基于gSpan改进算法的中医辨证论治模式挖掘研究
2021-11-01任晋宇白琳周志阳冯睿智钟华
任晋宇,白琳,周志阳,冯睿智,钟华
中医药信息学
基于gSpan改进算法的中医辨证论治模式挖掘研究
任晋宇1,白琳1,周志阳1,冯睿智2,钟华1
1.中国科学院软件研究所,北京 100190;2.四川大学华西医院,四川 成都 610041
扩展经典的频繁子图挖掘算法以获得在中医学科中表现更好的数据挖掘效果,从而得出隐含在中医病案中的辨证论治模式。结合中医病案数据特征,扩展经典的图挖掘算法,对多个症状属性分别设置最小支持度阈值参数,再用扩展后的基于多重最小支持度的数据挖掘算法对数据集中蕴含的辨证论治模式进行挖掘。对3 319条慢性阻塞性肺疾病(急性加重期)真实病案数据应用扩展的频繁子图挖掘算法,得到一系列该病相关的八纲辨证模式。与经典算法相比,扩展算法挖掘得到的辨证模式在模式维度和数量方面均明显提升。扩展后的频繁子图挖掘算法能够运用于中医辨证论治模式的挖掘,发现病案中隐含的辨证规律,且在模式完备性上具有比原始算法更好的效果。
模式挖掘;频繁子图;多重最小支持度;辨证论治模式
数据挖掘是从数据集中发现潜在的、隐藏的归纳性知识的一种方法,能在纷繁的数据中获得具有代表性、可信度高的信息。传统的分类、聚类等数据挖掘算法主要针对简单类型数据进行挖掘。对于图这种计算机科学中通用的数据结构,普通数据挖掘算法难以应对其内部错综复杂的顶点之间的关系[1]。为解决这一问题,图数据挖掘应运而生,并且已经成为数据挖掘领域的基础性研究问题,特别是频繁子图挖掘方向引起了广泛关注。频繁子图挖掘的目的是找到在图集中频繁出现的子图模式,所得结果集可应用于相似性搜索[2-3]、图聚类和分类[4-6]、图索引[7-8]等诸多场景[9],其需求推动着该领域高速发展[10-11]。
中医名家的诊疗经验难以客观化,限制了中医的传承和发展,因此构建标准化的信息系统以辅助诊断尤为重要。中医理论体系中,多种辨证论治模式纷繁复杂,一般的数据结构难以表达模型中的复杂关系。本研究结合图挖掘理论,改进经典的图挖掘算法,将中医诊疗数据隐含的诊断模式视作一个图以简化问题,以中医思维理念模型为基础,融合八纲辨证知识,将每一个病案信息建模为一个图结构,在这些图构成的数据集中挖掘频繁子图,分析所得结果中目标病症的诊治规律,从而得出中医辨证论治模式,以期为大数据驱动的中医智能辅助诊断系统提供核心服务。
1 基本概念
根据数据挖掘理论,频繁出现的图结构包含可利用的、高价值的信息,频繁子图挖掘即在多个图构成的图集中寻找频繁出现的图结构。本研究基于性能较优的gSpan算法进行扩展,从而提升算法对中医病案数据集的挖掘效果。
1.1 图及相关概念形式化定义
1.1.1 标记图
标记图是边和顶点均带有标签的图,可以表示为五元组=(,,,,)。式中,是图的非空顶点集合,是图的非空边集合,和分别是图的顶点标签集合和边标签集合,为→、→的映射关系。
1.1.2 子图
标记图1=(1,1,1,1,1)是标记图2=(2,2,2,2,2)的子图,当且仅当①1⊆2,1⊆2;②∀∈1,1()=2();③∀(,)∈1,1(,)=2(,),记作1⊆2。
1.1.3 子图同构
设有标记图1=(1,1,1,1,1)与标记图2=(2,2,2,2,2),如果存在一个1到2的双射函数:1→2,且满足1=<1i,1j>是图1的一条边,则称1与2同构,记作1≌2;如果存在1≌2且2⊆,则称1子图同构于。
1.1.4 支持度
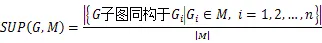
1.1.5 频繁子图
给定一个图集合={1,2,…,G}和最小支持度阈值∈(0,1],如果图G是频繁的,当且仅当(,)≥。
2 算法描述
2.1 原始算法
gSpan算法基于深度优先搜索思想和最右路径扩展方法,并通过逐步扩展频繁边而生成频繁子图。gSpan算法对访问过的顶点集合反复扩展,从而建立一个深度优先搜索树。由于gSpan算法扩展时只对最小的DFS(深度优先搜索)编码进行最右扩展,因而有效减少了复制图的产生[12],借此提高了挖掘效率。算法及子程序如下:
2.2 扩展算法
原始的gSpan算法设置统一的最小支持度参数,挖掘结果为在图集中出现频率大于该支持度的所有频繁子图。将gSpan算法应用于中医学具体问题时,由于各症状值域分布范围不同,造成某些症状特征因值域范围广而出现概率低的情况。以中医症状属性“脉象”为例,其取值包括沉、滑、弱、涩、细、迟、缓、软、弦、数、疾、紧、濡、稳、代、弦、促、浮、洪、结、平等数十种。我们将症状属性连同其某个取值合称为一个症状特征,如“脉象沉”“脉象滑”。如果对全部症状特征都设置相同的最小支持度参数,会使因值域范围广而出现概率低的症状特征被视为低频特征,在模式挖掘过程中被过滤掉,而这些特征有可能是辨证论治的关键特征,将其过滤掉可能造成辨证论治模式完备性的缺失。因此,采用扩展的gSpan算法,结合症状属性值域范围和数值分布特征,为每个症状属性分别设置单独的最小支持度参数,实现基于多重最小支持度的辨证论治模式挖掘。算法如下:
3 算法应用
3.1 数据来源与筛选
以慢性阻塞性肺疾病(急性加重期)中医病案为实验数据,来源于四川大学华西医院医院信息系统,为该院中西医结合科2011年1月1日-2019年1月31日出院患者病案。由于该病临床证名繁多,难以统一归类,而八纲辨证(阴阳、表里、寒热、虚实)全部为二分类,条目清晰,因此,根据原始中医辨证结果,结合病历记载的四诊资料,标记出八纲辨证。
纳入标准:病案首页主诊断为慢性阻塞性肺疾病(急性加重期)且记录完整清晰,包括完整的四诊信息和诊断信息。排除标准:①缺失“中医证候”项;②缺失患者四诊描述信息;③“中医证候”项的值错填为西医疾病名。根据纳入和排除标准筛选后得到3 319条病案数据,按照八纲辨证进行统计,结果见表1。其中,表证病案仅10条,且相关研究显示慢性阻塞性肺疾病(急性加重期)患者特别是住院患者表证很少[13-15],故本文不讨论表证辨证模式。
表1 3 319条慢性阻塞性肺疾病(急性加重期)病案数据八纲辨证分布
八纲辨证病案数百分比/% 八纲辨证病案数百分比/% 阴证1 92958.1 寒证1 62248.9 阳证1 39041.9 热证1 69751.1 虚证1 09132.9 表证 10 0.3 实证2 22867.1 里证3 30999.7
3.2 数据预处理
3.2.1 四诊信息规范化处理与分词
为每个症状描述信息(即症状特征)定义一个标准名称,对四诊信息进行规范化处理,如“脘腹按痛”“脘腹按压痛”“脘腹按压疼痛”统一为“脘腹按痛”。分词是将复杂文本描述的症状信息进行拆分,分解为细粒度的最小症状描述单位,如“脉象沉弦细数”分词为“脉象沉”“脉象弦”“脉象细”“脉象数”。
3.2.2 数据建模
根据“1.1”项下定义,每条病案数据对应一个图结构。病案中表现异常的症状属性与该病案诊断的八纲证型构成图的顶点集合,症状属性与八纲证型的联系构成图中边的集合,边的标记为这条边关联的症状属性在病案中表现的症状特征。
以病案集中第0005号病案为例,症状为“恶寒发热,盗汗,纳呆,常口渴,夜间失眠,呼吸气粗,痰白色黏稠,脉沉”,证候为“痰热犯肺”,属阳证。根据建模规则,病案中表现异常的症状属性“寒热”“汗”“饮食”“口”“睡眠”“呼吸”“痰”“脉象”,以及所属的八纲证型“阳证”共同构成图的顶点集合。每个症状属性顶点与证型顶点之间以边相连。边的起点为症状属性顶点,终点为证型顶点,表明该症状属性属于该证型的临床关联属性。“恶寒发热”“盗汗”“纳呆”等症状特征作为边的标记标注在相应症状属性对应的边上。该病案对应的图结构见图1。
3.3 支持度参数设置
依据各症状属性对应的症状特征分布情况,对不同症状属性设置不同的最小支持度。统计结果显示,病案数据的四诊信息可通过19个症状属性进行描述,包括“舌苔色”“舌苔质”“饮食”“睡眠”“痰”“脉象”等,同一病案的症状属性最多有17个,最少仅1个,约86%病案的症状属性为5~10个,见图2。
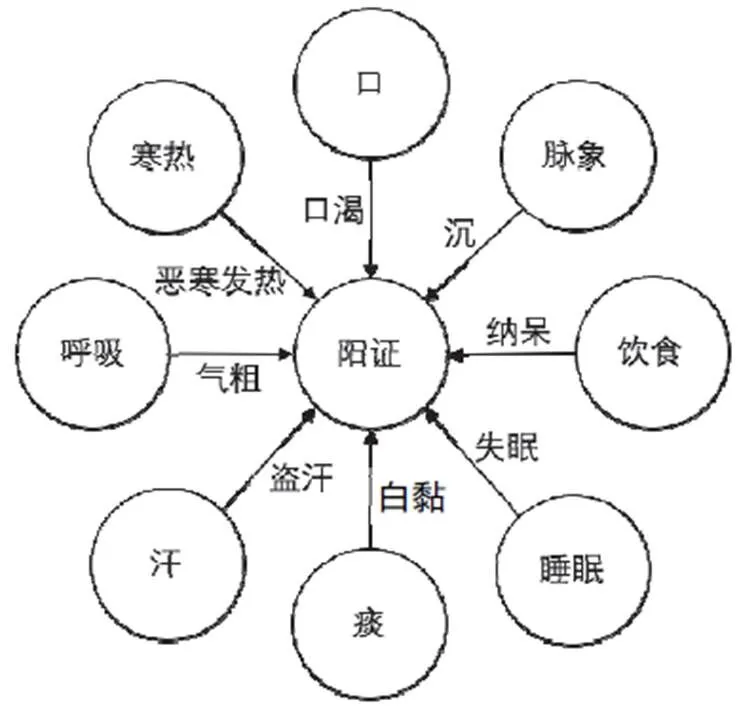
图1 病案记录转化为图模型示例
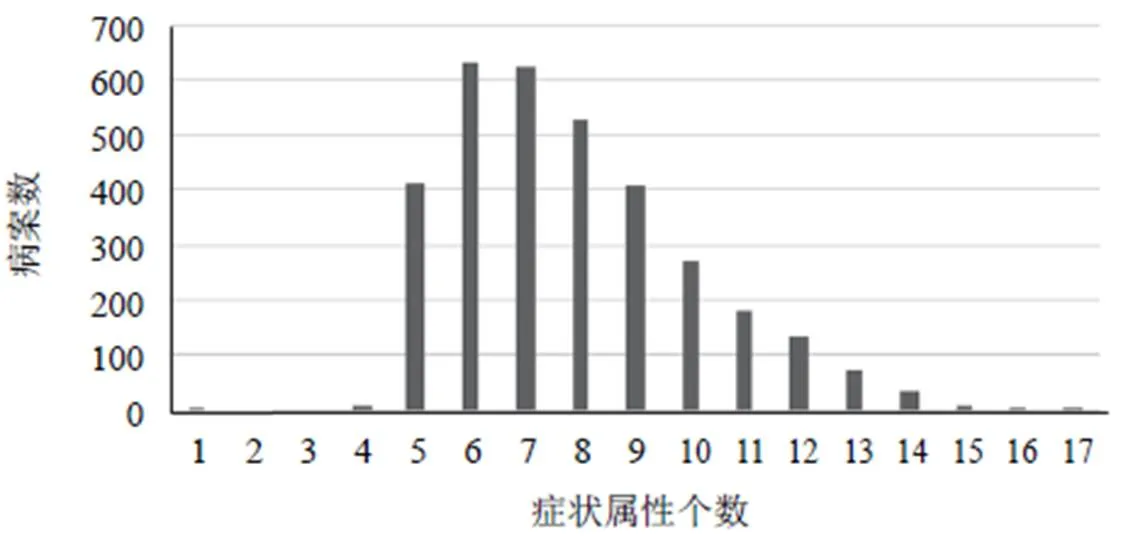
图2 3 319条慢性阻塞性肺疾病(急性加重期)病案数据症状属性分布
不同症状属性的症状特征数量及其出现频率存在较大差异。“脉象”这一症状属性的症状特征数量最多,在八纲证型(阴、阳、虚、实、寒、热、里7种证型)上表现的特征数量分别为34、27、25、29、36、29、35个;症状特征数量最少的是“睡眠”“饮食”“汗”症状属性,均包含2个症状特征,分别为“失眠”“嗜睡”、“纳呆”“多食易饥”、“盗汗”“自汗”。出现频率最高的是“舌苔质”属性对应的“舌苔质薄”,为81.2%。症状特征分布较为分散,只有约9%的症状特征出现频率在20%以上,见图3。
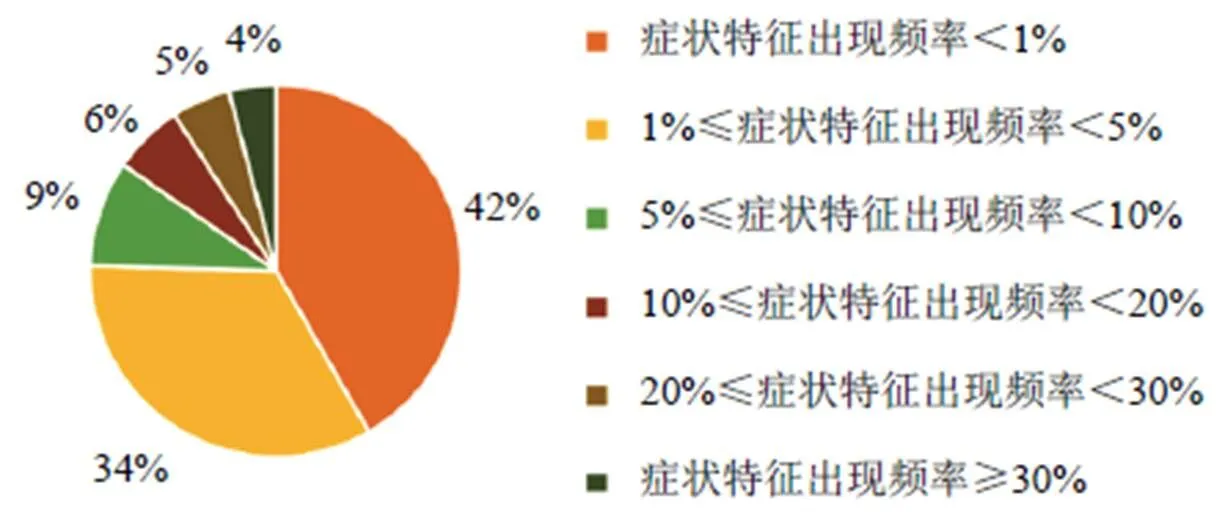
图3 3 319条慢性阻塞性肺疾病(急性加重期)病案数据症状特征出现频率分布
对每一个症状属性,根据其症状特征的出现频率分布情况,设置最小支持度参数。具体方法:①设δ为挖掘算法的默认最小支持度,为当前症状属性对应的全部症状特征频率的集合;②若min()<δ(即全部为低频特征),则以δ为当前症状属性的最小支持度参数,过滤全部低频特征;③若max()>δ(即全部为高频特征),则以δ为当前症状属性的最小支持度参数,筛选全部高频特征;④否则,计算中各频率值的离散程度,若标准差σ()<α,表明各症状特征的频率分布相对集中,取的上四分位数QU()作为当前症状属性的最小支持度参数,筛选优势特征;否则,中各频率值分布较为分散,取对排序位置不敏感的平均数AVE()作为当前症状属性的最小支持度参数。其中,α为可设定的阈值。
以“热证”为例:1 697条病案中,症状属性“舌苔色”的症状特征包括“舌苔色黄”“舌苔色白”,频率分别为52%、48%,设定δ=20%、α=20,则最小支持度参数minSup.舌苔色=20%。类似的,症状属性“脉象”的症状特征“脉象滑”“脉象数”“脉象弦”“脉象细”“脉象沉”“脉象弱”“脉象浮”“脉象濡”“脉象虚”“脉象洪”“脉象缓”“脉象代”“脉象涩”“脉象结”频率分别为48%、48%、22%、19%、10%、5%、4%、2%、1%、1%、1%、1%、1%、1%,标准差σ()=16.22,则minSup.脉象=QU()=17%。
3.4 挖掘结果与分析

表2 原始算法挖掘得到的辨证论治模式数量(不包含子模式)
证型最小支 持度/%模式维度合计 证型最小支 持度/%模式维度合计 二维三维四维五维 二维三维四维五维 寒证10495119 阴证10958022 1511608 15415010 2013408 2011406 2502305 2536009 3033006 3021003 热证10153011056 阳证1093010150 1517200037 1513182033 201540019 209110020 251010011 25830011 3080008 3090008 虚证1013128033 里证1013185036 1540105 151043017 2015107 20570012 25933015 2551006 3003003 3031004 实证1011248043 151363022 201121014 2563009 3041005
可以看出,采用单一最小支持度进行挖掘,从模式的数量和维度两方面综合考虑,参数设置为20%时,挖掘结果最理想。因此,选取20%作为原始挖掘算法的最小支持度参数与扩展算法进行比较,同时将扩展算法中多重最小支持度的默认值δ设置为20%。挖掘结果见表3~表9(辨证论治模式以所包含的症状特征表示)。其中,模式的支持度即该模式在当前病案集中的出现频率。
表3 寒证单一和多重最小支持度设置挖掘结果比较(模式维度≥3)
最小支持度设置辨证论治模式支持度/% 单一{舌苔质薄,舌苔色白,舌色淡红,痰白色}26 minSup=20%{舌苔质薄,舌苔色白,舌色淡红,脉象滑}26 {舌苔质薄,舌苔色白,舌色淡红,脉象细}25 {舌苔质薄,舌苔色白,舌色淡红,脉象数}23 {舌苔色白,舌色淡红,饮食纳呆}21 {舌苔质薄,舌色淡红,饮食纳呆}20 {舌苔质薄,舌苔色白,饮食纳呆}20 多重{舌苔质薄,舌苔色白,舌色淡红,痰白色}26 minSup.睡眠=18%{舌苔质薄,舌苔色白,舌色淡红,脉象滑}26 minSup.痰=34%{舌苔质薄,舌苔色白,舌色淡红,脉象细}25 minSup.舌色=50%{舌苔质薄,舌苔色白,舌色淡红,脉象数}23 minSup.舌苔色=50%{舌苔质薄,舌苔色白,舌色淡红,饮食纳呆}19 minSup.舌苔质=17%{舌苔色白,舌色淡红,脉象弦}17 minSup.脉象=17%{舌苔质薄,舌色淡红,脉象弦}17 minSup.其他=20%
表4 热证单一和多重最小支持度设置挖掘结果比较(模式维度≥3)
最小支持度设置辨证论治模式支持度/% 单一{舌苔质薄,舌苔色黄,舌色红}26 minSup=20%{舌苔质薄,舌苔色白,舌色淡红}23 {舌苔质薄,舌苔色黄,脉象滑}22 {舌苔质薄,舌苔色黄,痰白色}21 多重{舌苔质薄,舌苔色黄,舌色红}26 minSup.睡眠=24%{舌苔质薄,舌苔色白,舌色淡红}23 minSup.痰=26%{舌苔质薄,舌苔色黄,脉象滑}22 minSup.舌苔质=15%{舌苔质薄,舌苔色黄,痰白色}21 minSup.脉象=17%{舌苔质薄,舌色红,痰白色}19 minSup.其他=20%{舌苔质薄,舌色淡红,脉象滑}19 {舌苔质薄,舌色红,脉象滑}18 {舌苔质薄,脉象滑,脉象数}18 {舌苔质薄,舌苔色黄,脉象数}18 {舌苔质薄,脉象滑,痰白色}17 {舌苔色黄,舌色红,脉象滑}17 {舌苔质薄,舌色红,脉象数}17 {舌苔质薄,舌苔色白,脉象数}17 {舌苔质薄,舌色淡红,脉象数}17 {舌苔质薄,舌苔色白,脉象滑}16 {舌苔质薄,舌色红,饮食纳呆}15 {舌苔质薄,舌苔色黄,饮食纳呆}15
表5 虚证单一和多重最小支持度设置挖掘结果比较(模式维度≥3)
最小支持度设置辨证论治模式支持度/% 单一{舌苔质薄,舌苔色白,舌色淡红,脉象细}26 minSup=20%{舌苔质薄,舌苔色白,脉象数}24 {舌苔质薄,舌苔色白,痰白色}21 {舌苔色白,舌色淡红,脉象数}21 {舌苔质薄,舌色淡红,脉象数}20 {舌苔质薄,舌苔色白,饮食纳呆}20 多重{舌苔质薄,舌苔色白,舌色淡红,脉象细}26 minSup.痰=32%{舌苔质薄,舌苔色白,舌色淡红,脉象数}19 minSup.舌苔色=50%{舌苔质薄,舌苔色白,舌色淡红,痰白色}16 minSup.舌苔质=14%{舌苔质薄,舌苔色白,舌色淡红,饮食纳呆}14 minSup.其他=20%{舌苔质薄,舌苔色白,脉象滑}14
表6 实证单一和多重最小支持度设置挖掘结果比较(模式维度≥3)
最小支持度设置辨证论治模式支持度/% 单一{舌苔质薄,舌苔色白,舌色淡红,脉象滑}22 minSup=20%{舌苔质薄,舌色淡红,痰白色}21 {舌苔质薄,舌色淡红,脉象数}21 多重{舌苔质薄,舌苔色白,舌色淡红,脉象滑}22 minSup.睡眠=22%{舌苔质薄,舌色淡红,痰白色}21 minSup.痰=36%{舌苔质薄,舌苔淡红,脉象数}21 minSup.舌苔质=17%{舌苔质薄,舌苔色白,脉象数}19 minSup.脉象=17%{舌苔质薄,舌苔色白,痰白色}18 minSup.其他=20%{舌苔质薄,痰白色,脉象滑}18 {舌苔色白,舌色淡红,脉象数}18 {舌苔质薄,舌苔色黄,舌色红}17 {舌苔质薄,舌苔色黄,脉象滑}17 {舌苔质薄,脉象滑,脉象数}17
表7 阴证单一和多重最小支持度设置挖掘结果比较(模式维度≥3)
最小支持度设置辨证论治模式支持度/% 单一{舌苔质薄,舌苔色白,舌色淡红,脉象滑}23 minSup=20%{舌苔质薄,舌苔色白,舌色淡红,痰白色}22 {舌苔质薄,舌苔色白,舌色淡红,脉象细}21 {舌苔质薄,舌苔色白,舌色淡红,脉象数}20 {舌苔质薄,舌苔色白,饮食纳呆}20 多重{舌苔质薄,舌苔色白,舌色淡红,脉象滑}23 minSup.痰=34%{舌苔质薄,舌苔色白,舌色淡红,痰白色}22 minSup.舌苔色=50%{舌苔质薄,舌苔色白,舌色淡红,脉象细}21 minSup.舌苔质=14%{舌苔质薄,舌苔色白,舌色淡红,脉象数}20 minSup.脉象=16%{舌苔质薄,舌苔色白,舌色淡红,饮食纳呆}16 minSup.其他=20%{舌苔质薄,舌色淡红,脉象弦}20 {舌苔质薄,舌苔色白,脉象弦}20
表8 阳证单一和多重最小支持度设置挖掘结果比较(模式维度≥3)
最小支持度设置辨证论治模式支持度/% 单一{舌苔质薄,舌苔色黄,舌色红}28 minSup=20%{舌苔质薄,舌苔色白,舌色淡红}27 {舌苔质薄,舌苔色黄,脉象滑}26 {舌苔质薄,舌苔色黄,痰白色}24 {舌苔质薄,舌色淡红,脉象滑}22 {舌苔质薄,舌苔色黄,脉象数}21 {舌苔质薄,脉象滑,脉象数}21 {舌苔质薄,脉象滑,痰白色}20 {舌苔色黄,舌色红,脉象滑}20 {舌苔质薄,舌色红,脉象滑}20 {舌苔质薄,舌色淡红,脉象数}20 多重{舌苔质薄,舌苔色白,舌色淡红}27 minSup.睡眠=23%{舌苔质薄,舌苔色黄,痰白色}24 minSup.痰=28%{舌苔质薄,舌色淡红,脉象滑}22 minSup.舌苔质=17%{舌苔质薄,脉象滑,脉象数}21 minSup.脉象=15%{舌苔质薄,脉象滑,痰白色}20 minSup.其他=20%{舌苔质薄,舌色淡红,脉象数}20 {舌苔质薄,舌色红,痰白色}19 {舌苔质薄,舌苔色黄,舌色红,脉象滑}17 {舌苔色黄,痰白色,脉象滑}17 {舌苔质薄,舌苔色黄,饮食纳呆}17 {舌苔质薄,舌苔色白,脉象滑}17 {舌苔色黄,舌色红,脉象数}17 {舌苔质薄,舌苔色白,脉象数}17 {舌苔质薄,舌色红,脉象数}16 {舌苔质薄,痰白色,脉象数}15 {舌苔质薄,饮食纳呆,脉象滑}15 {舌苔色黄,脉象滑,脉象数}15
表9 里证单一和多重最小支持度设置挖掘结果比较(模式维度≥3)
最小支持度设置辨证论治模式支持度/% 单一{舌苔质薄,舌苔色白,舌色淡红}49 minSup=20%{舌苔质薄,舌色淡红,脉象滑}23 {舌苔质薄,舌苔色白,脉象滑}22 {舌苔色白,舌色淡红,脉象滑}21 {舌苔质薄,舌色淡红,脉象数}21 {舌苔质薄,舌色淡红,痰白色}20 {舌苔质薄,舌苔色白,脉象数}20 多重{舌苔质薄,舌苔色白,舌色淡红,脉象滑}19 minSup.睡眠=21%{舌苔质薄,舌苔色白,舌色淡红,脉象数}17 minSup.舌苔质=14%{舌苔质薄,舌苔色白,脉象细}17 minSup.脉象=22%{舌苔质薄,舌苔色白,饮食纳呆}16 minSup.其他=20%{舌苔质薄,舌苔色白,舌色淡红,痰白色}15 {舌苔质薄,舌色淡红,饮食纳呆}20 {舌苔质薄,痰白色,脉象滑}14 {舌苔质薄,舌色淡红,脉象细}14
可以看出,与采用单一最小支持度的原始算法相比,扩展挖掘算法根据病案中不同症状属性的特征分布设置多重最小支持度参数,挖掘结果在模式的维度、数量方面均有所提升。具体表现在三方面:第一,发现更高维度的新模式,如模式r:阳证←{舌苔质薄,舌苔色黄,舌色红,脉象滑}、r:阴证←{舌苔质薄,舌苔色白,舌色淡红,饮食纳呆}等都是在原有三维模式的基础上经设置多重最小支持度参数而发现的更高维度的新模式;第二,发现症状特征间新的关联组合方式,如模式r:实证←{舌苔质薄,痰白色,脉象滑}、r:热证←{舌苔色黄,舌色红,脉象滑}等;第三,发现新的症状特征及其模式,如模式r:寒证←{舌苔色白,舌色淡红,脉象弦}中的“脉象弦”、r:里证←{舌苔质薄,舌苔色白,饮食纳呆}中的“饮食纳呆”都是设置多重最小支持度参数后发现的新的症状特征。可见,采用扩展算法设置多重最小支持度后,挖掘的辨证论治模式在完备性方面较原始算法有明显提升。
将挖掘的辨证论治模式与《中医诊断学》[16]所述八纲辨证进行比较可以看出,模式中包含的症状特征基本符合《中医诊断学》相应证型的临床症状描述。以阳证为例,《中医诊断学》有“阳证临床表现面赤……喘促痰鸣……舌红绛……苔黄黑生芒刺……脉浮数、洪大、滑实”,结合阳证辨证论治模式挖掘结果(见表8):一方面,证实“舌色红”“舌苔色黄”“饮食纳呆”“脉象滑”“脉象数”等症状特征确是“阳证”的关键特征,所挖掘的“阳证”辨证论治模式中包含上述症状特征是准确的,并且采用扩展算法更有效地发现了“饮食纳呆”这一阳证辨证的关键症状特征;另一方面,说明“舌色”“舌苔色”“脉象”等是慢性阻塞性肺疾病(急性加重期)的典型辨证属性,其中,在“阳证”诸多“脉象”表现中,“脉象滑”和“脉象数”是该病“阳证”的典型症状表现。
4 讨论
本研究将扩展的频繁子图挖掘算法应用于中医病案挖掘,旨在解决原始算法中单一最小支持度在挖掘过程中可能产生的关键症状缺失问题,通过改善最小支持度参数设置方式,基于各症状属性的值域范围和数据分布特征设置多重最小支持度参数,发现和挖掘低频关键症状特征,进而提高辨证论治模式的完备性。挖掘得到的辨证论治模式的支持度即该模式在整个病案集中出现的频率,能够有效反映模式中包含的各症状特征在相应证型病案中共现的概率,是衡量模式有效性的重要指标。另外,考虑到算法应用的医疗背景,模式的“特异性”也是衡量模式价值的一个关键因素。临床中存在许多常见但对疾病或证型辨识度并不高的非特异性症状,如发热、乏力等,通过计算症状对某个疾病或证型的“特异性指数”可以得出整个辨证论治模式的“特异性指数”,从而有效识别支持度虽高但对疾病或证型辨识度并不高的辨证模式。此外,如果将挖掘得到的辨证论治模式应用于症状间的关联分析和影响力分析,置信度、不平衡比等指标也是评价模式有效性的重要指标。对辨证论治模式的评价是一个综合、复杂的过程,且与实际应用场景密切相关。本研究重点解决辨证论治模式挖掘的完备性问题,旨在发现更多具有辨证能力的关键症状特征,今后将继续研究和探讨模式的综合评价。
探究中医辨证论治模式是大数据、数据挖掘在中医学科研究中的重要内容。本研究通过扩展经典的图挖掘算法,改善了原始算法对现有数据集的挖掘效果,挖掘得到的辨证论治模式能够包含更多的关键症状特征,提高了挖掘结果的完备性。除算法外,挖掘结果在很大程度上依赖数据集的质量。更大量级的数据集能够使症状特征的分布更趋近其在相关疾病或证型上的自然分布,从而更有利于挖掘出更为真实、准确的辨证模式。另外,数据的标准化程度也在很大程度上影响模式挖掘的效果,未经标准化或标准化不足的症状特征描述会导致更加分散的特征分布,使关键症状的提取更加困难,进而影响挖掘效果。因此,在改进算法的基础上,逐步丰富病案数据集、提高数据标准化程度是进一步改善辨证论治模式挖掘效果的重要工作内容。
[1] 崔景洋.图数据挖掘研究[J].太原师范学院学报(自然科学版),2018, 17(1):38-40,46.
[2] WANG K, LIU H Q. Discovering typical structures of documents:a road map approach[C]//Proceedings of the 21st Annual International ACM Conference on Research and Development in Information Retrieval.New York:ACM,1998:146-154.
[3] KRIEGEL H, SCHONAUER S. Similarity search in structured data[C]//Proceedings of the 5th International Conference on Data Warehousing and Knowledge Discovery.Berlin:Springer-Verlag, 2003:309-319.
[4] FISCHER A, RIESEN K, BUNKE H. An experimental study of graph classification using prototype selection[C]//Proceedings of the 19th International Conference on Pattern Recognition.Washington, DC:IEEE Computer Society,2008:1-4.
[5] HUANG J B, SUN H L, HAN J W, et al. SHRINK:a structuralclustering algorithm for detecting hierarchical communities in networks[C]//Proceedings of the 19th ACM International Conference on Information and Knowledge Management.New York:ACM,2010:219-228.
[6] HUANG J B, SUN H L, SONG Q B, et al. Revealing density-based clustering from the core-connected tree of a network[J]. IEEE Transactions on Knowledge and Data Engineering,2013,25(8):1876- 1889.
[7] YAN X F, YU P, HAN J W. Graph indexing:a frequent structure-based approach[C]//Proceedings of the 2004 ACMSIGMOD International Conference on Management of Data. New York:ACM,2004:335-346.
[8] WILLIAMS D W, HUAN J, WANG W. Graph database indexing using structured graph decomposition[C]//Proceedings of the 23rd IEEE International Conference on Data Engineering. Washington,DC:IEEE Computer Society,2007:231-235.
[9] 孙鹤立,陈强,刘玮,等.利用MapReduce平台实现高效并行的频繁子图挖掘[J].计算机科学与探索,2014,8(7):790-801.
[10] 严玉良,董一鸿,何贤芒,等.FSMBUS:一种基于Spark的大规模频繁子图挖掘算法[J].计算机研究与发展,2015,52(8):1768-1783.
[11] 王海荣.基于加权频繁子图挖掘的图模型在文本分类中的应用[J].科学技术与工程,2014,14(22):80-85.
[12] YAN X F, HAN J W. gSpan:graph-based substructure patterns mining[C]//Proceedings of the 2002 IEEE International Conference on Data Mining.Washington,DC:IEEE Computer Society,2002:721- 724.
[13] 徐卫方,哈木拉提•吾甫尔,李风森,等.乌鲁木齐地区375例慢性阻塞型肺疾病急性加重期中医证候及证素特点临床研究[J].中华中医药杂志,2011,26(6):1401-1404.
[14] 叶玲.慢性阻塞性肺疾病急性加重期103例中医证型聚类分析[J].广西中医学院学报,2011,14(4):9-11.
[15] 林琳,胡旭贞.慢性阻塞性肺疾病急性加重期中医证候规律的初步探讨[J].广州中医药大学学报,2008,25(1):1-4.
[16] 李灿东,陈家旭.中医诊断学[M].北京:中国中医药出版社,2019:174.
Study on Pattern Mining of TCM Syndrome Differentiation and Treatment Based on Improved gSpan Algorithm
REN Jinyu1, BAI Lin1, ZHOU Zhiyang1, FENG Ruizhi2, ZHONG Hua1
To extend the classic frequent subgraph mining algorithm to obtain a data mining method that performs better in TCM; To obtain the patterns of TCM syndrome differentiation and treatment implicit in the TCM medical records.Combining with the characteristics of TCM medical records data and extending the classic frequent subgraph mining algorithm, data mining algorithm which set different minimum support threshold parameters for different symptom attributes was used to discover the patterns of TCM syndrome differentiation and treatment contained in the data set.The extended frequent subgraph mining algorithm was applied to the 3319 real medical records of chronic obstructive pulmonary disease (acute exacerbation period), and a series of patterns of syndrome differentiation of eight principles related to the disease were obtained. Compared with the classic algorithm, the patterns of TCM syndrome differentiation obtained by the extended algorithm had a significant improvement in the dimension and quantity of patterns.The expanded frequent subgraph mining algorithm can be used in the TCM syndrome differentiation and treatment pattern mining as well as find the implicit syndrome differentiation rules in medical records, and it has a better effect than the original algorithm in the completeness of the patterns.
pattern mining; frequent subgraph; multiple minimum supports; patterns of syndrome differentiation and treatment
R229;R2-05
A
1005-5304(2021)10-0022-07
10.19879/j.cnki.1005-5304.202003457

国家重点研发计划(2017YFB1002303)
白琳,E-mail:bailin@otcaix.iscas.ac.cn
(收稿日期:2020-03-17)
(修回日期:2020-08-18;编辑:陈静)
