改进深度强化学习的室内移动机器人路径规划
2021-11-12郝密密
成 怡,郝密密
天津工业大学 控制科学与工程学院,天津300387
路径规划是移动机器人研究的重要方向,是实现导航任务的关键[1],即移动机器人从起始位置到目标位置能够自主探索出一条平滑且无碰撞的路径轨迹[2]。传统的路径规划算法有A*算法[3]、人工势场法[4]以及快速扩展随机树法[5]等,这些算法用于解决已知环境下的路径规划,且容易实现,但机器人在规划路径时存在探索能力差的问题。针对传统算法存在的问题,许多研究者引入了深度强化学习算法[6-8],让机器人在环境状态中能做出更准确的运动方向。深度强化学习由深度学习和强化学习相结合,深度学习通过感知环境来获得目标状态观测信息。强化学习通过获取的信息给予动作,再结合奖励判断动作价值,是智能体与环境不断交互试错,再利用奖惩函数指导动作好坏的过程。
Mnih等[9]提出第一个深度强化学习模型,即深度Q网络(DQN),该网络模型是将神经网络和Q-learning相结合,利用神经网络代替Q值表解决了Q-learning中的维数灾难问题,但在网络训练时收敛速度较慢。Tai等[10]把DQN应用到了无模型避障的路径规划中,但存在状态-动作值过估计问题,造成移动机器人获得的奖励稀疏,且规划出的路径并非最优。Yu等[11]提出一种基于深度强化学习的安全约束月球车端到端的路径规划算法,通过利用课程学习的思想,针对不同地形特征的月面环境对网络进行训练,提高了月球车对月面不同地形的适应性。根据地形的坡度角和当前状态来预测月球车的行驶率,设计安全奖励函数作为当前状态的奖励反馈。徐晓苏等[12]在Q值初始化的过程中引入了人工势场,便加快了网络的收敛速度,增加了动作步长和调整了机器人的动作方向提高了机器人规划路线的精度,该方法在机器人进行局部路径规划时效果较好,但在全局路径规划上实施性不好。
因此,为了有效解决机器人探索能力差和奖励稀疏的问题,本文提出一种基于深度图像信息的改进深度强化学习的路径规划算法,利用Kinect视觉传感器感知自身周围的环境信息,并结合自身的位置信息和将到达的目标点组成一个状态空间作为网络的输入,以实际的线速度和角速度作为机器人下一步动作的输出,且设计合理的奖惩函数,提高了算法的奖励值,改善了环境状态空间的奖励稀疏性。
1 深度强化学习
强化学习是智能体与环境交互时,通过“试错”方式得到不同奖励值的过程。如图1所示为强化学习交互过程。Q-learning[13]是一个值迭代过程,它会计算出每个Q值,在执行动作时,根据机器人所学的先验知识更新Q值表。然而,当机器人所处的环境状态变得复杂,则状态-动作空间会变得很大,便带来了“维数灾难”问题,导致模型很难形成或不能计算,而深度强化学习能有效解决此问题。

图1 强化学习流程图Fig.1 Reinforcement learning flow chart
深度强化学习(DRL)[14]由深度学习(DL)和强化学习(RL)两者相结合来实现端到端的学习,深度学习[15]负责通过传感器扫描周围的环境信息来感知机器人当前的状态信息,而强化学习[16]负责机器人对获取的环境信息进行探索,做出决策,从而实现机器人路径规划的智能化需求。
DQN算法[17]结合神经网络和Q-learning,神经网络以RGB图像作为输入,实现对Q值表的建模,表示所有的状态-动作值,Q-learning以马尔科夫决策建模[18],以当前状态、动作、奖励、策略、下一步动作来表示。DQN通过引入经验回放来提高机器人的样本关联性和效率利用问题,并通过固定目标Q值提高更新的不平稳性。DQN包括建立目标函数、目标网络和引入经验回放[19]这三个步骤:
(1)目标函数。DQN的目标函数通过Q-learning构建,公式如下所示:
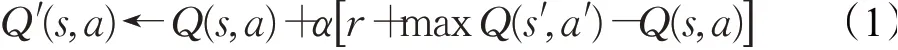
其中,(s,a)表示当前的状态和动作,(s′,a′)表示下一步的状态和动作,Q′(s,a)表示更新后的状态-动作值,在状态s下,得到动作奖励r,并对其进行评估。
目标状态-动作值函数用贝尔曼方程可表示为:

其中,y′表示目标Q值。
损失函数为均方误差损失函数,公式如下所示:

其中,θ为神经网络结构模型中训练的权值参数。
(2)目标网络。DQN通过目标网络和预测网络来评估当前的状态-动作值函数。目标网络基于神经网络得到目标Q值,利用目标Q值来估计下一时刻的Q值,以解决Q-learning中Q值表的“维数灾难”问题。预测网络使用随机梯度下降法更新网络权重△θ,梯度下降算法的公式如下所示:
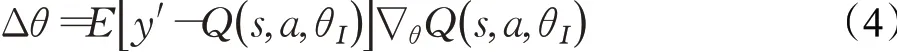
(3)经验回放。经验回放解决了数据的样本关联性和效率利用问题。在机器人和环境交互时,可获得样本数据库,把样本数据库存储到建立的经验池中,从经验池中随机抽取一小部分数据用于训练样本,再将训练样本送入神经网络中训练。经验回放主要起到样本本身可重复利用来提高学习效率。
2 改进的深度强化学习算法
本文提出了一种基于深度图像的深度强化学习的改进算法,该算法是移动机器人通过Kinect传感器感知周围环境状态获取深度图像信息和目标位置信息作为网络的输入,以机器人的线速度和角速度作为下一步动作的输出,实现在有障碍物环境下朝向目标点运行的过程,从而完成移动机器人的导航任务。机器人的主要目标是在室内未知环境下能够自主到达目标点并规划出更短的路径。
2.1 改进算法
改进DQN算法主要分为仿真和训练两部分,如图2所示,上面仿真部分说明了强化学习过程如何使用深度Q网络选择决策获得状态s和奖励r,下面网络训练部分说明了改进DQN网络优化参数的前向和反向传播过程。
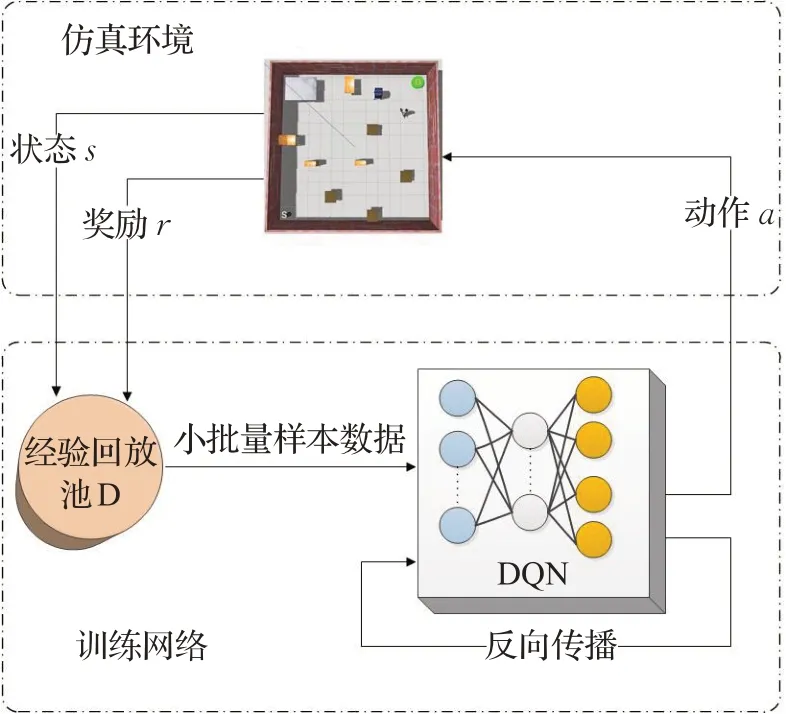
图2 改进DQN算法的主要组成部分Fig.2 Main components of improved DQN algorithm
在仿真环境中,机器人把直接采集的深度图像信息作为训练样本,再结合自身所处的环境状态特征和要到达的目标点作为网络的输入,并将当前位置下的Q值作为网络模型输出,且利用ε-greedy策略进行动作选择,来到达下一步状态。当到达下一步状态时,计算出相应奖励值r,便可得到一个完整的数据元组(s,a,r,s′),于是将该系列的数据存储到经验回放池D中,再从经验回放池D中抽取小批量样本放入神经网络中进行训练。其中,机器人在探索最优路径过程中,从经验回放池D中选取奖励值r非常关键,奖励值r决定了机器人路径规划的好坏程度。机器人把得到的奖励值r送到优化目标函数中进行网络参数的更新,一直循环迭代直到训练完成。如图3所示为本文算法的模型。
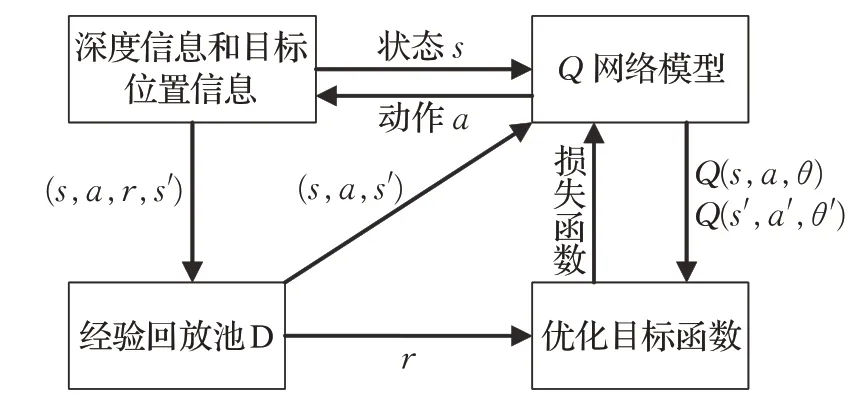
图3 改进的DQN算法模型Fig.3 Improved DQN algorithm model
在网络训练过程中,若机器人利用Kinect传感器识别出障碍物,则通过改进深度强化学习算法使机器人能有效的避开障碍物。否则,机器人将会继续导航,直到到达目标点。改进的深度强化学习算法设计如下所示。
算法1基于移动机器人改进的深度强化学习算法


2.2 设计改进的奖惩函数
奖惩函数是移动机器人在当前状态采取某一动作并到达下一状态获得的奖励值,表示当前状态采取某一动作的好坏。在强化学习中起到关键作用,决定了智能体的学习效率和效果。
移动机器人在执行导航任务时,要使训练网络产生可行的控制策略,给予机器人正确动作。在这一过程中,机器人与环境不断交互来得到反馈信息(奖励值),机器人接收到反馈信息继续与环境交互,同时评估将要执行的动作,从而使机器人更快地学习得到最优动作策略,根据动作选择策略设置合理的奖惩函数。机器人在运行过程中碰撞到障碍物会返回到起始点,重新开始探索路径,若到达目标点则会停止训练。
DQN算法的奖惩函数定义为:

其中,v表示线速度,ω表示角速度,dt表示每隔0.2 s循环训练一圈。
在运行过程中,速度是机器人行驶的关键因素,速度决定了机器人获得奖励值的正负。在机器人和环境交互时,通过设置奖励函数获得奖励值,根据奖励值评价机器人的动作好坏,然后机器人会积累自身的学习经验,再一一评价从环境中获得的动作,进而改变动作行为使产生的下一步动作更准确。为了使机器人快速准确地获取下一步动作,由机器人的转向角度cos(2vω)和线速度平方的2倍来共同决定奖励值的大小。其中,转向角度设为cos(2vω)是为了使机器人得到的转向角度更小,选择下一步动作更准确,所获得的奖励值更高。线速度平方的2倍是为了提高机器人在无障碍的情况下能加快运行速度。
改进DQN算法的奖惩函数定义为:

其中,v表示线速度,ω表示角速度。
由式(6)可知,机器人获得的奖励值是由线速度和角速度共同控制的。如表1为机器人的动作值和速度的对应关系。
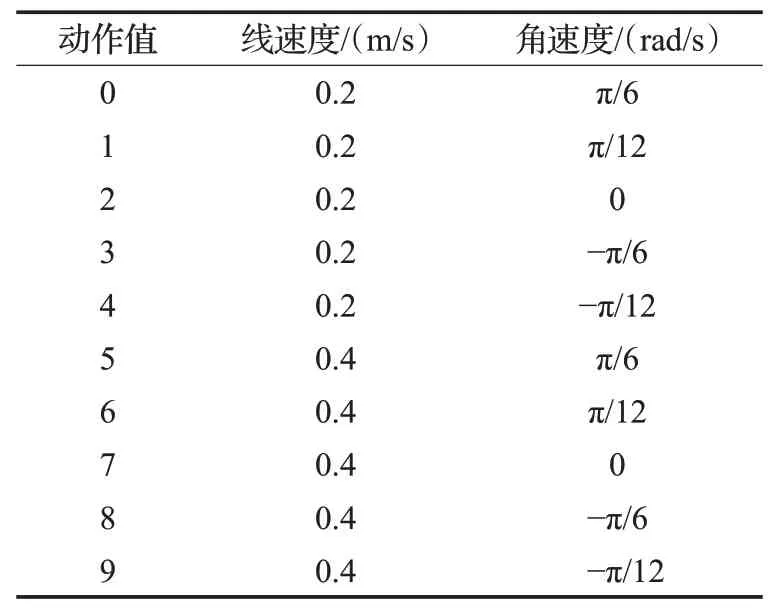
表1 机器人动作值和速度指令对应表Table 1 Correspondence table of robot action value and speed command
机器人依靠自身的经验探索学习,从记忆的动作中选择适应环境的行为。机器人在运行时,根据不同的情况设置相应的奖励值r,rtarget表示每个片段(episode)完成之后所有瞬时奖励值的累加,即到达目标点的总奖励值;rcollision表示机器人原地旋转或与障碍物发生碰撞时,会受到惩罚,奖励值为−10。因此,在训练过程中,每个学习片段(episode)将每隔500步更新一下目标网络的奖励值。
3 实验分析及结果
3.1 实验环境和参数配置
为了实现移动机器人避障实验,验证本文算法在路径规划中的有效性,并与DQN做了对比实验。实验环境为NVIDIA GTX 2080Ti GPU服务器,机器人的操作系统(ROS)[20]和Gazebo[21]完成的。机器人训练过程是在Gazebo中搭建的仿真平台上完成的,且机器人使用带有Kinect视觉传感器的Turtlebot。如图4所示,图中的“S”代表机器人的起始点,绿色的圆柱体“G”代表到达的目标点以及各种形状不同的障碍物组成的仿真环境。
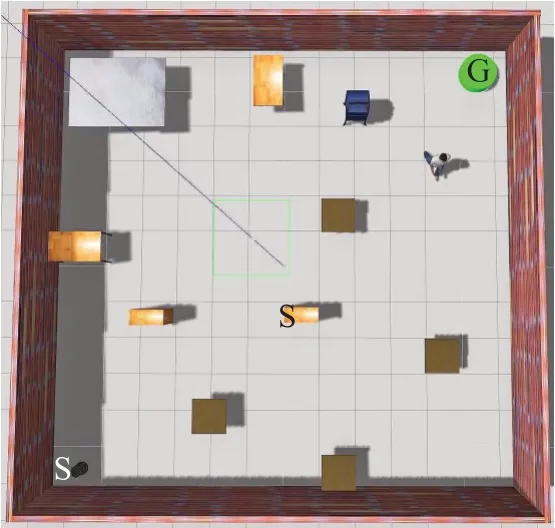
图4 仿真平台Fig.4 Simulation platform
移动机器人利用Kinect视觉传感器获取的深度图像信息和目标位置信息作为网络的输入,通过采集的深度图像提取数据信息,即物体与传感器的距离,再结合要到达的目标点形成一个状态空间,并以机器人实际的动作方向作为输出,机器人便可实现导航任务。在训练过程中,机器人避开障碍物是关键问题之一,它从起始点开始探索运行到达目标点结束。若检测不到障碍物,则机器人就会继续运行;若检测到障碍物,则会利用改进深度强化学习算法避开障碍物。当机器人碰撞到障碍物时,机器人将会回到起始点,重新开始探索。随着探索次数的增多,机器人记忆的动作会逐渐增加,则下一步动作的选择会更精准。图5代表机器人避开障碍物的过程,图中的黑色箭头表示机器人下一步要做的动作方向。图6为机器人在行驶的过程中遇到障碍物的深度图像信息。
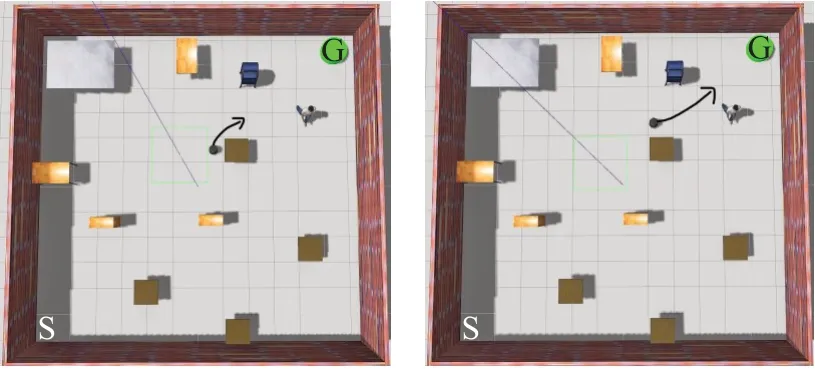
图5 避开障碍物的过程Fig.5 Process of avoiding obstacles

图6 遇到障碍物的深度信息Fig.6 Depth information of obstacles encountered
机器人以状态Q值作为输入,动作Q值为输出,便形成了状态-动作对。若机器人在运行时碰撞到障碍物,则会得到负奖励;若机器人到达目标点,则会得到正奖励。通过奖惩机制的方法使机器人在学习过程中避开障碍物而不断接近目标点完成路径规划这一过程。改进深度强化学习算法的参数设置如表2所示。
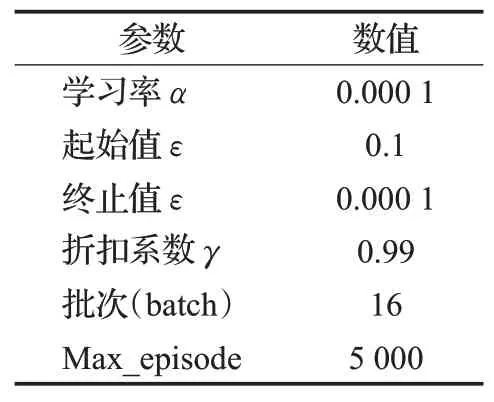
表2 参数设置Table 2 Parameter settings
3.2 实验结果分析
本文对DQN算法和改进算法利用平均奖励值和损失函数值做了分析和实验结果的对比。如表3列出了DQN、改进DQN算法平均奖励值和平均损失函数值的对比,改进DQN的平均奖励值比DQN提高了51.2%,改进DQN算法的平均损失函数值比DQN降低了15.3%。利用平均奖励值评估算法的性能。如图7所示,黑色线代表DQN算法运行得到的平均奖励值变化曲线,红色线代表改进DQN算法运行得到的变化曲线,蓝色线代表对改进算法进行测试得到的变化曲线。当奖励值为(−10~0)阶段时,在训练初期,机器人刚开始探索学习避障运行的过程,且未能对障碍物做出正确的判断,得到的是负奖励值。当奖励值为(0~20)阶段时,训练次数达到500,机器人处于探索学习阶段,表示机器人开始识别并能够避开部分障碍物,但它仍在和环境不断地交互学习进一步调整动作选择策略,来获得相应的正奖励值。当奖励值为(20~40)阶段时,训练次数在500~2 100时,机器人在DQN算法和改进DQN算法中获得奖励值都不稳定,训练次数达到2 100左右,DQN算法获得的奖励值趋于平衡。当奖励值为(40~60)阶段时,改进算法和测试阶段的训练次数达到1 500左右平均奖励值趋于稳定。测试阶段是利用训练的结果模型在相同环境中做测试进一步验证网络的有效性。测试和训练的平均奖励值的递增趋势一致。因此,改进算法可以缩短网络训练时间,提高平均奖励值,改善了奖励稀疏性,使机器人规划出更短的路径。

表3 平均奖励值和平均损失函数值对比Table 3 Comparison of average reward and average loss function value
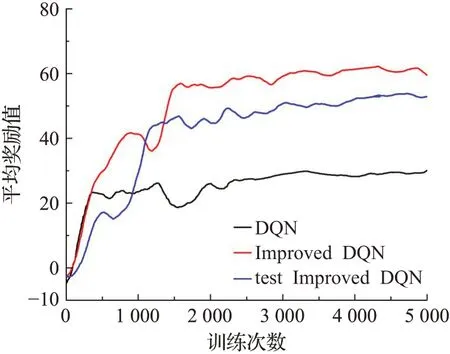
图7 平均奖励值对比图Fig.7 Comparison chart of average reward value
利用损失函数值评估算法的性能。如图8所示,黑色线代表DQN算法运行得到的损失函数值变化曲线,红色线代表改进DQN算法运行得到的变化曲线,蓝色线代表对改进算法进行测试得到的变化曲线。在训练初期,Q值的初始化为0,机器人的学习经验不足,只能随机选取动作,导致算法的收敛速度较慢。DQN算法得到的损失函数值波动较大,训练次数达到2 500左右,损失函数值趋于稳定。而改进算法的损失函数值波动性较小,训练次数达到1 000左右,损失函数值便能很快趋于稳定。测试阶段的训练次数达到1 200左右时,损失函数值趋于稳定。测试和训练的损失函数值的衰减趋势一致。因此,改进算法具有一定的优越性,加快了网络的收敛速度。
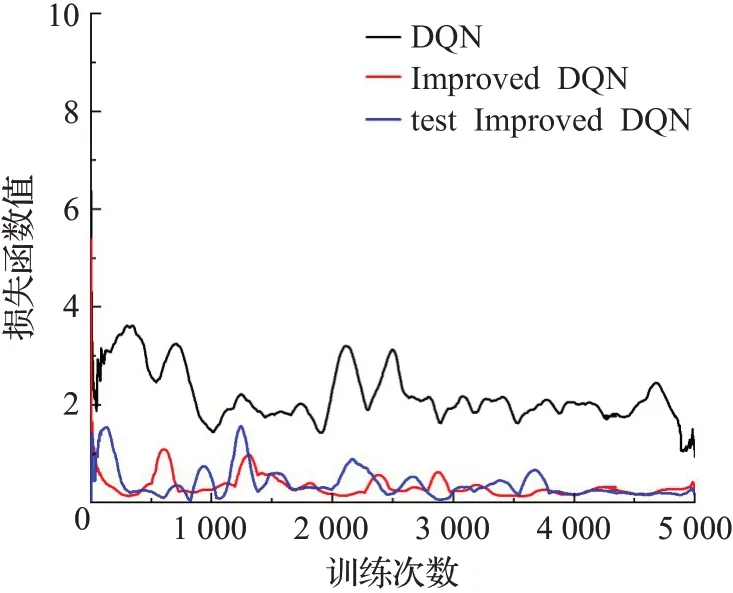
图8 损失函数值对比图Fig.8 Comparison chart of loss function value
3.3 对比分析简单环境下的路径长度
为了验证改进算法的有效性,在简单环境中对路径规划做了对比分析。如图9的(a)和(b)所示,简单环境下机器人运行得到的路径轨迹。图中,由机器人的起始点(白色S),机器人的目标点(黑色G)以及障碍物组成。表4列出了机器人在简单环境下利用每种算法运行15次取得的平均路径长度和规划的路径轨迹上避开障碍物的个数。改进DQN算法的路径长度比DQN缩短了21.4%。且避开障碍物个数比原来增加了一个。
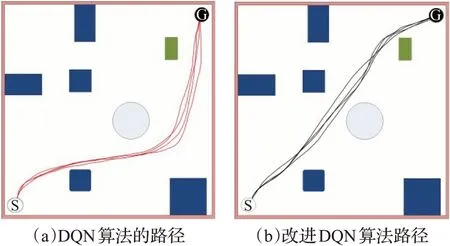
图9 简单环境下的路径轨迹长度比较Fig.9 Comparison of path length in simple environment

表4 简单环境下路径规划算法比较Table 4 Comparison of path planning algorithms in simple environment
通过对比分析图9的(a)和(b),可以看出(b)规划的路径轨迹更短,且避开这条路径轨迹上的障碍物多。图(a)避开了3个障碍物,而图(b)能避开4个障碍物。因此,改进算法的机器人避障能力更强,机器人有更好的适应和学习能力,不仅提升了其探索能力,且可以得到更短的路径。
3.4 对比分析复杂环境下的路径长度
复杂环境下对路径规划做了两组对比实验,验证了改进算法的可行性。如图10的(a)和(b)所示,复杂环境下机器人运行得到的路径轨迹。在一个密闭的环境中,设定起始点和目标点以及相应的障碍物,机器人从起始点出发到达目标点结束,获得了一条较短的路径轨迹。通过调整机器人的速度设计改进的奖励函数,奖励函数主要用于判断机器人的动作好坏,机器人根据奖励函数和环境的交互得到奖励值来调节其动作选择策略。机器人会在训练一圈之后得到状态-动作对的Q值,动作被ε-greedy策略选择后状态会被固定,机器人则会根据记忆的状态-动作值运行。因此,当机器人探索出一条路径时,它会选择相似的轨迹行驶。表5列出了机器人在复杂环境下利用每种算法运行20次取得的平均路径长度和规划的路径轨迹上避开障碍物的个数。改进DQN算法的路径长度比DQN缩短了11.3%。且避开障碍物个数比原来增加了两个。
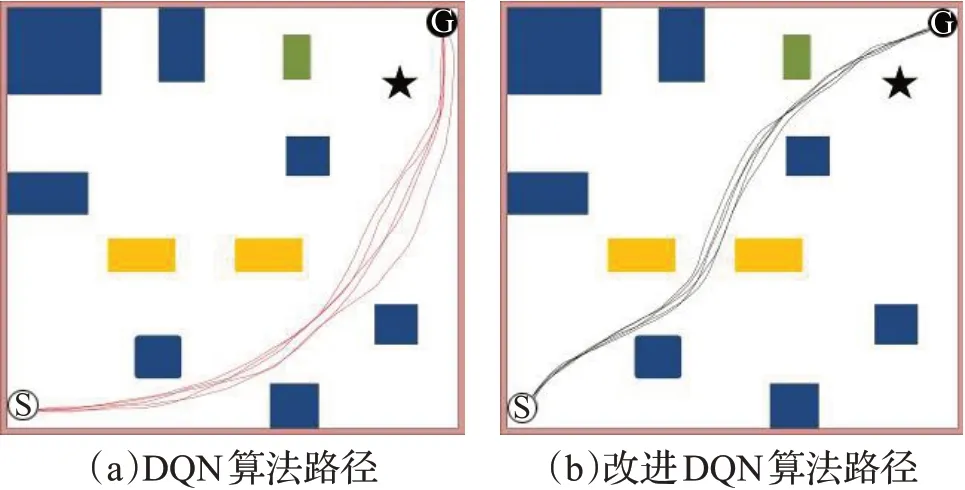
图10 复杂环境下的路径轨迹长度比较Fig.10 Comparison of path length in complex environment

表5 复杂环境下路径规划算法比较Table 5 Comparison of path planning algorithms in complex environment
通过比较分析图10的(a)和(b),DQN、改进DQN算法都规划出了一条无碰撞的路径,可以看出图(b)规划的路径轨迹上避开障碍物较多,图(a)避开了4个障碍物,而图(b)能避开6个障碍物。图(b)规划的路径类似一条两点之间距离最短的轨迹。由此得出,改进DQN算法的运行轨迹更短,避障能力更强,通过对比说明了改进DQN算法能够规划出一条更优更短的路线。
如图11的(a)和(b)所示,调整了机器人的起始点和目标点,机器人在该复杂环境下,利用DQN算法和改进算法运行得到了不同的路径轨迹,改进算法的路径明显比DQN算法运行得到的路径短。进一步验证了改进算法的可行性。
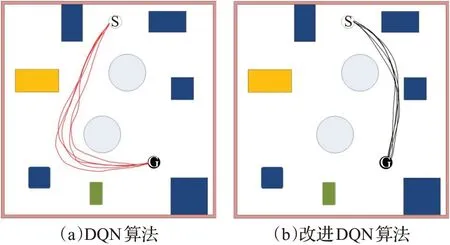
图11 复杂环境下运行路径的情况比较Fig.11 Comparison of running paths in complex environment
4 结束语
针对移动机器人在室内未知环境下路径规划时探索能力差的问题,提出了基于深度图像信息的深度强化学习的改进算法。利用Kinect视觉传感器获取障碍物的深度图像信息,再把信息直接输入到网络中,提高了网络训练的收敛速度。设置奖惩函数提高了机器人的奖励值,优化了状态-动作空间解决了环境状态空间奖励稀疏的问题,使机器人的动作选择更精准。仿真和实验结果表明,通过对比实验分析了DQN算法和改进DQN算法的平均奖励值和损失函数值,并利用测试阶段进一步验证了改进算法的有效实施性。改进算法不仅提高了机器人的探索能力,加强了避障能力,且规划出的路径长度更短,验证了其在路径规划上的可行性。
