多源异构数据融合驱动的股票指数预测研究
2021-10-28耿立校刘丽莎李恒昱
耿立校,刘丽莎,李恒昱
河北工业大学 经济管理学院,天津 300401
随着信息时代的到来和网络媒体的普及,股票市场预测已经受到学术界各个领域的广泛关注。在金融市场中,根据传统的有效市场假说理论,股票的价格基本反映目前可用的信息,同时指出股票价格总是由理性的投资者驱动,大致反映出公司预期未来收益的合理现值[1]。因此股票价格受新信息的影响很小,遵循随机的变化路径。但是随着信息技术的发展,越来越多的投资者会关注与股票市场相关的信息并不断地做出改变,意见的不一致使得股票实际价格与内在价值产生差异,最终产生价格的波动[2-4]。近年来行为金融学领域的实证研究发现股票走势并不是无迹可寻的,Chan[5]在研究公司新闻发布对股票的影响中发现股票面对公司负面新闻时表现不佳,会出现比较大的波动,而面对好消息时表现出较小的波动。Vega研究了私人信息和公共新闻对股票的影响,实证结果表明,投资者(私人或公众)对资产真实价值的了解越多,对该信息的认同程度越高,交易的异常收益波动越小[6]。虽然传统金融学与行为金融学领域对信息如何影响股票市场的意见不一致,但是也证明了信息对股票市场是存在影响的。
网络媒体的出现,使得信息释放、传播和吸收的方式发生了翻天覆地的变化。现阶段研究中股票市场预测主要是依靠三方面的信息:基本面信息、技术指标信息以及网络媒体信息。基本面信息主要包括公司的总体经营情况、财务报告、管理能力以及宏观经济一些指标信息,Cheung等研究了随时间变化公司规模与股票价格波动之间的关系[7]。技术指标信息主要是包括反应当天的交易情况数据,例如每日的收盘价、最高价和最低价等等。越来越多的研究者使用历史价格来预测未来的趋势,前两种信息是定量信息,获取是相对来说比较容易的。技术的进步使得信息交互的方式发生了变化,由单向传播变成了双向多元传播,人们对股票相关信息的看法和态度拥有更多的表达渠道,社交媒体中用户的广泛参与导致网络媒体信息的重要性越来越大[8]。因此行为金融学与计算机科学领域学科的学者开始探索网络媒体信息对股票的影响,Li等提出了媒体感知量化交易框架,发现公共情绪会因公司的特征对股票走势产生不同的影响[9]。Nguyen等提出一种基于方面的情感分析方法,通过大规模的实验研究了社交媒体对股票走势的影响[10]。网络媒体信息属于定性信息,在研究过程中对于前两类信息来说属于互补信息。股票信息更新快速并且以“前所未有”的速度传播着,对于投资者来说在正式统计报告出来之前获取第一手信息尤为重要[11-13]。
为了研究多种来源信息的共同影响,金融学领域的学者开始应用计量经济学分析模型[14],主要有线性回归、逻辑回归、向量自回归(VAR)以及时间序列模型自回归综合移动平均(ARIMA)。计算机科学领域的研究人员提供了更多可选择的方法,主流的是机器学习的模型[15],可以找出股票走势和信息来源之间的非线性关系,SVM和KNN是最初广泛运用的模型,可以预测未来的股票走势及股票价格。深度学习的方法近年来开始被广泛应用到预测模型中,它可以弥补机器学习中一些缺点,例如可以更好地处理时序化数据,捕获高度的非线性关系[16-17]。
根据以往的研究,越来越多的数据源被运用到股票预测中,但对于股票话题数据情感的分析大多集中在情感词典以及词袋方法上,较少地运用深度学习的算法;因此本文的投资者情绪将采用卷积神经网络(Convolutional Neural Networks,CNN)模型,捕获更深层次的情感特征。
为了更准确地预测股票市场的变化,在此基础上引入深度学习中的长短期记忆网络(Long Short-Term Memory Network,LSTM)构建股指涨跌预测模型,旨在将股票交易数据、技术指标以及投资者情绪三种源数据结合起来,探究其对股票指数趋势的共同影响。通过LSTM和其他基线方法的比较,验证多种数据源以及深度学习模型的有效性。
1 基于卷积神经网络的情感分析模型
1.1 卷积神经网络原理
卷积神经网络(CNN)属于监督学习中的深度学习算法,实验之前需要对数据进行标注,通过对打标数据构建语料库,深度学习文本中的复杂特征,同时考虑语义之间的联系。
假设需要对一些句子进行分类,句子中每个词是由n维词向量组成的,也就是说输入矩阵大小为m×n,其中m为句子长度。模型需要对输入样本进行卷积操作,对于文本数据,卷积核采用向下移动的方式,提取词与词间的局部相关性,最终得到多个卷积后的向量。然后对每一个向量进行最大化池化操作并拼接各个池化值,最终得到这个句子的特征表示,将这个句子向量输入到分类器中进行分类,至此完成整个流程。CNN情感分析模型结构设计如图1所示。

图1 CNN情感分析模型结构图Fig.1 Structural figure of CNN emotion analysis model
以下具体介绍每一层的具体工作原理。
(1)嵌入层(Embedding Layer):通过将股吧评论进行过滤和分词操作后,句子表示为多个词语的集合,因此需要将每个句子的长度对齐统一嵌入层的维度;在此之后通过word2vec训练进行词向量的表示,将编码后的句子作为输入层。
(2)卷积层(Convolution Layer):卷积层的作用是通过不同的卷积核从嵌入向量中提取多维的特征,在text-CNN中,卷积核的宽度的取值为3、4、5,每个尺寸卷积核的数量为256;可以通过卷积层从不同的角度分析句子,考虑了语义之间的关系,以获取更全面更深层次的特征表达。在卷积层后加一个激活函数,用于生成每个尺寸卷积核的特征遍历。
(3)池化层(Pooling Layer):池化层中采用最大池化的方法,即抽取每个特征向量的最大值表示最重要的特征。当对所有卷积层生成的特征向量进行池化之后,还需要将每个特征值给拼接起来,合成一个长形特征向量。在池化层到全连接层之前可以加上dropout防止过拟合。
(4)全连接层(Fully connected layer):全连接层使用SoftMax激活函数可得到属于每个类的概率,根据概率计算出情感值以及每日的消极与积极的分数。在模型的评估方面,在分类问题中损失值常采用交叉熵损失函数,除此之外,精准率、召回率以及F1值也是本实验中的主要评价指标。
1.2 情感分析流程
在情感分析的过程中,将获取到的社交媒体文本进行划分,在原则上选取全部数据集的一部分进行打标,为后续的模型训练做准备。总体的情感分析流程如图2所示。

图2 CNN情感分析流程图Fig.2 CNN flow chart of emotion analysis
具体步骤如下:
(1)标注数据:由于CNN是一种监督学习算法,因此需要对数据集进行标注,本文采取交叉打标的方法,确保数据标注的质量;其中积极和中性的文本标注为1,消极的文本标注为0;打标的数据集参与模型的训练过程,而另外一部分则为实例数据集。
(2)划分训练集与测试集:将标注好的数据集进行训练集和测试集的划分,并且分别将积极和消极的数据区分开来,按照命名规范统一存储到一个文件夹内。
(3)数据预处理:主要包含数据清洗,将不符合规范或空值的文本信息进行处理,根据去停用词的列表将无意义字符与标点符号去除,之后使用jieba分词对每条文本进行分词,为后续的词向量转换做准备。
(4)生成词向量:首先根据分词结果统计训练集中所有的词汇,生成vocab.txt,根据词汇来构建索引,并将每个单词映射到0~M间的整数(M为词汇大小),将每个句子都成为整数向量,生成vec.txt。
(5)模型训练:首先定义模型训练前的一些参数,包含句子长度(统一后)、输出层的类别数(本文是两类:积极和消极)、嵌入维度、滤波器的数量等等,定义之后梳理输入层、卷积层、池化层以及输出层的代码,细节如上一节中的模型设计。根据定义好的模型进行结果以及评估指标的输出,根据验证集的结果来保存最优的参数。
(6)模型复用及测试:将测试集通过相同的数据预处理方式得到词向量,根据训练过程中保存的参数,进行模型的加载与复用,最终对得到的结果进行评估,结果可以再次优化,重新训练,直到最终的效果最优。
以上为CNN情感分析的流程,后续通过测试集得到最优的结果之后可将其用于实例数据的情感极性结果的输出,作为投资者情绪来源。本文设定了两个参数,作为投资者情绪的量化指标,在情感分析的研究中,如需给文本的情感赋值为积极与消极,大多是采用1和0的方式;本文的情感分析模型是卷积神经网络(CNN),是一个二分类模型,因此本文将积极情感赋值为1,消极情感赋值为0,这样就可以得出定正向和负向的数量。首先需要统计当日积极和消极的条数来去确定当日股吧帖子条数,以一天为一个单位为当日内情感极性为积极的帖子数量,为当日内情感极性为消极的帖子数量,numt为t天的股吧论坛帖子数量,见公式(1);另外本文将非交易日周六和周日的帖子数量总和放在周五,共同影响周一的股票市场。

投资者情绪参数是通过对每一条文本信息输出情感极性之后,将根据对数平均值的方法来量化当日股民的情绪值。由于规定积极的情感值输出为1,消极的为0,最终是以对数函数为基础来定义,可以得出持有某种倾向的投资者数量的多少,为senti t,计算方法见公式(2)。情感指标值越大,说明偏向于积极情感的投资者数量越多。

2 基于LSTM的股票涨跌预测
2.1 长短期神经网络(LSTM)原理
长短记忆神经网络(通常称作LSTM),是一种特殊的RNN,能够学习更长的依赖关系。LSTM由Hochreiter和Schmidhuber[18]引入,并被许多人进行了改进和普及,现在被广泛使用。
LSTM是一种特殊的递归神经网络,解决了RNN长期依赖中梯度消失和梯度爆炸的弊端,在时间序列数据的预测方面具有优势。LSTM的内部空间的单元结构如图3所示。

图3 LSTM模型单元结构图Fig.3 LSTM model unit structure diagram
模型中相较于RNN添加了输入门、遗忘门和输出门三种记忆细胞的状态,其中模型输入的参数是h t-1和x t,分别代表上一个的隐藏层输出状态和t时刻的变量值,通过对输入的参数对无用信息进行处理,而同时更加注重有用信息,达到遗忘门的作用,给出式(3),参数为左侧第一列中遗忘门的权重矩阵(w)与偏置项(b),同理,第二三列为输入门,计算方法为式(4)和式(5),第四列的式(6)为输出门以及单元状态的权重矩阵与偏置项:
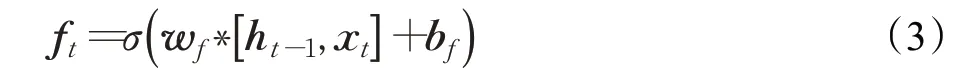

步骤中的σ为sigmoid函数,tanh为正切函数,上述步骤计算完成之后,式(7)计算了t时刻的输出状态C t,是使用遗忘门和输入门的参数f t、i t和C′t;最终在输出门状态下,式(8)使用正切函数计算t时刻的隐藏层输出。

至此,一个LSTM层的计算完成,t时刻的输出将被传递到下一个时刻进行计算。
2.2 融合投资者情绪的股票涨跌预测
在本研究中,本文的预测模型的功能是捕获多个信息来源与未来股价走势之间的关系。本节将从股票市场的特点以及影响其变化的主要因素出发,借助网络媒体平台,将股票交易数据、技术指标以及投资者情绪特征整合起来,通过深度学习的方法构建股票趋势预测模型,探索它们对股票走势的综合影响。其中论坛文本数据采用卷积神经网络的方法进行投资者情绪的挖掘,整合多维特征数据,输入LSTM模型进行预测,最终输出分类结果。后续将在此基础上,选取4个在股票预测研究中常见的方法作为基线方法,与主体方法进行对比实验。
将特征数据进行预处理之后输入LSTM模型进行预测,最终输出分类结果。整体预测框架图如图4所示。

图4 融合投资者情绪的股票预测框架图Fig.4 Block diagram of stock forecast incorporating investor sentiment
本文的主题是股票市场的涨跌预测,由于是时间序列预测,因此要考虑时间步长,不同的步长效果会有所不同;在预测模型的输入中,可以从图5流程图中看出,左侧是输入前t天的股票特征数据,其中包括股票每日交易数据、技术指标以及投资者情绪,而右侧则是输出下一个交易的股票趋势,分为上涨和下跌。

图5 股票涨跌模型预测流程图Fig.5 Stock rise and fall model prediction flow char
模型训练的过程中,采取交叉验证的方法,以此来减小损失,损失计算选择均方误差作为损失函数,利用随机梯度下降的方法更新权重。模型评估则是通过计算真实值和预测值的误差来进行比较,最后在验证集中验证模型的准确率,选取最优的模型进行测试集结果的输出。
3 实验结果与分析
3.1 样本选取与实验设置
交易数据以及技术指标数据:本文选择上海股票主板市场的代表“上证50指数”(上海证券市场最具影响力的一批优质大盘企业)作为研究对象。时间跨度为2017-03-20至2020-03-20。在选择时,选取接口中的开盘价、收盘价、最高价、最低价、涨跌额、涨跌幅、成交量以及成交额是最重要的变量,这应该是投资者主要关注的因素;除以上变量外,还手动构建了5和10日的移动平均线(MA)、指数移动平均线(EMA)、变动率指标(ROC)、相对强弱指数(RSI)、能量潮(OBV)技术指标等量化数据。
社交媒体文本数据:根据股票指数数据,从东方财富平台的股吧论坛(http://guba.eastmoney.com)获取社交媒体话题数据,这一时间段的选取为2017年03月20日—2020年03月20日。为了自动化抓取网络媒体中的评论数据,本文在PyCharm平台基于Python编写爬虫程序。网络爬虫主要收集了包括浦发银行(600000)、上海机场(600009)、民生银行(600016)、中国石化(600028)、中信证券(600030)、三一重工(600031)等50只包含在“上证50指数”中股票的股吧评论,主要用于股票论坛语料库的构建,一共爬取到约240万条评论。
3.2 模型验证与对比
3.2.1 数据预处理
(1)文本预处理
文本数据预处理包括查看重复评论数据、去除评论中出现的数字和英文字符、分词、去除停用词及词性标注。数据清洗:首先对爬取到的文本进行清洗,删除内容或者时间缺失与异常的评论,通过对应去停用词将评论中的标点符号以及无意义词清洗掉。中文分词与去停用词:使用python的jieba分词器完成分词工作,并使用哈工大停用词表,在分词过程中直接去除停用词;与此同时,进行词性标注。词向量生成:通过word2vec训练出评论的词向量,并统一词序列的长度,作为模型的输入。数据对应关系:当天15点之前的评论数据影响当天的股票走势,15点之后的影响下一天的股票走势。
(2)标准化处理
由于每个特征属于不同量纲,因此需要对数据进行标准化,使用的是Z-score方法,进行特征缩放,保证处理后的数据符合正态分布。计算方法如式(9):

其中,μ为样本均值,σ为样本标准差,x为样本数据本身。
将整体的数据集按照8∶2的比例划分训练集与测试集,再从训练集中挑选10%的数据作为验证集。在训练过程中,采取每次40条交易数据的批量,总迭代次数为500次,时间窗的跨度为5~14天,选择不同的时间窗做对比实验。
3.2.2 模型验证及结果分析
根据设置好的具体参数,将数据输入LSTM涨跌预测模型进行结果的输出。在此基础上,实验选取机器学习中分类预测表现比较出色的随机森林(RF),K最近邻(KNN),朴素贝叶斯(NB)以及支持向量机(SVM)这四种基线方法进行对比,通过改变时间窗的大小,分别研究方法以及时间窗对预测模型的影响。
首先是针对本文所提出的模型的分析,LSTM模型的预测效果如图6所示,图中为测试集的146条数据的预测结果,可以看出股票涨跌的趋势基本是一致,当股价变化比较小时,预测得比较准确,但是在100~140这个区间可以看出当股价变化较大的时候,真实值与预测值之间的误差变大,准确率会有所下降。一个方面是因为在这段期间,“上证50指数”每日的收盘价、开盘价等交易数据变化较大,导致以此为基础构建的技术指标的变化也相对较大,多个指标的不确定性增加,因此导致了预测的偏差较大;另外一个方面是由于当时的大环境处于新冠肺炎疫情期间,大多数股民的情感偏向与消极,因此情感指标的不确定性再次导致预测的误差偏大。虽然指标的不确定性导致预测值与真实值的偏差较大,但是总体看来,模型在此期间的涨跌趋势预测是准确的,具有一定的指导意义。

图6 模型预测结果Fig.6 Model prediction results
其次是与基线方法的比较,图7为五种方法的预测准确率对比图。从图中可以看出,根据不同方法的对比,虽然随着时间窗的增加,LSTM模型从整体上看准确率基本高于其他方法,呈上升的趋势,但是增长幅度比较小,说明了在LSTM模型中交易信息的长期与短期数据对股市的影响基本没有太大变化。
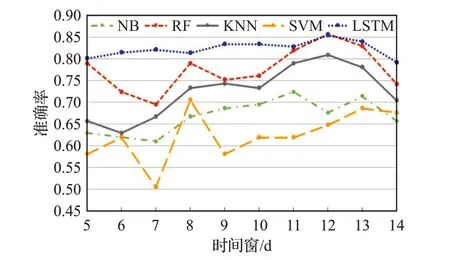
图7 预测模型准确率对比图Fig.7 Comparison of prediction model accuracy
从图7中可以看出,随着时间窗的增加,基线方法的准确率呈逐步增长的迹象,说明了时间窗越大,模型学习到的信息越多,预测效果越好;但是从12天到14天的变化中可以看出,大部分算法的准确率呈下降趋势,说明时间窗的设置并不是越长越好。
从总体上可以看出,在预测下一个交易日的涨跌方面,LSTM方法的准确率在这几种方法中表现最好,并且时间窗在一定范围内的改变下,准确率的波动比较小,整体上都高于其他的基线方法,表现出了其在处理时间序列数据的优越性;在基线方法中,SVM方法的准确率在5~9天的范围内随时间窗变化的波动变化比较大,之后呈现上升的趋势;其中随机森林(RF)的表现最好,其次是KNN、NB、SVM方法。
上面的实验基本验证了模型的有效性,接下来在模型的输入变量上,本文寻求了更多的可能性。通过手动构造技术指标以及投资者情绪来衡量其对股票市场的影响,对实验做进一步的改进,形成更加多样的对比实验,从而使本文的结论更加丰富。
3.3 对比实验一:添加技术指标
上述实验中,本文考虑了接口中固定的几个指标,因此在特征工程方面,尝试构造更多的技术指标来探究对股票市场的影响;技术指标都是由交易数据计算得出的,本文在技术指标的选取一方面是考虑到中国股市的交易周期是一周五天,构建了5日和10日的移动平均线(MA),另外由于涨跌预测是一个趋势预测,为了更好地观察股票价格的变化,还构建了指数移动平均线(EMA)、RSI指标(相对强弱指数:某一个期间内股价上涨总幅度占股价变化总幅度平均值的百分比),另外就是能量潮OBV(统计成交量变化的趋势)和ROC(变动率)这几个指标,旨在通过添加特征来提高准确率。在本次实验中,选取时间窗中的第11天(该参数下各个算法的准确率比较稳定),调整不同的算法进行对比实验,实验结果如表1所示。

表1 添加技术指标后的准确率Table 1 Accuracy after adding technical indicators
从表中可以看出,添加技术指标之后,各个算法的准确率都有不同程度的增加,股票市场预测模型的预测效果有所提升,说明本文构造的技术指标对于股票市场也是有一定影响的。
后期通过PCA方法对添加的技术指标进行指标排序,排名靠前的是涨跌点、成交额、指数移动平均线、变动率,说明这些特征对股市的影响更加突出。
3.4 对比实验二:添加投资者情绪
通过训练CNN情感分类模型,对上证50中的50支股票约240万条评论进行情感值的输出。由并将每日的15点作为节点,按照日期汇总每日情感值;由于非交易日也有部分评论,考虑到周六周日的评论会影响周一的股票市场,故将其归结到周五的评论中,共同影响周一的股市。最终结果的输出为看涨与看跌,对应股民积极和消极的情感倾向。实验最后输出第一个情绪特征(蓝线)与收盘价(红线)进行Z-score标准化之后基本变化如图8所示。

图8 每日收盘价与每日情绪趋势Fig.8 Daily closing price and daily mood trend
从图中可以看出,相对于股价的变化来说,股民每日的情感值变化波动较大,间接说明了股价牵动着万千股民的心。
整个时间的跨度为2017-03-20到2020-03-20,从整体上观察可以看出在2017年到2018年6月份之间和2019年到2020年3月份之间两个特征的趋势基本一致,股价上涨,股民的情感呈现上升的趋势,上升的程度较小;但是股价一旦下跌,股民的情感会很敏感,负向情感比较明显,与前一天产生比较大的落差,联想实际可以看出股民对于股价下跌的接受程度比较小。比较反常的是2018年6月份到2019年初,这段期间股价在3年之内属于最低的一部分,股民情绪前后落差较大,但是股民的情感在股价下跌的过程中整体呈现上升的趋势,预估是股民们觉得股价应该不会跌到如此程度,抱着看涨的心态,但是好景不长上升一段时间后开始急速下降,之后股价的一点点上升都会引起情感值大幅度的上升,间接体现了当股市处于低迷时,股民的情绪比平常更加不稳定。
通过将每日的两个情感特征输入到前一个阶段的股票预测模型中,实验结果如图9所示:绿色线为添加投资者情绪之后的准确率结果。可以从图中看出:添加投资者情绪之后,各个算法准确率都增加了。
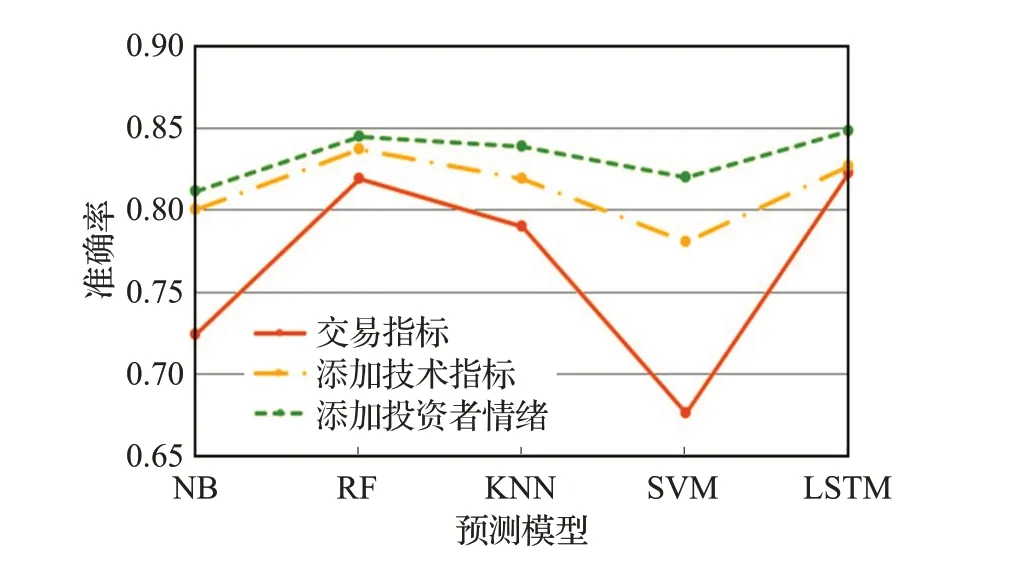
图9 添加投资者情绪后的准确率Fig.9 Accuracy of adding investor sentiment
实验结果显示上文中通过CNN情感分析得到的股民情绪虽然起伏比较大,但是一定程度上反映在了股票市场的决策方面,投资者情绪变量对预测股票市场涨跌有一定的作用,验证了本文的研究目的,可以在一定程度上辅助相关利益者及时做出决策。
4 结束语
本文首先提出了卷积神经网络模型,提取深度情感特征,构建了股票市场中的投资者情绪特征;引入深度学习中的LSTM,建立了一种股票指数涨跌预测模型,定量研究了交易数据、技术指标以及投资者情绪三种源数据对股票市场涨跌的影响。通过对上证50指数近三年数据的实证研究,与单一数据源和基线方法相比,融合投资者情绪的LSTM模型预测效果更佳,拟合程度更高;证明股票市场对于公众的情绪是相对敏感的,模型可以为相关利益者辅助决策。目前存在的问题是未考虑投资者的社交关系,后期可以考虑增加社交节点权重来丰富模型的输入,进而提升模型的性能。
