多种混合智能算法在城市水环境综合整治中应用的研究
2021-11-092
2
(1.中山市环境保护技术中心,广东 中山 528400;2.暨南大学水生生物研究中心,广东 广州 510632)
目前,人们对环境保护愈发重视,针对城市水环境污染的综合整治是我国环境保护领域的一个重要工作,同时也是城市环境治理中的一个重要环节[1]。2015年,由国务院印发的《水污染防治行动计划》中提出:“直辖市、省会城市、计划单列市建成区要于2017年底前基本消除黑臭水体。”同时提出到2020年,长江、黄河、珠江、松花江、淮河、海河、辽河等七大重点流域水质优良(达到或优于Ⅲ类)比例需要总体达到70%以上。
城市中河涌水体是城市水污染物排放的主要受体,接纳着来自生活污水、工业废水等多种类型的水污染物,城市河涌是整个城市生态空间的一项重要构成要素,同时也是城市水循环系统的关键部分。引起城市河涌水体污染的因素很多,根据污染主要来源可分为工业企业污染源、居民生活污染源、农业面源污染源及初期雨水污染源等[2]。通对过污染源的现状评价工作,可以更好地掌握工程区域内的污染物来源、污染总量、污染类型。针对污染源来设定工程措施,更有针对性、更加高效、更加切实可靠。在对城市污染源进行现状评价的过程中,由于污染源数量巨大、来源复杂,因此对城市河涌水体的研究需要投入大量的人力和物力。
近年来,智能算法在预测与评估等领域,由于其无需准确的数学模型和快速推理机制,且不同智能算法之间匹配时具有良好的兼容性和相互弥补性,应用日益广泛[3]。在水污染治理和研究过程中,智能算法的出现可以很好地应对水污染治理研究中存在的约束性、非线性、不确定性和建模困难等问题。目前已在河涌水质预测、水环境质量综合评价、现场工艺控制等方面有所应用[4-5]。吴志远等[6]提出的基于分段粒子群算法的梯级水库多目标优化调度模型,有效解决了水库调度模型在时间步长较小、计算时段数目较多时寻优效率低下的问题。李祥蓉等[7]将静电放电算法和投影寻踪融合模型成功应用于水功能区水质综合评价。本文以中山市南朗流域共13条河涌水体为研究对象,结合当前热门的智能算法,建立起基于多种混合智能算法的河涌水质预测模型、以高锰酸盐指数和溶解氧为目标的河涌水质多目标优化模型。
1 数据与方法
1.1 数据来源和分析
中山市南朗流域共有河流59条,属于典型的河网型流域,河涌分布密集。主要河道有北部排洪渠、中心二河、泮沙排洪渠、兰溪河等。北部排洪渠位于南朗镇北面,拦截北部山区的雨洪水,中心二河东西向贯穿南朗城区,两河道大致平行,相距约450m。泮沙排洪渠位于镇区中南部,在合水口附近设有一节制闸,水流主要经泮沙排洪渠出海。兰溪河在镇区的南部,独立出海。
本文以中山市南朗镇南朗流域河涌为研究对象,数据选取中山市南朗流域内的北部排洪渠、中心二河、泮沙排洪渠、兰溪河、大溪、麻子涌、南冲渠、贝里坑、白企坑、合水坑、大车南渠、大车北渠、东桠涌13条黑臭河涌污染源现状调查数据和水质现状监测数据(调查数据来源于《中山市未达标水体综合整治工程可行性研究报告(南朗流域)》相关章节数据和中山市生态环境局网站相关统计数据,水质现状监测在河涌枯水期展开,在4月、10月对13条的河涌进行了检测,水质现状分析按照国标中规定的有关方法进行)。南朗镇南朗流域13条河涌地理分布见图1。
为尽可能全面地考虑不同污染源对河涌水质的影响,本文选取对河涌水质影响最为明显的污染源类型:
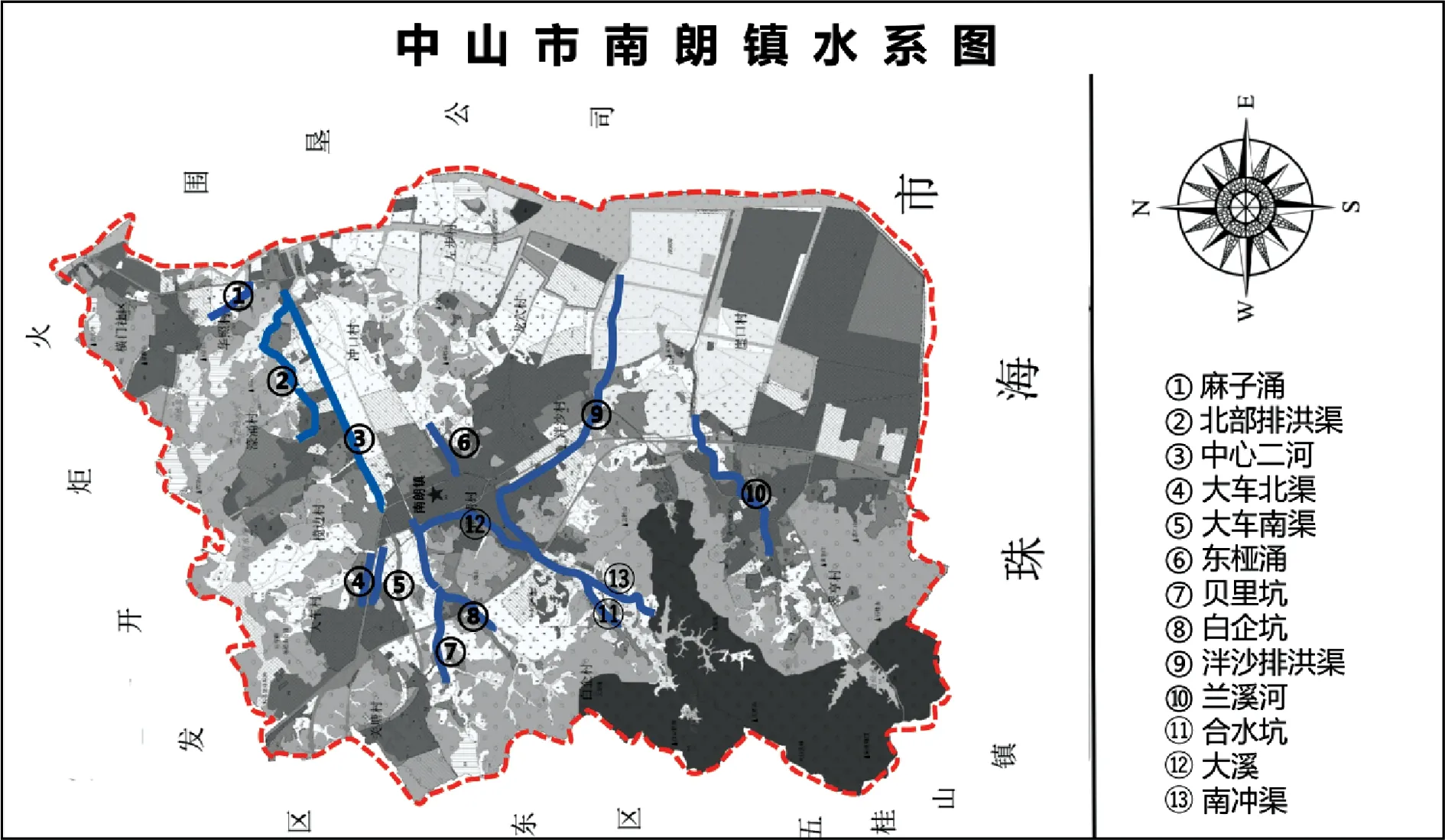
图1 南朗流域13条河涌分布情况
工业企业污染源、居民生活污染源、农业面源污染源(包括农田和鱼塘)和初期雨水污染源(由于流域内的13条河涌多为并行排列状态,暂不考虑入河支流对主河道的污染入流影响)。调查数据包括统计各条河涌沿岸的居民人口数和河涌沿岸截污管道的敷设情况;针对工业企业污染源,调查各河涌流域的应处理达标的工业废水污染的入河量;对于农业面源污染,调查出流域内每条河涌排水区域内的农业种植面积及鱼塘面积;最后,对流域内各个河涌的水文参数和水质状况进行汇总。
本文分别选取年生产废水入河量、居民人口当量、农田面积和鱼塘面积、初期降雨总净流量对工业企业污染源、居民生活污染源、农业面源污染源及初期雨水污染源的影响进行表征。同时,选取河涌集雨面积对河涌自身水环境容量进行表征,水质现状监测数据以高锰酸盐指数和溶解氧进行表征。中山市南朗流域13条河涌水质现状调查数据见表1。
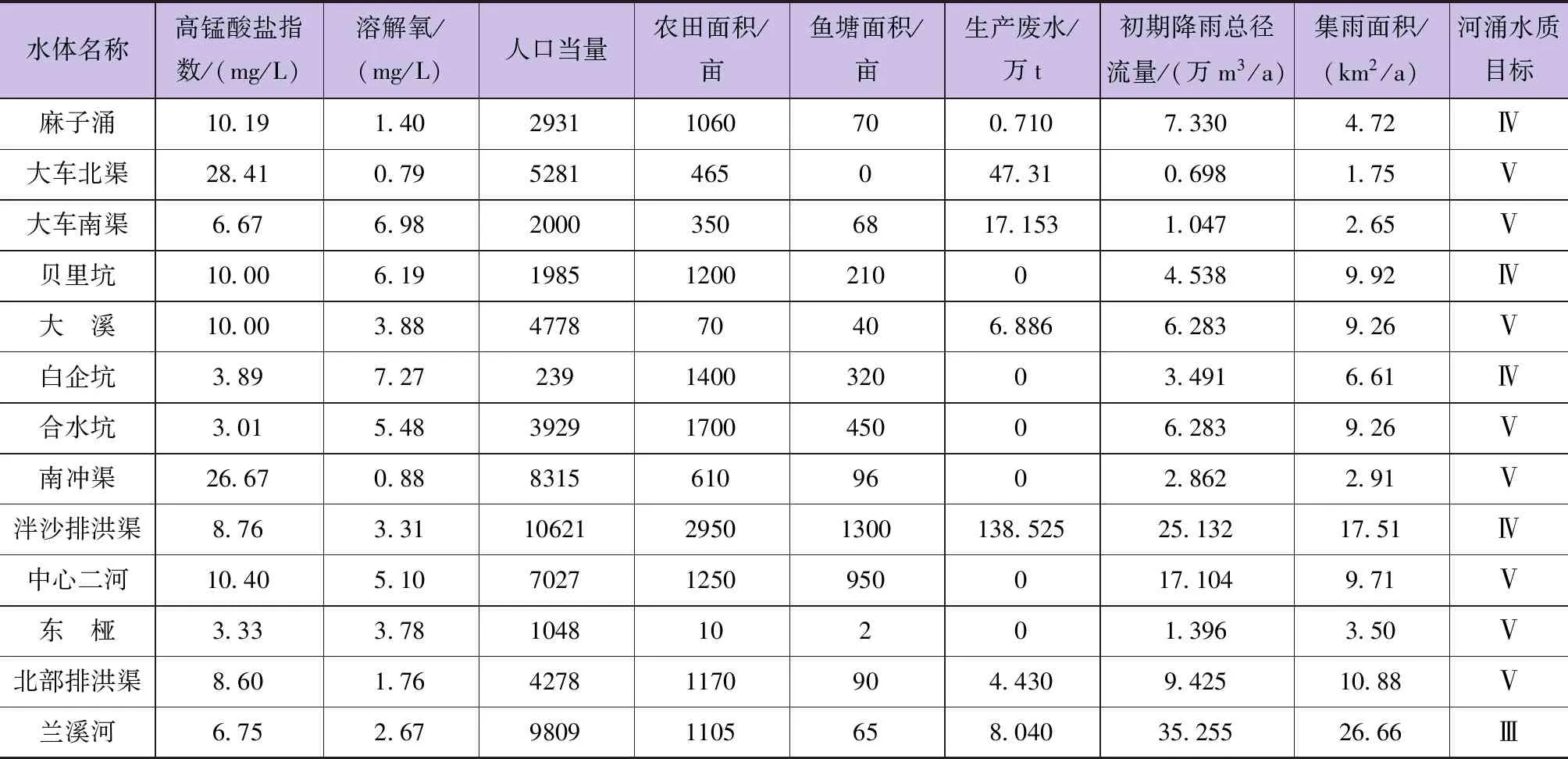
表1 南朗流域13条河涌水质现状调查数据
1.2 PCA-LSSVM模型的建立
支持向量机(SVM)算法是基于结构风险最小化要求,通过选择分类核参数类型和其他不同参数,使训练误差与测试风险达到最小的智能算法[8]。LSSVM算法则是对SVM的一种变形与拓广,其在SVM的基础上,应用训练误差的二次平方项代替优化目标中的松弛变量,另一方面,通过将原来的不等式约束改为等式约束,可大大提高计算的运行速度。对比神经网络的启发式学习手段,SVM对于数据样本有较小的依赖性,因此需要更为严格的数学论证,其所得的局部最优解可解决神经网络训练中易陷入局部极小点的问题。支持向量机是学习算法中一种常用的分类方法,可用于解决实际训练中存在的样本数量少、线性不可分的问题,恰好符合流域河涌水质调查中的复杂性、时变性、困难性的特征[9]。
在针对智能算法的实际应用过程中,由于对河涌流域水质的预测是一个包含多种变量、多个目标、同时涵盖多个层次的复杂系统,加之所获取的水环境系统信息不完善,各种参数之间不可避免会出现耦合和关联的情况,因此本文采用了PCA(Principal Component Analysis)对各过程变量间线性相关关系进行处理,实现输入数据降维,即辅助变量的精选[10-11]。
当前,对PCA和LSSVM模型建立的研究已经较为成熟,本文仅对建立PVA-LSSVM预测模型的主要步骤进行阐述。
a.原始数据的获取:通过资料收集和水质实测,整理得到与每条河涌相关的生产废水入河量、人口数量、农田面积、鱼塘面积、初期降雨总净流量、河涌集雨面积数据,考虑到生活污染源除受人口数量的影响外,还会受是否铺设截污管道的影响,因此在本文中以人口当量的影响[人口数量×(1-管网覆盖率)×调整系数计算得到],同时农业面源污染源以农田面积与鱼塘面积之和表示。
b.数据预处理:为更好地提高模型的运行速度,减少运行时间,本文通过算法将步骤a获得的数据进行归一化操作,从而使模型的输入和输出的数据统计分布大致均匀。
c.利用步骤b中获得数据,应用PCA算法计算得出主成分的累计方差贡献率,以较好的拟合水平(本文以累计方差贡献率不小于90%为要求)确定出主成分个数,组成新的数据样本矩阵,通过PCA操作可进一步实现数据的精简。
d.利用步骤c中获取的新样本数据,应用LSSVM算法建立起流域河涌水质预测模型;选择合适的初始参数(包括核函数、核参数和正则化参数),对上文中的数据进行训练与测试,直到获得较好的预测效果。
1.3 基于PCALSSVM和NSGA-Ⅱ的多目标优化模型
在城市水环境整治过程中,需要针对流域河涌不同的情况制定整体系统的治理方案。如何在保证满足当前水质要求的情况下,设计出具有针对性和合理性的治理方案十分重要。在进行方案设计时,人们往往希望能掌握典型情景下不同污染物输入对河涌水质的变化影响特征,流域河涌水质预测模型可以很好地帮助人们解决这一问题,但对于同时能够优化管理、降低运行成本等多目标问题仍需进一步的研究。
NSGA-Ⅱ算法是对基于NSGA(Non-Dominated Sorting in Genetic Algorithms)算法的改进,已经应用于实际中解决多目标优化问题,在处理具有高维数、多模态、非线性等复杂问题上应用广泛。将前一节建立的PCA-LSSVM流域河涌水质预测模型,代替传统的数学模型用于NSGA-Ⅱ算法中,可很好地解决NSGA-Ⅱ算法中关于河涌水质预测模型建立困难的问题。
改进的NSGA-Ⅱ算法的基本流程如下:
a.根据多目标问题和约束条件对种群进行初始化。
b.对初始种群进行快速非支配排序,其算法具体步骤如下:对一个初始化种群为P的种群,其每个个体i都有对应的两个参数ni和Si,其中ni代表种群P中支配i的个体数目,Si则代表被个体i支配的个体数目。第一步,找到种群中不受其他个体影响即ni为0的个体并将其存入到前集合Fi中。第二步,对于集合Fi中的每一个个体j,考察受到个体j即被个体j所支配的个体集Sj,由于个体集中Sj中的个体k已存在于当前集Fi中,因此需要将集合Sj中每一个个体k的nk减去1,如果其值为0,则将个体k存入新的集合H,否则,则保留在集合Sj中。第三步,赋予集合Fi中每一个个体相同的非支配序,并将Fi作为非支配个体集合的第一级,对集合H进行分级排序操作直到所有个体都有其对应的排序值。这样,集合中所有的个体都进行了分级。
c.确定拥挤度和拥挤度比较算子。在对种群完成快速非支配排序以后,为保证所求得的支配解集分布均匀和种群的多样性,引入了拥挤度和拥挤度算子。拥挤度是指群体中某一指定点附近包含个体本身但不包含其他个体的最小长方形。通常用Id表示,其计算方法为
对于前集合Fi,n为其包含的所有个体数目,初始化群体中每个个体i的拥挤度为0。即Fi(dj)=0,j代表Fi中的第j个个体。
对于选定目标函数m,进行快速非支配排序操作:
I=sort(Fi,m)
(1)
式中:Fi为集合;m为目标函数。
为确保边界上的两个解都能进入下一代,假定每个目标函数处在边界上的解的拥挤度趋于无穷大:
I(d1)=∞,I(dn)=∞
(2)
式中:I(d)为个体拥挤度。
则其余个体的拥挤度为
(3)
式中:k为第k个个体。
经过以上排序和拥挤度计算,种群中每个个体都具有非支配序和拥挤度两个属性。
d.根据种群个体的非支配序和拥挤度进行筛选工作,其评价准则为:当两个个体的非支配排序不同时,非支配排序更高的被筛选出来;当非支配排序相等的两个个体进行比较时,选取拥挤度更小即周围不拥挤的个体。根据锦标赛选择策略,重复进行筛选工作直到达到最大种群规模。
e.基因操作。为避免算法陷入局部最优的情况,NSGA-Ⅱ算法选择交叉变异操作,包括基因的重组和变异操作。通过模拟二进制交叉(SBX)基因重组使得到的子代个体能够保留两个父代个体中的模式信息。其子代具体产生过程如下:
(4)
(5)
式中:ci,k为交叉产生的子代,pi,k为其父代,βk≥0,为种群的任意一个个体。
概率密度函数为
(6)
(7)
可由式(8)、式(9)导出:
(8)
(9)
NSGA-Ⅱ算法基因变异产生子代主要是靠多项式变异算子(PM)实现的,其操作过程为
(10)
式中δk可由式(11)、式(12)求得:
(11)
(12)
式中:rk为个体的非支配排序;ηm为变异分布指数。
f.模拟二进制交叉和多项式变异产生的种群与原种群合并形成新的种群,通过筛选进一步形成新的种群直到当前进化代数达到最大进化代数,输出最终种群的非支配个体,见图2。
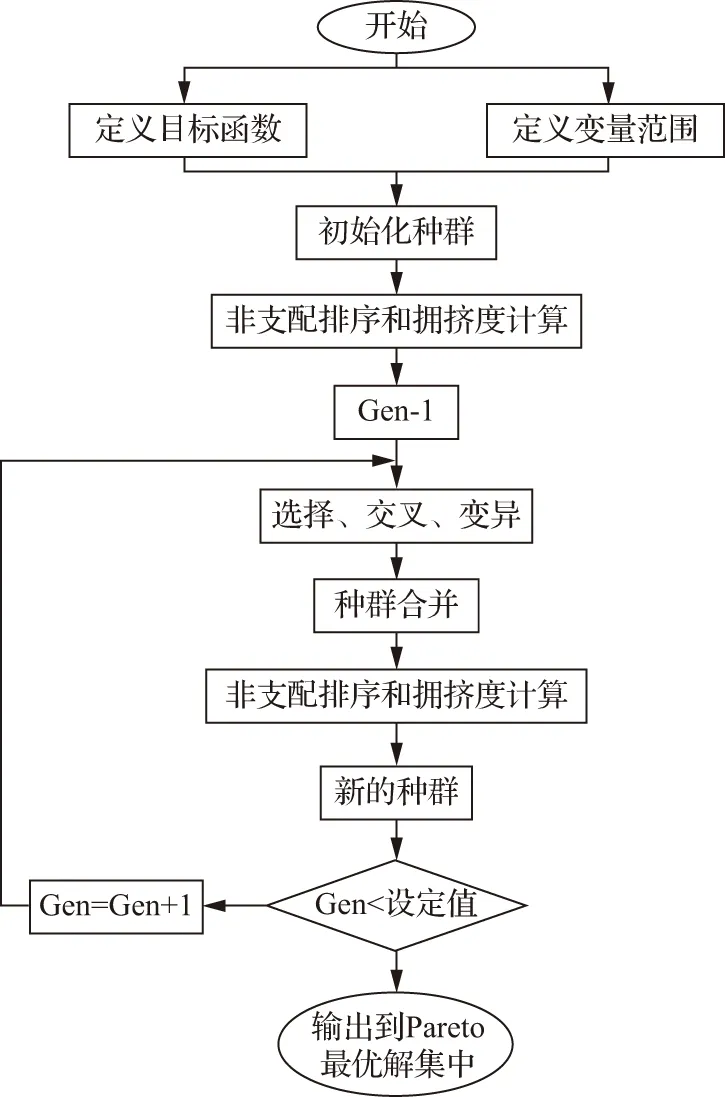
图2 优化模型流程示意
1.4 原始数据的采集及PCA处理
本文收集得到中山市南朗流域13条黑臭河涌(北部排洪渠、中心二河、泮沙排洪渠、兰溪河、大溪、麻子涌、南冲渠、贝里坑、白企坑、合水坑、大车南渠、大车北渠、东桠涌)相关数据。选取的模型输入量包括人口当量、农业面源面积、生产废水入河量、初期降雨总净流量4项外部污染源变量和河涌集雨面积1项河涌自身影响变量,算法模型的输出变量为河涌实测水质高锰酸盐指数和溶解氧浓度。
在进行模型训练前,为消除不同量纲的影响,首先对获得的数据进行归一化处理:
(13)
式中:S(i)为数据集中的一组数据;max(S)为数据集中最大的一组数据;min(S)为数据集中最小的一组数据。
经归一化处理后的数据利用PCA算法进行降维操作,本文所有算法运行均在MATLAB 2015b软件环境下运行。PCA算法处理结果如图3、图4所示,图3中连接原点与各变量的直线的“向量”可显示辅助变量与样本点之间的多元关系,具体的向量在某一主成分上的投影可表明该变量对该主成分的重要程度,投影矢量长度越大,代表该向量的重要程度越高,该主成分对该变量的解释程度也越高[13]。从图3双标图中变量的矢量长度可以看出,外部污染源中人口当量、初期降雨总净流量和生产废水入河量是十分重要的影响变量,河涌自身影响变量集雨面积也十分重要,农业面源面积影响较小。从图4可以看出,第一主成分的方差贡献率为73.13%,对变量的解释程度一般,第二主成分的方差贡献率为15.19%,与第一主成分的累计方差贡献率为88.32%,对变量的解释属于中等偏上的水平,第三主成分的方差贡献率为7.28%,前三主成分的累计方差贡献率为95.60%,有很好的拟合度水平。

图3 双标图

图4 各主成分方差贡献率结果
为进一步对此次流域河涌水质模型预测性能的好坏进行量化,本文分别选取均方根误差(RMSE)和相关系数(R)对模型的预测性能进行表征。其中RMSE值越小,R值越接近于1,说明模型的水质预测值与河涌水质的实际值的相关度越高,代表模型的预测性能越好[14-15]。
2 结果与讨论
2.1 PCA-LSSVM模型预测仿真
结合PCA-LSSVM模型的河涌水质高锰酸盐预测模型和溶解氧水质预测模型进行仿真。其中,输入层为人口当量、农业面源面积、生产废水入河量、初期降雨总净流量和河涌集雨面积,输出层分别为河涌水质高锰酸盐指数和溶解氧,使用Matlab2015b中LSSVM工具箱编写程序建立河流水质预测模型,选取径向基函数(RBF)作为核函数,算法初始化正则化参数γ和核参数σ2的取值范围为:γ∈(0,1000),σ2∈(0,100)。通过网格搜索法和10倍交叉验证法最终选出的正则化参数和核参数的最优值分别为γ=35.2606和σ2=5.7196。仿真结果见图5、图6和表2。
从图5、图6中可以看出,基于PCA-LSSVM模型的河涌水质模型中高锰酸盐指数和溶解氧预测值与实际真实值基本趋同;由表2可知,训练数据样本中高锰酸盐指数预测值和真实值之间的均方根误差为5.11,预测数据与实际数据的相关系数为0.8290;而对于溶解氧而言均方根误差为1.65,模型预测数据与河涌水质实际数据的相关系数为0.8126。两模型的预测数据与河涌水质实际数据的相关系数都在0.8以上,属于较好的预测水平。尽管两个模型都存在部分数据的偏离,但总体预测效果较好,这表明LSSVM具有很好的预测能力和非线性映射能力,能够作为NSGA-Ⅱ的目标函数。

图5 PCA-LSSVM模型对高锰酸盐指数仿真结果
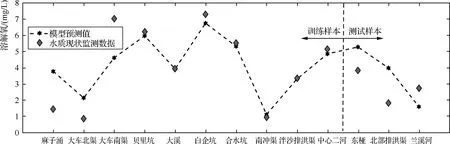
图6 溶解氧仿真结果

表2 模型预测性能
2.2 基于PCA-LSSVM和NSGA-Ⅱ的多目标优化的实现
采用PCA-LSSVM智能算法的河流水质预测模型能够较好地模拟出各参数辅助变量与优化目标量之间的关系,鉴于该模型选用输入量人口当量、农业面源面积、生产废水入河量、初期降雨总净流量和河涌集雨面积中包含了一部分不可控量(初期降雨总净流量和河涌集雨面积量),为避免优化过程中其值被当作可变因素影响模型输出,在本节中我们采用人口当量、农业面源面积、生产废水入河量3项参数,利用PCA-LSSVM 建立新的河涌水质预测模型,同时将该模型代替传统的数学模型用于NSGA-Ⅱ算法中解决城市水环境综合整治决策过程中的多目标优化问题。在满足水质目标要求的前提下,探寻不同污染源变量之间与河涌水质之间的关系,最终建立起基于PCA-LSSVM和NSGA-Ⅱ相结合的多目标优化模型。优化模型为目标函数:
f1(CCod)=sim(net1,[人口当量,农业面源面积,生产废水入河量]
f2(DO)=sim(net2,[人口当量,农业面源面积,生产废水入河量]
(14)

(15)
式中:为保持预测的准确性,约束条件的选择范围依据预测模型的取值范围;net1,net2分别为基于PCA-LSSVM算法建立的高锰酸盐和溶解氧预测模型。进一步选取NSGA-Ⅱ 参数为:种群数量100、交叉概率0.4、变异概率0.05、最大进化代数1000。优化结果见图7。
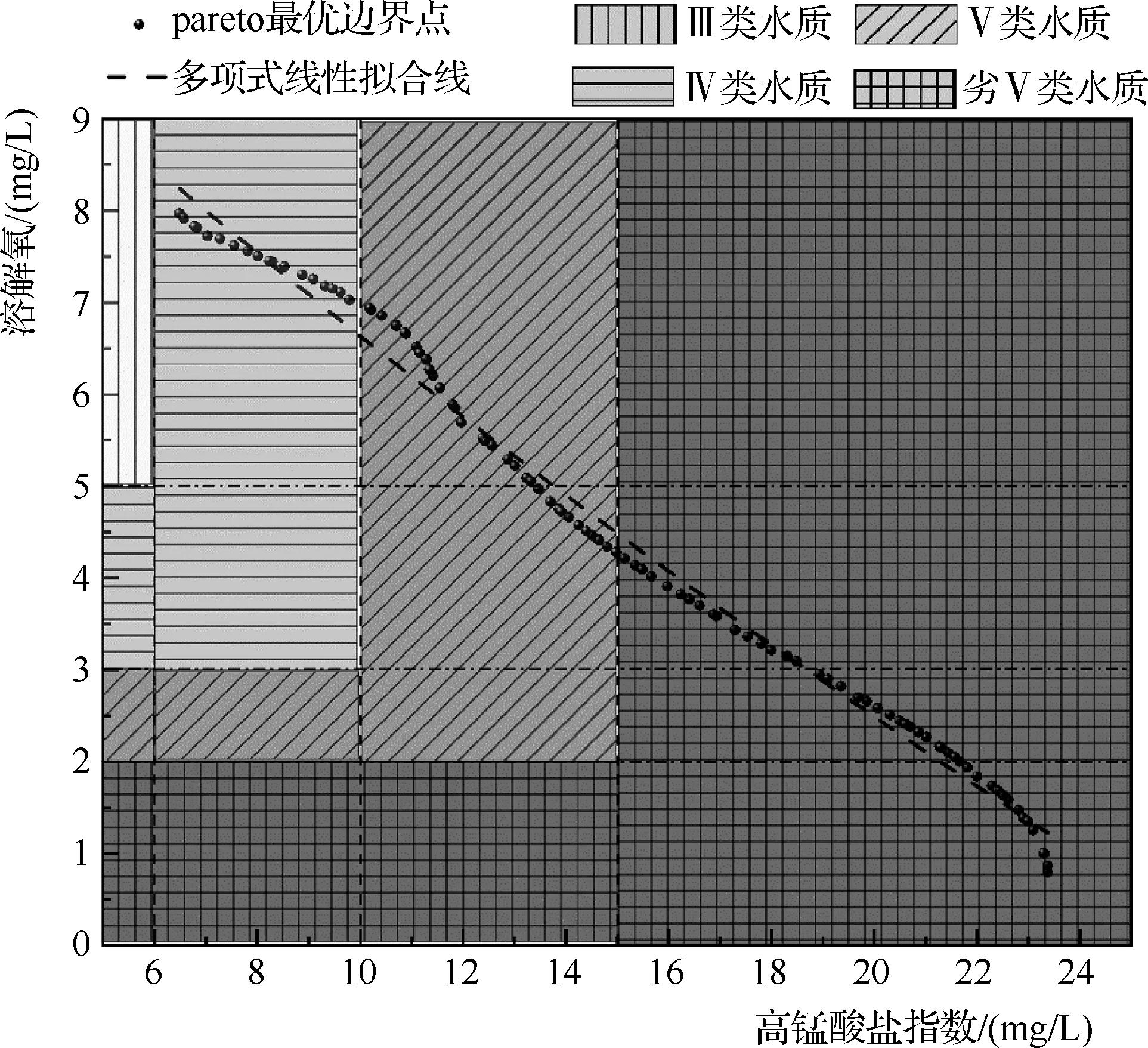
图7 优化模型运行结果
由图7中Pareto最优边界点的轨迹可以看出,高锰酸盐指数和溶解氧之间存在或有这样的关系:随着河涌水质中高锰酸盐浓度的升高,水质中溶解氧浓度下降,反之亦然。进一步地,从数学模型的角度解释预测模型中高锰酸盐指数和溶解氧之间的相关关系,运用Matlab的聚类多项式线性拟合工具对图中的曲线进行拟合,拟合后,河流水质高锰酸盐指数和溶解氧的联系可以用二次多项式表示为
Y=11.38681-0.50521X+0.00302X2
(16)
相关性系数为0.99111。

表3 部分最优边界点参数
表3给出了部分Pareto最优边界点。从表中可以看出,人口当量,即生活污水入河量对水质影响较最明显。图8给出了目标迭代过程中人口当量、农业面源面积、生产废水入河量的分布。从图8中可以看出,人口当量对河流水质的影响最为明显,表现为高锰酸盐指数之间有较明显的规律:当人口当量较少(接近于0)时,农业面源污染较高(农业面源面积较大),河涌水质高锰酸盐指数随生产废水入河量升高而上升。尽管农业面源面积和生产废水入河量保持下降的态势,但当人口当量增加时,河涌水质高锰酸盐指数仍然有明显的上升势态。可见在区域流域的水环境综合治理中,决策方案的制定应该重点关注对居民生活污染源的治理,采取对应的截流措施以达到较好的治理效果,同时考虑工业污染源、农业面源及其他污染源的影响。
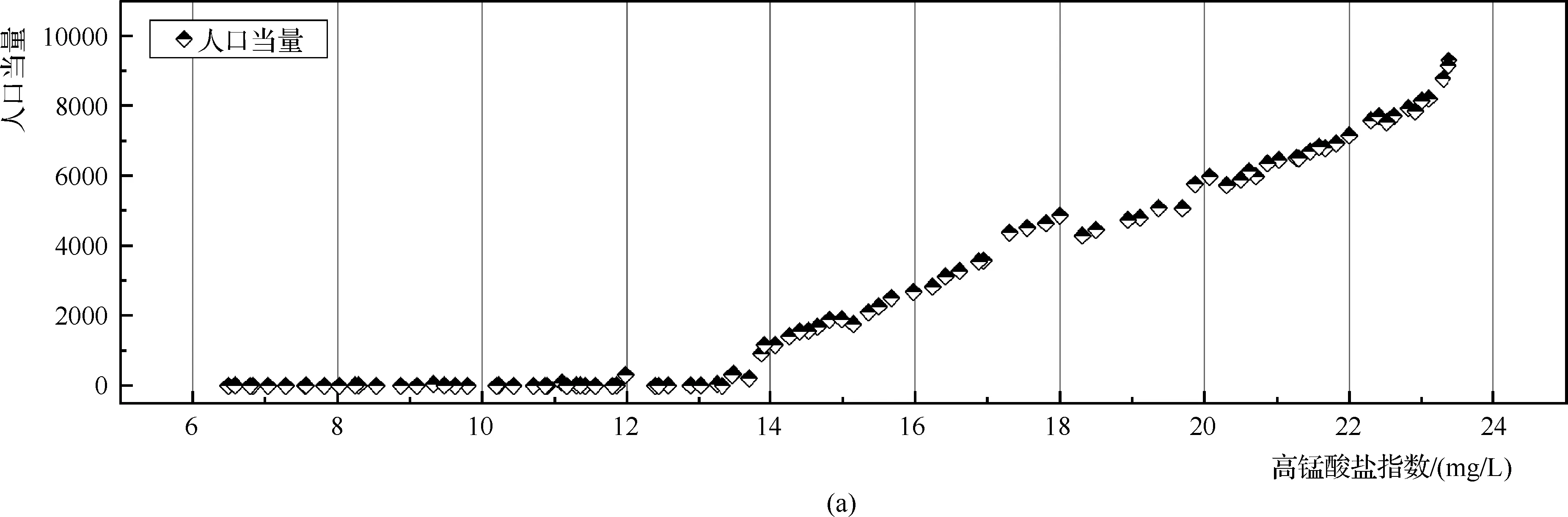
图8 Pareto最优边界中各变量分布
3 结 论
a.建立城市水环境综合整治过程中的多目标优化模型。本文通过资料收集和文献查阅等方式共得到南朗流域13组河涌水质组元数据。实验模型选取人口当量、农业面源面积、生产废水入河量、初期降雨总净流量和河涌集雨面积5项输入变量,河涌水质实测数据高锰酸盐指数和溶解氧作为模型输出变量。
b.针对城市水环境综合整治决策过程中的多目标优化问题,通过多种混合智能算法,成功建立起基于PCA-LSSVM的河流水质高锰酸盐指数和溶解氧预测模型,模型测试数据与实际数据的相关系数分别为0.8290和0.8126。基于PCA-LSSVM混合智能算法的河流水质预测模型也可为入河支流对主河道的污染预测提供参考。
c.为解决城市水环境综合整治决策过程中的多目标优化问题,利用NSGA-Ⅱ算法建立了优化模型,优化结果表明,在区域流域的水环境综合治理中,决策方案的制定应该重点关注对居民生活污染源的治理,同时考虑工业污染源、农业面源及其他污染源的影响。可为解决城市水环境综合整治方案的设计和操作提供参考和指导。
