面向实际应用场景的实时行人检测算法研究
2021-11-02桑海峰
张 萌,桑海峰
(沈阳工业大学信息科学与工程学院,沈阳110870)
1 引言
在深度学习发展成为主流之前,传统目标检测算法的实现步骤为:先对检测目标进行区域选择,以SIFT[1]和HOG[2]等算法在区域范围内提取特征,再将提取的特征放入分类器(SVM[3]和Adaboost[4])中进行分类任务。然而这一传统目标检测算法存在两个问题:一是区域选择没有针对性,致使时间成本较高;二是鲁棒性较低。随着深度学习时代的到来,目标检测算法也得到了巨大的改进,以卷积神经网络为代表的另一种目标检测算法已经出现。该算法又可以分为类:一类是基于Region Proposal(建议区域)的深度学习目标检测算法,以R-CNN[5]为代表,除此还包括Fast-RCNN[6]、Faster-RCNN[7]等,都需要先产生建议区域,然后在这一区域上做分类与回归。另一类则是一个单阶段(one-stage)的基于回归方法的深度学习目标检测算法(YOLO[8]、SSD[9]等),通过运用一个CNN网络就可以直接预测不同目标的类别与位置,提高了训练速度。
行人检测是目标检测技术的主要分支,应用广泛。在具有挑战性的场景下,例如遮挡、模糊、形态变化等,检测性能通常会受到影响。为解决这些问题Hariharan等人[10]将分割用作检测的先验,周春銮等人[11]为应对不同的行人遮挡模式设计了模型。但这些方法并不完全适应于现实使用场合。赵祈杰等人[12]提出的M2Det网络提出了多层次特征金字塔网络来构建更有效的特征金字塔,用于检测不同尺度的对象,取得了较好的检测结果。但是由于M2Det需要使用8个TUM模块,参数量巨大,训练占用内存高,为此,此处在M2Det的基础上加以改进,得到新的行人检测网络MCDET。
2 改进的VGG网络
改进的基于M2Det的行人检测方法MCDET整体流程如图1所示。使用改良后的VGG网络对输入图片提取特征,并且在VGG网络中的conv4_3提取特征层后使用注意力模块增强细节信息,再与pool5层后得到的特征通过特征融合模块(FFM)中的FFMv1模块进行初步融合。将融合后的基础特征层依次输入4个瘦化U形模块(TUM)中进行U型特征提取,先不断压缩特征层,再进行上采样操作融合特征,最终使用TUM模块获得6个有效特征层,对其使用FFMv2特征增强融合后再次输入到下一个TUM中,依此方式一共通过四个TUM模块,将输出结果输入到尺度特征聚合模块(SFAM)中,最终得到所需的检测层。
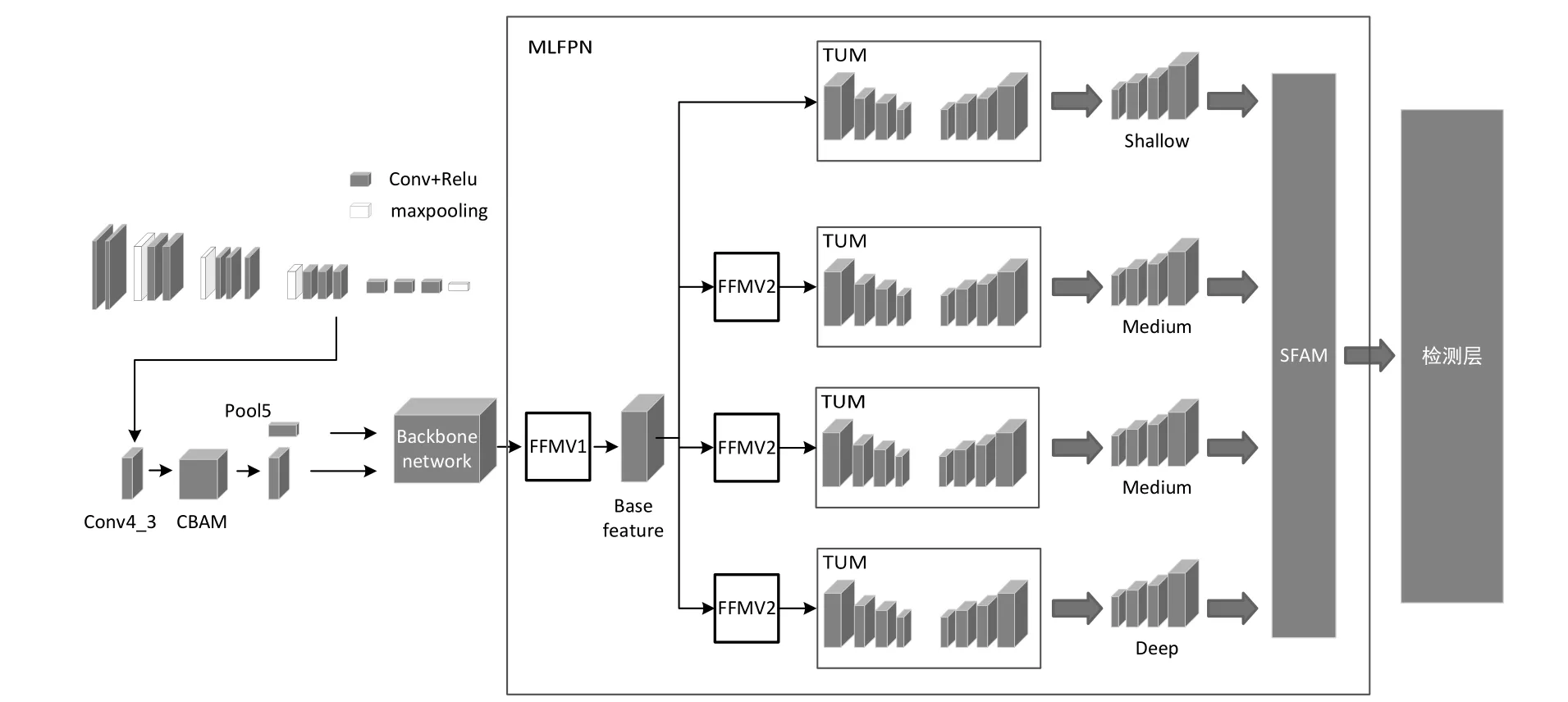
图1 MCDET网络结构图
MCDET提取特征网络采用的是VGG网络,使用3个3×3卷积核来替换7×7卷积核,以及使用2个3×3卷积核来替换5×5卷积核。这样做虽然增加了卷积核的个数,但提升了网络深度,改善了网络效果,同时保证感知野不变。VGG自身含有3个全连接层,这3个全连接层参数众多,会产生大的计算量,占用大量内存。为解决这一问题,此处在VGG网络的基础之上做了一定改进:将VGG-16网络结构中的3个全连接层删掉以减少参数且对性能基本不产生影响;删掉conv 4_3后的池化层使conv4_3作为提取的浅层特征信息,pool5作为深层特征信息。改进后的VGG网络模型如图2所示。
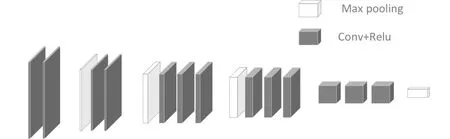
图2 改进的VGG网络结构图
M2Det本身具有8个TUM模块。TUM模块使用简化的U形结构,这一点上与FPN和RetinaNet两种都不同。编码器采用的是3×3卷积层,步长为2。解码器解码后得到多个特征层,制成特征集。当前级别的多尺度特征由当前TUM的解码器中的所有输出组成;多层次多尺度特征由堆叠的TUM的所有输出组成;浅层特征、中等特征、深层特征分别由TUM的前、中、后分别提供。每个TUM经计算共有6210432个参数,如若使用8个TUM模块参数量过于庞大,导致训练时间长,内存占用量大,因此需要使用4个TUM模块,将参数量减少至原有的一半,以减少训练时长。
将原有的8个TUM模块改为4个,在一定程度上减少了浅层信息的获取,此时就需要在浅层特征层添加注意力机制来增强对浅层信息的获取,即添加卷积块注意力机制模块(CBAM),其网络结构如图3所示。CBAM兼顾了空间注意力和通道注意力,与只关注一方面的注意力机制相比,取得了更佳的结果,尤其有助于对小目标捕获能力的提升。
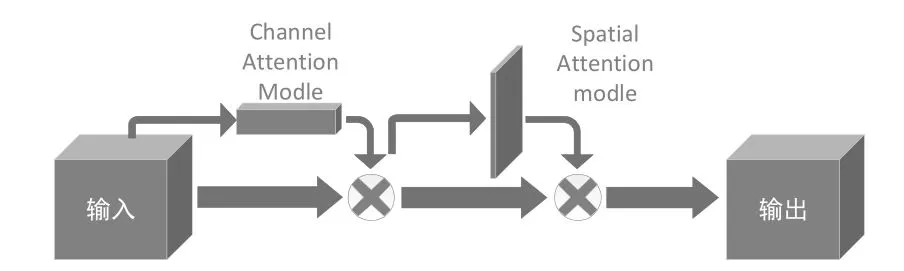
图3 CBAM模块结构图
CBAM的通道注意力机制结构如图4所示,其流程为:特征图输入后,通过基于width和height的全局最大池化和全局平均池化后再通过多层感知器(MLP)操作,最终加和;再使用Sigmoid对加和结果激活,生成最终的通道注意力特征图。将所生成的特征图与输入特征图做elementwise乘法操作,得到下一部分空间注意力模块所需的输入特征。
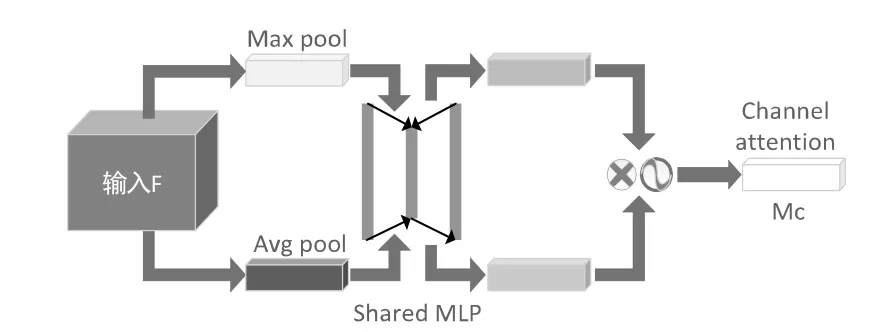
图4 通道注意力机制结构图
CBAM的空间注意力机制结构如图5所示。结构流程为:输入通道注意力产生的特征图后,首先在基于通道的全局最大池化和全局平均池化的结果上做基于通道的concat操作。然后通过卷积操作将特征降维为1个通道。再使用sigmoid操作生成空间注意力的特征图。最后将得到的特征和输入的特征做乘法操作,最终生成特征即为使用CBAM模块后得到的特征。
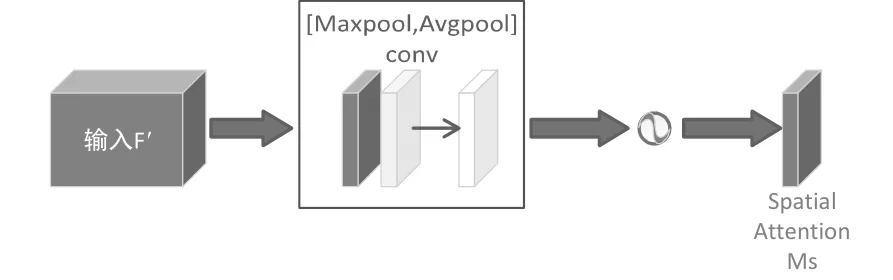
图5 空间注意力机制结构图
3 实验结果与分析
实验的软件环境均在Ubuntu16.04系统下进行配置,使用的深度学习框架为Keras2.1.5;电脑显卡为GeForce RTX 2080 Ti,显存大小为11GB。主要采用Caltech作为数据集来完成对于改进算法的训练和评估。
实验采用目标检测领域公认的平均精度(AP)来衡量模型的性能。将Caltech中122187张图片划分为训练集和测试集,其中73312张图片用于训练,48875张图片用于测试。不同算法在caltech数据集下的检测结果如表1所示。可以看到改进的MCDET算法相较于yolo v3算法,以及相较于只有四TUM模块的M2Det算法,在平均精度上均有不同程度的提高。

表1 不同算法在Caltech数据集下的平均精度
为实现面向实际情况的行人检测系统,在实验中也比较了算法的检测速度,以检测所需的时间来衡量,实验结果如表2所示。由表中看到,虽然注意力机制的添加稍微延长了检测时间,但相对于8个TUM的M2Det,检测速度还是有些许提升的。

表2 不同算法的检测时间
为更加直观地体现MCDET模型的检测效果,将改进算法与Yolov3开源代码算法的实际表现进行对比,如图6所示。其中,图6(a)、图6(b)为简单场景下的检测效果,图6(c)、图6(d)为复杂场景下的检测效果;而图6(a)、图6(c)采用的是Yolov3源码检测,图6(b)、图6(d)则为MCDET改进算法的检测效果。可以看出简单场景下两者检测效果基本相同,但在复杂场景下MCDET对行人的检测效果更佳。

图6 算法检测实际效果对比
图7 显示了MCDET算法针对遮挡的检测效果。图8为MCDET算法针对远处小目标行人的检测结果。可以看出在这两种有代表性的实际应用场景下,该算法均有较为理想的良好表现。

图7 对被遮挡行人的检测效果

图8 对远处小目标行人的检测效果
4 结束语
提出一种融合CBAM模块的改进M2Det目标检测模型的行人检测方法MCDET,使得对于检测较小目标的有效特征层能够很好地融合,获得一个较强的语义信息,并可以进行实时检测。该模型在Caltech数据集中在保持精度的前提下实现了对于行人的实时检测,具有实际意义。因为TUM模块的减小,导致改进算法在精度上相较于Yolov3系列之后的算法还有所逊色,因此在后续研究中,对于像Caltech这样的大规模数据集还应进行进一步的模型实现与分析,同时还应注重移动设备端的研究,如Tiny-Yolo之类的浅表替代模型,以在硬件有限的情况下提高准确性。
