基于GANs-LightGBM的序贯三支异常用户检测研究
2021-11-08罗珺方
陈 芮,杨 新,罗珺方,陈 阳
(1.西南财经大学 经济信息工程学院,成都 611130;2.西南财经大学 金融智能与金融工程四川省重点实验室,成都611130;3.清华大学 自动化系,北京 100084)
0 引 言
互联网在给人们带来便利的同时,也助长了黑灰产业的发展。黑灰产业在网络中利用非法或作弊的手段牟取利益,例如恶意抢券、木马刷量、电信诈骗等。其中,黑灰产业在谋取不正当利益时,通过寻找网络中的漏洞,自动生成或盗取他人信息,生成虚拟的用户,进行套利、发布广告、网络欺诈和制造不良舆论等[1]。这一类无价值的虚拟用户,给网络管理带来了不便,甚至会给相关主体带来巨大损失,亟需有效的方法对这一类异常用户进行检测和识别。
国内外现有对于异常用户检测的方法呈现出智能化、自动化的趋势,为了解决数据类别分布不均的问题,普遍采用了集成学习的方法来应对异常用户识别的问题。例如,文献[2]根据社交网络中的用户信息,利用集成分类器XGBoost进行特征选择,建立分类模型;文献[3]利用XGBoost对电力行业中的异常用户进行识别,发现该方法优于其他传统的机器学习方法,并且能够应对类别不平衡的问题。此外,文献[4]利用用户的个人特征及用户之间的关系,构建了基于图卷积网络的异常用户识别方法。虽然集成学习以及深度学习算法在异常识别中得到了大量的研究,并在异常用户识别中取得了良好的效果[5],但是,其大多是关注于如何减轻类别分布不平衡给检测算法带来的影响,而忽略了检测过程中的代价,未考虑实际的应用情形。
目前异常用户检测尚存在2个方面的研究难点。
1)具有异常标签的数据稀少,样本分布极度不平衡。异常样本主要来源于人工拦截的样本、风控策略拦截的样本和风控体系无法识别并最终带来损失的样本[6],而这一类异常用户的数据往往较少,使得类别分布不均匀,模型难以学习少数类的分类规则,对预测造成一定的偏差。
2)检测代价高,模型泛化能力低[7]。检测代价不仅包括检测过程中花费的成本,还包括因误分类带来的损失。当前在异常用户检测的研究中,以随机森林、GBDT和神经网络为代表的机器学习模型普遍表现出良好的分类精度,但由于异常用户检测任务的代价敏感性,当把异常用户识别为非异常用户时,极有可能造成巨大损失。此外,用户操作行为、交易过程中的复杂性导致的不确定性,也需要一个具有鲁棒性的模型。
因此,针对上述的2个问题,利用生成式对抗网络(generative adversarial nets, GANs),本文提出了基于GANs-LightGBM的序贯三支异常用户检测方法。利用GANs技术解决样本分布不平衡的问题;借助序贯三支决策模型能够有效降低决策成本的特性, 以及集成学习方法LightGBM的强泛化能力,构建了多层次多粒度的序贯决策框架。最后,通过对多个模型在多个指标下的对比分析,验证了本文所提出模型的良好性能。
1 序贯三支决策
序贯三支决策(sequential three-way decisions,S3WD)是文献[8]在2013年提出的一种多阶段、多粒度的动态决策方法,为解决异常用户检测代价高的问题提供了一个可行方案。三支决策的核心思想是通过决策规则将论域划分为正域、负域和边界域3部分,是一种“分而治之”的策略[9],如图1。而序贯三支决策则是一个动态决策的过程,随着决策的进行,特征信息粒度由粗到细,部分对象可以在少量信息的情形下做出决策,从而降低测试代价,并能在具有足够信息的前提下做出决策,从而降低误分类代价。该算法可通过总代价最小为目标函数,在多阶段的决策过程中平衡误分类代价和测试代价[10]。序贯三支决策的思想在许多领域都得到了广泛的关注,包括推荐系统、文本分类、人脸识别以及风险识别等。例如,文献[11]考虑到推荐信息的不确定性和多层次特征,将三支决策与粒计算相结合,建立了一种动态的推荐模型;文献[12]提出了一种基于序贯三支决策的代价敏感人脸识别方法,在人脸识别中实现了低分类误差;文献[13]将三支决策模型用于处理二分类文本的不确定边界,提高了文本分类的性能;文献[14]将三支决策用于信用评估,在小微企业数据集上取得了良好的效果。因此,利用序贯三支决策的方法降低异常用户检测的决策过程代价和误分类代价,是一种可行的方案。

图1 三支决策框架图
基于此,本文在序贯三支决策框架下提出了一种基于生成对抗网络和集成学习模型的异常用户检测方法,如图2。首先通过不同的特征集合构建由粗到细的特征粒层;其次在每一层上利用GANs模型对边界域的数据进行类别平衡;并在多层次多粒度的特征空间下应用LightGBM模型持续地处理不确定域的样本以识别异常用户和降低决策代价。实验结果表明,与传统的机器学习算法相比,该方法在达到较高AUC值的同时具有更低的检测代价,在实际异常检测过程中体现出更强的适用性。

图2 模型框架图
2 生成式对抗网络
为了解决数据类别分布不平衡的问题,本文不再单一地借助模型本身去应对类别进行平衡的问题,而是采用了双重机制——GANs和一种更高效的集成学习模型LightGBM[15],以增强模型的鲁棒性。GANs是文献[16]于2014年提出的一个基于博弈论思想的生成模型,在计算机视觉领域已经取得了不错的成效,可将其用于解决数据分布不平衡的问题。文献[17]将GANs用于生成信用卡欺诈数据,在XGBoost上取得了较好的精度。与传统的生成模型相比,GANs在缺乏大量真实数据的情况下可以生成逼近真实数据分布的人工候选数据,有利于解决在异常用户样本稀少时的分类问题。因此,采用GANs将得到一个更加均衡的增广训练集,减少数据采集方面的人力投入成本,扩展数据多样性,避免过拟合。
在生成式对抗网络中,一个生成器G和一个判别器D通过类似博弈的方式达到动态均衡。生成器以随机噪声z作为输入,目的是学习训练数据中的概率分布,并将z映射到这种分布从而产生尽可能接近真实数据的新人工候选数据,而判别器用于区分数据的来源:原始数据或者由生成器产生的数据,如图3。

图3 GANs模型
定义1[17]在GANs模型中,生成器G定义为G:Z→X,其中Z为随机噪声数据,X为生成数据,其目的是学习真实数据的分布。判别器D定义为D:X→[0,1],它判断样本属于真实数据分布的概率,二者达到动态平衡时该概率接近0.5。2个网络的具体模型可以是不同的神经网络模型,如MLP多层感知器与LSTM模型。模型训练过程中,生成器G和判别器D按照以下函数进行极小-极大博弈竞争(Minimax game),判别器通过最小化预测误差来训练,而生成器通过最大化预测误差来训练,可表示为
Ez~pz(z)[log(1-D(G(z)))]
(1)
(1)式在求解最大和最小优化问题时包含2个优化过程。可将(1)式分解为以下2个公式,首先优化判别器D得
Ez~pz(z)[log(1-D(G(z)))]
(2)
其次优化生成器G得
(3)
(2)—(3)式中,x和z是分别从真实数据分布pdata和噪声分布pz(z)中的采样。G(z)是生成模型的输出结果;D(X)是原始输入数据的分布;D(G(z))是判别器D的输出结果,取值为[0,1]。(2)式使真样本x的输入D(X)最大化,即真样本的预测结果越接近1越好,并使假样本的预测结果最小化,即D(G(z))越接近0越好。GANs的训练过程可使用随机梯度下降法对D和G进行优化。
数据的生成过程如图4。该示例有2个连续变量和2个离散变量。模型按照原始数据中的顺序依次生成这4个变量。每个样本由6个步骤生成。每个数值变量由2步生成,每个类别变量由1步生成。生成器使用含有2个cell的LSTM模型, 连续生成每个特征; 判别器D将所有特征进行拼接,并使用多层感知器(MLP)来区分真实数据和虚假数据。

图4 使用GANs生成数据的示例
3 基于序贯三支决策的异常用户识别模型
3.1 序贯三支决策过程
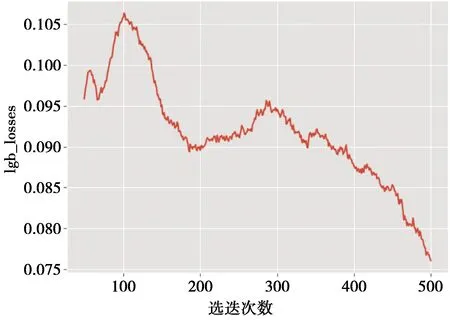
定义2[18]在异常用户检测过程中,设存在n+1个特征粒度层:Gi(i=0,1,2,…,n),n为特征的最细粒度层,0为最粗粒度层。对应存在n+1个子数据集:Di(i=0,1,2,…,n),D0⊆D1⊆…⊆Di⊆…⊆Dn。根据文献[8]的模型,在每个特定粒度层Gi(0 定义3[18]在异常用户检测中,评价函数值为分类器输出的类别概率值。而对象x在第i个粒度层上的决策取决于其在第i层上属于正域Xi的条件概率Pr(Xi|x)和阈值对(αi,βi),可获得如下的决策规则为 POS(αi,βi)(Xi)={x∈Di|Pr(Xi|x)≥αi} (4) NEG(αi,βi)(Xi)={x∈Di|Pr(Xi|x)≤βi} (5) BND(αi,βi)(Xi)={x∈Di|βi (6) (4)—(6)式中,Di=POS(αi,βi)(Xi)∪NEG(αi,βi)(Xi)∪BND(αi,βi)(Xi)。最终在最细粒度层Gn上做出二支决策,识别出异常/非异常用户可得 POS(αn,βn)(Xn)={x∈Dn|Pr(Xn|x)≥0.5} (7) NEG(αn,βn)(Xn)={x∈Dn|Pr(Xn|x)<0.5} (8) 在每个粒度层上,3WD模型的决策集为D={aP,aN,aB},分别表示3种可能的决策行为(“正”、“负”和“边界”),对象的实际状态集合为S={X,X},即非异常和异常,因此,可得决策成本估算矩阵如表1。 表1 三支决策代价矩阵 定义4[19]在第i粒度层下,aP,aB,aN这3种决策的风险成本可以分别表示为 (9) (10) (11) 由贝叶斯风险决策理论,各阶段决策根据如下规则进行。 1)若costP≤costB且costP≤costN,将对象x划到正域(非异常); 2)若costB≤costP且costB≤costN,将对象x划到边界域(延迟判断); 3)若costN≤costB且costN≤costP,将对象x划到负域(异常)。 在异常用户检测中,对象识别失误带来的损失通常大于模型的测试代价,而正确分类的代价最小。其次,将异常用户判断为非异常用户的代价通常高于将非异常用户判断为异常用户的代价。据此可得如下关系[20]: 因此,可得阈值对计算方法,第i(i=1,2,…,n)层的阈值αi和βi分别为 (12) (13) 当i=n时,αn=βn=0.5,即进行最终的二分类。 序贯三支决策是以最小化决策成本为目标函数的多步动态决策过程。因此,分析任何可能的决策成本来获得最优决策结果是其中的关键步骤。根据文献[8]的模型,决策的总成本主要来自错误决策所造成的成本和决策过程带来的成本[6]。在本文中称为误分类成本和测试成本。设总成本为COST,误分类成本为COSTR,测试成本为COSTT,其关系可表示为 COST=F(COSTR,COSTT) (14) (14)式中,F由具体函数而定。 值得注意的是,2种成本并非完全独立,并且在实际情况中可能存在一种反向关系。这是由于付出较高的测试成本更有可能产生高精度的分类结果。一般来说需要在这2种成本之间进行权衡,从而做出有效决策。根据文献[20],可计算第i层的检测代价为 (15) COST=COST1+COST2+…+COSTi (16) (17) 所有测试样本的检测总代价除以总的测试样本数,可得平均检测代价。 我们可以得到基于GANs-LightGBM的序贯三支异常用户检测算法(算法1)。输入为数据集D、每一层上的属性集合及每一层上的阈值(αi,βi),输出为POS(正常)或NEG(异常)。首先对于每一层上边界域的异常数据,利用GANS进行数据生成;其次,应用LightGBM对数据进行预测,获取概率;最后,基于概率判断对象所应当划分到的区域,直到第n次决策或者边界域为空。检测代价的计算需根据每一个测试对象何时停止决策进行计算。该算法只含一个单层循环,时间复杂度受序贯三支决策模型的层数、数据量、LightGBM模型和GANs模型的影响。 算法1基于GANs-LightGBM的序贯三支异常用户检测算法 输入:数据集D、每一层上的属性集合以及相对应的不同粒度层的阈值对(αi,βi)。 输出:决策结果,即POS(正常)或NEG(异常)。 1.U0=D,i=0,POS=∅,NEG=∅,BND=∅/*初始化*/ 2.fori=0,1,…,n-1do/*三支决策过程*/ 3.ifUi=∅then 4.break 6./*对于∀x∈Ui,通过LightGBM模型计算对象x在第i层不同域的条件概率*/ 7.forxinUido 8.Pr(Xi|x)=LightGBM(Di,x) 9.POS(αi,βi)(Xi)={x∈Di|Pr(Xi|x)≥αi} 10.NEG(αi,βi)(Xi)={x∈Di|Pr(Xi|x)≤βi} 11.BND(αi,βi)(Xi)={x∈Di|βi 12.POS=POS∪POS(αi,βi)(Xi)/*判断为正域(正常)的对象*/ 13.NEG=NEG∪NEG(αi,βi)(Xi)/*判断为负域(异常)的对象*/ 14.Ui+1=BND(αi,βi)(Xi)/*延迟决策的对象*/ 15.end for 16.i=i+1 17.end for 18.ifBND≠∅then/*最细粒度层上做出二分决策*/ 20.forxinUndo 21.Pr(Xn|x)=LightGBM(Dn,x) 22.POS(αn,βn)(Xn)={x∈Dn|Pr(Xn|x)≥0.5} 23.NEG(αn,βn)(Xn)={x∈Dn|Pr(Xn|x)<0.5} 24.POS=POS∪POS(αn,βn)(Xn) 25.NEG=NEG∪NEG(αn,βn)(Xn) 26.end for 27.end if 28.returnPOS,NEG 本文设计了以下2个实验。 实验ⅠGANs模型的选择。将对比3种主要GANs模型在样本生成上的实验效果,进而选择合适的GANs模型。 实验Ⅱ模型对比分析。基于已选择的GANs模型,建立基于GANs-LightGBM的序贯三支异常用户检测模型。并在多个指标下与多个模型进行对比分析。 根据网络异常用户检测的特殊性,本文选择Recall(召回率),Precision(精准率),F1值和AUC值[21]4个常用评价指标以及检测代价作为评价方法,分别表示为 (18) (19) (20) (21) (18)—(21)式中:TP,FN,FP,TN分别为真正例、假负例、假正例和真负例的数量;Np和Nn分别为正样本和负样本的数量。 本实验使用2018年甜橙金融的竞赛数据集(https://js.dclab.run/v2/cmptDetail.html?id=265),共31 179条关于用户信息及操作行为的数据,在经过特征处理之后共有630维特征,由离散型和连续型变量组成,标签为1和0,1为异常用户,0为非异常用户,其中仅有2 672条为异常,占比约8.57%, 数据类别高度不平衡。训练集与测试集的比例设置为4∶1。LightGBM模型的几个重要参数的设置为:learning_rate设置为0.01,feature_fraction设置为0.8,num_leaves设置为63,min_data_in_leaf设置为20。 参考已有研究对于生成器和判别器模型的选择,本文使用LSTM网络作为生成器,判别器使用多层感知器,并采用随机搜索的方式来调整GANs模型的超参数。选用了3种GANs模型进行对比,即传统的GAN,使用类别标签的CGAN和同时使用类别标签与Wasserstein距离度量的WCGAN。最后使用生成数据和实际数据共同训练LightGBM模型,使用AUC值作为评价标准,依据损失下降的情况判断训练停止条件,最终选择一个GANs模型用于数据生成。 为提高效率,生成器采用固定的LSTM模型(drop-out值为0.2,mini-batch size为64,激活函数为ReLU)。在判别器中,MLP网络架构为3层,mini-batch值为64。表2表示了训练后确定的3个GANs模型的超参数,包括多层感知器中的学习率、drop-out值和Node数。 表2 参数表 首先,初始化学习率为0.001,随着训练进行不断调整学习率,控制更新权重的步长;且为防止过拟合,drop-out值通常被设置为0.5,即在每个训练批次中,忽略一半的特征检测器,可以明显地减少过拟合现象,接着在训练过程中寻找更高效的参数。Adam优化器在训练相对较大的数据集(包含上千个训练样本或更多)时,在训练时间和验证分数方面都表现出良好的性能,因此这里采用Adam优化算法作为权重优化的求解器。最后,使用Leaky-ReLU激活函数进行训练,防止梯度稀疏。 图5为WCGAN方法生成数据的情况。 图5 真实样本(左)与生成样本(右)对比示例 图6显示了在测试结果上,经过 500次迭代后,WCGAN方法产生的损失趋于平稳,而GAN和CGAN相对较差,均在训练过程中产生了模式崩溃的问题。因此,在每个决策阶段,本文采用WCGAN方法对数据进行生成。 图6 WCGAN损失下降 首先,按照属性重要度从高到低排序(图7),其次,根据特征重要度构建6层多粒度结构。在各决策阶段,特征数量递增,而新加入的特征重要度递减,以此为基准在不同的特征集合下构造粒度层。例如,第0层仅包含重要度排序前100位的特征,而第6层包含所有特征。将所有特征按照重要度从高到低排序后重新标记为V={V1,V2,…,Vn},其中V1为重要度最高的特征。则粒度划分如下: 图7 特征重要度图 第0层,G0={V1,V2,…,V100}; 第1层,G1={V1,V2,…,V200}; …… 第i层,Gi={V1,V2,…,V100×(i+1)}; …… 第6层,G6={V1,V2,…,V630}。 由于不同的异常用户带来的损失并不确定,但根据3.2节的阈值设置规律:将异常用户判断为非异常用户的代价远远大于将非异常用户判断为异常用户的代价,且误分类代价远远大于模型的测试代价。根据参考文献[11]和文献[20]中序贯三支决策代价的设置方式,本文采用相对成本的方式表示决策代价矩阵如表3。 表3 代价矩阵 根据4.4节,本实验采用WCGAN进行数据生成,利用LightGBM分类模型进行多阶段决策,可得到不同粒度层的分类结果,如表4。 表4 S3WD不同粒层的分类结果 此外,选取了5种常用的分类算法与本实验提出的S3WD框架进行比较,包括:随机森林(RF)、LightGBM、XGBoost、CatBoost和单粒度的GANs-LightGBM模型。前4种集成算法都未使用GANs模型,并且只进行一次二支决策。传统的分类算法均不考虑延迟决策带来的测试代价,因此决策代价仅来源于误分类代价,即λPN=70,λNP=30。6种异常用户检测方法在各指标上的效果如表5。 从表5可以看出,S3WD在精准率、F1值、AUC值和平均检测代价上优于其他分类算法。由于使用GANs作为新的过采样方法,并结合LightGBM集成分类算法,一定程度上提高了分类鲁棒性,使得模型在多个指标上表现出较优的性能;序贯三支决策模型在降低决策成本中的所发挥的作用,由于边界域的存在,S3WD方法具有更多的试错机会,比一次性二支分类方法的误分类成本更低,并且对于部分测试样本,其能在少量信息的情形下做出决策,使得总的检测代价较低。这充分说明了本文所提出方法在用户异常检测中的有效性。 表5 实验结果 已有的机器学习算法已经在异常用户识别上实现了强大的分类预测能力,但大多数算法都是代价不敏感的,导致实际应用价值不高。因此,本文借助了序贯三支决策模型具有较低决策代价的优势,并同时利用生成式对抗网络和集成学习方法增强模型的泛化能力,提出了一种具有实际应用价值的异常用户检测方法。未来的研究中将会利用序贯三支多粒度模型解决面向多模态数据的异常检测代价敏感问题。3.2 三支决策阈值的确定

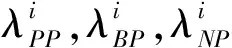
3.3 检测代价的计算


3.4 算法描述


4 实验结果与分析
4.1 实验设计
4.2 评价指标
4.3 实验数据及参数设置
4.4 GANs模型的选择


4.5 序贯三支多粒度结构的构建


4.6 实验结果与分析


5 结束语
