融合上下文信息的篇章级事件时序关系抽取方法
2021-11-05史存会俞晓明程学旗
王 俊 史存会 张 瑾 俞晓明 刘 悦 程学旗,3
1(中国科学院计算技术研究所数据智能系统研究中心 北京 100190) 2(中国科学院网络数据科学与技术重点实验室(中国科学院计算技术研究所) 北京 100190) 3(中国科学院大学 北京 100049) (wyswangjun@163.com)
文章如新闻通常描述一系列事件的发生,这些事件看似离散地被叙述着,其实存在着一定的联系,其中最重要的一种事件联系为时序关系.时序关系表示事件发生的先后顺序,其串联了文章中事件的发展演化.如果能准确地抽取文章中的事件时序关系,将有助于理解文章信息,梳理事件脉络.因此,事件时序关系抽取成为了一项重要的自然语言理解任务,受到越来越多的关注.
事件时序关系抽取的目标为抽取文本中包含的事件时序关系,如图1中的例子,其包含4个事件:刺杀(E1)、暴行(E2)、屠杀(E3)和内战(E4),其中可抽取出时序图中的6对事件时序关系.图1中时序关系BEFORE表示事件在另一个事件之前发生;时序关系INCLUDES表示一个事件包含另一个事件;时序关系VAGUE表示两个事件之间不存在特定的时序关系.

Fig.1 An sample of event temporal relation extraction图1 事件时序关系抽取样例
目前,与实体关系抽取[1]类似,已有的事件时序关系抽取方法往往将事件时序关系抽取任务视为句子级事件对的分类问题,以事件对和事件对所在的句子信息作为输入,使用基于规则、基于传统机器学习或基于深度学习的方法识别事件对的时序关系类别.然而,这种句子级的事件时序关系抽取方法使用的事件对所在的句子信息十分有限,往往不足以支持事件时序关系的识别,限制了事件时序关系识别的精度.同时,句子级的事件时序关系抽取方法孤立地识别事件对的时序关系,未考虑文章中其他事件对的时序关系,其抽取的事件时序关系可能与其他事件时序关系冲突(即不满足时序关系的自反性、传递性等),使得全文的事件时序关系一致性难以得到保证.
为此,本文提出一种融合上下文信息的篇章级事件时序关系抽取方法.该方法使用基于双向长短期记忆(bidirectional long short-term memory, Bi-LSTM)的神经网络模型学习文章中每个事件对的时序关系表示,再使用自注意力机制学习待识别事件对与其文章上下文中其他事件对的联系,利用联系结合上下文中其他事件对的信息,得到更优的事件对的时序关系表示,从而增强事件时序关系抽取模型的效果.为了验证模型的性能,本文在TB-Dense(timebank dense)数据集[2]和MATRES(multi-axis temporal relations for start-points)数据集[3]上进行实验,实验结果证明本文方法的有效性.
1 相关工作
按照事件时序关系抽取研究的发展,其方法主要可以分为3类:基于规则的事件时序关系抽取方法、基于传统机器学习的事件时序关系抽取方法和基于深度学习的事件时序关系抽取方法.
1.1 基于规则的事件时序关系抽取方法
事件时序关系抽取研究发展的早期,由于缺乏相关的成熟语料库,主流的事件时序关系抽取方法通常是基于人工制定的规则展开的.Passonneau[4]提出使用文本中的时态与体态信息来构造规则,用以推断事件的时序关系.Hitzeman和Moens等人[5]提出的话语时序结构分析方法,考虑了时态、体态、时间状语和修辞结构的影响.
基于规则的方法实现简单,但其效果极大地依赖于规则的数量和质量,其实用性不高.
1.2 基于传统机器学习的事件时序关系抽取方法
随着国际标准化组织制定了TimeML[6](time markup language)标注体系,以及时序关系抽取领域的一些重要标准数据集(如TimeBank[7])的构建.传统的统计机器学习方法开始被广泛应用于事件时序关系识别研究.Mani与Schiffman等人[8]提出基于决策树分类模型的新闻事件时序关系识别方法,该方法使用时序关系连接词、时态、语态和时间状语等特征.之后,Mani等人[9]又提出基于最大熵分类算法的时序关系分类方法,使用数据集给定的TimeML特征(如事件类别、时态、体态等).Chambers等人[10]在Mani等人提出方法的特征之上,添加了词性、句法树结构等词法和句法特征,以及WordNet中获得的形态学特征,较之前的方法有了3%的提升.Ning等人[11]使用手工制作的特征作为输入,在训练过程中对全局的事件时序关系结构进行建模,利用结构化学习优化时间图的全局一致性.
基于传统机器学习的事件时序关系抽取的方法研究重点主要集中在特征工程,方法的有效性极大地依赖于特征工程的设计.
1.3 基于深度学习的事件时序关系抽取方法
随着深度学习技术的发展与兴起,神经网络模型被引入到事件时序关系抽取任务中来.Meng等人[12]提出一种简单的基于LSTM(long short-term memory)网络结构的事件时序关系抽取模型.该模型以事件之间的最短的句法依赖关系路径作为输入,识别相同句子或相邻句子中的事件时序关系类别,在TB-Dense数据集上取得不错效果.类似地,Cheng等人[13]采取最短句法依赖关系路径作为输入,构造了一种基于双向长短期记忆的神经网络模型,同样取得不错的效果.之后,Han等人[14]提出了一种结合结构化学习的神经网络模型.该模型包括递归神经网络来学习成对事件时序关系的评分函数,以及结构化支持向量机(structured support vector machine, SSVM)进行联合预测.其中神经网络自动学习事件所在情境的时序关系表示,来为结构化模型提供鲁棒的特征,而SSVM则将时序关系的传递性等领域知识作为约束条件,来做出更好的全局一致决策,通过联合训练提升整体模型性能.
基于深度学习的事件时序关系抽取方法,相较于基于传统机器学习的方法,能自动学习并表示特征,无需繁杂的特征工程且模型性能更高而泛化性能力更强,如今已经成为了事件时序关系抽取领域的研究趋势.
2 结合上下文的篇章级事件时序关系抽取
现有的事件时序关系抽取方法,无论是基于规则还是基于传统机器学习或深度学习,其本质上都是一个句子级的事件对的时序关系分类器.其实现方式为
rij=f(sentij),
(1)
其中,rij表示任意事件对ei,ej的时序关系,f为时序关系分类器,sentij为事件对所在句子.可以看出时序关系rij仅基于事件对所在的句子信息,而这有限的局部信息导致识别的精度较低且无法保证全文整体的时序关系的一致性.
针对句子级事件时序关系抽取方法的局限性,本文提出结合上下文信息的篇章级事件时序关系抽取模型.可形式化为
rij=f(sentij,contextij),
(2)
其中,contextij为事件对ei,ej的上下文,即事件对所在文章信息.
2.1 上下文信息增强的事件时序关系抽取模型
本文提出篇章级的事件时序关系抽取模型,称为上下文信息增强的事件时序关系抽取模型(context information enhanced event temporal relation extraction model, CE-TRE).模型的整体框架如图2所示,主要包含3个部分:1)事件对的时序关系编码模块;2)事件对的上下文增强模块;3)输出模块.其中,我们分别将每个事件对的句子级时序关系表示Sk通过全连接层得到Query:Qk,Key:Kk,Value:Vk.CE-TRE模型以文章作为基本输入单元.按照事件对分句后,事件对的时序关系编码模块使用基于Bi-LSTM的神经网络模型学习事件对的时序关系表示;事件对上下文增强模块利用自注意力机制结合上下文中其他事件对的信息,得到更完备的事件对时序关系表示;输出模块根据事件对时序关系表示预测事件对的时序关系类别.

Fig.2 Context information enhanced event temporal relation extraction model图2 上下文信息增强的事件时序关系抽取模型
2.2 时序关系编码模块
时序关系编码模块用于初步编码每个事件对的句子级时序关系表示.CE-TRE模型以文章作为输入单元,对于每个文章输入,先将其按一个个事件对把文章分为一个个句子(存在一个句子包含多个事件对的情况),得到所有事件对的所在句子集合.时序关系编码模块就以每个事件对的所在句子作为输入,编码事件对的句子级时序关系表示.具体如图3所示.
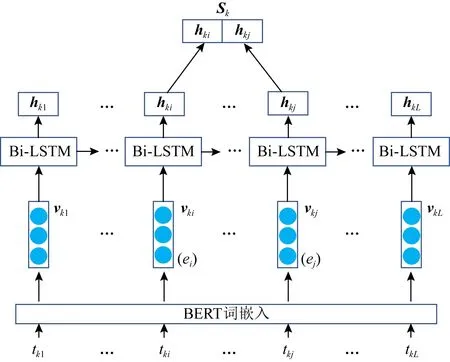
Fig.3 Temporal relation coding module图3 时序关系编码模块
给定事件对所在的句子(可以是单独的1个句子或连续的2个句子),表示为tk=(tk1,…,tki,…,tkj,…,tkL),其中k表示该句子是文章按事件对分句后的第k个句子,tki和tkj为事件对应的词.
首先本文使用预训练好的BERT[15]模型计算每个词的词嵌入vki,得到句子的向量表示sentk.使用BERT计算词嵌入的目的是为了得到上下文有关的词向量表示,使得后续模块能更好地学习事件对的时序关系表示.因为预训练的BERT只用于计算词向量,不参与整体模型的训练,因此不会影响整体模型的训练难度.形式化过程为
sentk=(vk1,vk2,…,vkL)=EmbeddingBERT(tk).
(3)
接着,将事件对所在句子sentk通过Bi-LSTM模型,可以得到句子长度的隐藏状态序列Hk=(hk1,…,hki,…,hkj,…,hkL).将2个事件的位置(i和j)相对应的隐藏状态hki和hkj串联起来,得到事件对的句子级时序关系向量表示Sk=(hki;hkj).上述过程可形式化为
(hk1,hk2,…,hkL),hkL=Bi_LSTM(sentk,hk0),
(4)

最后,1个句子可能包含多个事件对,因此本模块针对1个句子输入,可能输出多个事件对向量表示,一起汇总成文章的事件对表示集合.
2.3 事件对上下文增强模块
本文将时序关系编码模块得到的每个事件对的句子级的时序关系表示,输入到事件对上下文增强模块,得到上下文信息增强的事件对时序关系表示.具体如图4所示:

Fig.4 Context enhancement module for event pairs图4 事件对上下文增强模块

Fig.5 Self-Attention diagram图5 Self-Attention示意图
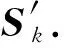

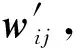
(5)

(6)
该过程可简写为

(7)
2.4 输出模块
本模块用于输出事件对的时序关系的分类预测值.如图6所示,本模块将上下文增强后的事件对时序关系表示,通过一层全连接层和用于分类的softmax层,得到该事件对的T维的时序关系概率向量Rk.其中第j个元素表示将其判别为第j个时序关系类型的概率值.我们采用真实时序关系类型和预测概率的交叉熵误差作为损失函数:
(8)
其中,N为事件对总数,I为指示函数.

Fig.6 Output module图6 输出模块
3 实 验
本节主要介绍实验部分的相关细节.首先介绍本文所使用的公开数据集与实验的评价指标,接着介绍实验对比的基线方法,随后介绍实验的参数设置,最后对实验结果进行分析与探讨.
3.1 数据集与评价指标
本文在公开的TB-Dense和MATRES数据集上对模型的效果和性能进行评估,这2个数据集的规模信息如表1所示:
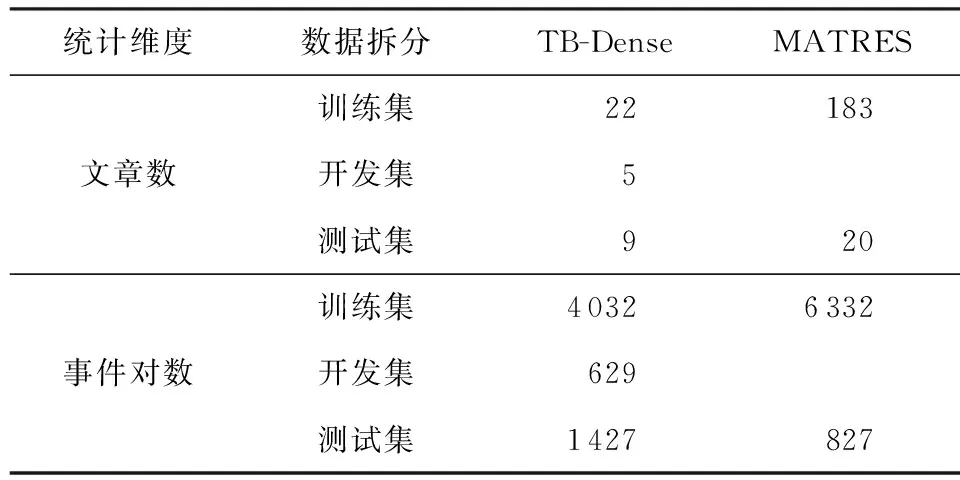
Table 1 Statistics of TB-Dense and MATRES Datasets表1 数据集TB-Dense和MATRES的规模统计
表1详细说明为:
1) TB-Dense数据集是Cassidy等人[2]基于TimeBank数据集,通过标注相同或相邻句子中的所有事件对的时序关系,构建的稠密标注语料,解决了TimeBank的标注稀疏性,近年来已被广泛应用于事件时序关系抽取研究.TB-Dense包含6类时序关系:VAGUE,BEFORE,AFTER,SIMULTANEOUS,INCLUDES,IS_INCLUDED.
2) MATRES是Ning等人[3]在2018年基于TempRels3数据集(TempEval第3次评测任务[17]构建的数据集,包括TimeBank,AQUAINT(advanced question-answering for intelligence),Platinum)构建的新数据集.该数据集通过使用多轴注释方案并采用事件起点比较时序来改进注释者之间的一致性,进一步提高了数据质量,成为近几年来值得关注的一个新数据集.MATRES只包含4类时序关系:VAGUE,BEFORE,AFTER,SIMULTANEOUS.
为了与已有相关研究进行对比,本实验采用2套微平均F1值作为评价指标,具体为:
1) 针对数据集TB-Dense,使用全部6个时序关系类别的Micro-F1.
2) 针对数据集MATRES,使用除了“VAGUE”外的3个时序关系类别的Micro-F1.
3.2 基准方法
1) CAEVO.Chambers等人[18]于2014年提出的有序筛网式流水线模型.其中每个筛子可以是基于规则的分类器,也可以是机器学习模型.
2) CATENA.Mirza等人[19]于2016年提出了多重筛网式的事件关系抽取系统,可利用时序关系抽取模型和因果关系抽取模型之间的交互作用,增强时序和因果关系的提取和分类.
3) 文献[13]方法.Cheng等人[13]于2017年提出了一种基于双向长短期记忆(Bi-LSTM)的神经网络模型,该模型采取最短句法依赖关系路径作为输入,能达到与基于人工特征相当的性能.
4) 文献[20]方法.Vashishtha等人[20]于2019年提出了一个用于建模细粒度时序关系和事件持续时间的新语义框架,该框架将成对的事件映射到实值尺度,以构建文档级事件时间轴.基于此框架,训练模型联合预测细粒度的时序关系和事件持续时间.
5) 文献[21]方法.Meng等人[21]于2018年提出了上下文感知的事件时序关系抽取的神经网络模型,模型以事件最短依存路径作为输入,按叙述顺序储存处理过的时序关系,用于上下文感知.
6) 文献[22]方法.Han等人[22]于2019年提出了一种具有结构化预测的事件和事件时序关系联合抽取模型.该模型让事件抽取模块和事件时序关系抽取模块共享相同的上下文嵌入和神经表示学习模块,从而改善了事件表示.利用结构化的推理共同分配事件标签和时序关系标签,避免了常规管道模型中的错误传递.
3.3 实验参数设置
CE-TRE中,Bi-LSTM层的输出维度为100,线性层的输入维度为400和100;模型训练的batch_size大小为1(因为篇章级的事件时序关系抽取以文章为基本单位 ,一篇文章包含若干的事件对).
此外由于篇章级时序关系抽取以文章为输入单位,而不同文章包含的事件对的数目是不同的.这种差异导致不同batch包含的事件对数目存在明显差异,如果使用一样的学习率进行训练,会使得模型更新不均衡,导致模型优化过程不稳定.因此,本文使用的解决策略为设置动态学习率,为包含事件对多的文章样例增大学习率,即学习率与事件对数目正相关:
(9)
其中,lr_base为基准学习率,设置为0.000 1;lr_decay为学习率衰减,设置为0.9,每5轮进行1次衰减;rel_num为文本包含的事件对数目,学习率与其成正比.
3.4 实验结果与分析
为了验证本文提出的模型CE-TRE在不同数据集上的抽取效果,本文选取了近几年的主流模型(如3.2节所述)与CE-TRE在公开的TB-Dense和MATRES数据集上进行对比实验.
3.4.1 验证CE-TRE模型性能
实验1.在TB-Dense数据集上验证CE-TRE模型性能.
在数据集TB-Dense上实验的原因是该数据是事件时序关系抽取任务的传统数据集,有着充分的前人工作可以对比.实验结果如表2所示, 与近几年的主流模型对比,本文提出的CE-TRE模型在TB-Dense取得了最高的Micro-F1评分,这说明CE-TRE模型很有竞争力.
实验2.在MATRES数据集上验证CE-TRE模型性能.
在数据集MATRES上实验的原因是该数据是个新的标注质量更高且数据规模更大的数据集,可以进一步验证本文提出模型的效果.实验结果如表3所示,在MATRES数据集上,本文提出的CE-TRE模型的效果优于2019年最优的文献[22]方法[22].

Table 2 Comparative Experiment of CE-TRE and 6 Baselines on TB-Dense

Table 3 Comparative Experiment of CE-TRE and the Best Baseline on MATRES
3.4.2 验证结合上下文信息对模型的增强效果
实验3.验证结合上下文的有效性.
为了验证结合上下文信息,是否对事件时序关系抽取模型有着增益效果,本实验对比有无上下文信息增强的模型的效果.实验结果如表4所示,在2个数据集上,结合上下文信息的CE-TRE模型均优于未结合上下文信息的TRE(without CE)模型.此结果表明,结合上下文信息确实能够增强事件对时序关系抽取模型的效果.

Table 4 Comparative Experiment Between CE-TREand TRE (without CE)
此外,通过对比2个数据集上的实验结果可以发现,CE-TRE模型相比于TRE模型,在数据集TB-Dense上的性能提升较为显著(采用McNemar检验,所得p<0.005),而在数据集MATRES上的性能差距较小.本文认为原因是:MATRES数据集的标注类别只包含4类,相较于TB-Dense的6类,MATRES中的事件时序关系的识别难度较低.同时,MATRES数据集中的句子平均长度长于TB-Dense数据集,通常情况下,MATRES的句子包含的时序关系信息也会更多.这2点使得未结合上下文信息的TRE模型在MATRES数据集上也能取得较高的得分,从而CE-TRE模型相比TRE模型提升较小.同时,TRE(without CE)模型在2个数据集上的性能还优于许多基线模型,本文认为:TRE虽未结合上下文信息,但模型的训练方式和CE-TRE一样,以文章作为单位输入,使得模型的每次更新优化只针对1篇文本的数据,可以集中学习每篇文章所属文意的时序关系,从而学习出更优的模型.
3.4.3 实验结果样例分析
如表5中的样例,需判断事件E1与事件E2之间的时序关系.对于未结合上下文信息的事件对时序关系识别模型TRE,其预测结果为“VAGUE”,预测错误.而结合上下文信息的事件对时序关系识别模型CE-TRE的预测结果为“BEFORE”,预测正确.通过分析样例可知,TRE预测错误的原因是样例的句子信息不足以判别事件对的时序关系.而CE-TRE通过结合上文中的“1991年,查尔斯·基廷在州法院被判协助诈骗数千名投资者,这些投资者购买了基廷在林肯储蓄贷款公司员工出售的高风险垃圾债券.”的信息可知,基廷于1991年被判协助诈骗,导致投资者购买了垃圾债券,之后债券变得一文不值.由此推断1996年基廷的判决被推翻发生在债券变得一文不值之后.

Table 5 A Sample from TB-Dense Dataset表5 来自TB-Dense数据集的样例
由TRE和CE-TRE在样例上的预测结果进一步验证了结合上下文的有效性.
综合实验1和实验2的结果,本文提出的CE-TRE模型在2个数据集上均取得优于近年来的最新模型,说明了本文方法的有效性.其次通过对比有上下文增强的CE-TRE模型和无上下文增强的TRE(without CE)模型的评分,以及两者在表5中样例的预测结果可以看出,结合上下文信息确实能够增强事件对时序关系抽取模型的效果.
4 总 结
事件时序关系抽取技术是一种从文本中获取事件的时序结构信息的重要手段,有着很高的研究价值和实用价值.现有的事件时序关系抽取方法往往都是句子级的抽取方法,存在时序关系识别精度低且无法保证全文一致性的问题.本文提出了一种融合上下文信息的篇章级事件时序关系抽取方法,并通过TB-Dense数据集和MATRES数据集上的多组实验验证了本文方法的有效性.
目前事件时序关系抽取的数据集规模都较小,限制了神经网络模型的抽取性能.在未来的工作中,我们将进一步研究如何丰富相关数据集或如何引入外部资源来进一步提升事件时序关系抽取模型的性能.
