语音增强与检测的多任务学习方法研究
2021-10-28王师琦曾庆宁熊松龄祁潇潇
王师琦,曾庆宁,龙 超,熊松龄,祁潇潇
桂林电子科技大学 信息与通信学院,广西 桂林 541004
基于深度学习的语音增强通常是从单通道声学信号中提取出特征,利用深度神经网络(Deep Neural Networks,DNN)进行有监督学习,学习出各种嘈杂语音与干净语音之间复杂的非线性关系[1]。其中,具有多个隐藏层的全连接前馈神经网络是应用最广泛的DNN模型之一,文献[2]中,Wang等首次将其引入到语音分离任务中,相较许多单通道的传统方法,基于深度学习的方法在非平稳噪声中的降噪、多说话人的语音分离等方面均有着特殊的优势,但由于其结构比较简单,通常不能很好地挖掘语音中的深度特征。为了弥补这个缺点,文献[3]在输入端从特征工程方向考虑,尝试了多种语音特征,文献[4]通过引入CNN(Convolutional Neural Networks,卷积神经网络),使得模型自身的特征提取能力得到提升。文献[5]将LSTM应用于语音分离,使得模型获得了在长序列上建模的能力,即使在不使用未来帧的情况下也可以取得很好的效果。
VAD是指从声音信号中检测是否存在人类语音的一类任务。其在语音信号处理中被广泛地应用,如语音电话、语音编码、自动语音识别、音频监控、语音增强、说话人验证。经典的VAD算法有:基于阈值决策准则的算法[6]、基于统计模型的算法[7]。近年来,越来越多的研究者开始将深度学习技术应用在VAD任务中,文献[8]提出了一种能充分利用上下文信息的VAD深度学习方法,文献[9]提出了一种VAD与语音增强任务联合训练的模型,凭借有监督深度学习强大的数据驱动能力,它们均取得了很好的效果,但目前,在低信噪比以及不匹配噪声下的VAD仍是一个极具挑战性的任务。
如今,深度学习技术越来越成熟,但目前的各种DNN模型往往复杂度大、参数多,导致其部署难度很大。即使可以通过知识蒸馏的方法减小网络的规模[10],但如果需要在同一个终端上同时实现多个任务就必须同时部署多个模型,还是会对硬件带来巨大压力。语音增强与VAD这两个最重要的前端处理任务具有很强的相关性,它们可以分别看作是在时频域和时域估计语音存在的概率。多任务学习通过共享参数,使其在抽象的层次具有相同的表达,相当于对参数施加了软约束,这意味着任务的泛化能力都将得到改善。同时其通过参数共享的方式,以较少的参数就可以一次性同时完成两个任务。
针对上述问题,提出了一种多任务的在线模型,其贡献主要有以下两点:第一,本文首次尝试在多任务模型中平衡语音增强与VAD两种任务,并验证了其可行性;第二,本文使用LSTM作为模型的主要部分,其本质上是一个因果系统,可以实现逐帧输入的在线处理,两个任务能在同一个模型中并行完成,降低了运算成本,这对于模型的部署具有重要的意义。
1 基于多任务的深度学习
1.1 基于LSTM网络的在线语音信号处理
通常,DNN模型由于没有时序建模的能力,因此需要将语音的上下文特征拼接起来,组成语音的局部作为输入,但这会使得语音预处理的复杂度大大增加,模型只能在延迟多帧的情况下,以缓存器的形式实现在线语音增强[11]。通常,VAD会作为语音信号处理流程中最前端的模块。因此,往往要求VAD算法应具有较低的延迟以及对噪声具有很强的鲁棒性,为了满足这些要求,选择了具有时间序列建模能力的LSTM网络作为本文模型的重要组成部分。
循环神经网络(Recurrent Neural Network,RNN)引入了循环和递归,非常适合处理序列数据。但简单的RNN只具有短期记忆的能力,当训练输入序列较长时,存在梯度爆炸和消失的问题。为了改善这个问题,文献[12]提出了LSTM,这是一种特殊的门控循环神经网络。LSTM网络引入了内部状态c t进行线性的循环信息传递,同时输出信息给隐藏层的外部状态h t,定义公式如下:

其中f t、i t和o t分别为遗忘门、输入门和输出门,用于控制信息的传递,x t和h t-1代表当前输入和上一时刻外部状态,为向量元素乘积,σ表示Logistic函数,tanh代表双曲正切函数,͂是通过非线性函数得到的候选状态,定义公式如下:
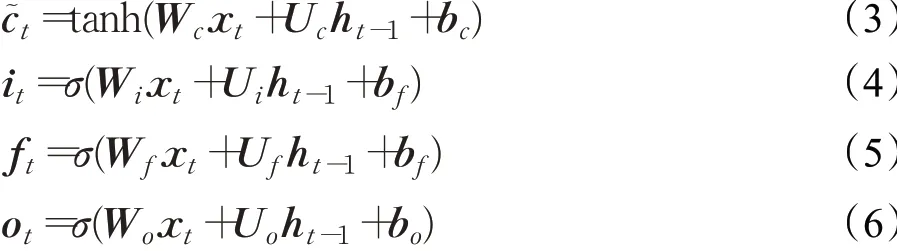
凭借LSTM的时序信息记忆能力,即使逐帧输入特征,也可以获得足够的语音局部信息,这对于需要在线实时运行的场景具有重要的意义。
1.2 基于多任务的语音增强与检测
看似无关的许多任务,由于数据和信息的共享而具有很强的依赖性。多任务学习指的是通过合并几个任务中的样例来提高模型泛化能力的一种机器学习方法[13]。语音增强和VAD任务的相关性意味着它们在某种抽象的层次中必定有很多相似的可共享的部分,基于深度学习的VAD在不匹配噪声下的表现往往不尽如人意,其原因在于普通模型的泛化能力不够,文献[9,14]提出把语音增强加入模型,组成多任务学习模型,迫使模型必须在共享的部分更好地理解语音,从而改善VAD的泛化能力,例如:在较低的信噪比下也能检测出语音的存在、在babble噪声下正确的检测和增强出目标语音而不是背景人声。文献[9,14]的模型均是以VAD作为主任务,语音增强仅仅作为训练时提升VAD泛化能力的辅助,在模型的预测阶段,语音增强的层将会被移除。近年来,深度学习被广泛地应用在语音信号处理的各个任务中,若要在终端同时部署多个大型的深度模型,将对硬件造成很大压力,与文献[9,14]的思路不同,本文将尝试平衡两个任务,以硬共享的模式将其合并在一个模型中,使其能以较少的计算量并行地完成两个任务,对于模型的部署将具有重要的意义。
1.3 模型结构与训练
图1是本文的多任务学习模型结构,该模型采用的是硬共享的参数共享模式[13],通过共享最底层的两个LSTM层,每层具有512个单元,使两个任务能够共同提取一些通用特征。由于两个任务具有强相关性,直接将两个全连接的输出层作为两个任务的私有模块,这样的方式可以很大程度地减少整个网络的参数量。
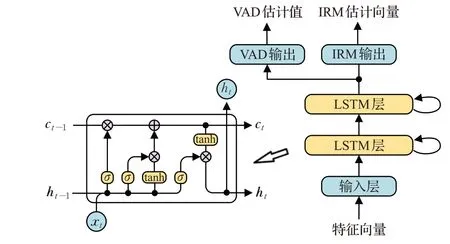
图1 多任务学习模型结构以及LSTM单元内部结构Fig.1 Structure of multi-task learning model and internal structure of LSTM unit
文献[15]详细研究了各种语音增强的训练目标,主要有直接谱映射和时频掩蔽两类。其中,时频掩蔽的概念来自于计算听觉场景分析(Computational Auditory Scene Analysis,CASA),将时频掩蔽加权在嘈杂语音的时频域上,可以很好地分离目标语音和噪声。CASA的主要目标是理想二值掩蔽(Ideal Binary Mask,IBM),它以1和0分别表示时频单元是目标语音还是噪声占主导地位。除了IBM还有很多种时频掩蔽,其中应用最广泛的是理想浮值掩蔽(Ideal Ratio Mask,IRM),它是一个0到1之间的值,表示在每个时频单元中语音所占的比重。本文的系统选用IRM作为训练目标,主要原因有两点:首先,将时频掩蔽作为目标,比直接的谱映射训练方式要更容易训练;其次,使用时频域的IRM作为增强的输出结果,有利于在之后的工作中与很多先进的信号处理方法结合[16]。对于VAD的训练目标,可以将VAD任务当作一个二分类的问题来处理,在语音的时间帧上的标注语音是否存在即可得到训练目标。
由于多层的LSTM本身具有很强的特征提取能力和时序建模能力,因此仅选用当前帧的对数能量谱(Log-Power Spectral,LPS)作为输入特征。LPS仅取对数抑制语音的动态范围,除此之外不对时频域幅度谱做任何的处理,以保留更多的原始信息让模型在训练中自主挖掘。
对于多任务的学习模式,模型的损失函数将会有多个,通过采用超参数α加权求和的形式,可以将损失函数整合并同时优化。LSE代表IRM的损失函数,LVAD代表VAD的损失函数,模型的损失函数LMTL可以定义为:

对于语音增强任务,输出的IRM是一个0到1之间的值,因此,采用了sigmoid函数作为输出层的激活函数,均方误差(Mean-Square Error,MSE)作为损失函数。对于VAD任务,可以将其看作是一个二分类的问题,采用二元交叉熵作为损失函数。两个损失函数定义如下:

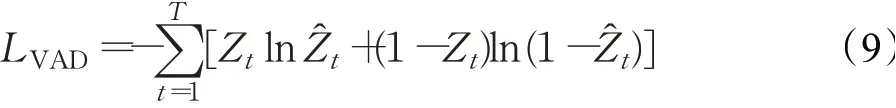
其中,Y t为输出的IRM向量,Z t为VAD输出,和Ẑt代表训练目标,T为帧数,F为频带数,由于本文中没有将时频信号转化到其他变换域,因此F同时也是本文中特征值和输出的维数。
2 实验与结果
2.1 实验配置
本文中的实验数据集均混合自TIMIT数据集[17]。选取的噪声有:NOISEX-92数据集[18]中的factory1噪声、destroyerengine噪声以及DEMAND数据集[19]中PCAFRETER噪声的其中一个通道。将以上三种噪声作为匹配噪声以信噪比-5 dB、0 dB和5 dB与TIMIT中的语音加性混合,得到8 316句的训练集和840句的验证集。混合过程如下:

其中,s、n和x分别代表干净语音信号、原始加性噪声信号和混合信号,I代表波形的采样点个数,SNR为理想的混合信噪比,通过β调整噪声的能量来控制混合信号的信噪比。
选用TIMIT数据集的一个重要原因是,其作为一个主要用于语音识别的数据集,带有音素级别的人工标注信息,本文将音素h#、pau、epi、bcl、dcl、gcl、pcl、tck和kcl视为非语音段,其他音素视为语音段,以此方法生成的VAD标签具有很高的可靠性。
值得注意的是,TIMIT数据集的语音和非语音段占比约为78%,为了使VAD任务的性能评估更加准确,在VAD实验中通常会在数据集的每个句子之间填充随机的零段,使得数据集中的语音和非语言占比调整至相对平衡[10]。然而对于语音增强任务来说,在训练集中出现过多的非语音段将会对模型的训练产生影响,为了评估这一矛盾带来的影响,分别生成了p=60%、p=70%和无填充(p=78%)三组训练集,其中p代表填充过后语音段的占比。三组训练集的时长分别为7.10 h、7.95 h和9.28 h。
选取了NOISEX-92中的babble噪声和factory2噪声作为不匹配噪声,factory1和babble噪声分别与factory2和PCAFETER噪声有相似之处,但却是模型在训练阶段没有见过的噪声,因此可以很好地测试模型的泛化能力。选取TIMIT核心测试集中说话人的200个句子作为本文的测试集,依次以信噪比-5 dB、0 dB和5 dB与匹配噪声和非匹配噪声混合,得到匹配测试集和非匹配测试集。其中,保证训练集中的噪声片段不会出现在验证集和匹配测试集中。
本实验中的所有信号均重采样为16 kHz的采样率,每帧的帧长和帧移分别为512和256个采样点。模型的输入LPS和输出IRM均为每帧257维。本文提出的模型在训练时使用Adam优化器,一次输入200个时间步长,批量大小为128。为平衡两个任务,根据实验中的经验,式(7)中的超参数α确定为0.2。
2.2 评估指标
使用了PESQ和STOI两种指标来评估模型的语音增强效果,它们分别评价的是语音感知的两个主要因素:语音质量和可懂度。短时客观可懂度(Short-Time Objective Intelligibility,STOI)是通过测量干净语音与增强语音之间短时包络的相关性得到的,其值的范围在0到1之间,也通常以百分比表示[20]。语音质量的感知估计(Perceptual Evaluation of Speech Quality,PESQ)应用听觉变换产生响度谱,并比较干净语音和增强语音的响度谱,以产生与预测MOS得分相对应的分数[21],其分数范围在-0.5到4.5之间。
在基于深度学习的VAD任务中,接收者操作特征曲线(Receiver Operating Characteristic,ROC)是一种评价VAD性能的指标,与直接选定阈值得到VAD的准确率不同,ROC通过变化不同的阈值,得到对应的语音检测率(Speech Hit Rate,SHR)和虚警率(False Alarm Rate,FAR),使得VAD的评价更加全面[8-9]。在实际应用中,也有利于根据不同的应用场景,选择更适合的阈值。由于篇幅有限,本文将使用ROC曲线下面积(Area Under ROC Curve,AUC)作为ROC的定量指标。
2.3 基线模型
为了验证本文模型的结果,选择了以下几个具有代表性的单任务模型作为基线:
(1)DNN-SE:由4个全连接隐藏层组成的深度神经网络,每层包含1 024个隐藏单元,这是早期经典的深度学习语音增强(Speech Enhancement,SE)模型[3,15],由于模型本身不传递任何的时间信息,因此每次需要输入当前帧以及相邻2帧一共5帧的特征信息。
(2)LSTM-SE:由两个LSTM层和一个全连接的输出层组成,每个LSTM层具有512个单元,输出是257维的时频掩蔽。由于LSTM属于循环神经网络,具有在时域上建模的能力,所以每次只需要输入一帧的信息即可获得不错的效果[16]。该模型本质上是一个因果系统,因此理论上可以实现逐帧处理的实时语音增强。
(3)Sohn:这是最经典的基于统计模型的VAD算法之一[7],本实验将其语音活动似然比作为输出。
(4)LSTM-VAD:由两个LSTM层和一个全连接的输出层组成,LSTM层分别具有512和256个单元,输出的是1维的VAD信息。和LSTM-SE一样,LSTM-VAD也能以逐帧输入的形式运行。
值得注意的是,这些基线模型的超参数都已分别在本实验的数据集下调至最优。其中,语音增强任务基线将使用非填充数据集训练,VAD任务基线和本文的多任务模型将使用填充数据集训练。由于PESQ和STOI均对填充的非语音段不敏感,因此,所有的模型在测试时都将使用p=60%的填充数据集。
2.4 结果分析
图2显示了本文模型用(p=60%)和VAD基线模型在各种信噪比匹配与不匹配噪声下的AUC比较结果。基于深度学习的LSTM-VAD和本文算法在匹配噪声下,要远好于经典的Sohn方法。在5 dB的噪声下,无论是匹配噪声还是不匹配噪声,两个基于深度学习模型的AUC都可以达到97%以上。但是在不匹配噪声测试中,信噪比的降低将会使基于深度学习的模型性能受到严重影响,但得益于本文中多任务学习的方法给模型带来的泛化能力提升,在低信噪比下,本文模型的AUC均好于LSTM-VAD。如表1所示,在低信噪比的babble噪声下,LSTM-VAD的性能严重下降,这是由于,在0 dB和-5 dB下,目标语音与babble噪声中的背景人声能量相当,甚至更低,因此模型很难分辨出目标语音是否存在。但本文的模型由于加入了语音增强任务的学习,在低信噪比babble噪声下判断目标语音是否存在的能力得到了提升,最终在-5 dB下AUC相较LSTM-VAD提升了7.4%,0 dB下提升了3.7%。

图2 Sohn、LSTM-VAD和本文模型(p=60%)的AUC结果比较Fig.2 Comparison of AUC results of Sohn,LSTM-VAD and proposed model(p=60%)

表1 Sohn、LSTM-VAD和本文模型(p=60%)不匹配噪声下的AUC结果比较Table 1 Comparison of AUC results of Sohn,LSTM-VAD and proposed model(p=60%)under unmatch noise %
图3对比了本文模型(p=60%)与各种基线的语音增强结果,本文模型的增强效果介于LSTM-SE和DNN-SE之间,虽然差距很小,但本文模型的PESQ和STOI始终比LSTM-SE的结果要略差一些,这是因为训练数据集中填充零段使得语音段占比变低最终导致语音增强能力受到损失。为了研究这一问题,使用了p=60%、p=70%和无填充(p=78%)三组训练集训练本文模型,并在p=60%的测试集中测试。值得注意的是,PESQ和STOI对于非语音段的感知较弱,填充的零段对于最终的增强评估结果几乎没有变化,但p=60%可以使得语音和非语言段占比相对平衡,使得AUC的评估结果更加准确,因此,选择了在p=60%中测试所有实验。如图4所示,训练集填充越少,语音的PESQ和STOI的结果就越好,但总体来说变化并不明显。对于VAD任务,训练集填充越多语音占比越平衡,VAD的性能就越好。因此,选择使用p=60%的训练集训练模型,既可以获得不错语音的增强效果,又可以得到最优的VAD效果。

图3 DNN-SE、LSTM-SE与本文模型(p=60%)的PESQ、STOI结果比较Fig.3 Comparison of PESQ and STOI results of DNN-SE,LSTM-SE and proposed model(p=60%)
截取了一段5 dB的PCAFRETER噪声下的嘈杂语音在三种模型下的消噪结果,如图5所示,PCAFRETER噪声中有大量的背景人声,LSTM-SE最终增强的语音质量虽然会略好于本文方法,PESQ和STOI的得分更高,但是其会在非语音段错误残留了一些背景人声,这对于听感或识别会造成一定的影响。本文的方法由于在训练集中填充了零段,并加入了VAD信息的学习,因此,模型能从PCAFRETER中理解背景人声和目标语音的区别,可以从图4中看出,本文方法对非语言段的消噪效果更优,然而这方面的提升在PESQ和STOI中是无法体现的。

图4 不同语音占比训练集对PESQ、STOI和AUC的影响Fig.4 Influenceof different speech proportion training sets on PESQ,STOI and AUC

图5 DNN-SE、LSTM-SE与本文模型(p=60%)的消噪结果对比Fig.5 Comparison of denoising results of DNN-SE,LSTM-SE and proposed model(p=60%)
由于本文的多任务模型与单任务的LSTM-SE和LSTM-VAD都属于可实时运行的在线模型,因此可以通过比较完成两个任务的实时率(Real Time Factor,RTF)来评估系统的效率。两个方法均在Keras-CPU-2.3.1+Tensorflow-2.1.0的环境中运行,终端CPU为Intel i5-4200U 1.60 GHz。如图6所示,本文的多任务模型(p=60%)在语音增强质量非常相近、VAD效果更优的情况下,其速度比串行分别运行两个任务快了44.2%,这对于将深度学习模型部署在更低功耗更低性能的终端设备上将具有重要的意义。

图6 多任务模型与单任务模型的实时率对比Fig.6 Comparison of real time factor between multi-task model and single-task model
3 总结
在本文中,提出了一种多任务的在线实时模型,用于同时处理语音增强和VAD这两项任务。首次尝试在多任务模型中平衡了语音增强与VAD两项任务,使得两项任务都可以作为最终的结果输出,并验证了其有效性。结果表明,相较基线模型,本文模型在语音增强结果非常相近、VAD效果更优的情况下,其速度比串行处理两个任务快了44.2%,这对于将深度学习模型在各种终端上的应用和部署具有重要的意义。在未来的工作中,将尝试通过使用更大的数据集以及改进网络结构,探索在多任务学习中能保证语音增强质量不损失的方法。
