基于Tor网站文本内容和特征的分类方法
2021-10-29李明哲
◆李明哲
基于Tor网站文本内容和特征的分类方法
◆李明哲
(北京交通大学计算机与信息技术学院 北京 100044)
所谓暗网,指的是包含有意隐藏的内容且无法被传统搜索引擎检索的深层网络,在目前主流的暗网形态中,洋葱路由(Tor)是其中使用最广泛的一个。洋葱网站通过隐藏服务协议模糊网络IP,导致近年来大量违法犯罪活动在Tor网络上托管。在本文工作中,我们探讨了基于其文本内容自动引入外部知识在Tor暗网上识别非法活动的可能性。在对2000个隐藏服务的网页进行爬取和过滤后,我们将它们分类为6个不同的非法类别,并使用异构图神经网络模型训练了分类器。在该模型中,使用TF-IDF作为文本特征加权方法来选择对类别影响因子大的关键词。然而,由于暗网非法网页的短文本特性,经典的机器学习分类器很难在有限的语境中进行准确的语义理解。为了克服这一缺点,我们在图神经网络模型中引入了实体和主题等外部知识捕捉文本与附加信息之间的丰富关系。结果表明,用图神经网络建模代替经典机器学习模型是有效果的,在相同数据集的前提下,基于图神经网络的方法比现有的暗网文本分类方法提高了3个百分点。
暗网;图神经网络;文本分类;非法活动;Tor
1 简介
暗网是一种建立在互联网基础之上,经过加密的匿名网络,由于无法直接访问暗网,因此用户需要使用特殊的软件,目前最为流行与实用的匿名通信系统为Tor(洋葱路由)。Tor依靠志愿者计算机网络通过一系列其他用户的计算机来路由用户的Web流量,这样流量就无法追踪到原始用户[1]。根据Tor Metrics显示,截至2021年1月网络中每天V2版本onion服务的唯一地址数超过17万,Tor的直连用户估计数目超过200万。
基于难以追踪和匿名的特性,暗网中充斥着各类犯罪,诸如枪支买卖、毒品交易、人口贩卖、淫秽信息传播等。那些在现实中被严厉打击的非法交易,却在暗网中找到了藏身之地。根据Al-Nabki等人[2]的研究发现,在他们从Tor暗网爬取的活跃域中,29%的域名包含不同种类的可疑或潜在的非法活动。2017年7月,美国司法部与欧洲刑警组织宣称,他们的联手打压促使世界上四个最大暗网市场中的两个AlphaBay与Hansa关闭业务[3]。此外还有RAMP暗网市场最终的结局也是被彻底摧毁,此后买卖家又换到暗网黑市Dream Market和其他市场继续进行毒品交易。直到现在Dream Market宣布关闭,至此自 2010 年开始崛起的暗网四大门户网站全部被摧毁或关闭,无数交易者被捕。更令人担忧的是,暗网逐渐成为非法信息贩卖的主要渠道。2020年3月19日5亿微博隐私数据被爆遭遇泄漏,大量被泄露的个人信息用于btc和eth交易,此事在国际暗网上产生巨大影响。这说明暗网作为在恶意活动中提供出售非法商品或服务的匿名交易平台吸引了大量的犯罪分子,未来黑市的存在和需求将会更普及。因此,我们有必要对暗网上的非法活动进行识别和监测,从而为维护网络空间安全和执法机构掌握暗网非法活动类别分布提供帮助。
然而,现有的关于暗网网页分类的研究面临以下挑战:
(1)由于暗网空间域名存活期短,其中大部分网站上公开的暗网数据已无法再次访问,无法实时追踪最新的暗网非法活动。
(2)在实际的隐藏服务空间具有短文本特性,篇幅短小、特征稀疏等问题导致传统的网页文本分类算法不能很好地适用,需要提出一种特征扩展方法。
(3)隐藏服务空间中非法活动分布并不均匀,某些可能造成严重安全威胁的非法活动(如武器贩卖、数据泄露等)网站数量十分有限,会导致分类过程中的数据集不均衡问题。
为了应对上述挑战,我们的研究重点在于设计和构建一套集域名发现、验证和爬取为一体的暗网爬虫框架,同时结合网页中的文本信息对Tor暗网上的非法活动进行精准分类。因此,我们在研究中做出以下贡献。
(1)我们开发了一套基于暗网和明网两种渠道的暗网爬虫框架,该爬虫持续运行累计收集了超过3万个洋葱页面。
(2)提出了一种应用图神经网络建模进行暗网非法活动分类的方法,利用文本的潜在主题和实体标注来丰富语义,从而缓解暗网网页文本的稀疏性。
(3)在我们自己创建的文本数据集上训练文本分类器,在我们爬虫存储库中的子集上做小规模分类测试,其达到了0.967的精确度。
本文的其余部分安排如下。首先,第二节回顾相关工作。其次,第三节描述了我们提出的分类方法的设计思想。然后,第四节介绍了实验的部署和技术细节。最后,第五部分给出了结论和下一步的工作。
2 相关工作
目前关于隐藏服务内容的研究主要分为隐藏服务空间资源获取和网页内容分类两个方面。隐藏服务的大规模发现和收集是内容分析的前提,关于Tor域名的采集来源,现有的研究主要集中在表层网络和深层网络两种渠道的搜索以及自己部署服务器节点捕获[4]。Kang Li等人利用Tor2Web工具从明网搜索引擎上检索特定关键词来发现隐藏服务,使用亚马逊服务器在一小时内收集到173667个独特的洋葱地址,其中4857个在线活跃可访问,证明了该方法的可行性和有效性[5]。不同于明网的搜索引擎,暗网的许多隐藏服务列表包含在数据库中,Clement Guitton通过使用暗网中三个主要的数据库(Hidden Wiki、Snapp BBS和Ahmia.fi),对其中的Tor隐藏服务地址进行采集爬取,统计结果表明,这三个数据库提取的总体数据有很大的重叠,暗网目录网站收录的大多是影响力大的知名隐藏服务而忽略一些私人的、不受欢迎的网站[6]。Owen等人通过在6个月内运行大量的Tor服务器,从Tor分布式哈希表中捕获数据,以收集隐藏服务的列表,对其内容进行分类并统计请求数。总共观察到大约80000个隐藏服务,其中在任何一个时间点都有大约45000个服务[7]。
在暗网网页文本分类方面,由于数据集中不相关特征的存在,使用经典的机器学习分类技术来检测来自暗网网站的文本数据的性能会受到影响。Mohd Faizan研究团队提出了一种基于互信息和线性判别分析的两步降维方案,对暗网文本内容进行分类。在两种数据集上进行了测试,结果表明,其所提出的两步技术可以积极地提高分类性能,同时显着减少特征数量[8]。Spitters等人提出了一种基于Web内容的挖掘方法,用于分析TOR网络上的1000多个隐藏服务,以揭示它们的“主题组织”和“语言多样性”[9]。另一方面,Ghosh等人提出了一种用于分析公共TOR HS生态系统内容的自动爬虫系统,命名为“洋葱自动标记工具”(ATOL)。它包括三个核心组件:1)一个新的关键词发现机制:“ATOL关键词”;2)一个分类框架:ATOL分类;3)一个聚类框架:“ATOL集群”。在武器、毒品和黑客三种类型暗网非法活动数据集上,ATOLClassify比分析师提供的基线性能提高了12%,而ATOLCluster比最先进的半监督聚类算法提高了7%[10]。
3 Tor暗网分类方法设计
通过大量的暗网网页浏览分析,我们总结出暗网网站普遍具有的内容结构特点,并针对性的设计检测暗网中非法网页的分类方法。下面将分别从网页特征分析、分类模型设计两方面展开介绍。
3.1 Tor网页特征分析
在设计分类方法之前,我们首先对拿到的待分类的暗网网页进行观察,发现其与明网普通网页在内容和结构上存在一定差异,这也决定了传统的网页分类方法不能完全适用于暗网分类任务,有必要人工进行特征分析以设计相对应的分类策略,总结得出的特点如下。图1是暗网非法网站的典型模式。
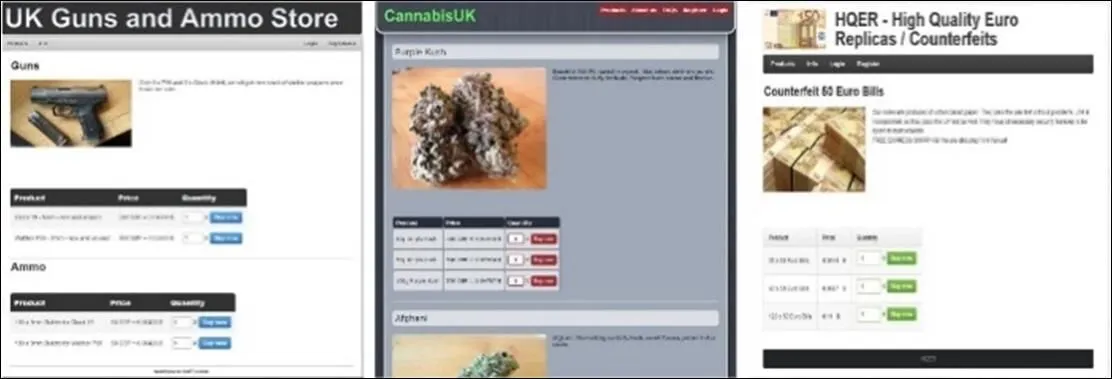
图1 暗网非法网站部分截图
(1)暗网空间中存在合法类别的个人网页或分享技术帖,也有严重危害的非法网页。经初步统计,Tor隐藏服务中超过80%的非法网站都涉及严重违法行为,在规模和内容方面存在很强的相似性,从研究意义的角度,之后的分类数据都采用暗网的违法活动网页。
(2)非法交易网站普遍篇幅短小,结构简单,缺少足够的特征信息来进行统计推断,因此机器很难在有限的语境中进行准确的语义理解,需要添加一些附加信息来帮助语义理解和避免歧义。
(3)暗网网页中使用的词汇大部分偏向商品专有名词和暗网黑话,很难通过字面意思判断,只有借助工具标注或经验理解好相关术语,才能提取出有价值的特征信息。
基于以上暗网网页的内容结构特点,我们提出一种应用图神经网络引入外部知识来鉴别违法活动的分类方法,在传统的网页文本分类技术的基础上综合考虑潜在主题和实体标注来丰富语义,以达到更好的分类效果。对于暗网不平衡数据集分类的欠拟合问题,标准分类器可能会忽略少数类的重要性[11]。在数据层面进行重新采样,在训练集增加具有相关性的明网网页,从而平衡数据、提高泛化能力。在第四部分,我们通过对比实验证明了所提出的分类模型具有良好的实验性能和可用性价值。
3.2 分类模型选择与特征扩充
对于文本分类的模型选择,传统的基于人为设计特征的机器学习分类器和近年来兴起的深度学习模型适用于不同场景,各有利弊。由于暗网网页自身的文本稀疏性,常用的基于词频和统计的特征加权方法体现不出良好的效果,因此,我们需要引入外部知识来丰富语义信息、标注词汇含义,尽可能多地在有限的文本中挖掘出具有类别区分性的代表特征来提高准确率。经典的机器学习分类器模型依赖于自身的词汇组成表示文档,并不符合我们的应用场景。受Linmei Hu等人提出的异构图神经网络[12]的启发,我们发现基于图的方法在处理暗网分类任务上也有一些优势。使用图建模的好处在于可以充分利用有限的标记数据,通过节点间的关联将标注信息传播到其他未标注文档。另外,不局限于文档本身的词汇特征可以集成多种额外的信息来丰富语义,如果用来表示文档的附加信息选取合理,则分类的提升较大。
除了网页文本自带的词汇语义信息之外,我们考虑两种类型的外部知识引入:潜在主题分析和语料实体链接。主题通常是一组词的聚类,没有明确的可解释性语义。主题分析的原理是将文本转化为一种映射在语义空间里的向量,向量的每一个维度对应一个主题,人们只能通过主题下的特征词猜测其代表的含义。在以往的研究应用中,潜在Dirichlet分布(LDA)[13]被证实在捕获有效的语义表示方面具有优势。LDA是一种生成式模型,它能够通过非监督的方式给出文档集合中每篇文档所属主题的概率分布,从而实现文本分类的效果。它采用词袋的方式,用索引值替代文档中的单词形成语料词典,将每篇文档表示为词频向量的形式,使得文档数据集能够以数值矩阵的形式参与运算。在LDA模型中,每篇文章都是由在主题中概率分布的词语构成,同时文章中也隐含着主题的概率分布,当我们提供词语-主题、主题-文档的标注数据时,LDA模型则能够通过训练实现文本分类。
在自然语言处理中,实体链接是一种关键的语料处理技术,旨在将存在多种含义的词语从输入文本映射到目标知识库中的相应唯一实体。比如对于“Apple”一词既可以指水果的“苹果”也可以代表手机的“苹果”,出现在不同语境中含义也截然不同,实体链接工具可以完成这种基于上下文语义标注实体概念的工作。TagMe是一个强大的实体链接工具,它可以在非结构化文本中动态识别有意义的子字符串,并以高效的方式将它们链接到相关的Wikipedia页面。用户只需要向官方给出的API发出查询即可注释文本,应用工具标注后的概念表示文本,能有效解决一词多义的歧义问题。
4 实验
这一部分展示了我们分类模型的实验建立,以及实验中采取的具体技术细节。为了验证模型的分类性能,在相同数据集的情况下,与目前已有的暗网文本分类方法进行对比实验,根据结果分析各自优劣。
4.1 数据源
我们考虑从明网和暗网两种渠道来分别收集Tor域名。明网方面,借助Tor2Web关键词配合搜索引擎的site语法查找明网Tor2Web项目收录的洋葱站点,将获得的明网地址存入数据库。暗网方面,抓取来自诸如ahmia,tordex 等一些暗网大型目录网站索引的洋葱地址。最后,使用我们改进的scrapy爬虫下载数据库中所有的onion地址对应的完整网页。在完整数据集中,我们发现大量重复内容托管在不同域名的网站上,通过对比标题和内容去重,获得了2088个唯一的域名。考虑到分类工作的实际意义,我们选取6个典型的暗网非法类别构成包含300个页面的暗网子集进行实验(伪造、色情、毒品、武器、黑客、数据泄露)。
4.2 文本预处理
对于上述Tor暗网网页的HTML文件,首先我们清除了HTML标签和格式设置,从而获得网页对应的文本数据集。然后,我们利用网页文本分类中的英文停用词列表,通过添加一些与类别无关的暗网常用词来过滤文本数据,使其更适合我们的应用。
文档主题提取:使用LDA推测文档的主题分布,将文档集中每篇文档的主题以概率分布的形式给出,通过分析一些文档,抽取出它们的主题分布,便可以根据主题分布进行文本分类。
文档实体识别:首先,向TagMe api发出查询。浏览器访问“https://tagme.d4science.org/tagme/tag”,通过请求参数输入正文。然后,通过TagMe注释文本。TagMe返回结果是(spot,entity)形式的注释对,其中“spot”是输入文本的子字符串,“entity”是对Wikipedia页面的引用,表示在上下文中该实体的含义。图2是使用TagMe的演示界面进行实体注释的示例,蓝色字体代表文本中提取出的实体,同时返回的还有在当前语境中的实体释义。通过API查询原理相同。
4.3 实验方法
分类使用的图神经网络模型由三种类型的节点组成,即文档节点、主题节点和实体节点,节点之间的边表示从属关系,允许信息沿边传播。文档节点由基于词袋模型的TF-IDF特征加权方法表示,将文档转化成由特征词权重组成的向量形式。使用LDA主题模型挖掘潜在主题来丰富暗网网页的语义,每个主题由单词上的概率分布表示,我们将每个文档分配给概率最大的前两个主题,如果文档被分配给当前主题,则会建立文档与主题之间的边。文档中的实体使用TagMe工具将其映射到Wikipedia,如果文档包含实体,则会构建文档和实体之间的边。将一个实体作为一个完整的单词,在Wikipedia语料库的基础上使用word2vec学习实体嵌入,如果基于嵌入度计算的两个实体之间的余弦相似性超过0.5,则在实体节点之间建立边。至此,网络模型构建完成。图3是我们在处理过程中还原的一个节点的网络连接架构。其中7号代表文档节点,上面是文档中提取出的实体节点,下方是分配的两个主题节点。网络中其余节点连接情况类似。

图2 TagMe实体链接示例

表1 与现有方法的比较实验
4.4 实验结果
为了验证分类模型的性能,将我们改进的方法与现有的暗网分类方法进行了对比实验如表1所示。实验数据按照3:1的比例分为训练集与测试集,对于数据明显不足的武器和数据泄露类别在明网采集同类页面加以补充。我们选择仅使用人为提供的关键词列表计算余弦相似度与softmax变换组合作为测试的基线。还比较了在关键词提取技术上有很大改进的ATOL方法[10],在依照个人经验得出的关键词列表上使用改进的TF-ICF术语加权算法的分类效果。
结果表明,在相同数据集的情况下,我们提出的方法优于现有的暗网分类模型。ATOL方法人为提供的关键词列表需要对暗网活动充分了解,总结出符合的类别黑话术语,这对于不涉猎此领域的用户有一定困难。提供的种子列表不够符合暗网空间的实际情况可能是导致上述两种方法在此实验中表现不佳的原因。而我们的方法的优点是它需要的外部知识直接从知识库处理引用即可,对个人的经验不做约束。同时,基于异构图的方法可以添加任何附加信息,对于暗网分类任务有巨大的提升空间。
5 结论和今后的工作
本文介绍了一种对Tor暗网上的非法活动进行分类的方法。该方法在短文本信息量不足、非法活动分布不均的暗网空间可以得到很好的应用。选择图神经网络模型来训练分类器,可以引入外部知识进行特征扩充,将上下文对单词语义的影响纳入计算,降低因自身文本特征稀疏导致模型训练语料不足带来的预测误差。我们使用Scrapy爬虫从Tor暗网收集非法网页,基于特征扩充的思想分别引入了主题分析和实体标注,改进后的分类器比现有的暗网分类方法效果更好,达到了0.967的精度。此外,采用更适合的外部知识来表示文本,暗网分类任务可达到的上限将会很高,这使得基于图神经网络的暗网分类方法具有很大的潜力。
未来,我们的工作也可以在一些合法的暗网网页上进行实验,以验证我们提出的模型的检测性能和可靠性。另一方面,由于暗网提供非法物品交易页面的商品图片具有较强的类别区分性,以后可以考虑将文本与图片特征融合互补,提高分类方法的性能。
[1]Finklea,K.(2017). Dark Web,CSR-Congressional Research Service Report 7-5700,R44101.
[2]Al-Nabki,M. W.,Fidalgo,E.,Alegre,E.,& Fernandez-Robles,L..(2019). Torank:identifying the most influential suspicious domains in the tor network. Expert Systems with Applications,123(JUN.),212-226.
[3]Afilipoaie,A.,& Shortis,P.(2018). Crypto-Market Enforcement-New Strategy and Tactics1. Policy,54,87-98.
[4]Bian,J.,Cao,C.,Wang,L.,Ye,J.,Zhao,Y.,& Tang,C.(2021). Tor Hidden Services Discovery and Analysis: A Literature Survey. In Journal of Physics:Conference Series (Vol. 1757,No. 1,p. 012162). IOP Publishing.
[5]Li,K.,Liu,P.,Tan,Q.,Shi,J.,Gao,Y.,& Wang, X.(2016, April). Out-of-band discovery and evaluation for tor hidden services. In Proceedings of the 31st Annual ACM Symposium on Applied Computing(pp. 2057-2062).
[6]Guitton,C. .(2013). A review of the available content on tor hidden services:the case against further development. Computers in Human Behavior,29(6),2805-2815.
[7]Owen,G.,& Savage,N.(2016). Empirical analysis of Tor hidden services. IET Information Security,10(3),113-118.
[8]Faizan,M.,& Khan,R. A. .(2020). A Two-Step Dimensionality Reduction Scheme for Dark Web Text Classification. Ambient Communications and Computer Systems.
[9]Spitters,M.,Verbruggen,S.,& Staalduinen,M. V.. (2014).Towards a Comprehensive Insight into the Thematic Organization of the Tor Hidden Services. Intelligence & Security Informatics Conference (pp.220-223). IEEE.
[10]Ghosh,S.,Das,A.,Porras,P.,Yegneswaran,V.,& Gehani,A.(2017,August). Automated Categorization of Onion Sites for Analyzing the DarkWeb Ecosystem. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(pp. 1793-1802). ACM.
[11]García,Salvador,Herrera,& Francisco.(2009). Evolutionary undersampling for classification with imbalanced datasets:proposals and taxonomy. Evolutionary Computation.
[12]Linmei,H.,Yang,T.,Shi,C.,Ji,H.,& Li,X. (2019, November). Heterogeneous graph attention networks for semi-supervised short text classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)(pp. 4823-4832).
[13]Blei,D. M.,Ng,A.,&Jordan,M. I. .(2003). Latent dirichlet allocation. The Journal of Machine Learning Research.
