N1+N2结构语法关系判定的SVM算法
2021-10-28杨泉
杨 泉
北京师范大学 汉语文化学院,北京 100875
短语是在语义和语法上都能搭配、没有句调的一组词,是造句的备用单位。短语层级的语法关系判定是中文信息处理领域的重要基础性课题,其研究成果在信息搜索、自动问答、文本摘要等[1]诸多领域都有着较为广泛的应用。N1+N2结构是汉语中最为常见的短语结构之一,对该结构的研究也非常广泛。在中文信息处理领域对于该结构的研究目前涉及到查询[2]、识别[3]等方面;在语言学领域涉及到对其语法功能、语义类型和使用情况等方面的考察、描写和分析[4-5],但是前人研究中对于该结构语法关系自动判定的研究成果还鲜少得见。根据文献[6]的研究成果,N1+N2结构可以分成四种语法关系:定中关系、并列关系、复指关系和主谓关系,因此对于N1+N2结构语法关系判定实际上就是一个多分类问题,而该多分类问题又可以转化为一系列二分类问题。
支持向量机(Support Vector Machine,SVM)[7]作为一种强有力的二分类方法[8],在文本分类[9-10]、信息检索[11]、情感分析[12-13]、音字转换[14]、搭配识别[15]等自然语言处理的诸多领域均取得了较为理想的计算结果。SVM方法对于非线性情形使用核技巧,将低维空间的数据映射到高维空间,然后在高维空间中进行基于最大间隔原则的线性学习,并使用二次规划(Quadratic Programming,QP)技术获得划分超平面[7-8]。
N1+N2结构语法关系判定属于非线性分类问题,本文计划在自建语料库的基础上,研究如何更好地利用支持向量机进行汉语短语语法关系分类,以期提高计算机理解自然语言的能力。
1 N1+N2结构语料库简介
使用人工智能方法处理语言学问题离不开语料库的支持,本研究自建语料库,并为语料标注了语法、语义信息,具体建库过程如下:
(1)语料获取:从北京语言大学BCC语料库(http://bcc.blcu.edu.cn)自动提取N1+N2结构语料共17 108条。
(2)语料清洗:首先去掉各类不合格语料,比如有些英文、动词或成语当作名词被抽取出来;另外还有重复语料也要去除,最后剩下合格语料共4 944条。详细数据如表1所示。
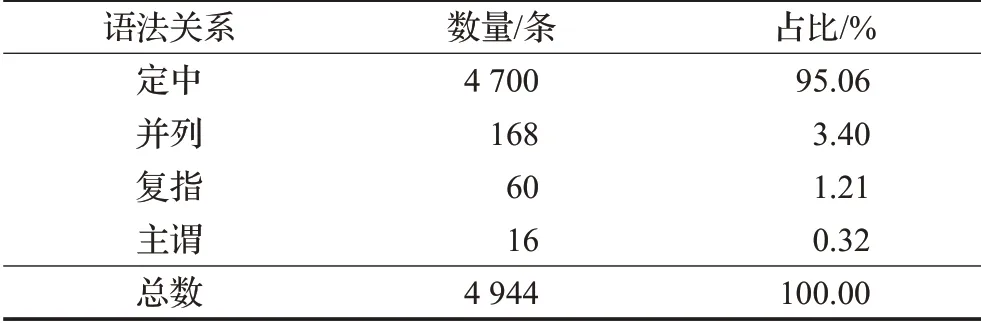
表1 入库语料各关系数量及占比表Table 1 Number and ratio of 4 relations in corpus
(3)语义标注:本文用《同义词词林》作为名词语义标注体系(《同义词词林》是梅家驹等人早年编撰的汉语可计算词库,后经哈尔滨工业大学研究人员对其进行扩展成为《哈工大信息检索研究室同义词词林扩展版》,下文简称《词林》),注方式采取Python编程自动标注。
(4)语法标注:为N1+N2结构人工标注并校对定中、并列、复指、主谓四种关系。
至此,N1+N2结构语料库构建完毕,具体样例如表2所示。
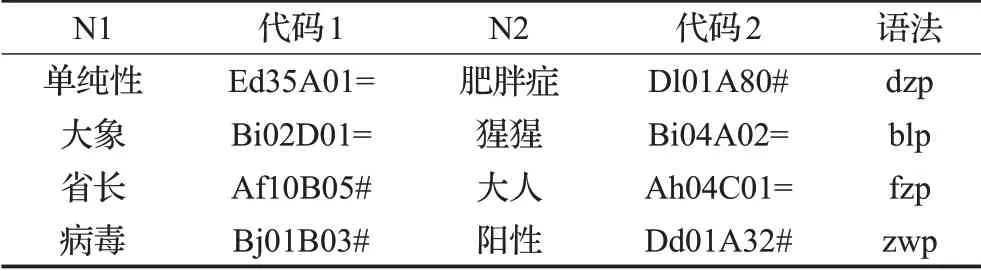
表2 N1+N2结构语料标注样例表Table 2 Sample table of N1+N2 structure in corpus
表2中“代码”是《词林》中的语义编码;dzp、blp、fzp、zwp分别表示定中、并列、复指、主谓四种语法关系。
短语的语法关系实际上就是其构成词的语义关系共性特征的抽象概括,N1+N2结构内部两个名词间的四种语法关系可以看作一个四分类问题。在机器学习算法中,有一大类算法可以解决分类问题,例如支持向量机就是解决分类问题的典型方法。支持向量机要求其输入是数值向量的形式,所以无法直接对N1+N2结构的汉语语料进行分类。要使用支持向量机,首先需要将N1+N2结构转换为数值向量的形式。根据前面分析,四种语法关系代表了不同名词组成该短语时的不同语义关系,短语的语法关系是由其所构成词的语义类别和语义关系决定的。因而在转换成向量时应重点考虑短语结构中表示语义类别和语义关系的相关信息。本文在上述观点的基础上建立熟语料库并生成短语结构向量,利用支持向量机对N1+N2结构中两个名词的语义类别和语义关系进行分类,进而判定该结构的语法关系。
2 基于支持向量机的N1+N2结构语法关系判定方法
2.1 支持向量机原理简介
支持向量机是机器学习方法中应用最广泛的分类方法之一。经典的SVM是一种二分类方法,其基本框架为:
给定训练样本集T={(x1,R1),(x2,R2),…,(xm,R m)},其中xi为k维空间的样本点,对应的标签记为Ri∈{-1,+1}。当训练集是线性可分时,则存在一个k维空间中的超平面可表示为公式(1):

将两类数据分开。显然,可以划分数据集的超平面可能不止一个,因此SVM是找到使数据集到超平面的几何间隔最大化的最优超平面。该平面满足如公式(2)的优化问题:
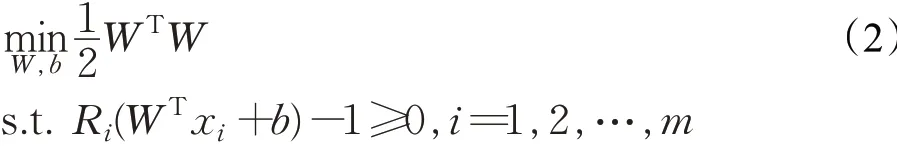
当数据在其样本集空间中非线性可分时,则无法在原样本空间中找到超平面,此时可以先用一个非线性映射把T中的所有样本xi(i=1,2,…,m)映射到一个高维甚至是无穷维空间(特征空间)中,使其线性可分,然后在此高维空间中寻找超平面。
令φ(x)表示将x映射后的特征向量,在特征空间中划分超平面所对应的模型可以表示为公式(3):

由于φ(x)的维数一般较高,甚至是无穷维,所有直接求解特征空间中的超平面会面临较大困难。因此SVM通过引入核函数κ(x,y)=φ(x)Tφ(y),用原空间中的低维向量来计算其特征空间中高维向量的内积。引入核函数的非线性SVM的对偶问题可以表示为公式(4):
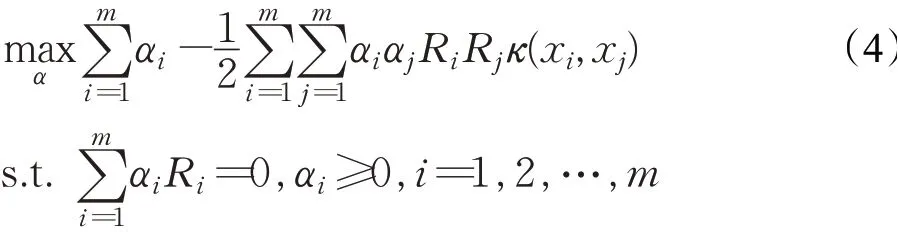
一般训练SVM时需要求解一个大规模的二次规划问题。常用的有序列最小最优化算法、二次规划方法和最小二乘方法等。
2.2 文本的特征选择与向量化
SVM已经是比较成熟和完善的算法,但要实现对N1+N2结构语法关系的分类,首先需要将原始语料中的N1+N2结构转换为Rk空间中的向量x。本节介绍将原始语料转换为向量的方法。
本文的语义标注体系——《词林》使用8位编码来表示词语义项:第1、2、3+4位编码代表大类、中类和小类,分别用1位大写英文字母、1位小写英文字母和2位十进制整数表示;第5、6+7位编码代表词群和原子词群,分别用1位大写英文字母和2位十进制整数表示;第8位编码代表原子词群中词语之间的关系,用1位符号表示,=、#、@分别表示词语之间同义、相关、独立的关系。表3详细展示了《词林》中的8位义项编码体系。

表3 《词林》义项编码表Table 3 Code table of meanings in Cilin
《词林》义项编码是一种向量化的表示方法,其中蕴含了词语的语义类别信息,这些语义类别也是语义关系的体现,在短语结构内部语义类别和语义关系对语法关系起到决定性作用,因此对于N1+N2结构语法关系判定可以借助其内部两个名词在《词林》中的语义编码进行。例如“单纯性肥胖症”是一个N1+N2结构,对应的《词林》编码为“Ed35A01=Dl01A80#”,其语法关系dzp就是分类结果R。依此类推,每一个结构都对应着一个由16个字符构成的向量,而SVM需要使用数值化的向量进行计算,因此需要进一步把《词林》编码向量映射为数值向量。《词林》编码体系包含12个大类,95个中类,1 428个小类,共涉及65个不同的字母、数字和符号。将每一个符号用一个16位二进制编码表示,则不同符号会有不同编码,编码示例见表4所示。
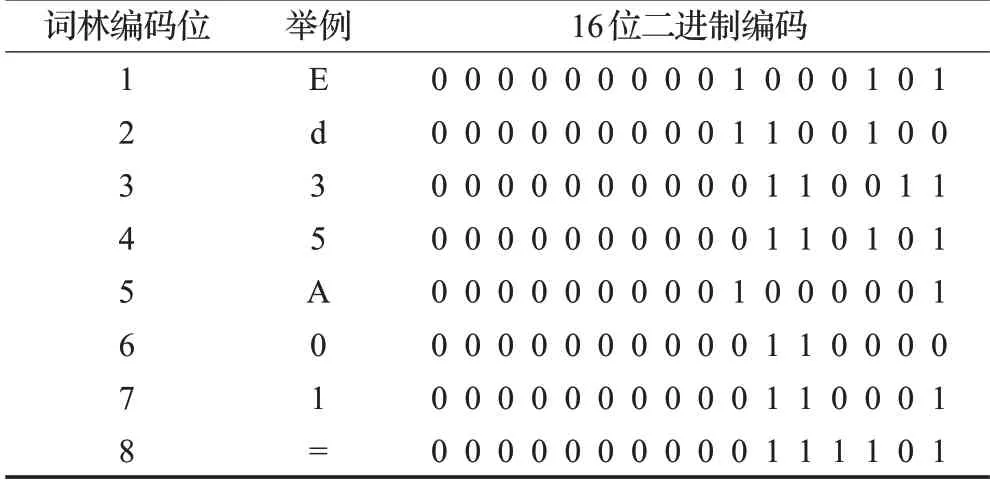
表4 16位二进制编码示例表Table 4 Examples of 16 bit binary code
至此每一个《词林》编码组均可转化为一个16×16=256位的二进制向量。而语料库文本可转化为标准训练样本集T={(x1,R1),(x2,R2),…,(xm,Rm)},其中xi为256维取值是{0,1}的向量,Ri可取{1,2,3,4}分别代表{dzp、fzp、blp、zwp}四种不同的关系。显然,在每一个结构对应的256维向量中都包含大量的零元素,直接使用会影响支持向量机算法的收敛性和运行效率。
综上,本文首先将数据集中全部结构的向量构成矩阵:X=[x1,x2,…,x m]T;然后,对该矩阵进行奇异值(SVD)分解:X=UDVT;最后,根据奇异值的大小分布,选取n个较大的奇异值对应的奇异向量作为最终用于结构语法关系分类的向量。此时仅需在n维空间中寻找用于分类的超平面。一般通过奇异值分解进行准确降维后,能够大大提高算法的运行速度和分类精度。
2.3 SVM判定N1+N2结构语法关系方法
通过上文关于N1+N2结构的关键特征提取与数量化表示,本文将待分类的短语结构映射到了一个维数适中的向量空间中,同时也将短语结构的语法关系用数量进行了表示。这样从形式上已将文本及其对应的分类结果转化为经典SVM算法可直接使用的数值向量和数值,但有两个关键问题需要进一步分析和研究。第一个关键问题是如何将经典的解决二分类问题的SVM方法,直接应用到解决多分类问题中。因为结构关系包含四种类型,因此本文研究的短语结构判断问题可以直接转化为一个四分类问题。本文提出的解决思路是将多分类问题通过逐次二分进行解决,在每一次分类过程中仅需要对分类样本进行二分。对于具有四种可能的N1+N2结构语法关系判定转化为3个不同的二分类问题进行解决。根据对样本分布的统计结构,在每次分类过程中尽量保持两类分类结果样本数量之间的均衡性,避免出现数量相差悬殊的两类样本先进行分类。根据这一原则,首先把训练样本集中的全部结构分为两类:{dzp}和{非dzp},其标签分别为1和-1,通过训练分类器SVM1进行分类;然后,把训练样本集中除dzp以外的结构再分为两类:{blp}和{fzp,zwp},并设其标签分别为1和-1,通过训练分类器SVM2进行分类;最后,通过分类器SVM3将{fzp,zwp}所对应的样本进行分类。具体分类流程图详见图1所示。
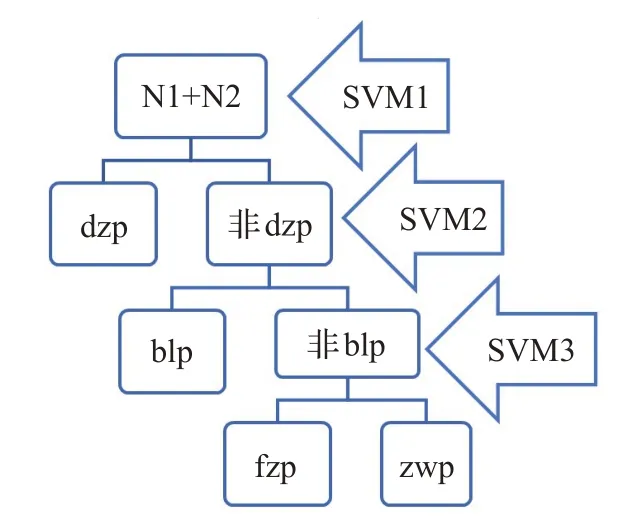
图1 SVM语法关系判定流程图Fig.1 Flowsheet of SVM syntax relation judgment
本算法训练的三个分类器关系如下:在分类过程中先用SVM1进行判别,若分类结果为dzp,则判断结束;否则,继续通过SVM2进行判断,若分类结果为blp,则判断结束;否则继续通过SVM3进行判断,根据SVM3的判断结果得到最终判断结果。至此本文已经完成了使用SVM对N1+N2结构进行分类的全部数据和算法的准备工作。本文通过对N1+N2结构进行特征标注,并将其特征集映射到相应的向量空间,要解决的第二个关键问题是,不同结构映射对应的数量向量在向量空间中是否具有可分性。如果这些向量在其空间中没有足够好的可分性,虽然可以通过SVM进行分类,但从理论上很难得到性质优秀的分类器。造成向量不可分的主要因素是特征的选取不合理,这些特征不能覆盖短语结构的最小可分特征集。其中最小可分特征集是指能够将全部的短语结构进行准确分类所需要的最少特征所构成的集合。
在实际应用中不可能掌握全部的N1+N2结构,根据语言学的相关研究,本文所使用的语料库从规模和代表性上可以看作是全部N1+N2结构的一个较充分的样本。它基本可以代表全部结构的特征。在建设语料库的过程中,对于这些N1+N2结构,都通过人工比对验证了本文所提特征在分类时的充分性。语料统计结果表明,基于本文所提短语结构特征,可以对短语进行完全的分类,因此从一定程度上解决了第二个主要问题。从理论上和算法上都保证了使用SVM对N1+N2结构进行分类的可行性。
3 实验结果与分析
本章使用语料库中的语料检验所提算法的有效性。为增加实验结果的可信度,本文采用随机交叉验证的方法进行检验,每次实验按训练集与测试集9∶1的比例对语料库中的语料进行随机分组,共进行了9次,用9次的平均值作为最终计算结果。其中,本文算法的三个支持向量机分类器均使用了二次核函数,并通过最小二乘法进行求解。为验证降维后不同维数对计算精度的影响,分别取不同的维数,对每一个固定的维数采取9次随机分组训练分类器并验证准确率。
表5中列出了从20到40之间11组不同维数的计算结果。从验证结果可以看出,随着维数的升高,计算结果的准确率有上升的趋势,但在36维时已经达到86%的准确率。当维数继续升高时,计算结果先降后升,但超过40后,随着维数的继续升高,精确率增长效果并不明显,因此采取40维左右的向量即可达到较好的分类结果。本文方法的分类结果还有较大提升空间,由于文献中没有缺少使用支持向量机处理N1+N2结构语法关系分类问题的相关研究,无法进行直接比较。但从利用支持向量机处理语言学问题的类似文献的结果来看,本文结果达到或超过了同类问题和方法的处理水平。
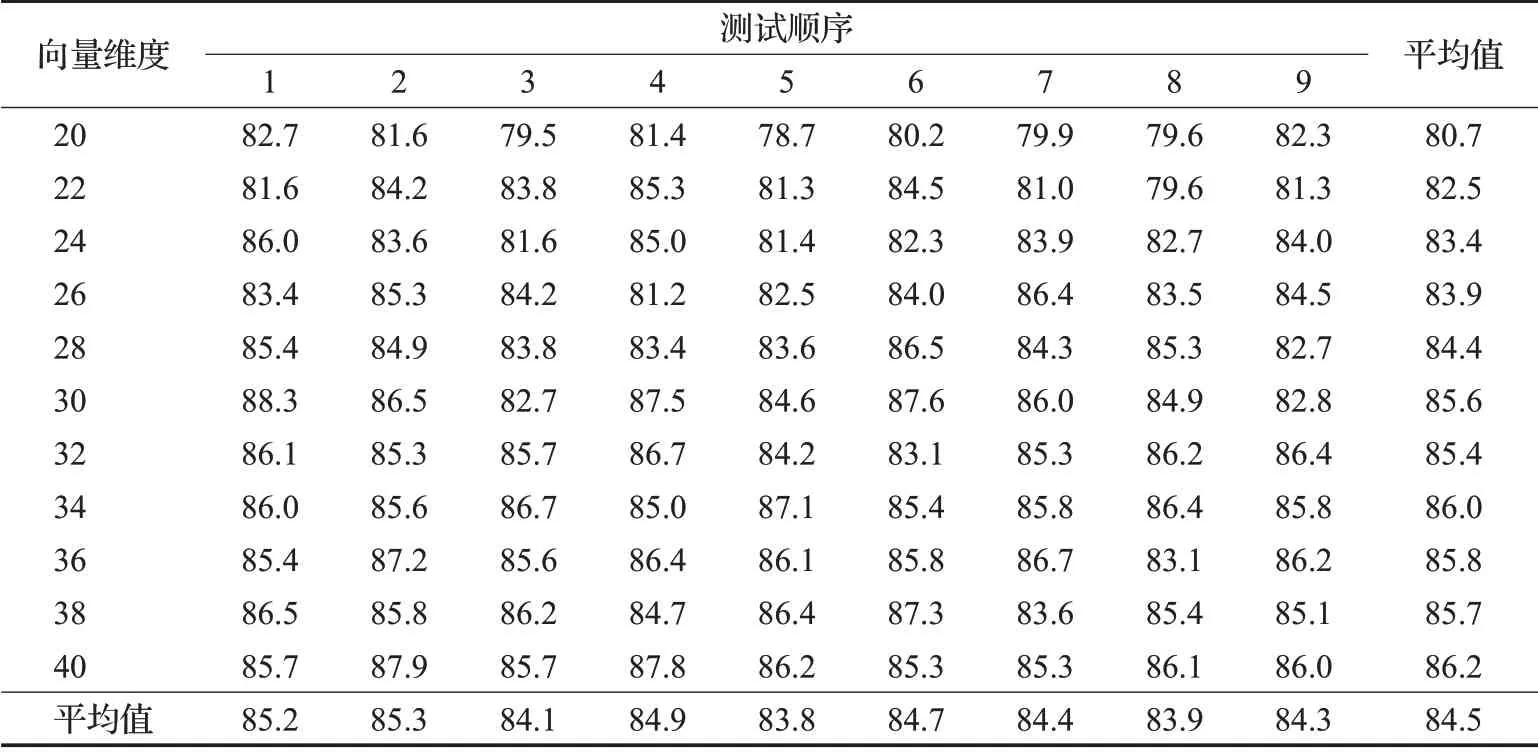
表5 SVM算法实验结果表Table 5 Experimental results of SVM algorithm %
4 结论与展望
短语结构语法关系判定问题是计算机处理自然语言时每时每刻都可能遇到的底层问题,本文以N1+N2结构为例研究如何使用机器学习方法处理这类问题。结果证明,基于语言学知识,将语言学问题转化为可以通过支持向量机解决的问题能够取得很好的处理效果。但本文算法还有较大提升空间,其错误主要来源于dzp和blp两类关系的分类和判定。可从两个方面提升区分效果:一是采取更优的向量化方法,二是在《词林》编码的基础上增加更多可用于分类的语言学信息,如上下文信息等。
由于目前相关研究不多,特别是难以找到可直接实验的数据集,因此本文前期准备工作中进行了大量人工标注工作,未来将进一步研究自然语言处理领域的问题如何深入依托机器学习、人工智能的方法,在“小数据、弱标注”的前提下完成“大任务”。
