国外过滤气泡研究:基础、脉络与展望
2021-10-26姜婷婷许艳闰
姜婷婷,许艳闰
(1. 武汉大学信息管理学院,武汉 430072;2. 武汉大学信息资源研究中心,武汉 430072)
1 引 言
当人们所接收到的信息输入量超过了人们理解和处理的范围,就会进入“ 信息过载”(informa‐tion overload) 状态。在应对信息过载时,“过滤”(filtering) 是一种常见的手段,即仅处理 “优先级高” 的信息[1]。日新月异的互联网技术虽然带来了信息的爆炸式增长,加剧了信息过载,但同时也实现了信息的自动过滤,将 “优先级高”(通常是指更符合个人偏好) 的信息直接推送给用户,从而降低了信息生产者的送达成本和信息消费者的决策成本[2]。
久而久之,人们开始发现自己正处在一个多样性降低的信息世界中:视频平台经常会推荐那些与自己以往喜好类似的电影[3];在线购物平台会不断地给自己推荐同一类型的产品[4];新闻网站推荐的新闻总是与自己的兴趣高度一致[5];音乐平台推荐的曲目与自己已经收藏的曲目在风格上也极为相似[6]。这种个性化的信息推荐促使网络世界中形成了一个个无形的过滤气泡,很多人都被困在自己的气泡中,与异质信息的接触越来越少。
“ 过滤气泡”(filter bubbles) 这一概念是由Pariser[7]在The Filter Bubble:What the Internet Is Hiding from You一书中提出的,他认为以PageRank 为代表的搜索算法已经成为过去,现在的搜索引擎可以时刻捕捉用户的偏好,并据此为其定制个性化的搜索结果,这使得每个人都身处一个独有的信息世界,即过滤气泡,阻碍人们偶遇异质信息①Pariser 在The Filter Bubble: What the Internet is Hiding from You 中对 “过滤气泡” 的原始描述为 “The new generation of Internet filters looks at the things you seem to like—the actual things you've done, or the things people like you like—and tries to extrapolate…these engines create a unique universe of information for each of us—what I've come to call a filter bubble—which fundamentally alters the way we encounter ideas and in‐formation.”(pp. 10)。
如上所述,“过滤气泡” 概念的初始定义非常清晰,强调了其与个性化推荐算法之间的密切关联,然而在后来的使用过程中却发生了概念混用的情况。其中,早在互联网推荐算法流行起来之前就出现的概念——“信息茧房”(information cocoons)是最常与之混淆的。 美国学者Sunstein[8]在Infotopia:How Many Minds Produce Knowledge一书中首次提出 “信息茧房”,并将其定义为一种特殊的信息世界,身处其中的人们只会听到令自己感到舒适和愉悦的信息。目前,国内的许多学术文献和媒体文章均将由技术因素造成的 “过滤气泡” 冠以“信息茧房” 之名,但两者本质上并不能等同:信息茧房是人们主动对信息进行选择的结果,而过滤气泡则是人们被动接受算法推荐的个性化信息的结果。
近年来,流行的个性化推荐算法在迎合用户喜好的同时,伴生着推荐质量下降的问题,过滤气泡的出现限制了每个人所能接收到的信息范围,用户正在逐步丧失信息自主权,长此以往令人担忧[9]。清楚认识过滤气泡,并提出应对之策迫在眉睫,但国内相关研究对这一概念内涵的挖掘较为浅显,研究进展也相对迟缓。因此,本研究采取系统性综述方法对国外过滤气泡研究成果进行分析、整合与展示,按照规范流程对文献进行搜索与筛选,并从中提取出研究脉络和重要主题,旨在深化概念理解、探讨未来的研究思路与发展趋势。
2 过滤气泡研究基础
2.1 理论基础
虽然过滤气泡是在近年来互联网信息爆炸的背景下产生的,但是其理论基础可以追溯到传播学领域于20 世纪40 年代所提出的 “守门人理论”(gate‐keeping theory)。这一经典理论认为,信息在向受众传播的过程中存在着 “门区”(gate)[10],那里的“守门人”(gatekeepers) 决定了哪些信息可以通过、而哪些信息被拒之门外[11]。在传统媒体时代,记者、编辑等新闻工作者扮演了 “守门人” 的角色,这些 “守门人” 会根据自身的经验和判断挑选出受众可能感兴趣的内容,并将其呈现给受众[12]。
Web 2.0 时代到来之后,政治、经济、科学等领域的信息得以在互联网上快速、便捷地传播,各类社交媒体、 搜索引擎等网络平台,如国外的Facebook、Google,国内的新浪微博、百度等,逐渐替代了传统媒体中的记者和编辑,在一定程度上成为了现代社会信息传播过程中的 “守门人”[13]。为了应对互联网上日益增长的信息量,这些新的“守门人” 引入了 “个性化”(personalization) 这一手段,通过设计并应用各种个性化推荐算法来实现信息的精准推送。虽然个性化推荐能够有效地缓解用户的信息过载负担,但同时也在很大程度上使得人们更有可能接触到自己已经感兴趣的信息,而其他信息被过滤掉。过度的个性化推荐会制造出一种单一的信息环境,令用户局限于狭窄的信息接收范围,将其困在过滤气泡之中。
2.2 技术基础
推荐系统(recommender system) 是信息过滤系统的重要组成部分,通过预测用户对信息价值的评分来实现个性化的推荐[14],既免去了用户查找信息的麻烦,又能准确地与其兴趣相匹配[15]。常见的个性化推荐算法主要包括以下几类。
(1) 基于内容的过滤(content-based filtering):根据目标用户以往喜欢或选择的信息,推荐与之相似的更多信息,该方式依赖于用户历史数据分析和可用信息特征提取,核心在于计算信息内容之间的相似度[16-17]。
(2) 协同过滤(collaborative filtering):可以分为基于信息(item-based) 和基于用户(user-based)的协同过滤。基于信息的协同过滤,是指如果两个信息条目同时被很多人喜欢,那么就可以认为这两个信息条目是相似的,可以向消费了其中一个信息条目的用户推荐另一个条目;基于用户的协同过滤,是指向用户推荐与之品味相似的其他用户所喜欢的信息条目。协同过滤的核心在于根据用户喜好计算信息之间的相似度[18]。
(3) 混合推荐(hybrid recommendation):将基于内容的过滤、协同过滤等多种推荐算法结合起来使用,充分发挥各种算法的优势,弥补不足,从而有效地突破单一算法的固有限制[19]。
3 数据与方法
本研究采用系统性综述的方法对国外近年来的过滤气泡相关研究进行梳理和总结。系统性综述是一种识别、评价和解释与特定研究问题、主题领域、感兴趣现象有关的全部现有研究的方法[20],具有系统、全面、透明、可复制等优点[21]。本研究参考系统性综述的常用流程开展工作,具体如图1所示。
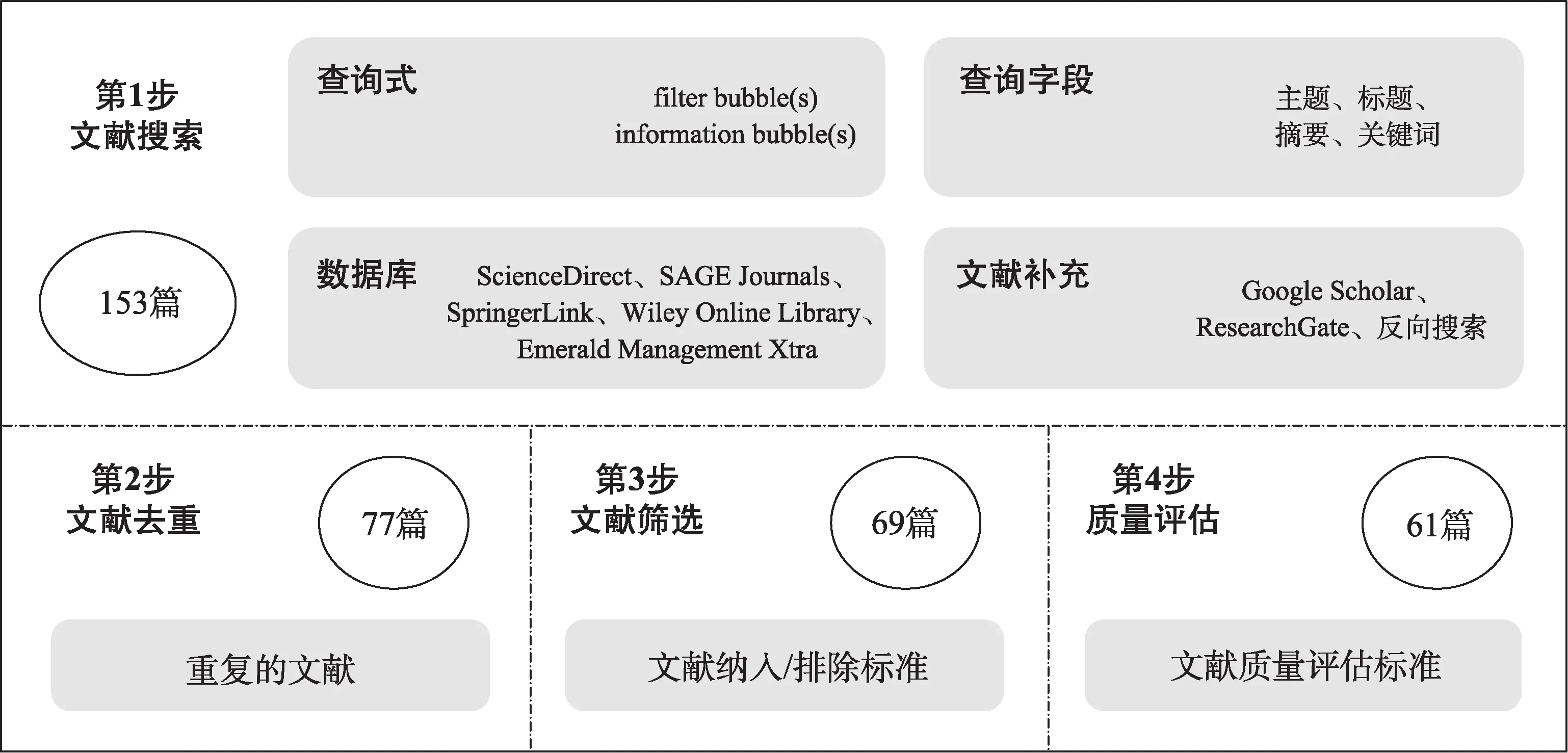
图1 系统性综述工作流程
在搜索国外 “过滤气泡” 相关文献时,本研究首先选择了覆盖多个学科领域的综合性数据库Sci‐enceDirect、SAGE Journals、 SpringerLink 和Wiley Online Library,以及侧重于社会学、管理学、政治学、心理学等人文社会科学研究的Emerald Manage‐ment Xtra 数 据 库,分 别 以 “filter bubble(s)” 和 “in‐formation bubble(s)” 为查询式,开展主题、标题、摘要和关键词字段的搜索;接着使用相同的查询式在Google Scholar 和ResearchGate 中进行搜索,补充了未被以上数据库收录的论文。此外,本研究还采用了反向搜索(backward search) 的策略,查看被已有综述文章纳入分析的文献,然后对现有搜索结果进行补充(如Bruns[22]、Spohr[23])。文献搜索工作于2020 年5 月进行,初步得到153 篇论文。
由图1 可知,经过第1、2 步的搜索、去重,获得了77 篇可能与过滤气泡相关的论文,但还需要进一步确定其是否符合本研究的综述目标,因此,本文设定如下的文献纳入标准:①发表在同行评审的期刊或是会议论文集上的英文论文;②提供了具体的研究设计和研究结果的实证论文,评论、社论等类型的论文被排除在外;③聚焦于过滤气泡的研究论文,仅提到该现象但研究问题与之无关的论文被排除在外。
根据上述纳入标准,进行第3 步的初步筛选之后得到69 篇相关论文,接着还需要对每篇论文开展质量评估,以确保综述对象的质量。评估时主要考虑以下因素:①研究背景阐述是否清晰;②研究目标及研究问题是否明确;③研究设计是否适用于研究目标;④数据采集方法是否合适,操作过程是否恰当;⑤数据分析方法是否合适,操作过程是否恰当;⑥研究结果是否可靠;⑦研究结论是否具有一定的深度和意义。经过第4 步质量评估完成二次筛选后,最终得到了61 篇高质量的过滤气泡研究论文的文献集合。如表1 所示,这些论文大多发表于近五年,以期刊论文为主,广泛涉及图书情报学、计算机科学、社会学、心理学等多个学科领域,由此可见,过滤气泡是一个跨学科的问题。

表1 文献集特征分布
4 过滤气泡研究脉络
4.1 过滤气泡是否真的存在?
信息过滤或个性化推荐会大大降低人们所接触信息的多样性,这一观点已经得到普遍认同,但是否已经达到产生过滤气泡的地步,是以往研究长期关注的一个问题。本研究梳理了涉及该问题的文献,从中提取了不同的甚至是相反的研究结论,并且发现过滤气泡存在与否,在很大程度上取决于研究的角度及判断的标准,如表2 所示。

表2 与过滤气泡是否存在有关的文献梳理结果
4.1.1 过滤气泡不存在或被夸大
有些认为过滤气泡不存在或被夸大的研究大部分都是面向用户的研究,即通过问卷、访谈等自我报告方法,调查用户使用网络应用的总体情况、日常浏览信息的一般习惯等[25-26]。这些研究发现,大多数用户会主动利用多个平台来获取信息,而且也会有意识地浏览观点不同的信息,将自己暴露于一个多样性较高的信息环境中[26-27]。 因此,Dutton 等[24]指出,技术对人类信息获取行为的影响受到了高估,理论上的过滤气泡在现实世界并不存在。
当然,也有面向平台的研究认为,过滤气泡不存在或被夸大。 Haim 等[31]、 Puschmann[32]、 Ne‐chushtai 等[33]以新闻网 站(如Google News) 为 背景,分析发现,平台推荐给不同用户的新闻在来源和内容上是高度同质的,因此,这些研究者认为在线新闻消费过程中人们对过滤气泡的担忧可能被夸大了。针对Google 搜索引擎的一部分研究显示,系统根据个人以往行为和偏好返回的搜索结果在不同用户间并未表现出明显的差别[29-30],Google 不仅不会将用户困于过滤气泡内,而且还会促进跨意识形态的信息消费[28]。
4.1.2 过滤气泡真实存在
少量以社交媒体或音乐平台为背景的研究认为,这些平台上确实存在着过滤气泡。Bechmann等[34]将过滤气泡理解为较低的信息相似性,即点击的链接、浏览的信息内容与其他人不存在重合,通过分析Facebook 上1000 名用户在14 天内获得的个人推送发现,确实存在少量用户完全孤立于其他用户,受困于过滤气泡之中。Min 等[35]在微博上部署了128 个社交机器人并分析了这些机器人及其社交网络接收到的信息,认为过滤气泡是社交媒体上的一种高度密集的用户社区,这些社区中的用户具有相似的偏好,其星状结构会自发地排除异质信息,造成群体极化。Wheeler-Mackta 等[39]调查了Pandora用户的音乐播放习惯后指出,音乐平台提供的个性化推荐功让用户不太可能主动挑战其已有偏好,促进了过滤气泡的产生。
值得注意的是,针对Google 的另一部分研究却认为,该搜索引擎中是存在过滤气泡的,因为不同用户得到的搜索结果具有一定的差别[37],或者少数用户得到的搜索结果有别于其他用户[36]。
4.2 过滤气泡会带来怎样的影响
实际上,Pariser[7]在首次提出 “过滤气泡” 概念时就带有批评的意味,因此,这一概念本身就暗含着消极影响。但是本研究发现,也有少数学者注意到过滤气泡在特殊背景下的积极影响。
4.2.1 过滤气泡的消极影响
信息多样性的下降带来了过滤气泡[40]。由于人们常常意识不到过滤气泡的存在,或者即使意识到其存在,却不知道如何与之对抗,因此,更倾向于对过滤气泡采取一种被动接受的态度[41-44]。由于缺少干预,过滤气泡在多个社会领域都造成了消极影响,其中在政治和健康领域尤为突出。
在过滤气泡中,个体的意见容易被同质化的群体声音所淹没,这会导致个人话语权面临巨大的挑战[45]、个体理性的力量将会减弱[46]、公众的批判性思维能力会遭受影响[43]。 因此,Ribeiro等[43]根据在本国开展的一项调查研究推断,在政治领域,过滤气泡能够在民主选举等重要的公共事件上影响甚至故意引导人们的观点;加快了意识形态的极化,促进了 “回音室” 的出现,不利于社会团结[47-48]。此外,因为过滤气泡中大多只充斥着人们感兴趣的信息,所以那些相对枯燥、复杂的话题,如政治、环境等重要的公共议题将会逐渐被动地退出社会大众的视线[7,49-50],公共议程的发展将面临迟滞。
由于过滤气泡可以促进信息的定向传播,因此,在健康领域可能被利用来将蓄意编造的错误信息直接送达到特定的弱势群体,最终威胁其生命健康[41,45]。例如,家长在社交媒体或搜索引擎中接触到与儿童疫苗接种有关的错误信息后,可能会犹豫是否要给孩子接种疫苗,甚至选择不给孩子接种疫苗,无意中让孩子面临感染常见可防疾病的风险[41,51]。
4.2.2 过滤气泡的积极影响
尽管过滤气泡的消极影响毋庸置疑,但它并非一无是处。首先,过滤气泡是利用技术手段实现信息过滤的产物,确实能够有效减轻人们的信息过载[47,52],不仅能节省信息搜寻和筛选的时间成本,而且还能获取自己感兴趣的信息。除此之外,特殊领域的过滤气泡可能带来意想不到的好处。例如,反性别歧视过滤气泡为其参与者提供了一个免受性别歧视和社会质疑的小空间,是她们物质需求和安全感的重要来源[53]。社交软件上的关系型过滤气泡能够帮助用户找到与他们相似的人,使其得以更好地与陌生人分享个人兴趣、品味乃至价值观,有效地拓展了自己的社交圈[25]。
4.3 如何应对过滤气泡
上述研究证据表明,过滤气泡是一种真实的存在,可能在特定的网络环境中表现得更为明显。过滤气泡在大多数情况下也是一种不利的存在,可能阻碍个人及社会的正常发展。因此,探讨如何应对过滤气泡成为国外相关研究的落脚点。本研究基于文献比较识别出应对过滤气泡的两种策略:①通过信息过滤可视化降低过滤气泡的影响;②通过个性化推荐算法优化破除过滤气泡。
4.3.1 信息过滤可视化
对信息过滤进行可视化有利于增强用户对过滤气泡的感知[41],提升用户对信息过滤过程的控制感[46,52],并鼓励用户主动接触不同观点的信息[24,54],从而削弱过滤气泡可能带来的不利影响。
以往最受关注的是针对在线评论的可视化,相关研究对评论内容进行收集、整合与展示,以一种更加直接的方式增加用户对异质信息的接触,促进用户对不同观点的思考和讨论。Opinion Space 是一款在线评论浏览工具,它将一个网络论坛中的评论投射到二维视图中,每个点代表一条评论,观点差异越大的评论相距越远。当用户浏览某条评论时,系统会提示用户对自己认同该评论观点的程度进行打分;一条评论越受不同价值取向的用户认同,视图中对应的点会变得越大。该可视化工具不仅使得多样性的评论一览无余,而且方便用户发现那些引起广泛共鸣的评论[55]。另一款在线评论浏览工具Reflect 在每条评论旁都设置了一个聆听框,鼓励其他用户简明扼要地重申评论者的观点或是发表自己不同的意见,从而为用户之间的相互倾听与交流创造了机会[56]。ConsiderIt 是一个观点审议平台,它广泛地邀请用户就某一公共话题分别创建赞成和反对的观点列表,以此来促进正反观点的互动,引导人们反思和权衡他人分享的不同看法[57-58]。
围绕搜索引擎开展的可视化研究旨在帮助人们意识到搜索中过滤气泡的存在。一款名为Bobble 的浏览器插件拓展了Google 搜索结果的可见性,针对同一查询式,仅用户自己可见的搜索结果以黄色背景显示,同时,该用户不可见而其他用户可见的搜索结果以红色背景显示,这样可以直观地反映个性化的程度[59]。Tabrizi 等[60]提出了基于观点的搜索范式(perspective-based search paradigm),认为搜索应该具有平等性,因而将搜索主题所涉及的不同观点识别出来并展示给用户,用户可以在这些观点中自由地选择查看哪些搜索结果。这种做法充分尊重了用户的自主权,有利于提升用户的批判性思维,避免偏听偏信,从而增强搜索引擎的可信度。
针对社交媒体上的过滤气泡,Nagulendra 等[61]专门创建了一种非常形象的可视化方式,即采用圆圈来表示过滤气泡,圆圈内的好友及其状态更新是用户原本可见的,而原本被过滤掉的内容则显示在圆圈外。在这个可视化界面上,用户可以通过添加、删除等操作改变气泡所包含的内容,从而使自己 “逃 离” 气 泡。
此外,Munson 等[62]开发了一款名为Balancer 的浏览器插件,利用 “小人走钢丝” 的简笔画来表现用户在浏览器中的阅读行为:分析其所读内容的倾向性,这个小人在钢丝上会相应地摆动身体,从而提醒用户其阅读行为实际上是带有偏向性的。
4.3.2 个性化推荐算法优化
个性化推荐算法能够实现信息的精准推送,但是过度的个性化会降低用户所接收到的信息的多样性,导致过滤气泡的产生。因此,个性化推荐算法优化的基本思路,在于降低个性化程度、提升信息多样性,从而在根源上阻断过滤气泡的形成[63-64]。
在推荐过程中引入 “意外发现”(serendipity)机制一直是个性化推荐算法优化的主要方向。信息获取情境中的意外发现又称为 “信息偶遇”(infor‐mation encountering)。不同于主动的、有目的的信息搜寻,信息偶遇具有低参与、低预期的特点,偶遇经历可能带来意料之外的价值,包括获得新知识、发现新方向、实现社交效益等[65-66]。在推荐算法中添加适度的意外发现可以为用户制造惊喜,避免用户对接收到的信息产生厌倦;惊喜是一种积极的情感反应,有利于唤起思考、激发学习兴趣,从而增强人们接触多样化信息的意愿[67-68]。
推荐算法中的意外发现应该平衡信息新颖性和相关性之间的关系,涉及用户建模和语义推荐两个方面,基于内容模式从用户模型中识别可能是意外发现的那些概念并据此推荐信息[69]。 Symeonidis等[70]将新颖性表示为信息之间的距离,即目标信息与用户以往接收到的信息在所属类别、文本特征等方面的相似度越低、距离越大,目标信息的新颖性就越高,再结合用户原本的信息偏好,为其推荐既新颖又可能感兴趣的信息。Yokoyama 等[71]针对推特推文提出了“ 新鲜度导向”(freshness-oriented)的推荐方式,首先确定推文所包含的主题,若用户之前很少接触到该主题,则认为推文具有较高的新鲜度,再根据用户的偏好对新鲜度较高的推文进行筛选推送。
值得注意的是,意外发现有助于信息多样性的提升,同时也导致信息推荐的精准性下降。为了解决这一问题,Lunardi[72]首先使用内部多样化算法(intra-diversifier) 生成一个候选推荐列表,再将该列表输入过滤后多样化算法(post-filtering diversifi‐er) 中得到最终的推荐列表,这样将信息多样化和信息过滤两个过程结合起来,可以避免单一过程可能带来次优结果的情况。
5 讨 论
5.1 重新解读“过滤气泡”
尽管Pariser[7]在2011 年提出 “过滤气泡” 概念时就指出了这一现象的普遍性,但令人意外的是,“过滤气泡是否真的存在” 仍然是以往研究关注的重要问题,而且相关探讨得到的结论出现了相互矛盾的情况。究其原因,这些研究对过滤气泡的理解存在着明显的差异,因而采取了不同的研究角度和判断依据(见表2)。
在原始的概念表述中,Pariser[7]以搜索引擎为例,将过滤气泡的产生归因于个性化推荐算法。很显然,他认为算法并不是凭空存在的,其载体是搜索引擎、社交媒体等网络平台;不同的平台提供信息的类别、方式、目标等不尽相同,相应地也会采用不同的算法。也就是说,算法是具有平台属性的,可能有的平台所采用的算法会导致过滤气泡,而有的却不会。因此,对于过滤气泡存在与否,基于不同的平台得到的结论不一致是可以理解的。目前,互联网资源的丰富性和可访问性决定了用户获取信息的来源绝不是单一的,大多数人都会接触到多个种类的网络平台以满足其各个方面的需求,甚至会在同一种类中同时使用多个平台以扩大信息的覆盖面。即使单个平台的算法个性化程度过高,其不利影响是有可能被其他平台所平衡或消解的,这也是为什么以往面向用户的相关研究均认为过滤气泡不存在或被夸大了。这些研究人员所考虑的范围是用户所处的整体信息空间,更关心用户本身对过滤气泡的认知,而弱化了过滤气泡与算法之间的关联。
Pariser[7]最初在描绘“ 过滤气泡” 时曾提到,“过滤气泡” 是一个人所独有的信息世界,并且这个信息世界中缺少异质信息。然而之后的部分研究对过滤气泡的理解在不同程度上逐渐偏离了这两点。有的研究认为,社交媒体上同质化的用户社区就是过滤气泡[35],尽管这种用户社区的形成离不开个性化推荐算法的作用,但其本质上是 “回音室”(echo chambers),因为包含了多个个体及其之间的紧密关系[73]。此外,有的研究认为,过滤气泡存在的根本依据是不同用户所接触到的信息具有较大差异,却忽略了每位用户自身所接触到的信息应该是很单调的[34,38]。事实上,多个用户的信息差异性和单个用户的信息多样性是两个相互独立的变量,不难设想,在前者差异性很高的情况下,后者的多样性也可以很高,这样过滤气泡是不存在的。
在深入分析了核心概念的初始定义及其理解误区后,本研究认为,“过滤气泡” 具有三个基本特征:①过滤气泡是在网络平台个性化推荐算法的作用下产生的;②每个过滤气泡内部的信息多样性一定是很低的,且不同过滤气泡之间的信息差异性有可能很高;③过滤气泡是一种针对个体的存在,即一个过滤气泡包裹着一位用户。
5.2 过滤气泡研究发展趋势
过滤气泡在减轻信息过载、提供情感和精神支持方面发挥了一定的积极作用,但对公民话语权、公共议题讨论、健康信息传播等方面确实带来了更为普遍的不利影响。因此,如何有效应对过滤气泡一直都是研究人员关注的重点。本文第4.3 节梳理了两大类应对策略,从时间上来看,信息过滤可视化研究主要集中在2015 年以前,而2015 年至今的研究主要围绕个性化推荐算法优化展开,因此,可以通过图2 表现过滤气泡应对思路的转变。该转变一方面源自计算机技术的发展、算法设计与分析手段日益成熟;另一方面,则源自人们对过滤气泡问题认识的深入,降低其影响只能 “治标”,只有破除过滤气泡或阻断其形成才能“ 治本”。 当然,目前该领域对算法优化的探索尚处于初级阶段,相关研究数量较少、优化路径较为单一,而且仅从技术角度思考问题,忽略了用户个体在信息获取活动中的主体地位。因此,深化推荐算法研究、进一步拓宽过滤气泡应对思路应该是该领域未来发展趋势。

图2 过滤气泡应对的思路转变过程
鉴于过滤气泡与个性化推荐算法的密切关系,深化以 “意外发现” 机制为核心的算法改进依然是应对过滤气泡的主要手段之一。未来研究可以进一步探索如何提高推荐信息的新颖性,也可以考虑在传统精准推荐的基础上,通过调整排序(reranking)将用户原本可能会忽视的信息推向更为显著的位置,或通过反向推荐(modification) 让用户看到与之不同的人所不喜欢的信息[74]。此外,在个性化推荐工作中,融入以递归神经网络(recursive neural network)、 卷积神经网络(convolutional neural net‐work)、生成式对抗网络(generative adversarial net‐works) 为代表的深度学习技术,可以通过学习数据的潜在特征来捕捉用户的深层次信息偏好,帮助其丰富个人兴趣。
Bozdag[13]指出,信息在流向用户的过程中会经过层层过滤,除了个性化推荐外,信息源选择与收集、信息选择与优先级排序、信息展示等多个技术环节都会通过相应的算法实现信息的过滤,在不同程度上降低了信息多样性。此外,该过程中也会发生人为过滤,不符合个人判断、组织倾向、政府要求的信息都可能被删除或拒绝。已有研究表明,在线信息审核(online censorship) 也会导致过滤气泡的产生[75]。也就是说,过滤气泡可能是多个环节共同作用的结果,而仅着眼于个性化推荐算法的改进是存在局限性的,未来研究应该充分考虑信息过滤的过程性,深入各个环节,有针对性地设法提升信息多样性,如丰富信息收集渠道、采用更灵活的信息排序操作、制定系统的信息审核规范、提供交互性强的信息展示方式等。
6 结 论
互联网技术,特别是推荐系统的发展,导致过滤气泡问题日益显著,相关研究在国外呈逐年递增趋势,在国内却由于概念混用而停滞不前。本研究首次采取系统性综述的方法对国外过滤气泡的研究成果进行分析、整合与展示,以信息行为研究人员的眼光重新审视过滤气泡的本质,揭示了过滤气泡的基本特征,将其与 “信息茧房”“回音室” 等相似概念进行初步辨析,以期推动研究人员对过滤气泡的深入探索,为图书情报领域对过滤气泡的进一步研究提供参考。
