三江源地区灌木亚菊的转录组分析
2021-11-10夏铭泽张发起
徐 浩,夏铭泽,张发起
(1.中国科学院高原生物适应与进化重点实验室,中国科学院西北高原生物研究所,青海西宁810001;2.中国科学院大学生命科学学院,北京100039)
灌木亚菊(Ajania fruticulose(Ledeb.)Poljak)隶属菊科(Asteraceae)亚菊属(Ajania),小亚灌木,主要分布于我国西北地区及俄罗斯中亚地区550~4 400 m的荒漠及荒漠草原[1]。灌木亚菊在青藏高原地区资源量丰富,全草入药,有止咳止血、排毒消炎、镇定、祛痰及抗蛔虫等药效,还可用于活血化瘀、咽喉肿痛等疾病[2]。该植物具纵深发达的根,且蒸腾作用较弱,使得灌木亚菊的抗旱能力较强,广布于干旱和半干旱的荒漠地带[3]。此外,因其适口性好,可作为牛、羊等牲畜的食料[4]。目前亚菊属植物的研究主要集中在化学成分及其药理学方面,如Li等[5]以灌木亚地上部分为原料提取出两种新的愈创木内酯和四种黄酮类化合物,对黄嘌呤氧化酶有较好的抑制作用。张占欣[6]通过亚菊属植物细叶亚菊(A.tenuifolia)的全草提取到了以萜类、黄酮及香豆素为主的35个化合物。Liu等[7]对细裂亚菊(A.przewal⁃skii)精油研究发现其具有一定的抗菌活性。Shi等[8]在柳叶亚菊(A.salicifolia)中分离得到了47种次生代谢产物,以此来探讨它们在亚菊属中的化学分类学意义。此外,通过研究亚菊属植物(A.shiwogi⁃kuvar.kinokuniense)内抗氧化酶对锈病的抗性来探明其对锈病的抗性机制[9]。通过测定同科植物菊花(Chrysanthemum morifolium)及其炮制品中绿原酸、木犀草苷等药用成分的含量,提供炮制品合适的质量控制参考方法[10]。然而该属的分子生物学研究涉及较少,仅有少数基于高通量测序获取叶绿体基因组开展系统发育分析等研究工作[11],而在转录组与基因组方面的研究接近空白。
近年来,基因组学、转录组学、蛋白组学、代谢组学等组学技术的发展突飞猛进,特别是以转录组等功能基因组学在植物分子生物学研究中的应用越来越广泛[12-13]。对接种链格孢菌(Alternaria tenui⁃ssima)的菊花(C.morifolium)叶片进行转录组分析,观察到病原体识别、细胞壁修饰等差异转录的基因在病原体侵入后被上调[14]。油料作物红花(Cartha⁃mustinctorius)的转录组分析成功预测出黄酮类化合物和种子油脂生物合成的相关基因[15]。低温诱导的灰白银胶菊(Parthenium argentatum)表皮组织转录组研究发现天然橡胶的生物合成与夜间低温相关[16]。
青藏高原地区的灌木亚菊资源量巨大,有着巨大的开发潜力,且其主要分布在荒漠区,也具有重要的生态价值。然而,目前对该植物的研究涉及还较少,尤其在灌木亚菊的药理作用、功能成分及作用机理研究较少[4]。因此,本研究利用Illumina HiseqTM测序平台对灌木亚菊叶片进行转录组测序、组装和生物信息学分析,挖掘药用活性相关基因及代谢通路,并对其分子标记进行预测分析,为灌木亚菊的资源利用和保护、遗传多样性等研究提供基础数据。
1 材料与方法
1.1 试验材料
灌木亚菊新鲜、健康的叶片于夏季(7月初,植物花期)采集于青海省海南州共和县(地理坐标N36°10′53″,E100°59′14″;海拔2 835 m)。分别采集3株植物的叶片经75%乙醇和超纯水处理后迅速置于液氮,带回实验室后置于-80℃的超低温冰箱下保存备用。凭证标本(凭证标本号:zhang2018023)保存于中国科学院西北高原生物研究所青藏高原生物标本馆(HNWP)。
1.2 试验方法
1.2.1 灌木亚菊RNA的提取与文库构建
利用Total RNA Extractor(Trizol)提取试剂盒提取灌木亚菊叶片(3株植物的叶片混样)中总RNA,并用琼脂糖凝胶电泳与Nanodrop 2000检测总RNA的浓度与纯度。检测合格的RNA参照生工生物工程(上海)股份有限公司的标准流程进行文库构建。文库构建完成后,采用Qubit 2.0、Agilent 2100进行文库质量检测,并使用Q-PCR方法对文库的有效浓度进行准确定量(文库有效浓度>2 nM),以保证文库质量。
1.2.2 序列的测序及拼接
基于Illumina HiseqTM高通量测序平台进行测序,经CASAVA碱基识别(Base calling)把数据文件转换为原始测序序列(Raw reads)。利用FastQC v0.11.2[17]对原 始 数据进行质量 评 估,Trimmomatic v0.36(http://www.usadellab.org/cms/?page=trimmo⁃matic)对含有带接头的、低质量的序列进行数据质控,得到高质量的序列(Clean reads)。最后使用Trinity v2.4.0[18]将Clean reads进行从头组装,得到的转录本去冗余后,将每个转录本聚类中长度最长的作为Unigenes用于后续分析。
1.2.3 基因的功能注释
为获得全面的基因功能信息,通过NCBIBlast+v2.60[19]将Unigenes与CDD、KOG、NR、NT、PFAM、Swissprot、TrEMBL、GO、KEGG等数据库比对。根据Swissprot、TrEMBL的蛋白注释结果得到GO功能注释信息。利用KAASv2.1[20]将Unigenes与KEGG数据库比对进行代谢通路分析。根据转录本与数据库Blast的比对结果通过软件TransDecoder v3.0.1进行编码序列(Coding sequence,CDS)预测。
1.2.4 SSR与SNP的预测
基于组装好的转录本Unigenes序列,利用工具MISA v1.0[21]来 识 别Unigenes中 的 简 单 重 复 序 列(Simple sequence repeat,SSR),其中一至六重复单元SSR的至少重复次数依次为:10、6、5、5、5、5次。结果包含复合型与完美型SSR,BCFtools v1.5[22](参数设置:质量值>20,覆盖度>8)抽提Unigenes中的单核苷酸多态性SNP(Single nucleotide polymor⁃phisms,SNP)进行统计分析。
2 结果与分析
2.1 转录组测序数据分析
经琼脂糖凝胶电泳检测总RNA的产量与质量胶图如图1所示(本研究样品编号为23,其中Marker为DNA Marker,其只为检测基因组污染,并不代表RNA条带大小),检测合格后的样本再进行后续转录组分析。灌木亚菊转录组共得到Raw reads 47 084 098条(平均长度为150 bp),质控后Clean reads 45 983 774条,平均长度为145 bp,平均GC含量46.13%,Q30(碱基质量在30以上的序列)的序列占95.01%,表明测序所得序列质量能够满足后续分析。
图1 总RNA琼脂糖凝胶电泳图Fig.1 Agarose gel electrophoresis of total RNA
基于Trinity从头测序组装和拼接共获得103 820个Transcripts,其中挑选最长的转录本共得到53 760条Unigenes,N50长度为1 155 bp(表1)。对Unigenes的长度进行统计(图2),200~300 nt之间数量最多,有19 461条,占比36.20%;300 nt~2 000 nt之间的有31 158条,占比57.96%;大于2 000 nt的序列共有3 141条,占比5.84%。其中,共有38 215条Unigenes可作为CDS序列,长度在200~300 nt之间的CDS序列占比最多(25.20%),与Unigenes长度的分布趋势大体一致(图3)。
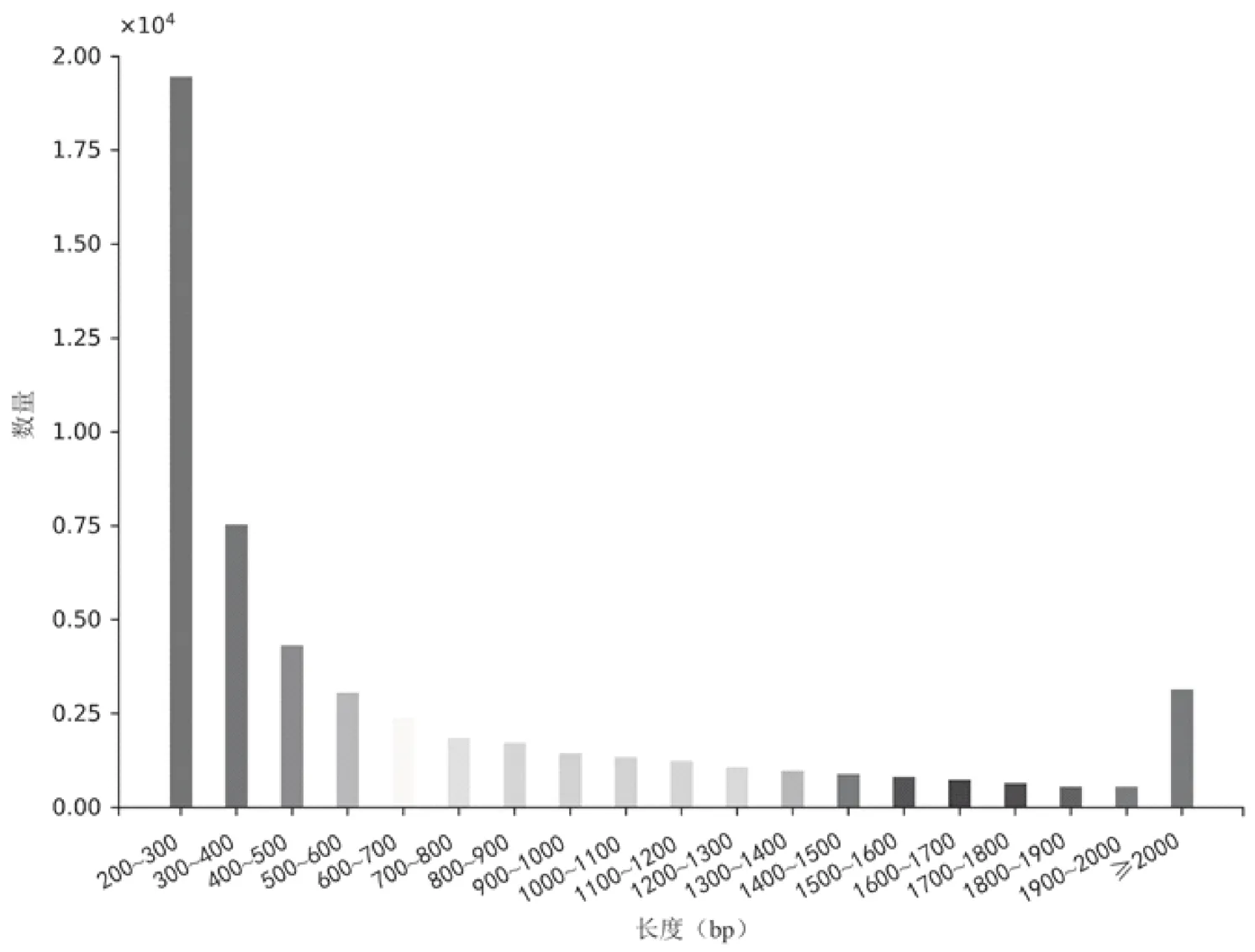
图2 灌木亚菊Unigenes的长度分布图Fig.2 Length distruption of A.fruticulose Unigenes
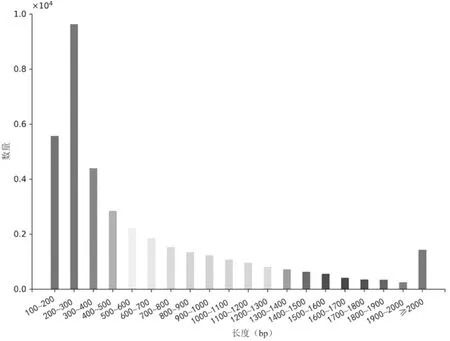
图3 灌木亚菊CDS的长度分布图Fig.3 Length distruption of A.fruticulose CDS

表1 灌木亚菊转录组数据拼接结果Table 1 Assembly result of transcriptome data from A.fruticulose (单位:bp)
2.2 灌木亚菊Unigenes的功能注释
将从头组装的Unigenes共53 760条分别与CDD、KOG、NR、NT、PFAM、Swissprot、TrEMBL、GO、KEGG数据库进行比对,发现至少注释到一个数据库的Unigenes数量为33 766(62.81%)条,有2 142条Unigenes在9个数据库中都能匹配成功,但仍有19 994条未能与上述数据库成功匹配(表2)。将Unigenes与NR数据库比对,共获得注释信息32 505条。与灌木亚菊Unigenes的NR注释匹配数最多的十个物种中,同科多年生草本植物洋蓟(Cynara car⁃dunculusvar.scolymus)与灌木亚菊的Unigenes相关序列最多,共18 898条(占比58.14%),剩余物种匹配度不高且与灌木亚菊亲缘关系较远(图4)。
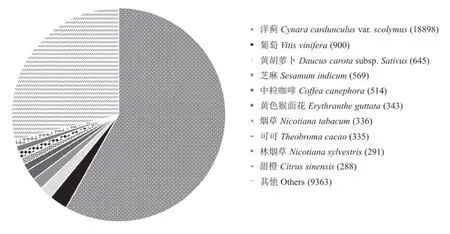
图4 灌木亚菊NR库的物种分布Fig.4 Species distribution of A.fruticulosa in NRdatabase
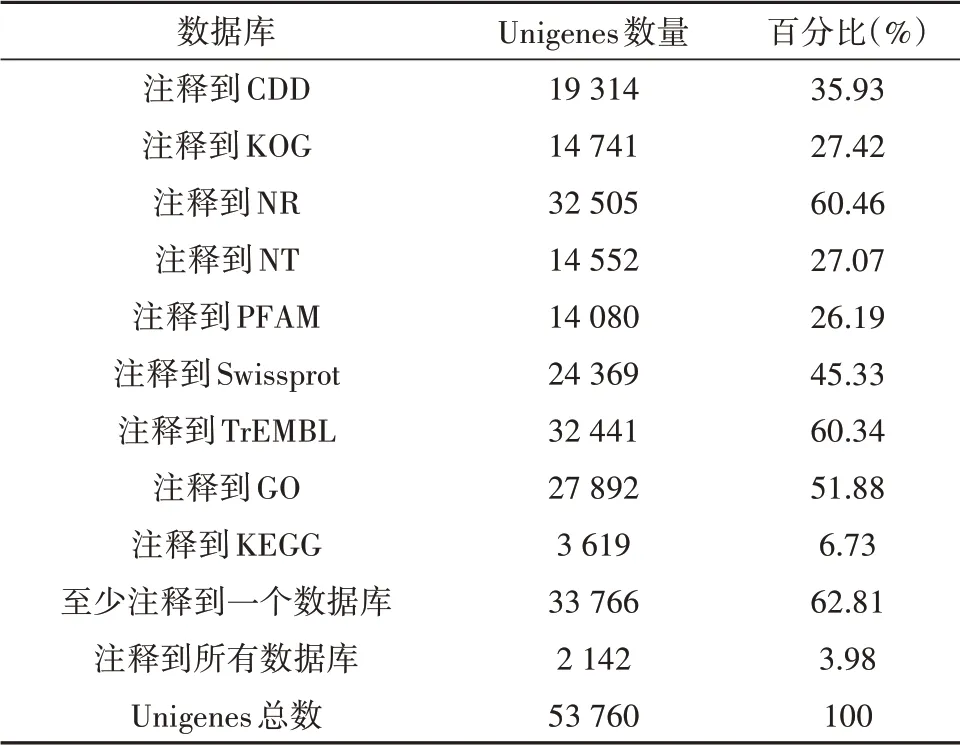
表2 灌木亚菊转录组注释结果Table 2 The resultsof transcriptome annotation of A.fruticu⁃lose
2.3 GO数据库功能分类注释
基于Swissprot和TrEMBL两种数据库的蛋白注释结果,根据Uniprot所得注释信息得到Unigenes的GO注释,共有27 892条Unigenes被注释,获得171 904条注释信息,分属于细胞组分(Cellular com⁃ponent)、分子功能(Molecular function)以及生物学过程(Biological process)三大类(图5)。在与药用成分相关基因注释中,涉及甾体(366条)与黄酮类化合物(204条)的居多,分别归属于生物学过程及分子功能类。苯丙素类主要涉及苯丙素的生物合成及代谢,有68条信息被注释出,而中草药中常见的萜类化合物也有48条信息被注释。
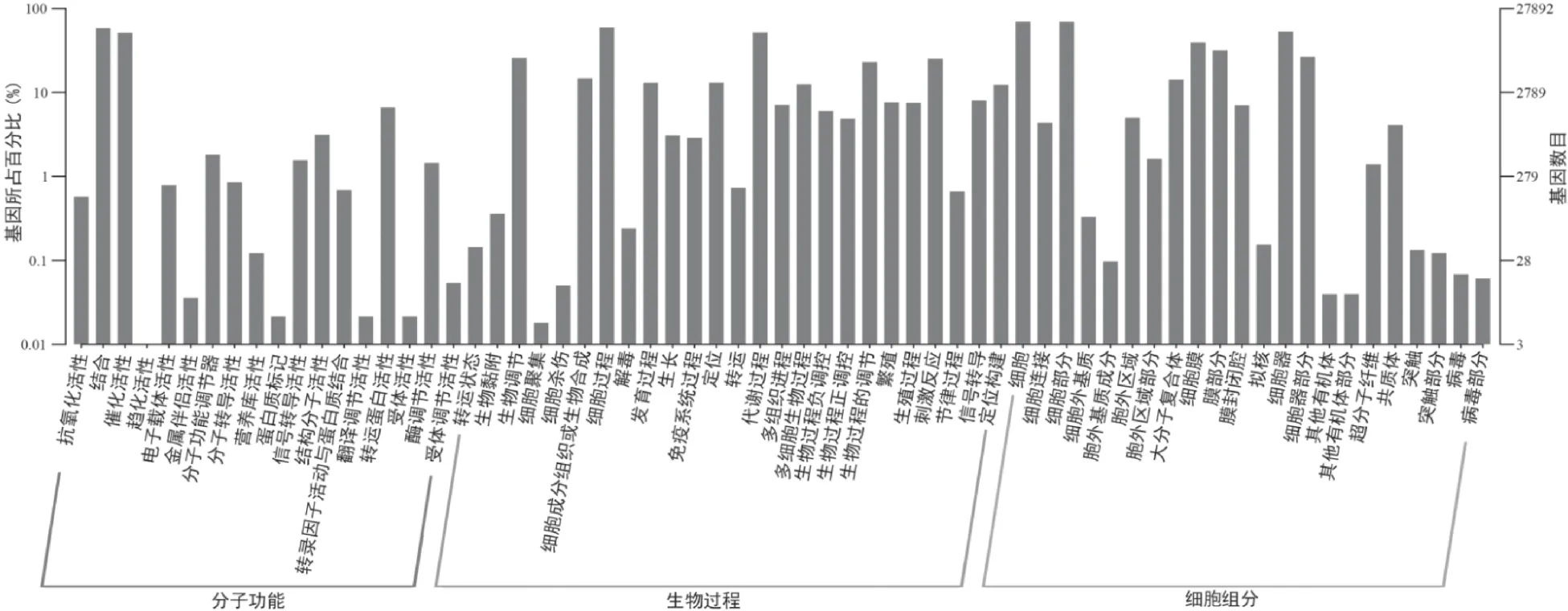
图5 灌木亚菊Unigenes的GO功能分类统计图Fig.5 GOfunctional classification statisticsdiagramof A.fruticulose Unigene
2.4 KEGG数据库的代谢通路分析
为了解灌木亚菊基因所参与的代谢途径,将Unigenes序列与KEGG数据库比对分析,共3 619条Unigenes获得注释,包含有5 892个注释信息,共归为细胞进程、环境信息处理、遗传信息处理、新陈代谢、有机体系统五大类(图6)。
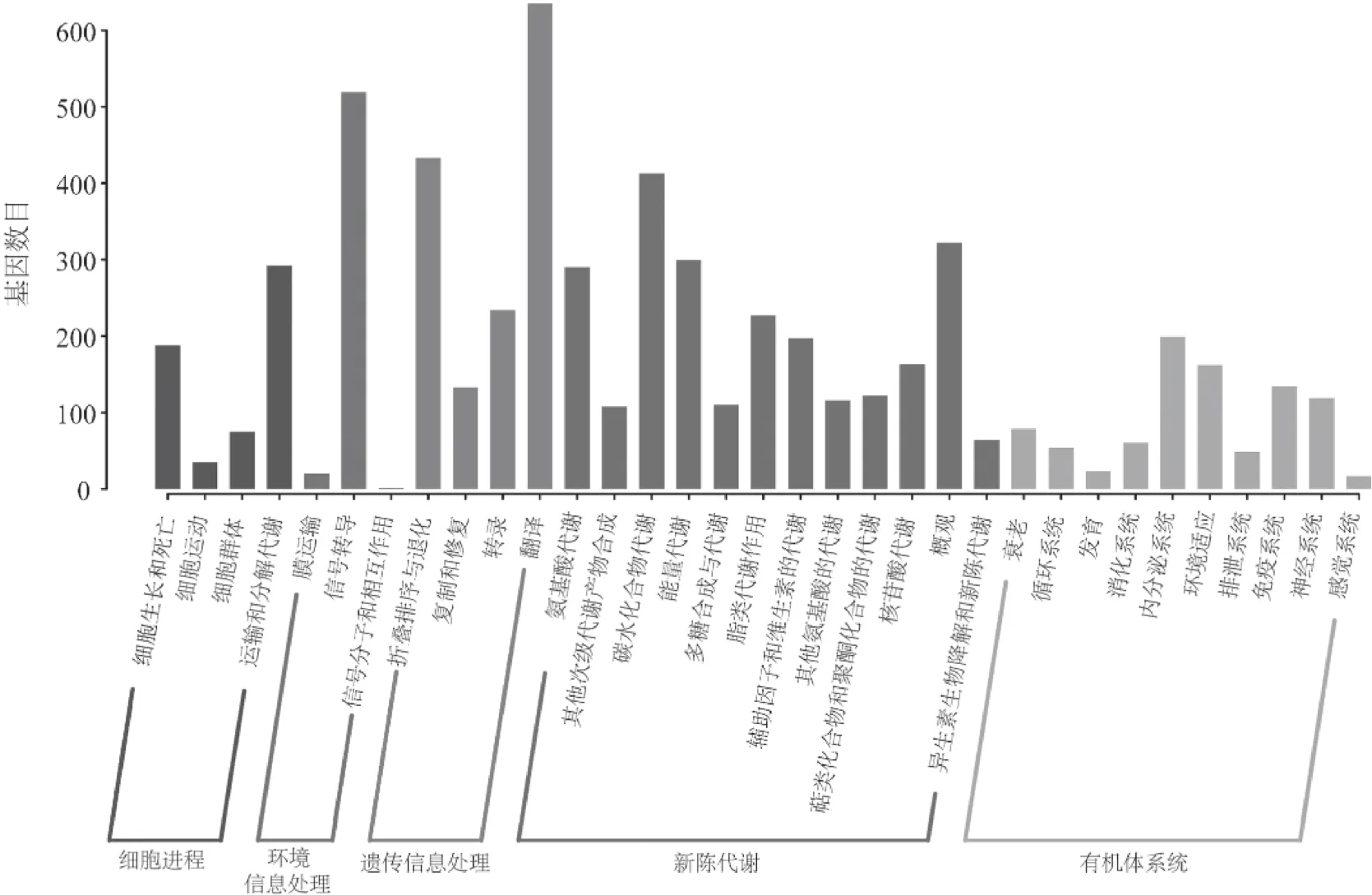
图6 灌木亚菊Unigenes的KEGG代谢通路分析Fig.6 Metabolic pathways analysis of A.fruticulose Unigenes in KEGGdatabase
为了解灌木亚菊化学成分的相关信息,筛选出了包含主要药用活性成分的相关通路(表3)。通路涉及苯丙素类、黄酮类、醌类、生物碱类、萜类、有机酸及酚类这些常见药用活性成分。在萜类化合物的生物合成途径中,倍半萜合成通路较为显著,其主要是由焦磷酸金合欢酯衍生而成,多以五元内酯环的形式存在,是亚菊属植物中特有的萜类成分。黄酮类化合物也是重要的药用活性成分,且涉及该通路基因的表达比重上升,它通过抑制酪氨酸酶的活性而具有显著的抗氧化能力。此外,反式肉桂酸等芳香族衍生物表达量的上升促进了苯丙素类生物合成的化学反应;通过接受呼吸链电子传递的脂溶性辅酶促进泛醌及其衍生物的合成。
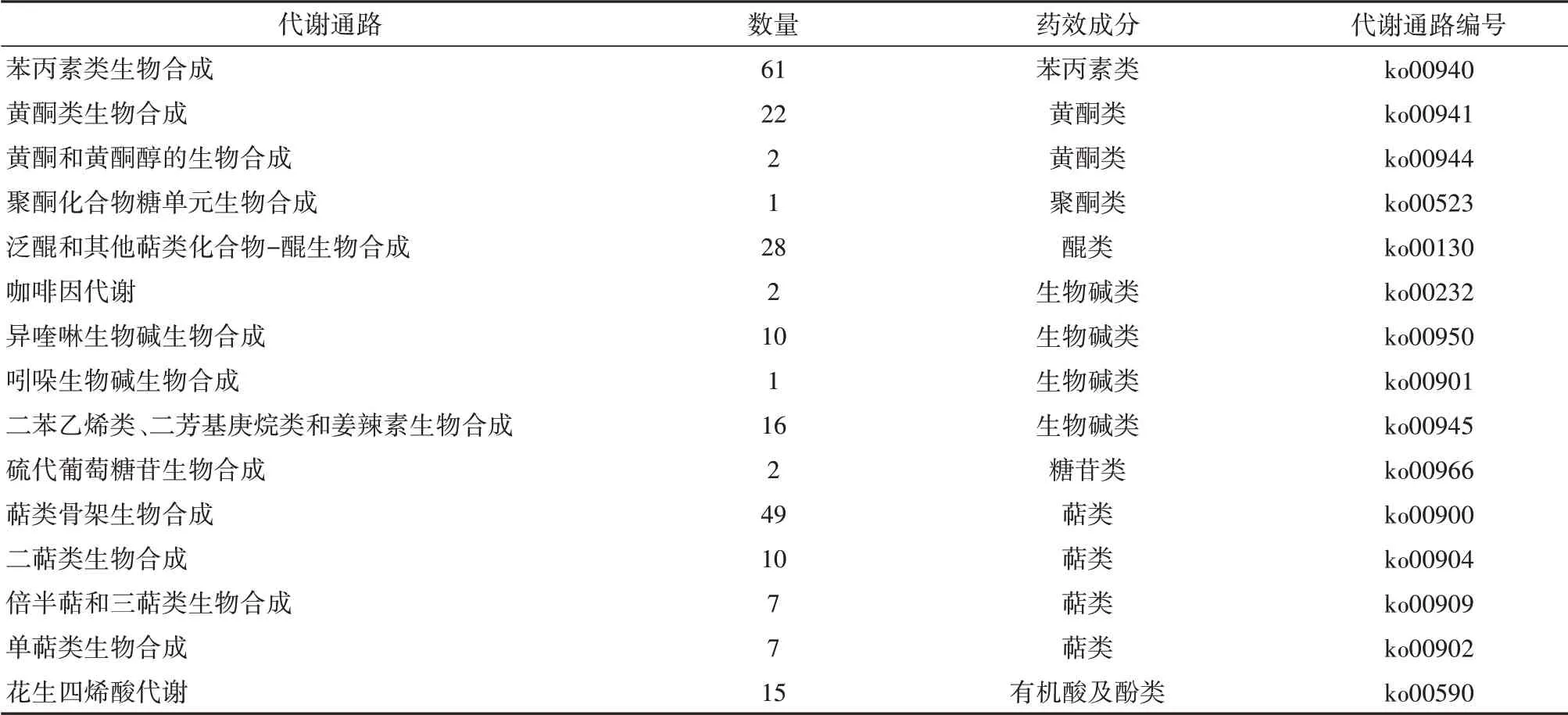
表3 灌木亚菊药用活性成分代谢通路分析Table 3 Metabolic pathway of active components of A.fruticulose
2.5 灌木亚菊转录组的SSR及SNP分析
灌木亚菊转录组共鉴定出6种SSR重复类型,不同类型简单重复序列出现的数量差距显著,其中单、二和三碱基重复的数量要远高于其他类型。单核苷酸多态性分析共获得42 013个SNP位点,4 470个InDels,转换和颠换所发生的比率近似2:1(图7)。
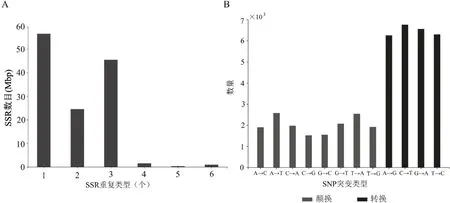
图7 灌木亚菊Unigenes的SSR(A)和SNP突变类型(B)分布Fig.7 Distribution of SSR(A)and SNPmutation type(B)of A.fruticulose Unigenes
3 结论与讨论
灌木亚菊广泛分布于我国西北地区及俄罗斯中亚地区,被用于治疗阑尾炎、肺结核、肺气肿等疾病[23]。灌木亚菊多作为提取倍半萜和酚类等药用化学组分的主要原料[24-25]。为了解灌木亚菊药用次级代谢产物的代谢途径,本研究对灌木亚菊进行了转录组测序及分析,旨在挖掘药用成分的相关功能基因,为亚菊属植物的资源利用及保护提供基础数据。植物基因组结构复杂和倍性变化等导致其基因组学研究进展缓慢。而转录组可以精确反映植物在特定时空状态下的基因表达,能够在不同的组织器官、发育阶段和生理状态下,发现植物基因的差异性表达[27-28]。
对灌木亚菊转录本进行测序、质控、拼接共获得53 760条Unigenes,N50长度为1 155 bp,平均长度为817.23 bp,与巴哈雀稗(Paspalum notatum)[29]、光皮树(Swida wilsoniana)[30]、万寿菊(Tagetes erec⁃ta)[31]、滨麦(Leymus mollis)[32]、碰碰香(Plectranthus tomentosus)[33]等物种的转录本在同一水平,表明本研究所得拼接序列Unigenes能够满足转录组生物信息学分析的要求。
约有1/3(19 994条)的灌木亚菊Unigenes在与CDD等主要数据库比对中未获得注释。在云南松(Pinus yunnanensis)[34]、多 穗 柯(Lithocarpus polys⁃tachyrus)[35]、云锦杜鹃(Rhododendron fortune)[36]等植物的研究中也有类似结果。这可能由于其近缘属植物的转录本测序研究相对较少,数据库中没有足够相似的序列与之匹配,也可能是灌木亚菊本身的特异性较高所导致,这需要对其近缘类群开展进一步的研究。NR注释中,多年生草本植物洋蓟(Cy⁃nara cardunculusvar.scolymus)与灌木亚菊的相似序列最多,洋蓟与灌木亚菊同为菊科植物,其亲缘关系较近,且二者均分布于干旱的荒漠环境中[1]。与灌木亚菊相类似,洋蓟的次生代谢产物主要有酚酸、类黄酮、倍半萜等,具备抗菌、抗氧化、抗癌等特性[37]。通过与GO数据库进行功能分类注释,获得与灌木亚菊药用成分相关的基因主要富集于甾体、黄酮类、苯丙素类和萜类化合物,涉及次级产物的生物合成和代谢调控过程,基因富集提供了这些化合物合成途径的线索。
通过KEGG数据库进行代谢通路分析得到与灌木亚菊药用活性相关的代谢通路百余条,如萜类、黄酮类、苯丙素类等。这些代谢通路与灌木亚菊药效,如抗炎[38]、抗氧化作用[39]、抗菌抗氧化[40-41]等密切相关[42]。苍术(Atractylodeslancea)转录组分析发现萜类骨架和倍半萜主要经甲羟戊酸途径进行生物合成,并且在干旱胁迫下倍半萜的合成通路下调[43]。灌木亚菊的倍半萜合成通路的数目相比较少,可能是因为灌木亚菊对荒漠及荒漠草原干旱环境的适应从而导致倍半萜合成通路依赖性降低。紫菀属植物(Aster spathulifolius)转录组分析发现该植物在抗脂肪生成、抗高血脂等方面的功效主要与其高表达的苯丙素途径密切相关[44],而本研究的分析结果与之一致,表明灌木亚菊植物在抗脂肪生成、抗高血脂等方面可能也有一定应用潜力。但是仍需要对灌木亚菊开展进一步的研究,尤其是次级产物的药效方面,如抗菌消炎、止痛止血等,以确定灌木亚菊的药物效能。
此外,在灌木亚菊转录本中鉴定的SSR要以单碱基、三碱基、二碱基重复序列较多,与怀菊(Chry⁃santhemum morifolium)[45]、药用植物半枫荷(Semiliq⁃uidambar cathayensis)[46]、长梗秦艽(Gentiana walton⁃ii)和粗壮秦艽(Gentiana robusta)[47]的结果相近。分子标记能够反映基因座的遗传多态性,为绘制高密度的遗传图谱提供了可能,为今后灌木亚菊的资源保护及遗传多样性研究提供了一系列的有效工具。
本研究通过高通量测序获得了三江源地区灌木亚菊转录组,预测得到53 760条Unigenes,通过生物信息学分析获得了丰富的功能基因、代谢通路、分子标记等基础数据,发现与药用活性相关的基因主要富集在甾体、黄酮类、苯丙素类及萜类化合物。KEGG代谢通路分析中得到233条Unigenes与药用活性相关的次生代谢通路,主要涉及具有镇痛消炎的苯丙素类、萜类化合物等成分。此外还检测出SSR位点4 586个及SNP多态性位点42 013个,为灌木亚菊的资源利用和保护、遗传多样性等研究提供了基础数据。
