基于XGBoost的医药专利多标签文本分类
2021-11-05戴佩娟贺春林山岳玉蓉
戴佩娟, 贺春林, 山岳玉蓉
(西华师范大学 计算机学院, 四川 南充 637000)
0 引言
在大数据时代,对专利数据的有效利用,能够为企业单位研发人员提供极大的帮助.专利信息资源是一种重要的科技信息源,是科研人员和科技情报工作者在实际工作中经常需要检索的重要参考资源,加之医药行业的特殊性,医药专利数据是药物信息分析的重点与难点.
文本分类在国内外的研究已基本趋于成熟,只是在不同的文本分类中不同的模型和算法表现得效果不同.而对于专利文本分类的研究,在深度学习上很少.目前,在对专利的标引工作中,大多只运用了强约束策略式标引、人工标引两种,而前者是其领域的权威者由自己所积累的行业知识来确定匹配规则,缺点是领域权威者自身意识的限制,对知识的了解和掌握也无法保证全面,准确率和查全率无法满足需求;后者效率低,对人力资源消耗巨大.这两种方式都不适合大数据专利知识下的标引分类工作.
文本分类技术发展过程从最开始的专家系统、慢慢发展到后来的机器学习、到现在还将深度学习应用到了这个领域.专利数据分类进一步利用了基于自然语言处理(NLP)的方法[7]、基于语义分析的方法[8]、基于规则的方法[9]、基于属性函数的方法[10]和基于神经网络的方法[11].所以本文的研究内容和创新点是提供一种基于XGBoost模型进行专利自动分类的方法,通过理论和实验结果证明XGBoost模型对医药专利标签的分类相比于其他深度学习模型准确率更高.
1 相关研究
本实验设计了一种医药专利大数据自动分类方法,使用NLP方式,在医药技术方面构造了词典,并且利用计算机来提取医药专利特征,使模型以高准确率、高速率地完成医药专利自动分类工作,对医药专利信息做到了有效利用、整合研究和应用创新,拥有满足需求的高查全率和高查准率.针对医药专利大数据分别设计了下列三种模型,第一种基于XGBoost的模型,在模型中使用sklearn中的TfidfVectorizer这个类来提取文本特征,使用TF-IDF对数据进行分词,XGBoost用'binary:logistic'参数选择二分类,并用OneVsRest -Classifier将其转换为多标签分类.调整参数训练模型使训练所得的模型效果最佳,最终查准率可以达到0.970219,查全率可达0.832452.第二种设计了添加注意力机制的双向长短时记忆网络模型.在数据预处理时,对比了三种词干化技术,最终采用了NLTK的ISRI来数据词干化,再对比GloVe(Global vectors for word representation)、Word2Vec(Word to Vector)进行数据向量化,选择对于此实验更优的GloVe词向量方式,并使用keras中的Tokenizer进行分词,将双向LSTM和Attention机制相结合,用深度学习方法解决标签分类问题,调整模型结构和参数,最终训练所得效果优秀,查准率可达到0.8951,查全率可达到0.8898,基本接近百分之九十,但比XGBoost的模型差.第三设计了一种基于文本卷积神经网络TextCNN的模型.在数据预处理方式上与第2种模型相同,使用GloVe进行词向量化,再加embedding层,然后将数据传入模型中,模型中选取维度为3、4、5的不同卷积并行操作,其中有两次卷积,一次池化操作、6次全连接层压缩维度,最后由softmax激活函数进行分类.在训练过程中不断调整模型,选取Adam优化器对模型进行优化,训练效果趋于稳定,但效果一般,查准率只能达到0.82897,查全率只有0.669222.
1.1 XGBoost理论原理
XGBoost(extreme gradient boosting decision tree)是由陈天奇等[14]研发的一个开源机器学习项目,它本质上是一个梯度提升决策树(gradient boosting decision tree,GBDT),采用了boosting思想,基本思路是将基分类器层层叠加,每一层在训练的时候,对前一层基分类器分错的样本,给予更高的权重.
XGBoost的目标函数为:
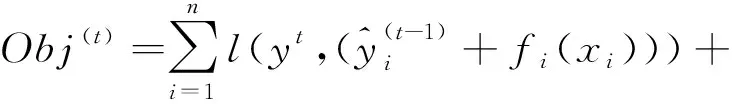
(1)
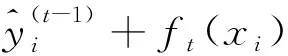
XGBoost树的构造方法是将一个节点延伸出两个分支,一层层的节点不断分裂最终就形成了整棵树.树节点的分裂方式有两种,枚举所有不同树结构的贪心算法、近似算法.贪心算法是从树深度0开始,每一节点都遍历所有的特征,对于某个特征,先按照该特征的值排序,再线性扫描该特征来确定最好的分割点,最后对所有特征进行分割后,选择增益最高的特征.计算Gain增益的方式:
(2)
近似算法针对大数据,通过特征的分布,按照百分比确定一组候选分裂点,遍历所有的候选分裂点来找到最佳的分裂点,这时遍历的范围便变小了.
1.2 Bi-Lstm+Attention理论原理
由于医药专利文本说明性较长,长文本较多,为解决在文本处理中长文本的梯度消失的问题,引入了LSTM的模型,它比起普通的循环神经网络,多了三个门的概念:遗忘控制门、输入控制门、输出控制门.遗忘控制门用来确定上一个隐藏层状态的信息哪些是重要的,输入控制门用来确定当前状态的哪些信息是重要的,输出控制门用来确定下一个隐藏层状态.
LSTM的细胞结构图1如下:
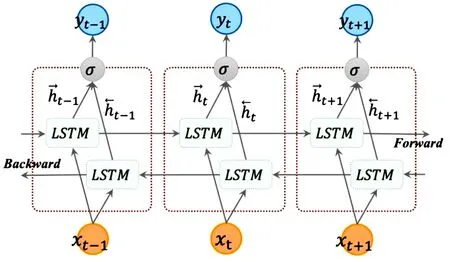
图1 LSTM细胞结构
LSTM就是为了解决长期依赖问题而生的,LSTM通过刻意的设计来避免长期依赖问题.图1中最上方平行的一条线可称为“主线”,贯穿整个链,只进行少量的信息交互,信息流保持不变会很容易.但LSTM却还无法解决上下文关联的问题,有些预测可能需要由前面若干输入和后面若干输入共同决定,这样会更加准确.因此提出了双向循环神经网络,网络结构如图2所示.

图2 Bi-LSTM结构
注意力机制是从序列数据中学习到每一个节点的权重,并按权重将节点合并.是为了将专业有辨别性的词语赋予更高的权重值,提高分类效果.Attention机制加入了三个新变量,查询(query),键值对(keys,value).计算时,首先是将向量query和向量key来进行点积,向量拼接,感知机等方式获取相似度,计算结果当作权重;其次使用一个激活函数来对权重归一化;最后将键值value和计算出来的权重一一对应求和,这就是Attention的值.
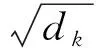
1.3 TextCNN理论原理
由于训练数据过大,在前两次模型训练过程中,训练时间过长,选择训练速度快的TextCNN作为第三种模型.TextCNN(文本卷积神经网络,Text Convolutional Neural Network),是专门用来解决文本任务的卷积神经网络,它同多窗口大小的n-gram方式相似,使用多个不同尺寸窗口来提取文本关键信息,具有很好的局部相关性,能够解决文本之间上下文联系性无法在卷积神经网络中获得很好的表示方式的问题.
TextCNN的一个很大的优点就是训练速度极快,实际上可以将它看作是使用一维卷积的方式获取句子中多窗口的言语特征.它在短文本领域的效果很优秀,因为它对于浅层特征的提取效果非常好,例如搜索、对话等方面应用时效果很好;而对于长文本领域,由于它依赖多窗口来获取文本之间的联系,在长文本关系获取的方面能力不足,还不能很好地获取语言先后顺序、时态等特征,不能很好地发挥自己的作用.
2 实验模型
本实验使用TF-IDF算法提取文本特征,主要思想是,如果某个词或短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类.再采用OneVsRestClassifier进行包装.它使用OnevsRest算法,也是一个评价器.它的原理是使用多个基分类器,其中每一个都是一个二分类,那么就可以由此组成一个多分类器.例如,对于一个特定类,其中一个二分类器一共有两个值,若测试类属于该类为1,不属于为0,就可以将该类和其他类区分开来,通过依次对多个二分类分类器执行上述操作,以此将多分类转为二分类任务.医药大数据专利的技术类型共有12个类,每个类由此算法划分成为12个训练集数据,将12分类变成12个二分类喂入XGBoost模型中.XGBoost模型结构如图3所示:

图3 XGBoost模型结构
基于Bi-LSTM+Attention模型结构如图4所示.在模型中,使用了两个双向LSTM层,在训练时选择了两个和三个双向LSTM层,但最终结果显示,两个双向LSTM层的效果更好.整个训练过程包括GloVe方法所训练的词向量、文本分词、训练模型.

图4 Bi- LSTM+Attention模型结构
TextCNN模型结构如下图5,该实验中filter_window_size=3,4,5,第一次卷积操作每个size下有num_filters = 256个卷积核,第二次卷积核操作每个size下有num_filters = 128个卷积核.在卷积操作后用BN进行数据归一化,使用relu激活函数.在两次操作之后进行最大池化,池化尺寸为4.最后将三个数据拼接起来,经过全连接层,dropout防止过拟合,最后压缩维度,使用softmax进行多分类.其中优化器使用的是Adam优化器,数据的度量方法为MSE,自定义了loss函数binary_focal_loss.

图5 TextCNN模型结构
3 实验与结果分析
3.1 实验数据集
本文数据集选取的是欧洲专利局的汤森路透医药专利数据,使用十七万标引数据用来训练模型,将其按照8∶2划分为训练集和测试集.通过人工标引将其划分为十二类医药专利类型.本实验要做的是将医药数据标引完成后针对专利技术类型对医药专利分类,医药大数据总字段数据说明专利公开号(openno)、专利技术类型(class)、标题(title)、摘要(abstract)、IPC分类号、权利要求(claim).实验主要是通过专利文字说明是否包含关键词来判断其为某一个技术类型.将数据分为三个部分,序列,文本说明,标签,训练时文本说明为X,标签为Y.源数据中专利技术类型组成如下:

表1 专利类型组成中英文对照表
3.2 实验评价指标
查准率:
Percision=TP/(TP+FP),
(3)
查全率:
Recall=TP/(TP+FP),
(4)
平衡因子F1:
(5)
查全率和查准率之间是互相影响的,理想状态下应该是都高,但是一般情况下查准率高,查全率就低,查全率低,查准率就高.所以用平衡因子F1来作为一个平均查准率和查全率的评价指标.它被定义为查全率和查准率的调和平均数.
3.3 XGBoost参数调优
该实验设置参数如下:max_depth, n_estimators, colsample_bytree, objective, scale_pos_weight,n_gpus,min_child_weight, gamma,subsample, learning_rate, reg_lambda.初始设置参数各个值为:8,200,0.8,1,binary: log -istic,0,0,mlogloss, 0,1,0.1,0.1.在经过一系列参数调整后,实验的参数为各个参数值为10,1200,0.8,1,binary:logistic,0,0, mlogloss,0.3,0.6,0.1, 0.1.最后再对max_depth和n_estimators进行调整得到如下结果:
由表2可以得出,max_depth=1200时模型效果最好,n_estimators=18时模型效果最好.所以模型选择max_depth=1200,n_estimators=18作为参数值.最后模型的最优结果为:precision=0.970 219,recall=0.832 452,f1:= 0.893 577.

表2 XGBoost参数调优
3.4 实验结果对比分析
本文将同样的训练集和测试集在另外两个不同的基于深度学习的网络模型,分别为:Bi-LSTM+Attention和TextCNN来做对比.得到的对比结果如下:

图6 两层Bi-LSTM+Attention模型训练结果

图7 TextCNN模型训练结果
在查准率、查全率和F1三个指标的综合对比下,XGBoost是最好、最稳定的,BiLSTM+Attention的F1因子过低,TextCNN相对稳定,但指标都偏低.以上分析可知,三种模型中,XGBoost模型训练所得的模型效果最佳,准确率可以达到0.970 219,查准率可达0.832 452.将Bi-LSTM和Attention机制结合,用深度学习方法解决标签分类问题,训练所得效果优秀,准确率可达到89.51%,查准率可达到88.98%,基本接近百分之九十,但比XGBoost差.选取文本分类卷积神经网络TextCNN模型,训练效果趋于稳定,但效果一般,准确率只能达到0.828 970,F1到达0.722 131.所以该医药大数据实验选取的最优模型为XGBoost.三种模型的结果对比见图8.

图8 三种模型结果比较
4 总结
XGBoost模型的精度更高,灵活性更强,医药专利分类对专业名词的关注更多,而相似的专利分类的相似专业名词有很多,只是在某些细微之处有差别.XGBoost在使用决策树进行文本分类时,能够一步步由节点分类使得相似类逐渐化为多类,而非在一个容器中直接划分,更适合处理医药专利数据的分类.Bi-LSTM+Attention能够处理长文本,且形成上下文关联,使得权重落在医药专利名词上,但由于医药专利的分类对上下文关联性要求不高,得到的效果无法匹敌XGBoost.TextCNN在训练中虽然发挥了其速度快的功效,但CNN处理文本分类在精度上还欠佳.实验结果同时验证,XGBoost模型更优.
综上所述,在对专利类英文文本分类问题上,与BiLSTM模型+Attention和TextCNN模型对比,本文提出的基于XGBoost模型的文本分类方法效果更优.但医药药品专利除了英文的专利还有其他语言的药品专利,在未来的研究中,我们将收集更多数据来进行研究分析,以找到更优的适配算法.
