基于改进Xgboost算法的多联机空调系统故障诊断策略
2021-10-30朱波胡宽李正飞陈焕新
朱波,胡宽,李正飞,陈焕新
(华中科技大学能源与动力工程学院,湖北武汉 430074)
0 引言
多联机空调系统也称作“一拖多”空调系统,是指一台室外机连接多台室内机,室外机风冷换热、室内机直接蒸发换热的一次制冷剂空调系统。多联机系统多用于中小型建筑和部分公共建筑,具有节约能源、控制先进和运行可靠等特点。机组适应性好、制冷制热温度范围宽、设计自由度高、安装和计费方便[1]。工作原理是通过控制制冷剂流量和压缩机的制冷剂充注量来实现制冷与节能。制冷剂充注量是多联机系统运行过程中重要的参数,一旦出现充注量故障,会导致一系列安全问题和经济损失。因此对制冷剂充注量故障的检测十分必要。目前,制冷系统故障诊断方法有3 种:经验知识、模型分析和数据分析。数据分析方法不需要先验知识,仅通过分析发现大量数据之间的联系,因此在多联机复杂系统故障检测中有较好的应用前景[2-4]。
特征选择是机器学习过程中重要的数据预处理过程,对现实任务的解决有两点重要意义。一是避免维度灾难。维度灾难是由特征属性过多引发的,若能从过多的属性中挑选重要的属性即可大大减轻计算量,从而避免维度灾难。二是去除冗余特征以降低学习难度,可以把握重点[5-6]。李正飞等[7]结合ReliefF 和mRMR 特征选择算法获得特征后建立反向传播算法模型进行故障诊断,结果表明:该方法可以提高多联机制冷剂充注量故障诊断的精度与效率。陈逸杰等[8]对比了Boruta 算法和改进的Boruta 算法,结果表明改进的Boruta 算法不仅降低了样本复杂度,而且提高了模型的预测性能。刘艺等[9]阐述了现有特征选择稳定性提升方法,分析比较了各类方法的特点和适用范围,总结了特征选择稳定性中的相关评估工作,并通过实验剖析稳定性度量指标的性能,对比了4 种集成方法的效用。石拓等[10]提出了SEFV_Bagging 算法,结果表明其具有良好的泛化性能与稳定性,在测试数据上表现出的预测精度理想。崔鸿雁等[11]总结了5 种特征选择方法,通过对比各个方法的原理、实现过程和应用场景,得出不同算法适用的范围和优缺点。徐廷喜等[12]提出一种基于支持向量数据描述的算法来检测变频空调系统制冷剂故障,利用主成分分析法进行降维,大幅提升诊断准确率。吴斌等[13]提出一种基于随机森林的屋顶空调故障诊断策略,结果表明该方法对于膨胀阀类型相同,但制冷剂、压缩机与系统冷量不同的屋顶机空调系统诊断效果良好。
以上研究对故障诊断的效率均有较大提升但他们的研究方法局限于单一特征选择法,单一特征选择容易得到局部最优解且抗干扰能力差、稳定性差。稳定性差的特征是不利于发现特征之间的相关性的[14]。为了解决这些问题,本文将集成策略与Xgboost 算法相结合,使用交叉验证和网格搜索寻找最优参数,提出了改进Xgboost 算法,将单一特征选择得到的变量重要性排序后集成,得到集成特征排序,以提高特征稳定性和预测准确率。
1 制冷剂充注量故障诊断实验
1.1 实验设计
本论文使用的数据是通过多联机制冷剂充注量实验获取的,多联机系统由一台室内机和五台室外机组成,室内机主要由风机和换热器组成,室外机主要由气液分离器、涡轮式压缩机和过冷器组成,室内机和室外机同时配备了多种传感器来采集相关数据。实验中的室外换热器采用的是U 型翅片换热器,有效加快了与外界的换热,同时室外机组还配备有相关安全设施来保证实验的安全进行。实验选择R410A 作为制冷剂,制冷剂额定充注量为9.9 kg,室内机和室外机的额定功率分别为28.0 kW和7.1 kW。多联机系统传感器用于测量温度、压力等数据,制冷剂充注量水平由膨胀阀来调节。多联机系统原理如图1所示。

图1 多联机系统原理
1.2 数据采集
实验共测试了10 种制冷剂充注量水平下机组的运行参数,充注量水平设定在63%~140%,制冷剂充注量水平划分为不足、适量和过量3 种情况,实验每隔15 s 记录一次数据,充注量与充注程度的对应关系和类别情况如表1所示。实验系统在室内温度下进行,运行工况数据如表2所示。
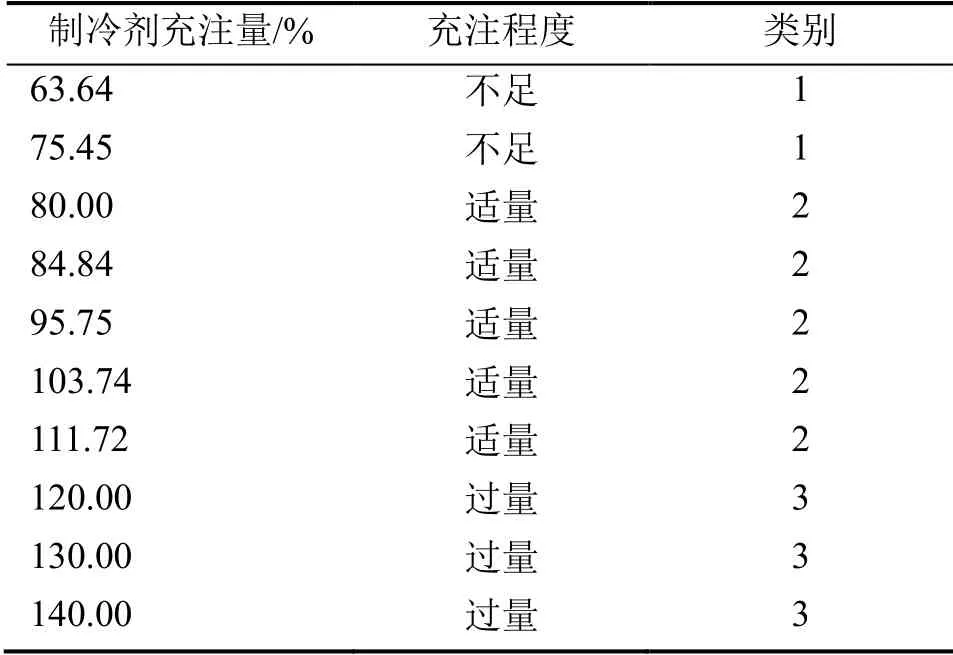
表1 制冷剂充注量与类别

表2 系统运行工况
2 Xgboost 算法及其参数设置
XgBoost 算法是陈天奇[15]开发的一个机器学习项目,它可以高效地实现GBDT 算法,在进行了算法和工程上的多次改进后,被广泛应用于各种机器学习竞赛中并取得了不错的成绩。Xgboost算法的核心思想是不断地进行特征分裂来生长一棵树,每生长一棵树,就会得到一个新函数来拟合上次预测的残差。训练完成后,当我们要预测一个样本时每个样本会落到每棵树中对应的叶子节点,每个叶子节点对应一个分数,最后只需要将每棵树对用的分数加起来就是该样本的预测值[16-17]。
Xgboost 算法目标函数为:
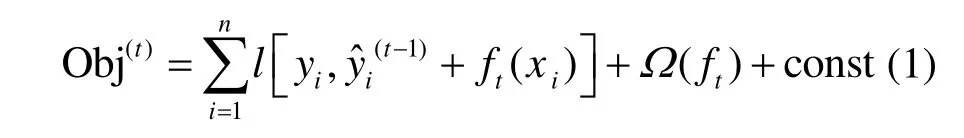
用泰勒公式展开得目标函数为:
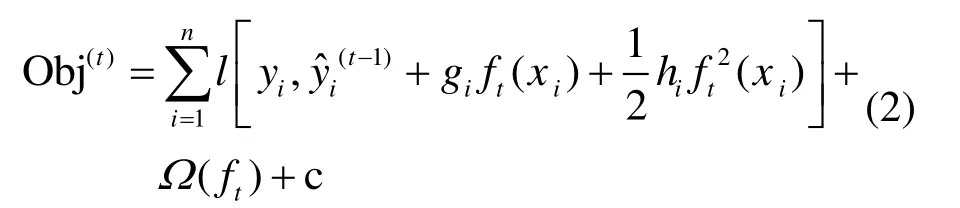
式中,l 为损失函数;Ω(ft)为正则项;c 为常数项。
Xgboost 算法参数较多,本文主要设置了max_depth、n_estimators 和learning_rate 三个参数。其中max_depth 控制树的深度,深度越大越容易过拟合,n_estimators 控制弱学习器的数量,learning_rate 为学习率。
3 贪心搜索集成
贪心搜索是基于贪心算法的集成搜索过程。贪心算法的基本思路是首先建立起数学模型来描述所要求解的问题,然后把待求解的问题拆分成若干个子问题,再对每个子问题进行求解,获得每个子问题的局部最优解,最后把每个子问题的局部最优解集成,得到原问题的解。贪心算法的使用有一定的限制,只能求解在约束范围以内的可行解,并不能保证最优,也就不能求解极值问题。贪心算法以迭代的方式连续做出贪心选择,每次贪心选择都将使所求解问题简化为更小的子问题[18-19]。
本文采用贪心搜索集成策略,贪心搜索集成的基本思路是将基特征选择器得到的特征序列构成特征子集,将每个特征看作一个候选特征子集,然后对所有候选特征子集进行评价且保证每轮的选择均为目前状况下的最优选择。对特征子集以预测准确率作为评价标准,每轮搜索都选择预测准确率最大的变量,据此对特征进行排序。
4 改进Xgboost算法的制冷剂充注量故障诊断
4.1 数据预处理
实验所得的数据量十分庞大,如果直接将如此庞大的数据量带入模型进行故障检测,不仅预测精度低、计算量庞大而且可能导致计算机崩溃。因此,数据的预处理十分重要。数据预处理就是剔除异常值、死值、无关变量和逻辑变量,降低数据维度,获得较好的特征变量,最后对特征变量进行归一化处理[20]。数据归一化是将数据转化为均值为0、方差为1的正态分布,这样可以使不同数据处在同一数量级,消除量纲对模型的影响,保证了预测的稳定性,可表示为:

式中,E(xi)为变量xi的数学期望,var(xi)为方差。
数据预处理分为两个步骤:1)数据清洗;2)选取特征变量。数据清洗时,时间记录和异常值要首先剔除,然后去除与目标变量相关性强的特征变量,降低数据冗余。特征变量的选取主要基于专家先验知识,最终选定18个变量作为最终的特征变量输入到故障诊断模型,变量名及编号如表3所示。

表3 变量名及编号
4.2 算法参数寻优
在运行Xgboost 算法前,需要输入数据矩阵,标签向量和迭代次数等参数。本文使用十折交叉验证和网格搜索来寻找最优参数。十折交叉验证是将数据集平均分为10 份,每次拿出1 份作为测试集,其余作为训练集,直到十个子集均作为测试集使用过,最后将10 个模型参数取平均值,作为最终指标。网格搜索是一种穷举调参方法,即在所有候选的参数中循环遍历,实验每一种可能,将效果最好的参数作为最终结果[21-22]。
4.3 特征选择优化
首先从原始数据集中抽取30,000 个数据作为样本子集,样本子集保留了原始数据集的所有特征。通过抽样可以大大减少运算时间,同时通过形成数据扰动,保证了特征子集的多样性和稳定性。抽样后运行五次Xgboost 算法,得到5 个特征子集,然后将所得特征子集按照特定集成策略集成,得到集成后的特征子集。
然后再取30,000个样本进行验证过程。在验证过程样本中取80%的数据作为训练集,20%的数据作为测试集。将5种单一特征排序和集成特征排序按照排名依次带入Adaboost和Xgboost预测模型中,最终获得6种变量排序对应的预测准确率。故障诊断准确率可以定义为:
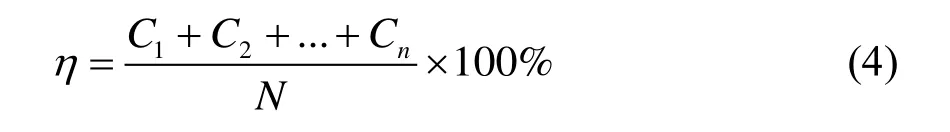
式中,C1、C2、Cn分别代表n种故障预测正确的样本数;N为样本总数。
数据处理与模型预测的过程如图2所示。
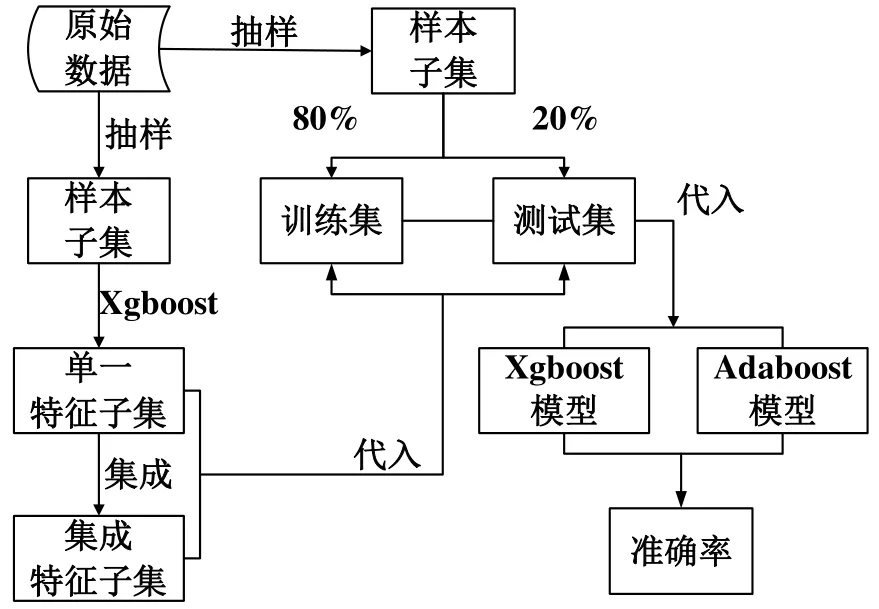
图2 模型训练流程
5 结果分析
5.1 准确率对比
图3所示为Xgboost模型和Adaboost模型准确率对比。由图3可知,在两种模型中改进的Xgboost算法获得的准确率基本都高于所有单一特征选择算法,最差时也和单一特征选择中的最高准确率持平,充分说明该算法的优越性,这也表明集成算法可以获得更好的特征排序、更优的诊断性能。集成算法的准确率随变量个数的增加呈现出先增再减最后趋于稳定的变化。准确率随变量个数增加先增加,是因为变量数少时,模型预测能力低,变量较少时无法对制冷剂充注量进行准确预测。变量数达到15时,准确率达到峰值。当变量数大于15时,准确率开始略有下降,这是由于过多的变量造成特征的冗余程度变大,冗余变量降低了预测性能,同时增加了运算负荷。特征选择的目的在于选择合适数量的变量构成特征子集,在获得较高准确率的同时降低运算量,因此,本论文选择贪心搜索集成得到的前7个变量构成最优特征子集,按照排序依次为压缩机排气温度、过冷器液出温度、压缩机模块温度、冷凝温度、气分进管温度、EXV、室外环境温度。这样选择既可以保证准确率,也可以保证较少的特征变量,尽可能减少计算复杂度。
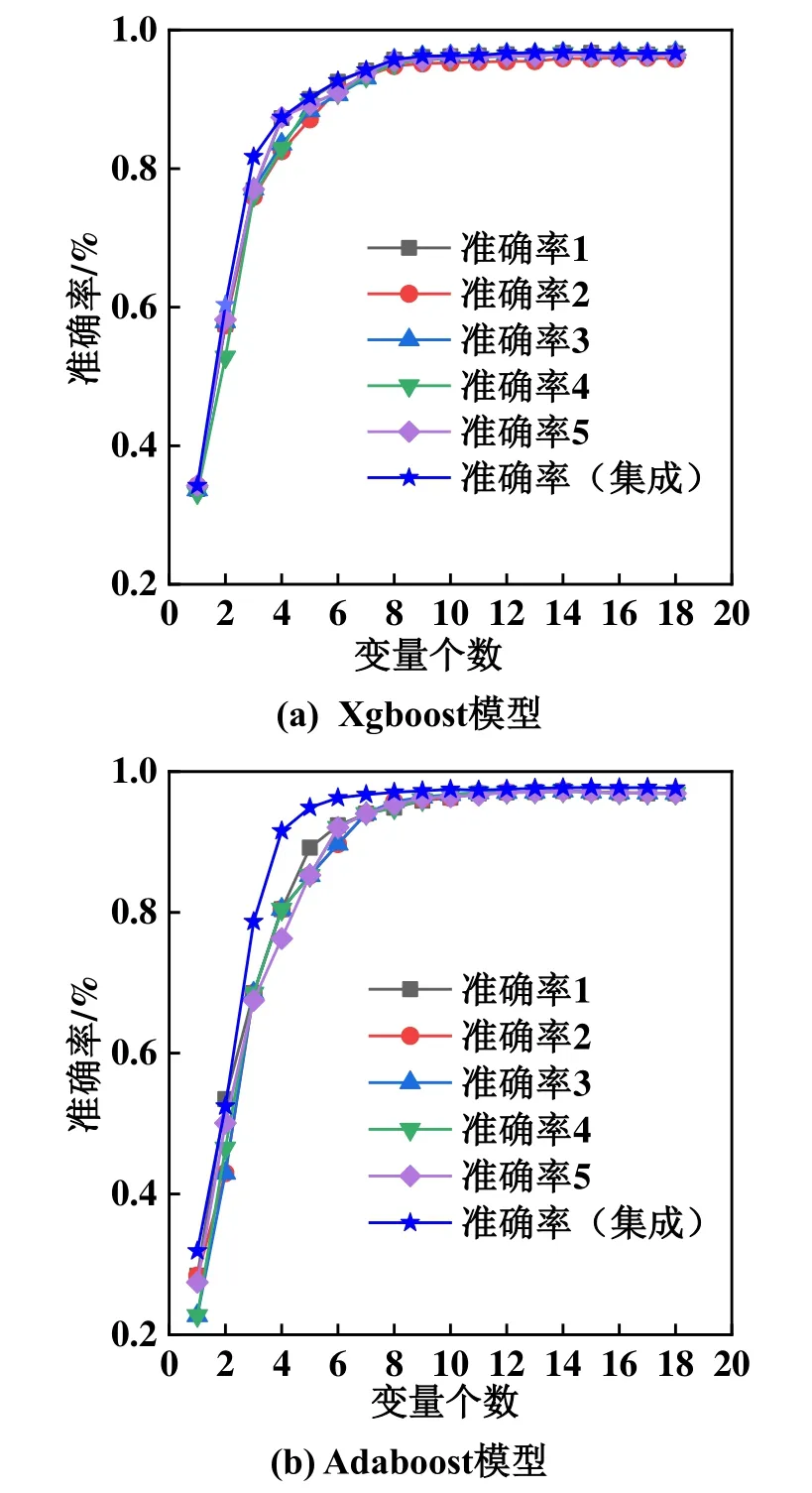
图3 Xgboost模型和Adaboost模型准确率对比
5.2 泛化性能验证
为了验证改进Xgboost算法的泛化性能,再次从原始数据中抽取40,000组数据,代入两种模型中进行验证,结果如图4所示,Xgboost模型部分准确率数值如表4所示。
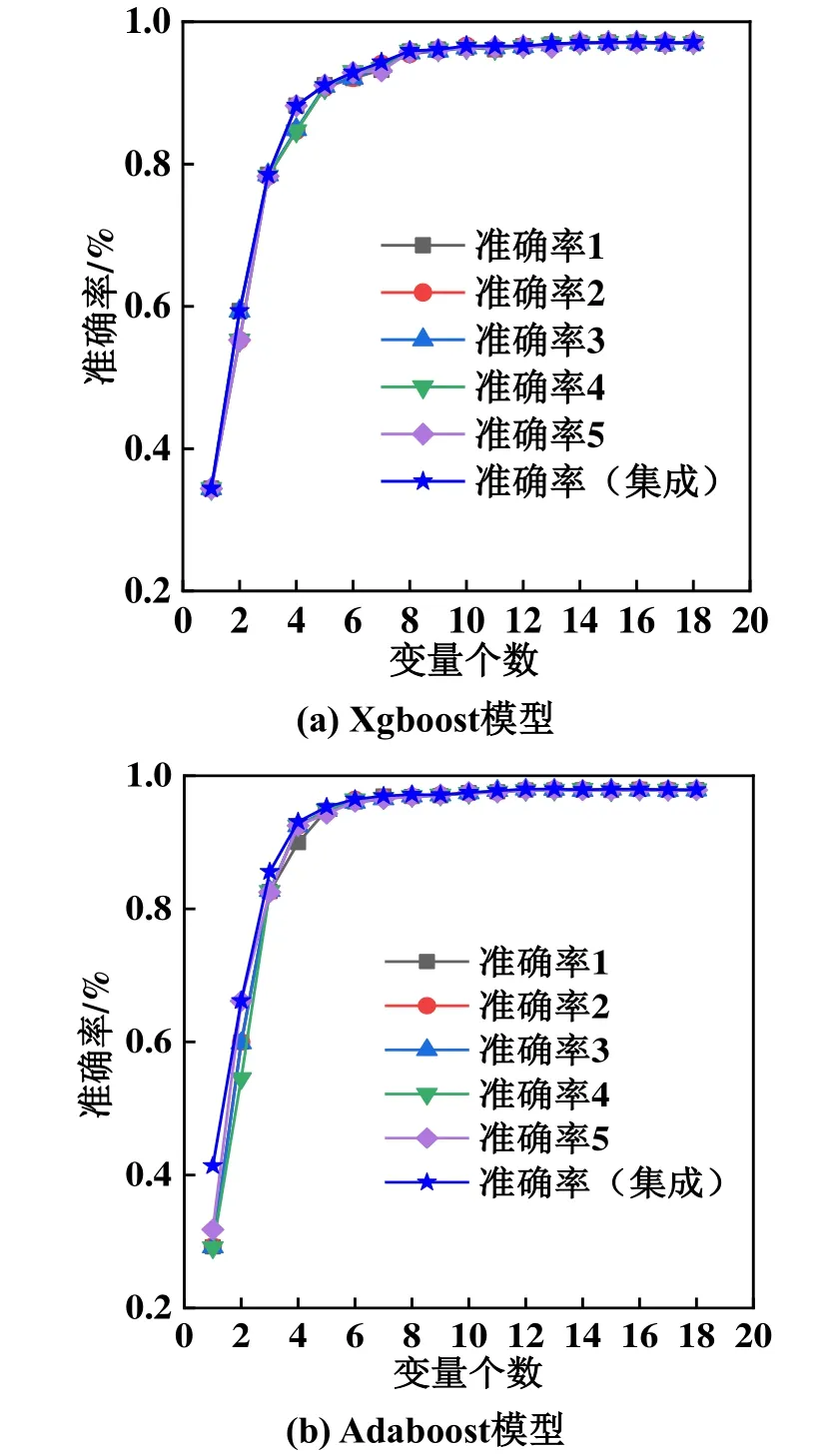
图4 Xgboost模型和Adaboost模型部分数据准确率对比
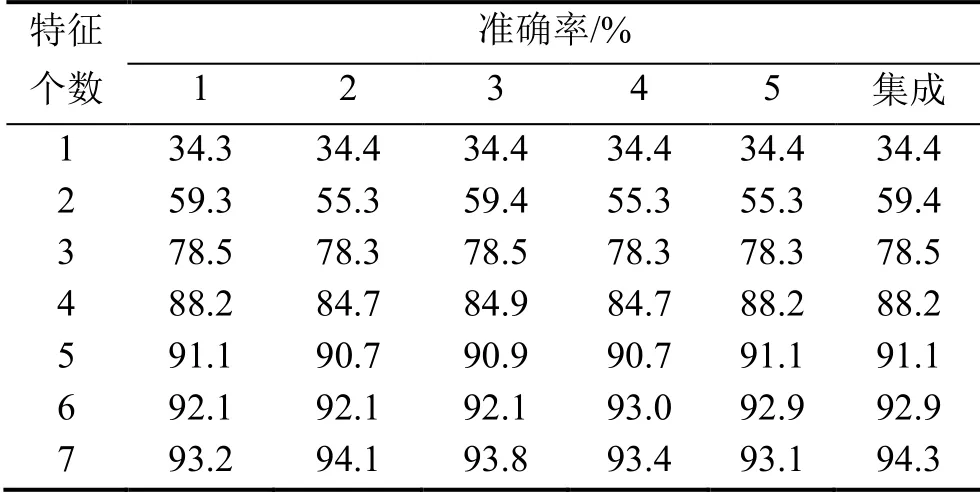
表4 Xgboost模型前七位特征准确率
图4所示为所有18个特征的准确率。表4给出了在Xgboost模型中排在前7位的特征准确率,因为7位以后的准确率已经十分接近,原因是随着特征变量的个数增加,准确率逐步提高,当变量个数达到一定数量时,基本接近了最高的准确率。由图4和表4可知,改进Xgboost算法的准确率依然整体上高于所有的单一算法,证明该模型泛化性能良好。
6 结论
本文将集成思想运用到特征选择上,将单一算法得到的特征顺序集成,结合交叉验证网格搜索等手段改进Xgboost算法,来提高模型预测的准确率,得出如下结论:
1)改进Xgboost算法的集成方法得到的特征子集能获得比所有单一特征选择方法更高的准确率,在Adaboost和Xgboost两种模型上选择特征数量较少时,准确率提升明显,最优时分别提升了15.28%和4.68%;
2)使用交叉验证、网格搜索和贪心搜索策略可以有效改进Xgboost算法,提高其特征选择稳定性和预测准确率;
3)改进Xgboost算法具有良好的泛化性能,适用于更多其他复杂情况,具备一定的推广能力。
