基于改进二叉树支持向量机的低压台区用户拓扑关系识别*
2021-10-26李晓蕾牛斌斌袁少光毛万登
李晓蕾,刘 昊,牛斌斌,夏 越,袁少光,毛万登
(1.国网河南省电力公司,河南 郑州 450000;2.国网河南省电力公司电力科学研究院,河南 郑州 450052;3.中国农业大学信息电气工程学院,北京 100083)
准确完整的拓扑关系是台区精益化管理的基础,尤其是用户与供电变压器隶属关系以及所连接变压器相序,对于客户报修定位、线损管理、台区变压器三相不平衡治理具有重要作用。部分老旧小区、沿街门面线路复杂,同时不法用户违约用电,私自搭接线路,台区用户拓扑关系常常不准确甚至缺失,电网工作人员在不停电状态下难以识别台区的拓扑关系。
当前,台区拓扑关系识别主要集中在研制基于端对端通信的设备或装置识别用户与供电变压器隶属关系以及所连接变压器相序。文献[1]提出了一种基于电力线载波通信的台区拓扑关系识别方案。文献[2]提出了基于电力载波信号法与脉冲电流法相结合的台区拓扑关系识别。文献[3]提出了基于工频通信技术的台区拓扑关系识别。基于端对端通信的设备或装置开展台区拓扑关系识别,需要配电运检人员手持设备逐个台区现场核查,耗费大量人力、物力,效率低下,无法开展实时大批量的台区拓扑关系数据核查。
随着用电信息采集系统的推广应用,电网公司积累了海量变压器和用户监测数据。充分挖掘用电信息采集系统的量测类大数据价值,从配电变压器、用户的电压、电流异常现象着手,快速识别台区拓扑关系问题数据是切实可行的。因此,提出了一种改进二叉树支持向量机的低压台区用户拓扑关系识别方法,基于电压曲线波动相似性大小快速识别用户连接变压器相序,以及与变压器的连接关系是否正确。经验证,该方法所需人力成本低,准确性高,可操作性强。
1 用户电压曲线及变压器电压曲线
低压台区由于用户用电的随机性,电压时刻在波动,电气距离较近的用户电压曲线常常比较相似,而电气距离较远的用户电压曲线相似度比较低。相应地,连接在供电变压器同一个相序的用户电压曲线波动比较相似,不同相序的用户电压曲线波动相似性比较差;连接在同一个供电变压器的用户电压曲线波动比较相似,不同供电变压器的用户电压曲线波动相似性比较差。因此,可以通过比较用户与供电变压器A、B、C 三相电压曲线相似性大小识别用户与供电变压器隶属关系以及所连接变压器相序。
图1 是2019 年6 月份某天某台区用户与供电变压器三相电压曲线。用户1、2、3、4、5 是某台区的5 个用户,其中用户1 和2 连接在变压器A 相,用户3、4 连接在C 相,用户5 与变压器隶属关系错误。从图1 可以看出,用户1、2 电压曲线波动比较相似;用户3、4 电压曲线波动比较相似;用户1、3 电压曲线波动相似性较差。用户5 与1、2、3、4 4 个用户电压曲线波动相似性都相对较差。
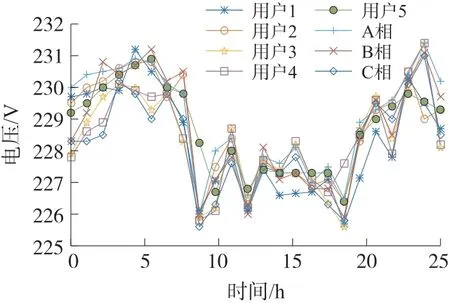
图1 某台区用户与供电变压器三相电压曲线
皮尔逊相关系数用来衡量2 个连续变量之间线性关联性的程度,给定2 个连续变量x和y,皮尔逊相关系数p定义如下:

上述台区用户与变压器三相电压曲线之间的相关系数矩阵如表1 所示,可以看出用户1、2 与A 相电压曲线之间相关系数较大,用户3、4 与C 相电压曲线之间相关系数较大,用户5 与三相曲线相关系数都较小。因此,智能电表电压序列数据之间的相关系数可以有效度量二者之间的相似性。

表1 某台区用户与供电变压器三相电压曲线相关系数
2 用户与变压器电压曲线相关系数
通过大量样本分析,如果只是通过某一天用户与供电变压器三相电压曲线的相关系数大小识别台区拓扑关系,准确性较低。需要统计一段时间内用户与供电变压器三相电压曲线的相关系数大小,通过相关系数分布识别台区拓扑关系。
(1)用户与变压器隶属关系正确
图2 为某台区用户与变压器A、B、C 三相电压曲线相关系数曲线,该用户与三相电压曲线相关系数在一个月内均大于0.6,而且该用户与A 相电压曲线相关系数普遍高于与B、C 两相电压曲线,判定该用户连接变压器相序为A 相。经过现场核查比对,该用户确实为A 相用户。
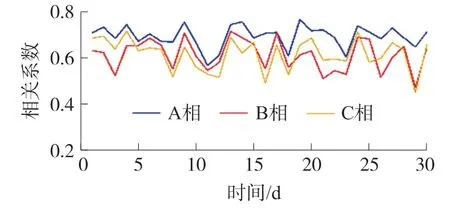
图2 某台区用户与变压器三相电压曲线相关系数曲线
(2)用户与变压器隶属关系错误
图3 为某台区用户与变压器A、B、C 三相电压曲线相关系数曲线,该用户与三相电压曲线相关系数在一个月内均小于0.5,判定该用户与变压器隶属关系错误。经过现场核查比对,该用户与变压器隶属关系确实错误。
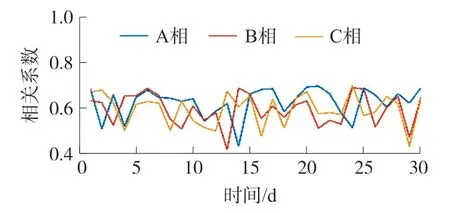
图3 某台区用户与变压器三相电压曲线相关系数曲线
基于用户与变压器三相电压曲线相关系数分布可以开展低压台区用户拓扑关系识别,但是在具体识别用户与供电变压器隶属关系以及所连接变压器相序时,需要设置2 个阈值:相关系数阈值和频率阈值,一个月内用户与变压器某相电压曲线之间相关系数大于相关系数阈值,频率大于频率阈值时,判定用户与变压器该相连接。2 个阈值设置不合理常常会导致识别效果不佳。
3 基于支持向量机的台区拓扑关系识别
支持向量机(Support Vector Machine,SVM)是一种典型的机器学习算法模型。相对于其他分类方法,主要优点如下:可以解决非线性、高维问题,可以解决小样本的机器学习问题;具有较好的推广性;避免了选择局部极小点问题。但是最初的SVM 是用来解决二类分类问题的,并不能直接运用在多类分类问题上。而SVM 决策树解决了多类分类问题,通过构造一系列的二类分类SVM,并把它们组合在一起来实现多类分类。针对低压台区用户拓扑关系识别,采用基于二叉树的SVM 多类分类方法,该方法优于其他多类分类方法,具有较好的推广性。
3.1 支持向量机原理
给定样本集合D={(x1,y1),(x2,y2),…,(xm,ym)},yi∈{-1,+1},SVM 的基本思想是在样本空间构造一个划分超平面使得所分样本之间的间隔达到最大,具体如图4 所示。
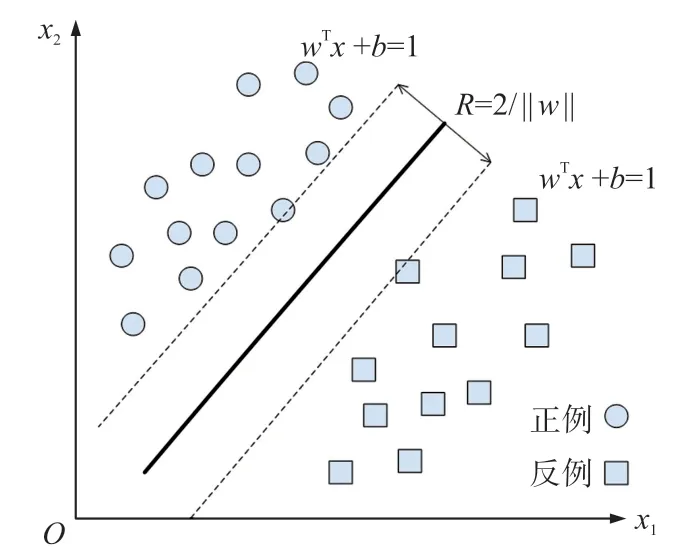
图4 支持向量机示意图
当样本线性可分时,划分超平面表达式为:

式中:w=(w1;w2;…;wd)为法向量,b为位移。为最大化间隔,式(2)转化为:
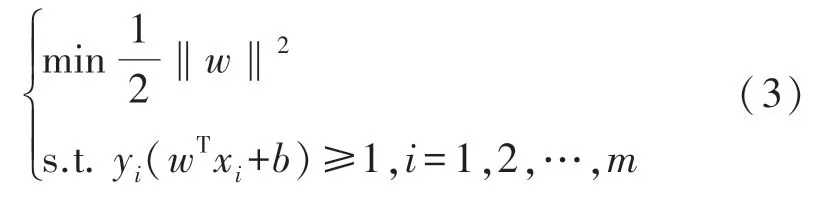
当样本线性不可分时,需要将样本从原始空间映射到更高维空间使得样本线性可分。设φ(x)是x映射后的特征向量,划分超平面表达式为:

为最大化间隔,式(4)转化为:

引入拉格朗日乘子,其对偶问题为:

式中:αi,αj是对偶最优化问题的解,(xi,yi)和(xj,yj)是两个不同训练样本。
φ(xi)Tφ(xj)通常求解比较困难,需要寻找一个函数K(xi,xj)=<φ(xi),φ(xj)>=φ(xi)Tφ(xj)。式(6)又可重写为:
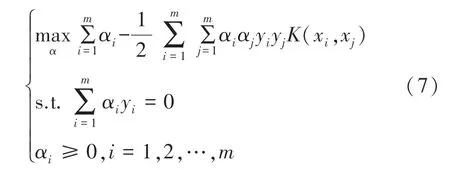
式中:函数K(xi,xj)称为核函数[6-7]。
3.2 基于二叉树的支持向量机多分类方法
在低压配电网中,电气距离越近的负荷电压曲线波动越相似。低压用户电压曲线,如果和供电变压器三相电压曲线相似性都很差,则用户与变压器隶属关系错误。否则,如果与A相电压曲线相似较大,则用户连接在变压器A相,如果与B相电压曲线相似较大,则用户连接在变压器B相,如果与C相电压曲线相似较大,则用户连接变压器C相。
如何根据具体应用构造最优的二叉树是SVM多分类应用领域的一个热点。二叉树的结构直接影响着分类器的分类性能,越靠近根节点的节点分类准确度对整个分类模型的整体性能影响越大,所以靠上的节点应尽量避免分类错误的发生。基于此思想,在构造性能优良的二叉树时,应考虑优先将容易分、不容易出现分类错误的类分出来,之后再分相对较难分的类,使可能产生的错分尽量地远离根节点,使其对整体产生的影响降至最小。因此,采用一种基于样本分布的类间分离性测度。
假设要进行M类分类,样本类别数为M,训练样本集由类Xi,i=1,…,M,ci为通过训练样本计算得出的类中心,Ci=,i=1,…,M;(ni为类中样本的个数),用dij表示类i和j中心间的距离:dij=‖ci-cj‖;
σi为表示类分布的类方差:
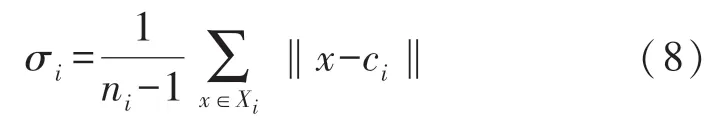
定义类i和j之间的分离性测度sepij:

如果sepij≥1,则类i和j之间无交叠;如果sepij<1,则两类之间有交叠。sepij值越大,代表类i和j之间的分离性越好。
类i的分离性测度sepi为该类与其他类之间的分离性,将类i与其他类间的最小分离性测度作为该类的分离性测度。所得到的分离性测度最大的类即为最容易分的类。
基于改进的决策树多分类支持向量机算法流程如下:
步骤1 计算各类的类中心ci,各类之间的距离dij,类分布的方差σi。
步骤2 根据类方差和类之间的距离计算各类样本数据的类间分离度sepij,并根据定义的类分离度从中选择最小的分离性测度作为该类的分离性测度。
步骤3 对所有类别的分离度进行比较,得到最容易分的类,即分离性测度最大的类,并根据由大到小的顺序进行排列,最终得到所有类别的排列n1,n2,n3,…,nm。
步骤4 在根节点选择分离性测度值最大的n1类作为正样本集,其余各类为负样本集来构造第一个分类器进行分类,然后把总样本集中所有n1类样本删除。同样地,在第二个节点处,将n2类样本作为正样本集,其余的为负样本集,构造第二个分类器,之后将属于n2类的样本删掉。按照此方法依次循环下去,直到将所有的类别都分出来,如果两个类最后算出来的分离性测度值相同,则选择将类标号小的类先分离出来,最终得到改进后的二叉树多类SVM 模型。
采用基于二叉树的SVM 多类分类方法,其多类分类器构造步骤如下:第1 个二类分类器SVM1将与供电变压器隶属关系正确用户、隶属关系错误用户分开;第2 个分类器SVM2将A 相用户与B 相、C相用户分开;第3 个分类器器SVM3将B 相、C 相用户分开。低压台区拓扑关系识别SVM 决策树判别流程如图5 所示。
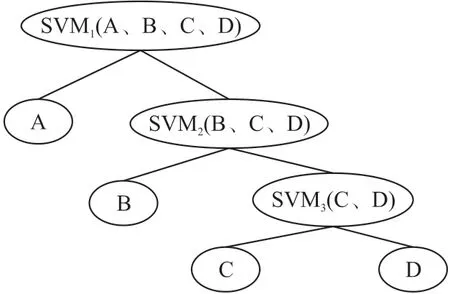
图5 二叉树支持向量机
3.3 基于SMOTE 算法的训练样本抽样
在不平衡数据集的分类中,采样方法通过对小类进行向上采样或者通过小类向下采样来平衡数据集,向下采样删除大类样本,向上采用增加小类样本。
合成少数类过采样技术(synthetic minority oversampling technique,SMOTE)是由Chaplain 等人[17]提出的一种新颖的向上采样,目的是解决小类中样本数量过少的问题。SMOTE 通过合成新的小类样本来减轻类别的不平衡。其主要思想是在相距较近的小类样本之间进行线性插值,从而生成新的小类样本。
SMOTE 通过生成人工样本来对小类样本向上采样。对于每个小类样本x,找到其k个同类最近邻样本。然后根据向上采样的倍率N,随机从中选择N个样本。接下来,在x和被选择的每个近邻样本构成的线段上生成新的样本。例如,假设向上采样倍率为300%,k=5,那么5 个近邻中的3 个样本将被选择,然后分别在每个被选择的近邻样本的方向上生成一个新样本。
其方法可以简单地概括为:对小类的每一个样本x,搜索其k个最近邻;若向上采样的倍率N,则在其k个最近邻随机选择N个样本,记为y1,y2,…,yN;然后在小类样本x与yj之间进行线性插值生成新样本Pj:

式中:rand(0,1)表示(0,1)内的一个随机数。
4 应用实例
所提出的基于改进二叉树支持向量机的低压台区用户拓扑关系识别,在某地市供电公司的营配贯通数据质量核查工作进行了验证和推广应用。
首先,从营销业务系统提取最新用户-变压器隶属关系数据,并获取每个台区所有用户列表;接着,对于每个用户,从用电信息采集系统提取其最近一段时间的电压序列数据,个别时间点电压值为空时根据线性插值法将电压数据填补。某台区变压器及其用户2019 年6 月某天电压曲线如图6 所示。
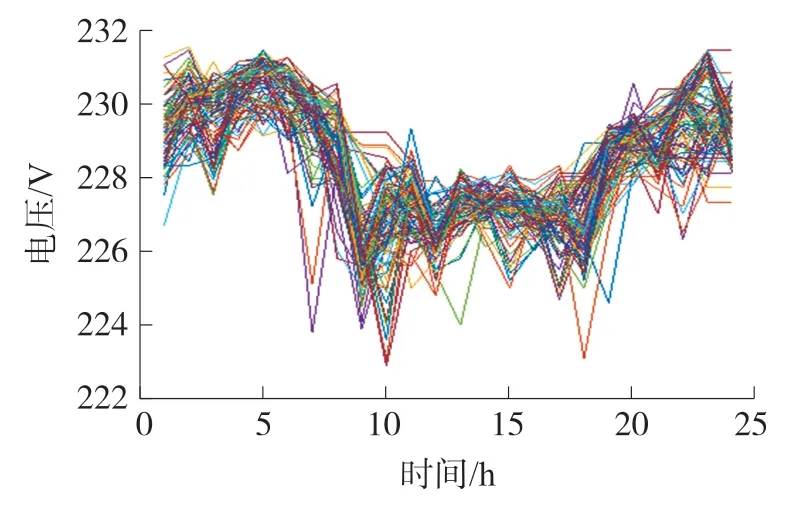
图6 某台区变压器与用户电压曲线
其次,以天为单位根据式(1)计算每个用户与变压器电压曲线之间的相关系数p,上述电压曲线相关系数矩阵如表2 所示。
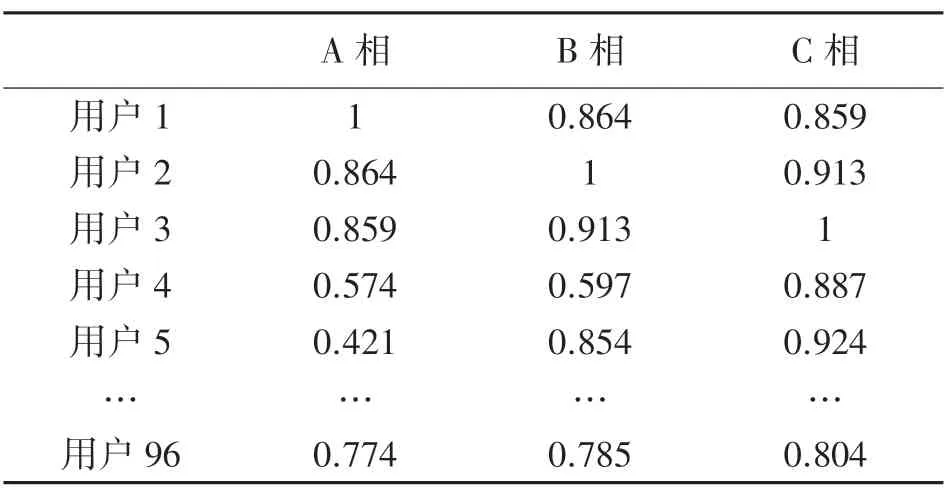
表2 某台区用户与变压器各相电压曲线相关系数矩阵
最后,统计该单位1 月份每个用户与变压器各相的相关系数值p在不同区间出现的频率作为输入属性(属性F1,属性F2,依次类推),其中用户与变压器A 相相关系数r 在[-1,0.2)出现频率为属性F1,在[0.2,0.6)出现频率为属性F2,在[0.6,0.8)出现频率为属性F3,在[0.8,1)出现频率为属性F4,依此类推。将A 相用户标记为A 类,B 相用户类别标记为B 类,C 相用户类别标记为C 类,用户-变压器隶属关系错误的用户标记为D 类作为输出属性,采用改进的二叉树支持向量机构建低压台区拓扑结构识别模型,判断用户与变压器隶属关系是否正确,以及用户所连接变压器的相序。
在模型构建和验证阶段,选择有代表性居民小区手持台区拓扑识别仪识别用户与变压器隶属关系,以及所连接变压器相序,同时通过计算机程序变更部分用户与变压器隶属关系数据,179 个用户-变压器隶属关系错误的用户标记为D 类。分别采用基于决策树、改进的二叉树支持向量机构建低压台区拓扑结构识别模型,判断与变压器隶属关系是否正确,以及连接变压器的相序。低压用户拓扑关系数据是否错误的混淆矩阵如表4 所示。

表4 隶属关系数据是否错误的混淆矩阵
根据所提出的校验方法,利用2019 年4 月份数据对某公司400 个台区44 826 个用户的拓扑连接关系进行识别,结果发现隶属关系错误用户744 个,A 相用户14 636 个,B 相用户14 712 个,C 相用户14 734 个。同时该公司营销人员对判断用户拓扑关系进行了现场核查,发现隶属关系数据错误用户679 个,正确识别A 相序用户14 201 个,B 相用户14 194 个,C 相用户14 224 个,准确率达到96.6%。结果证明与仅仅依靠人力现场巡测相比,该方法是切实有效的。

表3 用户与变压器各相电压曲线相关系数值分布
5 结论
针对当前电网公司用户拓扑连接关系缺失和不准确,提出了一种改进二叉树支持向量机的低压用户拓扑连接关系识别方法。从用电信息采集系统提取待识别台区所有用户最近一段时间的电压序列数据,计算每个用户与变压器A、B、C 三相电压序列数据之间相关系数p;基于电压曲线相关系数值在不同区间出现的频率,采用改进的二叉树支持向量机构建低压用户拓扑连接关系识别模型,可快速识别用户连接变压器相序,以及与变压器连接关系是否正确。经验证,该校验方法所需人力成本低,准确性高,可操作性强。
