融入注意力机制的深度学习动作识别*
2021-11-02张宇,张雷
张 宇,张 雷
(北京建筑大学 电气与信息工程学院,北京 100044)
0 引 言
动作识别[1]的目标是判断视频中人体正在执行的动作,其作为计算机视觉的一项基本而又极富挑战性的任务,在智能家居[2]、智能安防[3]、人机交互[4]、视频检索[5]等众多领域有着广阔的应用前景。
早期的动作识别研究中,国内外学者设计了多种手工特征,并进行了大量实验,如轮廓剪影、人体关节点、时空兴趣点、运动轨迹等。由于依赖人工特征提取,其抗扰性和泛化能力都较差,无法得到广泛应用[6]。相比之下,深度学习方法能够自主学习数据特征,并且更加高效准确[7]。因此,基于深度学习的特征提取方法逐渐取代了人工提取特征的过程。Ji等人[8]第一次提出了3D-CNN算法,对时间轴上的视频帧运用3D 卷积核来捕捉时空信息,并将其用于人体动作的识别。Tran等人[9]提出了C3D 网络,并将其用于动作识别、场景识别、视频相似度分析等领域。Carreira等人[10]将2D卷积膨胀为了3D卷积,形成了膨胀3D卷积网络I3D。Donahue等[11]提出了LRCN(Long-term Recurrent Convolutional Network)模型,该网络用卷积神经网络(Convolutional Neural Network,CNN)提取特征,再用长短时记忆(Long Short-Term Memory,LSTM)网络实现动作分类。在动作识别中,CNN与LSTM的使用,很大程度上提高了识别精度,减少了工作量。然而,随着CNN加深,将出现严重的梯度消失和网络退化问题。为了解决该问题,本文采用由卷积注意力模块[12](Convolutional Block Attention Module,CBAM)和残差网络[13](ResNet)构成的注意力残差网络提取特征,然后再利用LSTM进行动作分类。
此外,目前动作识别的难点主要有:视频动作样本较少,训练过程易出现过拟合;视频中存在许多冗余帧,易对模型产生干扰;网络模型对关键特征的提取能力不足,影响识别率提升。针对上述问题,本文采取的措施有:通过在数据预处理中加入数据增强算法,减少因样本较少而导致的过拟合;通过筛除低信息量的视频帧,减少冗余信息的干扰;通过在残差网络中融入注意力模块,增强模型对判别性特征的提取。
1 动作识别的模型架构
在视频动作识别中,处理的数据不再是单独的一张图像,而是具有时间顺序的图像序列。如果把视频中的每一帧都作为输入数据来处理,将极大地增加模型的计算成本。因此,本文参考了文献[14]中的采样方法,从每个视频中取16帧作为样本;然后,把样本输入到模型中,进行网络权重的学习;最后,用Softmax分类器对动作进行分类。本文模型的总体框架如图1所示,共分为三个部分:数据处理、特征提取以及动作分类。

图1 模型的总体框架
1.1 数据处理
1.1.1 数据预处理
传统的数据预处理过程如下:第一步,用ffmpeg模块把视频解析为视频帧序列;第二步,对原视频帧按训练要求等比例缩放;第三步,对缩放后的视频帧进行中心裁剪;第四步,把裁剪后的视频帧转换成张量形式;第五步,对张量进行正则化。
上述过程虽然简单,但是存在以下两个问题:一是视频帧的中心裁剪会造成边缘信息丢失;二是动作识别数据集样本容量相对较小,训练时极易出现过拟合问题。因此,为缓解以上问题,本文提出了一种针对视频的数据增强算法(以下称算法1),伪代码如下:
输入:动作视频所对应的视频帧序列V={f1,f2,…,fn}
1 创建序列V′
2 获取视频帧序列V={f1,f2,…,fn}
3 forfi∈V(i=1,2,…,n)do
3 在(-h,h)之间随机生成一个整数q
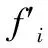
在算法1中,用视频帧序列{f1,f2,…,fn}表示每个动作视频V,便于我们使用图像处理的方法间接地对视频数据进行处理。具体而言,算法1把视频帧序列中的每一张图像按照原来顺序,在给定范围内进行水平方向上的平移(平移的单位长度和方向是随机的,q=-1,表示向左平移;q=1,表示向右平移)。如果一个动作视频包含50帧,且生成随机数的范围是(-6,6),那么经过数据增强处理,最多可以将数据扩充600倍。与此同时,对视频帧图像进行了水平方向的平移,还能缓解由中心裁剪造成的边缘信息丢失问题。所以,本文将数据增强算法加入到了数据预处理中,改进后数据预处理过程如下:第一步,数据增强;第二步,缩放;第三步,裁剪;第四步,转换张量;第五步,正则化。
1.1.2 视频帧采样
由于动作拍摄的起止与动作本身难以同步,所以视频的开始和结束阶段通常存在大量的冗余帧。文献[14]中提到的视频帧采样方法是在视频帧序列的全时段上采样,其具体过程为:在(0,R-16)之间随机生成一个数L,其中R是视频解析成视频帧序列后的长度;从第L帧开始,依次选取16帧图像作为模型的输入。该采样方法虽然解决了网络模型由于输入造成的计算成本问题,却没有考虑到在整个视频帧序列中各个时段所包含的信息量并不对等的问题。如果随机生成的起始帧位于整个视频中信息量很低的时段,那么通过文献[14]中的采样方法得到的输入数据反而会对模型产生干扰。因此,本文对文献[14]中的采样方法进行了改进(以下称算法2),伪代码如下:
输入:动作视频所对应的视频帧序列V={f1,f2,…,fn}
输出:采样结果S={fk+1,fk+2,…,fk+16}
1 获取视频帧序列V={f1,f2,…,fn}
2 ifn≤48
3 在(0,n-16)范围内随机生成一个整数k
4 再从集合V中的第k帧开始依次选取16帧图像
5 else
6 在(n/3-16,2n/3-16)范围内随机生成一个整数k
7 再从集合V中的第k帧开始依次选取16帧图像
8 输出采样结果S={fk+1,fk+2,…,fk+16}
在算法2中,当视频的帧数较小时(n≤48),本文采取的措施是忽略冗余帧的影响,在(0,n-16)范围内随机生成一个整数k,然后再从第k帧起依次选取16帧图像;当视频的帧数较大时,则剔除起止时间段内的冗余帧,在(n/3-16,2n/3-16)范围内随机生成一个整数k,然后再从第k帧起依次选取16帧图像。
1.2 特征提取
注意力机制是指利用神经网络自动获取需要重点关注区域的信息,同时抑制其他无用信息。卷积注意力模块[12](CBAM)作为一种轻量级的结构,参数量仅为2.53×106,占用的计算资源非常少。因此,在特征提取部分,提出了融入CBAM的残差网络。
1.2.1 CBAM的基本结构
CBAM由通道注意力和空间注意力两部分组成,如图2所示。通道注意力为拥有较多辨识信息的通道分配更大的权重,而空间注意力能在此基础上学习到关键信息在哪里,即定位到输入特征中的显著性区域。
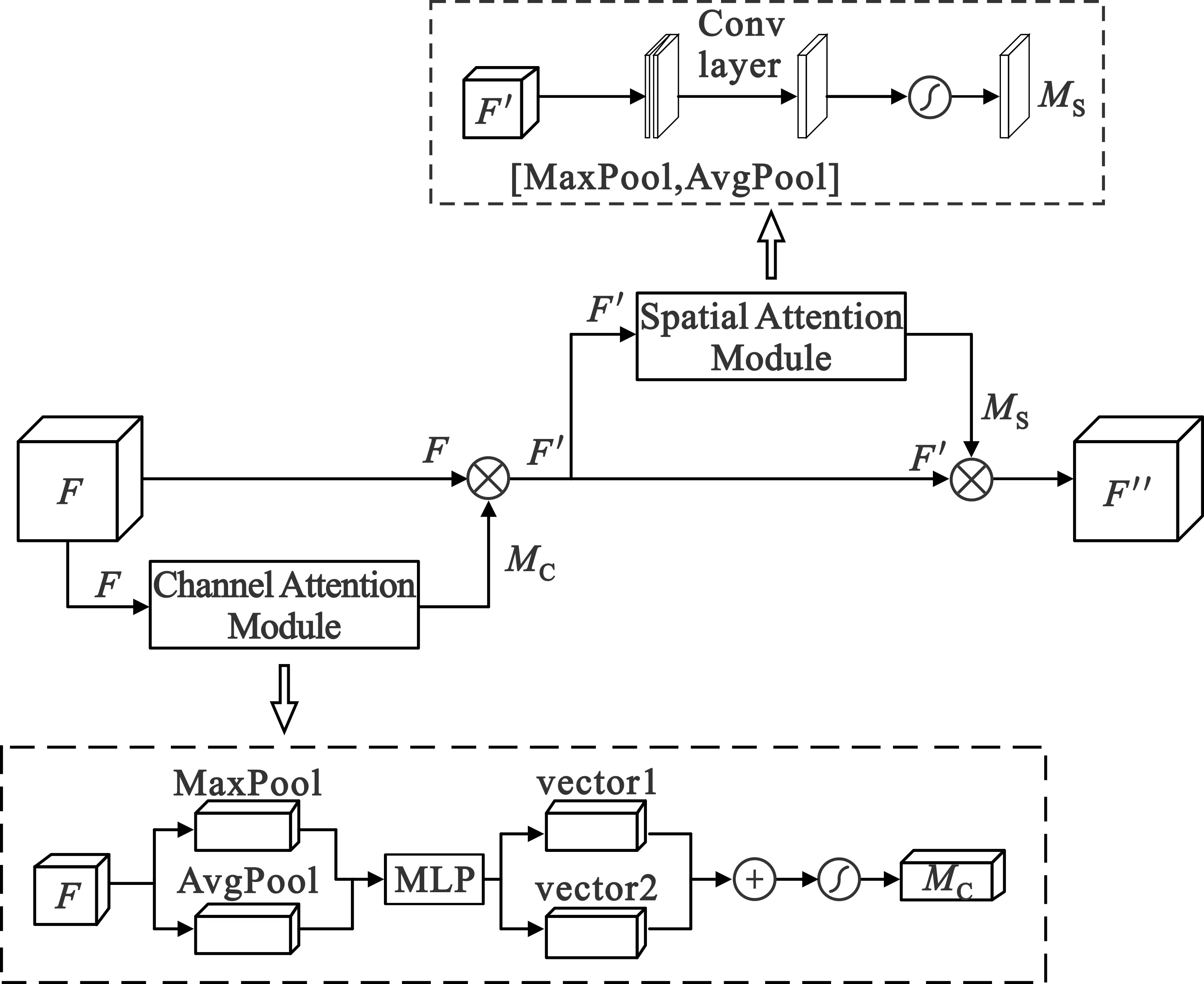
图2 CBAM的基本结构
从图2可以看出,通道注意力模块首先利用全局平均池化和最大池化对输入特征图F进行压缩,然后再把压缩后的两部分特征同时输入到一个多层感知器(Multi-layer Perceptron,MLP)中作降维升维操作,最后将MLP输出的两个向量进行求和运算,再经过Sigmoid函数就得到了通道注意力加权系数MC,如式(1)所示:
MC=σ(MLP(AvgPool(F))+MLP(MaxPool(F))=
(1)
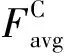
CBAM把输入特征F与通道注意力加权系数MC相乘,得到了新的特征F′。然后,将F′输入到空间注意力模块得到空间注意力加权系数MS。最后,让MS与F′相乘就得到了最终的注意力特征F″,如式(2)和式(3)所示:
F′=MC⊗F,
(2)
F″=MS⊗F′ 。
(3)
1.2.2 CBAM的改进
在训练过程中,网络的各个节点会根据输入特征不断调整其对应的参数,并且更易受到后输入特征的影响。在网络权重共享时,如果让两组特征通过同一MLP训练权重,则会出现左支右绌的问题。为了解决该问题,对CBAM的通道注意力部分作了改进,如图3所示。
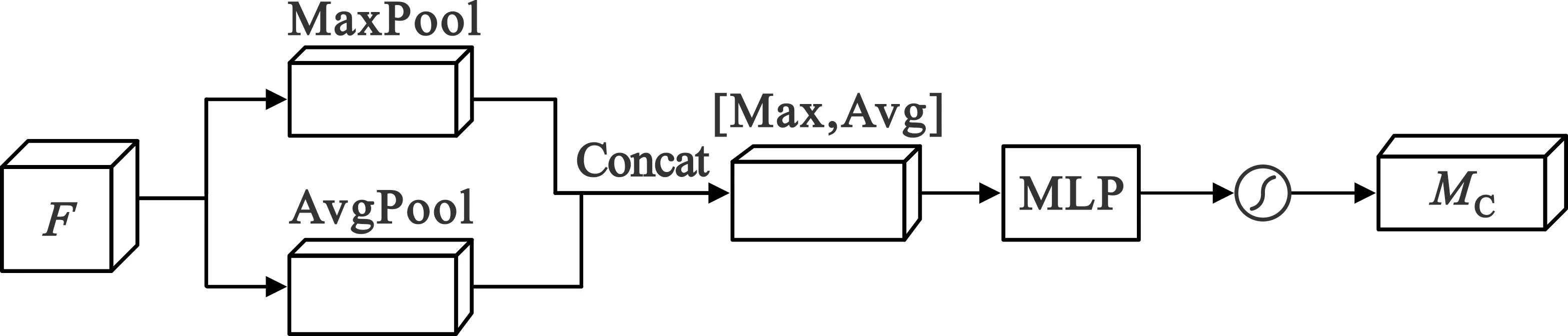
图3 改进后的通道注意力模块
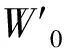
MC=σ(MLP([MaxPool(F);AvgPool(F)]))=
(4)
式中:[MaxPool(F);AvgPool(F)]是拼接融合后的特征。
1.2.3 残差模块
本文模型中的残差网络借用了ResNet50结构,它由16个如图4所示的残差模块堆叠而成。其中,虚线框右侧的部分代表捷径连接,它可以直接把输入x传递到输出位置,若x与F(x)维度不同,则通过一个1×1卷积对x进行维度调整;而虚线框中的结构代表残差部分,它由三个卷积层构成,利用1×1卷积核把输入张量的通道降维,使得3×3卷积核作用在size相对较小的张量上,达到降低计算量的目的,然后再用1×1卷积核把张量的通道进行升维,其输出为F(x)。所以整个残差模块的输出结果是
H(x)=F(x)+x。
(5)
当F(x)=0时,则H(x)=x,此时为恒等映射。因此,残差网络将残差结果F(x)逼近于0作为学习目标。此外,由式(5)可以看出,残差网络在进行误差反向传播时,由于x的导数恒为1,所以即使F(x)的链式求导趋近于0,也能有效避免梯度消失和网络退化问题。

图4 残差模块
1.2.4 融入G-CBAM的残差模块
融入G-CBAM的残差模块,如图5所示。首先利用G-CBAM模块来更好地提取输入特征中的关键信息,然后将提取到的关键信息输入到原残差模块的残差部分进一步提取深度特征,最后将残差部分的结果与捷径连接的结果相加融合后作为整个模块的输出特征。
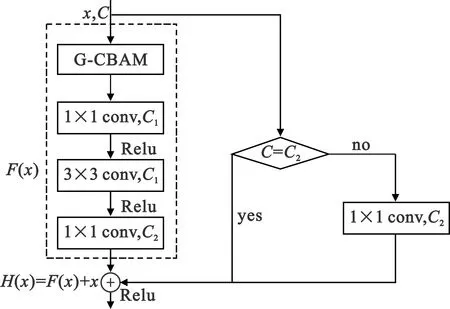
图5 融入G-CBAM的残差模块
1.3 动作分类
循环神经网络(Recurrent Neural Network,RNN)能够处理时序问题,但当输入序列较长时,会因梯度消失而无法学习。为解决该问题,Schmidhuber等人[15]提出了长短时记忆网络(LSTM)。作为一种特殊结构的RNN,LSTM擅长处理长时间序列信息。
LSTM的基本结构如图6所示,它通过输入门、遗忘门和输出门,完成信息的输入和输出。其中,输入门由图中间的σ层、tanh层以及一个逐点相乘“⊗”构成,决定了当前时刻的输入xt有多少需要保存到当前的单元状态ct中;遗忘门由图左侧的σ层和一个逐点相乘“⊗”构成,决定了上一时刻的ct-1是否保留到当前时刻的ct中;输出门由图右侧的σ层和一个逐点相乘“⊗”构成,决定了当前的单元状态ct有多少可以传递到LSTM的当前输出值ht中。
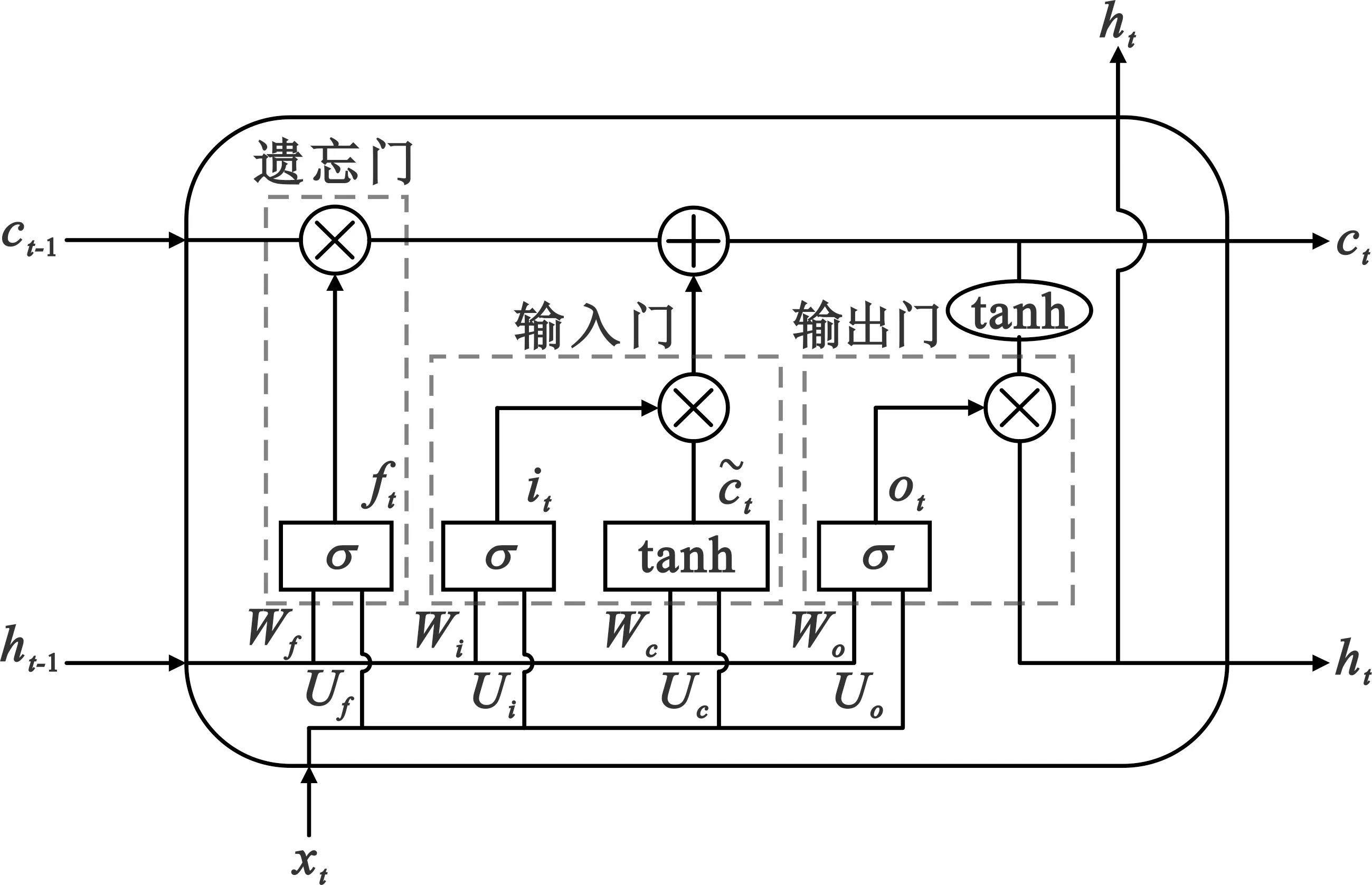
图6 LSTM基本结构
LSTM的更新递归公式如下:
ft=σ(Wfht-1+Ufxt+bf),
(6)
it=σ(Wiht-1+Uixt+bi),
(7)
(8)
(9)
ot=σ(Woht-1+Uoxt+bo),
(10)
ht=ot·tanh(ct)。
(11)
式中:Wf、Wi、Wc、Wo以及Uf、Ui、Uc、Uo为相应的权重矩阵,bf、bi、bc、bo为相应的偏置,σ和tanh为激活函数。
2 实验及结果分析
2.1 实验环境
本文实验运行环境如下:操作系统Ubuntu16.04;深度学习框架pytorch1.6.0;通用并行计算架构cuda10.2;深度神经网络GPU加速库cudnn7.6.5;显卡GeForce RTX 2080Ti,显存11 GB;显卡驱动nvidia450.80;硬盘512 GB。
2.2 数据集
UCF YouTube数据集包含1 600个视频,分为投篮、高尔夫挥杆、荡秋千、骑车、骑马、遛狗、跳水、颠球、打网球、跳蹦蹦床、打排球11个动作类别,每个类别包含25组视频,每组又至少包含4个视频片段,其分辨率为320 pixel×240 pixel。
KTH数据集有600个视频,分辨率为160 pixel×120 pixel。该数据集在4种不同场景下由25个人执行6类动作,具体包括走路、慢跑、快跑、拍手、挥手、拳击。
HMDB51数据集包含6 849个视频,共分为51个动作类别,每类至少有101个视频,分辨率为320 pixel×240 pixel。根据动作类别大致可分为5种类型:面部动作,如微笑、咀嚼;有操作对象的面部动作,如抽烟、吃饭;一般的身体动作,如挥手、走;身体与物体的交互动作,如梳头、运球、拔剑;人与人的交互动作,如拥抱、接吻。
为了验证本文方法的有效性,将UCF YouTube和HMDB51数据集按照60%作训练集、20%作验证集、20%作测试集来划分。对于KTH数据集,由于样本数量较少,采用5次交叉验证取平均值的方法,其中每次取80%的数据进行训练,剩下20%进行测试。
2.3 实验细节
首先,对于UCF YouTube和HMDB51数据集,
其分辨率均为320 pixel×240 pixel,直接使用会因计算量过大而导致内存溢出,所以需将其进行缩放,而KTH数据集的分辨率仅为160 pixel×120 pixel,可以直接输入模型。其次,由于视频动作识别对GPU算力要求很高,为了提升训练效率,对模型的特征提取部分运用了迁移学习,即将ResNet50在ImageNet上训练好的权重迁移到本文所用的ResNet结构中。最后,为了进一步降低网络过拟合的风险,在所有的FC层都使用了Dropout技术,即让FC层的节点按照一定概率随机失活。本文的实验参数设置如表1所示。

表1 实验参数
2.4 实验过程
2.4.1 注意力模块对模型性能的影响
为了更加直观地分析CBAM和G-CBAM对模型性能的影响,分别绘制了ResNet+LSTM(以下简称为RLNet)、RLNet+CBAM和RLNet+G-CBAM模型在UCF YouTube数据集上的准确率和损失值曲线,如图7所示。以上三个模型在最开始的迭代训练中准确率和损失值的波动较大,此后随着迭代次数的增加最终趋于平稳。融入CBAM的RLNet识别率相比RLNet有明显提升,但训练过程中的准确率和损失值波动较大。此外,融入G-CBAM的RLNet识别率最高,损失值最小,而且在训练过程中准确率和损失值波动较小,模型的稳定性最好。由于G-CBAM解决了CBAM训练中存在的左支右绌问题,更好地拟合了不同特征的关联性,降低了准确率和损失值的波动幅度,所以模型的稳定性和识别率都得到了提升。
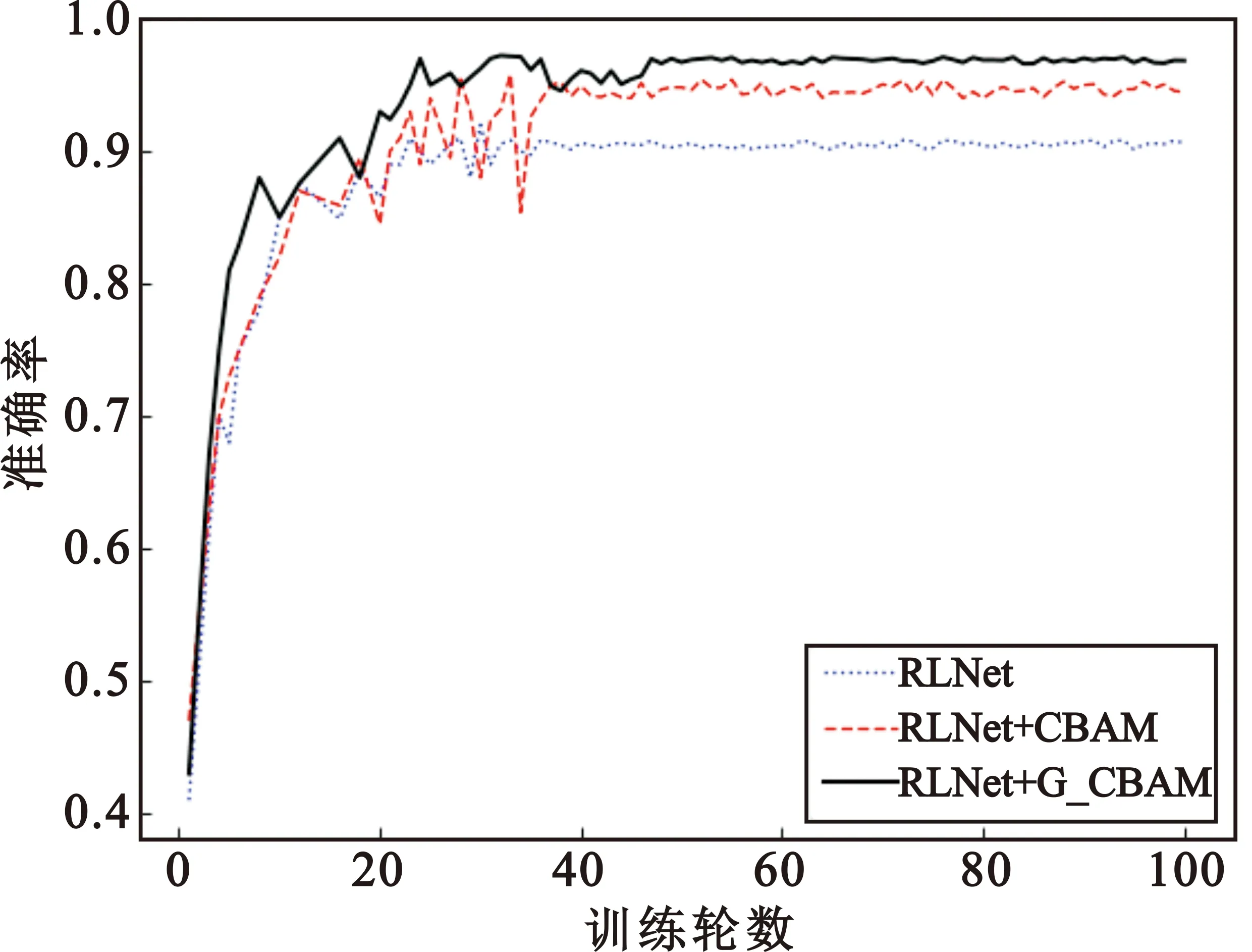
(a)准确率曲线

(b)损失值曲线图7 不同改进模型的性能曲线
2.4.2 改进措施的有效性验证
为了证明各种改进措施的有效性,在UCF YouTube数据集上对模型RLNet、RLNet1、RLNet1,2、RLNet1,2+CBAM和RLNet1,2+G-CBAM进行了消融实验,实验结果如表2所示,其中RLNet1是RLNet+Algo1的简写,RLNet1,2是RLNet+Algo1+Algo2的简写。

表2 各种改进措施的对比
由表2可知,各种改进措施对模型识别性能的提升依次为 1.56%、1.16%、1.88%和1.27%。
2.4.3 特征区域可视化
利用Grad-CAM[20]方法将特征提取部分的最后一层卷积所关注的动作特征进行了可视化,如图8所示。可以清楚地看到,融入CBAM的残差网络不仅能够定位到关键特征所在区域,还能抑制其他无用信息。与此同时,相较于CBAM,改进后的G-CBAM对关键特征的定位更加完整和准确,有效地提升了网络对判别性特征的学习。
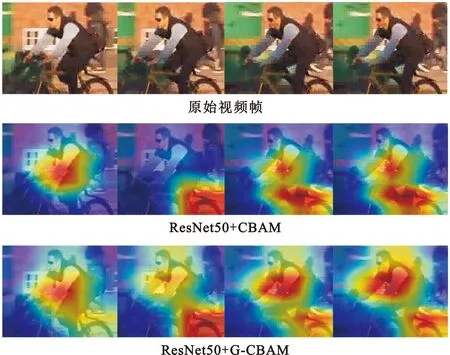
图8 特征区域热力图
2.5 实验结果
为了更加充分地验证本文所提方法,分别在UCF YouTube、KTH和HMDB51三个数据集上进行了实验。
2.5.1 在UCF YouTube上的验证
模型训练结束后,在UCF YouTube数据集上,所提方法的识别率达到了96.72%,与现有的动作识别方法相比,取得了更好的识别效果,如表3所示。

表3 在UCF YouTube上与其他方法对比
2.5.2 在KTH上的验证
KTH的特点是背景干扰信息较少,且不存在交互性行为,数据集相对比较简单。训练时,首先选取KTH中前120个视频作为测试集,其余的作为训练集,并称其为Dataset1,然后进行第一次交叉验证。其余相仿,一共进行5次交叉验证,最后取平均值作为实验结果,如表4所示。实验表明,模型RLNet1,2+G-CBAM在KTH上的识别率达到了98.06%。
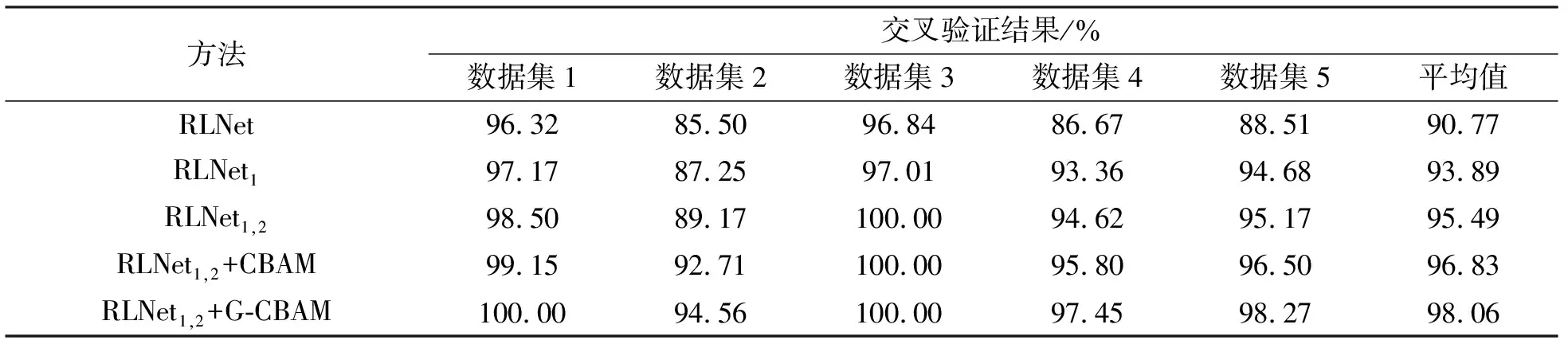
表4 在KTH数据集上的交叉验证
此外,由表5可知,在KTH数据集上本文方法相对其他方法依然拥有更好的识别效果。
2.5.3 在HMDB51上的验证
HMDB51数据集主要来源于电影,其特点是数据分布广泛,训练难度较大。为了验证模型RLNet1,2+G-CBAM在复杂场景下的识别效果,在HMDB51数据集上也进行了实验,并与其他方法进行了比较,结果如表6所示。

表6 在HMDB51上与其他方法对比
由表6可以看出,本文方法在HMDB51上与其他的动作识别方法相比,准确率有一定幅度的提升,但与在UCF YouTube和KTH上获得的识别准确率相比存在明显的差距。其主要原因是,HMDB51相对其他两个数据集,视频来源更加复杂,存在相机移动、遮挡、复杂背景、光照条件变化等诸多不利因素,导致其识别率较低。
3 结束语
本文提出了一种融入注意力机制的深度学习动作识别方法。该方法通过在数据预处理中加入数据增强算法,减少了模型过拟合的风险,通过筛除低信息量的视频帧,减少了冗余信息的干扰,通过将G-CBAM这一轻量级的结构融入到残差网络中,以较小的参数量获得了较好的性能提升,最终在UCF YouTube、KTH和HMDB-51数据集上分别获得了96.72%、98.06%和64.81%的识别率。此外,在HMDB51数据集上的实验结果表明,本文模型在复杂场景下的识别率较低。所以,下一步将围绕如何提升模型在各种不利因素下的识别率进行研究。
