基于能量均衡高效WSN的分簇路由算法
2021-11-01王宗山赵一帆杨俊东丁洪伟
王宗山,赵一帆,李 波,杨俊东,丁洪伟
(云南大学 信息学院,云南 昆明 650500)
0 引 言
无线传感器网络(wireless sensor network,WSN)中传感器节点的能量有限且电池难以更换[1],因此设计能量高效的路由协议对WSN有重要意义[2]。此外,如何使WSN在一定的时间内采集到尽量多的数据也是人们关注的热点问题[3]。
经典的层次路由协议LEACH[4]通过分布式概率的方法让每个网络节点周期性担任簇首,一定程度上均衡了网络能耗,延长了网络生存期。但LEACH协议随机选取簇首的方式不能保证簇首节点剩余能量充足且位置分散,影响了网络性能。为延长网络生存期,许多研究学者采用元启发式算法优化WSN分簇路由协议。文献[5]采用灰狼优化器解决WSN分簇路由协议中的簇首选举问题,通过选择最优簇首有效地均衡了网络能耗。但该协议没有使用任何簇间路由,簇首与基站直接通信会加速远离基站的簇首的能量消耗,从而缩短网络生存期。文献[6]以延长网络生存期为目的提出GAFCMCR协议,该协议采用由遗传算法改进的FCM聚类对网络节点聚类分簇,以此最小化簇内通信距离。每个簇内节点基于自身的能量与位置竞选簇首。该协议有效地均衡了网络能耗,延长了网络生存期。但GAFCMCR没有考虑任何簇间路由,采用的单跳通信机制限制了协议的应用。
上述协议一定程度上提高了网络能量效率,但仍有改进的空间。本文提出一种基于改进人工蜂群算法(CTABC)和模糊C均值(FCM)聚类的分簇路由算法(clustering routing algorithm based on improved artificial bee colony algorithm and fuzzy C-means clustering,AFCR)。AFCR采用CTABC优化FCM,并用改进的FCM对网络节点聚类分簇,簇内节点基于自身状态分布式竞选簇首。稳定传输阶段,提出一种基于改进蚁群优化的能量高效簇间路由算法,为每个簇首节点寻找最优传输路径,并将区分忙闲节点的轮询控制机制引入簇内通信,降低网络能耗的同时提高网络吞吐量。
1 系统模型
1.1 网络模型
本文参照文献[7]对无线传感器网络和网络节点做出如下假设:
(1)监测区域内随机分布N个传感器节点,每个节点具有唯一的网络标识(ID),节点部署后位置固定;
(2)所有传感器节点同构,初始能量相同,且无法补充能量,基站计算能力和能量无限;
(3)节点可以根据接收到的信号强度计算自身与信号发送端的距离,能够根据通信距离自主选择发射功率;
(4)所有节点都具备担任簇首的能力,可以对数据进行去冗余处理。
1.2 能耗模型
本文采用与文献[8]相同的一阶无线电模型,节点发送l bit数据消耗的能量主要包括两个部分:发送l bit数据的能量损耗和功率放大电路的能量耗损。节点接收数据消耗的能量仅包括接收电路的能耗。节点经过距离d发送l bit的数据所消耗的能量为

(1)
节点接收l bit数据所消耗的能量为
ERx(l,d)=lEelec
(2)

2 人工蜂群算法
2.1 标准的人工蜂群算法
标准的人工蜂群算法[9]将蜜蜂分为采蜜蜂、观察蜂和侦查蜂3种类型。通常情况下,采蜜蜂和观察蜂的数量相等,占蜂群总数的一半。蜜源数量SN等于采蜜蜂和观察蜂的数量,蜜源的位置代表优化问题的可行解,蜜源的花蜜量代表适应度函数值(可行解的质量)。初始时刻,所有的蜜蜂均处于侦查蜂模式,按照式(3)在搜索空间中随机产生SN个蜜源位置
xij=Lj+rand(0,1)(Hj-Lj)
(3)
其中,xij表示蜜源i在第j维搜索空间的位置,搜索空间的范围为[Lj,Hj],j=1,2,…,D,为D维解向量的某个分量,rand(0,1)表示[0,1]之间的随机值。
采蜜蜂在当前蜜源附近搜索,产生新的蜜源位置。邻域搜索产生新位置的方式为
vij=xij+rand()(xij-xkj)
(4)
其中,xij表示旧蜜源,xkj表示随机选择的蜜源,k∈{1,2,…,SN},并且k≠i,j和k随机生成,rand()为[-1,1]之间的随机数,取值大小决定扰动幅度。采蜜蜂根据贪婪准则保留新旧蜜源中花蜜量较优的蜜源。
所有的采蜜蜂完成邻域搜索后,返回跳舞区分享蜜源信息。观察蜂根据采蜜蜂分享的蜜源花蜜量信息计算跟随概率,计算方式如下
(5)
其中,fiti表示第i个解的适应度值。观察蜂以概率Pi寻找新蜜源,并且角色转化为采蜜蜂,进行采蜜蜂的相应的操作。
在搜索过程中,若采蜜蜂和观察蜂在一个蜜源附近连续扰动Limit次,仍然没有搜索到更优蜜源,则采蜜蜂转换为侦查蜂,按照式(3)随机发现一个新蜜源。
2.2 基于交叉禁忌的人工蜂群算法
基本的人工蜂群算法有很强的局部搜索能力,但全局搜索能力不足。算法在接近全局最优时,搜索速度变慢,个体多样性减少,易陷入局部最优。针对这一问题,本文对人工蜂群算法的全局搜索策略进行改进,在全局人工蜂群[10]的基础上引入遗传算法的交叉操作和禁忌算法的禁忌搜索思想,提出基于交叉和禁忌搜索的全局人工蜂群算法(CTABC)。
首先,CTABC在采蜜蜂邻域搜索时加入了全局引导项;其次,在采蜜蜂进行邻域搜索产生新解之后,将产生的新解与全局最优解进行交叉,进一步增强了算法的全局寻优能力。为协调算法的邻域搜索能力和全局寻优能力,引入新的参数交叉系数;最后,算法引入了禁忌搜索算法中的禁忌思想,在保持原有算法整体流程不变的前提下,添加了一个禁忌表。当某个蜜源的位置在连续Limit次扰动后没有更新,则将该解放入禁忌表中,侦查蜂随机生成新解。如果新解的适应度值小于阈值(将当前禁忌表中最优解的适应度值设定为阈值),则认为新解不合格,并重新产生新解,直到新解大于阈值。若有侦查蜂连续σ次生成的新解均不合格,则特赦禁忌表中的最优解,并将其指定为当前侦查蜂产生的新解。由于禁忌表中解的质量普遍较差,故禁忌表长度无限,除禁忌表中的最优解有一定概率被特赦外,其余解将被一直禁忌。
CTABC的交叉方式如式(6)所示。即采蜜蜂由式(4)进行邻域搜索产生新解vij后,生成一个[0,1]之间的随机数,与交叉系数cro进行比较,如果生成的随机数小于交叉系数,则采蜜蜂将邻域搜索产生的解vij与全局最优解按照式(6)进行交叉,产生新解cij,若生成的随机数大于交叉系数,则不进行交叉
(6)
其中,m为非负常数。交叉系数cro用于协调算法的邻域搜索能力和全局寻优能力。
3 AFCR算法
AFCR引入LEACH算法中“轮”的概念,每轮分为簇的构建和稳定传输两个阶段。簇构建阶段,基站运行由CTABC优化的FCM聚类算法形成网络分簇,每个簇内,节点根据自身状态竞选簇首。稳定传输阶段,簇首节点采用区分忙闲节点的轮询控制机制收集簇内节点感知到的数据,对数据进行去冗余处理后按照改进蚁群优化规划的最优路径发送至基站。
3.1 网络分簇
网络初始化时期,基站根据节点的地理位置,采用由CTABC优化的FCM聚类算法进行迭代计算,形成网络分簇,并将分簇结果全网广播。本节中,我们首先介绍了FCM聚类算法,然后详细阐述了所提出的基于CTABC和FCM聚类的最优聚类方法。
3.1.1 FCM聚类算法
FCM聚类是一种无监督聚类算法,其思想是使划分到同一类的对象之间相似度最大,而不同类之间的相似度最小[11]。采用FCM对网络节点进行聚类分簇,可以很好的将节点分为k个大小均匀且紧密的簇,最小化成员节点与簇首之间的通信距离,从而减少簇内通信能耗。FCM的目标函数如式(7)所示
(7)
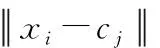
隶属度矩阵按照式(8)进行更新
(8)
聚类中心cj按照式(9)进行更新
(9)
迭代结束的条件为
(10)
3.1.2 CTABC优化FCM
采用FCM聚类算法对网络节点聚类分簇,聚类效果受初始聚类中心的影响,选取最优的初始聚类中心能够保证FCM聚类算法的性能,从而优化聚类效果。传统的FCM算法随机选取初始聚类中心,导致算法容易收敛至局部最优,影响聚类效果,为解决这一问题,本文将CTABC应用于FCM算法的优化计算中,由CTABC得到初始聚类中心,再使用标准的FCM算法得到最终聚类结果,从而形成网络分簇。
CTABC优化FCM聚类的步骤为:
(1)参数初始化:采蜜蜂和观察蜂的数量均为SN,蜜源可重复开采次数Limit,最大迭代次数maxCycle,交叉系数cro,聚类数目k,模糊指数m,误差阈值ε;
(2)种群初始化:按照式(3)随机生成初始种群。计算初始种群的适应度函数值。适应度函数为1/Jm;
(3)设置计数器iteration=1,开始循环;
(4)采蜜蜂按照式(4)进行邻域搜索,将邻域搜索后的解与迭代最优解按照式(6)进行交叉操作,产生新解。确保新蜜源位置在优化搜索范围内,并计算其适应度值,根据贪婪准则保留较优解;
(5)观察蜂根据式(5)计算出来的概率Pi选择要跟随的采蜜蜂,观察蜂角色转换为采蜜蜂,并执行采蜜蜂的相应操作;
(6)若采蜜蜂、观察蜂在某一蜜源附近的搜索次数超过Limit,仍然没有找到更优的蜜源,则将该解放入禁忌表,同时蜜蜂角色转换为侦查蜂,按照式(3)随机生成一个新蜜源。确保新蜜源合格且位置在优化搜索范围内,并计算其适应度值;
(7)记忆当前时刻最优蜜源的位置;
(8)判断是否满足停止迭代准则,若满足,输出最优解作为FCM的初始聚类中心,执行FCM算法,完成聚类,否则返回步骤(4)继续迭代。
3.2 簇首选举
相比于普通节点,簇首需要执行更多任务,能耗也更大[12]。因此选择高质量的簇首是均衡网络能耗,延长网络生存期的关键。簇构建完成之后,首轮簇首由距离聚类中心最近的节点担任。此后每轮不再重新分簇,由当前簇首综合考虑簇内节点的剩余能量、向心率、到基站的距离以及成功当选簇首的轮次等因素指定下轮簇首,直至当前分簇数不再适合此时的网络状态。
节点的剩余能量因子按照式(11)进行计算
(11)
其中,Ei表示第i个节点的剩余能量,Emax和Emin分别表示第i个节点所在的簇内,所有节点当前剩余能量的最大值和最小值。f1越大,说明该节点的剩余能量越多。这样设计的好处是,当多个节点的剩余能量值接近时,它们的剩余能量因子仍然有较大的区分度。
节点的向心率因子按照式(12)进行计算
(12)
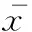
节点到基站的距离因子按照式(13)进行计算
(13)
其中,di表示第i个节点到基站的距离,dmax和dmin分别表示第i个节点所在的簇内,所有节点到基站距离的最大值和最小值。f3越大,说明该节点与基站之间的相对距离越近。
节点担任簇首的轮次因子按照式(14)进行计算
(14)
其中,rcurrent表示当前网络运行的轮次,ri表示节点i在前rcurrent轮中担任簇首的轮次。f4越大,说明该节点在前rcurrent轮中担任簇首的轮次越少。
每轮的最后,当前簇首根据簇内成员节点的信息计算其参量值f
f=αf1+βf2+γf3+ηf4
(15)
其中,α、β、γ、η为权重因子,用来调整4个因子的比重。根据当前的网络状态,实时调整权重因子,从而选出高质量簇首。权重因子按照下式进行更新
(16)
β=γ=η=(1-α)/3
(17)
其中,Eave表示节点i所在簇的平均剩余能量。随着网络的运行,节点的剩余能量越来越少,能量因子对应的权重动态增大,即能量因子在簇首竞选时所占比重动态增大。
参量值计算完成后,当前簇首选取参量值最大的节点,按照式(18)的方式与自身参量值进行比较
fCH≤λfmax(i),λ∈(0,1]
(18)
若式(18)成立,则需要进行簇首更新,当前簇首指定节点i成为下轮簇首。否则,不更新簇首。式中的γ为网络系数,取值大小决定簇首更新频率。取值小,则簇首更新慢,部分节点会因长期担任簇首而过早死亡。取值大,则簇首更新频繁,会产生不必要的网络能耗,降低网络性能。
3.3 簇间路由
根据能耗模型可知,节点的能量消耗与传输距离呈指数相关。若簇首采用单跳方式与基站通信,会加速远离基站的簇首的能量消耗,导致网络能耗不均衡,降低网络的能量利用率。因此采用改进的蚁群优化算法构建簇间路由,簇首根据最优传输路径完成数据传输。
3.3.1 转移概率函数的优化
基尼系数是经济学中衡量一个地区收入分配不均等程度的统计指标,它能够有效的从总体上概括抽象地反应个体之间收入分配的差异度[13]。基尼系数的一个常用公式为
(19)
其中,n为该地区的人口总数,xi为第i个的收入,μ为该地区人民的平均收入。
本文基于基尼系数,结合传感网中簇的特点提出能量基尼系数,用于预估网络中所有分簇的能量均衡度。能量基尼系数的计算公式如式(20)所示
(20)
其中,num(j)表示候选簇首所在簇内的节点个数,Eave(j)表示候选簇首所在簇的能量均值,E(i)和E(j)分别表示候选簇首所在簇的成员节点i和成员节点j的剩余能量。
基于上述分析,t时刻前向蚂蚁a由簇头i选择簇头j的转移函数为
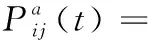
(21)
其中,τij(t)表示t时刻簇首i与簇首j之间的信息素含量,αant为信息素权重,ηij(t)表示路径搜索启发因子,βant为启发因子权重,alloweda为簇首a的候选下一跳簇首集合。
簇首i到簇首j的启发值按照式(22)进行计算
(22)
其中,Ej-rem表示下一跳簇首j的剩余能量,di,j表示簇首i与簇首j之间的距离,dj,BS表示下一跳簇首j与基站之间的距离。从上式可以看出,信息素启发因子考虑了下一跳簇首的剩余能量和地理位置,待选下一跳簇首的位置越合理,剩余能量越高,与当前簇首之间的启发值就越大。
在改进的转移概率函数中引入能量基尼系数项,保证了候选下一跳簇首的簇内能量均衡性,提出的信息素启发因子能够平衡下一跳簇首的能量因素与位置因素,保证选择的下一跳簇首剩余能量高且地理位置合理。
3.3.2 信息素更新
传统的蚁群算法仅根据路径长度更新信息素,没有考虑对路径影响较大的其它因素。本文结合传感网的特征改进了信息素的更新策略。此外,为优化蚁群算法效率,强化全局寻优能力,将信息素的更新分为局部信息素更新和全局信息素更新两个部分。
路径信息素更新模型为
τij(t+1)=(1-ρ)τij(t)+ρΔτij(t)
(23)
其中,ρ表示信息素挥发系数,Δτij(t)表示信息素增量。
前向蚂蚁由簇首i移动至簇首j,按照以下规则计算局部信息素增量
(24)
其中,Qlocal为局部信息素浓度,Ej-rem为待选下一跳簇首j的剩余能量,num(j)为待选下一跳簇首j所在簇内的成员节点数,d(i,j)为簇首i与簇首j之间的距离。从式中可以看出,局部信息素更新综合考虑待选下一跳簇首的剩余能量、负载和位置等因素,能够有效提高路由效率。下一跳簇首的剩余能量越高,负载越小,距离当前簇首越近,则两簇首间的局部信息素增量越大。
前向蚂蚁到达基站后自动消亡,并生成相应的后向蚂蚁。后向蚂蚁沿原路返回源节点,并按照以下规则完成全局信息素的更新
(25)
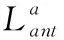
3.4 改进簇内通信机制
现存的大多数WSN分簇路由算法中,簇内通信一般采用TDMA(time division multiple access)机制[14]。簇首选举完成之后,簇首节点根据簇内成员节点的数量创建TDMA时隙表,节点在自己的时隙内被唤醒,向簇首发送监测到的数据,其余时间处于休眠状态,以减少能耗。如果传感器节点在一段时间内没有监测到有效数据,那么该节点在自己的时隙内就没有数据需要发送,这就会出现空闲时隙,同时造成能量浪费。为解决这一问题,本文引入区分忙闲节点的轮询控制机制[15]。在选出簇首之后,每个簇的簇首节点根据簇内成员节点的信息建立轮询表,轮询表中记录的是节点的ID、轮询顺序、忙闲状态三者之间的对应关系。在簇首轮询表中,有数据待发送的成员节点忙闲状态标识值置为1,没有数据待发送的节点忙闲状态标识值置为0。每一个轮询周期开始之前,对所有节点的忙闲状态进行更新。簇首轮询表建立之后,簇首节点按照轮询表中的查询顺序,依次轮询忙闲状态标识值为1的节点,接收其发来的监测数据。当节点能量耗尽、处于休眠状态或离开所在簇时,将其从轮询表中删除。如果有节点在一段时间内没有监测到有效数据,其忙闲状态标识值将一直为0,簇首不查询该节点,这样就避免了时隙的浪费,提高网络吞吐量的同时优化了能量利用率。
簇首完成一个轮询周期后,对收集到的数据进行融合,并采用CSMA机制发送至基站。
4 仿真实验
4.1 参数设置
本文使用Matlab R2016b对AFCR、FIGWO和GAFCMCR这3种协议进行了仿真,并在网络稳定期、网络生存期、网络吞吐量和网络总能耗等指标上对协议的性能进行了评估。为验证所提协议的可扩展性,本文设定了两种不同的网络场景,并在场景中分布不同密度的传感器节点。参照文献[16],对仿真参数和蚁群算法参数进行设定,具体参数见表1。网络场景参数见表2。根据文献[17],将最优簇头比例设置为5%。CTABC算法的参数设置为:种群大小为20,最大迭代次数maxCycle为200,交叉系数cro为0.7。

表1 实验参数
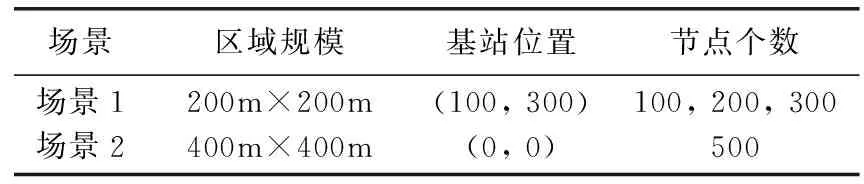
表2 网络场景参数
4.2 场景1中协议性能评估
4.2.1 网络稳定期
将网络稳定期定义为网络中首个节点死亡的时间。无线传感网中所有节点都能正常采集数据时,网络处于稳定期,一旦有节点能量耗尽,网络拓扑发生变化,采集到的数据信息出现缺失,网络不再稳定[18]。图1是场景1中3种协议的网络稳定期对比。场景1中分布100个、200个、300个节点时,AFCR的网络稳定期均长于FIGWO和GAFCMCR,这得益于AFCR采用改进的人工蜂群算法结合模糊C均值聚类优化了聚类效果,根据节点状态选出了高质量簇头,并使用改进的蚁群优化构造了高效的簇间路由,有效地均衡了网络能耗,同时提高了能量利用率,从而显著地延长了网络稳定期。

图1 场景1网络稳定期对比
4.2.2 网络生存期
本文参照文献[19]将网络生存期定义为网络中有75%的节点死亡所对应的时间。在分布不同数量的节点的场景1中对3种协议进行仿真,生存期对比如图2所示。从图中可以看出,AFCR的网络生存期明显长于GAFCMCR协议和FIGWO协议,这是因为本文提出的聚类方法能够很好解决无线传感网的聚类问题,并综合考虑节点的剩余能量、地理位置和当选簇首的轮次选择最优簇首,从均衡簇首负载,提高能量利用率,此外本文提出的基于改进蚁群优化的能量高效路由算法能够找到簇头的最优传输路径,减少簇首的通信能耗,从而延长网络生存期。
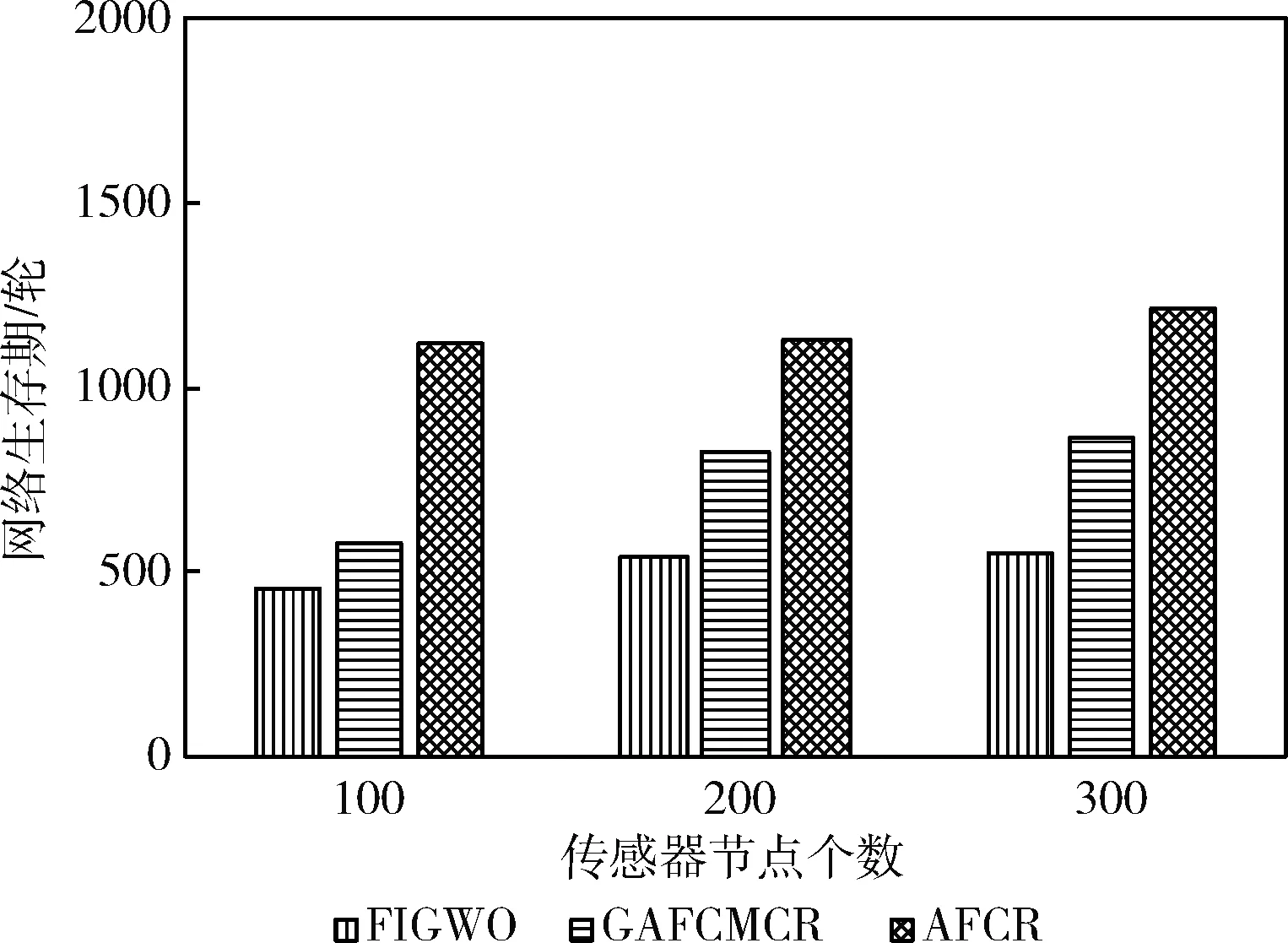
图2 场景1网络生存期对比
4.2.3 网络吞吐量
本文将网络生存期内基站接收到的总的数据包个数定义为网络吞吐量。在相同条件下对3种协议进行仿真,吞吐量对比如图3所示,场景1中分布的传感器节点越多,基站接收到的数据包也越多。传感器节点数相同时,AFCR协议的网络吞吐量明显优于GAFCMCR协议和FIGWO协议,使本文协议有更高网络吞吐量的原因为:AFCR协议的网络生存期长于其它两种协议,说明网络能够正常工作更多的轮数,基站也就接收到了更多的数据包;稳定传输阶段,簇首节点采用轮询控制机制收集簇内成员节点感知到的数据,避免了时隙浪费,簇首能够收集到更多的数据包并发往基站。
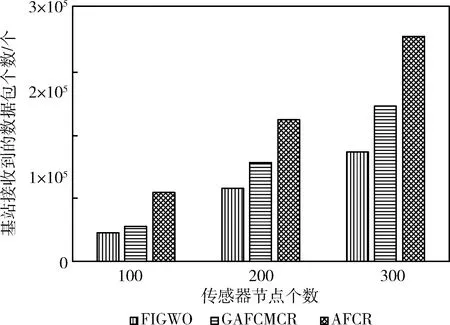
图3 场景1网络吞吐量对比
4.2.4 网络剩余能量
网络剩余能量是指传感网中所有存活节点剩余能量的总和。网络剩余能量越多,代表网络的正常工作时间越长,部署无线传感网的收益也就越大。图4~图6是AFCR、GAFCMCR、FIGWO这3种协议在分布3种节点密度的场景1中的网络剩余能量对比。从图中可以看出,AFCR的网络剩余能量自始至终高于其它两种协议,这得益于本文协议通过优化聚类效果最小化簇内通信间距,并采用能量高效的路由算法构建簇间路由,降低簇首能耗,从而使本文协议有很好的能耗均衡性和能量高效性。
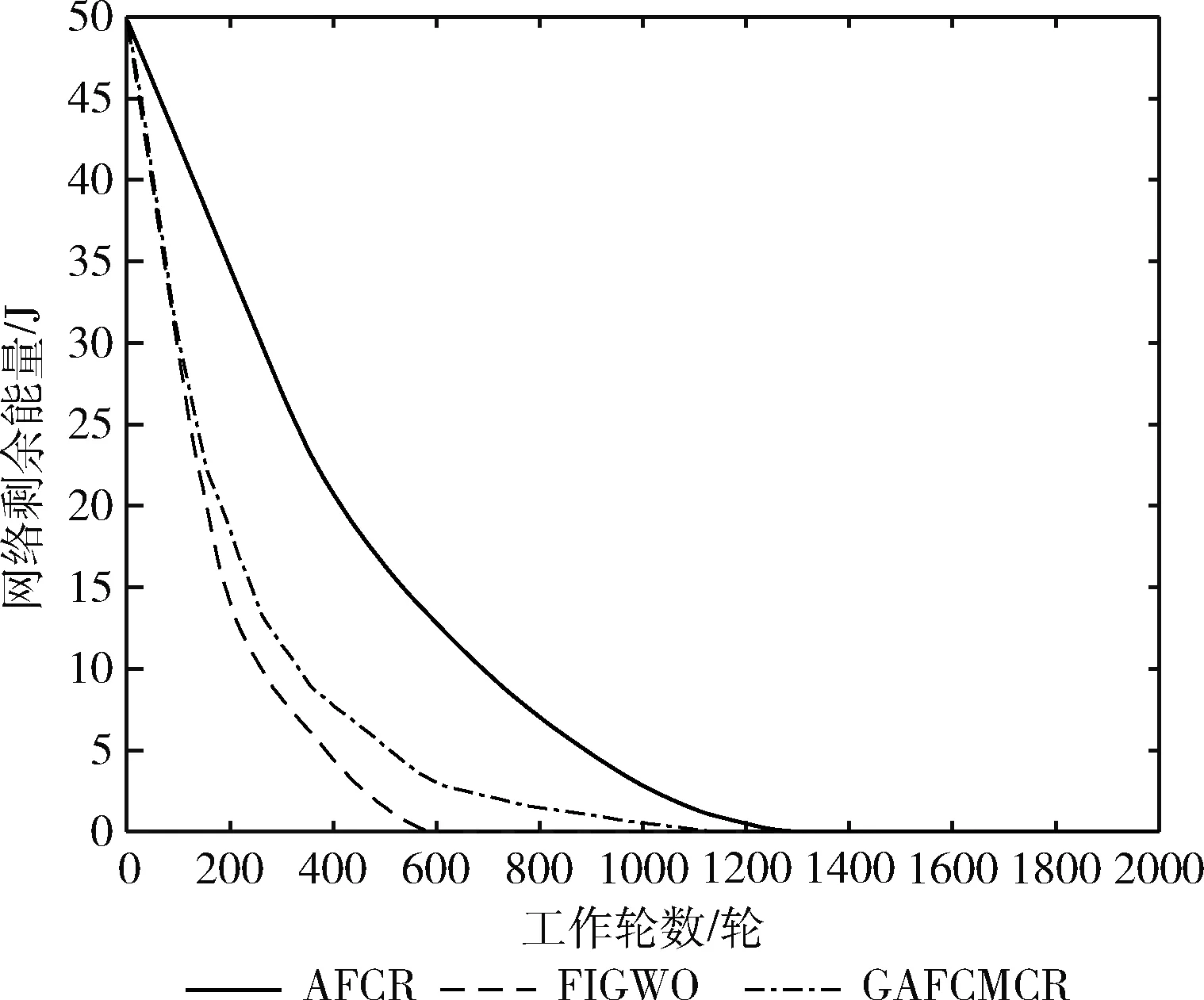
图4 场景1(100节点)网络剩余能量对比
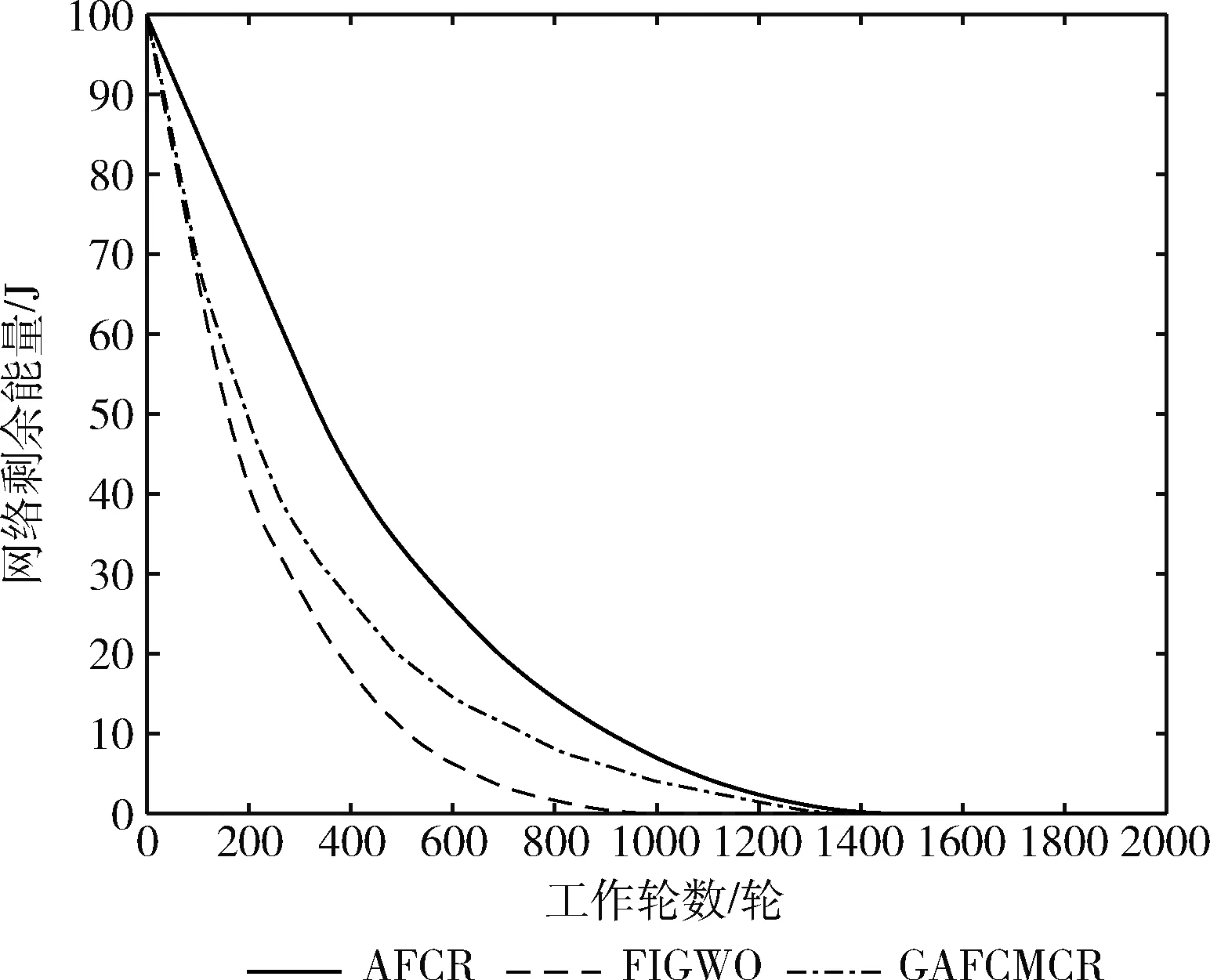
图5 场景1(200节点)网络剩余能量对比

图6 场景1(300节点)网络剩余能量对比
4.3 场景2中协议性能
场景2规模较大,传感器节点数量多,基站位于区域的边角处,在该场景中对AFCR协议的可扩展性进行了测试,并与GAFCMCR协议和FIGWO协议进行了对比。
4.3.1 网络稳定期
场景2规模大,部分节点距离基站较远,簇首的位置分布和路由效率对网络性能至关重要。图7是场景2中3种协议的网络稳定期对比。因为本文提出的基于改进蚁群优化的能量高效路由算法综合考虑下一跳的剩余能量和地理位置等信息,结合簇的能量均衡度、路径长度和路径的瓶颈能量等,构造了高效的簇间路由,簇首通过最优传输路径完成数据传输,有效地提高了能量利用率,并避免了远离基站的簇首的过度能耗,从而极大延后了首个节点的死亡时间。
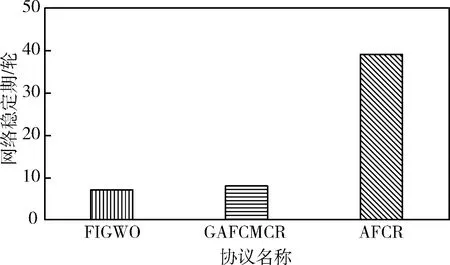
图7 场景2网络稳定期对比
4.3.2 网络生存期
图8是大规模场景中3种协议的网络生存期对比,从图中可以看出,相比于FIGWO和GAFCMCR,AFCR在网络生存期指标上有较大优势,这得益于本文算法成簇紧凑,簇首分布均匀,能够最小化簇内通信距离;其次,基于改进蚁群优化的路由算法能够找到簇首与基站之间的最佳传输路径,避免了远距离通信产生的大量能耗。

图8 场景2网络生存期对比
4.3.3 网络吞吐量
大规模场景中分布有较多的传感器节点,基站接收到更多的数据包,图9是场景2中3种协议的网络吞吐量对比。从图中可以直观看出AFCR协议的网络吞吐量远高于GAFCMCR协议和FIGWO协议,使AFCR协议在网络吞吐量指标上有优越表现的主要原因为:相比于其它两种协议,AFCR的网络生存期更长,代表网络正常工作了更多轮次,基站也就接收到更多的数据包;此外,AFCR在簇内通信阶段使用轮询机制,通过充分利用时隙提高了网络吞吐量。
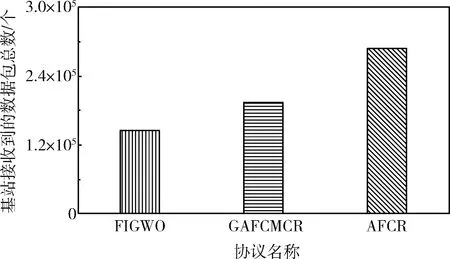
图9 场景2网络吞吐量对比
4.3.4 网络剩余能量
图10是场景2中3种协议的网络剩余能量对比,剩余能量指标反映了协议的能耗均衡性和能量有效性。从图中可以看出,本文协议在这一指标中有较大优势,网络剩余能量自始至终高于其它两种协议,这得益于本文协议优化网络聚类的同时构造了高效的簇间路由,最小化簇内和簇间通信距离,从而有效地均衡了网络能耗,提高了能量利用率。

图10 场景2网络剩余能量对比
5 结束语
为了均衡WSN中节点的网络消耗、延长网络生存期、提高网络吞吐量,本文提出一种基于改进人工蜂群算法和模糊C均值聚类的能量高效分簇路由协议。采用人工蜂群算法优化的模糊C均值聚类形成网络分簇,最小化簇内通信距离,综合考虑节点的剩余能量、地理位置、当选簇首的轮次等因素选择最优簇头,引入基尼系数对蚁群算法进行优化,并提出基于改进蚁群优化的能量高效路由算法,寻找簇头的最优传输路径,簇内通信阶段引入轮询控制机制,减少时隙浪费的同时降低节点能耗。仿真实验结果表明,与GAFCMCR协议和FIGWO协议相比,AFCR协议能够有效地均衡网络能耗,延长网络生存期并提高网络吞吐量。
