基于主成分聚类的本溪无资料地区中小河流参数移植研究
2021-10-28李晨涛
李晨涛
(辽宁省本溪水文局,辽宁 本溪 117000)
近些年来,受环境变化影响,中小河流突发洪水呈现逐年增多趋势,产生灾害的程度也越来越严重。本溪地区位于辽宁省东部,属于典型的东部山区,区域内中小河流众多,流域面积100km2和200km2以上的河流分别为12条和27条。本溪地区属于辽宁省暴雨洪水易发区,大部分中小河流位于无径流观测资料的区域,很难构建预报方案。为提高本溪地区中小河流预报能力,亟需对其预报断面进行方案构建。当前,对于无资料地区中小河流研究也取得一定研究成果,这些成果大都通过有资料地区进行参数移植到无资料地区,从而构建无资料地区预报方案,而采用的方法主要为相似流域法或者经验判定法,其中相似流域应用较多,但相似流域方法大都按照流域面积以及地理位置相近为原则,不能充分考虑流域下垫面特征或者水文特征对预报模型参数的影响,存在一定的局限。一些研究成果表明,对于无资料地区中小河流,综合考虑流域下垫面特征和水文特征,可以有效提高无资料地区中小河流参数移植的精度。本文以充分反映中小河流洪水模拟特点的下垫面及水文特征的7个参数作为聚类指标,采用主成分聚类分析方法对本溪地区中小河流预报断面进行参数移植,研究成果对于本溪及全省其他无资料地区中小河流洪水预报方案构建提供方法参考。
1 主成分聚类参数移值方法
1.1 聚类指标选取
流域产汇流地形等参数具有较高的相关性,水量平衡方程及水文情势受植被覆盖影响也不能忽略。伊璇等通过对全国多个无资料地区进行径流模拟试验表明流域径流影响指标主要为四类共计18个指标,分别为地形类包括流域面积、河流长度、流域比降、河网密度、流域形状系数;地势类主要为流域的高程;水文特征类包括降水量、径流深年均值;土地利用类主要包括农业用地、林地、草地、水域的占比面积;土壤类型类主要包括沙土、粘土、壤土的占比。本文依据此成果首先选取以上18个指标,考虑到各指标之间的关联度较多,不同指标之间的信息会有所重叠,一些变化规律有所掩盖,需要降低聚类分析的维度。基于此本文结合SCS降雨径流模型,将流域地形、地势、土地利用类型、土壤类型作为模型参数,选取辽东地区南甸峪、二道河子等7个水文站点50场洪水数据,以洪峰为目标,对选取的18个水文地理指标进行敏感度分析,敏感度分析成果可详见参考文献[17]。通过敏感度分析,对于辽东地区而言,河流长度、汇水面积、河流坡度、流域形态、植被覆盖度、降水量及径流深年平均值7个指标对于区域洪峰影响较为敏感,而其他11个指标敏感度较低,甚至不敏感。本文在进行辽东地区参数移植聚类指标分析时,以上述7个指标进行聚类分析。
1.2 主成分分析
主成分分析方法在大量的信息数据中通过方差解释来确定主成分分析向量,将原有数据的高维投影数据进行降维处理后得到特殊的数组矩阵,从而使得原有数据信息得到较为有效的保留,从而对数据信息进行更便捷的处理和使用,这其中需要对原有参数的主要信息进行有效提取,从而降低分析的指标个数,从主要关联度进行变量的提取后,降低参数分析的空间维数。
1.3 系统聚类分析
数据挖掘是聚类分析的主要方法,将多个数据按照相似度进行数据对象的分类,从而得到具有一定差异度的数据分类,主要步骤为:
(1)对于分析的各变量聚类指标而言,对于其维度空间P对应下的n个聚类指标,可以采用不同聚类指标之间的关联度进行分析,其关联度一般采用数学距离方法或者绝对值方法进行判定,其各聚类指标之间的变异度本文主要采用欧氏距离方法进行判定。
(2)对于距离判定较为接近的2类聚类指标进行合并成为一类指标,本文对各类指标进行平均法计算。
(3)计算各类指标与合并后的新的聚类指标的欧氏距离值,将距离最短的两类指标进行重新合并,若聚类指标合并为一类,则表示聚类计算结束,重新返回到第二个步骤进行聚类指标之间的欧氏距离计算。
2 本溪地区中小河流参数移值研究
2.1 流域概况
本溪市地处辽东山丘区。山多地少,呈现“八山一水一分田”的地貌格局,地势西北低,东南高并向中部倾斜。流域内属温带气候,受季风影响较重,冬夏气候分明。平均气温6~8℃,最高气温35~38.0℃,最低气温-29.2~-37.9℃。降雨量充沛,最大年降水量为1172.9mm,最小年降水量为503.5mm,年平均降水量为750~850mm。降水年内分配不均匀,暴雨多集中在七、八两月,降水量约占全年降水量的70~80%,七、八两月受副热带高压影响,常有台风雨,易造成泥石流。流域内全年平均降水天数为80~120天,由于降雨时空分布的差异性,本溪地区发生洪涝的频次较高。
2.2 中小河流站点概况
基于本溪地区中小河流站点水文地理特征数据,对区域区主要中小河流站点的下垫面特征以及水文特征进行提取,提取结果见表1。
2.3 聚类分析结果
采用本溪地区具有长系列观测数据的参考水文站和新建中小河流站点进行各指标的聚类分析,对各聚类指标进行关联度的计算,其关联度计算结果见表2。从表中可看出,各聚类指标之间存在一定的关联度,年径流深均值和年降水均值之间的关联度最大,且两个指标与森林率之间具有较高的关联度,关联系数均高于0.6。

表2 相关系数矩阵分析结果
2.4 主成分荷载矩阵
对聚类指标进行主成分贡献率累积值的计算,当两个主成分方差累积贡献率高于1.0,则认为为聚类指标的主成分,各主成分累积方差贡献率高于1 的荷载矩阵分析结果见表3。各聚类指标主成分与初始值之间的关联度可以通过荷载矩阵指标值进行分析,聚类指标的主成分主要表征各聚类指标的影响度。通过分析对于本溪地区聚类指标而言,对第二个主成分影响程度较高的是河长特征指标。

表3 主成分荷载矩阵分析结果
2.5 参数聚类分组结果
基于各站点主成分聚类分析值,可以对样本序列进行重聚类分析计算,从而得到各聚类指标之间的关联结构,通过分析可以将本溪地区各中小河流站点和其对应的参考站点划分为6个聚类组,各组内对应的参考站和中小河流站点见表4。

表4 本溪地区参照站与中小河流站对应表

(续表)
从对应分聚类分组结构可看出,在同一个聚类分组内的站点有相近的地理位置,也有个别站点具有较远的地理位置,在地理位置的相似度较低。而分组内的三道河站和偏岭站具有较为接近的地理位置,而统一分组内的孟柳站则距离二道河子站和偏岭站的地理位置较远。
3 参数移值验证分析
由于本溪站中小河流大都处于无径流观测资料的区域,且建站以来具有完成洪水测次的站点较少,对采用主成分聚类方法进行参数移值进行验证,需要两个有实测洪水数据的站点进行参数移植验证。按照聚类相似分组情况,南甸峪站和桥头站在同一个相似组,且桥头站已有预报方案,因此将桥头站的参数移植到南甸峪站,结合南甸峪站实测洪水数据选用新安江模型进行参数移值方法的验证。
3.1 南甸峪站概况
南甸峪水文站位于本溪县南甸镇小峪村,东经124°24′,北纬41°16′,始建于1958年1月,集水面积765km2,为区域代表站,国家基本站。南甸站流域内设有雨量站4处,分别是羊胡子沟、南孤山、林场、南甸雨量站。站点分布如图1所示。

图1 南甸峪站流域内站点分布
3.2 模型参数移值
本溪地区实用洪水预报方案中桥头站采用新安江模型进行预报方案的构建,将桥头站已率定好的新安江模型参数移值到南甸峪水文站,模型参数见表5。

表5 模型参数移值结果
3.3 模型参数移值结果分析
在模型参数移值的基础上,采用南甸站11场次洪水进行模型验证,模型产汇流计算结果见表6和表7。模型产流和汇流按照GB/T 22482—2008《水文情报预报规范》其合格率可分别达到91%和73%。

表6 南甸峪水文站产流模拟结果
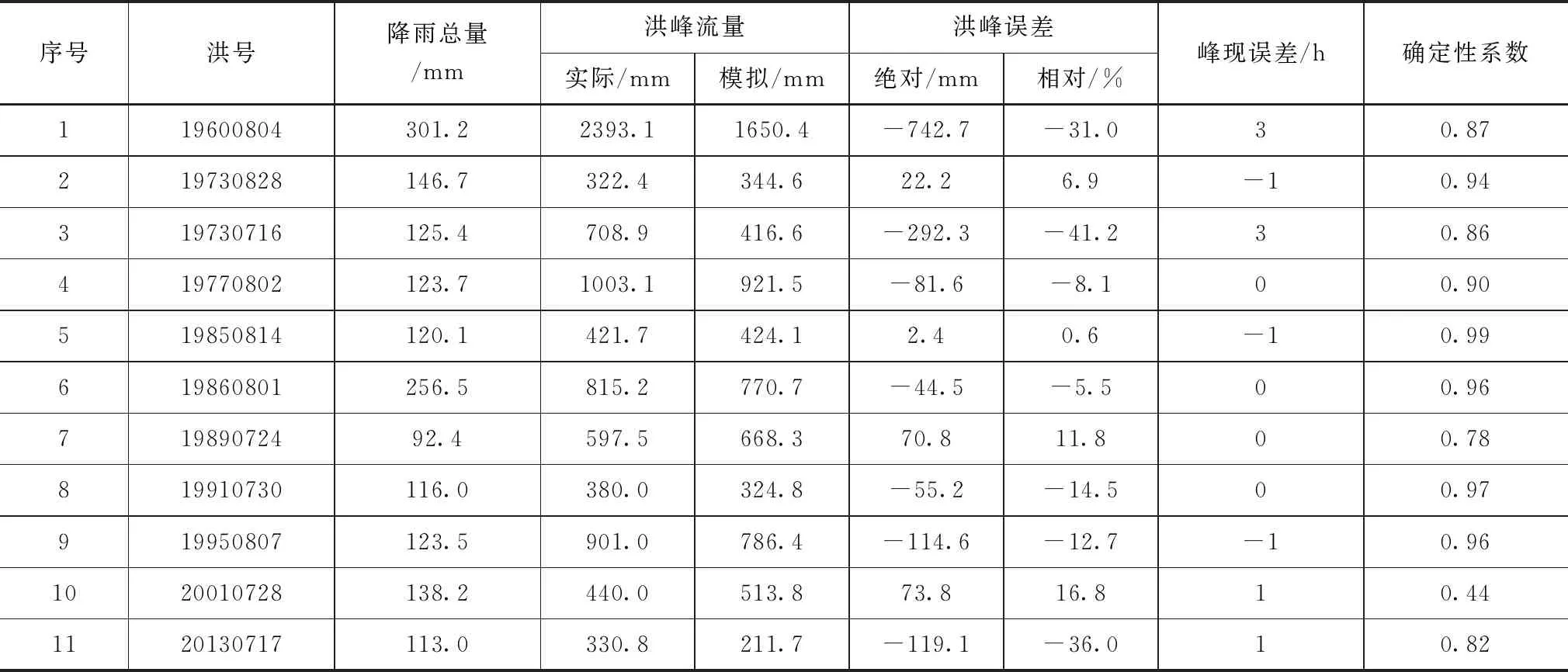
表7 南甸峪水文站汇流模拟结果
参数移值后南甸峪水文站以上流域各场次洪水径流量误差除个别场次洪水外,总体可低于15%,产流计算精度较高,尤其对于降雨强度较高,过程雨量较大的场次洪水其产流模拟误差较低,而对于前期影响雨量较高且过程降水量较小的场次洪水,其产流模拟误差相对较大,而对于“20010728”场次洪水而言,通过调查该场次洪水由于人类活动影响使得其产流量实际值有所偏低。
从汇流模拟结果来看,除个别场次洪水外,南甸峪水文站以上流域在进行参数移值后其汇流模拟精度也较高,峰现时间以及洪峰流量模拟值和实际值之间的误差均在水文情报预报规范的误差允许范围内,尤其对场次洪水的洪峰流量具有较高的模拟精度,整体的平均确定性系数模拟精度较高。对于“19730716”场次洪水,通过降雨资料可以看出降雨中心区域首先在南甸水文站下游,然后才转移到南甸水文站上游,降雨分布在时间上和空间上都不均匀,这就导致了实际洪峰出现时间较模拟洪峰出现时间较早,使得参数移值后模型模拟拟合度较低。
4 结论
(1)通过主成分聚类方法对流域下垫面和水文特征指标进行特征值的分析和处理,从而确定参考站和中小河流站点的相似分组,该方法可综合考虑流域许多指标之间的相关性,使得参数移值更为科学,可推广和应用于构建无资料地区中小河流预报方案。
(2)对于无径流观测资料的中小河流站点其年径流深指标值可通过区域径流系数等值线图,结合年降水量进行分析得到。年径流深、年降水量、森林率、流域面积具有较高的关联度,聚类分组内的站点空间属性具有差异性。
(3)无资料地区参数移值后洪水和模拟的精度受流域属性指标选取的直接影响,因此其流域特征指标的分层分类还有待研究,尤其是各指标与模型参数之间的响应机理还要深入分析,从而建立一套可以在全流域参数移值聚类指标选取的标准体系。
