基于WiFi的分级室内定位*
2021-11-02王行娟
王行娟
(武汉华夏理工学院 信息工程学院,武汉 430223)
0 引 言
随着室内环境中基于位置的服务(Location-based Service,LBS)的需求不断增加,室内环境中的定位成为了研究的热点[1-6],而基于WiFi的定位在室内环境中有较大的优势,原因如下:第一,室内环境中,卫星导航信号被遮蔽,无法提供室内的服务,因此通常将室内环境归于卫星导航拒止环境;第二,基于WiFi的定位不需要额外的硬件,仅需要含有WiFi功能的设备,随着智能手机的普及,这一点也容易满足;第三,许多需要室内定位的场景,如机场、火车站和商场等,都普遍存在许多WiFi信号,不用额外安装。
基于WiFi的室内定位可以分为两个步骤:离线指纹地图(Fingerprint Map,FM)的建立和在线的定位过程。这里的指纹表示在某位置的从不同WiFi接入口(Access Point,AP)的接收信号强度(Received Signal Strength,RSS)。简单来说,信号指纹可以看作一个向量,其中的元素为不同AP的接收信号强度。指纹地图为一个数据库,包含了不同室内几何位置测量得到的信号指纹。获取离线指纹地图的方法在文献[7-9]中有详细的叙述,由于其生成过程一般是事后的离线处理,因此该过程称为离线指纹地图建立。本文主要描述在线的定位过程,将采集的信号指纹与指纹地图中的信号指纹进行匹配,根据匹配结果解算人员的位置。
为了能够快速得到室内的位置,在定位过程中,对实时性的要求很高。然而,一般的匹配过程,如K最近邻法(K-Nearest Neighbors,KNN)算法的复杂度与指纹地图中的样本数目和区域内的AP数目的乘积相关[10]。如果待定位区域范围较大(如商场),并且其总的AP数据较大,可达1 000以上,KNN算法无法达到实时定位的要求。另外,KNN算法需要对不同维度的信号指纹进行补齐,使其维度相同,从而计算信号指纹间的距离,这带来了额外的计算量。
为了减小定位过程中的计算量,达到实时定位的要求,文献[11-15]提出将定位的过程分级,分为粗定位和精定位,其中粗定位一般通过聚类的方法将当前信号指纹归于某一类。这里,一类表示一个较小区域内的所有信号指纹。如果采集到的信号指纹归于某类,说明人员位于这个子区域内,因此叫粗定位。粗定位后,再将信号指纹与该子区域内的指纹进行匹配,从而获取更加精确的位置估计(精定位)。在这些方法中,文献[11-12]提出了用AP(Affine Propagation)聚类算法进行粗定位,文献[13-15]提出用k均值聚类的方法进行粗定位。然而,这些方法中仍然存在计算量较大的问题。每次定位中,新采集到信号指纹被放入指纹地图中的所有信号指纹中进行聚类,相当于每次定位都需要完成一次聚类。文献[16-18]同样利用了粗定位和精定位的框架,其中文献[16]通过当前估计得到的位置对KNN搜索的范围进行对应的缩小,可以有效提高平均定位精度和缩小定位时间。该方法的缺点是,在当前位置估计不准确时可能导致下一次定位误差增大,从而存在较多定位异常值。文献[17]方法同样拥有粗定位和精定位的框架,粗定位中通过编辑距离实现。编辑距离在算法实现上,需要递归地实现,在AP数目较大时,其运算速度仍然较慢。文献[18]利用DS证据理论进行粗定位,为了缓解DS证据理论中的 “指数爆炸”问题,将信号指纹库分成了多个层级,又导致了指纹库生成过程中复杂度大大提高。
本文提出一种基于WiFi的分级定位方法,同样分为粗定位和精定位。粗定位中,手动将定位区域划分为更小的几个固定的子区域,将子区域内的所有信号指纹并集作为新的信号指纹,通过汉明距离(Hamming distance)找到最近的几个子区域后(粗定位),再通过KNN的方法在这些子区域内进行匹配定位。由于该方法的子区域划分固定,可以在定位前一次性完成,相比于基于聚类的方法,不需要每次定位重新进行聚类过程(子区域划分)。实验结果表明,本文的分级定位框架具有延迟低的优点。
1 方法步骤
为了提高WiFi定位的速度和精度,将定位的流程分为粗定位和精定位,图1为整体流程图。首先对原始的指纹地图进行分区,获得子区域的指纹地图合集。

图1 WiFi分级室内定位结构
1.1 粗定位
粗定位的过程中,通过汉明距离匹配采集到的信号指纹和子区域内的指纹得到可能的子区域集合。这里的匹配过程中每个子区域的信号指纹经过处理仅含一个指纹,将在后面详细叙述。精定位中,将采集到的信号指纹和可能子区域集合内的信号指纹进行匹配,这里的信号指纹为指纹地图内的原始信号指纹,最终得到定位结果。本节主要描述粗定位的过程(包含分区的过程)。

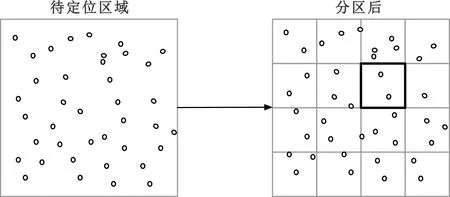
图2 粗定位中的分区过程示意图
信号指纹可以用一个哈希表(Hash map)键值表示,如式(1)所示(这里忽略掉上下标的索引):
(1)
表示信号指纹为一个哈希表,哈希表的键(key)为不同AP的MAC地址,可用于区分不同的AP,哈希表的值为从该AP的接收信号强度。进行分区后,通过该子区域内(如索引i的子区域)所有信号指纹的键值的并,得到该区域内的所有MAC地址集合:
(2)
式中:M为该子区域内的信号指纹的样本数目,函数keys(.)表示从某哈希表中取出所有键值。注意在实际应用中,分区过程和对每个子区域求MAC地址集合的过程中仅需要进行一次。当新的WiFi信号指纹需要被用于粗定位时,仍然可以用之前的分区结果。
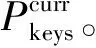
(3)
利用汉明距离的原因可以看作将不同AP的WiFi信号的可见性进行01编码,从而生成可见性向量。此处汉明距离给出的物理意义是两个信号指纹中的WiFi可见性不同的AP数目。在粗定位中选择汉明距离的原因是该距离的计算可以转换为与或的运算,不需要实际的信号强度相关运算,因此计算复杂度低。汉明距离相比于利用真实信号强度值的相关距离度量,用到的信息更少,导致精度更低。但是利用汉明距离进行粗定位能够达到缩小待定位区域的目的,因此最终选择汉明距离作为粗定位阶段的距离度量。
本文在粗定位的过程中,虽然看起来是手动划分子区域,但其本质是依照几何位置对子区域进行划分。从原理上看,通过几何位置进行子区域划分相比于传统的分级定位中按照信号空间聚类对子区域划分的方法扩展性更强,具体原因如下:传统的分级定位方法中,需要按照信号指纹进行聚类,因此需要所有信号指纹的先验信息,进行维度对齐,当定位区域较大时信号指纹的维度可能很高,从而影响定位的拓展性和实时性。本文方法通过位置直接划分子区域,并且在粗定位过程中直接通过汉明距离确定子区域,不需要对所有信号指纹的RSS进行维度的对齐,即不需要所有定位区域信号指纹的先验信息,因此拓展性更强。
在本文的应用中手动划分子区域的计算量可以看作是预处理过程,在建立信号指纹数据库后计算单次即可。在子区域数目增多时,由于粗定位中汉明距离匹配计算速度更快,并且不需要在预处理后再进行RSS维度的对齐,因此粗定位所需的复杂度在纵向对比上虽然会提高,但是相比于传统方法横向对比仍然具有优势。
1.2 精定位
假设在粗定位的过程中找到M个可能的子区域,这些子区域包含了人员可能存在的位置。假设在这些子区域内的信号指纹可以表示为{RSS1:N},其中N表示信号指纹的个数。
在精定位中,循环计算集合{RSS1:N}中的信号指纹与当前信号指纹的RSScurr的距离。本文的KNN精定位方法中,尝试利用两种不同的距离度量进行定位,分别为欧氏距离和高斯距离。下面分别对两种不同的距离度量进行详细介绍。
欧氏距离按照如下步骤进行计算:
Step1 首先从两个信号指纹RSSk和RSSq中取出其信号强度的值,分别可以写为
Veck=value(RSSk),
(4)
Vecq=value(RSSq)。
(5)
Step2 将两个向量补成相同的长度,使得两个向量中,每个维度对应的信号强度值来自于相同的AP。如果一个向量中存在来源于某AP的信号强度,而另一个不存在,则将AP的信号强度在另一个向量中设置为默认值-100 dBm。补齐后,两个向量可以分别表示为
(6)
(7)
式中:V表示补齐后的向量长度。
Step3 根据如下的公式计算两个信号强度向量的距离:
(8)
高斯对数距离的计算步骤的前两步与欧氏距离相同,都需要信号强度值的取出与对齐,然后根据下面的公式进行高斯对数距离的计算:
(9)
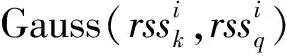
(10)
式中:σ2表示方差,方差的取值可以表示室内环境中不同的AP对应的信号强度的噪声波动水平。因此,从准确的角度来说,不同的AP需要设置不同噪声波动水平,因此需要不同的方差。但是这样设置会大大增强计算量,不适合实际定位情况的应用,因此本文将σ2设置为典型值。
根据传统的KNN算法完成精定位,这里近邻数取3。根据上面的步骤找到信号强度距离最近的3个信号指纹,并且找到其对应的几何位置,人员的最终估计位置为3个几何位置的算数平均值。
1.3 复杂度分析
在传统的部分级定位算法中,一次定位需要对所有的信号强度指纹进行比较(假设有N个),并且每个信号强度指纹的维度包含了区域内所有不同MAC地址的个数(此处假设有M个),因此其复杂度为O(NM)。而本文提出的方法中,一次定位的复杂度为O(nm),其中n表示精定位中子区域信号强度指纹的数目,m表示精定位中的子区域不同MAC地址的个数。子区域中的n与m通常远小于所有区域的N和M,因此从理论上进行分析,本文所提方法的定位复杂度更低。
2 实验与分析
2.1 实验场景设置
为了获取WiFi定位的精度,首先利用Google Nexus手机作为WiFi扫描工具获取环境中的WiFi信号指纹。采用Nexus的原因是其系统为Android的原生系统,能够更方便地通过编写手机APP录取WiFi指纹信号。在约50 m2的室内环境中,利用室内环境中已经存在的方形地板砖的交点作为已知的室内位置,地板砖的尺寸为60 cm×60 cm。在这些位置中录取WiFi信号指纹,从而生成了一个小型的WiFi信号指纹地图。在录取信号指纹的过程中,笔者开发了对应的安卓APP,可以将不同位置扫描得到的WiFi信号指纹进行离线存储,从而在实验中使用。如图3所示,人员在这些位置分别朝四个方向录取5个信号指纹。实验中用到的指纹地图含2 600个WiFi信号指纹。在该场地中,根据面积计算,大致包含了50/0.36≈139块地砖,若每块地砖不重复计算交点,大概在139个位置进行了测量,每个位置存在4个方向,每个方向录取5个信号指纹,总计信号指纹个数约为139×4×5=2 780个信号指纹。由于某些测量点靠近墙面,无法进行测量,因此最终得到的信号指纹约为2 600。在该实验中,根据测量得到的信号指纹,总共发现了12个AP。其中,人为在定位区域周围设置了5个AP,由于实验中不要求AP的具体位置,因此实验中未对其精确位置进行测量,只是大致在定位区域周边均匀设置。另外7个AP是室内环境中本来就存在的,其具体位置也未进行测量。本文实验设置的参数如表1所示。
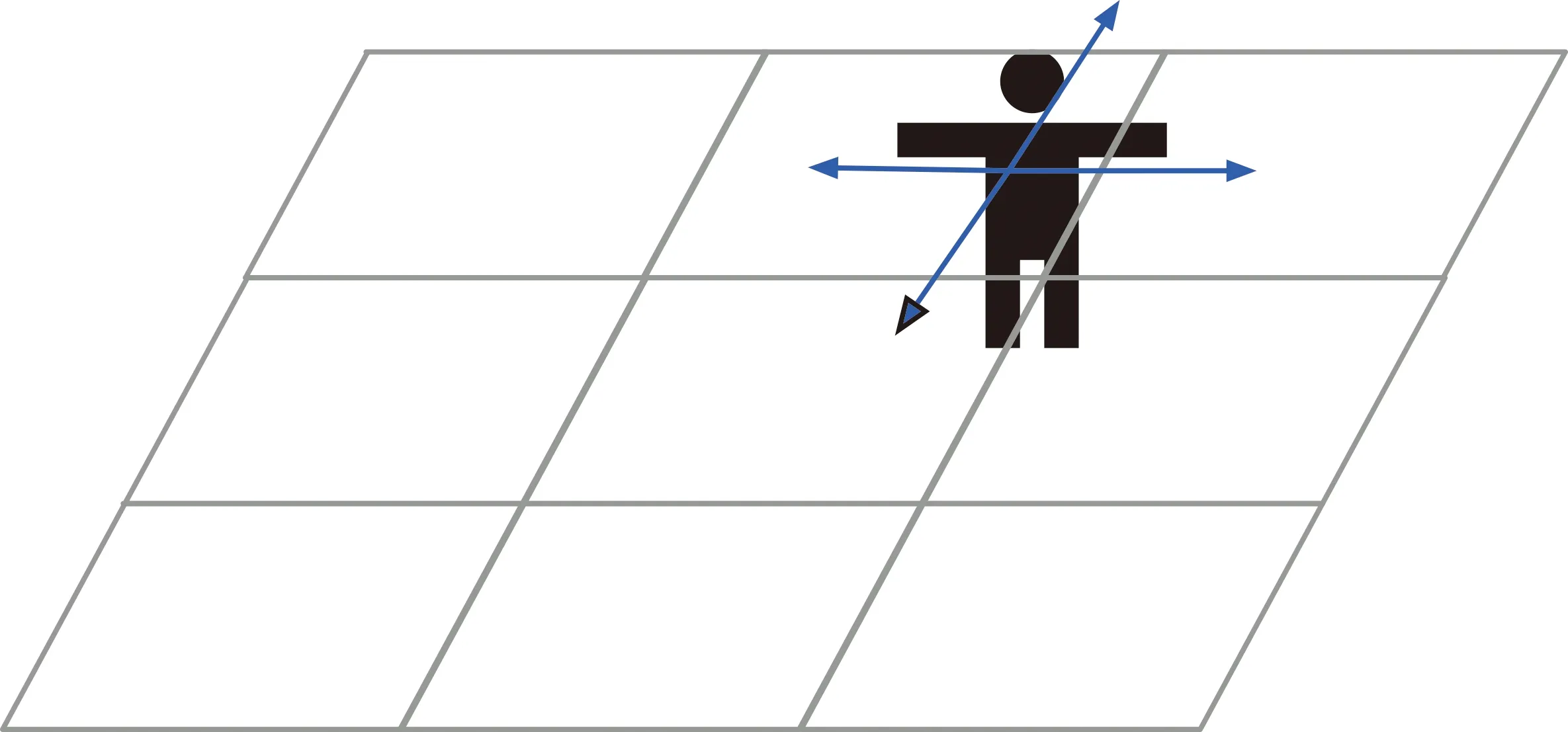
图3 录取指纹地图示意图

表1 实验场景参数
在定位过程中,通过全站仪跟踪人员(同时携带手机)的位置作为真实的位置,从而计算WiFi定位的误差。
2.2 方法超参数确定
为了能得到更好的定位精度,首先对方法中不同的超参数进行对比。根据获得的指纹地图和人员的真实位置,可以统计WiFi定位的误差。图4为不同的粗定位过程中选取不同的可能子区域的数目(上文中的参数M)的定位结果和经典的KNN定位方法的误差的积累密度分布函数(Accumulative Distribution Function,CDF),可以看出,在子区域的数目选择10时能够获得较好的定位精度,并且随着子区域继续增大,本文的分级定位方法逼近于传统的KNN方法;当子区域增大到所有子区域的数目时,本文的分级定位方法完全退化为经典的KNN方法。

图4 本文方法子区域数目与经典的KNN算法的定位误差积累误差密度分布函数比较
表2为本文分级定位方法取不同的子区域数目对应的定位精度的统计值,可以看出,当子区域数目为10时存在最小的误差均值与最大误差。

表2 不同子区域的数目对应的定位精度
本文算法中另一个超参数是L,表示划分的子区域的大小。不同的L对最终的定位性能有影响,需要通过实验确定其最佳值。下面对不同的L取值(分别为1 m、3 m、5 m、7 m、9 m)进行定位精度的对比。注意,此处用到的子区域数目为通过上文确定的最佳子区域数目,也就是10。如表3所示,当L=5 m时本文方法有着最小的定位误差,因此本文取L=5 m。

表3 不同的L长度对定位性能的影响
上述的L和子区域的定位数目M都是本方法中的超参数,即在方法实施前就需要确定的参数,实验中通常通过参数搜索的方法寻找最好的超参数配置。在工程实践中,往往不能像该实验这样每次寻找最佳的超参数,不同的应用场景中最佳的超参数不同。直接选择相同的超参数可能会造成精度损失,该损失可以看成工程实现造成的精度损失。在后续的工作中,笔者将会进一步研究本文方法在不同应用场景中进行迁移的问题,如最佳超参数不准造成的精度损失问题。
2.3 方法对比
本文主要提出了分级定位的框架,粗定位过程通过基于几何位置的子区域划分实现,精定位中既可以利用经典的KNN也可以利用对应的最大后验估计的方法。因此,本文方法的对比主要存在四种情况的对比,即分级定位(KNN精定位)、分级定位(最大后验精定位)、KNN直接定位和最大后验直接定位。在方法对比中,用到的测试数据中包含的信号指纹数目为500个,因此定位精度和定位时间是500次的平均。对比结果如表4所示。

表4 不同方法平均误差和单次定位时间统计
从表4中可以看出,不管利用经典的KNN定位算法还是利用最大后验概率算法,加入分级定位框架后,从定位精度上看并没有明显提升,仅有少量提升。其原因是,分级定位中,由于在粗定位中缩小了待匹配的范围,导致了匹配异常或错误匹配的情况,从而导致定位异常值的出现。另外,通过分级定位的框架后,平均单次定位时间在KNN算法下下降了约95%,在最大后验算法下下降了约96%,体现出了本文分级定位框架延迟低的优点。
上述实验中的距离度量(包含经典KNN方法和本文精定位中的度量)都采用了基于对数高斯距离的度量。下面对本文方法中精定位阶段采用不同的距离度量、含欧氏距离度量和对数高斯距离度量进行效果对比。在该实验中,控制其他的变量相同,如子区域数目选择为10,区域划分中的方格长度选择为5 m,最后的定位精度结果如表5所示。可以看出,采用对数高斯距离的定位精度更高,其平均定位误差和最大定位误差分别减小了8.3%和27.4%。

表5 精定位阶段不同距离度量的定位精度对比
3 结束语
本文提出了一种基于WiFi的分级定位方法。该方法分为粗定位和精定位两个步骤。粗定位中,利用汉明距离找到人员可能的子区域,在精定位阶段中利用经典的KNN算法利用信号指纹的欧氏距离获取人员的精确位置。实验结果证明了该方法在子区域数目为10并且利用对数高斯距离的条件下,平均单次定位时间在KNN算法下下降了约95%,在最大后验算法下下降了约96%,体现出了本文分级定位框架延迟低的优点。
为了能够更加充分地对本文方法进行验证,未来工作主要分为两个方面:一是设置更大场景、AP数目更多的实验场景,对本文方法和其他的分级定位方法进行充分对比;二是设置多种不同的实验场景,研究方法中不同超参数的设置对定位精度的影响。
