大规模知识图谱的多查询优化问题研究
2021-11-12郭欣彤
郭欣彤, 高 宏
(哈尔滨工业大学 计算机科学与技术学院,哈尔滨 150001)
0 引 言
知识图谱将客观世界中的海量信息以结构化的形式描述,提供了强大的组织、管理和理解互联网海量信息的能力。知识图谱不仅给搜索引擎带来了新的活力,同时也在智能决策中显示出强大威力,是人工智能的重要基石。随着知识图谱被广泛应用于各个领域,在真实SPARQL查询历史中发现很多相似查询。如果一定时间段内的相似查询可以一起处理,就能减少冗余计算,从而大大降低查询响应时间,提高吞吐量。因此,本文研究在知识图谱上的多查询优化问题。
关系数据库上的多查询优化问题是NP-hard,由于SQL与SPARQL二者之间有等价关系,因此RDF/SPARQL上的多查询优化问题也是NP-hard。MQO是关系数据和半结构化数据上的一个经典问题,有很多方法取得了很好的效果。一个很直观的想法是把已有方法推广到RDF数据上,但现有的方法并不能无缝的集成在已有的RDF查询引擎上,主要原因有:
(1)关系数据上的SQL查询通常可以转换成一棵抽象语法树,在树上检测同构的子树较为简单,而SPARQL查询通常表示成图结构,因此公共子结构检测更难;
(2)RDF的物理存储和索引并没有固定的模式,每个系统选用的方法都不同,例如 RDF-3X中使用全索引结构[1],Jena使用属性表[2],还有最近很多系统采用的垂直划分方法,这些多样的存储模式和索引选择,使得代价估算不准确,某些情形下优化后的响应时间并不总是小于未优化的;
(3)真实世界中的 SPARQL查询远比关系数据库上的SQL语句复杂,连接更多,这可以通过比较 TPC 测试集和一些RDF测试集得出结论。随着连接个数的增加,代价估计的准确性大幅下降。在查询处理时,代价估计是非常重要的,错误的代价估计有时反而会使查询效率下降[3]。
从图的角度也有很多针对多查询优化的解法,大多数都需要找出最大公共子图(Maximum Common Subgraph, MCS)。由于MCS检索是NP-complete 问题,很多查询同时到达时,时间开销难以承受。
除了多查询优化问题本身的复杂度,随着知识图谱数据集规模的不断增大,RDF查询引擎的可扩展性变得尤为重要,需要一个分布式的RDF查询引擎提高查询处理时的并行性,从而减少响应时间,此时数据划分变得尤为重要。众所周知,图划分问题是NP-complete的,现有系统大多都基于启发式方法,一些系统使用简单的哈希方法,但这种方法导致很少查询能够无通信的并行计算;一些系统使用了较为复杂的划分算法,这类方法局限于很高的预处理代价和较高的复制系数。
为了解决现有方法不足,本文提出了一个新的分布式,基于内存的RDF查询引擎Leon,能够解决多查询优化问题。Leon使用一个基于特征集合的平衡划分算法,具有时间复杂度低,有利于星型查询等特点。对之后的多查询优化也有很多好处,本文提出了一个新颖的多查询优化算法。首先,利用特征集合快速过滤没有优化前景的查询;其次,利用 triplet 进一步过滤,只保留十分相似的查询;最后,在剩下来的查询中精确、高效地查找公共子结构。实验结果表明,在多查询负载下,时间是无优化时的1/10。
1 算法框架
1.1 特征集合
RDF图中的主体都有一系列谓词,同一实体类型的主体拥有的谓词也十分相似。真实世界中的RDF数据集即使包含的三元组个数很多,谓词集合也很少。例 如,对于一个拥有超过8亿三元组的UniProt数据集来说,谓词集合只有 615个;DBLP数据集包含176.63M条元组,谓词集合只有95个。许多其它数据集也观察到这种现象,例如:YAGO、LibraryThings、Barton等。Neumann和Moerkott由此提出了特征集合的概念[4]。
给定一个RDF数据图G(V,E,L),s是一个主体,s的特征集合S(s)定义为式(1):
S(s)={p|∃o:
(1)
图G中所有特征集合可以表示为式(2):
S(G)={S(s)|∃p,o:
(2)
基于以上两个定义,定义特征集合块,特征集合为Si的主体对应的所有三元组,形成了一个特征集合块Bi,式(3):
Bi={
(3)
图中所有特征集合块可以表示为式(4):
B(G)={Bi|Si∈S(G)}
(4)
显然,B(G)是RDF数据图以主体为中心的一个划分,特征集合Si和特征集合块Bi之间是一一对应的。
将RDF图中的三元组根据特征集合编码,使用基于特征集合的平衡划分算法将特征集合块发送到从节点中。为了使各个节点上的工作量较为平均,保持每台机器上的三元组个数接近。假设划分计划表示为P={P1,P2,…,Pk}。将|E|条三元组平均分配到k个节点上,那么每台机器上的数量应为|E|/k个。根据每个特征集合块内三元组数量从大到小排序,将排序后的特征集合块贪心地放入剩余容量最多的节点。
1.2 公共子结构检测
多查询优化算法的核心是公共子结构检测,主要分为3个步骤:
(1)将SPARQL查询根据特征集合进行分解,根据包含的特征集合,将查询划分成几个粗粒度的聚类;
(2)使用triplet进一步精细聚类,只保留非常相似的查询进行优化;
(3)找出查询间准确的公共子结构。
到达的SPARQL查询会被分解成一系列不相交的星型的子查询,称为fork。fork中的三元组模式有相同的主体连接变量,根据谓词每个fork都能映射到0个或多个特征集合,相应的特征集合块一定含有这个fork的结果。
要筛选出哪些查询可以一起优化,因此使用k-means聚类算法粗粒度地对查询集合聚类。k-means聚类算法使用基于特征集合的Jaccard系数作为度量,使用特征集合对查询粗聚类是高效且准确的,特征集合中不仅包含了查询的谓词信息,也反映了结构信息。如果两个查询包含的特征集合都相同,那么其有很大可能结构也相似,相比已有方法只使用谓词进行聚类更加准确。
粗聚类后,在每个簇上进一步筛选可以共同优化的查询。将每个查询q分解成一系列triplet,所谓triplet就是相连的两条边组成的三元组。表1就是图1的triplet分解结果。
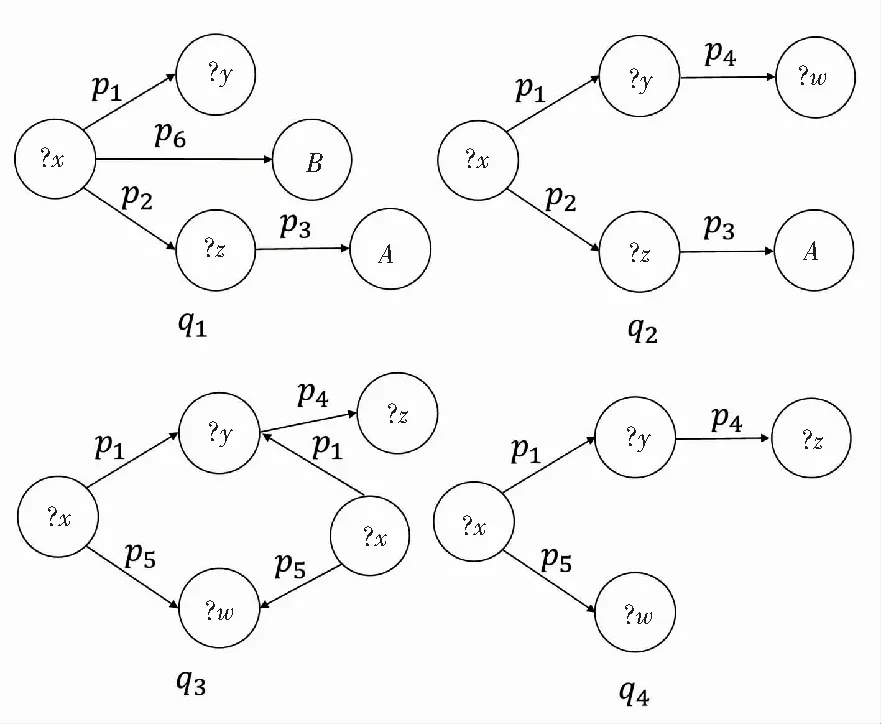
图1 一组查询
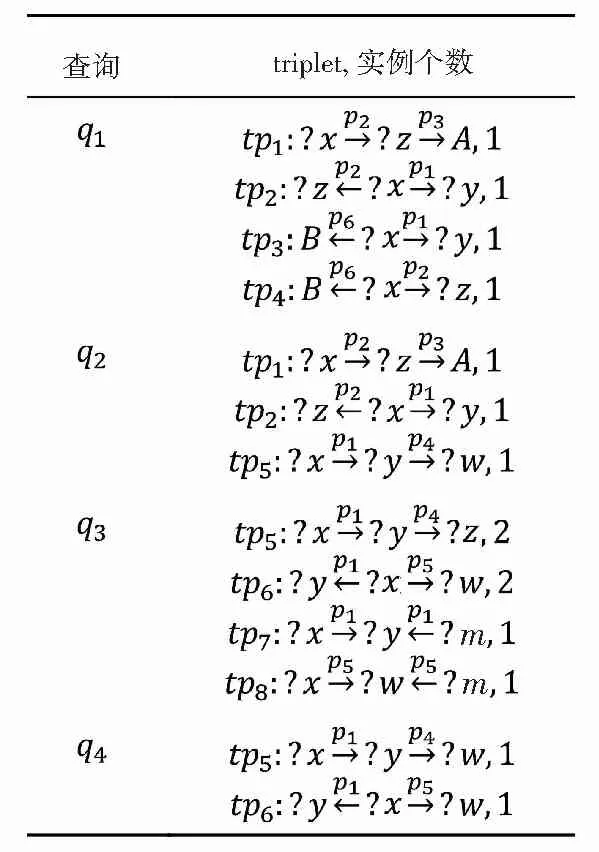
表1 Triplets
如果两个查询有很多公共的 triplet,那么其很可能有很大的公共子结构,计算两两查询的亲密度,式(5):
(5)
亲密度越高,说明两个查询公共子结构越大。只有当两个查询之间的亲密度高于一个阈值β时,才会被考虑一起优化。将不相似查询过滤出去后,在剩下的查询上运行最大公共子结构发现算法,找到的公共子结构如图2所示。
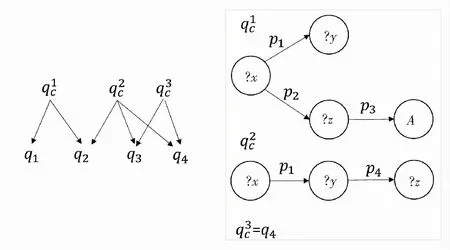
图2 查询的公共子结构
1.3 查询重写
给定一组查询Q={q1,q2,…,qn},假设qc是其公共子结构,将每个查询改写如式(6)和式(7):
(6)
(7)
为QOPT生成查询计划,进行查询处理。
2 实验结果
使用两个数据集进行实验。LUBM是一个广为人知的 RDF测试基准,其优点是数据集中的度量值随着数据集大小线性增长,结构简单的数据集,只含有11个特征集合,本文使用 LUBM 数据生成器生成LUBM1k 数据集;WatDiv也是一个人工数据集,其可以测试不同查询负载情况下RDF 系统的性能,本文生成了一个超过10亿条三元组的WatDiv1B数据集。将Leon与目前最先进的AdPart[5]系统进行对比,AdPart使用主体上哈希的划分算法,并能根据负载进行数据复制。
为LUBM1k和WatDiv1B数据集分别生成包含10k个查询的查询负载,比较4个算法AdPart-random、AdPart-seq、Leon和Leon-non(无优化),其中“AdPart-seq”表明相似的查询同时到达,“AdPart-random”代表相似查询随机到达,做这样的区分是因为AdPart是通过一段时间内重复出现的查询进行复制的。
图3给出了LUBM1k负载上的查询表现,横轴代表查询个数,纵轴代表累积处理时间。对于AdPart-random,由于相似查询随机到达,并没有检测到很多公共子结构,因此累积处理时间迅速增长;而AdPart-seq识别到了连续到来的相似查询,并将公共子查询的结果在集群中复制,因此时间远远小于AdPart-random。相比之下,Leon将所有查询看成一个整体,对不同的查询聚簇分别优化,运行时间比AdPart-seq减少了大约40%,这是因为最大程度的共享了公共部分的计算,而且选择了正确的公共子结构进行重写;Leon-non比AdPart-random花费时间少大约32%,这是因为基于特征集合的划分方法减少了查询处理时间。Leon的运行时间大约是Leon-non的1/10,说明引入多查询优化可以大大提高查询响应时间。
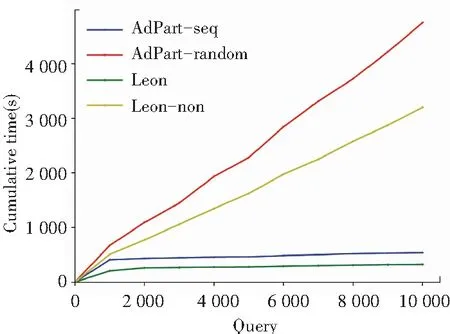
图3 LUBM负载表现
图4表明在WatDiv负载上各个系统的查询表现也有相同的变化趋势。由于WatDiv的查询模板更复杂,因此特征集合的剪枝能力发挥了巨大的作用。此外,基于特征集合的基数估计更准确,使得生成的查询计划更优。Leon比AdPart-seq节约了 25% 的时间,Leon比Leon-non节约了91%的时间。
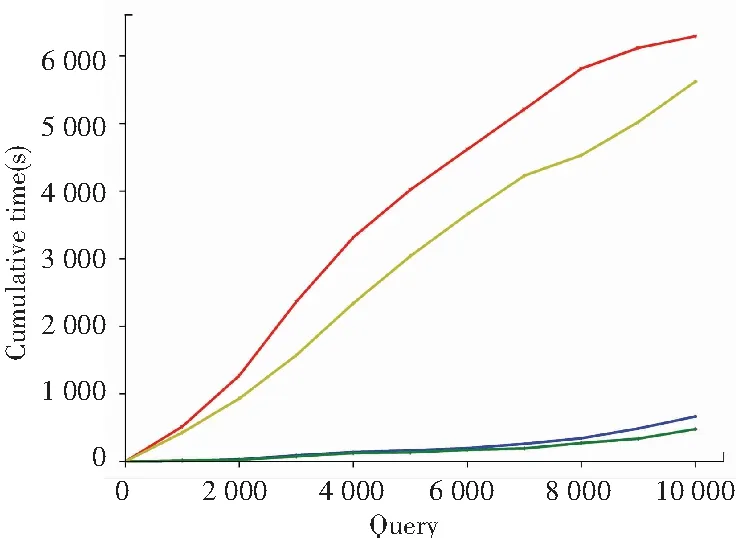
图4 WatDiv1B负载表现
3 结束语
本文探讨大规模知识图谱上的多查询优化问题,提出了一个基于内存的,分布式RDF处理引擎Leon。Leon基于特征集合对RDF数据进行划分,大大减少了连接个数,从而减少了计算时间。同时本文也提出了一个高效的提取公共子结构的算法,利用特征集合和triplet两次筛选,逐渐缩小搜索空间。实验证明,Leon 在单查询性能上与目前最好的RDF查询引擎相当;在多查询优化上,响应时间是无优化的版本的1/10。
