基于语音分离的人工设计特征、参数化特征和可学习特征的比较
2021-10-27朱文博王谋张晓雷SusantoRahardja
朱文博,王谋,张晓雷,Susanto Rahardja
(西北工业大学航海学院智能声学与临境通信研究中心,陕西西安 710072)
1 引言
语音分离的目的是将多个音源的混合语音分离成其对应成分。在本文中,我们研究了基于深度学习的说话人无关情况下的语音分离,其中说话人无关的情况是指训练时所用到的说话人与测试中的说话人可以不相同[1]。Hershey 等人首先提出用深度聚类的方法来解决语音分离问题[2]。在此之后,针对语音分离问题又提出了多种方法,例如置换不变训练[3-4],深度吸引子网络[5]。在这些方法中,被广泛应用的声学特征是短时傅里叶变换的幅度谱(short -time Fourier transform,STFT)。然而,在从分离后的幅度谱恢复成时域信号的过程中,所用到的是含有噪声的相位谱,这会导致得到次优的性能。
为了克服这一缺陷,数据驱动的从时域到时频域变换的可学习特征成为了新的趋势。其中代表性的就是一维卷积滤波器(1D-conv)[6-9]。由于该变换是与分离网络联合训练的,并且不需要额外的人工操作,因此该变换相比于STFT来说使语音分离的性能得到了提升。在这些时域方法中,Conv-Tasnet在帧长设置为仅2 毫秒的低时延情况下得到了杰出的分离性能,从而受到了广泛的关注。
近期有一些工作旨在研究Conv-Tasnet 的声学特征。例如,Ditter 和Gerkmann 用人工设计特征[10],即多相位gammatone滤波器组(MPGTF)来代替Conv-Tasnet中编码器部分的可学习特征,并在尺度无关信噪比(scale-invariant source-to-noise,SI-SNR)上带来了提升。Pariente 等人将参数化滤波器扩展为了复值的解析滤波器[11-12],同时他们也提出了类似的一维卷积滤波器的解析版本。解析的一维卷积滤波器相比于原始的Conv-Tasnet 也有性能上的提升。上述结果表明,人工设计特征和参数化特征与目前最先进的可学习特征相比也具有竞争力。
然而,目前缺少对于可学习特征,人工设计特征以及参数化特征的比较。受到用人工设计特征来代替编码器或解码器的可学习特征的启发,在这篇文章中我们将三种类型的特征在Conv-Tasnet 框架下进行了比较。同时为了了解这三种特征之间的联系,我们将多相位gammatone 滤波器组和参数化特征进行了结合,提出了参数化多相位gammatone 滤波器组(ParaMPGTF)。其中,ParaMPGTF的中心频率和带宽将与分离网络联合训练。我们在WSJ0-2mix 数据集[2]上比较了STFT、MPGTF、ParaMPGTF 以及可学习特征。实验结果表明:如果解码器是可学习特征,将编码器设置为参与比较特征中的任意一种都产生了相似的性能。我们还比较了将STFT、MPGTF、ParaMPGTF 作为编码器,它们的逆变换作为解码器。实验结果表明:我们所提出的ParaMPGTF 比其他两种人工设计特征的性能要好。
本文将以下面所述进行组织编排。第二节介绍了比较的框架以及所提出的ParaMPGTF,第三节展示实验结果。第四节总结了我们的发现。
2 方法
2.1 问题描述

本文研究的基础分离框架是Conv-Tasnet。如图1 所示,它由三个主要部分构成:编码器,分离网络和解码器。编码器和解码器采用小帧长来显著降低系统时延。编码器和解码器是可学习的一维卷积滤波器,他的作用是在时域信号和时频特征之间进行类似的转换。分离网络是一个由一维扩张卷积块堆叠成的全卷积的分离模块[13-14],以SI-SNR 为损失进行优化。其作用是为每个音源产生一个掩模。
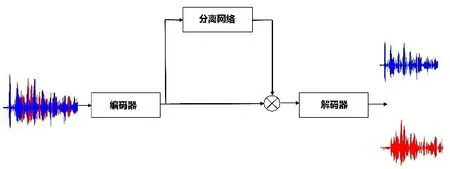
图1 Conv‐Tasnet的框架图
2.2 比较框架

2.3 参数化多相位gammatone滤波器组


3 实验及结果
3.1 数据集
我们使用WSJ0-2mix 数据集对双说话人语音分离性能进行比较[2]。它包含了30个小时的训练数据,10 小时的验证数据以及5 小时的测试数据。WSJ0-2mix中的混合语音是通过在Wall Street Journal(WSJ0)训练集si_tr_s 中随机选择不同的说话者和句子产生的,并将它们以-5分贝到5分贝范围中的随机信噪比混合。测试集中的句子来自于WSJ0数据集中si_dt_05 和si_et_05 中16个训练中未用到的说话人。WSJ0-2mix中所有的语音均被重采样至8000赫兹。
3.2 实验设置
该网络在4秒长的片段上进行了200个周期的训练。优化器采用Adam 优化器,初始学习率为0.001。如果在验证集上连续5个周期性能没有提升则学习率减半。同时,当验证集上的性能在过去的10个周期内都没有提升时,网络训练将会被停止。网络的超参数设置遵循Conv-Tasnet 中的网络超参数[10],其中滤波器数目为512。时序卷积网络(Temporal Convolutional Networks,TCN)的掩模函数分别被设置为sigmoid 函数和修正线性单元(rectified linear unit,Re-LU)。对于ParaMPGTF,我们将阶数设置为2,幅度设置为1。我们将和的初始值设置为其经验值,即我们将SI-SNR 作为评价指标。所报告的结果均是3000 句测试混合语音的平均结果。
3.3 解码器为可学习特征时的结果
我们首先比较了解码器为可学习特征,编码器为STFT,MPGTF,ParaMPGTF和可学习特征时的情况,表1 列出了比较结果。从表1 中可以看出,这四种特征并没有产生很大的性能差异。如果我们仔细比较,我们发现STFT特征在测试集和验证集都达到最高的性能。MPGTF 和ParaMPGTF 性能比较接近,ParaMPGTF 在验证集上略好于MPGTF,而在测试集上略差于MPGTF。
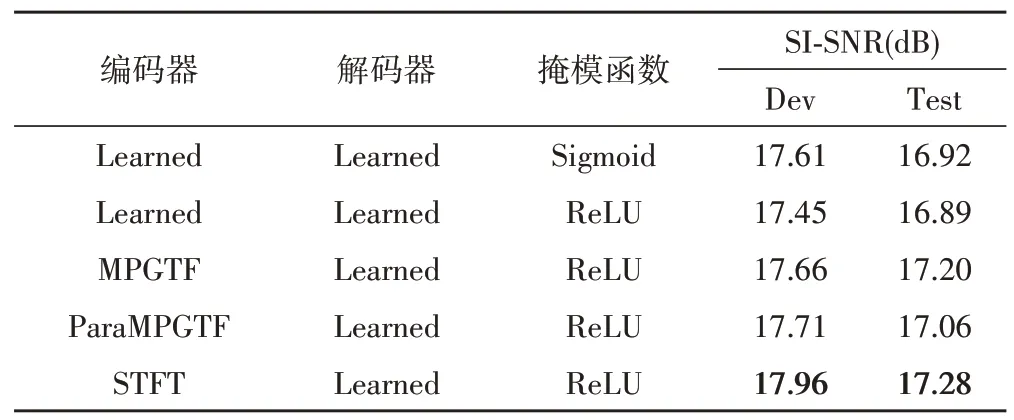
表1 当解码器为可学习特征时,不同特征作为编码器的比较
3.4 解码器为编码器逆变换时的结果
图2 所示的是用MPGTF,ParaMPGTF,STFT 和可学习特征作为编码器,解码器为可学习特征的幅度谱图,由于STFT 的实部部分和虚部部分有相似的形状[17],因此我们这里只绘制了从1 到256 频点的STFT。滤波器在0 到4000 赫兹的范围内均匀分布。从图中可以看出,ParaMPGTF 和MPGTF 的幅度谱图是相似的。这一现象不仅说明了它们的性能相似,而且也说明了参数化特征能够被成功地优化。不仅如此,图2也表明了(1)MPGTF是一个良好的人工设计特征,(2)可学习的解码器能够有效的学习到编码器的反变换。表2 列出了人工设计特征MPGTF 的和以及ParaMPGTF 中优化得到的和。从表中我们可以看出两组参数十分接近,这也进一步解释了MPGTF和ParaMPGTF相似的性能。
表2 当解码器为可学习特征时,MPGT和ParaMPGTF中和的比较

表2 当解码器为可学习特征时,MPGT和ParaMPGTF中和的比较
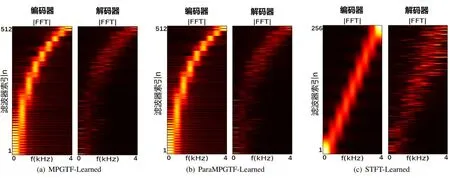
图2 不同设置的编码器和解码器的幅度谱图的可视化。左边为基于MPGTF的编码器,中间为基于ParaMPGTF的编码器,右边为基于STFT的编码器。
在该实验中,我们将分别将编码器设置为STFT,MPGTF,ParaMPGTF,并将解码器设置为其对应的逆变换。表3 列出了STFT,MPGTF,ParaMPGTF 以及它们逆变换分别作为编码器和解码器的实验结果。从表中我们可以看出,这三种比较方法的性能大体上是相似的。

表3 编码器和解码器为不同特征及其逆变换时的比较
如果我们仔细研究细节,我们发现在测试集和验证集上,我们所提出的ParaMPGTF 都达到了最好的性能,这也表明了参数化训练的策略有改进传统人工设计特征的潜力。图3展示的是将解码器为编码器的逆变换时所训练的模型在验证集上的收敛曲线。图中我们可以发现可学习特征比人工设计特征和参数化特征收敛的更快。尽管人工设计特征和ParaMPGTF 在前期以相似的速度收敛,然而ParaMPGTF 收敛的更快。

图3 不同编码器‐解码器的收敛曲线
4 结论
在本文中,我们提出了一种参数化的多相位gammatone 滤波器组。Para MPGTF将MPGTF中的核心参数与网络进行联合训练。我们还在同一个实验框架中比较了人工设计特征,参数化特征和可学习特征。据我们所知,这是第一个将三种特征放在一起比较。所比较的特征有STFT,MPGTF,ParaMPGTF 和可学习特征。实验结果表明:当解码器设置为可学习特征时,这四种特征的表现相似。STFT 比其他特征的性能稍好。当解码器设置为编码器的逆变换时,ParaMPGTF比其他人工设计特征的性能好。
