面向多价值链的汽车配件需求预测模型
2021-11-10任春华孙林夫
任春华,孙林夫+,韩 敏,3
(1.西南交通大学 计算机与人工智能学院,四川 成都 610031;2.西南交通大学 制造业产业链协同与信息化支撑技术四川省重点实验室,四川 成都 610031;3.成都信息工程大学 软件工程学院,四川 成都 610225)
0 引言
近年来,随着我国市场经济的发展,传统工业也迎来新的发展格局。以汽车行业为例,汽车作为出行便利的交通工具代表,随着生活水平的巨大改善,汽车保有量正在稳步增长。据相关资料统计,截止2019年底,我国汽车保有量达3.48亿辆,仅次于美国,且有望在2020年超越美国成为全球汽车保有量最多的国家,汽车工业已经成为我国的支柱性产业[1]。伴随着汽车保有量的增长,汽车售后换件维修量也在不断攀升。众所周知,汽车配件是汽车后市场获取利润的直接源泉。因此,汽车配件销售市场也迎来了巨大的挑战。其中,制定合理的销售计划和准确的需求预测是配件代理商亟待解决的重大问题,也是扩大市场份额的重要支撑。传统的中小型配件代理商往往根据下游计划订单或人工经验进行需求预测,随着工业信息化软件的升级,构建合理的模型和算法是有效提高配件需求预测准确率的关键。
目前,可用于汽车配件需求预测的主要方法有统计学预测方法,如自回归移动平均模型(Autoregressive Moving Average model, ARMA)[2]、差分自回归移动平均模型(Autoregressive Integrated Moving Average model, ARIMA)[3]等;机器学习预测方法,如随机森林(Random Forests, RF)[4]、支持向量机(Support Vector Machine, SVM)[5]等。CHEN等[2]基于ARMA模型进行调整,用于汽车配件“涂装材料”和“滤油器”的需求预测,结果表明该模型有一定的实用价值和较高的预测精度,但当时间序列波动或不稳定时,ARMA预测效果不够理想。为进一步提高预测精度,CHEN等[6]又提出一种回归-贝叶斯-反向传播神经网络(Regression-Bayes-Back Propagation Neural Network, RBBPNN)预测模型,该模型相比ARMA具有更高的预测精度和较好的鲁棒性;YU等[7]利用人工神经网络(Artificial Neural Network, ANN)对汽车配件“火花塞”进行需求预测,该方法相比ARMA能够有效降低预测误差,但需要对大量参数进行调优后才能获取较好的预测效果;MATSUMOTO等[8]分别利用ARIMA模型和霍尔特温特斯模型(Holt-Winters,HW)对汽车的“交流发电机”和“起动器”配件进行需求预测,结果表明平均预测误差能减少6.5%,但该模型缺少综合回归分析和时间序列的组合预测;廖伟智等[9]建立了动态故障规律的零配件需求模型,对汽车配件“钢圈”进行需求量预测,通过实验验证了模型的有效性,但该模型缺乏考虑“三包”期外的需求量;李敏波等[10]从销售数据和宏观数据两个层面对汽车轮胎销量进行分析,使用套索回归模型(Least Absolute Shrinkage and Selectionator Operator, LASSO)有效提高了轮胎销售预测的准确率,但该方法缺少与其他方法的有效性对比;杨静雅等[11]建立了一种量子粒子群算法(Quantum Particle Swarm Optimization, QPSO)优化支持向量回归(Support Vector Regression, SVR)的汽车售后配件预测模型,用于“刮雨器电机带支架总成”库存需求预测,该模型相比反向传播神经网络(Back Propagation Neural Network, BPNN)和粒子群优化SVR的预测精度有所提高,但结构单一且预测结果受较多参数影响;GONG等[12]提出一种灰色GM(1,1)非线性周期预测模型,对汽车零部件“座椅”进行销量预测,尽管该模型相比单一的GM(1,1)具有一定优势,但预测准确率有待提高。
为弥补单一预测模型的缺陷,组合预测模型应运而生。由于各单一预测模型具有不同的优缺点,采用组合预测能有效结合不同模型的优点,进一步降低预测的风险,提高预测精度。在配件需求组合预测领域,YANG等[13]基于ARIMA、多元回归(Multivariable Regression,MR)和SVR预测模型,建立了非负变权组合模型对汽车后市场的零部件进行需求预测,通过实验验证了该模型相比单一模型具有较高的预测精度,但没有考虑最优子模型的选择问题;孙其伟等[14]提出了基于ARMA、MR和BPNN的变权组合模型,通过对某汽车零部件进行需求预测,验证了该组合模型优于单个预测模型,但没有考虑单项预测方法在某些预测周期上的互斥性。随着人工智能的不断发展,最新的预测模型也取得了显著效果。朱周帆等[15]提出了ARIMA结合极端梯度增强(eXtreme Gradient Boosting, XGboost)的组合模型,对汽车市场批零量进行预测,结果表明该组合模型具有较小的误差,但其中没有融入深度学习的预测方法;陈明露等[16]构建了基于RF和长短期记忆网络(Long Short Term Mermory Network, LSTM)的组合预测模型,利用汽车配件的蓄电池销售和售后数据进行实验,结果表明该模型不仅优于单个模型(RF、LSTM),还优于ARIMA-LSTM组合模型,但子模型的权重需要进一步优化;MEHDIZADEH[17]提出一种集成分类库存分析法(Activity Based Classification, ABC)和粗糙集理论(Rough Set, RS)的预测模型,用于汽车零部件的需求预测,但采用常规的预测方法有待进一步提高预测精度;金淳等[18]设计了一种定量和定性相结合的集成预测模型,该模型融合了ARIMA、径向基神经网络和难以量化的外部因素,对“曲轴总成”和“气门弹簧”2种汽车零部件进行需求预测,实验结果表明该模型优于子模型,但其中融入了太多的主观因素。在其他应用领域,文献[19]给出一种GRU-BP组合预测模型,实现了供应链中制造业产品的需求预测;文献[20]提出一种基于LSTM和LightGBM的组合模型,用于供应链销售预测;文献[21]提出一种LSTM、GRU和XGboost的集成模型,实现了对出租汽车的需求预测;文献[22]提出一种LSTM结合XGboost的预测模型,应用于空气污染的预测。虽然以上组合模型均取得了较好的预测效果,但最新的深度学习和集成学习组合模型较少用于汽车配件的需求预测。
在组合预测模型中,文献[23-25]认为组合模型不一定比子模型的效果更好,但进行模型组合后比子模型的预测风险更小。尤其当子模型的预测值同时高于或低于真实值,此时组合模型无法有效提高预测精度。CANG等[26]提出一种基于信息论的最优模型子集选择算法,基于旅游需求预测的实验结果表明,选择最优子集的单个模型组合的预测效果明显优于所有可用的单个模型组合。考虑到所选子模型之间的冗余信息会降低组合预测模型的性能;CHE[27]提出一种基于最大线性相关性和最小线性冗余的选择算法,并通过3个市场数据集验证了提出的组合预测模型比其他模型的预测效果更好。针对如何组合单个预测模型,ANDERSON等[28]提出一种预测组合模型的动态选择方法,基于8个数据集的实验表明该方法能获得满意的预测结果。在汽车配件需求预测领域,当前大多数组合模型对不同时刻往往采用同一种组合预测模型,缺少针对不同时刻的数据特征而采用不同的预测模型,进而有效提高预测精度。
在第三方零部件多产业链业务协同云服务平台的多价值链协作模式下,汽车配件的销售模式主要包括链内的销售、跨链销售、跨链调拨、多链销售等。传统配件代理商的需求预测通常只考虑了链内的销售情况,没有考虑多链销售、急缺件跨链调拨等的情况。此外,在配件需求预测模型中,通常只涉及配件代理商本身的销售数据,忽略了下游服务商的配件相关售后服务数据。
针对以上不足和实际多价值链的配件需求预测,本文首先提出一种LightGBM_GRU_AM的组合预测模型,该组合模型能够发挥2种模型的优势,不但训练效率高效,而且模型结构简单。其次,在组合模型LightGBM_GRU_AM的基础上,进一步提出了一种基于LightGBM、GRU和LightGBM_GRU_AM的半组合预测模型,该模型能针对数据特征在不同时段进行子模型优选,从而有效地提高配件需求预测的准确率。最后,通过某代理商的3个多链配件需求预测数据集,验证了2种模型的有效性,同时也证明了半组合预测模型更有优势。
1 面向多价值链的配件需求预测背景
汽车零部件多产业链业务协同云服务平台(http://www.autosaas.cn/)是我国生产制造领域的第一批第三方云服务平台[29](简称第三方云平台或平台)。截止目前,该平台汇聚了1万多家整车制造企业、零部件供应商、配件代理商和售后服务商等中小型企业,旨在为汽车相关企业提供生产、制造、销售和售后维修等信息一体化服务。这些应用服务贯穿于上游的供应商、中游的整车制造企业和配件代理商、下游的服务商,逐步形成了以整车制造企业、部件制造企业为核心,上下游企业协作的多价值链网络(简称多链),其结构如图1所示。随着业务量的增长,平台中积累了海量的业务资源,这些资源可通过数据分析为协作企业提供决策依据,如客户挖掘、需求预测等。

由图1可以看出,整个汽车多价值链网络以第三方云平台做支撑。图中左边部分为价值链中服务链、配件链、营销链、供应链的常规业务,右边部分为多个以整车制造企业、部件制造企业为核心,上下游企业协作的价值链网络。在多价值链网络中,最频繁的业务交互通常发生在价值链内部,企业和信息化的发展使不同价值链之间的跨链和多链业务也随之增加。
随着我国汽车保有量的不断增加,申请加入第三方云平台的中小型企业越来越多,平台中的汽车配件需求和销量也在快速增长。中小型配件制造和销售企业希望发展壮大,提高市场占有率,因此合理的需求预测对企业制定采购策略至关重要[30]。在多价值链网络中,配件代理商的配件销售模式如图2所示,多价值链配件销售的特点:①传统的链内销售,配件代理商向链内的服务商、二级配件代理商销售配件;②多链销售,配件代理商与其他链的服务商、配件代理商产生跨链销售、跨链调拨、多链销售等行为;③在制定配件需求预测时,除了配件销售本身的数据,下游服务商的配件相关售后服务数据也具有参考性。因此,代理商在制定配件需求预测计划时,会存在以下问题:①平台中代理商的配件需求预测往往依靠人工经验和下游的配件计划单,制定的需求计划大多数是本链条内的需求,没有考虑多链的配件需求;②当面对多链销售、跨链调拨等行为时,原来的需求和实际需求存在巨大差异;③一个配件销售系统对应一个核心制造企业,也就是在多价值链中存在多个配件销售系统,每个系统之间又存在差异,面向多价值链的配件需求预测需要依靠第三方云平台提前整合多个配件销售和售后服务系统的数据。
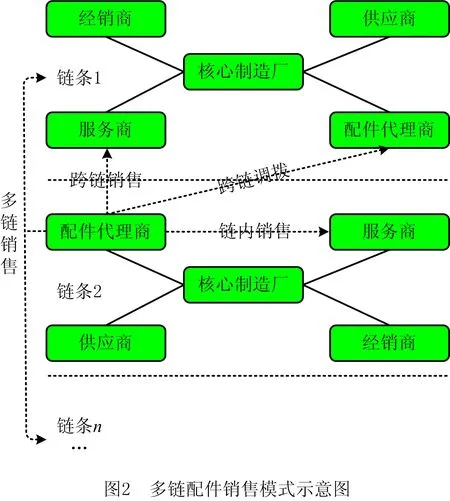
为解决在多价值链中配件需求预测不准确的问题,本文从配件代理商的角度,除了考虑传统链内的配件需求,还考虑了跨链销售、跨链调拨、多链销售等行为的需求。为进一步提高配件需求预测的准确率,采用科学合理的预测模型和算法是配件代理商进行需求预测的关键。
2 面向多价值链的配件需求预测模型
2.1 面向多价值链的配件需求预测组合模型
从配件代理商的角度,本文提出面向多价值链的配件需求预测组合模型(LightGBM_GRU_AM),考虑到组合模型的预测风险较单一预测模型要小,该组合模型融入LightGBM和GRU的特性,通过引入优势矩阵获取LightGBM和GRU的权重,进行组合预测。
2.1.1 轻梯度提升机
LightGBM[31]于2017年由微软公司发布,它是一种基于决策树的梯度提升框架,具有训练速度快、支持分布式、内存开销小等特性,一经发布就受到广泛关注。
LightGBM的主要思想是:设计了基于梯度的单边采样(Gradient-based One-Side Sampling,GOSS)算法解决高维海量数据耗时问题,该方法不需要计算所有样本点的梯度,而是选择信息增益大的样本点计算梯度。GOSS算法根据样本的梯度绝对值按降序排列,将梯度值排名前a%的样本组成一个子集A;接着在剩余样本集(A′)中随机抽取b%的样本作为子集B;最终将A和B的并集作为新的样本集A∪B,根据估计的方差增益对该样本集进行分割,定义节点分割特征j在点d处的方差增益为:
(1)

虽然GOSS采用小部分样本集计算方差增益,可能有损精度,但计算开销大大减少。文献[31]证明了该方法不但不影响训练精度,而且比随机抽样的性能更好。因此,LightGBM训练速度较快,更适合多价值链中的配件需求预测。GOSS的近似误差记作ε(d),计算方法如下:
(2)
式中:Vj(d)为所有样本的分割特征j在点d处的方差增益。其中,GOSS至少有1-δ的概率存在如下近似误差:
(3)

此外,LightGBM在特征处理方面,设计了一种互斥特征绑定(Exclusive Feature Bundling,EFB)算法,目的是将互斥的特征绑定在一起从而减少特征维度,进一步提高效率。EFB使用直方图算法,该算法的思想主要是对每个特征值进行分段,将特征上的取值进行装箱处理,最终实现连续的特征值转换为离散值。在遍历数据时,直方图累计离散化的值,并根据这些离散值寻找最优分割点。直方图优化示意图如图3所示。

XGboost采用按层生长的决策树生长策略(level-wise)。该策略同时分裂同一层的叶子节点,实现了多线程优化,且不容易过拟合,但对同一层的叶子节点都进行分裂时,有些叶子节点的增益较低,没有分裂的必要性,因此造成了额外的开销,level-wise的分裂策略如图4a所示。LightGBM在level-wise的基础上,进一步提出了更为高效的leaf-wise决策树生长策略,该策略从叶子节点中找到当前信息增益最大的节点进行分裂,循环该过程直到树的最大深度。leaf-wise的分裂策略如图4b所示。leaf-wise相比level-wise,在分裂次数相同的情况下,设置了树的最大深度,保障效率的同时防止过拟合。
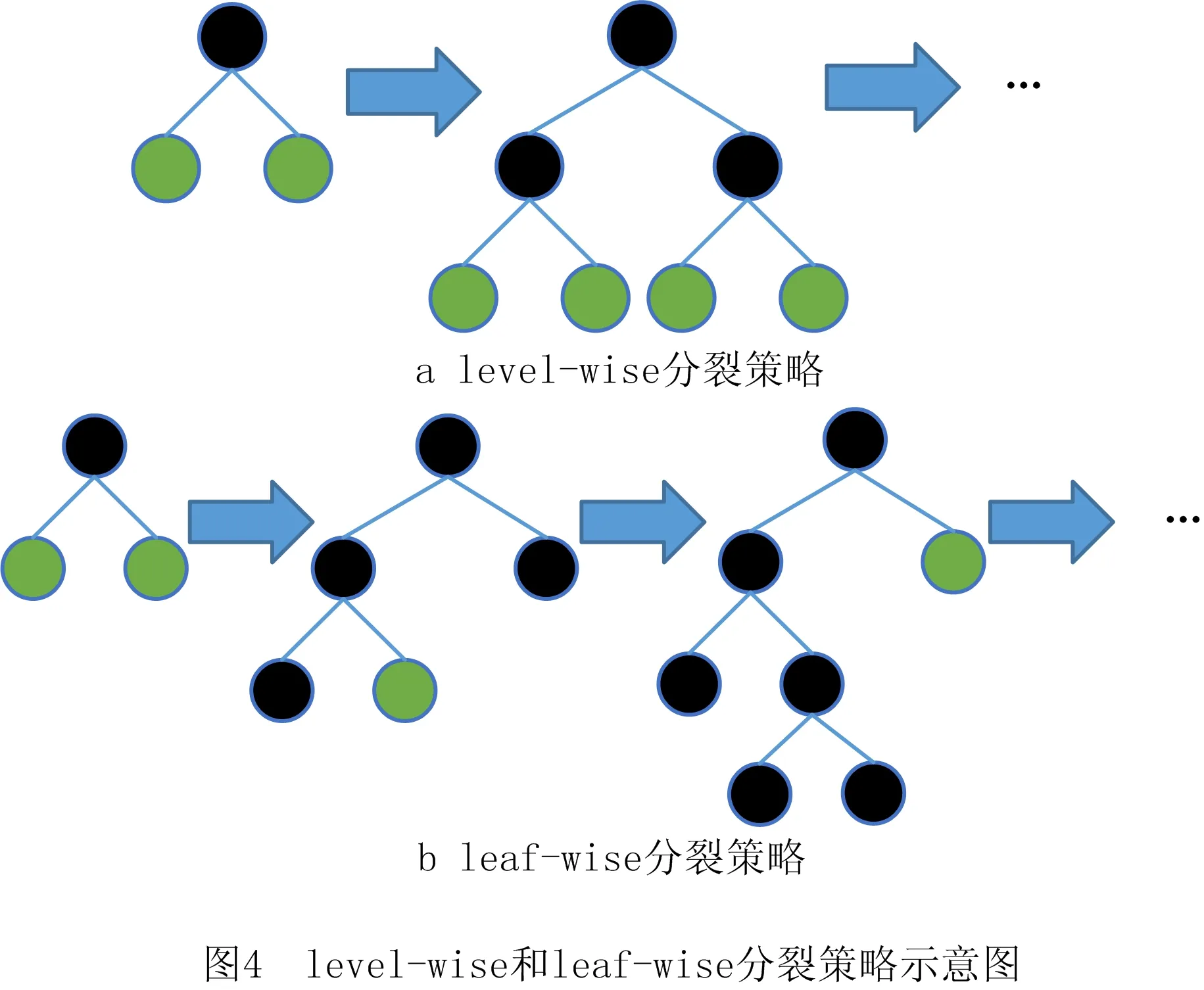
本文中多链配件需求预测的数据集主要包括配件销售和配件相关售后服务等,数据特征较多,而LightGBM在处理该类数据集的特征时更具优势。
2.1.2 门控循环神经网络
GRU于2014年由CHO等[32]提出,和LSTM[33]一样,也是用来解决循环神经网络(Recurrent Neural Network,RNN)中出现的梯度消失问题。GRU是LSTM的一个优秀变种,具有2个门:①更新门,替换了LSTM的输入门和遗忘门,主要控制前面记忆信息保存到当前时刻的量;②重置门,主要控制需要遗忘多少过去的信息。此外,GRU没有单独的存储单元,因此结构简单、参数更少且容易计算,其网络结构如图5所示。
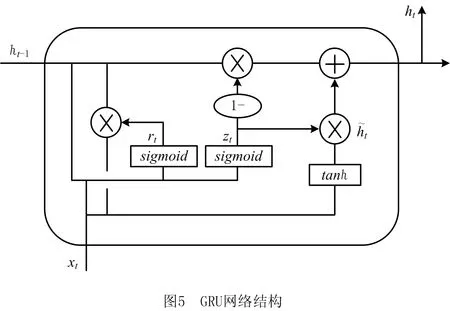
GRU的运行过程如式(4)~式(7)所示:
zt=sigmoid(Wz·[ht-1,xt]);
(4)
rt=sigmoid(Wr·[ht-1,xt]);
(5)
(6)
(7)
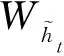
本文研究集中在汽车配件的需求预测,由于在多价值链中汽车配件种类繁多,数据量大小不同。若每种配件都要调整大量参数会导致时间成本增加,因此选用GRU将节省大量的额外开销。
2.1.3 优势矩阵
组合预测模型一般是单个模型的线性加权和,目前确定组合权重的方法有最小方差法、倒数法、最小二乘法等[34]。本文引入优势矩阵[35]确定单个预测模型的权重系数,其组合原理为:假设存在两个单项预测模型m1和m2,首先通过数据训练和预测获取单个模型的预测值,根据预测均方根误差(RMSE)建立单个模型预测误差对比矩阵,如式(8)所示:
(8)

(9)
接着计算m1和m2在优势矩阵中的优劣次数,n1为优势矩阵中第一列的和,n2为第二列的和。最后计算m1和m2的权重系数如式(10)所示:
(10)
由以上描述可知,优势矩阵还可以推广到多个预测模型,该计算方法简单有效。
2.1.4 配件需求预测组合模型
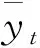
(11)
式中wmi表示第mi个子模型的权重。
同时,组合模型的预测误差et为:
(12)
本文从配件代理商的角度,结合多链配件销售和相关售后服务数据进行需求预测,该组合模型框架如图6所示。模型首先将多链配件预测数据集加载入模型,按一定比例划分训练集、验证集和测试集;接着调整LightGBM和GRU的初始参数,并利用训练集对模型进行初次训练,通过多次对LightGBM和GRU的参数调优,使其单个模型的预测效果达到最佳;最后引入优势矩阵计算单个预测模型的最优权重系数,经过模型加权组合后获取配件需求的预测值。

由图6可以看出,提出的组合预测模型(LightGBM_GRU_AM)具体实现步骤如下:
步骤1加载多链配件需求预测数据集(d),将数据集按一定比例划分为训练集(d1)、验证集(d2)和测试集(d3)。
步骤2初始设置LightGBM的学习率、估计器数目、树深度等参数,训练模型,记录初始预测值和误差。

步骤4初始设置GRU的神经元数目、时间步、激活函数等参数,训练模型,记录初始预测值和误差。
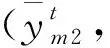
步骤6结合式(8)~式(10),将单个模型的误差转换成优势矩阵,同时计算单个模型的权重系数(wm1,wm2)。

结合LightGBM_GRU_AM的具体实现步骤,本文给出了LightGBM_GRU_AM的伪代码:
Model 1:LightGBM_GRU_AM
Input:Multi-chain parts demand forecast data setd

1: Load d1,d2 and d3;
2: Initialize and execute LightGBM;
3:for i=1 to t1 do //t1 is the number of tuning parameters
4: Setting parameters;
5: Execute LightGBM;
7: end
8: for i=1 to t2 do //t2 is the number of tuning parameters
9: Setting parameters;
10: Execute GRU;
12: end
13: Calculate wm1and wm2use equations(8)~(10);
2.2 面向多价值链的配件需求预测半组合模型
在LightGBM_GRU_AM组合预测模型中,当某时刻LightGBM和GRU的预测值均高于或低于实际值时,通过加权的LightGBM_GRU_AM组合模型并没有很大优势。考虑到加权的组合预测模型都存在这样的问题,为进一步提高配件需求预测的准确率,本文设计了一种基于LightGBM、GRU和LightGBM_GRU_AM的半组合预测模型(LightGBM_GRU_SC)。该模型首先对验证集建立分类标签,对其进行特征提取,并建立分类回归树的子模型选取规则,最后集成不同子模型的预测值形成最终的预测结果。
2.2.1 特征提取及分类回归树
特征提取是数据挖掘中最常有的一种方法,从数据集的全部特征中筛选出最重要的特征,去除冗余或不相关的特征,从而使模型性能最佳。其中,基于树模型的特征提取是最有效的一种方法,本文借鉴分类回归树(Classification and Regression Tree,CART)和XGboost[36]中最重要的特征提取步骤,即信息增益的计算方法,如式(13)所示:
(13)
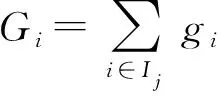
结合本文的多链配件需求预测数据集,通过计算得分求出数据集中每个特征的Gain,得到特征的重要度排序。同时,按照特征Gain排序,通过节点分裂、递归生成分类回归树和提取分类规则。
2.2.2 配件需求预测半组合模型
本文的半组合预测模型包括LightGBM、GRU和LightGBM_GRU_AM三个子模型,其模型如图7所示。该模型主要针对不同时刻的数据特征采用子模型优选策略进行预测,即一部分数据使用LightGBM_GRU_AM组合模型获取最优预测值,一部分数据使用LightGBM或GRU子模型获取最优预测值,最后集成一段时间范围内的预测值形成最终的需求预测。
从图7可以看出,半组合预测模型(LightGBM_GRU_SC)具体实现步骤如下:

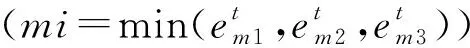
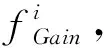
步骤4选择信息增益最大的特征从根节点(root)开始划分特征,依次递归建立子节点,当执行到所选的特征增益很小或没有特征可选时,形成分类回归树(Cart)。
步骤5利用分类回归树对验证集进行训练,同时从根节点到叶子节点形成子模型选择规则(rulemi)。

步骤6对测试集数据(d3)进行预测,根据建立的子模型选择规则,以测试集中的数据特征进行模型选择。

结合LightGBM_GRU_SC的具体实现步骤,本文给出了LightGBM_GRU_SC的伪代码:
Model 2:LightGBM_GRU_SC
Input:Multi-chain parts demand forecast data set d

3: for i=1 to n do //n is the number of features in the data set
img id="b5451dac2cf01f334dd3fbe5459eaeaa" class="formula" src="images/b5451dac2cf01f334dd3fbe5459eaeaa0.jpg" width="161" height="17" title="width=161,height=17,dpi=110" alt="复杂单元:FZ" />
5: end
7: for i=1 to n do
9: break;
10: end
13: Establish rulemi;
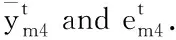
3 面向多价值链的配件需求预测算例分析
3.1 数据和实验环境
以第三方云平台中的多链配件销售和配件相关售后服务数据作为实验数据集,本文除了考虑链内、链外配件代理商的销售订单和数量外,还考虑了下游服务商的一些售后服务数据。由于汽车保养和维修服务最主要的方式是换件,因此配件寿命、急缺件和故障件对配件需求也有一定影响。此外,目前平台中一个销售系统对应一个核心制作企业,一个售后服务系统亦对应一个核心制作企业,获取多个系统的数据需要花费大量时间成本。换句话说,本文基于平台从多个系统中提取配件相关需求预测数据,由于不同系统的数据表和字段格式不同,首先对数据进行清洗,主要删除缺失值、异常值和重复的数据;接着对数据进行集成,主要合并相同含义的字段值;最后,整理得到可用于多链配件需求预测的数据集。
本文以平台中某配件代理商作为研究对象,采用其销售的“散热器总成”、“燃油滤清器总成”和“发动机油”3个真实数据集进行算例分析和模型对比。“散热器总成”和“燃油滤清器总成”数据集因为不是每天都有销售记录,所以将其拟合成周,时间范围为2017年1月~2019年12月,该数据集按一定比例划分为训练集、验证集和测试集;“发动机油”数据集因为是常规保养类配件,每天都有销售记录,所以以天为单位进行模型训练和预测,时间范围为2015年1月5日~2019年12月31日,该数据集按一定比例划分为训练集、验证集和测试集。数据集的特征主要考虑配件代理商的历史订单、退货订单、销量等,下游服务商和下级代理商的故障件数量、配件寿命、急缺件数量、该类配件的整车保有量等。这些配件相关数据构成了多链配件的需求预测数据集。
限于篇幅,本文给出了“散热器总成”部分数据集的示例,如表1所示。
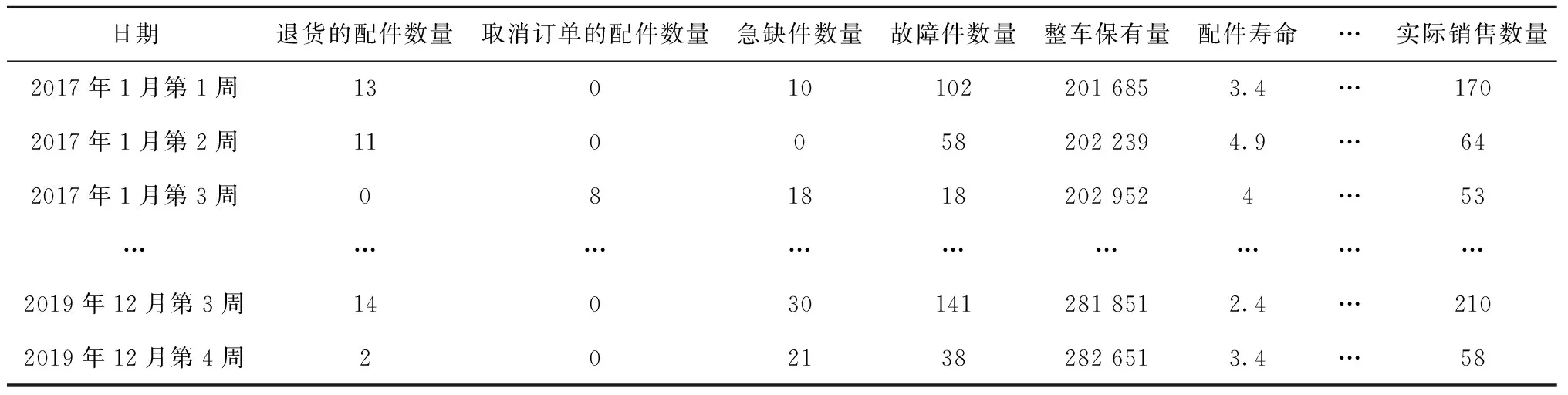
表1 “散热器总成”部分数据集的示例
考虑到各数据特征量纲之间的差异,为消除特征之间的相互影响,在实验之前对数据集进行标准化处理,如式(14)所示。
(14)
式中:xmin、xmax分别为当前特征的最小值和最大值;x为当前待标准化的特征值;x*为标准化后的特征值。
实验平台为Inter®CoreTMi7-7500 CPU,12 G RAM,NVIDIA GeForce 940MX以及Windows 10 64位操作系统。软件平台采用Spyder 3,编程语言采用Python 3.7。LightGBM模型采用lightgbm 3.0,GRU模型采用深度学习框架Keras 2.0。
本文选取均方根误差(RMSE)和平均绝对误差(MAE)作为实验的评估标准:
(15)

针对不同模型的预测结果对多价值链内企业影响不同,考虑到各模型的优劣排名在预测周期内变动,本文设计了一种用于评估模型综合排名的标准,即平均综合排名指标(ACR),该指标通过评估预测周期内m个模型的平均排名情况,
1≤rank(…)≤m。
(16)

3.2 参数调优
为使单个模型的预测值达到最优。以“散热器总成”配件为例,对LightGBM的参数调优,设置初始学习率为0.1,接着获取最优的迭代次数(num_boost_round,nbr),迭代过程中的RMSE分布如图8所示。从图8可以看出,该数据集规模不大,最优的迭代次数为26。限于篇幅,本文不一一列出每个参数的选优过程,LightGBM和GRU的最优参数值如表2和表3所示。
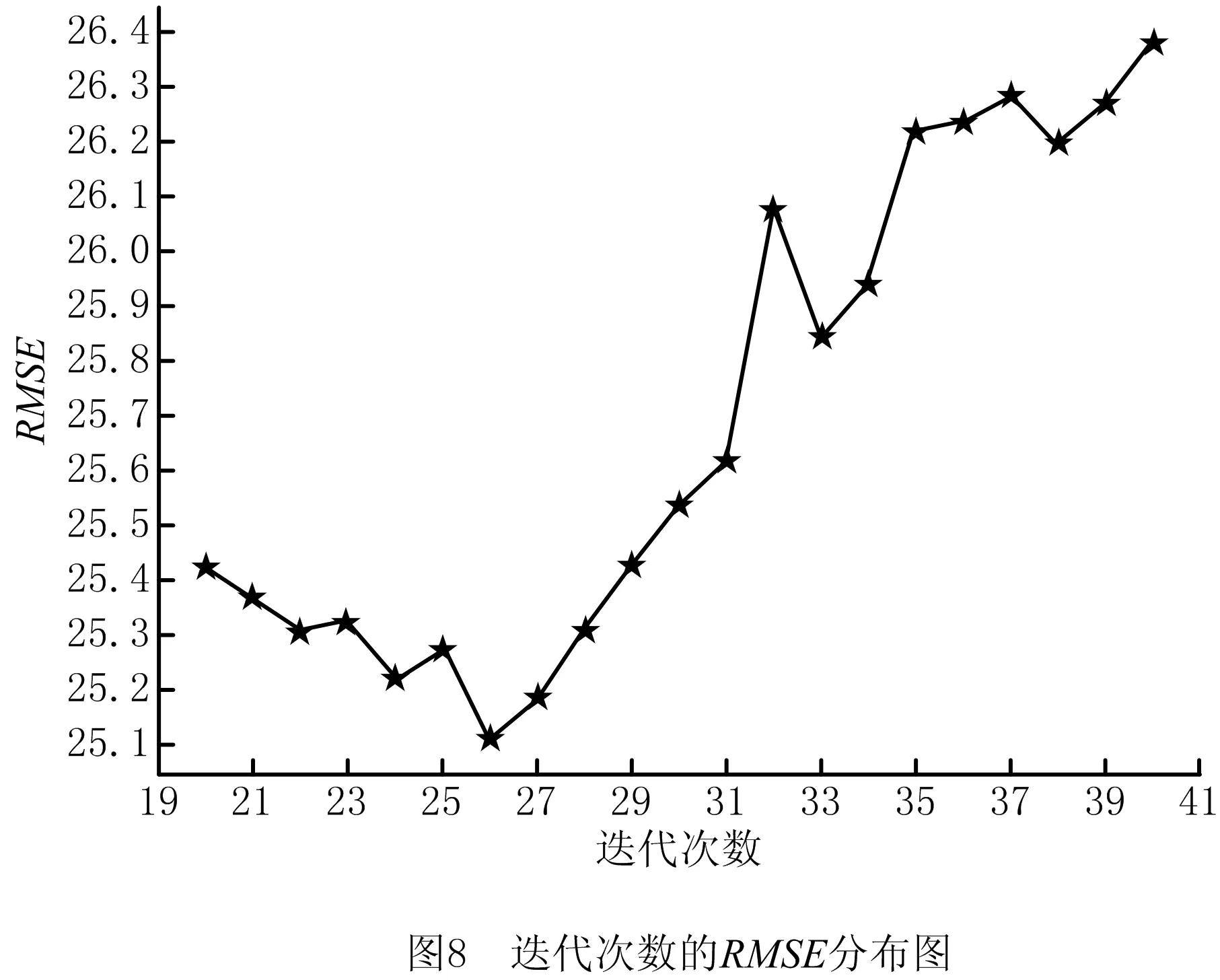

表2 LightGBM的参数

续表2

表3 GRU的参数
3.3 需求预测模型实验
为验证LightGBM_GRU_AM和LightGBM_GRU_SC的合理性,分别与LightGBM和GRU子模型进行对比实验。“散热器总成”数据集以周为单位,对2019年7月1日开始的24个周进行需求预测,为使组合模型的预测效果最佳,引入优势矩阵后LightGBM的权重系数为0.458,GRU的权重系数为0.542,预测结果如表4所示;“燃油滤清器总成”数据集也是以周为单位,对2019年7月1日开始的24个周进行需求预测,为使组合模型的预测效果最佳,引入优势矩阵后LightGBM的权重系数为0.667,GRU的权重系数为0.333,预测结果如表5所示;“发动机油”数据集以天为单位,对2019年8月11日开始的120天进行需求预测,引入优势矩阵后LightGBM的权重系数为0.45,GRU的权重系数为0.55,预测结果如表6所示。

表4 “散热器总成”数据集的预测结果

表5 “燃油滤清器总成”数据集的预测结果
从表4~表6可以看出,在3个配件需求预测数据集中,本文提出的2种预测模型在RMSE和MAE指标上相比子模型(LightGBM和GRU)的误差值都要低,因此在多链配件需求预测中,LightGBM_GRU_AM和LightGBM_GRU_SC是可行的,LightGBM_GRU_SC经过子模型优选后,其预测效果更佳。
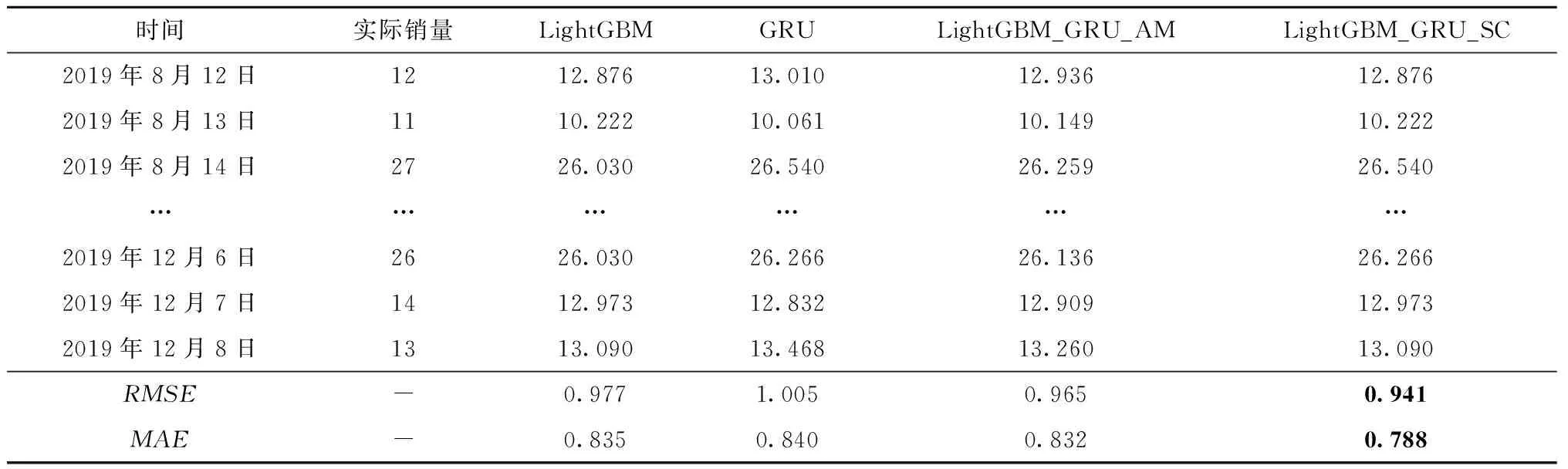
表6 “发动机油”数据集的预测结果
3.4 与其他模型对比
为进一步验证LightGBM_GRU_AM和LightGBM_GRU_SC的有效性,分别与LSTM、卷积神经网络_长短期记忆网络(Convolutional Neural Networks_Long Short Term Memory networks, CNN_LSTM)、XGboost、Catboost[37]以及误差倒数(Reciprocal Error,RE)优化的LightGBM_GRU(LightGBM_GRU_RE)模型进行实验对比。本文选取这些模型,主要考虑:LSTM是一个经典的预测模型,广泛用于预测应用场景,本文采用的GRU模型是LSTM的一个变体;CNN_LSTM是一个组合预测模型,该模型既考虑了数据特征又考虑了梯度消失问题;XGboost是集成学习中的一个经典框架,也广泛用于回归预测;Catboost是继XGboost后的又一个梯度提升框架;LightGBM_GRU_RE主要采用倒数法对组合模型进行优化,通过该模型可以验证本文使用的优势矩阵进行模型组合是否有效。LightGBM_GRU_AM、LightGBM_GRU_SC与其他几种模型的预测结果如图9所示。


由图9可以看到各模型在周期内的配件需求预测值,为进一步了解不同模型在周期内的预测优劣情况,即通过本文提出的ACR评估标准来计算各模型的综合排名,结果如图10所示。


由图10可以看出,在“散热器总成”数据集中,Catboost的ACR值最大,预测效果最差;LSTM和CNN_LSTM的ACR值都为4.29,预测结果的综合排名基本一致;本文的LightGBM_GRU_AM与LightGBM_GRU_RE的ACR值差距不大,但LightGBM_GRU_AM也有一些优势;在该数据集中,LightGBM_GRU_SC的ACR值最低,预测效果最佳。在“燃油滤清器总成”数据集中,CNN_LSTM的ACR值最高,预测效果最差;尽管LightGBM_GRU_AM相比LightGBM_GRU_RE的ACR值较高,但比LSTM、CNN_LSTM、XGboost和Catboost的预测效果都好;而LightGBM_GRU_SC的预测效果最佳。同理,在“发动机油”数据集中,本文的提出2种预测模型LightGBM_GRU_AM和LightGBM_GRU_SC较其他几种模型具有一些优势,而LightGBM_GRU_SC的预测效果最好。
如表7所示为9个模型在3个数据集上的实验误差。可以发现,本文提出的2种模型结合了LightGBM和GRU的优势,相比其他7种模型的误差值更低,表现得更平稳。此外,经过子模型优选后的LightGBM_GRU_SC预测效果最好。
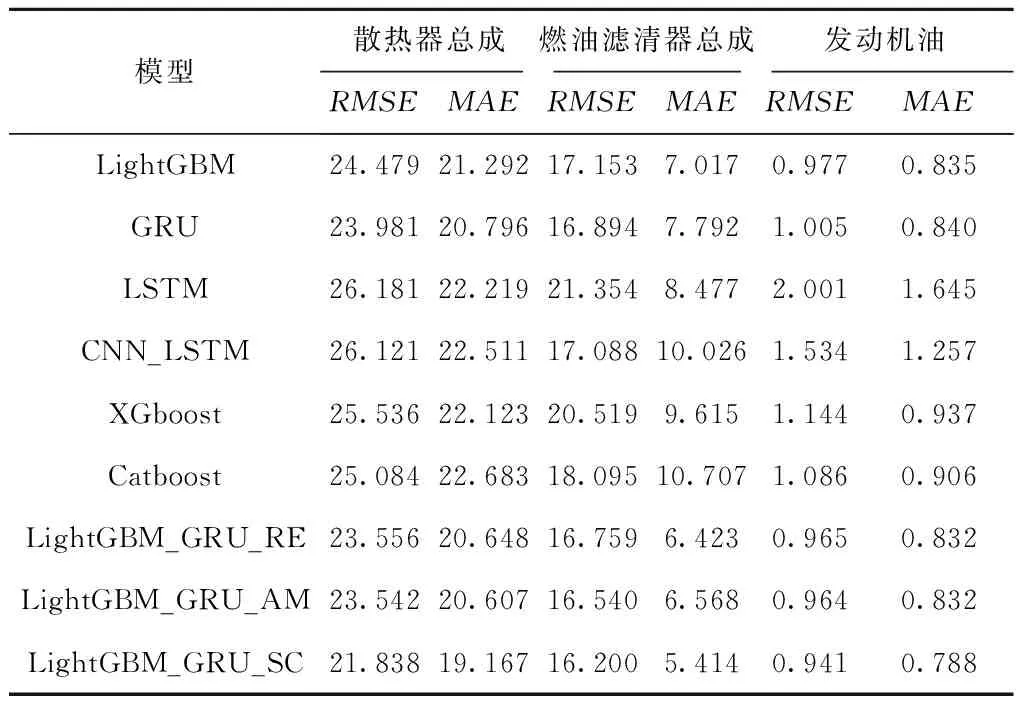
表7 与7种不同模型之间的误差对比
4 结束语
基于多价值链协作模式下配件代理商的实际预测需求,本文首先提出了LightGBM_GRU_AM组合预测模型,该组合模型能够有效结合2种模型的优点,不仅效率高效且结构简单。其次,考虑到LightGBM_GRU_AM组合模型中,部分时刻LightGBM和GRU的预测值都高于或低于实际值时,LightGBM_GRU_AM组合模型不如单一的LightGBM和GRU,因此提出了LightGBM_GRU_SC半组合预测模型,该模型通过子模型优选获取最佳预测值。最后,集成平台中多链配件销售和配件售后服务相关数据对提出的2种模型进行算例分析,通过3个配件数据集验证了LightGBM_GRU_AM和LightGBM_GRU_SC的有效性,且LightGBM_GRU_SC的预测效果更好,为配件代理商的采购计划提供了指导依据。尽管本文提出的2种预测模型能有效应对多链的配件需求预测,但LightGBM_GRU_SC在进行子模型优选过程中增加了一些时间开销。未来,也将重点考虑在提高预测精度的同时,降低预测模型的时间成本。
