于整个加密过程中没有传统图像隐写方法的信息嵌入过程,该方法具有更加强大的抗隐写分析的能力。
1 基于信息最大化对抗生成网络的图像隐写方法
1.1 InfoGAN图像隐写方法
InfoGAN是GAN网络的一个创新。传统GAN的输入是连续噪声向量z,但对生成器如何使用该噪声的方式没有限制。因此,生成器可能以高度纠缠的方式使用噪声,导致z的各个维度不对应于数据的语义特征[6-8]。而InfoGAN则将输入噪声矢量分解为两部分——不可压缩噪声来源z和针对并影响数据分布的显着结构化语义特征c,c被称为潜在代码(Latent Code)。因此,InfoGAN不是使用单个非结构化噪声矢量,而是使用的互相之间具有很大互信息的z和c。在数学上可以用c1,c2,...,ck表示潜在变量的集合。在其最简单的形式中,可以假设为如下形式的因式分布:
该方程代表各自的潜在代码ci概率独立,互不影响,即:
p(c1,c2,…,ck)=p(c1)×p(c2)×…×p(ck)。
InfoGAN将生成器的输入改为2个部分,则可得出如图1所示的网络结构。
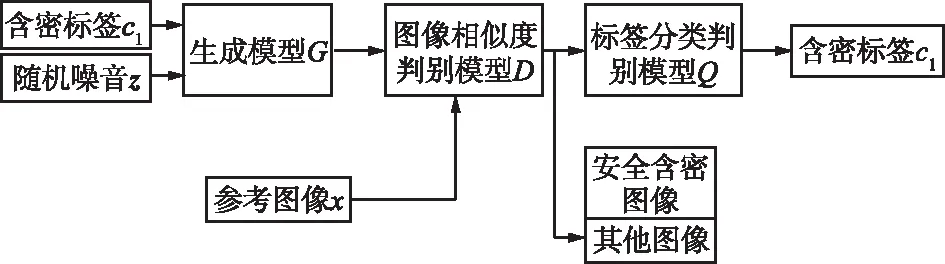
图1 InfoGAN图像隐写方法的网络结构图Fig.1 Network structure of InfoGAN image steganography method
参考InfoGAN的设计思想,将随机噪声z和潜变量(含密标签c1)一起作为生成器G的驱动。随后将参考图像x输入判别器,使用含密图像生成模型G与图像相似度判别模型D博弈,循环训练生成隐藏有秘密信息的图片。再由标签分类判别模型Q在对含密图像的含密标签进行分离,最后将标签输出,完成解密过程。且由于InfoGAN使用含密标签用作密文的索引,所以加密内容较为限制,占用容量不大,节约空间。因此,使用InfoGAN实现图像隐写,最大的优点是没有嵌入操作,并且可以使用判别器Q提取机密数据。
1.2 生成模型G
在InfoGAN图像隐写网络结构中,生成模型G用于生成安全含密图像。本文所提出的InfoGAN的生成模型由4个卷积层[9]组成,在进行操作时,每个卷积层都会对输入的噪声进行3个操作,依次进行逆卷积操作,再经过一个正则化层,进行归一化操作,最后使用激活函数进行“激活”。隐写网络的生成模型G的网络结构如图2所示。

图2 生成模型G的网络结构Fig.2 Network structure of generative model G
图2中,k代表卷积核大小,n代表通道数,例如RGB图片有3个通道,而灰度图像则只有一个通道数,s代表步长。
其中,逆卷积操作分为3步,在传入的参数中给定了输入与卷积核设置,第一步为对输入的矩阵进行一些变换,得到新的卷积,第二步为求新的卷积核设置,得到新的卷积核设置,最后用新的卷积核在新的矩阵上做常规的卷积,得到所需要的逆卷积的结果。
在正则化层中,将c-out(经过逆卷积操作之后输出的新矩阵)归一化到一个均值为0,方差为1的正态分布里。需要注意的是这个归一化操作并不是将每一层输出后的数据都归一化,因为此种情形会导致每一层的数据分布都是标准正态分布,导致其完全学习不到输入数据的特征,本文所使用的BatchNorm2d方法对每个Batch做均值和方差归一化处理,并在预测过程中通过训练数据进行估算。由于深度神经网络的训练十分复杂,每一层的输入分布在训练期间都会发生变化,因此需要对逆卷积操作生成的新矩阵进行归一化操作,即必须使用一个较低的学习率以及对参数进行很好的初始化。但是这也会带来一定的负面影响,即在降低训练速度的同时也使训练饱和非线性的模型变得十分困难。这种现象被称作内部协变量偏移(Internal Covariate Shift,ICS)。对于一个神经网络来说,前面卷积层的权重参数不断变化时,必然导致后面卷积层的权重参数发生改变,而Batch Normalization可以弱化隐藏层权重分布变化的程度,即重整了关于权重(Weight)和偏移项(Bias)的线性函数Z,限制了前面卷积层参数更新而影响Z数值分布的程度,使得这些数值更加稳定,将前后不同的层之间的耦合程度降低,使得每一层不过多依赖前面的层,能够获得更高的学习速率而不用过于关注初始化,帮助网络更好地收敛。
最后使用激活函数进行激活,本文在前面几层使用的是ReLU[11]激活函数,最后一层使用的是Tanh[12]激活函数。然后用多个神经单元进行组合,可获得更强的分类能力。
1.3 真假图片判别模型D
真假图片判别模型D的作用是对输入模型D中的图片进行真假判断。在判断真假图片这一功能上判断器大体操作分为两步:提取特征以及对提取的特征进行分类,区分输入判别器的是真实图片还是虚假图片。整个项目的真假图片判别模型D的网络结构如图3所示。

图3 真假图片判别模型D网络结构图Fig.3 Network structure of true and false picture discrimination model D
真假图片判别模型D的特征提取层由3层卷积层组成。每一层卷积层之后会对输出进行归一化操作,最后使用LeakyReLU[13]激活函数进行操作。本文对卷积操作设置了6个参数,分别为in_channels(输入图像的通道数)、out_channels(通过卷积层之后产生的通道数) 、kernel_size(卷积核的大小)、stride(卷积操作的步长,默认值为1,这里设置为2可以缩小特征层的大小)、padding(将0填充到输入的两侧)和bias (若为True,则会为输出添加可学习的偏差)。通过第1层卷积层将输入的图片输出64个矩阵,然后将输出送入正则化层进行归一化操作。最后将经过归一化操作的输出融入激活函数中。判断模型D所使用的激活函数是LeakyReLU激活函数。在总共3层的卷积层中,每一层都做这3步操作,最终得出所需要的特征值。根据所设定的网络结构,输入判断模型D中的图片包括生成网络G生成的含密图片和数据集中的真实图片。这些图片通过判断模型D中的特征提取层,输出的是1 024个矩阵,而最后这些特征值则通过分类器最终会得到一个0~1区间内的数,如果这个数大于0.5就认为它是真实图片,相反地,这个数小于0.5则认为它是生成模型G所生成的伪图片。
输入判别模型D的既有真实图片又有生成模型G生成的虚假图片,当输入真实图片时网络会得到一个预测结果pred_f,同样当输入的是生成图片时网络也会得到一个预测结果pred_f。本文使用损失函数对真实结果和预测结果进行监督,得出二者之间的误差,再通过反向传播算法更新前面网络的参数,如此反复,经过多次的迭代使判断网络的效果越来越好。
1.4 标签分类判别模型Q
标签分类判别模型Q与真假图片判别模型D共享卷积层,可以减少计算花销,此外再通过2层卷积层实现标签分类的功能。与判别模型D是二分类的分类器不同,模型Q的分类为多分类的分类器。整个项目的标签分类判别模型Q的网络结构如图4所示。

图4 标签分类判别模型Q的网络结构Fig.4 Network structure of label classification discrimination model Q
与判别模型Q不同,因为判别模型Q是一个多分类的分类器,所以使用的损失函数与判别模型D不同。模型Q使用的是交叉熵损失函数[14],该函数用于度量2个概率分布间的差异性信息,可以认为是在给定的真实分布下,使用非真实分布的策略消除系统的不确定性所需要付出的努力的大小。交叉熵越小,证明计算出的非真实分布越接近真实分布。
2 实验结果与分析
2.1 含密图片成果展示
本文实现了基于InfoGAN的图像隐写。将潜码与随机噪声一起作为驱动输入生成模型中,使生成模型G与真假图片判断模型D竞争,通过反向传播算法更新权重参数,通过不断进行迭代训练,使二者的效果越来越好,最终达到所需要的效果。
经过不断训练之后生成的含密图片如图5所示。

图5 生成含密图片可视化Fig.5 Visualization of generated secret picture
图5中可以清楚地看见,随着迭代次数的增加,所得到的生成图片的清晰度与准确度都在不断地增加。
2.2 抗隐写性分析
在现代的隐写术中,大多数图像隐写都是将秘密信息嵌入到载体图片中,以类噪声成分的替代来实现秘密信息的隐藏。隐写分析术即是通过对载体图片的特征变化进行分析,从而判断所分析的图片是否载有隐藏信息。由于只要是通过嵌入算法进行的信息隐藏,必然会有原始载体图片某个部分数据的改变,一旦检测出来载体图片有修改过的痕迹,无论能不能破密,只要对整个含密图片进行破坏就能使秘密传输信息的目的无法实现。因此,若一个信息隐藏系统在将秘密信息嵌入(隐藏)到载体过程中,不改变载体的概率分布,则该信息隐藏系统在理论上是安全的[15-17]。这便意味着若能用将噪声与秘密信息进行某种结合,直接生成含密图像,便可以在根本上保证原始载体的概率分布不受任何影响。因此,本文通过InfoGAN实现了将噪声与含密标签一起送入生成模型中,同时影响生成图片的概率分布。这种方法将潜码与噪声结合到一起,不对载体图片做任何嵌入操作,即隐写分析无法根据载体图片和秘密信息的不相关性检测出图片被人为做过手脚。根据文献[15]中通过信息论所给出的隐写系统安全性定义可以得出,本文提出的基于InfoGAN的图像隐写方法在理论上具有十分强大的抗隐写性。文献[18]中提到Auguste Kerckhoffs所提出的6条密码设计与使用的基本原则,其中有一条便是密码系统的安全性取决于密钥而非算法。本文在InfoGAN的实现之外,提出了秘密信息与潜码c一一对应的码表,相当于通信密钥,没有这个码表在手里,无论如何也不能破译其含义。因此,本文提出的隐写方法可以抵御现有的基于载体图像数据分布异常的隐写分析方法。
除了对基于InfoGAN的图像隐写的安全性能进行了理论性分析之外,本文还将其与真实图像作为信息载体和生成图像作为载体再使用±1嵌入算法生成的含密图片进行了对比实验,使用隐写分析分类器S对其进行分类,其实验结果如下:真实图像的检出率为84.5%,SGAN[14]的检出率为73.5%,InfoGAN的检出率为1.5%。
由此可知,与将秘密信息嵌入真实图像的传统隐写方法或是以GAN生成嵌入载体再进行秘密信息的嵌入相比,基于InfoGAN所实现的图像隐写方法由于并没有对载体图像进行任何修改,是可以抵御现有的隐写分析技术的(检出率1.5%属于必然存在的误差)。
2.3 标签判别器Q分析
模型Q的设计意图是要将潜码解析出来进行输出,而解析器的精度关系着整个图像隐写功能的成败。因此,本文使用3 000组解密实验得出下列10个含密标签的解密精度,如表1所示。
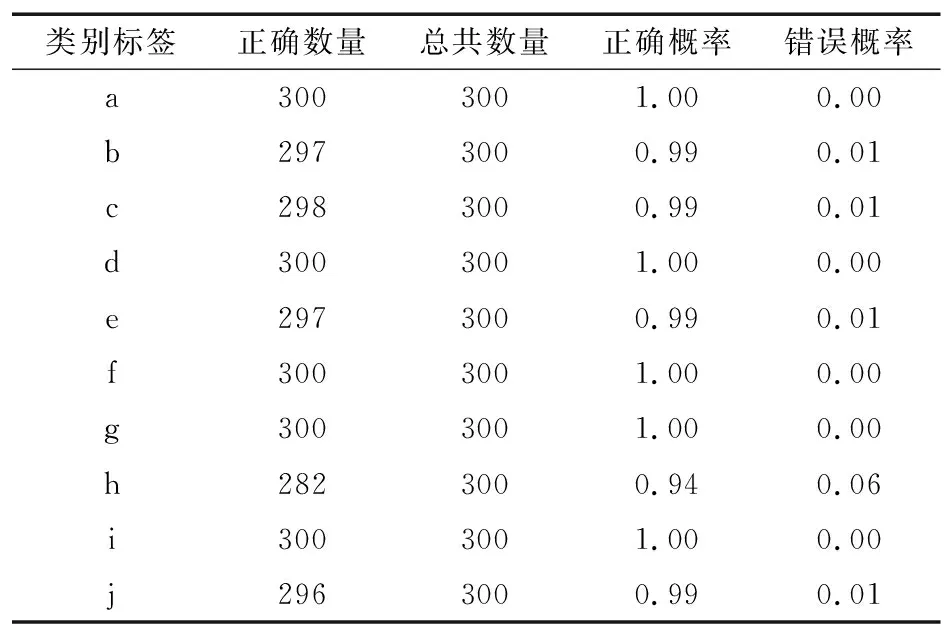
表1 Q模型准确率Tab.1 Accuracy of model Q
相对于现阶段普遍使用的GAN,InfoGAN更加适用于图像隐写,一是因为InfoGAN的潜码对应隐藏信息可以不通过复杂的隐写算法对隐秘信息进行隐藏;二是由于InfoGAN由于可以不经过载体图片的修改,于是相对于常规隐写算法具有更好的抗隐写性。
3 结束语
本文使用Pytorch深度框架实现了InfoGAN的图像隐写方法。所提出的图像隐写方法无需对载体图像某些不被重视的区域进行修改,而是实现了直接将“隐写信息”与噪声同时作为驱动生成含密图像,通过解码器进行多分类,将含密标签分离并输出。由于该方法从来源上进行隐写操作而没有对载体图片进行修改,所以这种无载体信息隐藏方法能够从根本上解决现有的隐写分析方法的检查,具有更高的安全性。在后续的工作中,将要寻找一种方法使含密标签的数量增多,并尝试将标签进行组合,成为新的含密标签,以增加码表的内容量。
