支持汽车故障数据增值的词汇增强实体识别
2021-11-01杨雯迪任春华孙洁香
杨雯迪,任春华,孙洁香
(1.西南交通大学信息科学与技术学院,成都 611756;2.北京机械工业自动化研究所有限公司,北京 100120)
0 引言
在制造业产业协同与信息化技术支撑四川省重点实验室研发的汽车产业链协同平台上汇聚了多条汽车产业价值链的销售、配件、服务等业务协同数据,其中包括大量非结构化的文本数据,由于描述性的故障文本信息包含了大量汽车维修知识,具有增值服务价值。利用文本数据的前提是将文本数据转换为知识,针对故障文本的命名实体识别作为知识库建立、故障分类、故障关系发现、故障诊断等应用服务的上游任务,为后期应用提供基础支撑。
在中文命名实体识别中,由于文本不像英文具有自然分割的特征,常见的做法使用分词边界标记作为特征进行基于词的序列标注,该类方法忽略了汉字字符的表征能力且依赖于分词效果[1]。因此大多数模型为避免分词工具带来的分割错误,直接利用字符进行特征提取,模型主要包括长短时记忆(LSTM)网络、双向长短时记(Bi-LSTM)网络,以及条件随机场(CRF)等[2],但是基于字符的命名实体识别并没有充分利用汉语词汇信息,对于汽车维修这样的专业领域来说,故障件“后桥支架”在模型中经常会被认为是“后桥”和“支架”两个实体。如何更好地在命名实体识别中利用中文词汇信息一直受到研究的关注[2]。其中,文献[3]提出了Lattice-LSTM模型,将词汇信息整合到了基于字符的NER中。由于网络结构的增加,模型的可操作性小、训练难度大且与其他后续模型的结合性不高,模型的专业领域应用性不高,因此本文提出一种面向专业领域词汇增强的命名实体识别模型(Named Entity Recognition model based on lexically Enhanced,Enhanced_NER模型)。模型首先采用一种基于词典的双层标注方式对汽车维修领域故障文本进行数据预处理。接着利用BERT获取字符的上下文信息,其次利用Word2Vec获取分词后的词汇信息,进而得到文本数据的向量特征,并利用加权的方式将词汇特征连接到相应的字符表示中。最后利用词汇增强的字符特征构建BiLSTM_CRF模型实现文本的实体识别。
1 相关工作
1.1 汽车维修领域故障文本处理难点
针对汽车维修领域的文本处理,由于数据的预处理难度大且缺乏足够的标记训练数据[7],研究主要集中于故障文本分类和特征提取。针对故障文本特征提取,文献[5]利用TF-IDF实现了故障诊断模型中的文本特征提取。文献[6]将字向量作为输入,提出一种利用卷积神经网络的小样本文本特征提取方法,并结合随机森林模型实现了飞机设备的故障原因判别。然而,现有研究在涉及故障文本知识命名实体识别时多采用规则和词典的方式,没有特定的故障知识命名实体识别模型。
针对于汽车产业链平台所产生的故障文本数据处理,除了缺少充足的标注预料外,仍存在以下难点:
(1)故障文本数据多为人工录入的短文本表述,存在录入不规范、描述口语化、语义不完整等现象[7]。
(2)故障文本实体识别具有领域专业性,导致文本中的实体与领域专业词汇高度关联,分布密度高于通用领域文本,实体分布集中。
(3)部分实体结构复杂,实体间存在相互嵌套的情况[8]。例如容易将“一缸喷油器”中的“喷油器”识别为一个单独的实体,因此需要结合上下文位置信息,准确定位实体边界。
1.2 词汇信息在实体识别中的应用现状
如何在基于字符向量的模型中融合词汇信息是近期研究的热点。文献[9]通过对N-Gram的卷积操作来得到句子中的潜在词语信息,并引入Rethinking机制,让模型重新思考。文献[10]提出的FLAT模型将格子转化为一维平面结构,提高模型的性能和效率。文献[11]提出WC-LSTM模型,对RNN编码进行了改进,并提出了4种编码策略。文献[12]利用一个多维图结构来融合词汇信息,最后采用GRU网络进行更新。
对于词汇融合的命名实体识别而言,大多模型都具有结构复杂、计算性能低下、模型可移植性差的缺陷,且研究主要针对比较规整的公开数据集,未对专业领域进行实际的应用。一方面针对专业领域暂时无法获得良好的标注数据,数据处理的难度大,另一方面模型的复杂度高难以达到实际应用的要求。
通过对汽车维修领域故障文本分析,针对现有模型网络层次复杂、专业领域应用不强等问题,而本文提出的Enhanced_NER模型在不增加模型网络复杂度的前提下,显式地表示词汇信息,以达到词汇增强的字符表示效果,进一步提高汽车故障文本实体识别的精确度。
2 支持词汇增强的命名实体识别方法
本文提出的支持汽车故障数据增值的词汇增强命名实体识别方法的技术路线如图1所示,主要分为针对汽车故障专业领域的文本数据处理、融合字词信息的文本特征构建和命名实体识别模型实现3个部分。
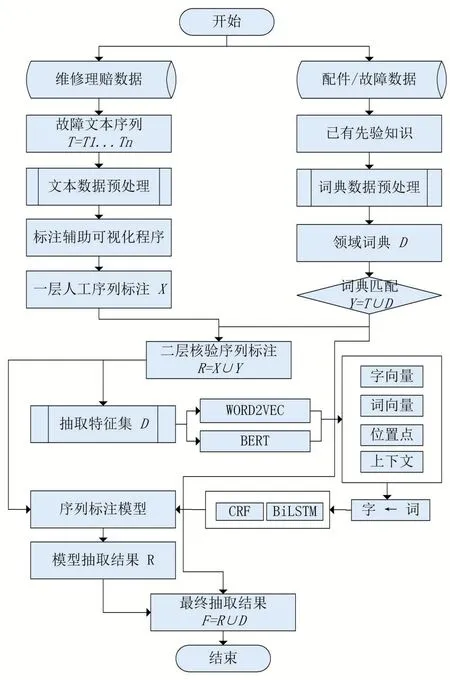
图1 词汇增强命名实体识别技术路线
2.1 汽车故障文本的数据处理
本文所研究的汽车故障领域数据来自于汽车产业链协同平台。本文利用配件、故障等基础信息结合汽车维修领域的第三方信息建立故障领域词典,以适应汽车维修领域故障知识识别的需求。保证专业领域的数据标注能满足模型训练需要,本文采用一种基于词典的双层标注方式,该方法的流程在图1中已有相应展示。本文采用BIOES的序列标注法,便于训练数据能在多个模型上进行实验。基于词典的双层数据标注的具体步骤如下:
(1)对于故障文本序列集合T=T1…T n,利用自主开发的标注辅助工具进行人工标注,得到一层人工序列标注X。
(2)根据建立的领域词典D,与故障文本序列T词典匹配,得到匹配结果Y=T∪D。
(3)利用极大似然估计计算故障文本序列T的联合条件概率,如式(1)所示,最终得到二层核验序列标注R。

2.2 融合字词信息的文本特征构建
Lattice-LSTM模型是将潜在的单词信息集成到基于字符的LSTM-CRF模型中,通过利用Lattice结构表示句子中的词汇。为了保存所有可能匹配词汇信息,Lattice-LSTM在LSTM中添加了一条字符与词典的连接,这样的结构将LSTM的链式结构转化成了图结构,如图2所示。本文通过调整字符表示,直接将词汇信息融合到字符表示中。本文所建立的Enhanced_NER模型的字符表示层如图3所示,主要分为基于BERT获取的字符特征、基于Word2Vec获取的词汇特征以及字词特征的融合3个方面。
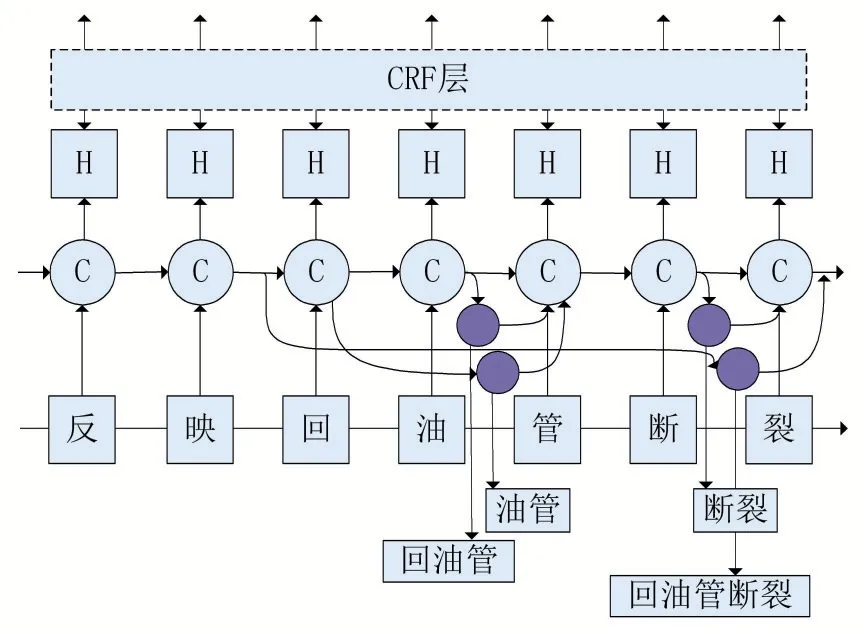
图2 Lattice-LSTM模型

图3 Enhanced_NER模型字符表示层
2.2.1 文本字词特征的获取
本文为了在字符特征中融合词汇特征,首先利用BERT获取文本字符表示,接着利用Word2Vec对分词后的文本数据进行词向量训练,获得可能对应的词汇特征,最终利用加权融合的方式将词汇特征融入到字符特征中。
(1)字符特征的获取。对于语言模型的研究经 历 了One_Hot、Word2Vec、ELMO、GPT到BERT[13]。本文所研究的故障文本数据,例如在“客户反映发动机下有漏油现象,经检查发现是油底壳有裂纹导致,更换油底壳”中,“客户反映”后多为故障现象,出现“导致”字段的多为故障原因,出现“更换”字段的多为解决方案,这类文本数据具有强有力的上下文特征,因此本文利用具有较强语义表征优势的BERT模型对文本数据的字符特征进行预训练,尽可能保存文本的语境,进而提高命名实体识别的准确率。
(2)词汇特征的获取。目前针对中文文本的分词工具较多,研究环境较为成熟,通过对汽车维修领域故障文本的分析,本文选取Jieba工具库提供的精确分词模式对汽车产业链协同平台上的故障文本数据进行分词,本文将2.1小节中所建立的专业领域词典添加到结巴分词中,利用自定义词典的方式避免分割错误,提高分词的转准确性。为了向量化文本数据中可能存在的词汇信息,本文采用Word2Vec对分词后的文本数据进行词向量的预处理,获得词汇特征。
2.2.2 词汇增强的字符特征融合
通过对文本数据字符特征以及词汇特征的提取后,为了使特征能够输入到基于字符的BiLSTM_CRF模型中,本文采用加权的方式将词向量特征匹配到对应的字符特征中,即为每个字符选择一个最可能的词汇信息。以“回油管断裂”为例,词汇增强的字符特征融合示意图如图4所示,具体步骤如下:
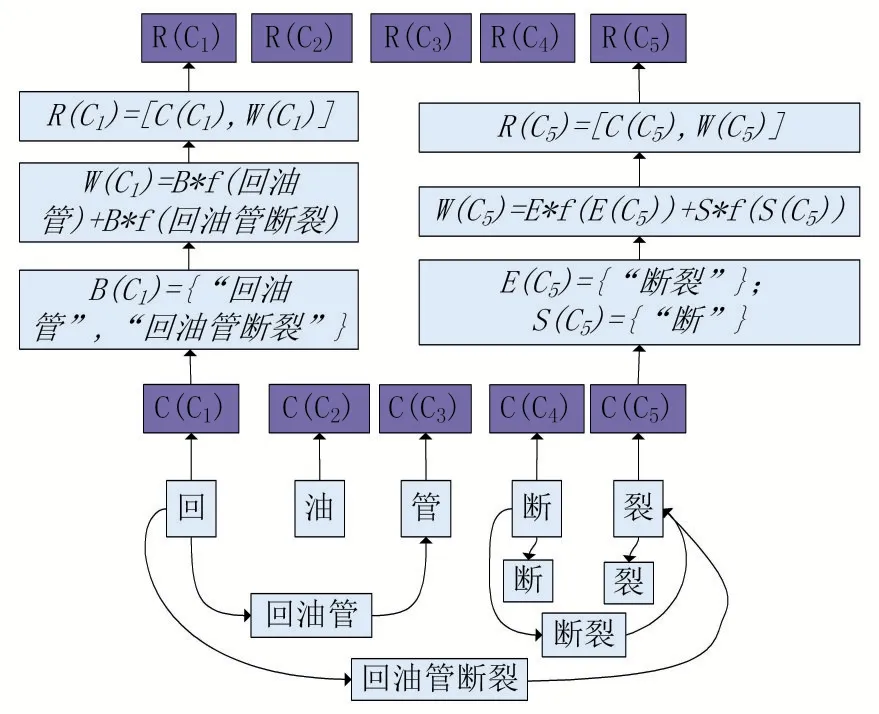
图4 词汇增强的字符特征融合
(1)将字符C与所有相关的分词进行匹配,获得该字可能出现的所有实体标记数量,由于本文采用BIOES的标记方式,所以一个字符C的S(Ci)由B(Ci)、I(Ci)、O(Ci)、E(Ci)、S(Ci)组成,其中B(Ci)表示所有以字符C开始的实体:

其中D[i,k]表示在领域词典D中以该字符为首的词汇时的实体类别。I(Ci)、E(Ci)、S(Ci)的表示与B(Ci)的表示类似,其中由于S(Ci)是由一个字符组成的实体,因此可将其进行简化,即S(C i)=C i。如果一个字符没有在已有词典中出现过词汇组合,则在融合词汇信息的过程中它应该作为O标签,因此O(Ci)表示该字符未被匹配,O(C i)=0。
(2)获得字符C的B(Ci)、I(Ci)、O(Ci)、E(Ci)、S(Ci)后,利用加权的方式将五个词汇表示集合变为一个字符词汇表示向量W(Ci),由于无法准确判定哪个标签表示的词汇信息对于所识别的字符类别最为接近,本文采取该词汇的词频作为权重,对BIOES标签进行加权平均,最终W(Ci)的表示为:
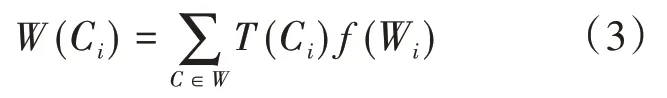
其中,T(Wi)为字符Ci对应的B(Ci)、I(Ci)、O(Ci)、E(Ci)、S(Ci),f(Wi)为字符Ci匹配到的词汇Wi在文本数据中出现的频率。
(3)最终,将字符的词汇向量表示W(Ci)添加到通过BERT提取的字符本身特征C(Ci)中,组成融合词汇信息的字符最终特征R(Ci):
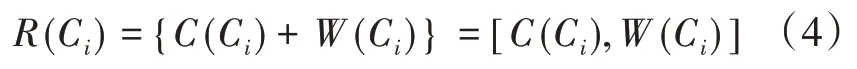
2.3 结合Bi LSTM_CRF的模型实现
由于单向的LSTM模型无法同时处理过去和未来的信息,文献[14]提出了BiLSTM模型,将同时刻的输出进行前向和后向合并,可以有效地利用同一时刻过去和未来的特征。BiLSTM能够处理长距离的文本信息,预测出每个字输入不同标签的概率,但却忽略了标签之间的关联性,而CRF能够通过转移矩阵的方式,使模型考虑标签之间的关联性,进而弥补BiLSTM无法考虑相邻标签间依赖关系的缺陷。BiLSTM_CRF是目前比较流行的序列标注算法,已有研究表明,该模型具有更好的鲁棒性且能产生准确的标记性能[15]。
本文提出的Enhanced_NER模型改变了BiLSTM_CRF模型中的字符表示层,结合2.2小节提出的词汇增强的字符表示,Enhanced_NER模型由输入层、字符表示层、序列建模层、标签推理层和输出层构成,模型总体架构如图5所示。
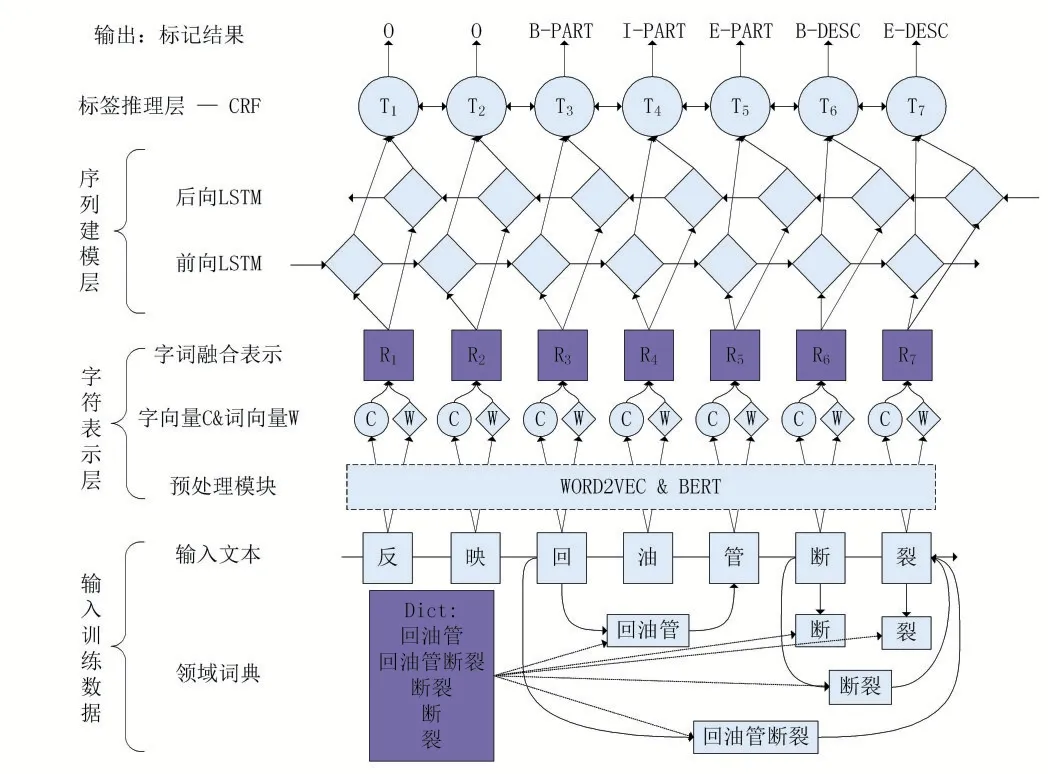
图5 Enhanced_NER模型的架构
3 针对Enhancede_NER模型的实验结果分析
为了证明模型的有效性,本文将使用基于词序列的命名实体识别模型、基于字序列的命名实体识别模型、Lattice-LSTM模型与本文提出的模型进行对比分析。本文还利用模型对汽车产业链协同平台其他数据集进行了实验,进一步验证了Enhanced_NER模型的领域通用性。
3.1 同一数据集不同模型对比
本文选用LD故障文本数据集进行模型训练,表1展示了不同模型的结果对比。
本文进行了基于词序列CRF模型实验,基于字序列的CRF、LSTM、BiLSTM_CRF模型实现和字词融合的Lattice-LSTM模型的实验,为了验证不同嵌入向量对Enhanced_NER模型的影响,本文还进行了不同的词汇增强字符表示方式对比,包括基于Word2Vec的字词向量、基于BERT的字向量与Word2Vec的词向量、基于BERT字向量与添加了自定义分词的词向量训练,共9组实验,如表1所示。

表1 LD数据集不同模型对比
最终发现利用基于BERT的字向量和利用Word2Vec训练的词向量融合的字符表示的Enhanced_NER模型的结果在3项评价指标的表现上都达到了最好的效果,因此利用BERT、Word2 Vec、BiLSTM、CRF结合的Enhanced_NER模型可以满足LD故障文本数据集命名实体识别的需求。
3.2 模型对各类实体识别的结果分析
本文对Enhanced_NER模型在LD故障文本数据集中故障件、故障现象、故障原因、解决方案4类实体的识别效果进行了对比,如表2所示。

表2 Enhanced_NER模型对各类实体的识别效果对比
通过分析发现Enhanced_NER模型在故障件、故障现象这两类实体的识别效果最好,达到了90%以上,但对于其他类别的实体来说,特别是故障原因类实体的识别表现不佳。这可能是因为所构建的词汇信息中没有故障原因相关词条,对于该实体类别所对应的字符来说无法进行词汇增强,加之故障原因在文本数据中描述形式多种多样,缺少像类似于故障现象中的“反映”和解决方案中的“更换”这类明显的结构特点,因此模型在识别故障原因类实体时效果欠佳。
3.3 不同数据集Enhanced_NER模型对比
本文为避免模型结果的偶然性,利用汽车产业链协同平台上整车制造厂WP和CQ的服务协同数据对Enhanced_NER模型进行了实验。由表3可以看出LD领域词典对WP和CQ数据集也有较好的实验结果,为了进一步证明Enhanced_NER模型的可迁移性,本文针对WP和CQ数据对领域词典进行了相应变动,最终模型的实验效果与LD数据集较为接近。通过对不同数据集的实验,Enhanced_NER模型都取得了较好的结果,进而可以看出Enhanced_NER模型具有一定的模型可迁移性和领域适用性。
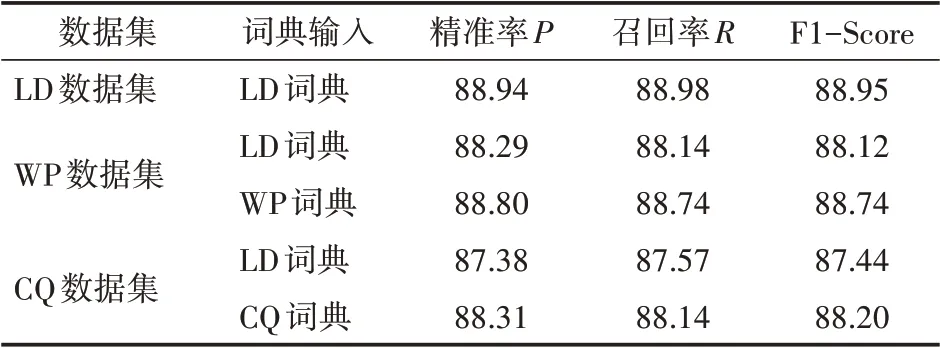
表3 不同数据集Enhanced_NER模型对比
4 结语
本文面向汽车维修领域故障知识命名实体识别的应用需求,研究了领域文本数据的现状和词汇信息在命名实体识别中的应用现状,针对基于字符的实体识别模型无法利用词汇信息以及Lattice-LSTM模型中基于字元的词汇在专业领域的表现不足,提出了词汇增强的命名实体识别模型Enhanced_NER。该模型利用将词汇信息融入到字符向量中,实现了词汇增强的字符表示,进而利用BiLSTM_CRF结构实现了词汇增强的命名实体识别。该模型最终实现了汽车维修领域故障知识中关于故障件、故障现象、故障原因、解决方案的实体识别,并在汽车产业价值链协同数据空间的真实数据集上达到了良好的识别效果,通过实验进一步验证了Enhanced_NER模型在汽车维修领域故障知识提取的有效性和适用性。在未来的研究中,将继续探索Enhanced_NER模型在维修故障知识中的应用。
