面向推荐系统中有偏和无偏一元反馈建模的三任务变分自编码器
2021-11-10林子楠刘杜钢潘微科
林子楠, 刘杜钢, 潘微科, 明 仲
1 深圳大学大数据系统计算技术国家工程实验室 深圳 中国 518060
2 人工智能与数字经济广东省实验室(深圳) 深圳 中国 518060
3 深圳大学计算机与软件学院 深圳 中国 518060
1 引言
随着互联网的快速发展, 信息的数量呈现出爆炸性的增长, 这进一步加剧了信息过载的问题。为了缓解这一问题, 推荐系统应运而生[1-4], 并被用于从海量的信息中为用户提供有效的信息, 从而满足用户的需求。推荐系统的基本思路是通过对用户的历史行为、兴趣偏好等信息进行建模和分析, 挖掘出用户的需求, 进而为用户推荐可能感兴趣的物品。
在推荐系统中, 用户的行为(即对物品的反馈)可分为多元反馈、二元反馈和一元反馈等。多元反馈指的是用户对物品的反馈是显式且具有多个等级的,例如用户给物品进行打分, 打分范围为{1,2,3,4,5}。二元反馈和多元反馈类似, 用户对物品的反馈也是显式的, 但不同于多元反馈, 用户的反馈只有两个等级, 即喜欢和不喜欢。而一元反馈指的是用户对物品的反馈是隐式的, 是由系统根据用户的行为自行记录的, 例如点击和购买等。在现实生活中, 多元反馈和二元反馈都需要用户主动对物品进行反馈, 收集过程较为困难, 而一元反馈是由系统自行记录的,收集过程相对容易, 这使得一元反馈在推荐系统中更为常见, 并且得到了更广泛的应用。然而, 一元反馈建模存在一个巨大的挑战, 即用户的反馈不一定能反映用户的真实偏好, 比如点击并不代表用户一定喜欢, 而没有反馈也不代表用户不感兴趣, 有可能只是物品没有被用户观测到, 从而使得没有浏览、点击或购买等行为被系统记录下来。
现有的大部分推荐模型在建模的过程中, 往往忽略了一个重要问题, 即推荐系统中的偏置问题。因为推荐系统作为一个闭环的反馈系统, 在用户与系统的交互过程中容易出现多种偏置问题[5-8]。例如位置偏置, 它指的是用户倾向于点击展示位置靠前的物品[6]; 流行偏置, 它指的是系统倾向于向用户推荐流行度较高的物品, 也就是越受欢迎的物品越可能被推荐给用户[7]。除此之外, 还有选择偏置、曝光偏置等等, 这些偏置使得系统收集到的用户历史行为数据存在有偏性, 而现有的大部分推荐模型都只基于这样的有偏数据来构建。一些研究工作从理论和实验两方面说明, 忽略偏置问题会导致得到次优的推荐模型, 而解决这些偏置问题能够提高推荐模型的性能[5,9-11]。因此, 基于这样的背景, 本文重点研究了推荐系统中一元反馈的偏置问题, 旨在提出一种新的推荐模型。
为了缓解这一偏置问题, 本文引入了无偏数据,通过与有偏数据进行联合建模, 来获得更加精准的推荐模型。其中, 无偏数据指的是推荐系统通过采用随机的推荐策略而收集到的反馈数据, 因为推荐策略的随机性, 故可以被认为是不受偏置影响的[10-12]。有偏数据指的是推荐系统通过采用常规的推荐策略而收集到的反馈数据, 被认为是固有地受到偏置影响的。一般而言, 因为采用随机策略的推荐结果较差,会带来用户的流失和平台的损失, 所以无偏数据的收集规模通常都较小。因此, 如何有效地利用无偏数据是本文研究问题的挑战之一。除此之外, 有偏数据的规模比无偏数据大得多, 且由于推荐策略的不同导致有偏数据和无偏数据之间存在异构性, 如何有效地结合有偏数据和无偏数据进行联合建模是本文研究问题的另一个挑战。
先前的研究工作表明引入无偏数据可以有效缓解偏置的影响[10-11]。在文献[10]中, 作者提出了一种新的领域自适应算法, 通过正则化约束来纠正模型的参数, 从而达到消除偏置的目的。但是, 当模型参数维度较高时, 参数对齐较难训练, 使得模型不能取得很好的效果。在文献[11]中, 作者提出了一个新的基于知识蒸馏的框架, 并从四个不同层面提出了多种策略, 旨在通过利用无偏数据或由无偏数据训练的预训练模型来消除偏置, 但是作者只是简单地使用了某一种策略, 不能充分利用无偏数据中的信息。除此之外, 先前的大部分研究工作认为偏置隐式地反映在标签或者模型参数上, 并且只在标签或模型参数的层面上来缓解偏置问题[5,9-13], 很少有研究工作从特征的角度来解决偏置问题[14]。
因此, 根据研究问题的挑战和已有研究工作的局限, 本文提出了一种新的视角, 即从多任务学习的角度来解决偏置问题, 把有偏数据、无偏数据和联合数据当作三种相互关联的信号, 分别对应三个不同但相关的学习任务。其中, 联合数据指的是有偏数据和无偏数据的并集。目前在一元反馈问题中, 变分自编码器模型取得了非常好的推荐性能[15-16]。为此,本文基于变分自编码器提出了一个新的模型, 即三任务变分自编码器。该模型包含三个变分自编码器,分别对这三种数据进行重构。变分自编码器之间共享同一个编码器和同一个解码器。此外, 在三个任务之间, 本文设计了特征校正模块和标签增强模块来加强任务之间的关联。其中, 特征校正模块用于校正用户的潜在特征, 得到更无偏的潜在特征, 进而从潜在特征的角度来缓解偏置的影响。标签增强模块通过无偏数据训练的无偏模型来生成可靠性较高的伪标签并加以利用, 从而更有效地利用无偏数据中的信息。
本文的主要贡献如下:
1) 研究了推荐系统中的一个重要问题——一元反馈的偏置问题, 提出了一种新的解决方案, 将结合有偏数据和无偏数据的偏置消除问题建模成一个多任务学习问题, 即把有偏数据、无偏数据和联合数据当作三种不同但相互关联的数据, 并为此设计了一个新的三任务变分自编码器;
2) 提出了特征校正模块和标签增强模块, 其中,特征校正模块用于获得无偏的用户潜在特征, 进而从潜在特征的角度缓解偏置的影响, 而标签增强模块能够更加充分地利用无偏数据中的信息;
3) 在两个不同领域的真实数据集上进行了大量的实验, 结果表明, 相比于现有最新的解决偏置的推荐模型, 本文提出的模型取得了更好的推荐效果。
2 相关工作
2.1 面向推荐系统中一元反馈建模的方法
面向推荐系统中一元反馈建模的方法指的是通过一元反馈数据来学习用户和物品之间的关系, 为每个用户生成对应的个性化推荐列表。到目前为止,推荐系统中一元反馈方法大致可以划分为基于邻域的方法、基于分解的方法和基于神经网络的方法。
基于邻域的方法包括基于用户邻域的方法和基于物品邻域的方法。基于用户邻域的方法通过计算用户之间的相似度, 为每个用户找到最相似的用户集合, 并推荐与相似用户有交互而与用户本身未交互的物品[17-19]; 类似地, 基于物品邻域的方法则是计算物品之间的相似度, 为每个用户找到和他自身有交互的物品的相似物品, 并进行推荐[20-21]。常用的计算相似度的方法有余弦相似度、杰卡德指数和关联规则[22]等等。此类算法计算简单、可解释性较好,但无法学习用户与物品之间较为复杂的关系。
基于分解的方法的主要思想是构建低维度的数学模型来表示用户与物品之间的关系, 再通过训练数据来学习模型的参数。比较有代表性的工作有贝叶斯个性化排序[23]、分解的物品相似度模型(Factored Item Similarity Models, FISM)[24]和对数几率矩阵分解(Logistic Matrix Factorization, LMF)[25]。贝叶斯个性化排序采用成对的思想来构建形如三元组( u , i ,j)的训练数据, 并认为用户u 对i 的喜欢程度大于j,其中u 表示用户, i 表示与用户u 有交互的物品, j表示与用户u 没有交互的物品。结合基于矩阵分解的思想, 即使用两个维度更小的矩阵来表示用户和物品的潜在特征, 通过使用三元组数据进行训练, 学习用户和物品的潜在特征。分解的物品相似度模型(FISM)创新性地提出物品之间的相似度可以通过学习得到, 并通过构建物品的潜在特征向量, 利用训练数据来学习用户对物品的偏好程度。类似地, 对数几率矩阵分解(LMF)结合矩阵分解的思想, 并利用对数几率损失函数来拟合数据, 学习用户和物品的潜在特征。此类方法能够有效学习用户与物品之间的线性关系, 但无法学习它们之间更为复杂的非线性关系。
基于神经网络的方法在近几年才被提出, 通过利用深度学习技术来学习用户与物品之间的高维度关系, 弥补了以往算法无法学习它们之间非线性关系的缺陷[16,26-27]。此类方法包括基于多层感知器的方法和基于自编码器的方法, 其中比较有代表性的工作有神经协同过滤(Neural Collaborative Filtering,NCF)[26]和变分自编码器(Variational Autoencoder,VAE)[16]等。神经协同过滤(NCF)使用多层感知器代替原本用户和物品潜在特征之间的点乘操作, 从而实现非线性交互。此外, NCF 将矩阵分解和多层感知器统一在同一个框架下, 结合了它们之间的优势,同时捕获用户和物品的潜在特征之间的线性和非线性交互。变分自编码器(VAE)是目前在一元反馈建模方法中推荐性能最好的方法之一。它首先将用户与物品的交互记录编码成变分概率分布, 并使用多项式似然来模拟一元反馈数据的生成过程, 对原始输入数据进行重构。区别于以往的研究工作, 变分自编码器学到的是用户潜在特征的概率分布, 而不是用户潜在特征的点值, 这也是该算法取得非常突出的性能的主要原因。
2.2 面向推荐系统中有偏反馈建模的方法
推荐系统中偏置消除问题起步较晚, 近几年才逐渐被学术界和工业界重视。目前偏置消除的方法大致可以分为基于反事实学习的方法、基于启发式的方法和基于无偏数据增强的方法[11]。
基于反事实学习的方法主要是从因果推理的角度来缓解偏置问题, 目前其中一个主流的方法是引入逆倾向性得分(Inverse Propensity Score, IPS)评估器, 即给每一个观测到的样本都赋予一个倾向性得分, 从而学习一个更无偏的模型[9,28-29]。此类方法需要根据一些假设来设计倾向得分评估器, 因为真实的倾向性得分是无法求得的, 从而导致此类方法的准确性和稳定性取决于评估方法本身。在文献[28]中, 作者通过引入曝光概率, 根据物品的流行度来计算每个样本的倾向性得分。在文献[29]中, 作者通过神经网络模型来学习样本的倾向性得分。但是, 这些倾向性得分的评估方法容易出现高方差等缺点,为了缓解这一问题, 在文献[30]中, 作者提出了双稳健(Doubly Robust, DR)评估器, 利用插补模型来提高模型的稳定性。除此之外, 在文献[13]中, 作者提出了一个非对称训练框架, 利用两个模型来产生更具无偏性的伪标签, 以此加强第三个模型的训练。但该方法的有效性取决于伪标签的准确性, 而伪标签的生成又受限于超参数的设置。在文献[31]中, 作者建立了有关流行偏置产生的因果图, 认为用户对物品的反馈和用户与物品之间的匹配程度、物品的流行度和用户的活跃度有关, 并为此设计了一个多任务学习框架。但该方法仅用于解决流行偏置问题, 具有一定的局限性。
基于启发式的方法目前较少, 其主要思路是通过分析造成偏置的原因并作适当的假设, 以此达到消除偏置的目的。但是偏置往往较为复杂, 并不是由单一因素造成的, 所以采用此类方法来解决偏置是也是比较困难的。在文献[32]中, 作者假设推荐系统中偏置的产生和沉默的螺旋理论有关, 并提出了一种模拟沉默螺旋产生的概率模型。
基于无偏数据增强的方法通过引入无偏数据,对有偏数据和无偏数据进行联合建模, 从而达到解决偏置问题的目的[10-11,33-35]。此类方法是目前稳定性和准确性较好的方法, 因为与上述方法相比, 此类方法引入了更多真实的无偏信息。在文献[34-35]中,作者利用无偏数据来协助倾向性得分的计算, 得到更加稳定且准确的倾向性得分。同样地, 此类方法也受限于倾向性得分评估方法的准确性。在文献[10]中, 作者认为偏置的产生可以通过模型参数来进行纠正并提出了CauseE 算法, 通过引入额外的正则化项来约束有偏模型和无偏模型的参数。其中, 有偏模型是指使用有偏数据进行训练得到的模型, 而无偏模型是指使用无偏数据进行训练得到的模型。然而,当模型参数的维度较高时, 参数对齐本身也是一个较难的问题。在文献[11]中, 作者提出了一个基于知识蒸馏的框架, 即利用无偏数据训练得到一个无偏模型, 从蒸馏的角度提取无偏模型中的有效信息,进而和有偏数据进行联合训练来消除偏置的影响。但是, 该方法没有充分利用无偏数据中蕴含的信息,因为仅仅是简单地使用了某一种策略。在文献[33]中, 作者先利用无偏数据训练得到因果迁移随机森林模型, 接着再利用有偏数据和无偏数据进行校正。该方法主要用于解决位置偏置问题, 且模型复杂度较高。因此, 为了更好地利用无偏数据中的信息, 本文从多任务学习的角度出发, 联合有偏数据和无偏数据进行建模, 并设计了特征校正模块和标签增强模块来缓解偏置问题。
3 问题描述
3.1 定义
本文使用 U = {u } = {1 ,2,… ,n}表示所有用户的集合, I = {i} = {1 ,2, …,m}表示所有物品的集合,SA= {( u ,i)}和 ST= {( u ,i)}表示包含这些用户对物品的一元反馈的两个日志数据。其中, SA是系统使用常规的推荐策略进行推荐时产生的, 具有规模较大和相对有偏的特点; ST是系统使用随机的推荐策略进行推荐时产生的, 具有规模较小和相对无偏的特点。本文使用 XA∊{0 ,1}n×m和XT∊{0 ,1}n×m分别表示由SA和ST构成的用户与物品的交互矩阵。此外, 本文使用SC表示联合数据, 即SC= SA∪ST,以及 XC∊{ 0,1}n×m表示由SC构成的用户与物品的交互矩阵。本文的目标是在给定有偏数据SA和无偏数据ST的前提下, 如何对它们进行联合建模来缓解偏置问题, 从而获得一个更加精准的个性化推荐模型。
3.2 挑战
本文研究的问题存在以下三个挑战:
1) 通常情况下, 无偏数据的规模较小。为了尽可能地减少偏置的影响, 从推荐系统中收集无偏数据需要采用随机的推荐策略。然而, 采用随机策略的推荐结果往往很差, 这不仅会降低用户的体验, 而且会导致系统带来的收益大幅下降。因此, 为了尽可能地减少损失, 无偏数据的收集过程不会持续很久,从而使得其数据规模是较为有限的。
2) 有偏数据和无偏数据的规模差别较大, 有着严重的不平衡性。不同于无偏数据, 获取有偏数据是相对容易的, 从而导致了它们之间的数据规模的不一致性。
3) 有偏数据和无偏数据具有异构性, 因为它们分别是由两组不同性质的推荐策略产生的, 导致用户对物品的反馈所代表的偏好信息有所不同。在有偏数据中, 用户对物品的反馈不一定是因为用户喜欢物品, 有可能是受到了偏置的影响; 而在无偏数据中, 这通常表示用户喜欢相应的物品。
4 三任务变分自编码器
4.1 概述
针对上述挑战, 本文从一个新的角度对有偏数据和无偏数据进行联合建模, 将有偏数据SA、无偏数据ST和联合数据SC看作3 种不同但相互关联的信号, 分别用于学习不同的用户偏好, 并基于变分自编码器, 提出了一种新的推荐模型, 即三任务变分自编码器(Tri-VAE), 如图1 所示。Tri-VAE 包含了3 个子模型, 分别记为MA、MT和MC。它们的作用分别是对SA、ST和SC进行重构。在这个3 个子模型中, MC作为目标子模型, 其预测输出作为最终的推荐结果, 而另外两个子模型作为辅助子模型。3个子模型之间通过以下两个方面进行关联, 一是它们共享同一个编码器和同一个解码器, 二是MA和MT通过特征校正模块(Feature Calibration Module,FCM)和标签增强模块(Label Enhancement Module,LEM)来协助MC的学习。其中, 特征校正模块指的是利用MA和MT的用户潜在特征来校正MC的用户潜在特征, 以获得更无偏的用户潜在特征; 标签增强模块则是进一步利用MT的预测输出来训练MC, 因为MT是重构无偏数据, 可以认为是相对无偏的模型, 其预测输出包含了较为丰富的无偏信息。
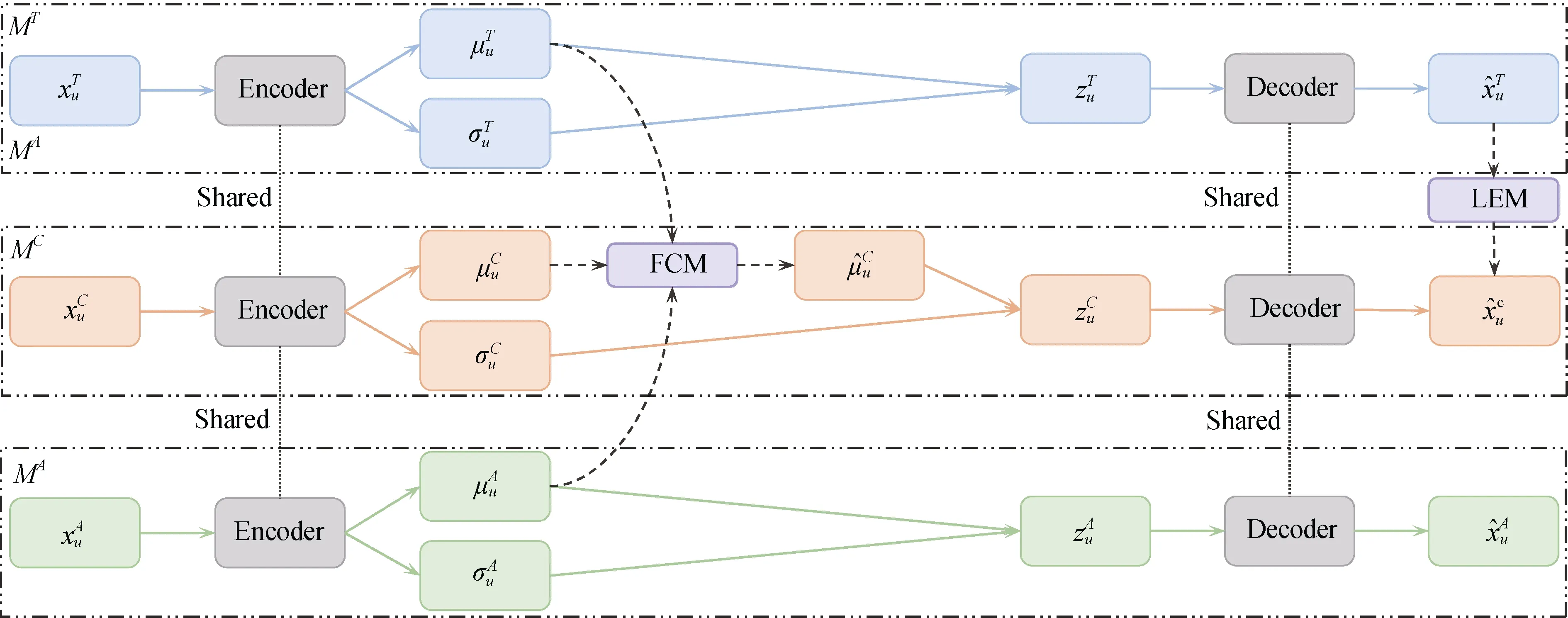
图1 三任务变分自编码器模型架构。该模型包含三个子模型, 分别是MA 、MT 和MC , 其中MC 作为目标子模型, 旨在产生更精准的推荐结果。三个子模型之间共享同一个编码器和同一个解码器, 并通过特征校正模块(Feature Calibration Module, FCM)和标签增强模块(Label Enhancement Module, LEM)进行关联Figure 1 llustration of tri-task variational autoencoder (Tri-VAE). It contains three sub-models of MA , MT and MC , where MC is used as the target sub-model to produce more accurate recommendation results. The three sub-models share the same encoder and decoder, and are associated through the feature calibration module (FCM)and the label enhancement module (LEM).
4.2 有偏数据重构
在Tri-VAE中, 子模型MA的作用是重构有偏数据SA。该子模型是变分自编码器, 其模型结构和Mult-VAE[16]一样, 包含编码器和解码器。其中, 编码器是推理模型, 将输入数据通过多层感知器压缩成用户潜在特征的变分分布, 得到均值和标准差; 解码器则是生成模型, 从用户潜在特征的变分分布中随机采样, 通过多层感知器对原始输入数据进行重构。在子模型MA中, 使用∊R1×k表示用户潜在特征,∊R1×k和∊R1×k分别表示用户潜在特征的变分分布的均值和标准差, 其中k 指的是用户潜在特征的维度。由XA可以得到每个用户与所有物品产生的交互向量, 记为∊{ 0,1}1×m, 并将其作为编码器的输入, 通过多层感知器可以得到用户潜在特征的变分分布qφ(|), 从该变分分布随机采样可得到, 进而有
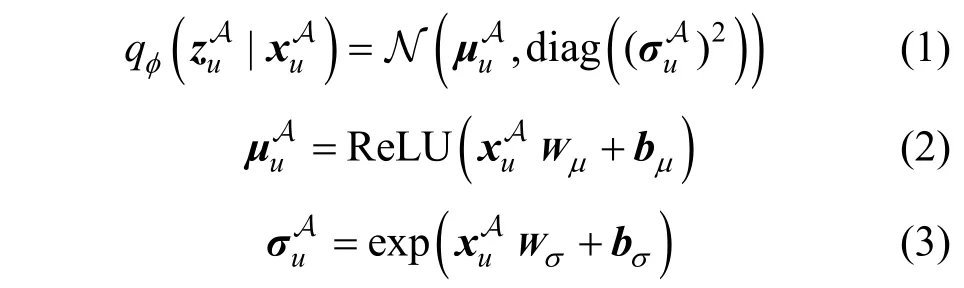
其 中, Wμ∊Rm×k和 Wσ∊Rm×k指 的 是 权 重 矩 阵,bμ∊R1×k和 bσ∊R1×k指的是偏置向量。
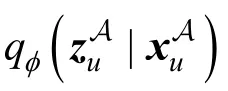
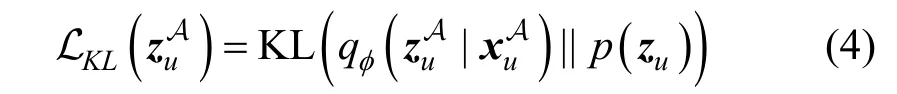
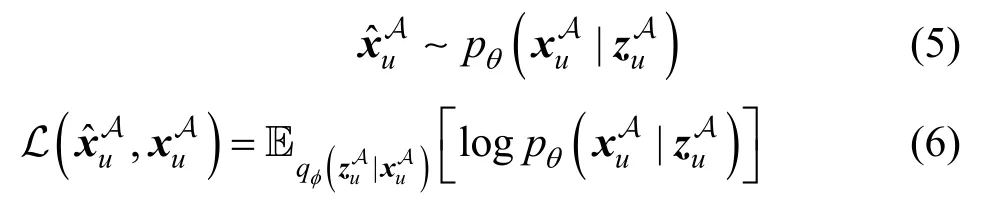
根据以上描述, 可以得到子模型MA总的损失函数, 即

其中, β 是超参数。
4.3 无偏数据重构
在Tri-VAE中, 子模型MT的作用是重构无偏数据ST。该子模型的模型结构和MA一样, 具有相同的编码器和解码器。在子模型MT中, 使用∊R1×k表示用户的潜在特征,∊R1×k和∊R1×k分别表示用户潜在特征的变分分布的均值和标准差。在给定XT的情况下, 可以得出每个用户和所有物品产生的交互向量, 记为∊{ 0,1}1×m。具体而言, 将的潜在特征的变分分布并由该分布随作为MT的输入,通过多层感知器可以得到用户机采样得到, 即
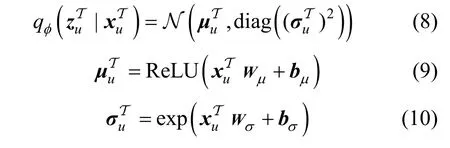

其中, β 是超参数。
4.4 联合数据重构
在Tri-VAE 中, 子模型MC的作用是重构联合数据SC, 即同时重构SA和ST。与MA和MT一样, 该子模型也是变分自编码器, 有着相同的编码器和解码器。在子模型MC中, 使用∊R1×k表示用户的潜在特征,和分别表示用户潜在特征的变分分布的均值和标准差。由XC可以得出每个用户和所有物品产生的交互向量, 记为。将作为MC的输入, 通过多层感知器来得到用户潜在特征的变分分布, 并由该分布随机采样得到, 即有


从信息的角度来看, 联合数据是由有偏数据和无偏数据组成的, 那么它所包含的信息是最丰富的,故在Tri-VAE 中, 将MC作为目标子模型。然而, 因为有偏数据和无偏数据的规模不同, 有偏数据占据了大部分。因此, 为了获得更精准的无偏的个性化推荐模型, MC应当有效地缓解偏置的影响。然而, 偏置本身是隐蔽的, 无法直接通过某种测量方式来衡量, 所以只能从间接的角度来解决这一问题。
先前的大部分研究工作认为偏置隐式地反映在标签或模型参数上[5,9-13], 并从标签的角度或从模型参数的角度上来缓解偏置的影响。很少有研究工作从特征的角度、潜在特征的角度、或结合多个角度来解决偏置问题。
受潜在特征的性质的启发, 不同类型的数据所对应的潜在特征不同。故本文从潜在特征的角度来缓解偏置问题, 即认为偏置实际上隐藏在用户的潜在特征中。也就是说, 由子模型MA和MC得到的和是相对有偏的, 而子模型MT得到的是相对无偏的。因为是从有偏数据学习得到的, 而是从无偏数据学习得到的。对于而言, 尽管它是从联合数据学习而来, 但联合数据中大部分都属于有偏数据。那么此时, 可以通过衡量,和的之间的差异来间接地缓解偏置的影响。因此,基于这样的动机, 本文设计了一个特征校正模块(Feature Calibration Module, FCM), 即以为基准,利用和之间的差异来消除中的偏置特征,从而获得无偏的用户潜在特征。

其中, d ∊R1×k指的是和的差异。

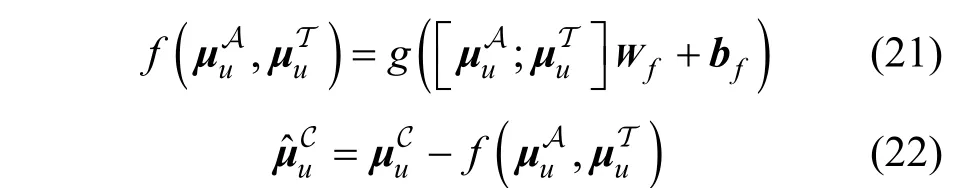
其中, g (∙)指的是一个具体的激活函数, Wf∊R2k×k和 bf∊R1×k分别是特征校正模块的权重矩阵和偏置向量。
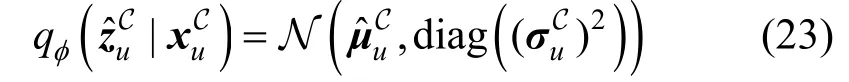
在子模型MC中, 本文使用表示由解码器生成的用户和所有物品产生的交互向量, 其计算公式如(24)所示。之后再通过最小化重构损失函数来优化模型。但不同于子模型MA和MT直接对输入的数据进行重构, 子模型MC在重构过程中, 并没有直接让和尽可能地接近, 而是对有偏数据SA和无偏数据ST作了区别对待。理想情况下, MC的输出应当更接近无偏, 而SA本身是有偏的。受偏置信息反映在标签上的启发, 如果直接对SA进行重构可能会影响模型最后的推荐性能。因此, 借鉴文献[11]中的Weight 策略的思路, 本文在重构SA时设置置信度来控制, 以保证模型的无偏性。具体而言, 本文为重构的损失函数设置了权重 α ∊ ( 0,1), 而将重构的损失函数的权重设置为1, 即有
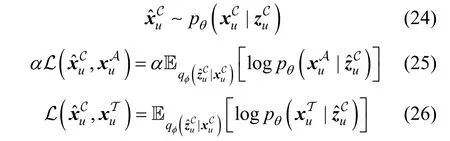
另外, 在本文提出的Tri-VAE 中, 由于MT是在重构无偏数据, 故MT的预测输出可以被认为是相对无偏的标签。受文献[11]中的启发, MT的预测输出包含了较为丰富的无偏信息。因此, 为了加强对无偏数据中的信息的利用, 借鉴于文献[11]中的Bridge策略的思路, 本文设计了一个标签增强模块(Label Enhancement Module, LEM), 旨在训练过程中加强利用MT的预测输出。
算法1. 三任务变分自编码器的训练过程
输入:用户与物品的交互矩阵XA、XT和XC,用户总数n, 物品总数m, 潜在特征维度rank, 正则化项权重λ, 重构损失函数权重α 和γ , KL 约束项权 重 β , dropout rate ρ , 最 大 迭 代 次 数iteration number, 学习率learning rate, 一次训练所选取的样本数batch size
输出:编码器φ, 解码器θ , 特征校正模块FCM
1. 随机初始化编码器φ, 解码器θ 和特征校正模块FCM
2. FOR iter = 1:iteration number DO
3. 从D 中随机采样和SA规模大小一样的(用户,物品)对, 并对用户ID 和物品ID 进行标记
4. 根据n 和batch size, 按照用户ID 顺序分成多个batches
5. FOR batch = 1: length(bacthes) DO
6. FOR 对于batch 中的所有用户 DO
7. 分别从XA、XT和XC取出用户u 对应的交互向量、和
14. 根据公式(5)、(12)和(24)重构输入数据, 即、和
16. 根据公式(29)求出总的损失函数 LTri-VAE, 进而求出梯度
17. END FOR
18. 对batch 中所求出的所有梯度进行平均
19. 对编码器φ, 解码器θ 和特征校正模块FCM进行更新
20. END FOR
21. END FOR
22. RETURN 编码器φ, 解码器θ 和特征校正模块FCM
本文使用D 表示所有用户和物品交互的集合,包括可观测到的和不可观测到的(用户, 物品)对。在训练过程中, 每一次迭代都从D 中随机采样和SA规模大小一样的(用户, 物品)对, 再利用MT对这些(用户, 物品)对进行预测得到相应的伪标签, 即用户对物品的反馈。本文将这一个伪数据集记为。另外, 本文使用∊{ 0,1}1×m表示由S~T 得到的每个用户和所有物品产生的交互向量。本文期望MC的预测输出和尽可能地接近, 为此构造了它们之间的重构损失函数, 如公式(27)所示。类似地, 本文在该重构损失函数设置了权重 γ ∊ ( 0,1), 因为无偏数据规模通常较小, 不足以让无偏模型MT得到充分的训练, 所以中的伪标签不一定都是正确的。因此, 为了解决这一问题, 本文设置了权重γ加以调整。
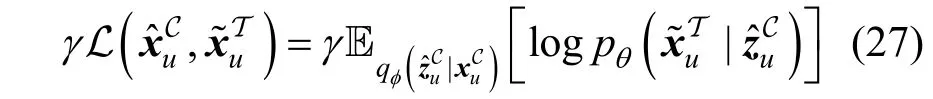
根据以上描述, 可以得到子模型MC总的损失函数, 即
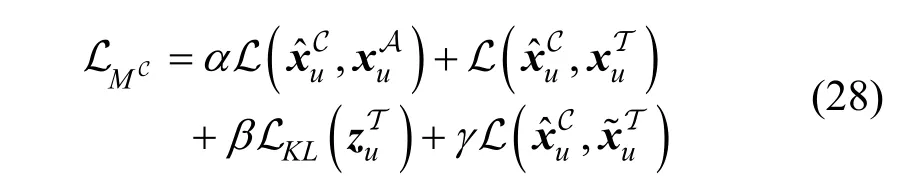
其中, α , β 和γ 都是超参数。
4.5 优化
结合以上所有描述, 本文采用联合训练的方式来训练模型, 并采用批量梯度下降(BGD)来最小化各个子模型的损失函数之和, 即
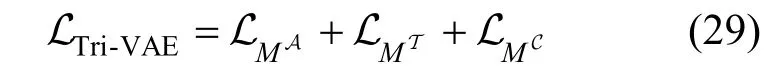
另外, 整个模型的训练过程如算法1 所示。
5 实验结果与分析
5.1 数据集
本文对解决偏置问题的有效性进行评估, 故所采用的数据集必须包含无偏数据。目前已公开的数据集只有两个, 即Yahoo! R3[38]和Coat Shopping[9],关于它们的具体信息如表1 所示。

表1 实验所采用的数据集的统计信息。其中“#Feedback”指的是反馈样本的数量, “P/N”指的是数据集中正反馈和负反馈的比例Table1 Statistics of the datasets used in the experiments. Notice that #Feedback denotes the number of feedback samples and P/N denotes the ratio between the numbers of positive feedback and negative feedback
· Yahoo! R3[38]: 这是一个关于用户对音乐评分的数据集, 包含了一个有偏的常规数据子集和一个无偏的随机数据子集。其中, 常规数据子集包含15400 个用户, 1000 首歌曲和大约30 万条评分记录, 评分范围是{1,2,3,4,5}。常规数据子集是由系统使用常规的推荐策略进行推荐, 用户根据自身选择来对歌曲进行评价而收集到的, 故被认为是有偏的。随机数据子集是通过要求前5400 个用户对10 首随机选择的歌曲进行评分收集而来的, 故被认为是无偏的。因为本文研究的问题是一元反馈的偏置问题, 故需将评分转换成一元反馈。因此, 本文对数据集进行了预处理。如果评分大于3 分, 那么该记录被认为是正反馈[10-11], 即 rui= 1。在实验中,本文将常规数据子集作为有偏数据(SA), 并将随机数据子集随机划分成3 个子集, 其中10%作为目标训练的无偏数据(ST), 10%作为验证集用以选择超参数, 最后的80%作为测试集用以评估模型的性能。
· Coat Shopping[9]: 这是一个关于用户对外衣(coat)评分的数据集, 是通过让Amazon Mechanical Turk 平台上的290 用户对300 件外衣进行评分收集而来的。和Yahoo! R3 一样, 该数据集包含了一个有偏的常规数据子集和一个无偏的随机数据子集。其中, 常规数据子集是用户根据自身选择来对外衣进行评价而收集的, 大约有7000 条评分记录, 评分范围是{1,2,3,4,5}, 被认为是有偏的。随机数据子集是通过要求所有用户对16 件随机选择的外衣进行评分收集的, 被认为是无偏的。常规数据子集和随机数据子集的预处理及划分方式和Yahoo! R3 一样。
5.2 评价指标
为了评估模型的推荐性能, 本文采用推荐系统中常用的评价指标进行评估, 包括ROC(Receiver Operating Characteristic, ROC)曲线下的面积(Area Under Roc Curve, AUC)、归一化折损累积增益(Normalized Discounted Cumulative Gain, NDCG)、精确率(Precision@N, P@N)和召回率(Recall@N, R@N)4 个指标, 各个指标的定义如下所示。其中, 在实验过程中, N 设置为10、20 和50。另外, 在实验过程中, 本文将AUC 作为主要指标, 其他作为参考指标[10-12]。
下面对4 个指标的定义进行一一阐述。
· ROC 曲线下的面积(AUC): 其计算公式如下所示
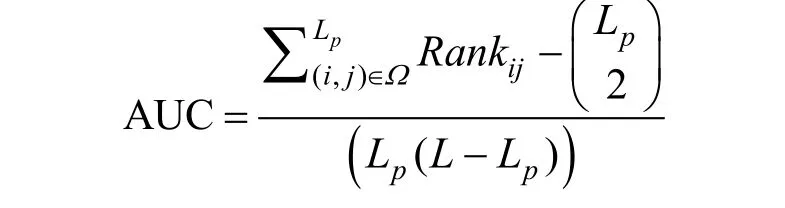
其中, Ω 指的是测试集上(在选择参数过程中为验证集)的所有正反馈的集合, Lp指的是Ω 中正反馈的总数, Rankij指的是根据预测结果进行降序排列得到的正反馈(i , j) 在所有的反馈中的排序位置, L 指的是在测试集上(在选择参数过程中为验证集)的反馈总数, 包括正反馈和负反馈。
·归一化折损累积增益(NDCG): 其计算公式如下
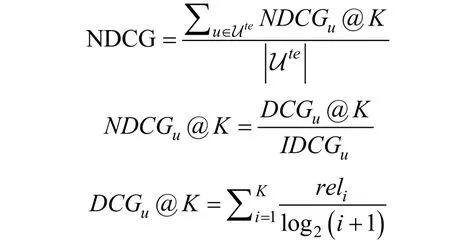
其中, Ute指的是测试集上(在选择参数过程中为验证集)的用户集合, NDCGu@K 指的是用户u 的归一化折损累积增益, DCGu@K 指的是用户u 的折损累积增益, IDCGu指的是理想情况下用户u 的折损累积增益, 即根据返回的结果, 按照真实的相关性重新排序, 进而计算 DCGu@K 得来的, K 指的是推荐列表的长度, reli指的是推荐物品的相关性。在实验过程中, K 设置为50。
· 精确率(P@N): 其计算公式如下
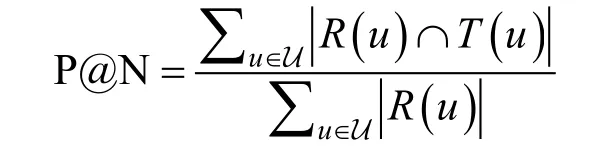
其中, R ( u )指的是模型给用户生成的长度为N 的推荐列表, T ( u )指的是用户在测试集上(在选择参数过程中为验证集)的反馈形成的推荐列表。
· 召回率(R@N): 其计算公式如下
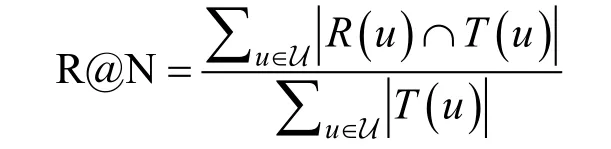
其中, R ( u )指的是模型给用户生成的长度为N 的推荐列表, T ( u )指的是用户在测试集上(在选择参数过程中为验证集)的反馈形成的推荐列表。
5.3 基线模型
本文提出的模型是在VAE的基础上进行改进的,故将VAE 作为最相关的基线模型。不同类型的数据进行训练会产生不同版本的VAE。在本文中, 有以下3 个版本, 即分别使用有偏数据SA、无偏数据ST和联合数据SC进行训练, 本文将它们依次记为VAE(SA)、VAE(ST)和VAE(SC)。除此之外, 本文还将近年来提出的具有代表性的方法作为基线模型,分别是基于逆倾向性得分的模型(IPS)[9,28-29]、CausE[10]和KDCRec[11]。
· 基于逆倾向性得分的模型(IPS)[9,28-29]: 基于逆倾向性得分消除偏置的算法是目前学术界比较主流的方法, 通过对训练集中的每个样本赋予一个倾向性得分, 从而来训练一个无偏的模型。倾向性得分的计算方法有很多[13,28-29], 本文采用的是其中一个具有代表性的方法, 即朴素贝叶斯评估方法。该方法通过朴素贝叶斯来计算物品的曝光概率, 以此得到每个样本的倾向性得分, 具体计算公式如下:
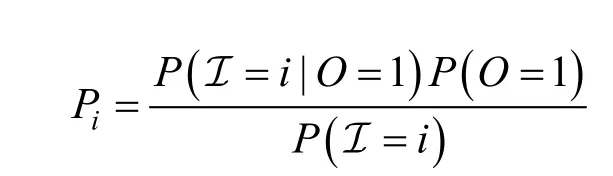
其中, P( I=i |O =1)指的是在可观测到的样本中,所有用户对物品i 产生交互的样本所占的比例;P (O = 1)指的是在全部样本中(包括未观测样本), 可观测的样本所占的比例; P( I=i)指的是在无偏数据中,所有用户对物品i 产生交互的样本所占的比例。另外,为了实验的公平性, 本文使用VAE 作为基本模型。
· CausE[10]: 其思想是通过正则化项来约束有偏模型和无偏模型的参数, 进而缓解偏置的影响。首先通过无偏数据进行训练得到无偏模型,接着使用有偏数据训练新的模型, 同时以无偏模型的模型参数作为参考, 使用正则化项进行约束。同样地, 为了公平比较, 本文使用VAE作为CasuE 的基本模型。
· KDCRec[11]: 一个基于知识蒸馏的框架。作者在文中提出了多种策略, 其中最具有代表性的策略是Bridge 策略。因为从作者提供的实验结果来看, 使用Bridge 策略训练出来的模型的推荐性能表现最佳。因此, 本文采用Bridge 策略作为基线模型之一。类似地, 为了公平比较,本文使用VAE 作为基本模型。
5.4 实验设置
本文使用Python 3.6 和TensorFlow 1.14 进行实验, 模型训练和测试都是在搭载了Ubuntu18.04 系统的计算机集群上进行的。该集群包含2 个26 核的CPU, 256GB 内存和2 个Nvidia Tesla P100 GPU。在Tri-VAE 中, 对于特征校正模块中的激活函数 g(∙),本文采用了tanh 函数和sigmoid 函数。本文使用网格搜索的方式对超参数进行搜索, 并通过验证集上AUC 的值来确定最佳的超参数。其中, 超参数的设置范围如表2 所示。另外, 对于Coat Shopping 数据集, 由于验证集的规模较小, 为了让实验结果更具有说服力, 在选参的过程中, 先使用网格搜索的方式进行搜索, 再选择在验证集上AUC 性能最好的前5 组参数, 让每组参数运行5 遍, 最后选择平均性能最好的那组参数作为最佳的超参数。此外, 在模型评估过程中, 本文通过改变随机种子, 对每个模型分别进行10 次训练和测试, 最后将平均值作为最终的测试结果。同时, 本文还使用双样本t 检验对各个指标进行了显著性检验, 即在各个指标上检验比较本文提出的模型的结果和最好的基线模型的结果。本文所涉及的实验数据、源代码和脚本将会公开, 可从http://csse.szu.edu.cn/staff/panwk/Tri-VAE/获得。
5.5 实验结果分析
5.5.1 性能比较
对于数据集Yahoo! R3和Coat Shopping, 本文提出的模型Tri-VAE 和基线模型的推荐性能比较如表3和表4 所示。其中, Tri-VAE-tanh 表示特征校正模块使用tanh 函数作为激活函数, Tri-VAE-sig 表示特征校正模块使用sigmoid 函数作为激活函数。从实验结果可以看出: (1)不管是Yahoo! R3 还是Coat Shopping,在绝大多数情况下, Tri-VAE 的推荐性能比所有基线模型都要好。注意AUC 是最关键的指标, 且模型参数是通过AUC 进行选择的。另外, 本文通过双样本t 检验进行了显著性检验, 发现大部分指标的p 值都小于0.01。这说明本文所提出的模型能够更好地对有偏数据和无偏数据进行联合建模, 有效地利用无偏数据中的信息来缓解偏置带来的影响; (2)对于本文提出的特征校正模块, 使用不同的激活函数对最终的推荐性能有一定的影响。从主要指标来看, 在Yahoo! R3 上, tanh 函数的推荐性能更好, 而在Coat Shopping 上, 则是sigmoid 函数的性能更好。造成这种差异的原因可能是不同的激活函数所提取到的偏置信息有所不同, 而这两个数据集包含的偏置信息存在一定的差异; (3)关于使用不同类型的数据进行训练产生的 3 个版本的 VAE, 其实验效果是VAE(SC)> VAE(SA)> VAE(ST), 这说明有偏数据和无偏数据之间具有互补性。而本文提出的Tri-VAE比这三个基准模型的效果都要好, 说明Tri-VAE能更好地对有偏数据和无偏数据之间的互补性进行建模;(4)IPS-VAE 的实验效果比较差, 这说明本文中所采用的利用无偏数据和朴素贝叶斯法来计算倾向性得分并不能很好地解决偏置问题; (5)CausE 和KDCRec的实验效果比VAE(SA)要好, 但比VAE(SC)差, 这是因为这两个基线模型都需要利用单独使用无偏数据得到的预训练模型, 而由于无偏数据的规模较小,导致预训练模型不能得到充分的训练。
5.5.2 消融实验
为了进一步研究Tri-VAE, 本文设计了消融实验。在本文所提出的模型中, 子模型之间通过特征校正模块和标签增强模块进行关联。简而言之, 通过利用、和的信息来协助目标子模型MC的训练。因此, 本文首先一一去除、和中的一个, 分别记为“-T”, “-A” 和“-P”, 接着再去除它们之间的组合, 包括同时去除和(记为“-TA”), 以及同时去除、和(记为“-TAP”)。从表3 和表4 的分析来看, 在Yahoo! R3 上采用tanh函数的推荐性能更好, 而在Coat Shopping 上则是采用sigmoid 函数。因此, 为了实验的公平性, 在Yahoo!R3 上的消融实验选择tanh 函数作为激活函数, 在Coat Shopping 上的消融实验则选择sigmoid 函数作为激活函数, 具体的实验结果如图2 所示。从实验结果可以看出, 去除Tri-VAE中的某一部分或者同时去除某几部分, 都会使推荐性能变差。其中, 去除之后, 模型的推荐性能小幅度下降, 而去除或者之后, 模型的推荐性能大幅度下降。这说明特征校正模块在Tri-VAE 中起到了重要的作用, 而标签增强模块是辅助作用, 同时也验证了从潜在特征的角度来缓解偏置的有效性。另外, 对于特征校正模块和标签增强模块对推荐性能的作用程度不同, 这是因为特征校正模块是直接对用户的潜在特征进行校正, 而标签增强模块通过标签增强的方式间接地对用户的潜在特征进行校正。
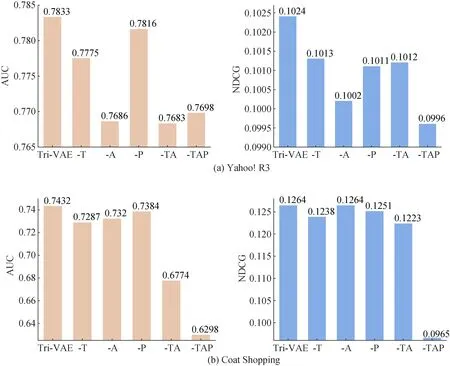
图2 消融实验中推荐性能的比较Figure 2 Recommendation performance in ablation studi es
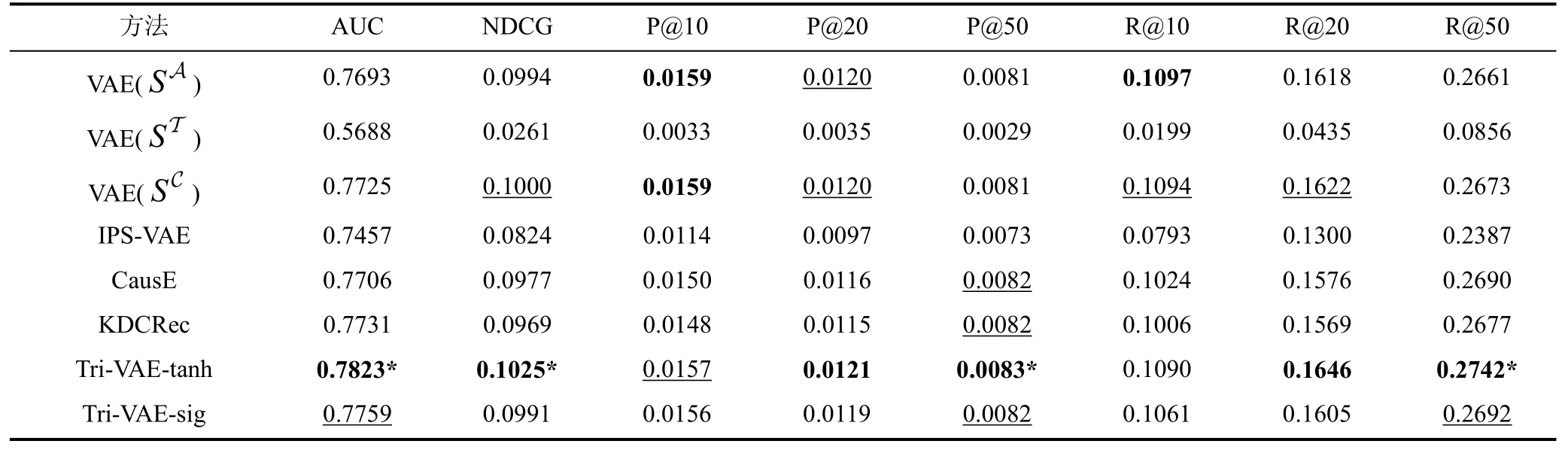
表3 在数据集Yahoo! R3 上, 本文提出的模型和基线模型的推荐性能比较, 其中最佳结果用粗体标记, 次优结果用下划线标记。另外, 显著性检验中p 值小于0.01 的最佳结果用星号(*)标记Table 3 Recommendation performance of our proposed model and the baselines on Yahoo! R3, where the best results are marked in bold and the second best results are marked underlined. In addition, the significantly best results are marked with a star (*), where the p-value is smaller than 0.01

表4 在数据集Coat Shopping 上, 本文提出的模型和基线模型的推荐性能比较, 其中最佳结果用粗体标记, 次优结果用下划线标记。另外, 显著性检验中p 值小于0.01 的最佳结果用星号(*)标记Table 4 Recommendation performance of our proposed model and the baselines on Coat Shopping, where the best results are marked in bold and the second best results are marked underlined. In addition, the significantly best results are marked with a star (*), where the p-value is smaller than 0.01
5.5.3 超参数敏感性分析
本文所提出的模型引入了两个主要的超参数,分别是α 和γ , 因此本文设计了以下实验对超参数进行分析。首先, 为了分析α , 先固定其他超参数,α 值依次从0.1变化到0.6, 重新训练并测试模型, 最后的实验结果如图3 所示。从图3 可以看出, 最优的α 值在数据集Yahoo! R3 和Coat Shopping 上分别是0.1 和0.5。α 值的大小可能和有偏数据与无偏数据的数据规模之比(即|SA|/|ST|)有关系。因为有偏数据与无偏数据规模差异直接影响到对SA的重构损失函数与对ST的重构损失函数的差异。当有偏数据规模较大时, 对SA的重构损失函数的影响相对会大一些, 此时为了削弱SA的重构损失函数的影响, α值就应当相对小一些。接着分析γ , 类似地, 先固定其他超参数, γ 值依次从0.0001 变化到0.1, 重新训练并测试模型, 最后的实验结果如图4 所示。从图4 可以看出, 最优的γ 值在数据集Yahoo! R3 和Coat Shopping 上分别是0.001 和0.0001, γ 值越大, 最终的推荐性能越差。这和无偏数据的数据规模有关。尽管通过无偏数据可以训练得到相对比较无偏的模型, 但由于无偏数据的规模较小, 较难充分训练得到一个很准确的预测结果, 也就是说, 标签增强模块产生的伪标签的可信度不会很高, 故γ 值不会很大。
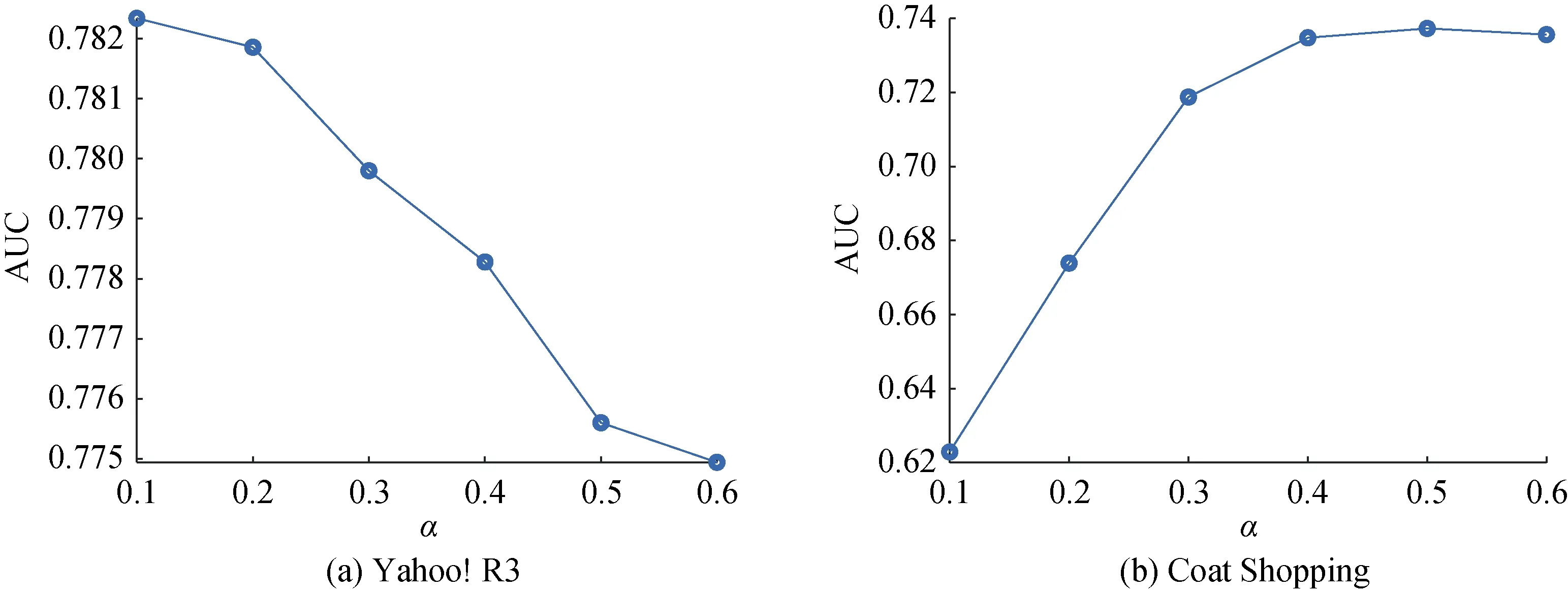
图3 不同α 值对推荐性能的影响Figure 3 Recommendation performance of our proposed model with different values of α

图4 不同γ 值对推荐性能的影响Figure 4 Recommendation performance of our proposed model with different values of γ
5.5.4 模型的收敛性分析
为了进一步分析本文提出的模型Tri-VAE 的收敛性, 本文进行了实验验证。通过5.5.1 节的实验结果可知, 在众多的基线模型中, VAE(SC)的模型性能最好, 同时VAE 也是与Tri-VAE 最相关的基线模型。因此, 本文通过分析Tri-VAE 和VAE(SC)这两个模型在训练时总的损失和验证集上的AUC 随迭代次数的变化情况来验证模型的收敛性。具体实验结果如图5 所示。从实验结果可以看出, 本文提出的模型的收敛性较好, 收敛速度不会随着模型复杂度的增加而减缓。首先, 在Yahoo! R3 数据集上, Tri-VAE 和VAE(SC)在训练时总的损失的收敛趋势较为相近。而对于验证集上的AUC, Tri-VAE 的收敛性要优于VAE(SC)。其次, 在Coat Shopping 数据集上, 与Yahoo! R3 数据集上的结果类似, Tri-VAE 和VAE(SC)在训练时总的损失的收敛性相当。而在验证集上的AUC, 却表现出了不一样的结果。通过比较发现, VAE(SC)出现了过拟合的现象, 即在训练集上总的损失越来越小, 但验证集上的AUC 却在变差。而本文提出的模型(Tri-VAE-sig)不仅能够正常收敛, 而且没有出现过拟合的现象。
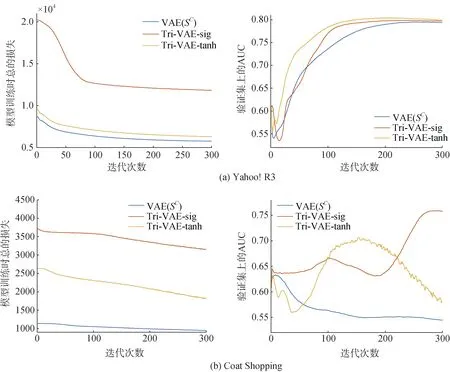
图5 模型训练时总的损失和验证集上AUC 随迭代次数的变化情况Figure 5 Variation of the total loss when training the model and the AUC on the validation set with the number of iterations
5.5.5 关于特征校正模块的进一步探讨
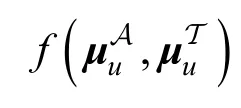
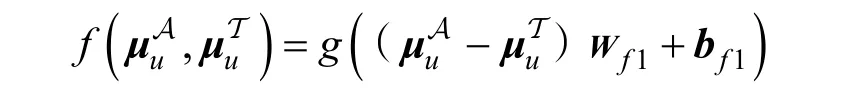
其中, g (∙)指的是一个具体的激活函数, Wf1∊Rk×k和 bf1∊R1×k分别指的是的权重矩阵和偏置向量。
本文将使用上述公式的模型记为Tri-VAE-sub,并使用了tanh函数和sigmoid函数作为激活函数进行实验, 最后的实验结果如表5 所示。结合表3、表4和表5 的实验结果可以看出, Tri-VAE-sub 的推荐性能比Tri-VAE 稍差一些, 但比所有基线模型都要好。这说明通过利用和之间的差异能够纠正用户的潜在特征, 进而有效缓解偏置带来的影响。另外,对于衡量和差异的方式, 使用拼接的方法比作差的方法要好一点, 这是因为使用拼接能够最大程度地保留两者差异的信息, 更有利于神经网络对偏置信息的提取。
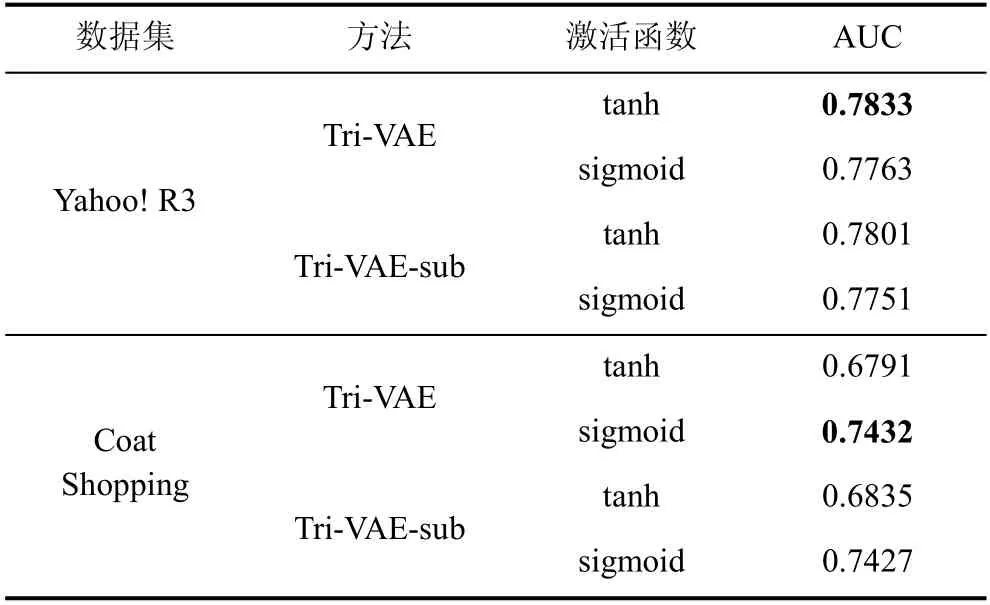
表5 在数据集Yahoo! R3 和Coat Shopping 上,Tri-VAE 和它的变体Tri-VAE-sub 的推荐性能比较, 其中最佳结果用粗体标记Table 5 Recommendation performance between Tri-VAE and its variant Tri-VAE-sub on Yahoo! R3 and Coat Shopping, where the best results are marked in bold
此外, 在Tri-VAE 中, 特征校正模块使用了带激活函数的单层全连接网络提取偏置特征。因此, 接下来本文从网络层数的角度来进一步探讨特征校正模块, 并先后使用了双层全连接网络和三层全连接网络。本文将使用双层全连接网络的模型记为Tri-VAE(双层), 将使用三层全连接网络的模型记为Tri-VAE(三层)。同样地, 使用了tanh 函数和sigmoid函数作为激活函数进行实验。另外, 对于同一个模型,多层全连接网络的设置相同, 比如在实验过程中,模型选择tanh 函数, 则双层全连接网络都使用tanh函数。Tri-VAE(双层)和Tri-VAE(三层)的推荐性能结果如表6 所示。从实验结果可以看出, 对于数据集Yahoo! R3 而言, 增加网络层数并不能提高模型的推荐性能, 而对于数据集Coat Shopping 而言, 增加网络层数能够进一步提高模型的推荐性能。这可能与数据集本身包含的偏置信息有关, 不同的数据集受偏置的影响程度不同。另外还有可能与无偏数据规模的大小有关, 对于Yahoo! R3 而言, 无偏数据的规模相对于有偏数据比Coat Shopping 更小, 在同样的数据规模下, 增加网络层数相当于增加了模型参数,这使得模型的训练更加困难。
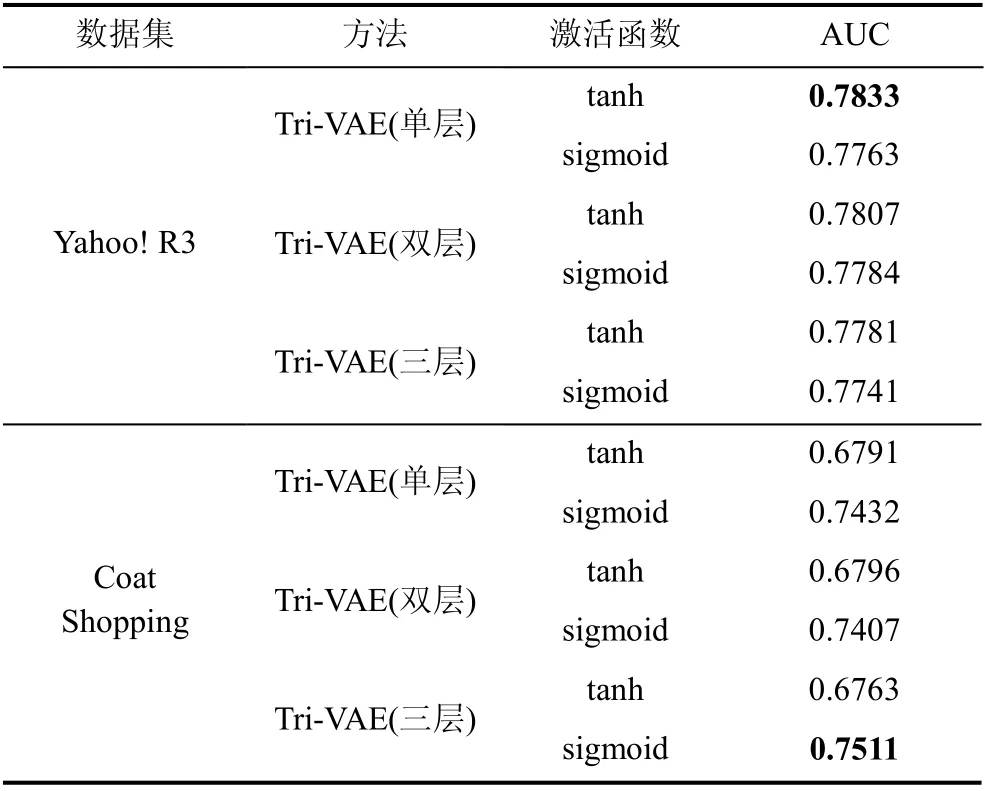
表6 在数据集Yahoo! R3 和Coat Shopping 上, 特征校正模块网络层数对推荐性能的影响, 其中最佳结果用粗体标记Table 6 Recommendation performance of our proposed model with different numbers of network layers on Yahoo! R3 and Coat Shopping, where the best results are marked in bold
6 总结
本文首先提出了推荐系统中一个重要且前沿的问题, 即一元反馈的偏置问题, 并对其进行了严格的定义和形式化。针对这一问题, 从一个新颖的角度提出了一种基于多任务学习和变分自编码器的模型,即三任务变分自编码器。该模型将有偏数据、无偏数据和联合数据当作三个不同的学习任务, 同时任务之间通过特征校正模块和标签增强模块进行关联。其中, 特征校正模块用于获取无偏的用户潜在特征, 而标签增强模块则是为了进一步利用无偏数据的信息。本文在两个真实的数据集上进行实验, 实验结果表明该模型能够有效缓解偏置的影响, 比现有的推荐模型有更好的推荐性能。此外, 为了进一步研究所提出的模型, 本文对其进行了消融实验、超参数敏感性分析和收敛性分析, 同时还进一步对其中的特征校正模块进行了探讨。
在推荐系统中, 保护用户的隐私越来越受学术界和工业界的关注。在未来的工作中, 我们将进一步研究面向用户反馈等隐私信息的保护技术[39], 以适应用户对隐私和数据安全的需求。
