基于深度神经网络的多分类方法研究
2021-10-28施启军龙福海苟辉鹏苏浩辀谢雨寒
◆施启军 龙福海 苟辉鹏 苏浩辀 谢雨寒
基于深度神经网络的多分类方法研究
◆施启军 龙福海 苟辉鹏 苏浩辀 谢雨寒
(贵州民族大学数据科学与信息工程学院 贵州 550025)
随着大数据和网络时代的飞速发展,网络数据呈爆炸式增长,对海量数据的分析和处理成为大数据领域最核心的问题。对数据进行分类是分析和处理数据流量的一项关键技术。在机器学习和数据挖掘领域,分类问题变得越来越重要。有关深度神经网络的分类研究中,大多数都是基于二分类问题的,用深度神经网络处理多分类问题的研究还很少。针对传统的数据分类模型分类精度低以及如何利用深度神经网络解决多分类这一问题,我们提出了一种基于深度神经网络的大数据高效分类方法,并在weka自带的鸢尾花数据集上进行分类实验,实验结果表明该方法能大大提高数据的分类精度。最后我们用该方法与几种机器学习中的经典分类算法进行性能对比实验,实验结果显示我们的方法在分类准确率上优于其他方法。
深度神经网络;机器学习;大数据分析与处理;多分类
1 引言
当今我们正处于大数据的浪潮中,数据爆炸式增长给大数据的分析和处理带来巨大挑战。人们迫切需要研究出更加方便有效的工具对收集到的海量信息进行快速准确的分类。对庞大的数据进行合理分类是大数据分析与挖掘过程中必不可少的环节,这一研究热点备受相关领域工作人员的青睐,不同的分类算法可根据不同的训练数据集训练出不同的分类器,分类器的可靠性和分类精度根据分类器的不同而不同,同时分类器的好坏会对数据的分类质量造成直接影响,所以我们需要挖掘出分类精度较高且可靠的分类器对数据进行精准分类,这不仅能提高对大数据的精准分类,还会为相关工作人员提供借鉴意义。
随着人们对分类算法的不断研究,机器学习领域出现了很多分类算法,包括有监督分类算法、无监督分类算法、半监督分类算法等。现有的分类算法有很多种,比较常用的有C4.5决策树[1]、K近邻(K-nearest Neighbor)[2]、支持向量机(Support Vector Machine)[3]、随机森林(Random Forest)[4]、贝叶斯神经网络(BayesianNeural Network)[5]等方法。虽然以上研究均能够对大数据分析与挖掘提供有利推动作用,但是从具体上来说,仍然存在局限性,其分类精度还有待提高。针对传统分类器分类准确率不是很高以及如何利用深度神经网络解决数据多分类这一问题,我们提出一种基于深度神经网络的数据多分类方法。我们在不同样本容量的大数据样本中进行分类实验,实验结果表明,我们提出的方法能取得较好的分类效果。论文其余部分结构如下:第二节对深度神经网络的概念和结构进行阐述;第三节介绍用于多分类实验的数据集以及DNN框架,并给出实验结果;第四节对本文进行总结。
2 DNN概述
2.1 DNN的基本结构
深度神经网络(Deep Neural Networks,DNN)也叫作多层感知机(Multi-Layer perceptron,MLP),它由神经网络演变而来,也可以理解为具有很多隐藏层的神经网络,它是深度学习的基础。DNN按照不同层的位置划分,其内部的神经网络层可以分为三类:输入层、隐藏层和输出层,如图1所示,第一层为输入层,中间的所有层为隐藏层,最后一层为输出层。
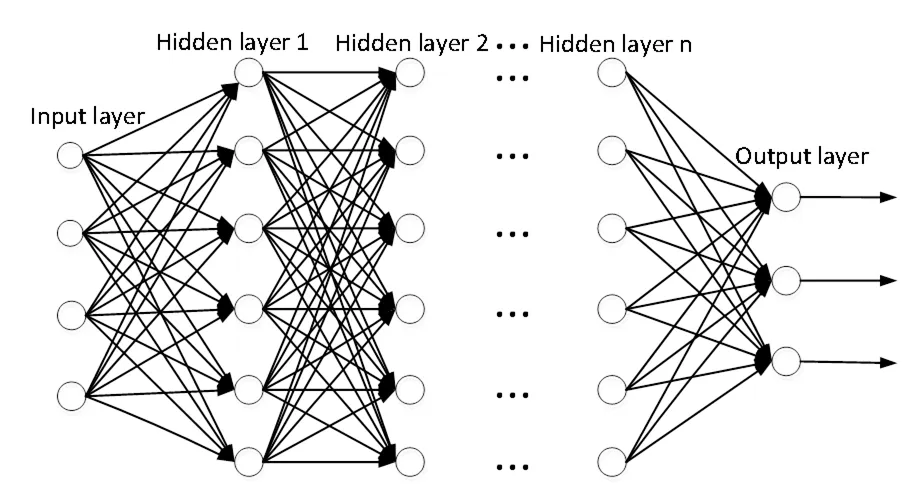
图1 DNN基本结构
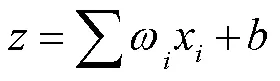
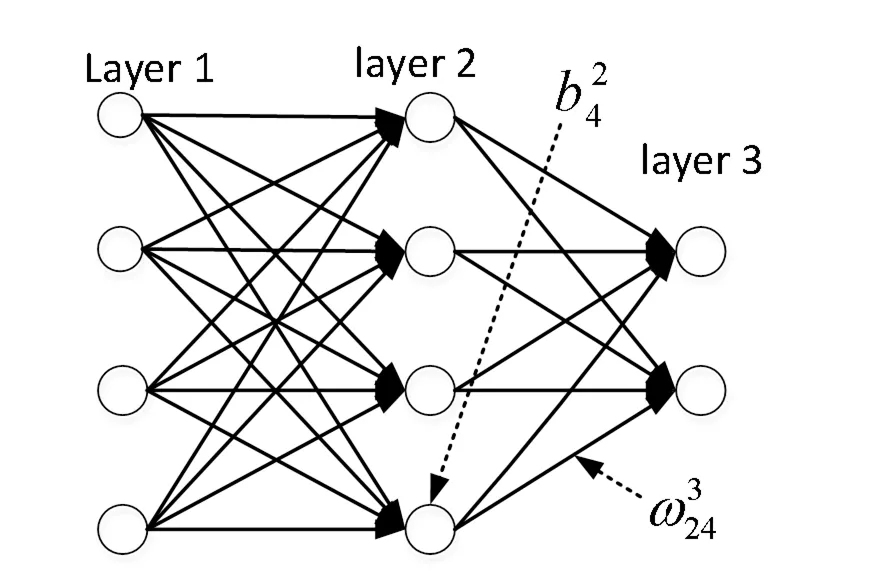
图2 用于对DNN线性系数和偏倚进行定义讲解
2.2 DNN前向传播算法

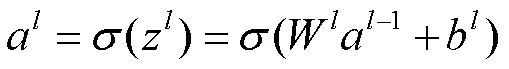
2.3 DNN反向传播算法

3 分类实验研究
3.1 数据集与实验环境
本文实验所采用的数据集是weka自带的鸢尾花数据集(Iris),如表1所示。该数据集总共有150个样本,每个样本包含了四个特征,分别为花萼长度(sepallength)、花萼宽度(sepalwidth)、花瓣长度(petallength)、花瓣宽度(petalwidth),将鸢尾花分为三类,分别为Iris-setosa、Iris-versicolour和Iris-virginica,每一类有50个样本。在实验中我们保持数据中各类数据样本比例不变,抽取该数据集的70%作为训练集,其余30%作为测试集。我们的实验是在Intel(R) Core(TM) i5-9400F CPU、运行内存为16G的计算机上,基于weka平台以及weka工具包设计实现的。
3.2 DNN搭建以及分类实验
我们利用Keras搭建深度神经网络来解决对鸢尾花数据集的分类问题,其具体结构如图3所示。
表1 实验数据集

我们搭建的DNN多分类实验架构图由输入层、隐藏层、输出层和softmax函数四个部分组成,由图3可知,架构图中的输入层由4个神经元组成,它们对应鸢尾花数据集中所具有的4个特征。中间部分为隐藏层,有两层神经元,分别有5和6个神经元。紧跟其后的为输出层,由3个神经元组成,对应鸢尾花数据集的3个类别。最后面是一个softmax函数。在本文给出的DNN模型中,我们选择ReLU函数作为神经元激活函数,选择交叉熵(cross entropy)作为损失函数,选择Adam作为迭代的优化器,各个层的连接权重和偏重的初始值是随机生成的。
定义完模型后,我们就对模型进行训练,本次实验采用交叉验证法(Cross Validation)进行评价,实验的最大迭代次数被设置为100。为了对模型进行评估,我们输出来该DNN模型的损失函数的值以及在测试集上的准确率,迭代100次后准确率达到98.26%,分类效果显著。
3.3 DNN分类性能分析
weka平台集成了所有主流的机器学习算法0,同时也可以实现数据的预处理操作。我们将相同的数据集导入到weka平台,分类器分别选择C4.5决策树、贝叶斯网络(BN)、K近邻(KNN)、随机森林(RF)和支持向量机(SVM),分别迭代100次后输出各个算法的分类准确率,然后与我们的实验结果进行比较,如图4所示。最终结果表明,DNN的分类准确率最高,其分类性能最好。
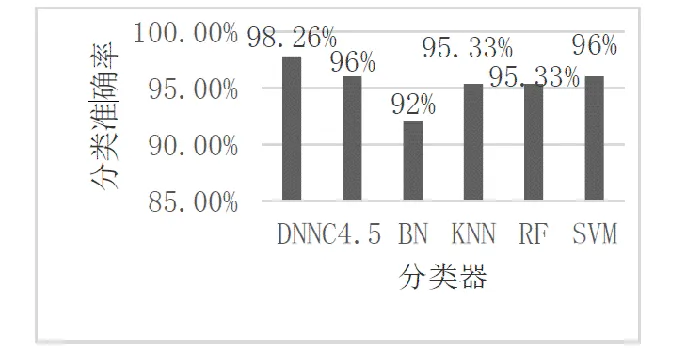
图4 各分类器在iris数据集上的分类性能比较
4 总结
在这篇文章中,我们利用深度神经网络解决多分类问题,并基于weka平台进行性能评估实验,实验结果表明,该方法具有较好的分类效果。对该算法的研究仍处在初级发展阶段,需要研究人员进一步加强相关内容的研究。在以后的工作中我们可以运用更加广泛的数据集来检验算法的运行效率,使用不同分类器来检测所选特征子集在分类时的准确性以及采用不同的评估方法对所提出的算法进行评估。
[1]徐鹏,林森. 基于C4.5决策树的流量分类方法[J]. 计算机学报. 2009,20(10):2692-2704.
[2]Indarti,Indarti,Indriyani Novita,Budi Arief Setya,Laraswati Dewi,Yusnaeni Wina,Hidayat Arief. The Classification Of Monster And Williams Pear Varieties Using K-means Clustering And K-Nearest Neighbor(KNN)Algorithm[J]. Journal of Physics:Conference Series,2020,1641(1).
[3]Este A,Gringoli F,Salgarelli L. Support vector machines for TCP traffic classification[J]. Computer Networks,2009,53(14):2476-2490.
[4]Gislason,PO,Benediktsson,et al. Random Forests for land cover classification[J]. PATTERN RECOGNITION LETT, 2006.
[5]Auld Tom,Moore Andrew W,Gull Stephen F. Bayesian neural networks for internet traffic classification.[J]. IEEE transactions on neural networks,2007,18(1).
[6]Hall M,Frank E,Holmes G, Pfahringer B,Reutemann P, Witten IH. The WEKA data mining software:an update. ACM SIGKDD explorations newsletter,2009,11(1):10-18.
