带有缓存约束的作业车间调度求解方法
2021-11-10陈浩杰宋小欣
罗 焕,陈浩杰,宋小欣,张 剑
(西南交通大学 机械工程学院,四川 成都 610031)
0 引言
作业车间调度问题是最常见的调度问题之一,长期以来众多学者在该领域进行了深入广泛的研究[1-3]。目前的研究在构建调度模型时,一般将机器缓存容量设为无限大,忽略缓存容量对作业调度的影响[4],导致实际生产过程中对许多作业车间数学模型不适用。机器间的缓存可以容纳加工设备单元后的产品零件或在相邻的工艺步骤中供应给下一个设备单元[5],因此生产中缓存对于缓解生产线的突然变化至关重要。在追求“零库存”甚至“零缓存”从而减少在制品的精益生产中,缓存容量极其有限,显然考虑缓存约束下的作业车间调度数学模型和求解方法是解决这些实际生产问题的有利手段。
带有缓存约束的作业调度问题可分为阻塞约束下的作业车间调度问题(Blocking Job Shop Scheduling, BJSS)和有限缓存约束下的作业车间调度问题(Limited-Buffer Job Shop Scheduling, LBJSS)。在前一问题的研究中,ZENG等[6]提出一个整数非线性数学规划模型来描述带有输出缓存的作业车间调度问题,并提出了求解问题的可行解和局部搜索两阶段算法;PRANZO等[7]对阻塞作业调度问题的两个扩展问题——允许交换的阻塞作业车间调度和不允许交换的阻塞作业车间调度进行研究,并提出迭代贪婪算法对问题进行求解;LOUAQAD等[8]研究了无等待阻塞运输作业车间调度问题,并建立了混合整数线性规划模型,提出了一种基于优先级规则的构造性启发式算法对问题进行求解。在有关有限缓存约束下的作业车间调度研究中,BRUCKER等[9]将LBJSS分为与机器相关的输出缓存、与机器有关的输入缓存、与工件相关的缓存3类问题,并给出带有缓存区的作业调度问题解的一个紧凑表示;WITT等[10]设计了3种启发式算法来保证找到高质量的LBJSS解,并验证了所提出的方法有效性;LIU等[11]研究了更为普遍的带有4种缓存约束(无等待、无缓存、有限缓存、无限缓存)的作业车间调度问题,对关键问题性质进行了深入的分析,建立一个适用的混合整数模型,并提出一种高效的启发式算法对问题进行求解;曾程宽等[12]针对缓存区间有限条件下的作业车间调度问题,以最小化完工时间为目标建立非线性混合整数模型,并提出基于邻域搜索的两阶段算法对问题进行求解。
可见,目前已有的研究对带有缓存约束的作业车间调度问题特征进行了分析,但是在求解方法方面研究甚少,且解决思路集中在粗粒度的工件层级,由于问题复杂性超越传统作业车间调度问题,基本上都采用启发式算法对问题求解。本文针对该问题,将解决方案从工件层级扩展到工序层级,首次提出元启发式算法对问题进行求解,即采用遗传算法进行求解,并设计工序调整方式以获得合法解,结合自适应交叉变异概率和良种交叉算子对算法进行改进,以避免遗传算法过早收敛和陷入局部最优的问题。最后通过实验验证算法的有效性以及求解结果的优越性。
1 带有缓存约束的作业车间调度模型
1.1 问题描述
带有缓存约束的作业车间调度问题可以描述为:有n个独立的、无抢占式的作业必须在m台机器上加工,考虑缓存容量对作业进行机器最优分配和排序,通常优化目标是最小化完工时间。每道工序都必须在给定的工艺路线上加工,但是不同的作业对应的工艺路线不一样。在一台机器上只能处理工件的一道工序,且每台机器一次只能处理一道工序,工件某道工序一旦在设备上开始加工直至加工完成不能被中断,每台机器都有指定的缓存容量。与加工时间、阻塞时间或存储时间相比,机器之间的工件转移时间可以忽略不计,因此在本研究中不考虑工件转移时间。当工件在非最后一道的某道工序机器上加工完成后,如果其下一道工序对应加工机器空闲,则可以进入下一台机器进行加工;若下一台机器处于繁忙状态时,则判断当前机器对应的缓存是否可用,可用则将工件移入当前机器对应的缓存(该缓存为机器对应的输出缓存),否则当前机器缓存被占满的情况下,工件停留在机器上并对机器造成阻塞,阻碍后续工件在此机器上的加工。
1.2 符号和变量
数学模型中相关符号和变量说明:
(1)符号
n为工件数量;
m为机器数量;
j为工件索引,j=1,2,…,n;
J为工件集合;
Jj为工件j,Jj∈J;
k为机器索引,k=1,2,…,m;
M为机器集合;
Mk为机器k,Mk∈M;
pj为工件j的工序数;
i为工件j在指定加工路线上的工序索引,i=1,2,…,pj;
Oij为工件j的第i道工序;
Pijk为工件j的第i道工序在机器Mk上的加工时间;
lk为机器Mk对应的缓存容量。
(2)变量
Sijk为工件j的第i道工序在机器Mk上的开始加工时间;
Cijk为工件j的第i道工序在机器Mk上的加工完成时间,Cijk=Sijk+Pijk;
Bijk为工件j的第i道工序加工完成后在机器Mk上的阻塞时间;
Dijk为工件j的第i道工序加工完成后离开机器Mk的时间,Dijk=Cijk+Bijk;
STijk为工件j的第i道工序加工完成后在机器缓存中的存放时间;
Lijk为工件j的第i道工序离开机器缓存的时间,Lijk=STijk+Dijk;
1.3 数学模型
(1)
式中Cj为工件j的完工时间。
约束条件:
Pijk>0,i=1,2,…,pj;
j=1,2,…,n;k=1,2,…,m;
(2)
i=1,2,…,pj;j=1,2,…,n;
(3)
i=1,2,…,pj;j=1,2,…,n;
(4)
i=1,2,…,pj;k=1,2,…,m;
(5)
i=1,2,…,pj-1;j=1,2,…,n;
(6)
j=1,2,…,n;
(7)
Cj=max(Cijk),i=1,2,…,pj。
(8)
其中:式(2)为工件的每道工序加工时间非负约束;式(3)为不同工件的工序之间无优先级关系,同一工件要满足工序间的工艺关系;式(4)为工件同一时刻只能在一台机器上加工;式(5)为一台机器在同一时刻只能加工一个工件;式(6)为有限缓存约束,不包括每个作业的工艺路线中的最后一道工序,工件最后一道工序加工完成则视为离开生产系统不再占用资源,该情况下,Oij完成之后在缓存区bk中的离开时间必须等于其同一作业后一道工序Oi+1,j的开始时间;式(7)为阻塞约束,缓存不足的情况下会造成机器阻塞,不包括每个作业的工艺路线中的最后一道工序,该情况下,Oij完成之后Mk可能由于对应的缓存被占满而被阻塞;式(8)为一个工件的完工时间等于该工件所有工序的完工时间最大值,即工件最后一道工序的完工时间。
2 改进遗传算法
启发式算法在可接受的计算时间内能够找到最好的解,但不一定能保证所得解的可行性及最优性,甚至大多数情况下无法阐述所得解与最优解之间的近似程度。采用启发式算法求解带有缓存约束的作业车间调度问题是以工件层级为编码,按照每个工件的总加工时间大小进行的排序,再基于这个排序进行局部搜索操作,这种基于工件层级的编码进行的局部搜索很可能导致局部最优,从而降低调度结果的精度。而元启发式算法是启发式算法的改进,它是随机算法与局部搜索算法相结合的产物。采用元启发式算法求解带有缓存约束的作业车间调度问题,将问题编码从工件层级扩展到工序层级,基于工序排序进行搜索操作,随机产生工序排序以扩大算法对问题的全局搜索范围,避免局部最优。在求解作业车间调度问题的元启发式算法中,遗传算法是运用最广泛的算法之一,对求解复杂多项式问题有较强的适用性,且一般能取得较优的结果。
本文首先采用传统的作业车间调度基于工序的编码方式,将问题的解决方案从工件层级扩展到工序层级,为保证解的合法性,需要对缓存约束下的基因编码进行调整。遗传算法适用性强,但是也存在不足,如遗传算法在传统遗传算子的作用下,容易使一些优良基因片段发生丢失,从而造成算法过早收敛以及在进化后期搜索效率低等问题。本文设计了合理的工序调整方法进行解码,提出采用自适应交叉变异概率结合良种交叉算子对算法进行改进。这种自适应调节方法使算法在进化前期,有较强的全局搜索能力,算法的全局搜索性随着进化的进行慢慢减弱,而局部搜索能力慢慢增强,提高了算法效率和适用性。改进遗传算法流程如图1所示。
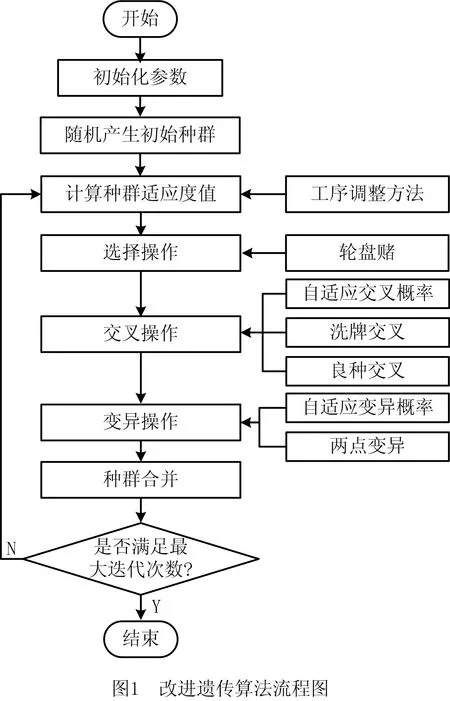
改进遗传算法步骤如下:
(1)初始化参数。设置种群大小PopSize,代沟OPT,交叉概率为Pc1、Pc2,变异概率为Pm1、Pm2,最大迭代次数为Gmax。
(2)初始化种群。采用实数编码随机产生工序排序生成初始种群Initial_Pop。
(3)计算种群适应度函数值。根据式(1)计算目标函数值再将目标函数值转化为适应度值。
(4)选择操作。根据适应度值和代沟OPT选择个体,采用轮盘赌方式进行选择。
(5)交叉操作。根据选择后的种群进行良种交叉与整数交叉相结合,根据个体适应度值和式(9)确定是否交叉。良种交叉是用种群的精英个体和选择后的适应度值较差的部分个体进行交叉操作[14]。选择操作后,除了进行良种交叉个体外的其余个体进行洗牌交叉。
(9)
式中:fmax表示种群中个体最大适应度值;favg表示种群平均适应度值;f′表示两个交叉个体中较大的适应度值;Pc1、Pc2表示最大、最小交叉概率。
(6)变异操作。根据个体适应度值和式(10)采用两点变异,随机交换两个不同工件的工序位置进行变异。
(10)
式中:Pm1、Pm2表示最大、最小变异概率;f表示变异个体适应度值。
(7)种群合并。采用精英保留策略,根据父代和子代个体适应度值保留前10%的精英个体,剩下的个体用遗传操作后的个体替换父代中的个体。
(8)判断是否满足最大迭代次数,满足则输出结果,不满足则返回步骤(2)。
2.1 个体编码

2.2 解码操作
传统作业车间调度的基于工序编码的解码方法只考虑工序约束和机器约束,没有考虑缓存约束,因此解码方式较简单且不会产生工序间的冲突。而带有缓存约束的作业车间调度的解码方法相对复杂,除了考虑工序间的约束和机器约束以外,还需要考虑机器缓存约束的影响以及工序之间的冲突。运用甘特图对比分析两种解码方式的不同,如图2所示。当前需要安排工件4的第二道工序402进行加工,按照传统作业车间调度解码方式得到工件4的第二道工序402在机器2上的加工甘特图。

在带有缓存约束下的作业车间调度解码方式下会出现以下几种情况:
(1)缓存容量充足时,如假设机器3的缓存容量为1,则在安排工件4的第二道工序402时需要考虑机器3的缓存是否够用,若够用,则得到如图3所示的结果。

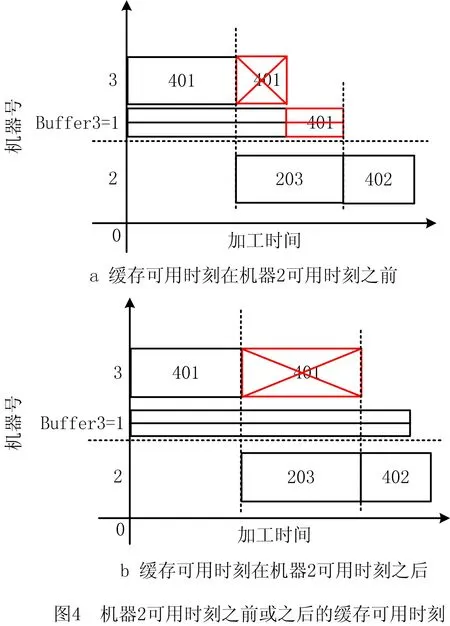
(2)缓存容量不足时,则会对机器形成阻塞,在这种条件下会发生不同的情况,如工件的工序401加工完成后先在机器3上存放一段时间直到机器缓存可用时刻,缓存可用时刻可能在机器2可用时刻之前或之后,如图4a和4b所示。
(3)除上述两种情况外还存在两个工序之间冲突的情况,如工序401完成时刻到工序402开始加工时刻缓存不足且阻塞时间段机器3上有其他已安排的工序在加工(如图5a),这时需要对401进行调整,调整后的结果如图5b所示。

解码和工序调整步骤如下:
步骤1根据工序排序进行解码,找到当前解码工序在机器上最早的开始加工时间。
步骤2若工序为工件的第一道工序,则返回第一步继续解码下一个工序,否则转步骤3。
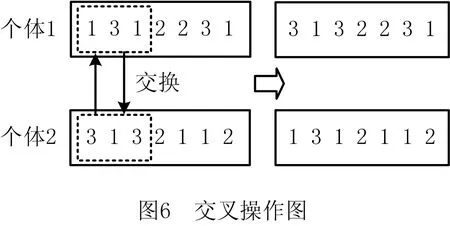
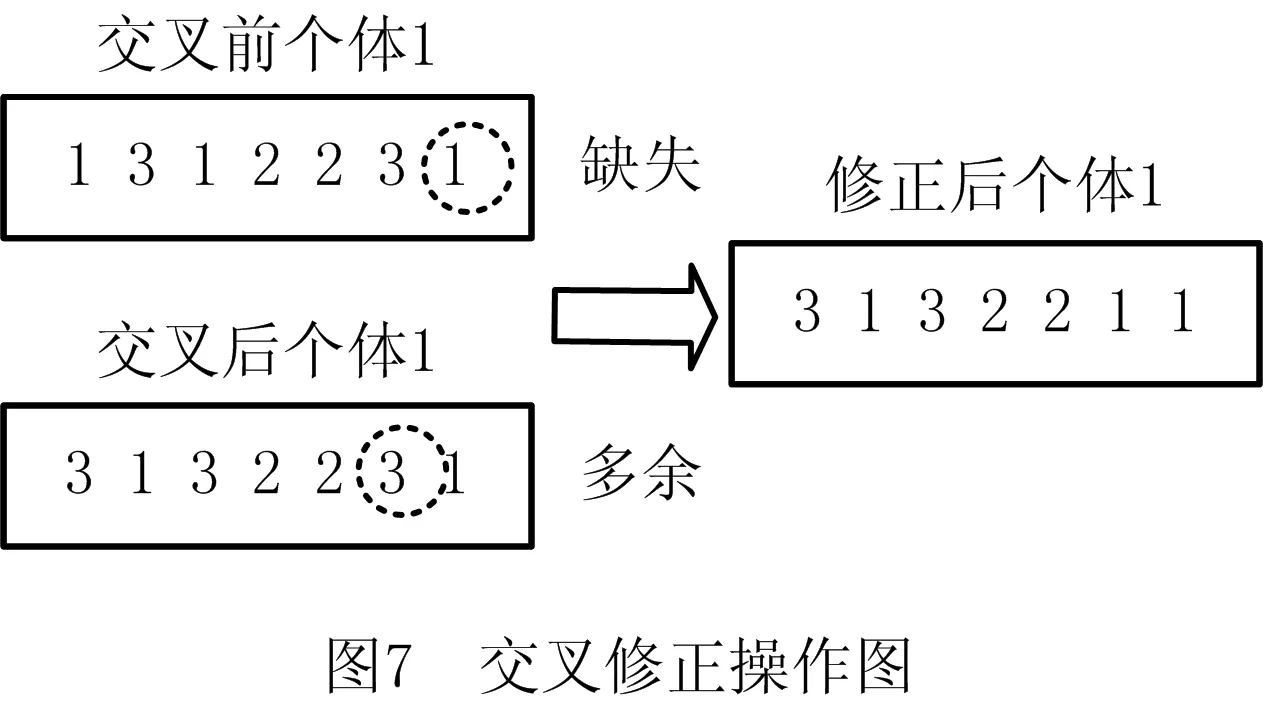
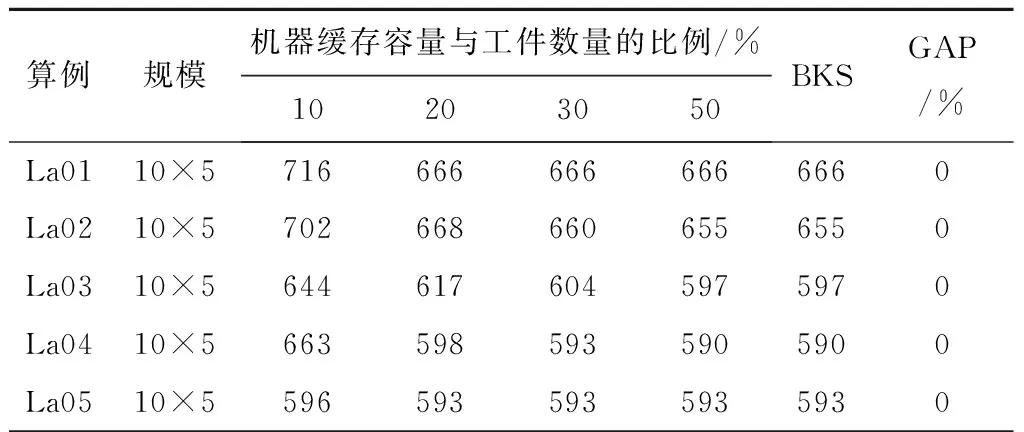
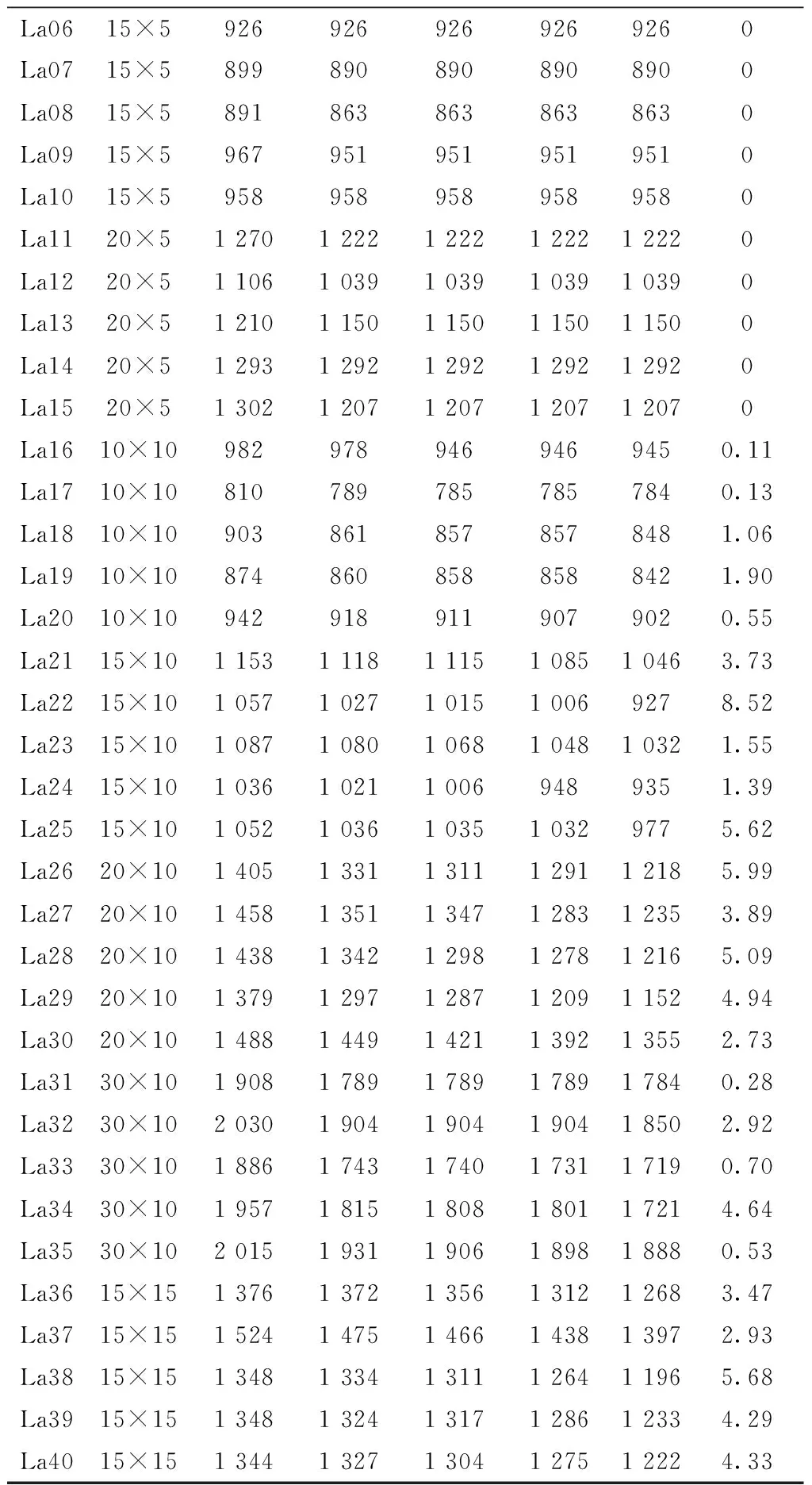
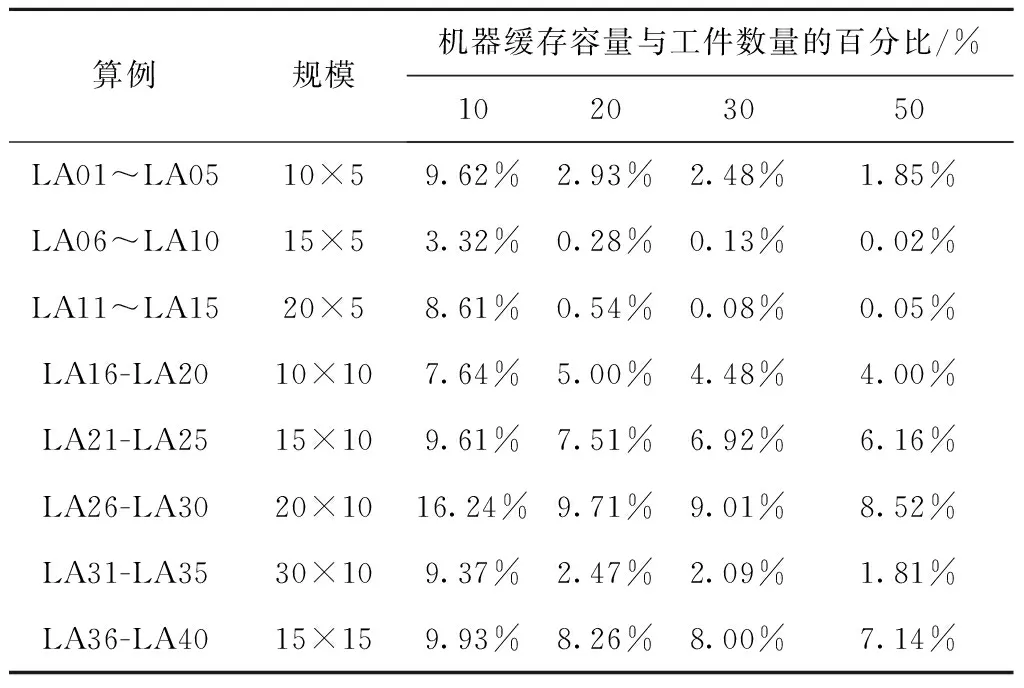
步骤3根据当前工序的开工时间Si+1,j,k与前一道工序的结束时间Cijk进行判断,若Si+1,j,k=Cijk,则转步骤4;若Si+1,j,k 步骤4更新机器加工时间、缓存时间、机器阻塞时间,判断当前工序是否为工件最后一道工序,若是,则转步骤6;否则,转步骤1。 步骤5判断时间段[Si+1,j,k,Cijk]前一道工序机器对应的输出缓存是否可用,若可用,则转步骤4;否则,转步骤7。 步骤6判断所有工件是否均已完工,若是,则结束;否则,转步骤1。 步骤7缓存不可用的情况下判断时间段[Si+1,j,k,Cijk]前一道工序对应的机器上是否已安排其他工件加工,若没有安排其他工序,则转步骤4;否则,转步骤8。 步骤8找到时间段[Si+1,j,k,Cijk]内缓存可用的时刻,判断从前一道工序完成到缓存可用时刻机器上有无其他已安排的工序且从缓存可用时刻到本工序开始时刻缓存都能满足,若阻塞时间段无其他已安排工序且缓存时间段缓存容量满足,则转步骤4;否则,转步骤9。 步骤9根据时间段[Si+1,j,k,Cijk]的冲突点对前一道工序进行调整,直到该工件已调度的所有工序之间没有冲突为止,转步骤4。 传统的交叉操作一般采用洗牌交叉,虽然保证了种群的多样性,但缺乏种群中的优秀个体对种群进化的指导作用,因此本文提出将洗牌交叉和良种交叉相结合的方法进行交叉操作,交叉操作均采用整数交叉法,首先选择两个需要进行交叉的个体,然后随机产生交叉位置进行交叉。交叉操作如图6所示,交叉位置为4。 交叉后某些工件会发生工序多余和缺失的情况,如个体1中工件1在交叉之后丢失了一道工序,工件3在交叉之后多出了一道工序,因此需要将工件多余工序变成工件丢失的工序,交叉修正操作如图7所示。 遗传算法中变异操作是对染色体产生较小的扰动以产生新的个体,从而增加种群多样性和算法的局部搜索能力。采用自适应变异概率可以避免算法在进化后期陷入局部最优。变异操作算子采用随机交换工序位置的方法进行,根据自适应变异概率选择需要进行变异的个体,然后采用两点变异方法随机选择两个变异位置,将变异位置对应的加工工序进行交换,如果随机产生的变异位置对应的工件相同则重新产生变异位置。变异操作图如8所示。 本文选用标准的作业车间benchmark算例测试算法的性能。标准算例La01~La20来自文献[15],参照文献[12]构建机器缓存容量与加工工件数的百分比,例如算例La01的规模为10×5,表示工件数量为10,机器数量为5,如果机器缓存容量与加工工件数的百分比为10%,则表示每台机器的缓存容量都为1。 (1)实验参数设置 改进遗传算法的初始种群规模大小、交叉变异概率、迭代次数均会影响算法的收敛性。本文通过将种群规模设置在50~200、迭代次数50~200进行多次实验比较,当种群规模PopSize=100、迭代次数Gmax=100时算法收敛性较好。自适应交叉变异参数参考文献[13],具体参数赋值如表1所示。 表1 改进遗传算法参数表 (2)实验结果分析 本文使用提出的改进遗传算法(Improved Genetic Algorithm, IGA)对构建算例进行求解,应用MATLAB R2014a软件编程实现问题模型算法。每个算例在同等机器缓存容量与工件数量百分比下运行10次,得到的最优解如表2所示。表2中,GAP的百分比为机器缓存容量与工件数量比例为50%时与现有无限缓存容量下的最优解之间的差值百分比。可以看出,对于经典JSP,本文提出的IGA即使在机器缓存容量与工件比例仅为10%的情况下也能达到无限缓存容量下的现有最优解(Best Known Solution, BKS)。例如La06和La10,机器缓存容量与工件数的比例达到20%时,算例La02、La03、La05~La15均能达到无限缓存容量下的现有最优解;而当机器缓存容量与工件数量比例达到50%时,La01~La15均可达到无限缓存容量下的现有最优解,复杂的大规模LA16~LA20算例虽然没有达到无限缓存下的最优解,但是与最优解之间的GAP值也很小,由此可以看出所提出的IGA对于求解该问题是有效的。从算例LA21~LA40可以看出,随着算例规模和算例自身复杂性的增加,机器缓存容量对算例求解结果影响将大大提高,即使机器缓存容量与工件数量比例达到50%时部分算例求解得到的最优解与无限缓存容量下的最优解之间的存在一定的差距。 表2 改进遗传算法求解不同缓存容量与工件数量百分比下的完工时间 续表2 为进一步分析算法的优越性,将IGA与其他算法进行对比。由于现有求解此问题的元启发式算法暂时没有,采用标准遗传算法(GA)和文献[12]的邻域两阶段算法(Neighborhood Two Stage Algorithm, NTSA)作为对比算法进行验证。分别将NTSA和GA求解最优结果与IGA最优值之间进行比较。现有研究针对此问题的求解算法较少,除上述两种对比算法外还采用了求解带有缓冲约束的流水车间调度问题的方法进行比较,选取文献[16-18]中的3种算法(免疫算法、混沌和声搜索算法、差分进化算法),计算在不同缓存容量百分比下的完工时间,并取3种算法中的最优结果与改进遗传算法求解的最优结果进行比较。由于对比算法NTSA仅对算例LA01~LA20进行计算,本文算法对比也选取LA01~LA20进行对比验证。结果对比如表3所示,表中I-F表示IGA的最优值与文献[16-18]中的3种算法的最优值之间的差值百分比,I-N表示IGA的最优值与NTSA最优值之间的差值百分比,I-G表示IGA的最优值与GA最优值之间的差值百分比。从表3中可以看出,IGA比其他算法在同等缓存容量百分比的情况下完工时间均能减少,在机器缓存容量与工件数量百分比为10%、20%、30%、50%的情况下,IGA比其他在带有缓存约束的流水作业车间调度问题的3种算法的最优值之间的平均差值百分比分别减小10.96%、7.55%、5.43%、4.83%,IGA比NTSA分别减小9.08%、0.69%、0.62%、0.46%,IGA比GA分别减小2.86%、0.47%、0.62%、0.46%。显然IGA比对比算法更加优越。 表3 改进遗传算法与其他算法在同等缓存容量百分比下的完工时间差值百分比 续表3 为验证IGA的稳定性,将每个算例在不同机器缓存容量与工件数量百分比下运行10次并取平均值,再计算平均值与无限缓存容量下的最优解之间的差值百分比,最后将同种算例规模下的差值百分比取其平均值,结果如表4所示。从表4中可以看出,当机器缓存容量与工件数量的百分比增加时,调度结果与无限缓存容量下的调度结果之间的差值会越来越来小,特别是在机器缓存容量与工件数量的百分比达到20%后,偏差迅速减小。 表4 偏差对比 本文针对带有缓存约束的作业车间调度方法进行研究,将解决方案从工件层级扩展到工序层级,并提出了改进遗传算法对问题进行求解;通过算例验证了算法能在不同的机器缓存容量与工件数量百分比的情况下进行求解,通过对比已有求解算法在同等机器缓存容量与工件数量百分比下的求解结果,证明了所提改进遗传算法能求得精度更高的解,由此验证了算法的有效性和优越性。后续研究将考虑更符合实际生产的问题,构建更精确的数学模型进行求解。如考虑设备最大负载、设备阻塞时间最小、缓存利用率最高等多个目标,以及多台设备共用缓存、物流运输时间、批量生产等情况下的约束条件,采用本文算法求解,进一步验证其有效性。2.3 交叉操作
2.4 变异操作

3 实验验证



4 结束语
