结合注意力机制的多策略汉语语义角色标注
2021-11-01万福成车郭怡
朱 傲,万福成,*,马 宁,车郭怡
(1.西北民族大学中国民族语言文字信息技术教育部重点实验室,甘肃 兰州 730030;2.西北民族大学甘肃省民族语言智能处理重点实验室,甘肃 兰州 730030)
语义角色标注(semantic role labeling,SRL)的目的是识别出句子序列中与核心成分相关的所有论元,例如施事、受事等;为后期进行深层次语义分析的研究提供帮助,同时在自然语言处理的多种应用领域具有广泛的实用价值.
SRL问题依赖于句法解析,根据句法解析的方式不同,可以分为基于短语结构和基于依存句法的SRL.其中,在依存句法分析中,谓语是核心成分,这点和SRL在一定程度上是相通的,同时依存句法可以表达词语间的依赖关系,所以相比于短语结构句法分析,依存句法可以为SRL提供更加丰富的语言学信息.2004年,Hacioglu[1]最先基于依存句法对汉语SRL问题进行研究,并且在公共数据集的评测中取得优秀成绩.但是当时句法解析精度较低,严重限制了模型的标注性能.针对这个问题,Jin等[2]提出只利用高质量的句法分析结果进行汉语SRL的方法,取得一定效果,但是并没有完全解决SRL对句法解析精度依赖的问题;与此同时,国内学者也基于依存句法分析对SRL展开研究[3-5].虽然取得一定进步,但是并不能满足当前需求,因此也有许多学者尝试将更多语言学的线索用于提升SRL的性能.邵艳秋等[6]基于北京大学的汉语语义词典(CSD),引入了配价数、主客体语义类等词汇语义特征来进行SRL研究,所有角色标注的总体评价F1值比单纯使用句法特征的上升了1.11%;李国臣等[7]将基于同义词词林语义资源库构建新的特征加入条件随机场(CRF)模型中,新构建的词林信息特征显著提高了SRL的性能.上述基于统计机器学习的研究方法,尽管对于特征融合的研究具有深刻的借鉴意义,但均为人工抽取特征,工作繁琐沉重,抽取出的特征稀疏、模型复杂且易过拟合.
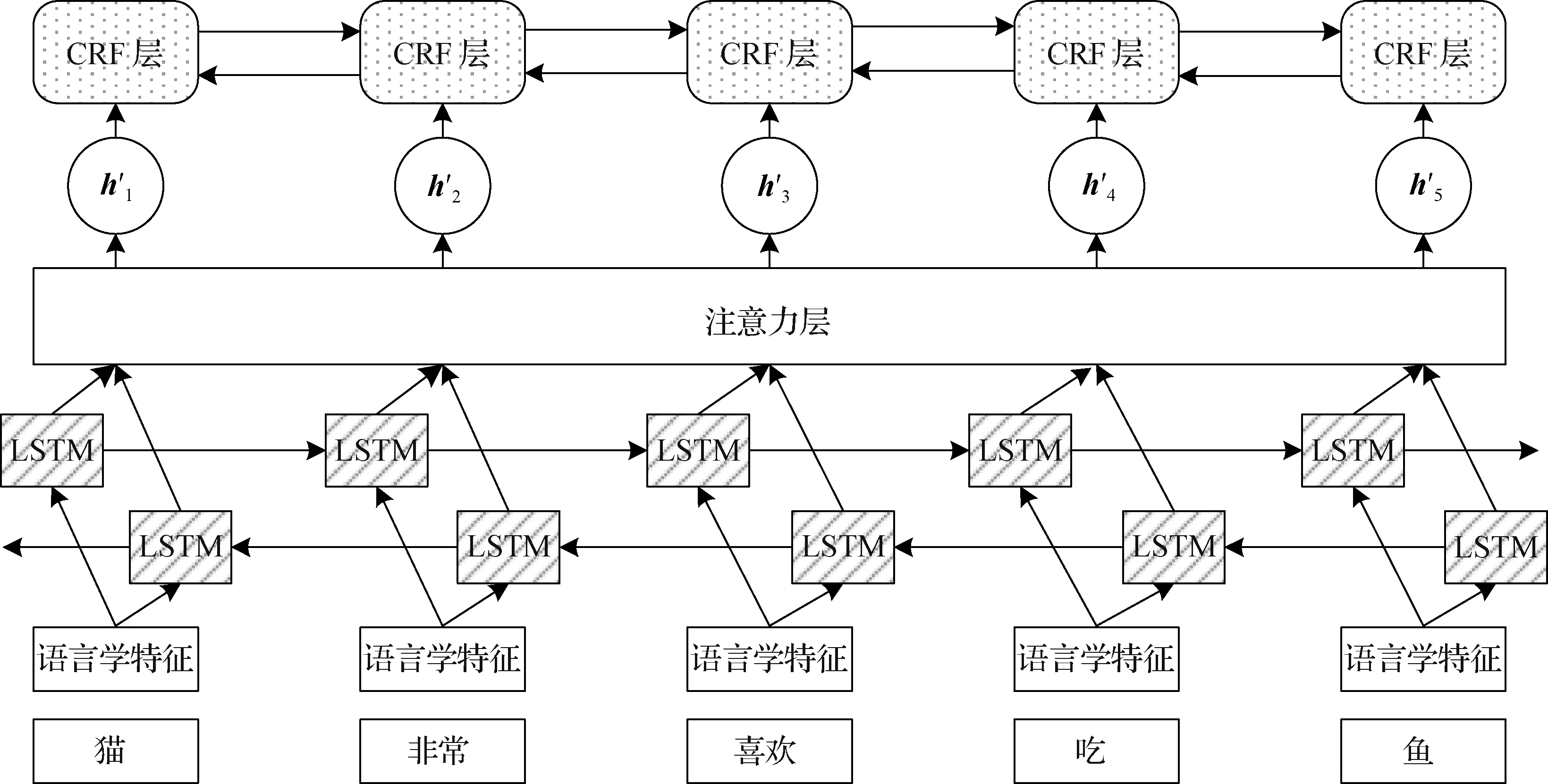
为融合句子中所有词语相关性的隐藏状态.图1 融合注意力机制的SRL模型结构Fig.1 SRL model structure incorporating attention mechanism
随着深度学习技术的发展以及计算机计算能力的提升,借助神经网络模型的超强非线性拟合能力,可实现特征信息句子的自动提取,同时模型可以处理更长距离的语义依赖,较好地兼顾上下文信息.利用深度学习方法进行SRL时,通常将其视作序列的标签分类任务.2008年,Collobert等[8]首次运用简单的神经网络进行SRL,随后,Socher等[9]采用神经网络单元与树结构编码器相结合的方式,Yin等[10]采用卷积神经网络进行SRL.但上述方法无法解决网络层数增加所带来的梯度爆炸现象,而且模型不能很好地理解长句的语义信息.长短时记忆(LSTM)的出现,基本解决了上述问题.Wang等[11]使用双向LSTM(BiLSTM)模型,在不引入任何其他资源的情况下,取得了当时最好的结果;张苗苗等[12]引入门控机制对词向量进行调整,同时扩展BiLSTM的深度以获取更深层次的语义信息,最终F1值可以达到79.53%.但对于SRL任务,相邻标签之间具有约束关系,BiLSTM无法学到该关系,不合理标签被大量预测的现象限制了模型性能的进一步提升.针对这种情况,Huang等[13]提出将BiLSTM和CRF结合,在CRF层引入标签转移概率矩阵,专门学习标签间的约束关系.
近些年,取得较好成绩的汉语SRL系统大部分基于BiLSTM-CRF序列标注模型.受到机器翻译模型中注意力机制的启发,本文尝试在BiLSTM-CRF模型中融入注意力机制,模型中添加注意力机制层计算序列中所有词语的关联程度,为进一步提升序列标注模型性能,并提出将词性、依存句法和短语结构句法等多种语言学特征同时融入模型.
1 模型构建
本文模型构建的工作从以下两点展开:1) 使用自然语言工具包对实验语料进行语言学特征的扩充;2) 搭建实验需要的模型.
1.1 特征提取
本文特征提取从基于依存关系和短语结构两方面入手.对于依存关系特征,借助开源工具包LTP(http:∥www.ltp-cloud.com/)[14]对实验语料进行依存句法分析,最终解析出16种依存关系.对于短语句法分析,借助开源工具包Berkeley Parser(http:∥code.google.com/p/berkeleyparser/)对实验使用的原始语料进行成分句法分析,共解析出24种成分句法关系.
1.2 模型结构
本文选取如图1所示的模型结构作为SRL模型,记为BiLSTM-attention-CRF模型.首先将句子中的词及其附加特征映射成词向量送入BiLSTM网络中;BiLSTM从已标注完成的语料中进行特征提取;然后通过注意力机制融合句中所有词语信息,生成新的融合全局信息的特征;最后使用CRF,消除非法标签被预测的现象,提高预测准确率.
1.2.1 输入层
本文采取预训练词向量,在SRL模型训练的同时对预训练的词向量进行微调.首先选取训练词向量的语料,训练语料来源于人民日报;其次根据人民日报语料的特点(数据量较小),选取连续词袋(CBOW)模型训练词向量,词向量维度为300维;再次根据CPB(Chinese Prop Bank)实验语料选取出现频率不低于3次的词作为CPB词表.最后根据训练好的人民日报词向量,制作CPB词表,对于在CPB词表中出现,但不在人民日报词表中出现的词,随机赋予符合正态分布的值.
将句子中的词以及附加的语言学特征转换成的词向量表示拼接送入下一层.
1.2.2 BiLSTM层

(1)
1.2.3 注意力层
注意力层可以生成新的特征,这个特征融合了句子序列中所有词语的信息,并且根据句子中不同词语之间的关联程度不同,分配不同的注意力系数.其训练过程可以理解为BiLSTM层输出的隐藏层状态{h0,h1,…,hn-1}经过注意力层的转换,生成融合句子中所有词语相关性的新的隐藏层状态{h′0,h′1,…,h′n-1},然后将新的隐藏层状态输入CRF层.
1.2.4 CRF层
本文实验语料通过BIOES(beginning-inside-outside-end-singleton)标记方法表达SRL中相邻标签之间的联系,B代表语义角色的开始,I代表语义角色的中间部分,E代表语义角色的结束,S代表单独一个语义角色,O代表非语义角色部分.例如在本文标注体系中,标签I-ARG2之前只能是B-ARG2或I-ARG2,而标签B-ARG2之后只能是I-ARG2、O、B-X或者S-X,其余的标签都是不应该被预测的.针对这种情况,CRF层通过引入概率转移矩阵的方式学习到相邻词语之间的标签联系,提升模型标注性能.即CRF层对句子序列中各标签的之间的转移概率进行建模,然后在所有的标签序列中,选取一条得分最高的路径作为最优标签序列.最优标签序列的得分公式为
(2)
其中,Aij表示标签i转移到标签j的概率,Pij代表句子序列中第i个词被预测为第j个语义角色的概率,θ是模型中可学习的参数,x是句子序列,y是句子序列对应的标签序列.对于非法标签之间的转移概率初值设为-10 000,表示该路径不被预测.
2 实 验
本文实验以公开的CPB语料集为基础,对其筛选剔除,建立SRL语料库作为本文实验的原始语料;搭建3组模型:BiLSTM、BiLSTM-CRF以及BiLSTM-attention-CRF;在模型训练阶段,依次向语料中添加新特征,逐步对基础模型进行优化训练,并进行模型测评,分析对比得到相关实验结论.
2.1 实验语料及参数设置
本文实验采用的CPB数据集,训练集共有17 821 句,测试集共有1 115句.对实验语料中句子长度构成进行简单分析统计,其中组成句子词语个数大于20个的称为长句,约占78%;小于20个但大于10个的称为中长句,约占18%,小于10个词语的称为短句,约占4%.实验模型使用的超参数词向量维度设为300,隐藏层维度设为200,失活率设为0.5,学习率设为0.001.
2.2 实验对比
实验1:测试对比经过基础语料训练的3组模型性能.本次实验使用的语料是在原始语料中添加词性特征组成的基础语料.词性可以帮助模型识别语义角色,例如,名词在句中大概率作为施事或者受事出现,动词通常作为核心成分.实验1的测试结果如表1所示.

表1 基础语料中3组模型性能的测试对比Tab.1 Comparison of performance test of three groups of models in basic corpus
从表1可以看出,BiLSTM-attention-CRF模型的各项指标均为最优,相对于BiLSTM其准确率、召回率和F1值分别提高了4.36,6.94和5.72个百分点.两种模型性能有明显差距.表2为例句“去年实现进出口总值达一千零九十美元”的标注结果.可见,未加入CRF预测标签时,“去年”的标注结果出错,而加入CRF预测标签后,例句的标注结果与正确标签一致,因此本文接下来的实验使用加入CRF预测标签的BiLSTM-CRF和BiLSTM-attention-CRF两种模型进行对比.

表2 是否加入CRF的标注结果Tab.2 Result with and without CRF annotation
实验2:在基础语料中分别添加依存句法特征、短语结构句法特征、依存句法特征+短语句法特征,组成3组训练语料,测试对比不同的句法结构对模型性能的影响.测试结果如表3所示,其中将依存句法特征简写为Dep,短语结构句法特征简写为Phrase.

表3 添加不同句法特征的模型性能对比Tab.3 Performance comparison of models with different syntactic features
单独采用准确率或召回率作为评价指标不能客观反应模型的综合性能,F1值同时结合准确率和召回率,能较为客观地反应模型综合性能,故本实验主要通过对测试结果的F1值进行对比分析.分析结果发现,融合3种特征的模型F1值都出现了显著提升.其中只融合依存句法特征和只融合短语句法结构特征对标注模型的综合性能提升幅度类似;相比于只融合其中一种特征的模型,融合了依存句法特征+短语句法结构特征的模型F1值提升最大.但是融合两种特征的模型综合性能提升幅度放缓,并没有明显高于只融合一种句法特征的模型性能.分析可能原因是过多的语言学线索,虽然为模型提供充足的语义信息,同时也降低了模型的收敛能力,训练难度增加,没有起到一加一大于二的实验效果.
实验3:为验证“融合两种特征的模型综合性能提升幅度放缓,可能是因过多的语言学线索,增加模型收敛难度”的想法.实验探索池化后的多特征组是否可以进一步提升模型性能.分别采取平均池化(average pooing,AvgPool)和最大池化(max pooling,MaxPool)对附加的语言学特征组采样提取,其中池化域大小设为3.表4是不同池化技术对模型性能提升的对比结果.

表4 不同池化技术对模型性能提升对比Tab.4 Comparison of model performance with different pool technologies
实验结果表明:与表3的结果相比,经过MaxPool采样提取模型的F1值没有得到提升,反而略有下降.经过AvgPool采样提取的模型F1值得到提升.因为相比于MaxPool选取池化域中最大特征,AvgPool对池化域内所有特征求和取平均可以保留更多语言学信息,同时还能减少训练参数,进一步提升模型性能.另外从F1值来看,该结果比文献[12]的79.53%高出了1.73个百分点.
3 结 论
本文在基于BiLSTM-attention-CRF模型进行汉语SRL时,尝试在训练语料中融入词性、依存句法特征以及短语结构句法特征,同时尝试采取池化手段对多特征组采样.实验结果表明,模型中融入注意力机制可以显著提升模型效果,同时通过针对性的添加新特征,还能进一步提升标注准确率.在未来的研究工作当中,将重点探究对词向量选取的进一步优化以及在模型中融入新的特征.
