基于深度学习的X光图像智能审像系统
2021-11-10张积存费继友宋雪萍冯佳伟
张积存 费继友 宋雪萍 冯佳伟


关键词:深度学习;X光图像;目标检测;Mask R-CNN;违禁品检测
快递物流业、机场海关等行业货物,包裹的安全性检测目前主要使用X光机人工检测的方式,由于待检测物品种类繁多,摆放位置可能出现遮挡,因此对检测人员能力要求较高,且存在误检和漏检的情况。快递物流业的货物一般分散存放,导致审像人员分散,每人只能对一台机器的X光图像进行审核;海关的X光检测机器各自独立,图像数据格式不统一,导致管理困难。将X光机产生的图像进行集中管理和审核成为这些行业较强的需求。
当前人工智能技术快速发展,基于深度学习的图像识别在计算机领域越来越成熟,由于它适应性强、具有自我学习和概括、抗噪声能力强、编程易实现等优点,目前已经应用到很多业务场景并取得了较好的效果。相比之下,对X光图像的识别存在更多的困难:包裹内的物品存在着种类多、背景复杂、物品相互遮挡等问题。随着深度学习技术的不断发展,对X光图像进行识别在医学领域已经有所应用,同时,针对X光图像违禁品检测的相关研究也取得了不错的进展,因此,利用深度学习技术代替人工识别的方式,实现X光图像智能识别、自动预警成为可能。
1智能审像系统
X光图片智能审像系统是集X光图像采集、数据汇聚、分析处理、违禁物品自动检测、数据存储为一体的非侵入式解决方案。可对多种类违禁物品如走私品、易爆物品、危险品等进行快速检查,智能识别、并能根据人工干预的结果进行机器学习,不断的提高物品检测的准确率,最终达到减少人工参与、提升效率的目的。
1.1审像系统架构
审像系统的总体逻辑处理结构如图1所示,X光机检测设备完成货物、快件、行邮物品等扫描检测,生成X光灰度图片,并将图片上传给自动审像系统,审像系统使用机器学习神经网络算法等方式,对待检物品的图像进行自动审像。监控指挥中心可以实时监控各设备的审像情况,对检出的危险品及违禁品进行处置。
如图2所示,系统共分为应用层,服务层,大数据层,数据接人层以及后台管理五部分。
其中数据接人层负责X光图片数据的对接,包括对数据进行采集、汇聚、传输、清洗,并将处理后的数据存储到数据资源层。
数据接人和传输使用FTP的方式,数据接人层实时监测FTP上传的XMI.文件,对接收到的文件解析清洗,然后将元数据和图片存储到大数据中心。
大数据层负责存儲原始数据和识别后的结构化数据,以及模型和样本数据。
服务层提供智能审像服务,包括审像算法,标注样本,训练模型及全文检索服务。
应用层负责检测结果展现和用户交互,包括审像结果、监控告警、综合查询、统计分析等。
管理层是运维人员的后台管理系统,包括角色管理,用户管理,机构管理,日志管理,站点管理,光机管理及模型管理等。
1.2审像系统特性
X光审像系统在深入分析X光图像成像特点基础上,设计并开发的基于深度学习的智能审像系统,系统的核心特性如下:
(l)实时采集、汇聚和存储X光图像信息,实现集中审像,解决了X光机分散部署,审像人员能力要求高,工作效率低的问题。
(2)采用领先的深度学习神经网络技术进行违禁物品的识别与检测,无需人工挑选特征,有效地解决了检测过程中遇到的目标图片姿态多样、背景复杂、物品种类繁多造成的漏检问题,达到了平均精确率高于83%的效果,使安检作业方式实现了质的飞跃。
如图3所示,业务现场采集的X光图片,经过深度学习算法进行审像后,可以较为准确的找出图片中的违禁品。自动审像系统对于采集的X光图像自动进行识别并标识出是违禁品的概率。
2智能审像算法
2.1目标检测算法
现有的目标检测算法总体分为两类,一类是OneStage算法,比如:YOLO和SSD算法,另一类是TwoStage算法,比如R-CNN系算法。其中OneStage算法训练快但识别精度相对低,TwoStage系算法训练相对慢但识别精度高。在使用主流配置GPU的情况下,无论OneStage还是TwoStage算法,其识别速度都能达到每张图片耗时几十到上百毫秒,均可以满足X光机智能审像的性能要求。而X光图像审像应用场景对物品的识别精度要求较高,因此R-CNN系算法更适合此场景。
R-CNN系算法的发展历程如图4所示,由RCNN、Fast R-CNN、Faster R-CNN发展到现阶段最先进的Mask R-CNN算法。MaskR-CNN算法流程如下:特征提取网络从原始图像提取出特征,经过区域建议网络生成候选区域,再由ROI Align转换为统一尺寸的特征供功能性网络训练。
2.1.1特征提取网络
Mask R-CNN使用的是利用特征金字塔结构将残差网络组合成的特征提取网络,分为自上而下和自下而上两个部分;
其中自下而上的部分使用了ResNet网络,通过C1 -C15模块生成了五个不同粗粒度的特征图。其中,每个模块由多个残差学习结构组成,例如C3的结构为{1×1,128;3×3,128;1×l,512}×4。这表示C中包含4个残差学习结构,每个残差学习结构由三个卷积层组成,其卷积核分别为1×1,3×3,1×1,通道数分别为128,128,512。在自下而上的路径中,每一个阶段的第一个卷积核的步长为2,其他卷积核的步长为1,这样使得到的特征图的尺寸随着模块减半,得到不同尺寸的特征决射。
另一方面,自上而下的路径则是将高层特征进,亍2倍采样,然后通过1×1的卷积与自下而上的珞径得到的特征融合,最后通过3×3的卷积得到新的特征映射图P2~P5。如图5所示,当输入尺寸为1024×1024的图像时,最终生成的特征映射尺寸为{32×32,64×64,128×128,256×256}。
2.1.2区域建议网络
区域建议网络(Region Proposal Network,RPN)是一种利用特征图计算代表物体在图像中位置的全卷积神经网络,可以接受不同尺寸的图像作为输入。不同于传统的选择性搜索( SelectiveSearch),RPN网络的输人为特征提取网络所得到的特征圖。
通过滑动窗口在特征图中滑动产生多尺度的锚(Anchor)。RPN会对特征图中的每一个特征向量回归,得到一个修正向量来对锚进行修正。修正值包括2个前后景信息(前后景置信度)和4个位置信息。其中位置信息的修正的方式如公式(1)所示:
对Anchor进行修正后可以得到大量的候选框,针对这些候选框计算其前后景得分,并通过非极大值抑制(Non-Maximum Suppression,NMS)的方法过滤出比较精确的候选框。
2.1.3ROI Align
在Faster R-CNN算法中,ROI Pooling可以将不同尺寸的输入图像转换为一个固定维度的特征向量输出,ROI Pooling采用最邻近插值法进行区域的伸缩,因此在池化的过程中如果遇到浮点数则会四舍五人,导致信息的丢失,进而影响检测的精度。Mask R-CNN算法为了避免信息的丢失,使用了ROI Align代替了ROI Pooling。
ROI Align在区域伸缩的过程中使用了双线性插值法,具体步骤为:遍历每个候选区域,保留浮点数的区域边界并将候选区域分割成k×k个单元,每个单元的边界也保留浮点数。最后使用双线性插值的方法计算出固定四个坐标位置的值,然后进行最大池化操作。ROI Align通过引入双线性插值进行池化,将原本的离散池化过程变为连续过程,从而解决了ROI Pooling中信息丢失的问题。
2.2基于Mask R-CNN算法的智能审像
2.2.1样本更新
为了保证审像模型的识别准确度,审像应用模块需要不断更新样本库,并重新训练审像模型。
样本库更新分为自动更新和手动更新两种方式。通过自动更新确保样本库能够源源不断的得到优质的新样本,同时在需要时也可以选择手动更新样本库。两种更新的流程:
(1)自动更新
当图像分析集群发现带有违禁品的图像时会主动推送给业务人员,业务人员可以对图像进行确认和校正,确保图像中标注信息准确。校正后的图像会自动存人样本库。
(2)手动更新
由业务人员通过Web服务集群主动添加样本,供模型训练使用。
从某品牌X光机选取了6000张含有违禁物品的图片作为样本,通过标注工具标注出刀、枪、液体瓶、手机、充电宝等五类违禁品在图片中的位置,形成训练样本,另外选择600张X光图片作为测试样本对系统的训练效果进行检验。
2.2.2数据预处理
原始X光图像中包含许多冗余的部分.如图6中上下部分的文字以及白色背景,但对算法训练与预测有作用的只有图中虚线标注出来的区域。
如果直接利用原始图像进行算法训练,一方面会引人多余的噪声造成算法的训练效果不佳,另一方面传人训练的图像尺寸过大会降低算法训练的速度。因此,在原始图像接人算法训练与图像分析模块之前需要对图像进行预处理。利用OPENCV中包含的轮廓检测算法可以有效的识别出原始图像中的货物部分,经过算法处理后的图像如图7所示。由于模型训练是在GPU上实现的,图像经过预处理后剔除了多余的部分,所占用的显存变得更小,每次可训练更多的图像,算法训练的效果和效率都可以得到提高。
3实验测试
实验硬件环境如表1所示,软件环境如表2所示。基于COCO数据集权重,针对X光图片样本数据调整参数得到预测模型。如图8所示,对比了各个ResNet的精度,最终选择ResNetl01作为PackBone训练网络,主要参数设置如表3所示。
对Mask R-CNN网络训练分三阶段:第一阶段是Head网络,训练40个epoch,每个epoch包含1000个batch,LR设置为0.001,LR衰减系数为0.001;第二阶段是”4+”网络微调,微调80个epoch,每个epoch包含1000个batch,LR设置为0. 001,LR衰减系数0.001;第三阶段是全网络微调,微调40个epoch,每个epoch包含1000个batch,LR设置为0.0001,LR衰减系数为0.0001,三个阶段训练后I-OSS值收敛于0.4左右。对Mask R-CNN训练后的模型在测试集上使用COCO的评估方法,平均精准率mAP50达到了0.83。
使用训练后的模型进行智能审像,模型基本能准确的检测出图像中包含的违禁品。针对多种目标物体,以枪为例,Mask R-CNN算法的识别结果如图9所示。横轴为召回率,纵轴为精准率,三条曲线分别代表不同IoU阈值下的检测效果。曲线下方的面积即为AP值。可以看出,曲线包围的面积很大,枪检测效果较好。
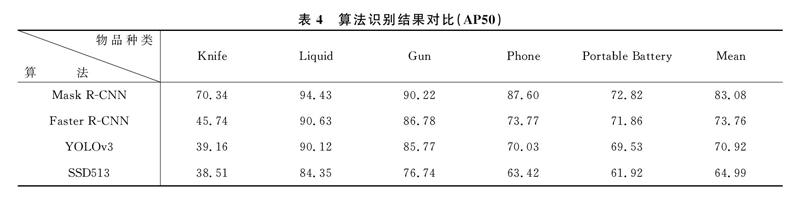
将Mask R-CNN算法的检测效果与Faster RCNN、YOLOv3、SSD513三种算法进行对比,以AP50为评判标准,结果如表4所示。
可以看出,Mask R-CNN算法的识别精度要明显优于Faster R-CNN及以One Stage的YOLOv3和SSD513算法。Mask R-CNN算法比Faster R-CNN识别精度高12.6%;比YOLOv3识别精度高17. 1%,比SSD513识别精度高27. 80/。从物品种类来看,液体瓶、手机、枪的检测效果要好于刀与充电宝,其原因在于这两类物品特征简单,容易和其他物品混淆。
4结论
(1)针对X光机部署分散、人工审像方式效率低、精度差等问题,构建了一套集前端数据采集、传输、汇聚,后端算法检测、告警为一体的X光图片智能审像系统。
(2)系统采用目标检测精度较高的Mask RCNN算法,对X光图像进行了预处理,对比了各个ResNet的精度,选择ResNet101作为BackBone训练网络,进行参数调整,训练出的模型平均精准率mAP50达到了0.83,违禁品检出的准确率明显高于Faster R-CNN、YOLOv3、SSD513等算法。该系统在某寄递物流业务场景下已实际应用,效果较好。
(3)对于刀、充电宝等特征简单、易于混淆的目标物体,检测精度还有一定的改善空间,后续进行神经网络算法的优化,进一步提升易于混淆物体目标检测的精度。
