战场环境因素对机器视觉目标检测的影响
2021-10-26吴晓强曾朝阳
吴晓强, 曾朝阳
(陆军工程大学 野战工程学院, 江苏 南京 210007)
0 引言
近年来,随着基于深度学习的神经网络技术的引入,机器视觉目标检测的效率和准确率得到大幅度提升,已经越过了应用的技术门槛, 正在广泛领域得到普及和应用。在这样的背景下,基于机器视觉的军事目标检测也日益受到研究者的重视。多年来,军事目标的自动检测技术一直是国防技术领域的研究重点, 但碍于准确性和效果没有达到满意的效果, 很长时间没有得到大范围广泛应用。现在,随着深度学习技术的引入,这些问题不复存在,因此, 基于机器视觉的目标检测技术在军事上的推广越来越受到重视。 Zheng 等[1]构建密集反卷积网络提取目标深层次的语义信息对伪装人员进行检测;Fang 等[2]构建强语义膨胀网络检测架构, 进一步提高伪装人员的检测效果;邓小桐等[3]通过改进RetinaNet 检测网络,对伪装人员进行检测。
不过,与普通的目标检测相比,军事目标探测有其自身的特殊性,比如战场环境的复杂多变,敌对双方的欺骗和攻击等,都使得军事目标探测面临更加复杂的情况。 而最根本的区别在于, 军事目标的探测方和所有方总是敌对的双方, 因此探测方所需要用来训练检测模型的数据不易获得。 而基于神经网络的机器视觉系统的能力从根本上依赖所训练的数据,当数据不完备时,检测系统的能力就会受到影响。 当然,目标的探测方可以为检测系统建设必要的数据集, 以反映假想的战场环境和敌方目标的特性。 尽管如此,真实的战场仍会出现难以预测的情况,比如敌方采取的临时伪装措施, 敌方对探测平台的攻击等。 这些不曾预想的情况究竟会对目标检测系统造成多大的影响? 为回答这个问题,本文设想了敌方攻击导致探测距离变远(导致图像分辨率降低)和敌方设置了伪装措施(导致目标显著性降低)两种情形,通过对比分析这两种情况出现和不出现的检测结果, 试图说明战场环境中不可知因素对机器视觉目标探测的影响。 毫无疑问,这种影响对目标检测技术和隐身伪装技术都非常重要。
根据当前目标检测算法的发展现状, 可将其分为三大类。 一类是基于候选区域的目标检测算法, 如R-CNN[4]、SPP-Net[5]、Fast R-CNN[6]、Faster R-CNN[7]、Mask R-CNN[8]和R-FCN[9]等。 此类算法先对输入图像提取若干个候选区域,然后对候选区域进行分类和预测,最后利用非极大值抑制((Non-Maximum Suppression,NMS)消除多余的目标框。 二类是基于回归的目标检测算法, 如YOLO[10]、YOLOv2[11]、YOLOv3[12]、YOLOv4[13]、SSD[14]、DSSD[15]和RetinaNet[16]等。 此类算法对输入图像直接进行分类和回归预测。第三类是基于anchor-free 的目标检测算法。此类检测模型包含基于关键点的检测和基于分类和回归进行改进的检测这两种,如CornerNet[17]、CenterNet[18]和FCOS[19]等。
本文以Faster R-CNN、YOLOv4 和CenterNet 三种类型的目标检测算法为基础, 将该三种模型在单个目标场景下进行多轮迭代训练, 将迭代损失最小的权重值作为预测权重, 分别对分辨率降低前后和伪装措施施加前后的测试集目标进行检测。 本文所用的数据集是在野外现地采集,并对该数据集进行了数据扩展。
1 数据集建立
1.1 伪装军事车辆数据集扩展试验方法
由于当前没有公开的伪装后的军事车辆数据集,因此针对当前实验任务,为贴近实际的战场侦察环境,在野外条件下,采集了348 张伪装后的军事目标图片数据,图像大小为5472×3048,此图片数据满足以下两个特点:
(1)图片数据包含不同明暗程度,不同俯仰,不同遮挡程度的目标。
(2)图片数据包含不同尺度的目标,即从不同高度,不同距离对图像数据进行采集。
(3)通过翻转,旋转,裁剪,变形,缩放,颜色增强等数据增强的方式,将原图片数据库扩展至1740 张,并采用PASCAL VOC 数据集标注方式, 对扩展后的图片数据进行标注。 扩展数据集统一标注为Car, 扩充的图像及其标注如图1 所示,其 中 图(a)和 图(b) 为选取的训练集中的两张图片,图(c)和图(d)分别为其对应的标注图片。

图1 数据集标注Fig.1 Dataset annotation
1.2 不同分辨率的伪装军事车辆数据集扩展试验方法
对扩展后的军事目标数据集中的测试集图像数据,进行不同分辨率的图像处理,得到当前的不同分辨率的测试集。 图像分辨率按照原图大小进行等比例缩小之后,再扩大至原图大小, 图像宽度分别设置为600、500、400、300、200 和100, 经过缩小后的图像,再扩张成原图尺寸大小,不同分辨率图像如图2 所示,其中图(a)、图(b)、图(c)、图(d)、图(e)和图(f)分别为宽度设置分别是100、200、300、400、500和600 下的不同分辨率测试集下的标注图片。
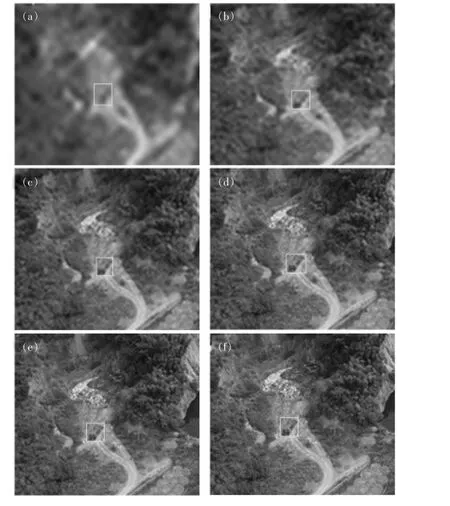
图2 不同分辨率数据集标注Fig.2 Different resolution dataset annotation
1.3 遮挡伪装军事车辆数据集的扩展试验方法
对扩展后的军事目标数据集中的测试集图像数据,施加伪装措施。 通过对图像目标周围的背景特征进行提取,将提取的背景特征对图像进行不同程度的遮挡。本文选择测试集1 进行遮挡,形成遮挡测试集。 遮挡数据集标注如图3 所示。 其中图(a)和图(b)分别为选取的遮挡数据集下的两张标注图片。

图3 遮挡数据集标注Fig.3 Occlusion dataset annotation
2 结果分析与讨论
2.1 实验的基础条件设置
本实验所使用的Faster R-CNN、YOLOv4 和Center-Net 三种目标检测模型, 均是以Tensorflow 作为基础框架,使用的电脑配置内存128GB,CPU 为i9-10980XE,并使用NVIDIA TITAN V 进行模型训练的加速并行运算。使得模型迭代运行速度大大提升,模型训练误差能够较快的收敛。 对扩展后的伪装目标数据集, 按照8:1:1 的比例,将其分为训练集、验证集和测试集。
2.2 目标网络模型的训练
三个目标检测模型的训练, 为保证模型在不同背景下预测时,具有较好的识别准确率。 选择模型多轮迭代训练后的最低损失权重作为该检测模型的预测权重。Faster R-CNN 目标检测网络模型经过多轮迭代训练后,损失最低值在0.507 左右, 损失收敛曲线见图4。YOLOv4 检测模型经过多轮迭代训练后, 损失最低值在3.955 左右,损失收敛曲线见图5。 CenterNet 检测模型经过多轮迭代训练后,损失最低值在0.615 左右,损失收敛曲线如图6 所示。
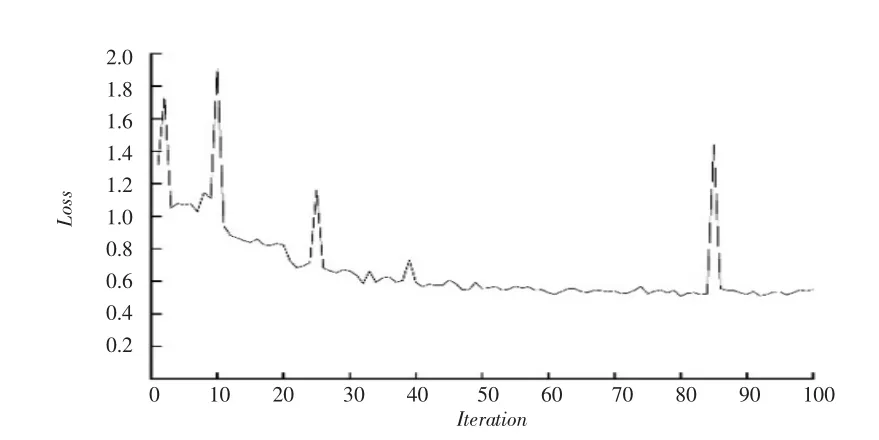
图4 Faster R-CNN 训练损失Fig.4 Faster R-CNN Training loss

图5 YOLOv4 训练损失Fig.5 YOLOv4 Training loss

图6 CenterNet 训练损失Fig.6 CenterNet Training loss
2.3 目标网络模型的测试
2.3.1 实验一
将三个训练好的目标网络模型,在验证集上进行测试,由于该数据集统一标注为Car 这一类,因而,只需通过计算模型在验证集上的平均准确率(Mean Average Precision,MAP)来衡量模型训练的好坏,平均准确率(MAP)越高,即该检测模型的性能越好。 平均准确率(MAP)从精确率(Precision)和召回率(Recall)两个方面进行衡量。
扩展后的伪装目标数据集1740 张, 测试集为即174张。 由于在设置时,测试集为随机选取数据集的10%,因而将在Faster R-CNN、YOLOv4 和CenterNet 三个模型上的测试集分别命名为测试集1、测试集2 和测试集3。
三个目标检测模型在各自的测试集上的检测结果如表1 所示。 从表1 各检测模型在各自测试集上的检测结果可以看出,三个目标检测模型检测效果较好。

表1 不同模型检测结果对比图表Tab.1 Comparison of test results of different models
2.3.2 实验二
分别对测试集1、测试集2 和测试集3 这三个数据集按照原图宽高比,进行图像分辨率的调整。为了体现图像不同分辨率之间的差异, 将其原图像宽高调整为100×56、200×112、300×168、400×225、500×281 和600×337。 然后再将图像扩展至原图比例尺寸。
利用Faster R-CNN、YOLOv4 和CenterNet 三个目标检测模型在扩展后的分辨率数据集上对Car 这一类目标进行测试,并计算该模型在不同分辨率的图像数据集上的MAP。
从表2、表3 和表4 的检测结果可知,Faster R-CNN、YOLOv4 和CenterNet 三个目标检测模型在各自不同分辨率测试集上的检测结果, 随着测试集图像分辨率的不断下降,检测精度也在不断下降。 从此检测数据可以看出,检测模型在充分训练的情况下, 在敌方攻击导致探测距离变远(导致图像分辨率降低)时,对目标检测模型检测结果具有一定的影响。

表2 Faster R- CNN 的检测结果Tab.2 Test results of Faster R- CNN

表3 YOLOv4 的检测结果Tab.3 Test results of YOLOv4
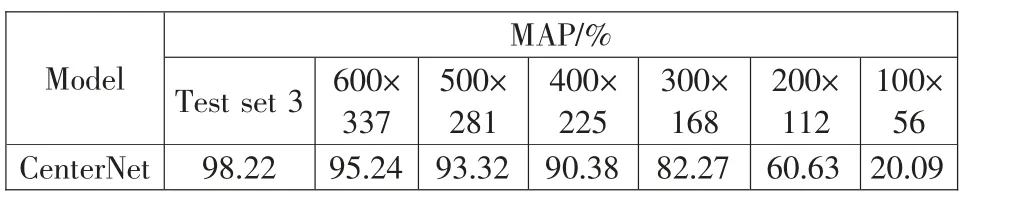
表4 CenterNet 的检测结果Tab.4 Test results of CenterNet
2.3.3 实验三
对测试集1 中的图像目标显著性进行调整, 即降低目标与周围背景之间的差异。目标与背景差异越大,即显著性越高。 反之。 具体操作:通过对图像目标周围的背景特征进行提取, 将提取的背景特征对图像进行不同程度的遮挡。 本文选择测试集1 进行遮挡,形成遮挡数据集。利用Faster R-CNN、YOLOv4 和CenterNet 三个目标检测模型在遮挡数据集上对Car 这一类目标进行检测。
各模型的检测图如图7 所示,其中图(a)、图(b)和图(c)分别为Faster R-CNN、YOLOv4 和CenterNet 在遮挡数据集上的识别图片。 模型在遮挡测试集上的检测结果如表5 所示,从表中数据可以看出,通过对目标图像设置伪装措施(导致目标与背景的显著性差异降低),模型检测的MAP 值明显降低。

图7 模型识别Fig.7 Model recognition

表5 不同模型检测结果对比Tab.5 Comparison of test results of different models
3 结束语
为考察战场环境因素对机器视觉目标检测的影响, 本文基于三种目标检测模型, 对比分析了分辨率降低和伪装措施增加前后检测结果的变化。 根据实验二、实验三的检测结果,分别从分辨率和显著性两个方面, 对基于机器视觉下的目标检测模型的影响进行了分析。
从实验二的模型检测结果中可以看出, 通过对测试集图像进行的分辨率调整, 检测模型对军事车辆伪装目标的MAP 也在变化。
从实验三的模型检测结果中可以看出, 通过对测试集图像施加伪装措施。 导致测试集图像与背景的显著性差异变小,模型检测的MAP 也在降低。
结果表明,对经过多次迭代、训练效果良好的检测模型,随着分辨率的逐渐降低和伪装目标显著性的改变,模型探测结果也受到极大影响。 这样的结果对目标检测和军事伪装都有很好的参考意义。
