基于GAN网络的煤岩图像样本生成方法
2021-10-30郝鹏程荆正军
王 星,高 峰,陈 吉,郝鹏程,荆正军
(1.辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛 125105; 2.神东煤炭集团公司寸草塔一矿,内蒙古 鄂尔多斯 017205; 3.阜新煤矿集团 恒大煤矿,辽宁 阜新 123002)
煤炭是我国的主体能源,也是最经济的化石能源,对我国的能源安全和经济社会发展起着举足轻重的作用[1-2]。煤炭的智能化、无人化开采在提高煤炭产量的同时,也是减少煤矿事故,特别是工作面事故的主要途径。煤岩界面自动识别[3]是实现智能化和无人化开采的核心技术,是采煤机滚筒和掘锚机截割部位高度的自动调节以及液压支架顶板支护自动调整的关键所在,同时也是公认的世界难题。因此,深入研究煤岩界面的自动识别方法具有重要的理论意义和实践价值。
围绕煤岩界面的自动识别研究,国内外学者提出了多种方法,如振动检测方法[4]利用拾振传感器监测采煤机切割力响应变化,通过减少采煤机噪声的方法提高煤岩识别效率;放射性探测方法[5]依据γ射线穿过煤和岩石表现出的不同衰减曲线来识别煤岩;声压检测方法[6]通过声波、雷达等进行煤岩界面探测;红外探测方法[7]通过检测煤岩界面切割时产生的红外辐射来识别煤岩界面。由于受到传感器自身性能、γ射线穿透能力、探测范围以及粉尘环境等方面的影响,上述煤岩识别方法的准确性和效率还有提升空间。
近年来通过提取煤岩的颜色、纹理和形状等特征来识别煤岩的方法受到越来越多的关注,出现了以字典学习法[8]、小波变换法[9]、相似性度量法[10]和神经网络法[11]等为代表的煤岩图像识别[12-15]方法。刘富强等[16]通过图像预处理、边缘提取、区域标记等分析煤或矸石的灰度分布情况,之后通过比较灰度直方图的方式区分煤岩。李文斌等[17]基于光泽并通过光漫射特征及直方图方法判别煤岩。HOBSON等[18]通过对比相关图像处理方法,得出纹理比灰度更适合进行煤岩识别的结论。为了提高共生矩阵惯性矩在图像纹理分析中的作用,于国防[19]提出一种基于间隔灰度压缩的扩阶共生矩阵惯性矩来提高煤岩识别效率。黄韶杰[20]以煤岩颜色为例,采用边缘检测和灰度阈值法进行煤岩识别。MENG等[21]通过分析煤岩纹理的不同,提出一种基于灰度共生矩阵和反向传播神经网络的煤岩识别方法。伍云霞等[22-24]提出了基于字典学习、Curvelet变换、带局部约束的字典学习等能充分表达图像的纹理特征和边缘特征的方法来提高煤岩识别的效率。相似性度量方法以图像之间的相似度大小作为分类依据,孙继平、陈浜等[8-10]提出了支持向量诱导字典学习和小波变换等的煤岩识别方法。常见的煤岩图像相似度距离测度还包括欧式距离、切比雪夫距离等。佘杰[25]运用支持向量机对煤岩进行识别。K-means方法[26]是最为常用的煤岩聚类方法,它在煤岩图像数量较大、图像光线好、煤岩差异性比较大时具有较好的处理效果。王莹[27]提出了多参数融合的煤岩识别方法。
通过研究分析发现,以下2个因素很大程度上制约了基于图像的煤岩识别方法的发展:① 井下采煤机等设备工作环境的复杂性导致获取图像困难,所获图像质量和数量不足以支撑相关算法的运行和优化;② 我国煤岩存在多样性、相似性和复杂性等特征,使得识别准确率还有待提高。因此,切实提高煤岩样本数量与质量、构建更加高效的煤岩识别模型是当前迫切需要解决的问题。
GAN[28-41]在图像生成和解决图像数据短缺问题上具有明显优势,可用于解决煤岩图像数据短缺问题。目前,在单张图像上训练GAN模型的方法相对较少,已经提出了3种在单张“自然”图像上训练的GAN模型,即SinGAN[29],InGAN[30]和ConSinGAN[31]。这3种方法都基于图像的双向相似性度量,可用于图像生成任务。SinGAN和ConSinGAN2种方法都是训练一个在单张图像上能够无条件生成图像的模型,在多种尺度上训练生成器和判别器,即在同一图像的不同分辨率上训练模型。ConSinGAN虽然在“自然场景”(具有明显结构的自然场景图片)中能够生成真实性、多样性都很高的图片,但是在煤岩图像的生成中,由于煤岩的结构布局并不明显,引发生成样本多样性不足的问题,同时其性能不能满足实际需求。经过实验发现,可以通过改进模型的结构和训练的方法使该模型在生成煤岩图像时增加生成图像多样性的同时提升其性能。
针对以上存在的煤岩图像数据短缺的问题并结合GAN的最新进展,笔者从扩大样本的数量和提高样本的质量出发,提出一种基于生成式对抗网络的Var-ConSinGAN模型并构建生成与特征迁移的框架,为基于图像的煤岩识别方法奠定样本基础。其中特征迁移的目的是使某一类图像的某种特征迁移到其他类别的图像中,提高生成图像多样性。主要工作包含4点,提出新的图像尺寸变换函数,增加生成煤岩图像的多样性;更改模型训练方式,通过改变不同尺度下的训练次数,使得模型学习图像特征的侧重点向纹理细节方向倾斜;将单张图像生成与大规模图像生成结合,实现特征迁移;通过改变模型的训练过程,减少训练模型的时间,提升模型性能。
1 生成式对抗网络
1.1 模型框架
GAN[28](Generative Adversarial Network)是无监督学习的一种方法,通过让2个神经网络相互博弈的方式进行学习。生成式对抗网络由生成器和判别器构成,其核心目标是训练生成器。生成器的目的是生成与真实样本尽可能相似的样本,判别器的目的是尽可能区分出给定样本是真实样本还是生成的样本。2者目的相反,在不断博弈的过程中相互提高,最终在判别器判别能力足够可靠的前提下仍无法区分给定样本是真实样本还是生成样本,此时生成器能够生成无法分辨真假的样本。
图1描述了GAN模型由2个神经网络模型组成,分别是生成器G和判别器D。GAN模型可以将任意的分布作为输入,Z表示输入的随机噪声,一般取Z~N(0,1)或[-1,1]的均匀分布作为输入。生成器G的参数为θ,输入Z在生成器下得到G(Z;θ),输出可以被视为从分布中抽取的样本G(Z;θ)~Pg,Pg为噪声Z经过生成器后的概率分布。
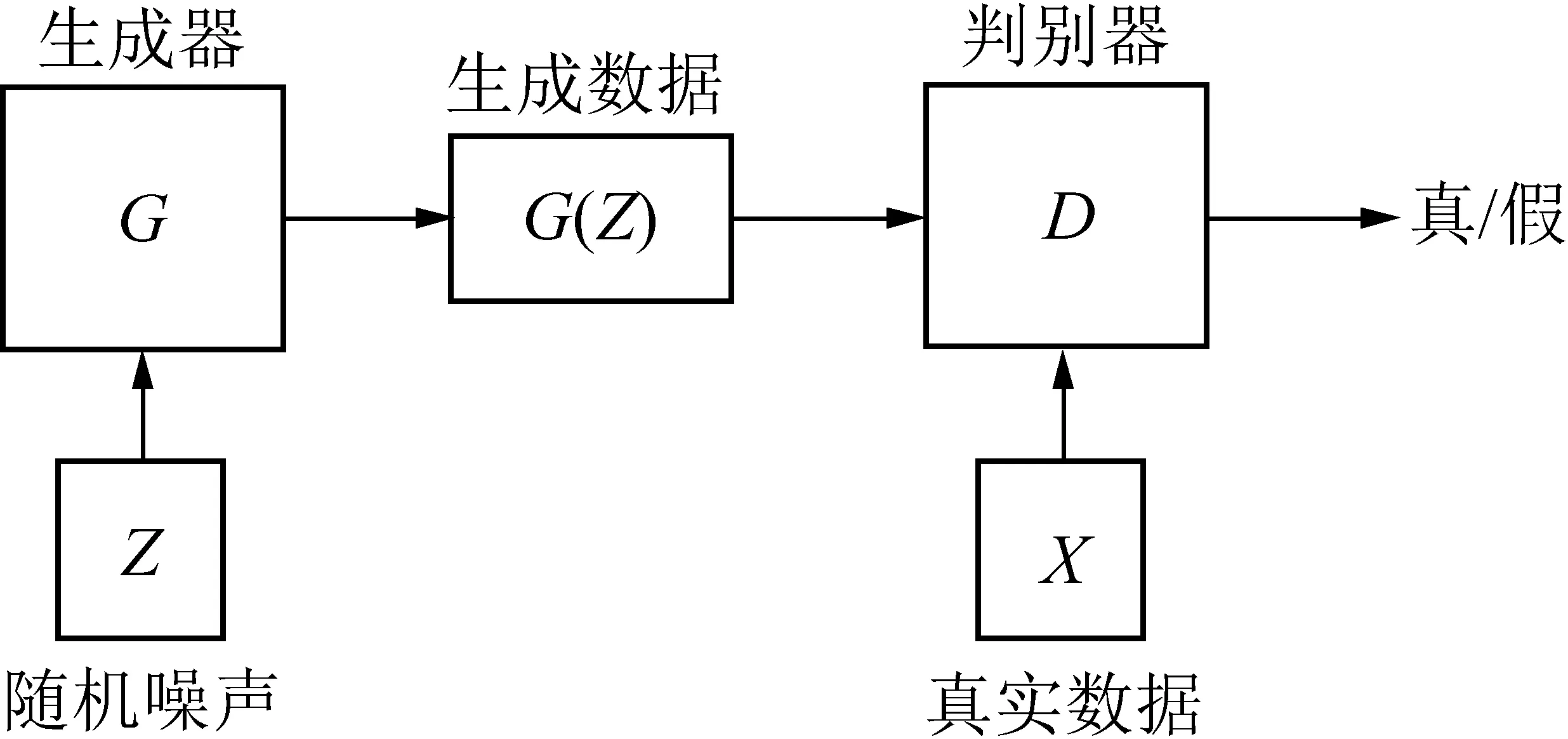
图1 GAN模型结构Fig.1 GAN model structure
1.2 基本原理
GAN的损失函数(即目标函数)为
[lg(D(x))]+Ez~pz(Z){lg[1-D(G(Z))]}
(1)
其中,V(D,G)为生成器G和判别器D的运算关系;x为真实数据;pdata为真实数据概率密度分布;E为分别对[lg(D(x))]和[lg(1-G(Z))]求数学期望。由式(1)可以看出,从判别器D的角度看,判别器D尽可能区分真实样本x和生成样本G(Z),因此D(x)必须尽可能大而D(G(Z))则尽可能小,即V(D,G)整体的值尽可能大。从生成器G的角度看,生成器G的目标是使自己生成的样本G(Z)尽可能骗过判别器D,使D(G(Z))尽可能大,即V(D,G)的值尽可能小。GAN的2个模块在训练中相互对抗,最终达到全局最优。
在训练初期,虽然G(Z)和x在同一个特征空间中,但它们分布的差异很大,此时虽然鉴别真实样本和生成样本的模型D鉴别能力不强,但它能够准确地把两者区分开,而随着训练的推进,生成样本的分布逐渐与真实样本重合,判别器D虽然在不断更新,但是也不能完全判断样本的类别。当生成样本与真实样本的分布基本重合时,模型达到最优状态,这时判别器D对于任意样本的输出都接近0.5。
2 基于GAN的煤岩样本生成模型
为煤岩识别提供数据支撑,解决煤岩数据短缺问题,通过少量的煤岩图像生成可以应用于计算机视觉的煤岩图像数据集。为了使生成的煤岩图像更接近真实煤岩图像,笔者利用Var-ConSinGAN和ACGAN[32](Conditional Image Synthesis With Auxiliary Classifier GANs)方法构建了样本生成与特征迁移框架。第1部分,用Var-ConSinGAN模型进行训练,训练后的模型可以生成任意数量且和原始煤岩图像类似的样本,生成的样本与原始图像相比,保留了原始特征且具有一定多样性。第2部分,使用ACGAN[32]对第1部分生成的大量煤岩图像进行特征迁移,得到多样性更加丰富的煤岩图像。
如图2所示,上半部分的Var-ConSinGAN模型对应第1部分的单张煤岩图像生成,其中,Ladv为GAN使用的目标函数。模型的输入是一张符合正态分布的噪声图片,经过网络训练,生成器输出满足真实图像分布的生成样本。模型的生成器由上自下从第0阶段开始训练,当前阶段生成器的规模和图像的分辨率都很小。随着训练阶段的增加,生成器的规模和图像的分辨率都会逐渐增加。所有生成器采用串联的方式连接在一起,并将生成的图像送入同一个判别器中。图2中下半部分ACGAN对应模型的第2部分,GACGAN和DACGAN分别是ACGAN中的生成器和判别器,由于所有的图像都由一个生成器生成且生成器模型中的参数数量固定不变,因此不同类别之间往往会发生参数共用的情况,当生成的一类样本在生成过程中用到了其他类别的参数时,也就学习到了其他类别的某些特征。其中第1部分的单张煤岩图像生成是核心,这决定了数据从少到多的生成,在有了大量的数据基础以后才能利用第2部分的模型做特征迁移的工作(2.6节中详细描述特征迁移)。
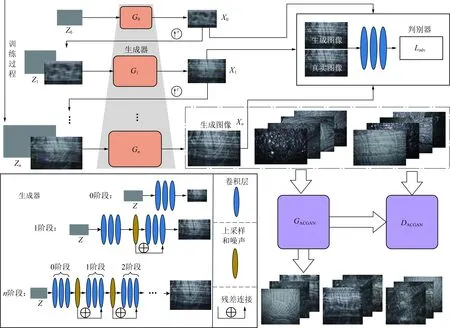
图2 煤岩图像生成与特征迁移框架Fig.2 Framework for image generation and feature migration of coal and rock
Var-ConSinGAN模型的训练过程如图2所示,Gn的输入是随机噪声图像Zn,和前一个生成器生成的图像Xn向上采样到当前分辨率的图像(除了纯生成的最低级别)。图像单尺度的生成是在每个尺度n上,将n-1尺度生成的图像Xn-1上采样,并添加输入噪声映射Zn,之后将结果送入生成器中。生成器的输出是一个添加了残差图像Xn-1的图像Xn,图像Xn就是对应尺度n的输出图像。图2中蓝色图形表示模型的卷积层,黄色图形表示经过上采样后的图像和噪声,他们之间通过一个残差操作相连接。
2.1 金字塔结构
Var-ConSinGAN模型的设计采用SinGAN[29]中使用的金字塔结构,具有多个阶段(每个阶段对应不同的图像尺度,即不同的图像分辨率),由许多个GAN叠加在一起组成一个金字塔的形状,其中训练和生成均以一种由粗到精(低分辨率到高分辨率)的方式完成。在每个尺度(分辨率)上,Gn学习生成图像样本,其中所有重叠的patch用判别器Dn进行识别,直到判别器无法从下采样训练图像Xn中的patch识别出图像的真假。patch指图3中的黄色区域,在用卷积神经网络处理图像时,神经网络每次处理的图像区域的大小等于卷积核的大小,这个卷积核处理的图像区域就是patch,即感受野。
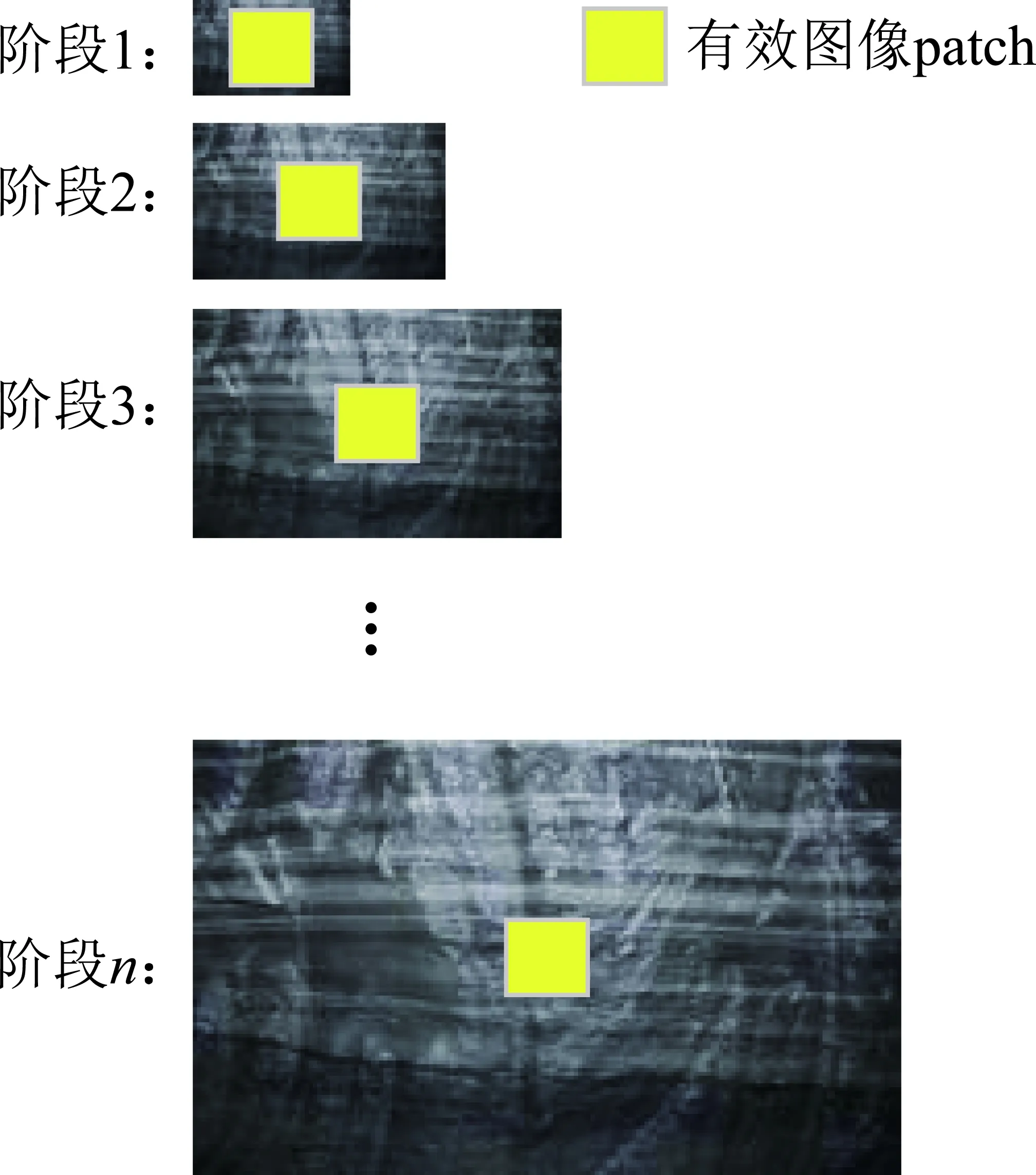
图3 图像patch变化Fig.3 Change map of image patch
如图3所示,在分辨率最低的那一个尺度上,输入的是原图像经过下采样得到的最小的尺度,在图像经过固定的11×11的感受野时,由于输入的图像是原图缩小到很小的一个尺度,所以即便网络的感受野很小,也能覆盖掉输入图像的大部分区域。而在分辨率越来越大的尺度上,输入的图像变大,感受野不变,则patch能覆盖的范围会越来越小。当训练进程沿着金字塔向下移动时,有效的patch大小会减小(在原始图像上用黄色标记以作说明)。判别器不将图像看做一个整体,而是由很多个小的patch组成,通过这种方法,它就可以判断每一个patch的真假。因此,生成器就可以通过生成在整体来看不同,但仅从patch来看却十分相似的图像,来达到使判别器无法判断是真实样本还是生成样本目的。在更高分辨率上训练的生成器,将前一个生成器生成的图像作为输入,在此基础上生成比当前分辨率还要高的图像。
2.2 多尺度架构
ConSinGAN[31]中的多尺度架构是实现金字塔模型的一个有效方法。多尺度图像样本的生成经历了多个生成器,每个生成器Gn负责生成逼真的图像样本。这通过对抗性训练来实现,在训练中,Gn生成的样本送入与之相对应的判别器Dn,该判别器Dn试图将生成样本中的patch与Xn中的patch区分开。
图像样本的生成从分辨率最低的尺度开始,依次通过所有生成器,直到分辨率最高的尺度,同时会在每个尺度中加入噪声。所有的生成器和判别器都具有相同的感受野,因此在生成过程中可以捕捉到尺寸减小的结构。在分辨率最低的尺度上,该生成是生成性的,即将空间高斯噪声Z0映射到图像样本X0中。式(2)是生成器用噪声Z0生成样本X0的过程:
X0=G0(Z0)
(2)
在分辨率最低的尺度中,有效感受野通常能在图像中占很大比例,因此可以生成图像的结构布局。每个生成器Gn都有更精细的尺度,增加了之前尺度没有的细节。除了空间高斯噪声Z0以外,每个生成器还会接受前一个生成器生成图像的上采样图像:
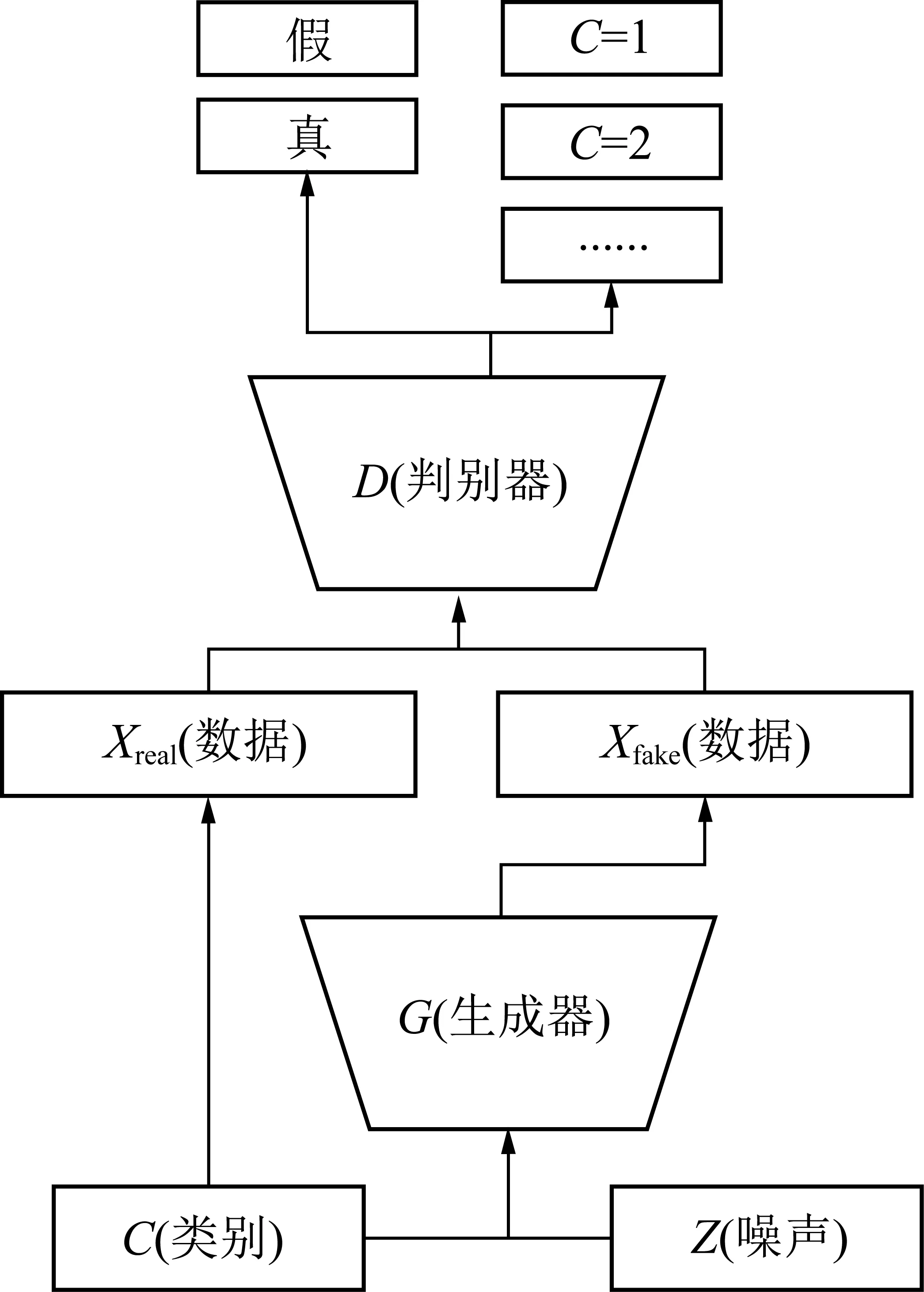
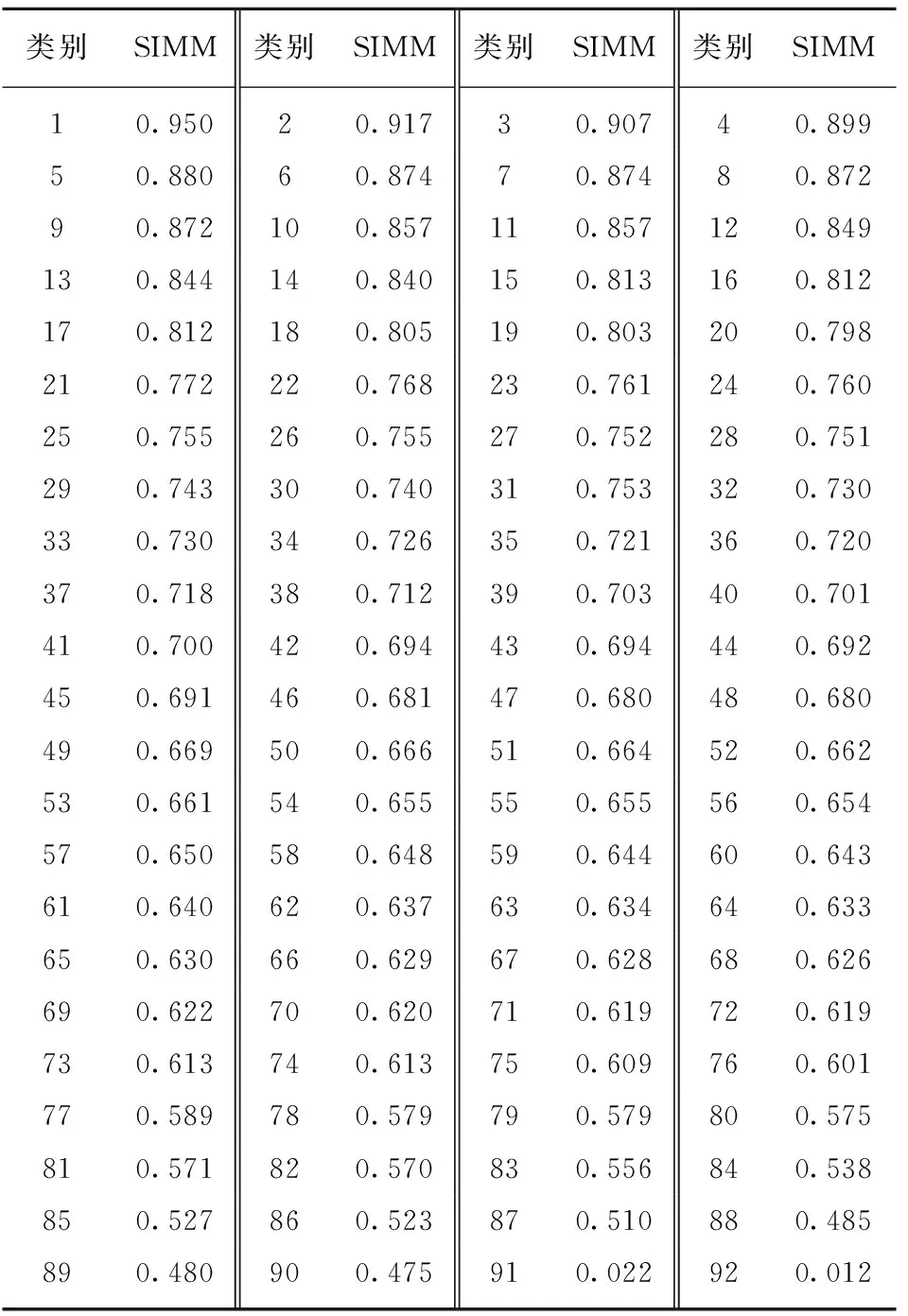
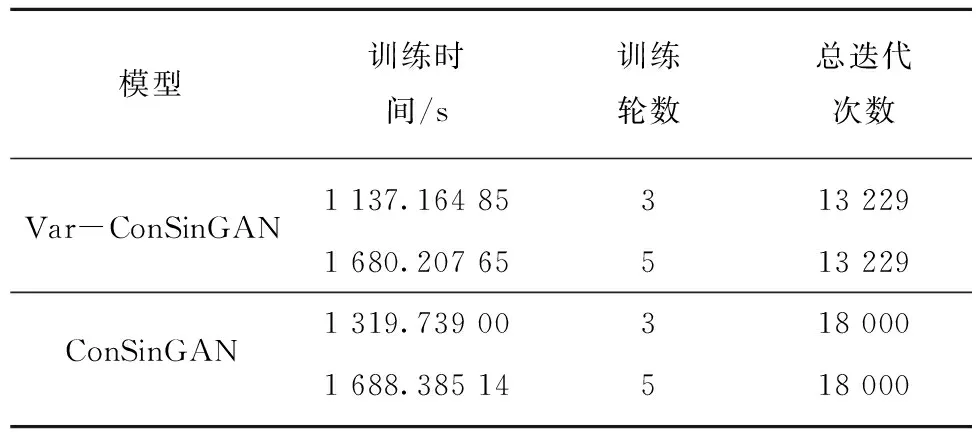
Xn=Gn(Zn+(Xn-1)↑r)n (3) 式中,↑r为图像Xn-1的上采样图像。 如图4所示,所有的生成器都具有类似的结构。具体来说,先将高斯噪声Zn加入到图像(Xn-1)↑r中,再将合成的图像送入到生成器中。这种方式可以确保生成器不会忽略噪声。卷积层的作用是生成(Xn-1)↑r中缺失的纹理细节,如公式(4)所示,其中γn代表卷积操作,卷积操作由3个完全相同的卷积块构成,每一个卷积块都是由卷积核为3×3的卷积层、归一化层和激活函数层组成,这种结构在生成煤岩图像时可以通过长宽比来生成任意大小的煤岩图像。 图4 生成器的残差结构Fig.4 Residual structure of generator Xn=(Xn-1)↑r+γn(Zn+(Xn-1)↑r) (4) 2.2节中提到,在训练前期模型主要学习图像的整体结构布局,在训练后期重点学习图像的纹理细节。由于煤岩图像的结构具有很大的不确定性,在判断煤岩类别的时候主要是从色泽和纹理等细节进行区分,因此在生成煤岩图像的时候把重点放在纹理和细节的生成上,对图像的布局进行粗略的学习。模型在训练的过程中需要用到图像在不同分辨率下的多张重构图像,不同分辨率图像的数量取决于训练时的阶段数。要实现纹理细节的学习需要一定的n阶高分辨率的学习(通常至少3个),而不需要太多低分辨率的学习。笔者设计了一个曲线函数用于尺寸调整,保持高分辨率阶段的密度大于低分辨率阶段的密度。曲线函数为 xn=1-xNr[(N-1)/lg(N)]lg(1+n)+1 (5) 式中,n的取值范围是[0,N-1]。 例如,使用原始的图像尺度调整方法,当训练阶段数为4时,得到的分辨率为25×38,40×60,89×133,167×250。在保持其他参数不变的情况下,使用新曲线函数的图像尺度调整方法得到的分辨率为56×83,100×150,117×176,167×250。除最大分辨率相同外,后者每一阶段的分辨率都大于前者。 单张图像生成的关键是多尺度、多阶段的训练方式。在训练更新当前阶段生成器的同时训练其附近部分生成器,固定其他生成器的所有参数,同时在训练过程中降低较低阶段的学习率。较大的学习率会使模型的学习速度加快,较小的学习率能够降低学习的速度,从而防止过拟合。 如图5所示,首先保证同时训练的生成器数量不超过3个,当超过3个时,选择当前阶段和前两阶段的生成器进行训练并更新参数,固定其他所有生成器的参数,其中,lr为深度学习中的学习率,是实验中人为设置的超参数。其次使用变化的学习率,默认情况下最多允许同时训练3个生成器,并分别将较低阶段生成器的学习率调至1/10和1/100。图5中从上到下的4个框表示训练过程中的4个阶段,从阶段0开始到阶段3结束,随着训练阶段的递增生成器的个数逐渐增加。当训练至第4阶段时,生成器G0的参数固定不变,更新生成器G1,G2,G3的参数并将其学习率设置为0.01lr,0.1lr,lr。 图5 模型训练过程中生成器及其学习率的变化Fig.5 Change of generator and its learning rate in the process of model training 由于金字塔模型具有多尺度、多阶段的结构特性,在训练上需要消耗很长时间。模型在完成单次训练任务时,所需要的训练时间在可接受范围之内,但是当需要完成多次重复训练任务时,需要消耗的时间将成倍增长。同时在煤岩图像生成中煤岩图像细节纹理特征比其结构特征更为重要。因此Var-ConSinGAN提出了在训练过程中改变每一轮训练需要的迭代次数,不仅缩短了模型训练的时间,还符合模型重点学习煤岩细节特征的思想。SinGAN[29]训练模型时需要训练每一阶段的生成器,之后ConSinGAN[31]提出了固定一部分生成器只训练特定数量生成器的方式,Var-ConSinGAN在此基础上更改了每一轮训练的迭代次数。 (6) 式(6)为一个分段函数,该分段函数用于计算每一轮需要的迭代次数。其中iter为每一阶段生成器的当前迭代次数;niter为自定义的迭代次数;β为达到训练峰值的速率;max为最大训练阶段数,当训练阶段达到最大值时,训练的迭代次数保持不变;depth为当前训练阶段,随着训练阶段的变化而变化。具有初始值的超参数都可以根据具体训练情况改变。 个别阶段生成器的迭代次数有增加,但是通过减少大部分生成器的迭代次数,使模型整体的迭代次数有明显下降,减少了训练所需时间,提高了模型的性能。 在实际开采中有各种各样的煤岩,由于开采的方式和进度不同,得到的煤岩图像千差万别,利用特征迁移处理不同类别之间的图像可以得到新样本。特征迁移是当b类图像不具有a类图像的某种特征时,通过模型将a类图像的某种特征迁移到b类图像中,使生成的新图像同时具有a类和b类图像的部分特征。Var-ConSinGAN模型利用一张煤岩图像进行生成,生成的结果在与原始图片类似的基础上通过改变其部分结构和纹理特征从而生成新的煤岩图像。因此,通过框架中的ACGAN[32]对Var-ConSinGAN模型生成的煤岩图像进行特征迁移具有重要意义。 生成器和判别器的模型由卷积神经网络组成,因此网络的规模和参数数量固定不变。模型中的所有参数共同决定生成图像的样子,因此不同类别之间在生成图像时会使用一部分相同的参数,这使得不同类别之间可以学习到自身不具备的特征。 利用Var-ConSinGAN模型训练一次后,就把这次生成的图像看作是一个类别,然后对这些不同类别的图像进行特征迁移。由于类别划分清晰,所以该部分采用ACGAN[32]的结构,如图6所示。图6中C,Z,Xreal,Xfake分别为输入图像的类别、用于生成图像的噪声、真实图像数据和生成器生成的假图像;真表示原图,假表示生成器生成的图。图7中的判别器除了判断真假外还会输出输入图像的类别C。 图6 ACGAN模型结构Fig.6 ACGAN model structure 按顺序训练多尺度架构,从最低分辨率尺度到最高分辨率尺度。当同时训练3个以上生成器时,只更新当前最近的3个生成器的参数,固定其他生成器。在第n阶段,GAN的损失函数包含对抗损失和重建损失。GAN的损失函数为 (7) 其中,ladv为对抗损失;lrec为重建损失;α为人为设置的权重。对抗损失指在生成的样本中,生成图像中的patch和真实图像中的patch分布之间的距离。重建损失可以确定一组能够生成图像的噪音。 对抗损失。模型中使用了WGAN-GP[33,37]损失,是一种截断修剪的策略,即惩罚判别器相对于其输入(由随机噪声Z生成的图片,即fake image)曲线的常量,这种损失能使模型的训练变得更加稳定,并且取得更高质量的生成效果。 重建损失。对于输入的噪声来说,希望它能够更好的生成原图像。构建一个噪声向量{Zrec0,Zrec1,…,ZrecN-1,ZrecN}={Z*,0,…,0},Z0,Z1等为Z噪声向量,下标0,1等为不同阶段噪声向量,下标rec表示该噪声向量在lrec损失中用到;Z*为固定的噪声向量,在一次训练中保持不变。式(8)为重建损失函数,重建损失也可以在每一阶段都使用n=0时的公式进行计算。 (8) 判别器的训练方式保持不变,即它的输入是生成器生成的图像或真实的图像,训练时的目标是使ladv最大化。在训练初始阶段,首先要对输入图像进行缩放,使图像的长边在第n阶段时具有250像素的分辨率。模型中生成器的每一级由3个卷积层组成,每层有64个滤波器,滤波器大小为3×3。判别器也使用和生成器相同的结构,即3个卷积层,64个滤波器,滤波器的大小为3×3。在训练中,始终训练模型的最后3个阶段。每个阶段训练的迭代次数由2.5节中的公式计算得出,初始学习率为0.000 5,在每个训练阶段迭代1 600次后学习率降低10倍,迭代次数达不到1 600次的不发生变化,模型使用ADAM优化器优化网络。模型中使用的激活函数是ReLU,激活函数的参数设置为0.05。 实验重点在单张煤岩图像生成上,在实验中检验了模型的有效性,同时与过去的模型在生成结果和性能上做了对比,结果表明该文Var-ConSinGAN模型能够在煤岩图像生成领域中取得较好的效果。实验时使用的数据由相机拍摄的500张煤岩图像组成。模型训练的硬件环境包括CentOS Linux release 7.5.1804(Core),Intel(R)Core(TM) i9-9900K CPU @ 3.60 GHz,NVIDIA GeForce GTX 2080Ti;软件环境包括Python 3.5,Pytorch 1.1.0和CUDA 10.2等。 在图像生成任务中,煤岩图像从随机采样的高斯噪音中生成。因为模型的结构由全卷积构成,所以可以通过改变噪声向量的大小,以达到用训练好的模型进行生成煤岩图像任务的目的。如图7所示,利用Var-ConSinGAN模型生成效果较好的煤岩图像,该生成图像具有不同尺寸大小,并且在接近真实煤岩图像的基础上提高了其多样性。在训练的煤岩图像的布局结构性较弱但细节纹理较强的情况下,模型能够达到最佳效果;在结构性较强而细节纹理较弱的煤岩图像生成时,会对模型的生成效果产生一定的影响。本次实验用到的部分重要参数设置分别为train_stages=4,lr_scale=0.1,nfc=64,ker_size=3,num_layer=3,padd_size=0,max_size=250,train_depth=3,niter=2 000,lr_g=0.000 5,lr_d=0.000 5。 图7中第1列是该实验使用的6张原始煤岩图像数据,第3列是模型训练过程中的重构图像,其余的图像是经过单张图像生成的不同尺寸的图像。从图7的结果可以看出,模型生成的图像并不是简单的由原图像拉伸得到,而是利用模型学习到的煤岩图像特征扩展而成。卷积神经网络中的卷积操作是将图像中的特征提取出来并以参数的形式储存下来,而在图像生成时使用卷积神经网络对图像进行下采样,由生成图像的方式决定,可以生成任意长宽比的煤岩图像。图7中除第4行的图像外,其他5行图像结构布局特征并不明显,所以模型生成的图像与原始图像极为相似,细节纹理也十分逼真,第4行的图像因为其纹理有横向分布的空间特征,所以效果没有其他图像的效果好。 实验中使用SSIM指数评估了生成图像的每一组结果。首先,把原图缩放重建到与生成图像相同分辨率的尺寸上,之后用每一张生成的图像计算其与原图像的SSIM指数,再对每一类图像的SSIM指数求均值得到该类图像(根据原始图像生成的图像)的SSIM指数,见表1,列举了结果中92个SSIM指标值。由SSIM测量系统可得相似度的测量可由3种对比模块组成,分别为:亮度、对比度、结构。SSIM值越大表明生成的图像和原始图像越相似,实验结果显示不同种类之间的值差距较大,主要是因为使用的煤岩图像数据分为结构性和纹理性2种。结构性指煤岩图像具有明显的块状分布,纹理性指煤岩的表面较为平整。 表1 各类生成图像的SSIM指数Table 1 SSIM index of various generated images 通过实验结果可以得出,当原图像结构性强时,生成的图像SSIM指数由于其结构发生了多样性变化,所以其SSIM指数较低;相反,当原图像结构性较弱而纹理较强时,生成的图像SSIM指数较高。为了保证生成高质量图像的同时提高其多样性,必须保证SSIM指数既不能太高也不能太低。 对比试验分别是ConSinGAN[31]、更换图像尺寸调整后的模型及使用迭代次数分段函数的模型。在实验中训练时采用的迭代轮数是6轮,每一轮迭代次数初始值是3 000次,训练时图像的最长边尺寸是250像素。主要从生成图像的多样性、生成图像的质量及相同轮数下不同方法的生成效果等3方面进行对比。在训练中是从n=0时开始训练,即当训练轮数n=2时,实际上已经训练了3轮,即n=1,2,3。 如图8所示,该结果是ConSinGAN[31]模型生成的效果图。从图8可以看出,当训练轮数n=2时,生成的图像已有基本轮廓,纹理也比较清晰。对比第2轮的4张生成样本,可以发现样本之间存在部分差异性,当在第3轮之后,生成的煤岩图像之间的差异性基本消失,但是图像的质量有所提高,清晰度比之前训练轮数较少时要高。由此得出结论,随着训练轮数的增加,生成图像的多样性会降低,而生成图像的质量会得到一定提高。另外,生成图像的多样性体现在了图像的中间区域,而图像的上下左右4块边缘区域的变化很少,多张图像一起看时就像给图像加了“边框”。 图8 ConSinGAN生成的不同阶段数下的图像Fig.8 Images generated by ConSinGAN under different stages 如图9所示,该结果在模型的训练过程中使用了曲线函数。从图中可以看出,当训练轮数n=2时,生成的图像“边框”感明显,并且纹理细节与原始图像差距较大,造成这种情况的原因是模型在训练过程中使用了曲线函数。模型为了增加生成图像的多样性而减少了前几轮中每一轮的迭代次数,导致模型总体的训练次数降低,从而无法学习到更多的细节。在之后的迭代轮数中,第3轮的多样性最高,同时图像的质量和原图像尺寸变换之后的质量相同。与ConSinGAN模型生成的煤岩样本相比,该方法改善了生成样本中存在明显“边框”感的问题。 图9 迭代次数动态变化时模型生成的不同阶段数下的图像Fig.9 Images generated by the model under different stages when the number of iterations changes dynamically 如图10所示,该结果是在模型中改变图像尺寸变换方法后生成的图像。从图10可以看出,在第2轮时模型只学习到了纹理细节特征,而图像的整体布局基本没有学习到,所以生成的图像看起来只有纹理,可辨识度不高。这种情况在之后的训练轮数中得到了解决,生成的图像具有很好的多样性。原模型在第6轮训练后,模型接近过拟合,生成的图像除细小变换外基本没有不同。但在使用了新的图像尺寸变换方法后,不仅增加了生成图像的多样性,还解决了图像边缘多样性不足的问题。 图10 更改图像尺寸变换方式后模型生成的不同阶段 数下的图像Fig.10 Images under different stages generated by the model after changing the image size transformation mode 经过实验对比,可以得出有效的结论。针对原有方法生成的煤岩图像多样性不足且“边框”感明显的问题,本文提出的2种方法具有明显的效果。每一种方法都会使结果得到改善,最后,该文将2种方法同时使用,使改模型能够很好地完成煤岩图像生成任务。 实验的数据、超参数和实验环境完全相同,在训练轮数为3和5时分别训练2个模型,得到的结果见表2。由表2可知,当训练论数等于3时两者相差约182 s,得益于训练方法的改变,模型性能有了较大的提升。但是当训练轮数等于5时,两者的时间差较小。虽然两者的总迭代次数都与训练轮数等于3时完全相同,但是训练所需时间却随着训练轮数的增加而变得接近。造成这种情况的原因是卷积运算增加了耗时,虽然通过改变训练方式使模型的总迭代次数减少,但是由于每一轮中前者比后者训练的尺度要大,卷积运算所需要的时间更长,所以总耗时增加。虽然随着训练轮数的增加,总耗时会逐渐接近原模型的训练时间,但在训练到第3轮时就能得到煤岩生成需要的结果。 表2 ConSinGAN和改进后模型的训练时间对比Table 2 Training time comparison between ConSinGAN and improved model 当模型Var-ConSinGAN训练完成时,将模型最后一次迭代的参数保存下来。接下来根据训练好的模型生成需要的煤岩图像,其中每一张训练图像对应一个模型参数,每次训练只能得到一张图像对应的模型参数。然后将这里得到的模型参数加载到网络中,此任务和训练时有部分不同,训练的时候需要将生成的结果输入到判别器当中,将得到的判别器的结果作为反馈去反向更新生成器的参数,然而在训练之后的生成任务中,由于生成器已经完全固定,所以不需要将结果输入到判别器中,同时生成器的参数也不需要更新,在加载模型之后,需要将模型模式设置为评估模式。 通过训练得到14个煤岩图像的模型参数。一个模型需要生成1 200张煤岩图像,其中分别生成相对于原图像的长宽比为1∶1,2∶1和1∶2各400张。特征迁移使用ACGAN[32],其生成器模型由5个卷积块构成,其中4个卷积块的结构相同,每个卷积块都是由一个卷积层、一个归一化层和一个激活函数层构成,最后一个卷积块去掉了归一化层并且把激活函数由ReLU换成Tanh。这些卷积块按顺序组合而成,并在模型的开头添加了一个全连接的线性层用来将噪声向量进行扩展。判别器模型也是由6个卷积块构成,每个卷积块的结构都一样,由一个卷积层,一个归一化层、一个激活函数层和一个Dropout层组成。 本实验使用生成的14类煤岩图像,每类1 200张共16 800张图像,达到了深度学习对数据量的要求。实验的模型参数设置是|nz|=110,lr=0.000 2,num_classes=14。参数中的num_classes表示训练的类别,可以根据具体实验更改;nz是噪音向量,如果需要更改噪音向量的大小,也需要修改模型对应的参数;生成器和判别器都采用Adam优化器。模型的生成器由一个全连接层和5个卷积层构成,每个卷积层后添加一个归一化层和ReLU激活函数层。判别器由6个卷积层构成,每个卷积层后添加归一化层、LeakyReLU激活函数层和Dropout层,最后添加2个全连接层用于分类和判断样本的真假。 如图11所示,左图为生成器生成的煤岩图像,右图为经过缩放变换后的真实煤岩图像。由于ACGAN模型的结构设计较为简单且煤岩图像整体较黑,导致生成的图像非常模糊。从生成的结果可以看出用GAN[32,35-36,38]来做图像生成的同时使用特征迁移是有一定效果的。右图中的真实图像在左图的生成图像中无法找到与其完全一样的图像,并且生成的图像具有真实图像所没有的特征,实现了不同类别之间的特征迁移。 如图12所示,实验中使用的煤岩图像具有明显的灯光反光点,这种白色反光点在煤岩图像的生成过程中会被模型认为是煤岩的特征,在利用Var-ConSinGAN模型生成煤岩图像时也会生成大量白色反光点,对生成效果产生较大影响;同时,该模型在生成时无法兼顾结构特征明显的煤岩图像。以上两点是本文未来工作中需要改进的一个重要方面。 图12 具有灯光反光点的煤岩图像Fig.12 Coal and rock image with light reflection points (1)Var-ConSinGAN模型不仅可以缓解现有模型生成的煤岩图像具有明显“边框”感的问题,还对图像的纹理特征、结构布局进行随机生成,同时缩短模型训练需要的时间,提升模型性能。 (2)使用相机拍摄的500张煤岩图像进行仿真实验,结果表明,相比于其他图像生成的方法,Var-ConSinGAN模型可以在极少的数据上进行训练(其他用于图像生成的GAN模型必须有大量的图像数据)。 (3)模型有效提高了生成图像的质量与多样性,证明了Var-ConSinGAN模型在煤岩图像生成领域中的可行性。 针对当前缺少煤岩图像数据的问题,下一步将利用生成式对抗网络构建煤岩图像数据集,在网络模型中引入注意力机制等方法,以消除煤岩图像数据本身(如带白色反光点和无法兼顾结构特征明显的图像)存在的不足对生成结果的影响。在使用AlexNet,VGG,GoogLeNet,ResNet,Inception等模型进行煤岩识别任务的同时,验证构造的煤岩图像数据集的可用性。采煤时采煤滚筒通过人为控制高度从而避开顶板和底板,会造成安全隐患。针对采煤时采煤滚筒需实现自动调节高度这一问题,接下来将采用图像语义分割这一技术,实现采煤机切割时的自动化。
2.3 图像尺寸调整
2.4 多阶段训练方式
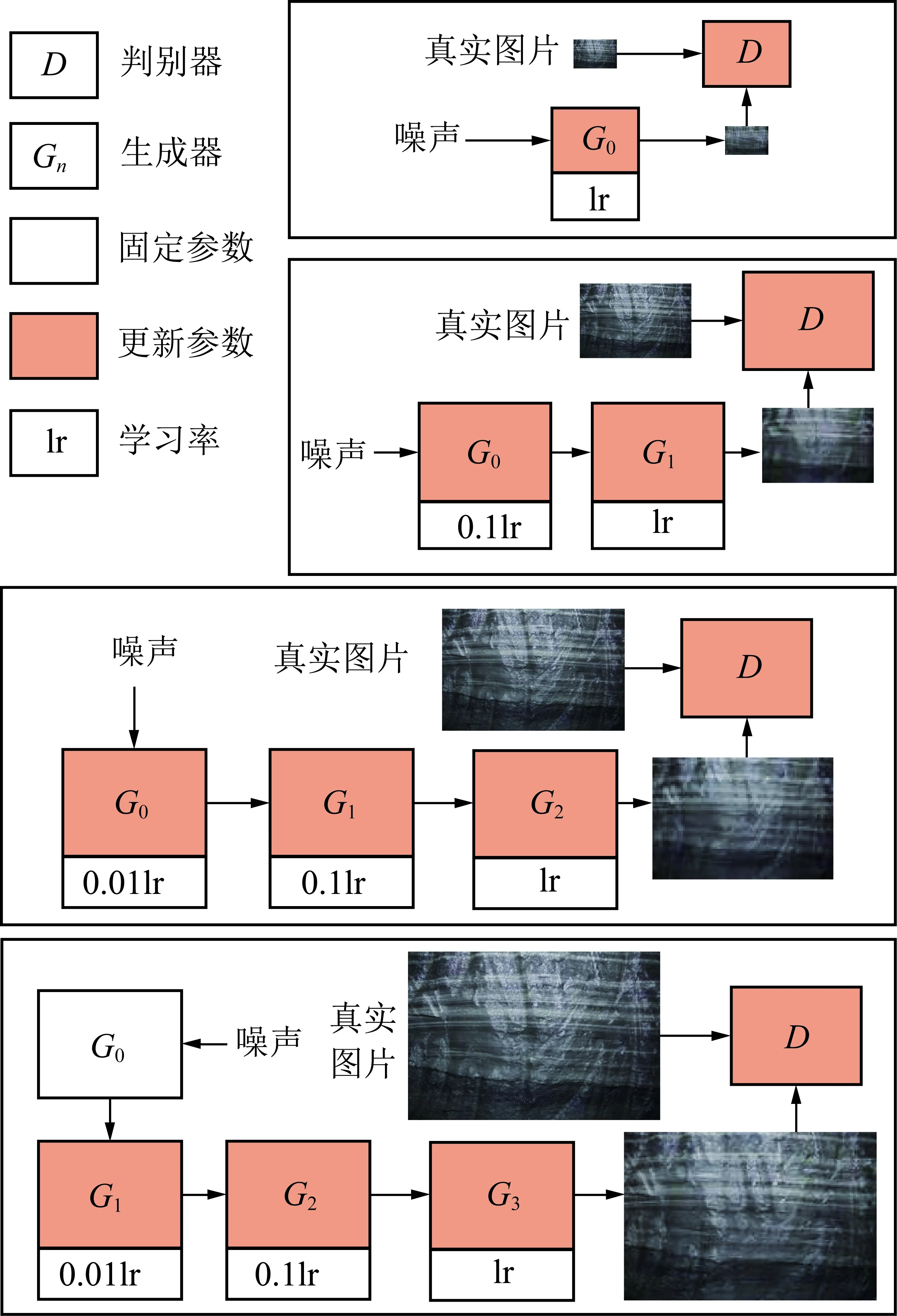
2.5 动态变化的迭代次数
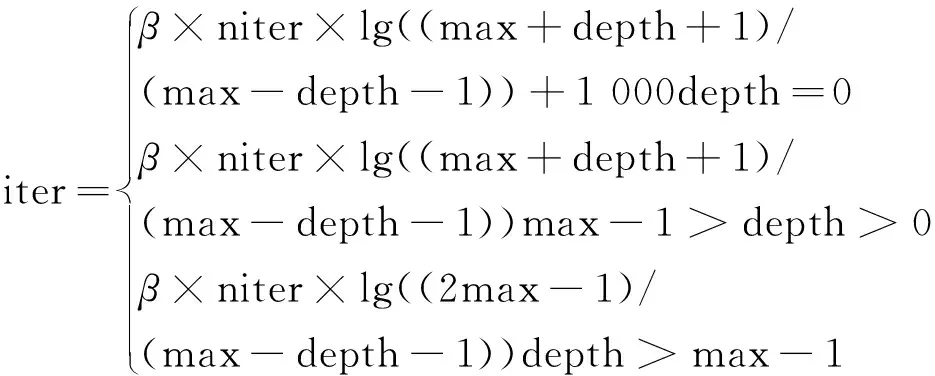
2.6 特征迁移
3 训练过程和损失函数
4 实验结果及分析
4.1 无条件煤岩图像生成
4.2 对比实验



4.3 模型性能
4.4 特征迁移

5 结论与展望
5.1 结 论
5.2 展 望
