面向遥感图像小目标检测的改进YOLOv3算法
2021-10-28王建军梅少辉
王建军,魏 江,梅少辉,王 健,2
1.西北工业大学 电子信息学院,西安 710129
2.西北工业大学 第365研究所,西安 710129
目标检测是一种为检测特定对象(汽车、建筑物和人类等)而提出的计算机视觉技术,广泛应用于机器人导航、智能监控、工业检测、航空航天等诸多领域。近年来,随着深度学习理论的成熟,基于深度学习的目标检测算法得到了快速发展,目前大多数目标检测算法都采用卷积神经网络(Convolutional Neural Networks,CNN)作为特征提取器,例如AlexNet[1]。基于CNN的目标检测算法通常可以分为两大类:一类是单阶段目标检测算法,这类算法不需要生成候选区域,直接在网络中提取特征来预测目标的类别和位置,再经过检测器得到检测结果,典型的代表算法有YOLO[2-5]、SSD[6]、Retina-Net[7]等;另一类是双阶段目标检测算法,这类算法首先产生候选区域,然后对候选区域进行分类,代表算法有R-CNN[8]、Fast R-CNN[9]、Faster R-CNN[10]、Mask R-CNN[11]等。
遥感图像通常由航空航天平台获取,其中感兴趣的目标相对背景而言比较小,这些小目标的检测是富有挑战的研究方向。大部分目标检测算法虽然在通用目标检测中有较高的精度和泛化性能,但是在遥感图像小目标检测中精度仍然较低。小目标的定义方式有两种,一种是相对尺寸的定义,若目标尺寸是原图像尺寸的十分之一,即可认为是小目标;另外一种是绝对尺寸的定义,即尺寸小于32×32像素的目标即可认为是小目标。Lin等人[12]提出的FPN(Feature Pyramid Networks)首先将小尺度特征图上采样,然后与大尺度特征图进行融合,最后再进行预测,使小目标检测的精度提升显著;Li等人[13]提出的感知生成对抗网络(Perceptual Generative Adversarial Network,Perceptual GAN)算法通过降低小目标和大目标之间的表示差距来提升小目标检测的精度;Kisantal等人[14]将包含小目标的样本进行过采样,使小目标的检测精度有较大提升;Liu等人[15]提出了RFB(Receptive Field Block)结构,通过引入空洞卷积[16],增大感受野,进而提高小目标的检测精度。
YOLOv3[4]借鉴了FPN的思想,通过特征融合,既保证了大目标的检测精度,又提高了小目标的检测精度。本文基于YOLOv3提出了一种改进的目标检测算法——YOLOv3-CS,首先根据不同尺度特征在网络中的重要程度来修改backbone结构,然后引入RFB结构增大浅层特征图的感受野,最后对anchor boxes重新分配。在数据集RSOD上的验证结果表明本文提出的算法在遥感图像小目标检测方面有较高的优势。
1 YOLOv3目标检测模型
图1为YOLOv3结构图,YOLOv3比YOLOv2[3]在精度方面有大幅度提升的一个主要原因是采用Darknet-53作为backbone。backbone包含1个输入层,5个下采样层和23个残差结构(Residual block),全部由卷积层构成,使用1×1和3×3两种尺度的卷积核。YOLOv3中每一个卷积层之后都含有一个BN层,对卷积层的输出进行归一化,再输入到激活层,激活函数采用Leaky ReLU,即构成backbone的最小组件DBL(Conv+BN+Leaky ReLU)。Darknet-53是基于ResNet[17]的思想提出的,在卷积层之间设置了快捷链路层(shortcut),防止由于网络过深导致的性能“退化”,相比于ResNet-101和ResNet-152,Top-1精度与ResNet-101相当,Top-5精度与ResNet-152相当,但速度比ResNet-152提高了2倍以上。

图1 YOLOv3结构图Fig.1 Structure of YOLOv3
YOLOv3对输入图片进行“端到端”预测。一幅输入图像(缩放到416×416)经过YOLOv3的backbone后输出三个不同尺度的特征(13×13、26×26和52×52),分别针对大、中、小三类目标进行预测,每个尺度对应一个三维张量,如图2所示。以13×13特征图为例,输入图像被划分为13×13的Grid Cell,则输出张量的维度为13×13×(k×(4+1+class)),每个Grid Cell对应一个三维张量中的一个子张量1×1×(k×(4+1+class)),其中k(默认为3)表示Bounding boxes数量,由anchor boxes对应得来,4表示每个Bounding box对应四个坐标预测,1表示每个Bounding box有一个置信度预测,class表示类别预测。如果一幅图像的目标对应Bounding Box的中心恰好落在了某个Grid Cell(图2红色Grid Cell)中,那么这个Grid Cell就负责预测该目标的Bounding Box,并将它的置信度设为1,其余Grid Cell的置信度则为0。
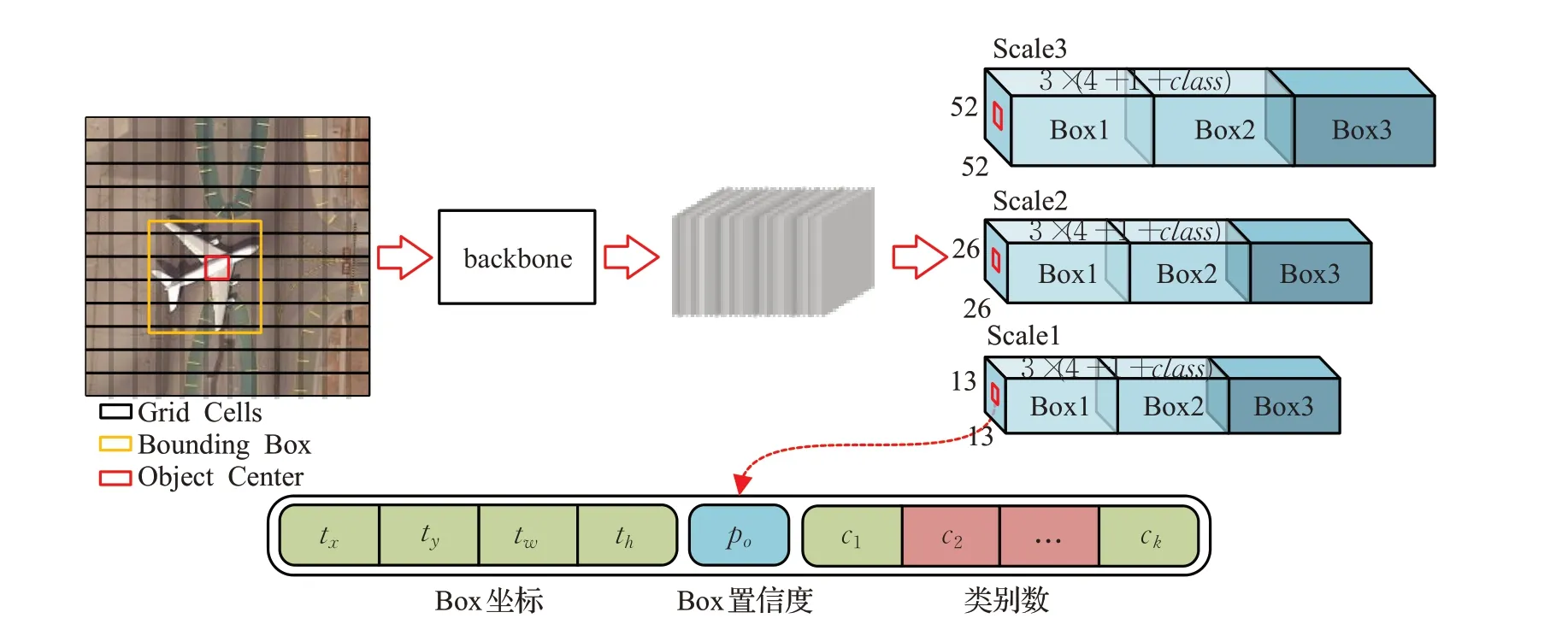
图2 YOLOv3检测流程Fig.2 Detection flow chart of YOLOv3
YOLOv3设定每个Grid Cell会预测3个Bounding Boxes。Grid Cell会选择与Bounding Box的IoU最高的anchor box进行微调作为网络的输出预测框。每个Bounding Box有5个预测参数(t x、t y、t w、t h、confidence)和class个类别概率。YOLOv3输出的Bounding Box坐标实际为偏移量,需要对其进行修正,图3为坐标偏移示意图。图中t x、t y表示预测框的左上角坐标,t w、t h表示预测框的宽度和高度,如果预测框中心点所处Grid Cell的左上角坐标为c x、c y,且anchor box的宽和高分别为pw和p h,则修正后的边框为:

图3 坐标偏移示意图Fig.3 Diagram of coordinate offset

b x和b y表示预测框的中心坐标,b w和b h表示预测框的宽和高,δ代表sigmoid函数,目的是将预测偏移量缩放到0和1之间。
2 改进的YOLOv3模型
YOLOv3虽然通过特征融合输出三个尺度的特征图,兼顾了小目标预测,但是对于以小目标检测为主的遥感目标检测任务,YOLOv3的检测精度仍然有待提升。本文首先根据对backbone中不同尺度特征重要性的分析,对backbone进行重构,其次引入RFB结构来增大浅层特征的感受野,最后优化了anchor boxes并改进其分配原则。
2.1 特征重要性分析
对于特定的数据集,backbone中五种尺度特征的重要性通常不同,本文在分析每种尺度特征重要性的基础上,对网络结构进行重构。
文献[18]证明了网络中某层的所有滤波器中,位于或靠近几何中位数(Geometric Median,GM)的滤波器对网络的贡献较小,可以用其他滤波器来代替。假设网络有L层,N i和N i+1分别表示第i层卷积层的输入通道和输出通道数,Fi,j∈ℝN i×K×K表示第i层卷积层的第j个滤波器,K为卷积核尺寸,则第i层滤波器的几何中位数定义为:

那么第i层接近几何中位数的滤波器可以表示为:

几何中位数是欧氏空间数据中心的一个估计量,如果某个滤波器接近几何中位数xGM,可以认为这个滤波器和其他滤波器共享信息,该滤波器可以被其他滤波器替代,因此去掉该滤波器不会对网络的输出产生影响。在训练过程中,直接将接近几何中位数的滤波器置零,即稀疏训练。滤波器置零后对应的输出特征图为无效特征图,对网络的输出不再起作用。
本文首先在遥感数据集上对YOLOv3进行流程如图4所示的稀疏训练,再统计不同尺度特征图中无效特征图的比例,最后调整不同尺度特征的深度来改善网络性能,调整原则为:如果一种尺度的特征图中无效特征图的比例较高,则降低该尺度特征对应卷积层的深度,反之则增加该尺度特征对应卷积层的深度。
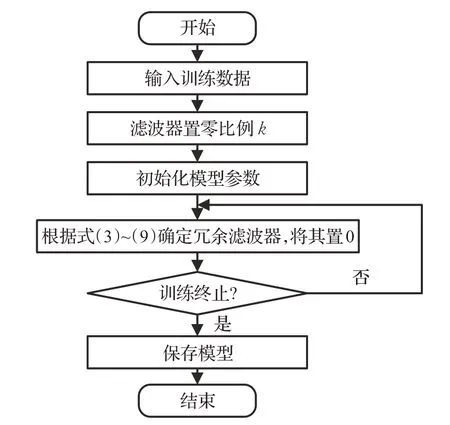
图4 稀疏训练流程Fig.4 Sparse training flowchart
2.2 RFB模块
在YOLOv3的三个检测头中,检测头2和检测头3分别融合了26×26和52×52的特征,进行中等尺寸和较小尺寸目标的预测。虽然浅层特征的细节信息比较丰富,对检测遥感图像小目标有很大的帮助,但是特征图的感受野较小,缺少上下文信息。本文为了增大特征图的感受野,在YOLOv3中引入了RFB。
RFB利用拥有不同尺寸卷积核的卷积层构成多分支结构,再引入空洞卷积增加感受野,提高了小目标检测精度。与Inception[19]结构类似,RFB的每个分支上使用不同尺度的常规卷积和空洞卷积的组合。不同尺度的常规卷积用来模拟群体感受野(population RF,pRF)中的不同感受野,空洞卷积所得到的离心率来模拟pRF的尺度与离心率的比例,最后将三个通道连接以减少特征的通道数。RFB度量了感受野的尺度、离心率间的关系,可以生成更有判别性、更具鲁棒性的特征。
图5为RFB的一种结构,首先通过1×1、3×3和5×5卷积核构成三分支结构,并在每一个分支中分别引入dilation rate=1、dilation rate=2和dilation rate=3的空洞卷积增大感受野,最后将三个分支的输出连接在一起,达到融合不同特征的目的。
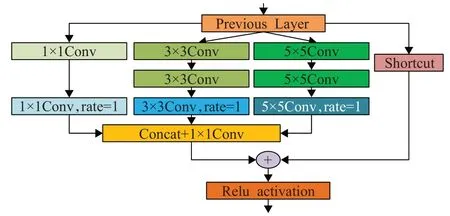
图5 RFB结构图Fig.5 Structure diagram of RFB
2.3 优化anchor
YOLOv3使用K-means算法对COCO数据集的标注框聚类得到9个anchor boxes,每个检测层分配3个anchor boxes。不同的数据集有不同的anchor boxes分布,anchor boxes的选择会直接影响网络的预测精度,在YOLOv3中9个anchor boxes平均分配在三个检测头上,但是不同尺寸的特征对不同的anchor box有不同的敏感程度,因此需要对不同尺寸的特征匹配对应的anchor boxes。文献[20]对数据集进行聚类,但是没有考虑anchor boxes分配问题,本文首先计算三种尺度特征图对应的anchor box尺寸范围[21],然后对数据集重新聚类,进行不同尺度特征上anchor boxes的分配。
图6为anchor box、Grid Cell和预测框的位置关系图,金色框表示anchor box,黑色框表示目标的标注框,红色框为Grid Cell。为了方便计算,假设anchor box和标注框均为正方形并且anchor box比标注框大,anchor box边长为a,标注框边长为g,Grid Cell边长为2s,s为下采样倍数。

图6 anchor box、Grid Cell和预测框位置关系图Fig.6 Structure diagram of anchor box,Grid Cell and prediction box location
下面分两种情况讨论:
(1)当标注框在anchor box内部时,IoU可以定义为:

当IoU≥0.5时,可得:

(2)当anchor box的中心在特征图Grid Cell的左上角,真实框的中心在Grid Cell的右下角,并且anchor box和标注框边长的二分之一大于Grid Cell的边长时,即,IoU定义为:
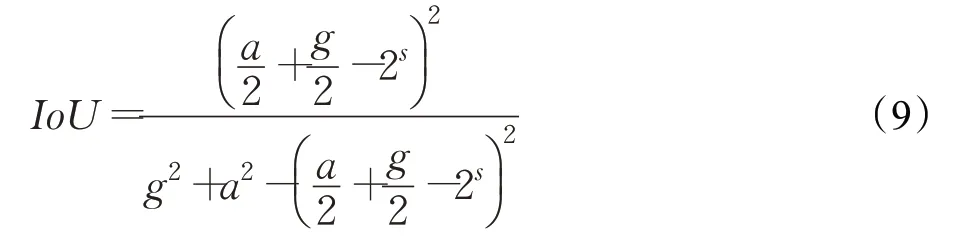
令a=g,可得:

当IoU≥0.5时,可以得到s和a的关系:

根据式(1),可以知道anchor boxes的尺寸和下采样倍数的关系如表1所示。实际的标注框不一定是正方形,因此通过K-means算法聚类得到的anchor boxes也不一定是正方形,这里通过面积做近似。假设一个anchor box的宽为w,高为h,则面积为w×h,即可用来近似a。

表1 下采样数与anchor boxes尺寸之间的关系Table 1 Relationship between down sampling number and anchor boxes size
3 实验
3.1 实验数据
本文实验在遥感图像数据集RSOD上测试。RSOD数据集由武汉大学于2015年发布,用于遥感图像目标检测。数据集包含从谷歌Earth和Tianditu下载的976张图像,图像的空间分辨率在0.3 m到3 m之间,其中包含飞机(aircraft)、油桶(oiltank)、立交桥(overpass)和操场(playground)四类目标。图7为样例图片。

图7 RSOD数据集样例Fig.7 Sample image of RSOD dataset
遥感图像中大多是小目标,这就导致目标信息量小,难以检测。由于YOLOv3的输入为416×416,因此本文首先将图片缩放到416×416,然后对目标的大小做了统计。图8为四类目标的标注框占原图像尺寸的比例分布图,可以看出,aircraft和oiltank类别中基本为小目标,并且分布集中。overpass类别中包含少量的小目标,playground类别中目标分布较为分散,总之数据集中大部分目标为小目标(目标的尺寸是原图的十分之一)。
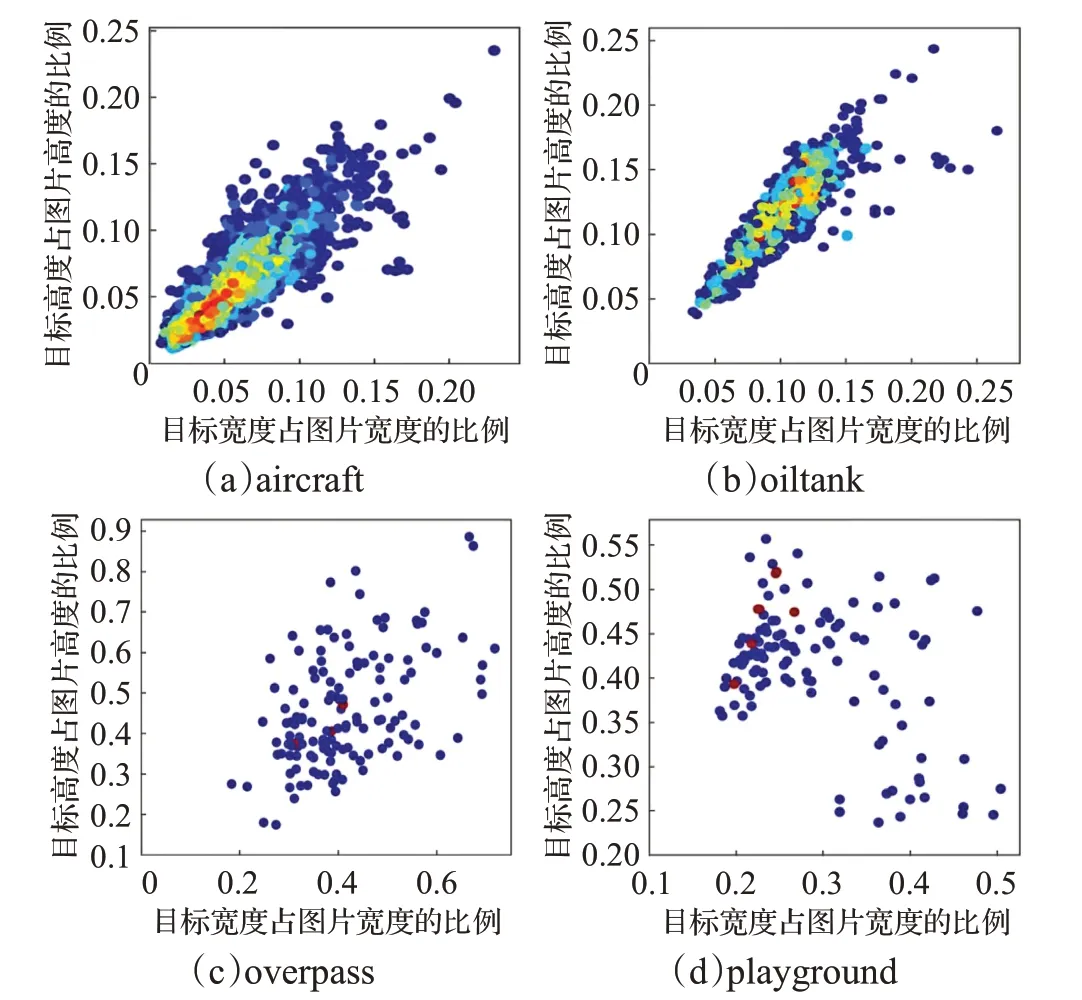
图8 RSOD数据集标注框占原图像尺寸的比例分布Fig.8 Proportion of labeled box to original image size in RSOD dataset
3.2 目标检测算法评价指标
目标检测的效果由预测框的分类精度和定位精度共同决定,因此目标检测问题既是分类问题,又是回归问题。目标检测算法的综合评价指标通常有平均精确率和F1分数。
(1)平均精确率(Average Precision,AP)
AP被定义为PR曲线下的面积,用来衡量数据集中一类的平均分类精确率,计算公式如下:
6.预防措施:正确使用安全套,采取安全的性行为;不吸毒,不共用针具;推行无偿献血,对献血人群进行HIV筛查;加强医院管理,严格执行消毒制度,控制医院交叉感染;预防职业暴露与感染;控制母婴传播;对HIV/AIDS患者的配偶和性伴、与HIV/AIDS患者共用注射器的静脉药物依赖者,以及HIV/AIDS患者所生的子女,进行医学检查和HIV检测,为其提供相应的咨询服务。

但是对于多分类问题,需要对N个类别的AP求均值,即平均精确率均值(mean Average Precision,mAP),用来衡量分类器对所有类别的分类精度,也是目标检测算法最重要的指标,计算公式如下:

(2)F1分数(F1 Score,F1)
仅使用P和R两个指标不能很好地评价模型的综合性能,因此通过F1分数来评价模型的综合性能,计算公式如下:

3.3 实验结果与分析
本文实验在Ubuntu16.04操作系统下进行,模型搭建采用PyTorch深度学习框架,CPU为i7-6850K,内存为64 GB,GPU为NVIDIA GTX1080。在模型的训练过程中batch_size设置为16;优化器为SGD(Stochastic Gradient Descent),动量参数momentum设置为0.93;epochs设置为273;初始学习率设置为0.005。
首先设计了三组实验分别对三个改进点进行训练和测试,最后结合三个改进点,设计了综合实验并进行训练和测试:
实验1对改进backbone的YOLOv3在遥感图像数据集RSOD上进行训练和测试。根据式对网络进行稀疏训练,设定稀疏率(无效特征图占总特征图的比例)为40%,然后统计每种尺度特征中无效特征的比例。图9为backbone在稀疏训练后不同尺度无效特征图的占比,可以看出,13×13的特征图中有70%以上为无效特征图,26×26的特征图中有约56%的无效特征图,52×52特征图的无效特征约为13%,104×104的无效特征约为2%,这说明YOLOv3在进行小目标检测时,具有丰富位置信息的浅层特征比具有丰富语义信息的深层特征更重要,因此小目标检测需要更多的浅层特征。在文献[22]中,通过进一步融合104×104的特征,提升小目标检测精度,文献[23]中更是对6个不同尺寸的特征进行融合。但是融合104×104特征会增加一个检测头,同时会增加32 448个输出预测框,不仅增大了模型尺寸,还降低了推理速度。
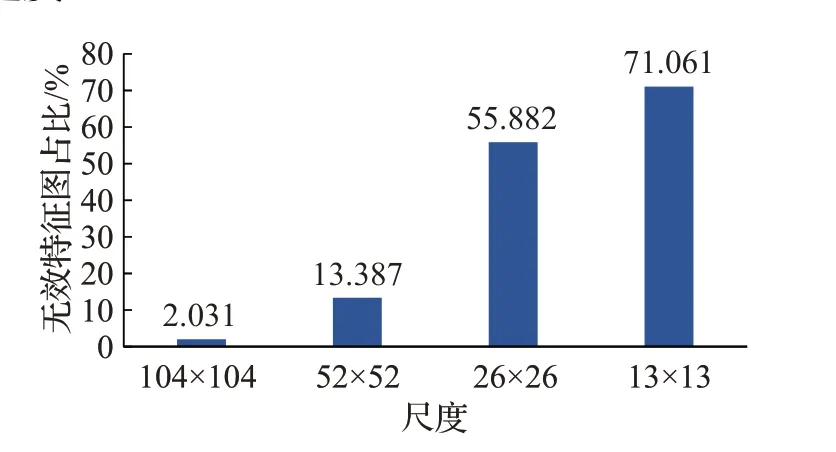
图9 不同尺度特征中无效特征的占比Fig.9 Proportion of invalid features in different scale features
为了符合YOLOv3的结构特点,以2的倍数增减残差层数量。表2中分析了增减不同尺度特征图对应残差块数量时,mAP和F1的变化情况,可以看出,当增加104×104特征图对应的残差层后,模型的mAP提升比较明显,降低13×13特征图对应的残差层后,mAP损失较小,而且模型大小降低较为明显。综合考虑模型的mAP、F1以及模型大小,本文在backbone的基础上增加了2个104×104特征对应的残差层,减少了2个13×13特征对应的残差层。

表2 增加不同尺度特征图对应残差块时精度的变化Table 2 Change of accuracy when adding residual blocks corresponding to different scale feature maps
表3比较了改进backbone的YOLOv3算法、文献[22]算法和YOLOv3,可以看出,相比YOLOv3-[22],改进backbone的YOLOv3算法mAP提高1.06%,模型大小降低16.97%。

表3 改进backbone的YOLOv3、YOLOv3-[22]和YOLOv3比较Table 3 Comparison of YOLOv3,YOLOv3-[22]and YOLOv3 of improved backbone

图10 改进backbone的YOLOv3在数据集上的各类精度Fig.10 Accuracy of improved backbone’s YOLOv3 in dataset
实验2对引入RFB的YOLOv3进行训练和测试。RFB结构的作用是增大特征图的感受野,一般来说浅层特征感受野较小,深层特征的感受野较大。YOLOv3通过上采样的方式将深层特征与浅层特征进行融合。本文首先将浅层特征输入RFB,然后再与深层特征进行融合,表4分析了RFB对不同尺度特征图的作用,可以发现,与YOLOv3相比,当RFB插入在检测头1之前时,mAP并没有提高,而F1有了3.15%的提高,而在检测头2和检测头3之前同时插入RFB时,mAP提高了3.07%,F1提高了4.97%。因此RFB可以增大浅层特征图的感受野,从而提高目标的检测精度。
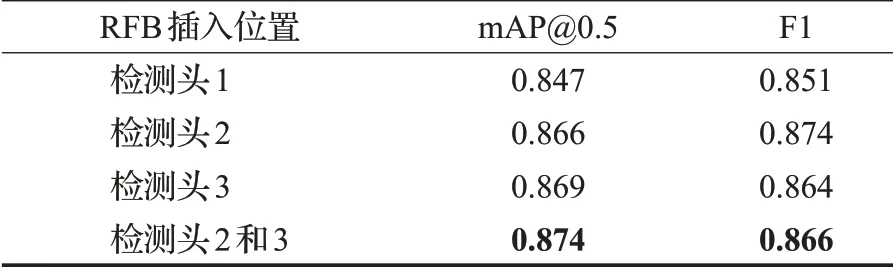
表4 不同位置插入RFB的精度比较Table 4 Accuracy comparison of RFB insertion in different positions
图11为检测头2和检测头3之前同时引入RFB时,数据集中各类的AP比较图,可以发现,小目标居多的aircraft类的AP提高约为6.42%,目标相对较大的playground类的AP提高约为1.15%。说明YOLOv3中引入RFB结构主要通过提高小目标的检测精度来提高整个模型的检测精度。

图11 引入RFB的YOLOv3在数据集上的各类精度Fig.11 Accuracy of YOLOv3 with RFB in dataset
实验3对优化anchor boxes的YOLOv3进行训练和测试。RSOD数据集小目标居多,本文对RSOD数据集使用K-means聚类算法进行聚类,得到新的anchor boxes,根据表1中不同下采样倍数与anchor boxes之间的关系重新分配三个检测头中的anchor boxes,分配结果与每个分类层的滤波器个数如表5所示。

表5 各尺度上的anchor box分配Table 5 Anchor box assignment on different scales
图12比较了优化anchor boxes的YOLOv3和原始YOLOv3的精度,可以看出,优化anchor boxes的YOLOv3在遥感图像数据集RSOD上,mAP提升约2%,F1提升约4.48%。

图12 优化anchor boxes的YOLOv3与YOLOv3精度比较Fig.12 Comparison of accuracy between optimized anchor boxes’s YOLOv3 and YOLOv3
综合实验前三组实验证明,本文对YOLOv3的三个改进点对目标检测的精度都有所提升,尤其是遥感小目标的检测精度。因此,综合三个改进点,本文提出了改进的YOLOv3目标检测算法——YOLOv3-CS,结构如图13所示。
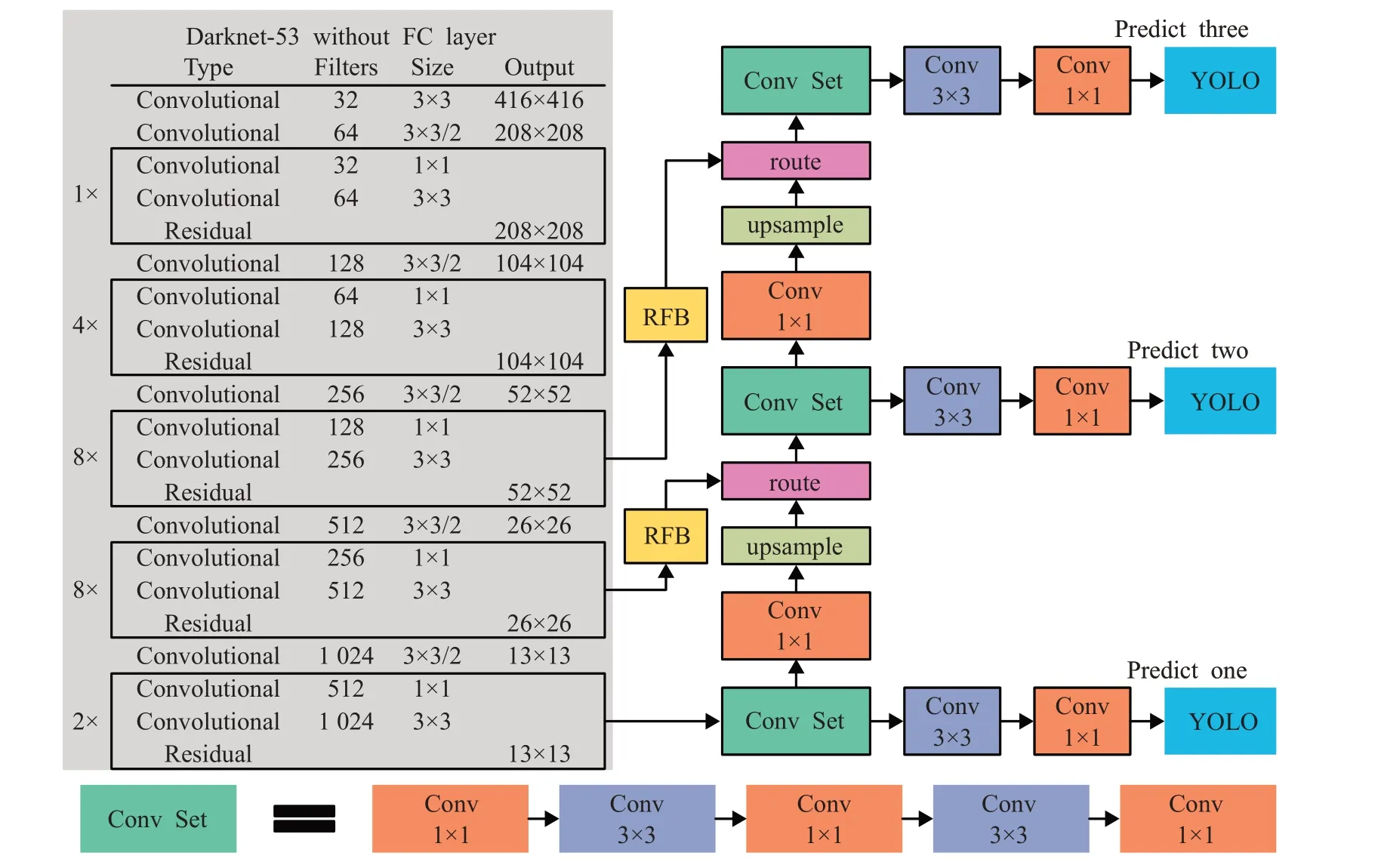
图13 YOLOv3-CS结构图Fig.13 Structure of YOLOv3-CS
CNN在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。YOLOv3-CS的训练过程中网络的总损失、mAP和F1的变化曲线如图14所示。横轴表示迭代次数(epoch),可以看出,随着训练过程的进行,网络的损失稳定下降,mAP和F1的变化也比较平稳,因此网络的收敛过程非常稳定。
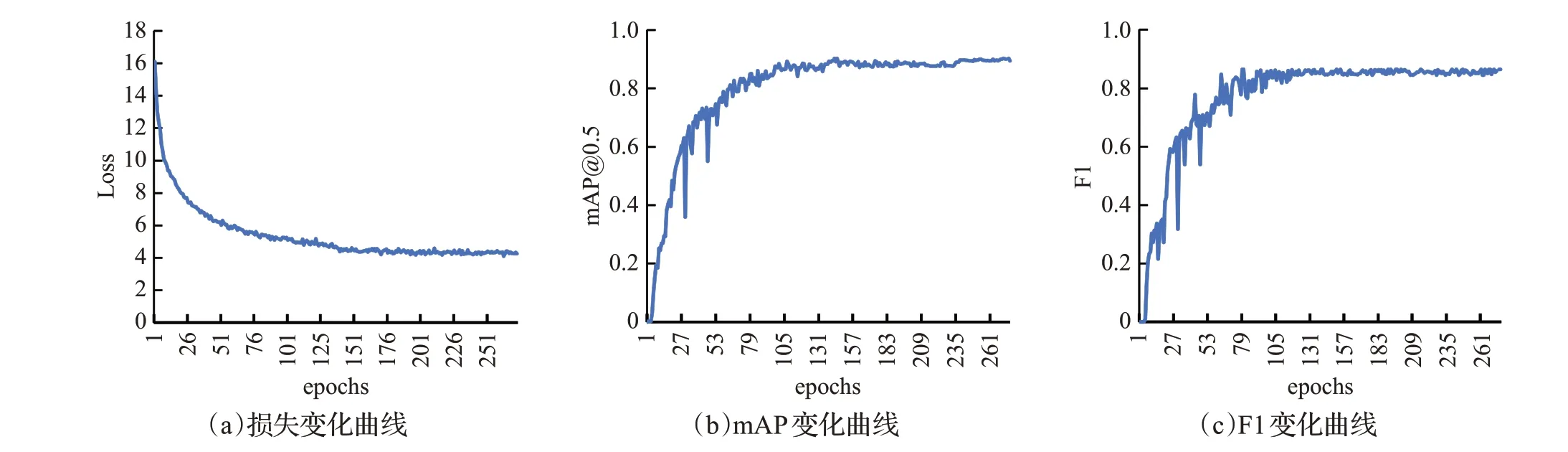
图14 YOLOv3-CS的损失、mAP、F1变化曲线Fig.14 Loss,mAP and F1 of YOLOv3-CS
表6中比较了YOLOv3-CS、YOLOv3、YOLOv3-SPP和YOLOv4[5]的精度、模型尺寸和推理时间,可以看出,YOLOv3-CS的mAP比YOLOv3提高约6.49%,比YOLOv3-SPP高5.49%,比YOLOv4高3.08%;F1比YOLOv3高4.85%,比YOLOv3-SPP高3.35%,比YOLOv4高1.53%;模型大小比YOLOv3减小了12.58%。可见,YOLOv3-CS目标检测模型在检测精度和模型尺寸上都具有较大优势。

表6 YOLOv3-CS、YOLOv3、YOLOv3-SPP和YOLOv4算法比较Table 6 Comparison of YOLOv3-CS,YOLOv3,YOLOv3-SPP and YOLOv4 algorithms
4 结束语
本文对YOLOv3的backbone和anchor boxes分配原则进行了改进,再引入RFB模块增大感受野。在数据集RSOD上做了训练和测试,结果表明本文提出的YOLOv3-CS在mAP和F1两种指标上都优于YOLOv3和YOLOv4,尤其是对小目标的检测,mAP提高较为明显,并且模型尺寸比YOLOv3更小。本文模型的推理时间比YOLOv3增加了9.4%,在一些算力较低且实时性要求较高的场合,仍然无法满足要求,如何在保持模型精度的情况下缩短模型推理时间是未来的主要研究目标。
