基于彩色图像分割的带网格底纹文档笔迹提取方法
2021-11-03常治国
常治国
(中国人民大学 北京市 100872)
1 问题分析
随着基于深度学习的图像识别技术的应用普及,手写体OCR识别被广泛用于小学生作业的识别与自动判卷上。通常小学生使用田字格本做汉字抄写作业,使用4 线英语练习本做英语抄写作业。然而作业本背景网格线的存在导致手写体OCR 识别难上加难,因为底纹叠的存在加大了神经网络的输入数据的方差,输入数据的方差越大,所需的网络模型也就越大越复杂,相应的模型训练难度与预测的算力需求都同步增加,因此,减小数据输入方差是值得尝试的方法。小学生作业练习本的网格线通常包含横线、竖线或斜线,使用颜色为绿色、红色或黑色,如图英语四线抄写本和汉字米字格抄写本均带网格底纹。空白文档无笔迹的情况下,使用经典的Hough 变换直线检测算法即可准确的从文档扫描的二值化图像中检测出这些背景网格线。然而实际应用时图像采集方式往往是相机拍摄而不是扫描仪扫描,作业本存在页面翘曲的情况,另外相机拍摄不可避免有视角倾斜的问题,这些因素导致横平竖直的网格线成像后退化为曲线。此外,笔迹覆盖在网格线之上,网格线会被分割成长短不一的大小线段,因此单纯的基于黑白图像几何特征难以精确分割出所有的网格线。本文通过经典图像处理算法,基于k-means聚类算法,充分利用图像的亮度信息、色彩信息、对象的几何空间分布特征,以较小的计算代价实现了从带网格底纹文档图像中提取笔迹内容,剔除背景噪声与网格线内容。
2 本文方法
通常情况下,小学生抄写文档包含3 种主颜色,即纸张颜色、网格线颜色,以及笔迹颜色,结合网格线的几何特征,本文提出一种几何特征叠加颜色特征的网格线剔除方法,具体步骤为:
(1)对输入的彩色图像Ic进行unsharp mask 操作,以突出浅色的网格线。当相机离焦或者光照过强、过弱的情况下拍照都会导致网格线弱化,但并不会完全消失,unsharp mask 操作属于一种图像边缘增强方法,能有效增强图像中的细线条对象,减弱光照不均匀以及镜头离焦模糊的影像。增强后的图像为Ie,将Ie变换为灰度图像得到Ig。
(2)基于局域自适应二值化算法(localadaptivethresholding, DOI: https://doi.org/10.1007/978-0-387-73003-5_506)对灰度图像Ig进行二值化得到二值图像Ib,0 像素为背景,非零像素为包含网格线和笔迹的部分。局域自适应二值化算法能很好的适应亮度渐变的图像,能在全局范围内有效分离背景色和前景色(前景色包括网格线与笔迹)。
(3)对二值图像Ib进行形态学膨胀(dilate)操作得到膨胀后的二值图像Id,膨胀操作使得笔迹和网格线边缘扩充而覆盖到背景像素区域,这样方便后续步骤选择笔迹和网格线附近的背景像素而不是全部像素参与k-means 聚类算法,对Id与Ib进行按位异或(bitwisexor)操作得到的二值图像作为掩摸mask,用mask 对Ic进行像素选择即可得到与笔迹和网格线相邻的背景像素,膨胀操作的强度越大,选择到的背景像素越多。
(4)以二值图像Id为掩模mask 选择彩色图像Ic的像素,选中的像素包含了网格线、笔迹以及背景,使用K=3 的k-means 聚类算法对选中的彩色像素进行聚类,得到3 簇像素,在3 簇像素中,中心值亮度最大的为背景,两外两簇像素为网格底纹像素和笔迹像素。
(5)由于网格底纹在整个文档内周期性重复,分布均匀,空间分布离散度小,而笔迹在整个文档范围内更大相比较而言分布更为随机,相应的空间分布离散度大,因此剩下的2 簇像素可依据各自的像素空间分布离散度统计量进行类别判定,即对2 簇像素各自生成掩模mask 二值图像,分别计算2 个mask 二值图像的空间分布离散度,离散度小的二值图像对应的像素簇为网格底纹,另一簇像素即为笔迹。
至此我们将背景、网格线、笔迹成功分割,即实现了本文的从带网格线底纹图像中提取笔迹内容的目标。
3 二值图像空间分布离散度计算方法
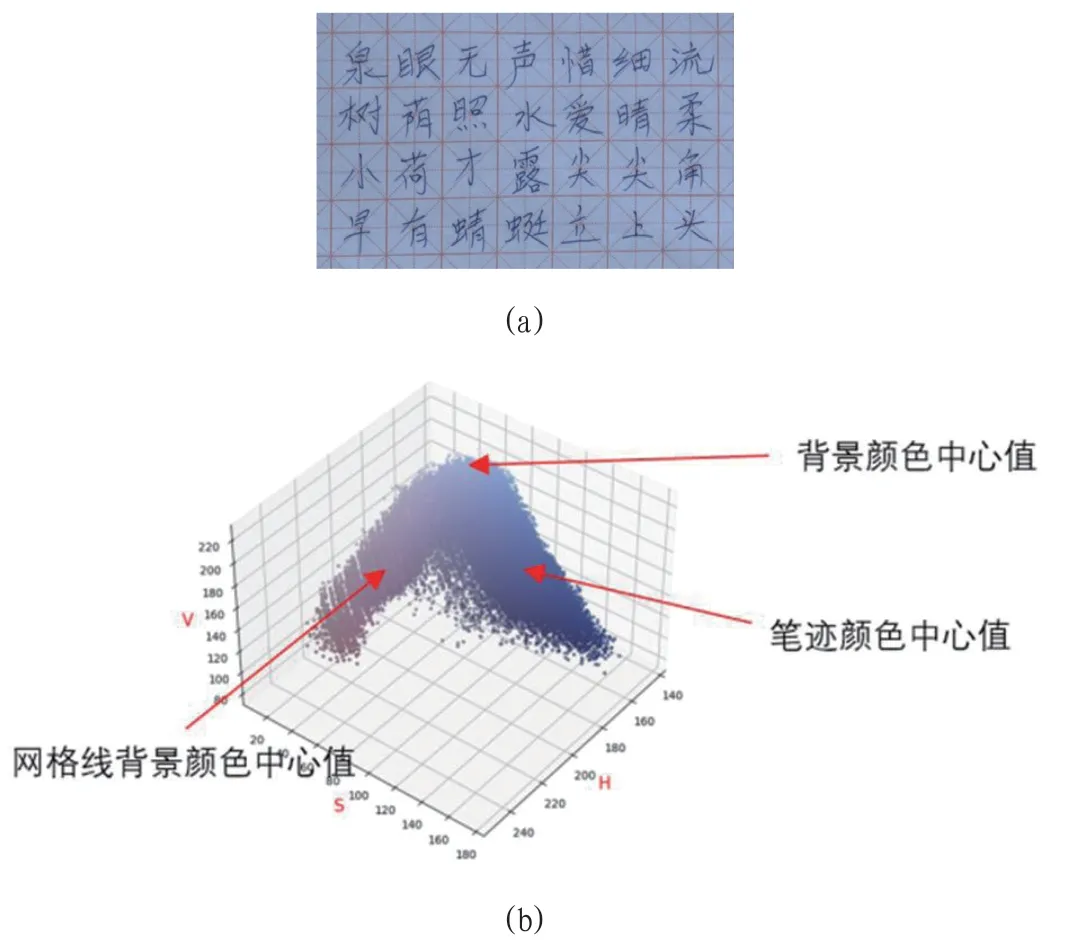
将二值图像划分为R 行C 列无缝拼接且尺寸相等的格子,格子的水平边长大于网格的水平方向重复周期,格子的垂直边长大于网格的垂直方向重复周期。统计每个格子内的非0 像素个数N(r,c),0 ≤r k-means 聚类算法的结果对初始中心点的选择非常敏感,初始中心点选择不当容易导致聚类结果陷入局部最优。本文充分利用输入文档图像的颜色分布与空域结构先验知识,优化选择聚类初始中心点。本文3 个k-means 初始中心点的选取方法: (1)将待聚类的像素集合由RGB色彩空间转为HSV色彩空间,此举目的是减小3 个颜色分量之间的相关性,提高不同类别对象像素之间的颜色空间距离。(参考文献:2005,图像图形学报,彩色图像分割方法综述,文章编号:1006-8961(2005)01-0001-10)。 (2)选择二值图像Id前景色边界像素对应的彩色像素(来自彩色图像Ic)的均值作为第一初始中心点C1(h1,s1,v1),代表背景像素簇。这是因为Id中网格线和笔划的边缘像素已经被扩散到背景区域,因此C1离真实的背景像素颜色中心点不远,作为初始中心点是稳定。 (3)统计HSV 三维色彩空间内的像素分布密度,某种颜色附近的像素越多,对应的三维色彩空间的密度值越大,这里说的密度值与灰度图像的直方图概念对等。如果要精确统计每种颜色的像素密度,8bit 彩色空间总共产生224个密度值,为了减小存储空间的占用,本文采用近似的密度计算方法,具体来说,将三维色彩空间划分为连续等体积的小立方块颜色空间,对每个小立方块颜色空间,计数落入其中的像素个数作为一个密度值采样D(i,j,k),总共得到m*n*p 个密度值,0 ≤i 图1a 为输入的彩色图,图1b 为输入彩色图的HSV 色彩空间3D 散点图,从3D 散点图中可以直观的看到网格线像素簇(偏红色)与笔迹像素簇(偏蓝色)的分布各自集中且互相保持了显著的距离。需要注意的是本文仅选取了笔迹与网格线附近的背景像素参与聚类,因为2D 空间上的相邻导致它们的颜色也必然是连续渐变的,即白色渐变到偏红色,以及白色渐变到偏蓝色,也就是图1b中“背景颜色中心值”箭头所指部分。此外,我们还应观察到“背景颜色中心值”下方亮度明显小于背景色的部分存在偏红色像素和偏蓝色像素平滑过渡融合的情况,这是因为从图像2D 结构上看,蓝色的笔迹一定比例部分覆盖或邻接于偏红色的网格线,笔迹和网格线的叠加和邻接处自然会形成一种混色效果。以上分析表明彩色空间的3D 散点图能直观明了的呈现彩色图像的像素颜色分布特征,对k-means 聚类算法的k 参数选择起到直接的指导作用。如果丢弃颜色信息而仅使用亮度信息进行目标分割,则本身在颜色空间中泾渭分明的两簇像素会混合在一起,必然难以将它们有效分割。本文的实验结果有效证实了这个推断。 图1:输入彩色图与HSV 色彩空间3D 散点图 本文选取传统的“彩色图像转灰度图像,再对灰度图像二值化”的方法做对比实验。图2 为图1a 彩色图像变为灰度图像后,再分别用阈值threshold=150、140、130、120 对其进行二值化的结果,从结果中可以看出,当笔迹完整保留时(threshold=140)网格底纹也被保留了,当网格底纹被滤掉时(threshold=120)笔迹也被丢失了,因此仅凭调节阈值是很难将网格底纹与笔迹分割开。这个结果与图1b 是相吻合的,显而易见垂直V 轴的平面不能将偏红色的像素簇和偏蓝色的像素簇分隔开。 图2:多阈值二值化分割结果对比 图3 为本文方法实验结果,其中a 为图1 进行unsharpmask 增强之后的结果,b 为将a 转换为灰度图像后再进行局域自适应二值化的结果,c 为本文方法提取的笔迹结果,d 为笔迹结果叠加在输入彩色图像上的效果,对比图3c 与图2 以及图3b,本文方法的优势是显而易见的。 图3:本文算法主要步骤输出结果 图4a 为k-means 聚类结果叠加在输入图像上的效果,绿色像素为背景,红色像素为网格,蓝色像素为笔迹,可以看到笔迹像素和网格线像素均被背景像素包围,然而绝大部分米字格的斜线像素被聚类到背景簇了,这是因为网格斜线由小点组成且颜色比较淡,在图1b 散点图中的上部分,离背景色的中心值更近,因而被聚类到背景色簇了,但这并不影响笔迹像素被正确的簇为一类。图4b是与图1b 同源的3D 散点图,区别在于点的颜色不是取自像素的值,而是像素聚类后的标签对应的颜色,3D 散点图直观的展示了色彩空间里的聚类结果,这个结果与前文对图1b 的分析结果是相吻合的。 图4:聚类结果原图叠加效果与3D 散点图效果 本实验使用python 编程语言调用opencv 库与numpy 库完成,为方便读者复现本实验结果,源代码与测试图片可于开源库获取,网址https://www.gitee.com/changzhiguo/stroke。 (1)整个算法的决策路径充分利用了图像的亮度信息、色彩信息、对象的几何空间分布特征,相比传统的仅使用亮度信息或仅使用色彩信息,决策的精度更高。 (2)k-means 聚类算法的输入剔除了大部分的背景像素,仅保留了与网格线和笔迹邻接的背景像素,均衡了输入样本的比例,提高了分类的精确度,同时因为参与分类的像素大幅减少,有效减少了k-means 分类算法的计算量。k-menas 算法的复杂度为O(nkt),其中n 为参与分类的像素个数,k 为分类数,t 为迭代数,由于k和t 取值较小,减小n 能显著降低计算量。 (3)使用统计量C1、C2、C3作为k-means 聚类算法的初始中心点,能保证算法找到全局最优值,同时减小了算法所需迭代的次数。 (4)利用网格线的周期性结构特性,基于二值图像的空间分布离散度统计量来区分聚类结果中的网格线与笔迹。 本方法的不足:本方法仅适用于文档笔迹颜色与网格线颜色不同、且笔记颜色为单一颜色的情形。对于黑色网格线上的黑色书写内容的识别,直接采用端到端的识别方案更为合适。4 k-means初始中心点选择方法
5 实验结果



6 本文方法的创新点
