基于SOM-K-means 算法的商品评论研究
2021-10-28顾亦然陈禹洲
顾亦然,陈禹洲
(南京邮电大学自动化学院、人工智能学院,江苏南京 210046)
0 引言
人们平时通过电商平台购物,看到愿意购买的商品时,通常会想要查看这件商品的具体信息,如颜色种类、尺寸大小及商品评论等。而很多商品的评论信息数量实在太大,并且会有各种虚假信息,查看及筛选颇为费时耗力。一些电商平台很贴心地给出了评价标签,将所有的评论信息聚类成几个评价标签,让用户查看时一目了然,并且对这件商品有一个直观的印象。消费者也可以单独查看某个评论标签下的所有评论信息,再决定是否购买商品,而这也是商家看重评论的重要原因。
评论信息中的有用词汇,一般都为情感词,因而需要对情感词进行提取,然后聚类,从而形成评价标签。因此,选择合适的聚类方法十分重要。
常用的文本聚类算法包括K-means 聚类算法、层次聚类算法、密度聚类算法,以及神经网络模型聚类算法等。K-means 是情感词聚类的经典算法,在聚类分析中经常被使用的一种迭代求解的无监督学习算法。该算法具有结构简单、运行速度快等特点,对大数据分析的效率较高、可伸缩性较强,因此常被用于数据挖掘任务中。但缺点也较为明显,K-means 算法在训练过程中容易陷入局部最优解,其聚类个数需要人为确定,并且聚类个数和初始聚类中心对整个K-means 算法的结果影响较大。
SOM 是自组织映射算法,是一种无导师学习网络,它通过自动寻找文本中的内在规律和本质属性,自组织、自适应地改变网络结构和参数。其目标是用低维空间的点表示高维空间中的所有点,并且尽可能地保持点与点之间的距离关系。
关于SOM 算法和K-means 算法的研究较多,并取得系列成果。Xu 等[1]提出一种面向混合属性的动态SOM 模糊聚类算法,并将其用于移动用户分类,验证了该算法的有效性;Yanik 等[2]使用SOM 算法生成客户集群,利用信用卡交易所得的消费模式进行客户聚类,得到了较好的聚类效果;尹积栋等[3]通过句法结构分析方法,在降低文本复杂度的基础上,通过K-means 算法挖掘信息,解决了K-means 算法容易陷入局部最优的问题;张素荣[4]在智能客服问答系统中采用K-means 算法和朴素贝叶斯分类算法,提高了系统效率和准确率;任春华等[5]提出基于LRFAT 模型选取K值,以改进K-means 算法,对汽车客户进行细分,并通过实验验证了其有效性;周本金[6]提出一种最大化减少当前误差平方和的K-means 初始聚类中心优化方法,实验结果表明,改进后K-means 算法的准确率和召回率等都得到了显著提高;Shi 等[7]使用K-means++算法,先对文本进行预处理聚类,再将聚类结果进行LDA 模型算法的聚类训练,从而得到更准确的主题词汇。
将SOM 算法与K-means 算法相结合,也取得良好应用效果。Mahjoub 等[8]运用SOM 算法与K-means 算法建立客户信用评分混合模型;赵凯等[9]提出基于SOM 和K-means聚类的风电场多机等值建模方法;赵文均[10]对基于SOM 网络改进的K 均值算法效果进行分析,为后续算法的进一步改进提供了基础;周欢等[11]应用SOM+K-means 算法对某地区电信家庭客户数据进行分析,具有较好的聚类结果;张石[12]将SOM 算法和K-means 算法用于银行客户细分,并通过实验验证了该算法能为不同客户群体提供个性化营销策略;李昌华等[13]为了解决非精确图匹配算法在应用上的局限性,采用SOM 算法和K-means 算法,结果表明这种方法可以有效提升准确率;周冰钰等[14]结合SOM 算法和K-means 算法对用户互动用电行为进行分析,实验表明,该算法可以更加精确识别和快速聚类互动用电行为;王育军[15]根据合作学习者的个性化特征,提出SOM 算法与Kmeans 算法进行分组,提高了合作学习者的学习效果;任云等[16]提出基于K-means 聚类的三维SOM 初始化模式库算法,实验结果表明,该算法减少了搜索时间,增加了信源的匹配度,提高了整体性能;赵翠翠等[17]利用K-means 和SOM 两种算法对商品评论分别进行聚类分析,通过实验得出了小规模样本中,SOM 聚类比K-means 聚类分布得更加均匀;赵莉华等[18]提出采用K-means 与SOM 神经网络相结合的混合算法,对断路器操作机构进行状态评估,混合算法模型在计算速度和聚类准确率上都优于其本身的两种模型;汪海涛等[19]提出一种分布式自组织映射(DSOM)结合K-均值聚类的网络流量攻击检测方法,实验表明,该方法能有效监测异常流量,提高了系统对攻击流量的反应速度,节省了系统开销;郑恒杰等[20]使用isolation forest 算法和SOM 算法对交通数据进行预处理,再通过K-mesns 聚类算法归类并添加标签,最后通过BP 神经网络构建分类器,实现了对驾驶员驾驶行为的分类和评价,实验表明,该算法能客观、有效地评价驾驶员的驾驶行为。
综上所述,基于SOM 算法改进的K-means 算法一般用于客户分类、寻找机械故障、防止网络入侵等方面,应用于商品评论的则很少。市场上普遍的聚类算法是LDA 算法,这种算法精度高,但运行时间很慢。针对该问题,本文采用SOM-K-means 模型对收集到的商品评论信息作情感词聚类,并对其结果进行可视化分析。
1 算法描述
1.1 SOM 算法
SOM 算法是一种无监督学习的神经网络算法,具有良好的自组织性和可视化等特征,由输入层和竞争层(输出层)组成。输入层主要负责接受外界信息,将输入的数据向竞争层传递,竞争层主要对数据进行整理训练,并根据训练次数和邻域的选择将数据划分为不同的类。SOM 神经网络的典型拓扑结构如图1 所示(彩图扫OSID 码可见,下同)。
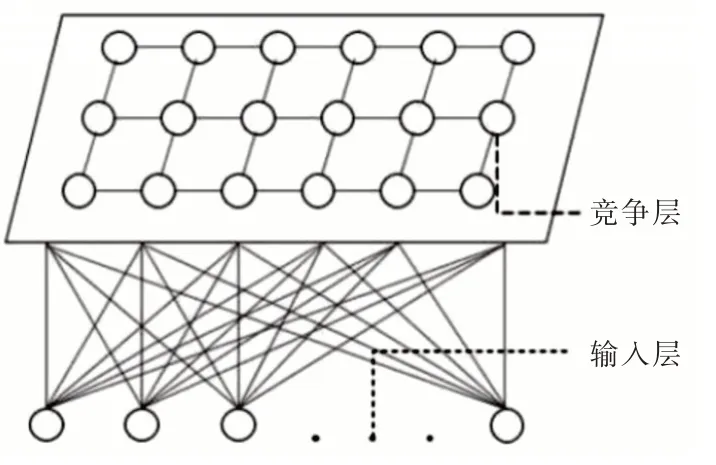
Fig.1 Typical topology structure of SOM neural network图1 SOM 神经网络的典型拓扑结构
算法步骤为:
(1)网络初始化,对输出层每个节点权重Wj随机赋予较小初值,定义训练结束条件。
(2)从输入样本中随机选取一个输入向量Xi,求Xi中与Wj距离最小的连接权重向量,如式(1)所示。
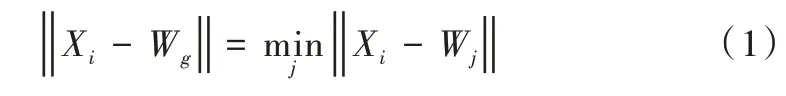
式中,‖ ‖为距离函数,这里采用的是欧式距离。
(3)定义g 为获胜单元,Ng(t)为获胜单元的邻近区域。对于邻近区域内的单元,按照式(2)调整权重使其向Xi靠拢。
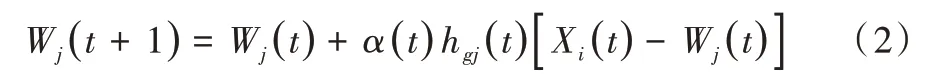
式中,t 为学习次数,α(t)为第t 次学习率,hgj(t)为g 的邻域函数。
(4)随着学习次数t 的增加,重复步骤(2)及步骤(3),当达到训练结束条件时停止训练。
(5)输出具体聚类数与聚类中心。
1.2 K-means 算法
K-means 算法基本原理是用距离函数作为相似度指标,将距离相近的样本对象划分为同一类别(称为“簇”),缺点是需要给定指定的聚类数和聚类中心,否则容易导致算法不收敛或者局部最优化。
算法步骤为:①随机选取K 个点作为初始聚类中心;②将其余样本数据根据他们与初始聚类中心的欧式距离划分给距离最小的初始聚类中心,形成新的簇;③重新计算每个簇的均值,作为新的聚类中心;④循环步骤②和步骤③,直至达到某个终止条件;⑤输出样本具体聚类信息。
1.3 SOM-K-means 算法
SOM 算法与K-means 算法比较如表1 所示。

Table 1 Comparison of the two algorithms表1 两种算法比较
SOM 算法不同于K-means 算法,它不需要提前确定聚类数,并且可以自动对输入数据进行聚类,但在训练数据时可能出现有些神经元始终不能胜出,导致分类结果不准确。K-means 算法优点较多,缺点是初始聚类数和聚类中心很难提前确定。本文提出SOM-K-means 算法,将SOM与K-means 算法结合,既解决了K-means 算法需要提前设定聚类数和聚类中心的问题,又克服了SOM 算法中分类结果不准确的缺陷。
SOM-K-means 算法步骤如下:
(1)赋予输出层每个节点的初始权值,定义训练终止条件;
(2)计算训练数据集中每个样本与每个输出节点之间的相似度,通常取欧式距离,找出距离最近的样本节点;
(3)根据邻域函数判断获胜单元,然后调整它的权值;
(4)重复训练,直到达到其最大训练长度,并满足训练终止条件,得出聚类数及聚类中心;
(5)将得到的聚类数作为k值,得到的聚类中心作为初始聚类中心;
(6)将样本数据根据他们与初始聚类中心的欧式距离,划分给距离最小的初始聚类中心,形成新的簇;
(7)重新计算每个簇的均值,作为新的聚类中心;
(8)循环步骤(6)和步骤(7),直至每个聚类不再发生变化;
(9)输出具体的聚类信息。
该算法在保持SOM 网络自组织特性的同时,将SOM 算法和K-means 算法相结合,在分类结果的准确度和运算效率上都有了较大提高。
2 聚类实验
2.1 实验流程
为了验证SOM-K-means 算法是否达到预期效果,所采用的实验步骤为:①选定一个电商平台中的某个商品,运用软件八爪鱼采集该商品评论信息,并以文本格式保存;②针对采集到的数据,建立一个自定义词表,词表里存放一些网络词汇和网络用语;③在网上下载一个较为权威的停用词表,然后对文本里的数据进行切词,去除停用词,保留自定义词句,以及对词句的向量化表示;④将得到的数据进行聚类,并将聚类结果进行可视化分析。
实验流程如图2 所示。

Fig.2 Experimental procedure图2 实验流程
2.2 数据准备及处理
本文选取淘宝网上销售的一款耳机作为研究对象,将其2 000 条评论数据下载下来,并将采集到的数据以文本形式保存,构成语料库;从网上下载停用词表,再自定义需要用到的情感词,如表2 所示,以文本形式保存。用Python导入语料库,使用Jieba 分词的精确模式,完成去除停用词表中的词语、加载自定义词表、去除特殊字符等操作,得到结果如表3 所示。

Table 2 Partial data of the custom word table表2 自定义词表部分数据

Table 3 Partial results of emotion vocabulary表3 情感词表部分结果
运用Python 中开源的第三方工具包gensim构建词向量模型,然后将切好的词句放入模型中进行向量化并加以训练,最后得到基于该模型的情感词向量,部分情感词向量如表4 所示。
2.3 SOM 聚类实验
在SOM 聚类实验开始时,需要对SOM 模型进行初始化,设置不通邻节点的半径为0.3,学习率为0.5,数据集中的特征数量为2。模型建立好以后,输入gensim 训练好的情感词向量,迭代次数为2 000 次,进行训练。SOM 模型最后将输入的词向量自动聚为5 类,得到的聚类数为5,聚类中心为[2.113 350 48,0.794 973 43]、[-0.578 455 51,1.512 801 01]、[0.237 874 86,1.228 131 42]、[0.586 385 88,0.942 294 46],可视化结果如图3 所示。

Table 4 Emotional word vectors表4 部分情感词向量

Fig.3 SOM clustering visualization results图3 SOM 聚类可视化结果
2.4 SOM-K-means 聚类实验
K-means 聚类需要指定的聚类数和聚类中心以得到具体分类信息,而上述SOM 聚类可以得到大致的聚类数和聚类中心,将其作为K-means 算法的初始输入,最后得到具体情感词的分类信息。
将聚类数5,聚类中心[2.113 350 48,0.794 973 43]、[-0.578 455 51,1.512 801 01]、[0.237 874 86,1.228 131 42]、[0.586 385 88,0.942 294 46]作为初始值传入K-means 算法,可视化结果如图4 所示。
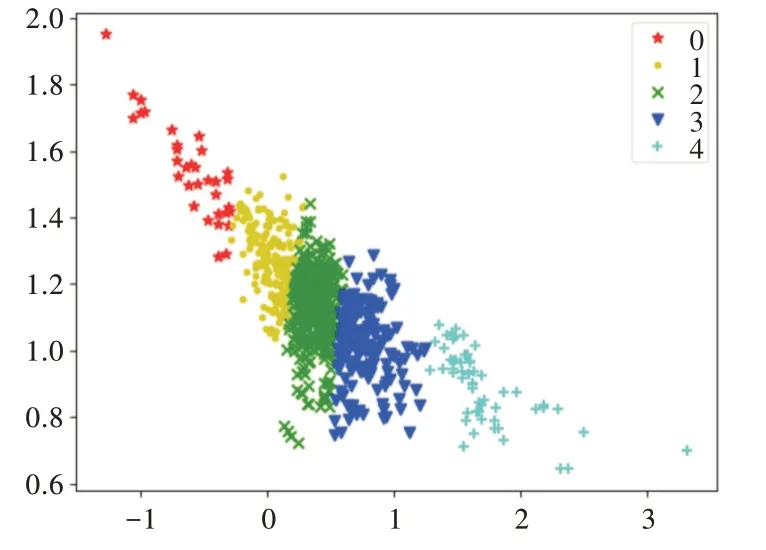
Fig.4 K-means clustering visualization results图4 K-means 聚类可视化结果
K-means聚类得到的聚类中心为[-0.597 892 767 272 727 2,1.542 160 406 060 606 2],[0.043 389 711 540 358 99,1.267 052 688 717 948 7]、[0.372 023 790 029 325 56,1.127 026 021 642 228]、[0.774 095 899 570 552 6,1.020 623 237 239 263 6]、[1.707 220 908 928 571 3,0.890 265 547 678 571 2],对应的簇也可得出。本文是为了得到商品评论中的用户评价标签,取距离聚类中心最近的样本点,最后得到的结果是:重低音、高端、浑厚、价格便宜、音质不太好。与淘宝网上的评价标签类似,具体如表5所示。
在大型购物APP 中,商品评论标签一般都是采用LDA算法聚类得到,LDA 算法是目前市场上的常用算法,但是它在保证自己准确率的同时,运行效率却很低。
SOM-K-means 算法与LDA 算法运行时间比较如图5所示。可以看出,随着数据量的不断变大,LDA 算法运行时间也明显变长,而SOM-K-means 算法运行时间基本保持稳定,增长并不明显,且十分迅速。在数据量为1 000、3 000、5 000、7 000、10 000 时,LDA 算法运行时间分别是SOM-K-means 算法的2、11、12、16、17 倍。
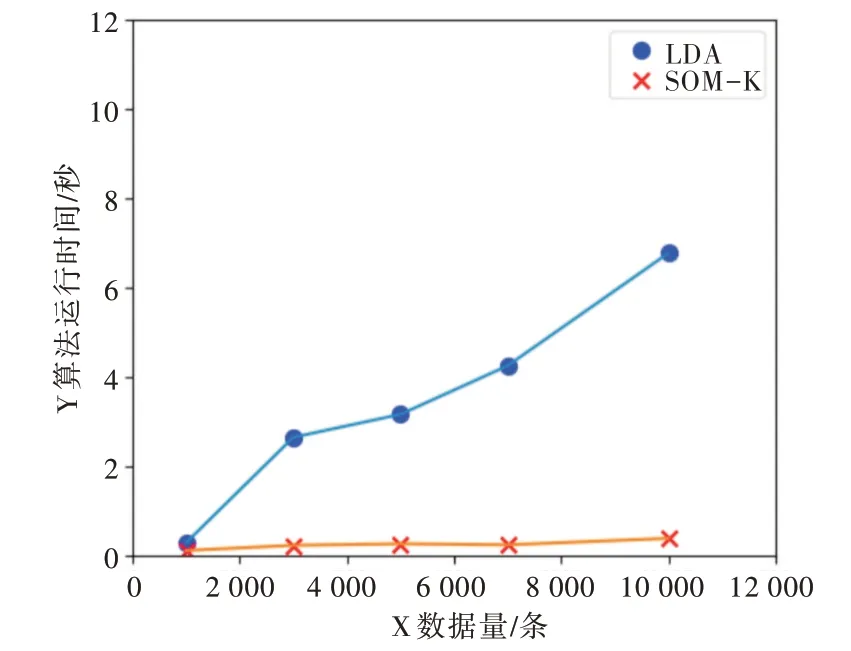
Fig.5 Comparison of running time of SOM-K-means and LDA algorithm图5 SOM-K-means 与LDA 算法运行时间比较
2.5 标签应用
本文根据SOM-K-means 算法聚类出来的评论标签,可应用在多种商品评论中,因实验数据有限,可以得出在数据量较少、自定义词表比较完善的情况下,使用SOM-Kmeans 算法能得出比较满意的聚类结果,并且得益于Kmeans 算法本身优点,相较于市场上常用的LDA 聚类算法,SOM-K-means 算法运行时间要快得多。在追求效率的小型购物软件中,会得到很好的应用。
3 结语
通过SOM-K-means 算法模型对商品评论信息进行聚类实验分析,发现该算法有较好的聚类效果。该算法模型结合了两种算法的优点,聚类过程减少了人工干预,具有较强的自适应性。SOM 算法首先算出聚类数和聚类中心,再将其作为初值传入给K-means 算法,这样可加速Kmeans 算法的收敛速度。该混合算法在得出令人比较满意的聚类结果的同时,运行效率也比市场上主流算法有了很大提高。
虽然SOM-K-means 算法有着较好的聚类效果,但自定义词表对于本文聚类效果有着重要影响。由于网络流行词越来越多,需要人工维持自定义词表更新,比较耗费人力。本文使用的自定义词表有限,想要获得更加精确的聚类结果,需要更多的评论数据并不断更新自定义词表。
