基于深度交互的文本匹配模型研究
2021-10-26余传明薛浩东江一帆
余传明,薛浩东,江一帆
(中南财经政法大学信息与安全工程学院,武汉 430073)
1 引 言
文本匹配是指将两个文本作为输入,通过理解各自的语义预测其关系类别或相关性分数[1],作为自然语言处理的重要任务,文本匹配在信息检索和文本挖掘等领域受到了广泛关注。从应用角度来看,文本匹配可分为相关性匹配和语义匹配。相关性匹配主要应用于信息检索任务,用来评估用户查询和文档之间的相关性,并对文档进行排序[2]。语义匹配强调文本对之间本体意义上的对应,通过对文本的深度表示、理解和推理来计算语句之间的语义相似度,其实现路径包括对文本上下文进行建模、加入注意力机制和引入外部知识库等。语义匹配任务包括释义识别[3]、自然语言推理[4]和答案挑选[5]等。释义识别任务是判断两个文本是否具有相同的含义;自然语言推理是判断输入的两个句子是否存在语义蕴含关系,即能否基于前提句推理出假设句;答案挑选任务是指给定一个问题,根据问题与各个候选答案的匹配分数对所有候选答案进行排序。从输入的两个文本长度来看,文本匹配任务可分为短文本-短文本匹配、短文本-长文本匹配和长文本-长文本匹配。短文本-短文本匹配常用于计算用户检索项与网页标题的相似度[6],短文本-长文本匹配可用于文档关键词抽取[7],长文本-长文本匹配可应用于个性化推荐[8]。
随着应用场景的扩展,文本匹配任务对于语义理解的要求逐渐升高,传统的文本匹配模型逐渐暴露其局限性,其主要面临以下挑战:①现有的文本匹配模型在对句子进行编码时,由于长距离依赖、一词多义等问题,不能有效地表示句子的上下文信息和隐含语义信息;②句间交互信息对文本匹配效果起着关键作用,而现有的文本匹配模型不能够有效地提取并利用两个句子的交互信息;③现有的模型缺乏泛化能力,在应用到不同的领域或场景时,不能同时拥有较好的结果。为了解决上述挑战,本文尝试提出基于深度交互的文本匹配(deep interac‐tion text matching,DITM) 模型,并开展实证分析,以期为相关研究提供借鉴。
2 相关研究
文本匹配模型在许多领域均得到了应用,并取得了较好效果。在医学领域,沈思等[9]将孪生神经网络应用到医学文本的相似度计算中;在电商领域,文本匹配模型可用于产品评论情感分析[10]、购物车个性化推荐[11]和产品特征词典构建[12]。此外,章成志等[13]将双向长短期记忆网络应用到实体识别任务中,林德明等[14]将文本深度表示模型应用到政策工具选择研究中。值得说明的是,现有研究对于文本匹配模型的选择并无明确的准则和依据,对文本匹配模型缺乏系统化的研究。鉴于此,本文对大量相关文献进行梳理,从基于表示和基于交互的文本匹配模型的角度分别展开系统性论述。
2.1 基于表示的文本匹配模型
基于表示的文本匹配模型注重构建文本的表示向量,在表示向量的基础上预测两段文本的关系或相关分数。从研究方法上来看,基于表示的文本匹配模型可分为传统的文本匹配模型、基于深度表示的文本匹配模型和基于预训练的文本匹配模型。
传统的文本匹配模型依靠人工定义的特征,计算特征之间的相似度。传统文本匹配模型,如TFIDF (term frequency-inverse document frequency) 和BM25 等算法,得到的是大维度稀疏矩阵,对潜在特征提取能力不足;基于Gibbs 采样的LDA (latent Dirichlet allocation) 近似推断算法,能将句子映射到隐式空间,并获取潜在语义表达[15],但只是达到了词汇层面的匹配,没有考虑词序和深层语义信息,面对大规模的数据集和多样化的任务,不能够表现出较好的效果。
近年来,涌现了许多基于深度学习的文本匹配模型,并表现出较好的性能。基于深度表示的文本匹配模型使用卷积神经网络和循环神经网络等方法自动捕捉文本特征,分别获取两段文本的表示向量。 深层结构语义模型(deep structured semantic models,DSSM)[16]将两个文本分别经过相同的深度神经网络计算各自的表示向量,但忽视了句子的词序和上下文信息,无法有效地表示文本的语义信息。Hu 等[17]提出ACRI (architecture-I) 模型,使用卷积神经网络融合句子中相邻词的语义信息,考虑了有限的上下文信息,但依旧无法捕捉长距离依赖词的信息。IBM Watson 实验室提出了结合卷积神经网络和长短期记忆网络的混合神经网络结构[18],并提出了两种基于LSTM (long short-term memory) 模型的改进方法,一种是结合CNN (convolutional neural networks) 与LSTM 模型的混合结构,另一种是在LSTM 模型中加入注意力机制。树状结构长短期记忆网络(tree-structured long short-term memory networks,Tree-LSTM)[19]模型将长短期记忆网络扩展到树形拓扑结构上,Tree-LSTM 单元中门向量和储存单元的更新与其子单元的状态有关,令每个单元能够接收多个子单元的信息,可以解决循环神经网络只允许顺序信息的传播的缺点。层次编码模型(hierarchical encoding model,HEM)[20],通过分层编码模块和层次匹配机制,充分利用了文本的语义特征捕获多视角交互信息进行文本匹配。上述模型的结构相对简单,具有较高的效率,但未能解决一词多义问题。
为了解决多义词的问题,学者们提出了ELMo(embedding from language models)[21]、 GPT (gere‐rate pre-training)[22]和BERT (bidirectional encoder representation from transformer)[23]等预训练模型。ELMo 使用了双层的双向长短期记忆网络,利用上下文信息动态调整单词语义;与ELMo 相比,GPT使用Transformer[24]作为特征提取器,规避了普通的循环神经网络不能并行计算的缺点,但GPT 的单向语言模型只利用了上文信息,而忽略了下文信息;BERT 模型与ELMo 和GPT 相似,采用Transformer作为特征提取器,使用了双向语言模型,兼顾了ELMo 和GPT 两者的优点,对各类下游任务具有普适性。RoBERTa[25]在BERT 基础上,使用动态掩盖机制代替静态掩盖机制和移除NSP (next sentence prediction) 等手段,改进了BERT 预训练的方式。上述预训练模型可代替先前模型中卷积神经网络或循环神经网络等网络结构编码句子的表示向量。例如,SBERT (sentence-BERT)[26]基于BERT 分别获取两个句子的语义表示,取得了较好的效果。预训练模型较好地解决了一词多义问题,但只是提取文本句子级别的表示向量,未能考虑文本对之间在词级别的交互信息。
2.2 基于交互的文本匹配模型
基于交互的文本匹配模型注重获取文本对之间的复杂交互信息,从研究方法上来看,下文从基于交互矩阵的文本匹配模型和基于匹配-聚合框架的文本匹配模型来论述。
基于交互矩阵的文本匹配模型,是基于余弦相似度、识别函数等方法,计算两个句子的交互矩阵,然后从交互矩阵中提取关键的交互特征作为是否匹配的依据。例如,Hu 等[17]提出的ACRII (ar‐chitecture-II) 模型先使用1D 卷积神经网络获取文本对之间词级别的交互矩阵,再使用2D 卷积和最大池化提取特征。Wan 等[27]针对答案挑选任务,提出MV-LSTM (multiple positional sentence representa‐tions) 模型,通过设计张量从多个维度获取两个句子的交互信息,然后使用K-Max 池化提取交互张量的关键信息。 MatchPyramid[28]模型借鉴图像识别的方法,使用多层卷积神经网络对相似度矩阵进行特征提取,获取到了文本对不同粒度上的交互特征。基于注意力机制的神经匹配模型(at‐tention-based neural matching odel,aNMM)[29]使用类似ARCII[17]的设计,但采用的是基于值共享的卷积神经网络,并引入注意力机制进行对齐,解决了模型无法获取足够匹配信号的问题。密集交互推理网络(densely interactive inference network,DIIN)[30]提出了密集交互推理网络模型,它基于多头注意力机制,将文本对进行词级别的维度对齐,以得到交互张量,再采用DenseNet 提取丰富的语义特征。 与基于表示的文本匹配模型相比,基于交互矩阵的方法考虑了文本对之间的交互信息,在多种文本匹配任务上可以取得更好的效果。但这类模型只是从交互矩阵或交互张量中提取关键特征,可能会丢失文本的原始语义信息,从而降低文本匹配效果。
基于匹配-聚合框架的文本匹配模型将交互矩阵作为注意力权重,得到两段文本各自的交互表示,然后将文本的编码信息和交互信息进行聚合,以预测两段文本的关系或相关分数。例如,Wang等[31]提出了一种通用的匹配聚合框架,并对六种不同的比较函数进行测试分析。为了捕捉更多层级上的交互信息,双向多视角匹配模型(bilateral multiperspective matching,BiMPM)[32]设计了一个双向多视角的匹配算法进行相似度计算,可以从多个角度获取文本对的交互信息,在释义识别、答案挑选等多项任务上取得了较好的效果。增强的序列推理模 型(enhanced sequential inference model,ES‐IM)[33]首先使用双向长短期记忆网络编码文本的语义信息,然后使用另一个双向长短期记忆网络聚合文本的语义信息和基于注意力的对齐信息,在自然语言推理任务上取得较好的效果。相较于ESIM 使用维数较大的拼接向量,压缩对齐分解编码器(ComProp (compare, compress and propagate) align‐ment-factorized encoders,CAFE)[34]提出了对齐因子分解层,压缩了交互特征向量将其增强为单词表示,并实现了轻量级模型。匹配-聚合框架可以基于注意力机制获取文本对之间的交互对齐信息,并通过融合文本的语义和交互信息更好地捕捉关键匹配特征。然而,单次的匹配-聚合仅能捕捉文本浅层的语义和交互信息,且需要设计复杂的函数进行融合。 为了提取深层次的交互特征,Kim等[35]和Yang 等[1]通过残差连接多次循环编码和交互模块,既可以捕捉丰富的深度交互信息,又可以避免模型过深导致的梯度消失/爆炸的问题。对于基于匹配-聚合框架的文本匹配模型,如何在算力有限的条件下提升推理效果成为一个紧迫的研究问题。
上述的文本匹配模型在特定的任务上取得了较好的效果,但这些模型大多只能在一种或两种文本匹配任务上表现良好,其泛化能力尚缺乏系统性的验证。在此背景下,本文提出了基于深度交互的文本匹配模型,在多个数据集上与基线方法进行比较,验证本文所提出模型的有效性和普适性,并探究基于表示的文本匹配模型和基于交互的文本匹配模型的效果差异,在扩展实验部分将进一步探讨网络结构对模型效果的影响。
3 研究框架与方法
3.1 研究问题
对于文本匹配任务,从形式化定义来看,即给定文本A 和文本B 作为输入,通过机器学习算法或者深度神经网络结构理解文本对的语义和关系,得到预测结果̂。对于排序任务,̂表示文本对之间的相关性分数;对于分类任务,̂表示文本对的关系类别。基于此,本文的研究问题是:针对不同的文本匹配任务,如何以较低的计算成本获取文本丰富的上下文信息和文本对之间的交互信息,以在多种文本匹配任务上取得较好的效果。本文尝试提出一个基于深度交互的文本匹配模型,在该模型的基础上探讨:①相较于传统的模型,基于深度学习的文本匹配模型是否具有更好的效果?②在基于深度学习的文本匹配模型中,基于交互的方法性能是否优于基于表示方法?③在基于深度学习的文本匹配模型中,网络结构对模型效果存在怎样的影响?具体而言,①交互模块的循环次数对模型效果是否存在影响?②卷积层后加入多头注意力是否能有效地提升模型的效果?③本文提出的多角度池化是否有更好的效果?
3.2 DITM模型
本文基于匹配-聚合框架提出了一种深度交互的文本匹配(DITM) 模型。DITM 模型的总体结构如图1 所示。
由图1 可以看出,DITM 由嵌入层、 编码层(1D 卷积和多头注意力)、共注意力层、融合层、池化层以及预测层组成。首先,将文本A 和文本B输入词嵌入层和编码层获取各自的语义表示信息。然后经过共注意力层捕捉文本对之间的交互信息,并基于门控机制将语义表示和交互信息融合。此外,受Kim 等[35]与Yang 等[1]提出的模型启发,将编码层、共注意力层和融合层视为一个交互模块,该交互模块循环N次,以获取文本对之间深度的语义特征和交互信息。最后,通过池化层提取关键匹配特征并进行预测。

图1 DITM总体结构图
3.2.1 词表示层
词表示层是将句子中的词转换为表示向量,本文参照Gong 等[30]的方法,将词嵌入特征、字符特征以及精确匹配特征拼接表示单词的嵌入信息。其中,词嵌入特征是预训练的词嵌入向量;字符特征是将句子中的每个词输入1D 卷积和最大池化层,得到其特征表示向量,字符特征可以有效地表示词典外(out of vocabulary,OOV) 的词;精确匹配特征是判定两个句子中是否包含相同的词。经过词表示层,两个句子会得到各自的表示矩阵,分别用A∈Rla×d和B∈Rlb×d表 示,其 中,la和lb分 别 表 示文本A 和文本B 的长度,d表示词向量维数。
3.2.2 编码层
编码层旨在通过神经网络获取文本具有上下文信息的语义表示,常用的网络结构有1D 卷积、长短期记忆网络等。DITM 模型的编码层使用了1D 卷积对相邻上下文进行建模,并通过加入多头注意力来消除语义歧义,具体表示为
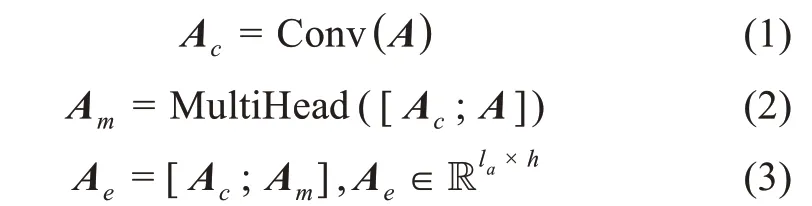
其中,Ac、Am分别表示卷积层和多头注意层的输出;[Ac;A]、[Ac;Am]表示括号内两个矩阵的拼接;h表示编码层的输出维度,即1D 卷积与多头注意力的输出维度相加。DITM 模型将卷积层Ac和多头注意层Ae的输出拼接作为下一层的输入,既可以融合文本中相邻词的语义信息,又减少了长距离依赖词的信息损失,因此可以更好地表示文本的语义。
3.2.3 共注意力层
借鉴Parikh 等[36]的方法,基于注意力机制的思想,首先计算两个句子的交互矩阵E,然后将交互矩阵E中每一行用softmax 函数进行归一化,作为文本B 中每一个词的注意力权重;同理,对矩阵E中每一列用softmax 函数进行归一化,作为文本A每一个词的注意力权重,具体表示为
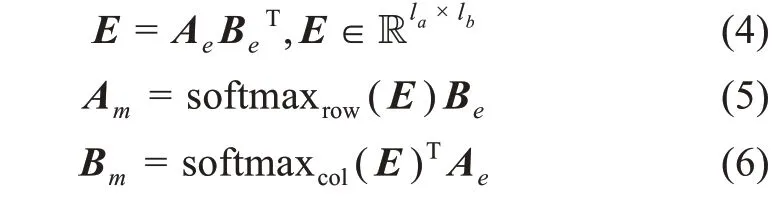
其中,softmaxrow(∙)、softmaxcol(∙) 分别表示对每一行、每一列进行softmax,这样得到的Am和Bm包含文本A 和文本B 在词级别的交互信息。
3.2.4 融合层
融合层通过设计一个融合门的结构将编码层的语义信息表示Ae和共注意力层的包含另一个句子注意力权重的交互信息表示Am进行融合。具体而言,将Ae、Am以及两者的对应元素相乘矩阵进行拼接,然后输入三个不同的前馈神经网络中。其中,一个前馈神经网络的激活函数为tanh,作为融合信息表示;另外两个前馈神经网络的激活函数为sigmoid,可以将输出的值限定在0~1 之间,作为门控。公式为
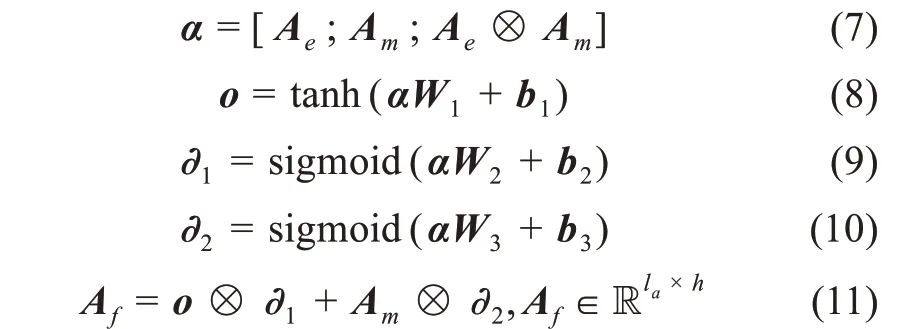
其中,[Ae;Am;Ae⊗Am] 表示三个矩阵的拼接;Wi∈R3h×h,bi∈Rh,i= 1,2,3;⊗代表对应元素相乘。
3.2.5 池化层
池化层是要将融合表示的关键信息提取出来。与其他模型常采用最大池化或平均池化方法不同,本文先使用多个不同大小卷积核的卷积核函数,同时处理上一层得到的融合表示信息;然后再进行池化,这样可以从多个角度上提取关键信息;最后将所有角度的池化向量拼接。其公式为

其中,Convi(∙) 表示卷积核大小为i的1D 卷积;n表示角度的个数;分别表示文本A 和文本B第i个角度的池化向量;k表示滤波器的个数,即卷积神经网络输出的维数。
3.2.6 预测层
在预测层,DITM 模型通过两层前馈神经网络得出文本A 和文本B 的匹配结果:
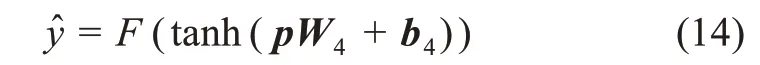
对于排序任务,F的激活函数为tanh,输出维度为1,返回的是两个句子的匹配分数;对于分类任务,F的激活函数为softmax,输出维度为数据集对应的类别个数。
3.2.7 损失函数
对于排序任务,DITM 模型使用排序学习中pairwise 的训练方式,即输入的是一个三元组(A,B+,B-),损失函数是Hinge Loss,即l(A,B+,B-) = Max (0, 1 -f(A,B+) +f(A,B-)) (15)其中,B+、B-分别表示与A相关/无关的样本;f(A,B*) 表示A和B*经过模型得到的匹配分数。对于分类任务,损失函数为交叉熵。
4 实验结果与分析
4.1 数据集
为了验证基于深度交互的文本匹配模型在观点检索、答案挑选、释义识别和自然语言推理任务上的效果,本文分别在四个公开的数据集上进行实验,四个数据集分别为SOCC (SFU Opinion and Comments Corpus)[37]、 WikiQA[38]、 Quora[32]和SciTail[39]。 其中,SOCC 是一个大型的观点评论语料库,包含10339篇观点新闻和663173条评论的相关信息[37],在这个数据集上用到的评价指标为NDCG@3、NDCG@5和MAP (mean average precision)。 WikiQA 是基于维基百科的问答数据集,包含1200 余个具有正确答案的问题,任务是以问题为查询,从候选答案中检索出正确的答案,该数据集用到的评价指标是MAP和MRR (mean reciprocal rank)。Quora 是一个释义识别的数据集,包含40 万对问题,任务是判断样本中的问题对是否具有相同含义,评价指标是Ac‐curacy。SciTail 是一个科学领域的自然语言推理数据集,包含2 万余组训练样本,前提和假说句子的关系包括蕴含和中立两种类别,其评价指标也是Ac‐curacy。训练时,SOCC 与WikiQA 数据集作为排序任务,使用pairwise 损失函数;Quora 与SciTail 数据集作为分类任务,损失函数为交叉熵。
由于SOCC 数据集中没有标注信息,本文对其原始数据进行预处理,生成一个包含新闻标题、相关评论和无关评论的数据集,任务是以新闻标题为查询语句,在此基础上检索与新闻相关的评论。其处理过程为:①鉴于过短的新闻标题或评论不能完整地表达语义,过长的评论可能包含大量的冗余信息,在处理中首先删除新闻标题单词数小于5 的新闻和单词数大于80 或小于10 的评论。此外,为了确保新闻包含足够多的相关评论,删除一级评论数小于10 的新闻。②采集与新闻相关的评论。本文将子评论数大于等于3 条的一级评论作为对应新闻的正样本,即与新闻相关的评论。③采集与新闻无关的评论。具体而言,首先将筛除后的新闻和评论转化为对应的词向量再取平均,然后计算新闻的表示向量与所有评论(除去该新闻的原始评论) 表示向量的余弦相似度,最后取余弦相似度最大的前k条评论作为负样本,其中k等于该新闻正样本的数量的5 倍。由于原始数据集中的新闻和评论较多,且无关评论只需与新闻具有一定的语义相似即可,综合考虑抽取无关评论的效率与数据集质量,本文实验中采用300 维的GloVe[40]词向量。
处理后的数据包括3885 篇新闻和132366 条评论,随机抽取200 篇新闻及每篇新闻下的所有评论作为验证、测试集。划分好的数据集详细信息如表1 所示。

表1 SOCC数据集信息
此外,本文从测试集中抽取了一组样本,标签为1 表示评论与新闻相关,而0 则表示为评论与新闻无关。数据样本如表2 所示。

表2 SOCC数据样例
4.2 基线方法与参数设置
在SOCC 数据集上,本文采用了九种基线方法,包括传统的文本匹配算法TF-IDF 和BM25,基于表示的文本匹配模型DSSM[16]和ARCI[17],基于交互的模型ARCII[17]、MV-LSTM[27]、BiMPM[32]和ESIM[33],以及基于预训练的模型BERT[23]。
在参数设置中,本文尽可能保证参数在各种模型中的一致性;在不能保证一致性的情况下,尽量保证和原始文献相同。具体而言,针对本文提出的DITM 模型,词嵌入使用预训练的300 维GloVe 词向量,字符特征的维数设置为147;在编码层,卷积神经网络的卷积核大小设置为3,滤波器个数设为128,多头注意力的头数为4,每一个注意力头的维数设为64;交互模块的循环次数N设为2~3;在池化层角度数n设为3~4,每一个角度的卷积神经网络的滤波器个数是128。
对于DSSM,本文使用三层的前馈神经网络,每一层的隐藏单元都设为256; 对于ARCI 和AR‐CII,均使用两层的卷积和最大池化,其中卷积神经网络的卷积核大小设为3,滤波器的个数设为256; 对 于MV-LSTM、 ESIM 和BiMPM,本文 将BiLSTM 和前馈神经网络的隐藏单元设为256,MV‐LSTM 的最大池化的k值设为256,BiMPM 的匹配函数的视角数设为5。此外,以上基线方法和本文提出的方法相同,均使用Dropout (统一设为0.4)减少过拟合问题,训练时使用学习率为0.0001 的Adam 优化器。对于BERT,本文先将样本中的文本对用SEP 标记分隔,然后输入BERT-Base 模型中,取其头部CLS 标记的向量作为两个句子的匹配向量,再输入到前馈神经网络得到两个句子的匹配结果,由于学习率太高,BERT 模型无法收敛,因此,本文将学习率设为0.00001。
4.3 基础实验
在SOCC 数据集上,基线方法以及DITM 的实验结果如表3 所示。可以看出,在传统的文本匹配算法中,BM25 的三个指标(即NDCG@3、NDCG@5 和MAP) 分别为0.400、 0.370 和0.364,优于TF-IDF的三个指标(分别为0.186、0.196 和0.241)。在基于表示的基线方法中,ARCI 的三个指标分别为0.502、0.473 和0.470,优于DSSM 的三个指标(分别为0.486、0.470 和0.447)。在基于交互的基线方法中,ESIM 的三个指标分别为0.908、0.845 和0.801,优于ARCII (0.529、 0.509 和0.500)、 MV-LSTM (0.786、0.734 和0.682) 和BiMPM (0.860、0.811 和0.750)。对比传统的匹配算法和基于深度学习的文本匹配模型,可以看出,在SOCC 数据集上,基于深度学习的文本匹配模型可以取得更好的效果;在基于深度学习的文本匹配模型中,对比基于表示和基于交互的方法,可以看出,后者的效果均优于前者。
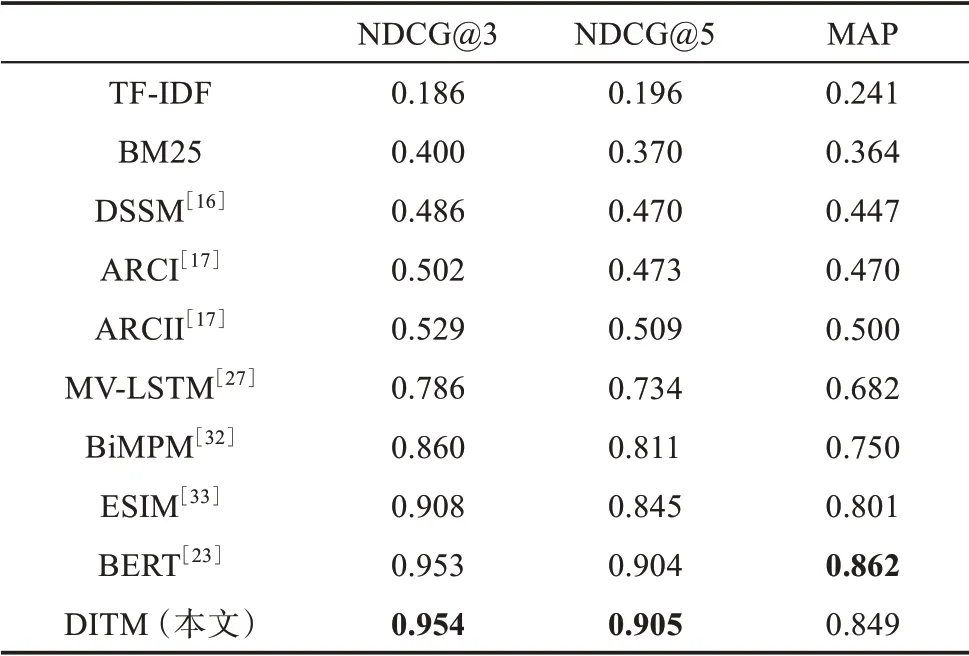
表3 SOCC数据集实验结果
相比于基线方法,本文提出的DITM 模型的三个指标分别为0.954、0.905 和0.849,优于两种传统的文本匹配算法(TF-IDF 和BM25)、两种基于表示的基线方法(DSSM 和ARCI) 和四种基于交互的基线方法(ARCII、MV-LSTM、BIMPM 和ESIM)。相比于传统匹配算法中表现最好的BM25,DITM 模型的NDCG@3、NDCG@5 以及MAP 值分别提高了0.554、0.535 和0.485;相比于基于表示的模型中表现较好的ARCI,DITM 模型的NDCG@3、NDCG@5以及MAP 值分别提高了0.452、0.432 与0.379,均取得了较大幅度的提升;相比于基于交互的模型中表现最好的ESIM,DITM 模型的NDCG@3、NDCG@5以及MAP 值分别提高了0.046、0.060 与0.048。
鉴于BERT 模型在自然语言处理相关应用中的重要性,本文进一步将DITM 与BERT 模型的效果进行了比较。 DITM 模型的NDCG@3 和NDCG@5值优于BERT,而MAP 值低于BERT,总体而言两者效果相当接近。从模型的适用性来看,BERT 需要在大型语料库中预先训练其网络参数,并在针对特定任务的数据集上进行微调,因此,在后者(即特定任务数据集) 数据量较小的情况下也能取得较好的实验效果。在数据量达到一定规模的情况下,BERT 相较于DITM 的优势有所减弱。例如,针对本文实验数据集,从参数数量来看,BERT 作为预训练模型,具有更多的参数(110M),DITM 仅有7.2M 左右的参数;从计算速度上看,在针对特定任务的微调过程中,BERT 仍需要较大的计算量,相比之下,DITM 能节省一定的时间成本。
为了进一步探究本文提出的模型与先前文本匹配模型的效果差异,本文在WikiQA、Quora 和Sci‐Tail 数据集上与六种效果较好的基线方法(包括单次交互的文本匹配模型DecAtt、 ESIM、 BiMPM、DIIN 和HCRN,以及多次交互的文本匹配模型RE2)进行比较,研究结果如表4 所示。
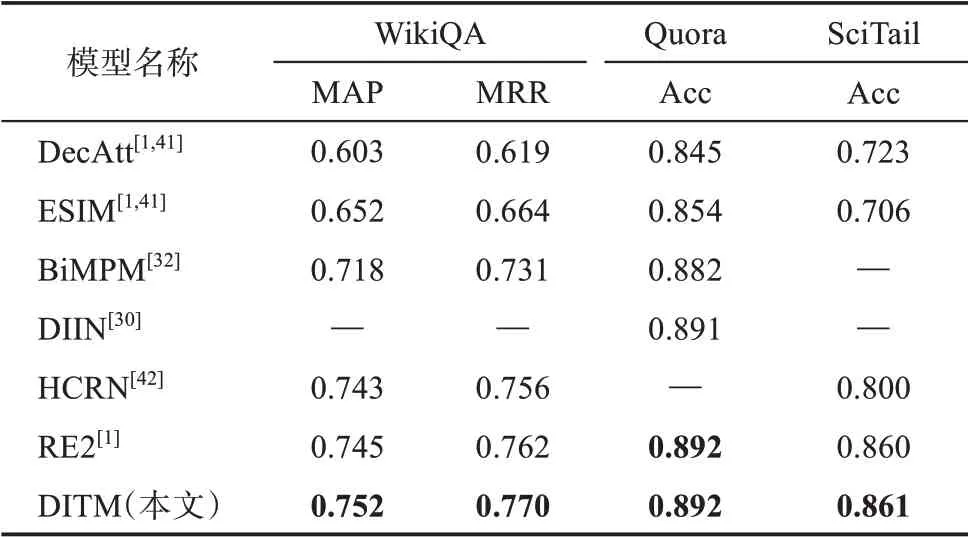
表4 WikiQA、Quora、SciTail数据集实验结果
由表4 可以看出,在WikiQA 数据集上,DITM取得了最好的效果(MAP 和MRR 值分别为0.752 和0.770)。相比于在SOCC 数据集上表现较好的ES‐IM,其MAP 和MRR 值分别提高了0.100 和0.106;相比于单次交互的基线方法中表现最好的HCRN,其MAP 和MRR 值分别提高了0.009 和0.014;相比于多次交互的RE2 模型,其MAP 和MRR 值分别提高了0.007 和0.008。 在Quora 数据 集上,DITM 的Accuracy 与RE2 相同,均达到了0.892,且优于其他的基线方法。在SciTail 数据集上,DITM 的Accura‐cy 达到了0.861,并且优于所有的基线方法。
4.4 扩展实验
为了进一步探究在基于深度交互的文本匹配模型中,网络结构对模型效果是否具有显著影响,本文在SOCC 与WikiQA 数据集上进行了三组扩展实验,以检验多头注意力及其头数、池化层角度数和交互模块的循环次数对模型效果的影响。
4.4.1 多头注意力及其头数对模型效果的影响
从理论上看,1D 卷积可以融合句子中相邻词的语义信息,但忽视了长距离词的影响;自注意力可以有效地解决长距离依赖问题,多头注意力在自注意力的基础上,从多个子空间学习相关的信息。因此,将1D 卷积与多头注意力结合起来可以更好地表示句子的语义信息。为了探究多头注意力及其头数对模型效果的影响,在实验中,保持其他参数不变,将多头注意力层的输出维数固定为256,改变注意力头数以及每一头的维数。其中,注意力头数等于0 表示编码层中去除多头注意力,只保留1D卷积神经网络。为了公平比较,当注意力头数等于0 时,将1D 卷积神经网络的滤波器个数增加到与原始模型编码层的输出维数保持一致。 在SOCC 和WikiQA 数据集实验结果如图2 和图3 所示。
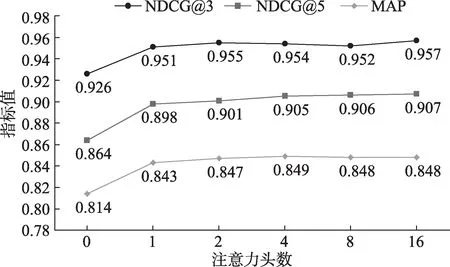
图2 注意力头数对SOCC数据集的影响
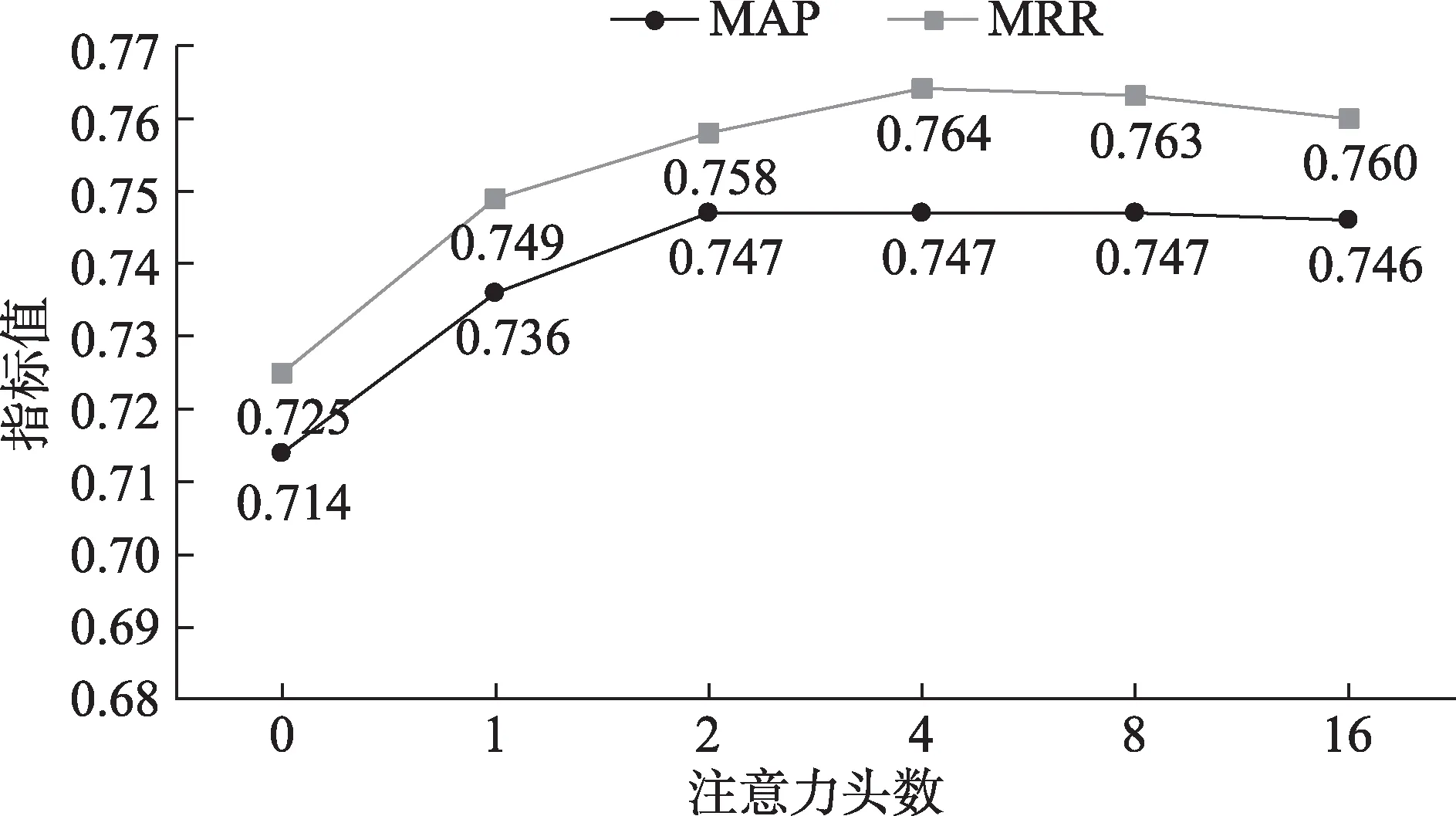
图3 注意力头数对WikiQA数据集的影响
由图2 和图3 可以看出,当去除多头注意力层时,相比于DITM 原模型(注意力头数为4) 的结果,在两个数据集上的效果均显著下降。具体而言,在SOCC 数据集上,NDCG@3、 NDCG@5 和MAP值分别下降了0.028、 0.041 和0.035; 在WikiQA 数据集上,MAP 和MRR 值分别下降了0.033 和0.039。当保留多头注意力层时,并且注意力头数为2、4、8 或者16 时,模型能够取得更好的效果,在该区间中模型效果没有显著差异。当注意力头数为1 时,相比于DITM 原模型(注意力头数为4)的结果,在SOCC 数据集上,NDCG@3、NDCG@5 和MAP值降低了0.003、 0.007 和0.006;在WikiQA 数据集上,MAP 和MRR 值分别降低了0.011 和0.015,这是因为仅在一个子空间学习信息,不能完全体现多头注意力的优越性。
4.4.2 池化层角度数对模型效果的影响
为了探究池化角度数对模型效果的影响,在实验中,保持其余参数不变,只改变池化的角度数n。其中,角度数n等于0 表示不使用卷积神经网络,直接对融合层的结果进行池化。由于n过大时会导致池化层提取的特征向量维数过大,既增加了参数数量,也容易导致过拟合的问题。因此,本文实验中将n的最大值设为4。在SOCC 和WikiQA 数据集的实验结果分别如图4 和图5 所示。
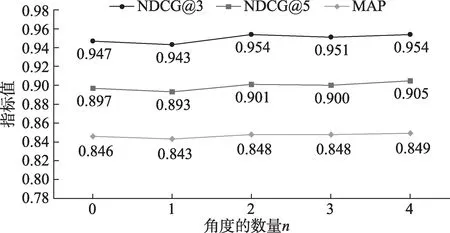
图4 池化角度数对SOCC数据集的影响
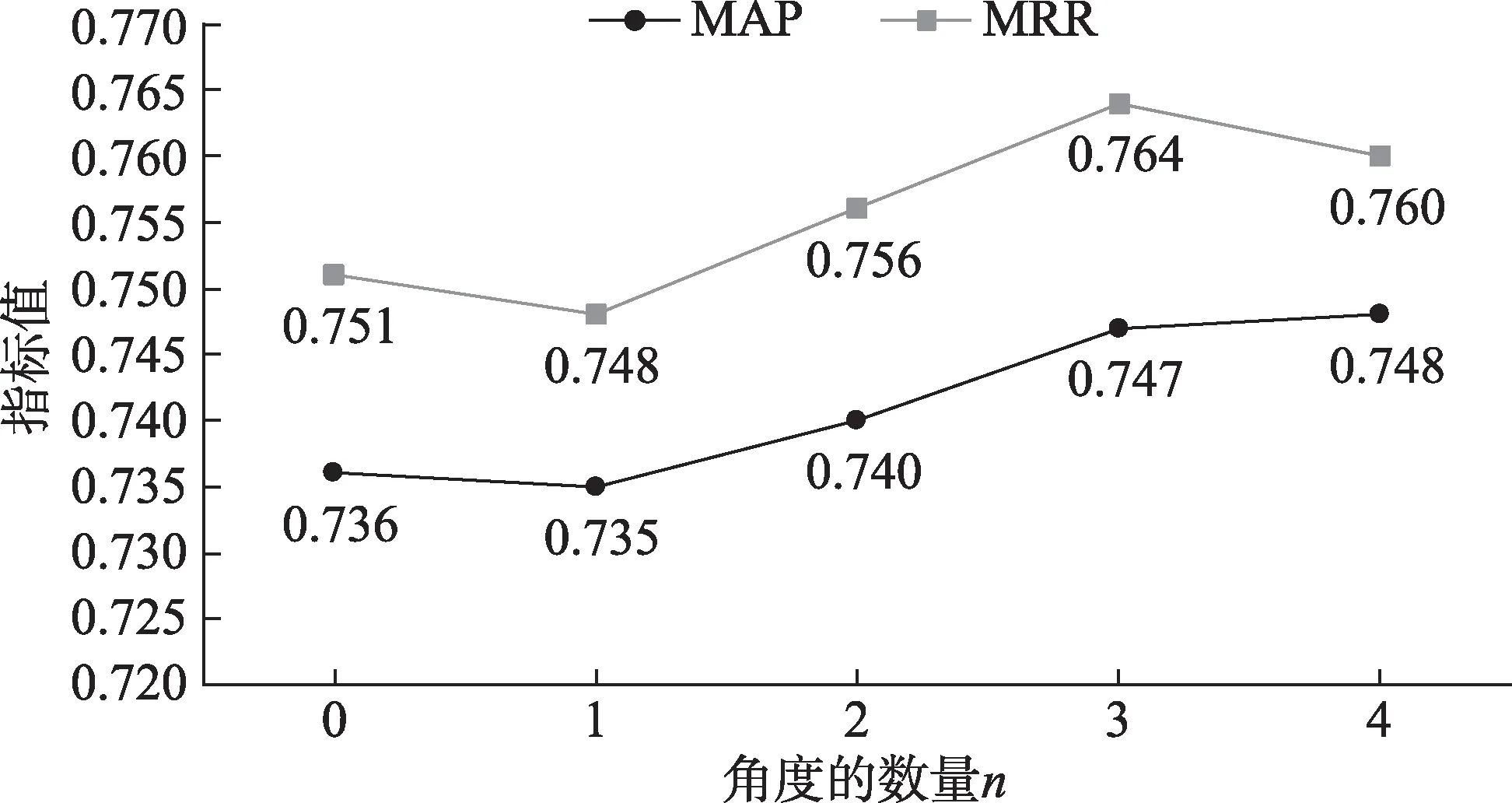
图5 池化角度数对WikiQA数据集的影响
由图4 和图5 可以看出,当模型仅从一个角度进行池化时,其效果与直接池化的方法相近。将n增加到2 时,相比于直接池化,在两个数据集上能够取得更好的结果。 具体而言,在SOCC 数据集上,NDCG@3、 NDCG@5 和MAP 值分别提高 了0.007、0.004 和0.002;在WikiQA 数据集上,MAP和MRR 值分别提高了0.004 和0.005。当n从2 持续增加到4 时,模型效果进一步提升。具体而言,在SOCC 数据集上,NDCG@3、 NDCG@5 和MAP 值分别提高了0.004、0.004 和0.001;在WikiQA 数据集上,MAP 和MRR 值分别提高了0.008 和0.004。
4.4.3 交互模块的循环次数对模型效果的影响
从理论上来看,一方面,交互模块的多次循环,能够更好地提取两段文本深层次语义特征以及两者之间的交互信息,进而有效地提升模型的效果;另一方面,若交互模块循环次数过多,则会导致模型的网络结构过于复杂,既增加模型训练参数、加长推理时间,又容易丢失底层的特征,增大训练难度,从而导致效果有所下降。为探究循环次数N对模型效果的影响,在实验中,保持其他参数不变,将N的取值范围设为1~5,在SOCC 和WikiQA 数据集的实验结果分别如图6 和图7 所示。

图6 交互模块循环次数对SOCC数据集的影响

图7 交互模块循环次数对WikiQA数据集的影响
由图6 和图7 可以看出,当N从1 加到3 时,模型在两个数据集的结果均能得到显著的提升。具体而言,在SOCC 数据集上,NDCG@3、NDCG@5 和MAP值分别提升了0.012、 0.009 和0.008; 在WikiQA 数据集上,MAP 和MRR 值分别提升了0.024 和0.028。当N从3 加到5 时,模型效果有所下降。 具体而言,在SOCC数据集上,NDCG@3、NDCG@5 和MAP值分别下降了0.011、 0.009 和0.006;在WikiQA 数据集上,MAP 和MRR 值分别下降了0.013 和0.015。 这表明相对于单次交互而言,多次交互可以更全面地捕捉语义特征和句间交互信息,但当模型过深、过复杂时,容易丢失底层特征,从而导致模型效果反而有所下降。从本文的数据集来看,当交互模块循环的次数为3 时,模型取得了最好的效果。
4.5 文本匹配效果实证分析
本文对比了DITM 和ESIM 在数据集SOCC、WikiQA 和SciTail 中的预测结果,在每个数据集中各随机抽取一条样本,如表5 所示。可以看出,在SOCC 数据集的样本中,虽然两个句子仅有一个相同词 “smoking”,但DITM 可以很好地理解两个句子的语义,并正确地判断两个句子的相关性,而ESIM 错误地理解句子的语义,并做出相反的判断;在WikiQA 数据集的样本中,相较于ESIM,DITM模型可以更好地理解问题和答案的语义,从而做出更合理的预测;在SciTail 数据集的样本中,相较于ESIM,DITM 模型可以准确地理解前提句子和假说句子的逻辑关系。

表5 文本匹配效果实证分析对比
4.6 讨 论
本文提出了一个基于深度交互的文本匹配模型DITM,在此基础上针对三个研究问题进行探讨。针对第一个研究问题(相较于传统的模型,基于深度学习的文本匹配模型是否具有更好的效果),在SOCC 数据集上的实验结果表明,相较于传统的文本匹配算法,基于深度学习的文本匹配模型能取得更好的效果。针对第二个研究问题(在基于深度学习的文本匹配模型中,基于交互的方法性能是否优于基于表示方法),在基于深度学习的文本匹配模型中,基于交互的文本匹配模型的效果均显著优于基于表示的文本匹配模型。这是因为基于交互的文本匹配模型考虑到了文本对之间复杂的交互信息,能够更好地把握语义焦点。针对第三个研究问题(在基于深度学习的文本匹配模型中,网络结构对模型效果存在怎样的影响),在扩展实验部分中,本文探究了网络结构对模型效果是否具有显著影响,从多头注意力及其头数、池化角度数和交互模块的循环次数三个方面进行实验,实验结果表明:①卷积层后加入多头注意力可以有效地提升模型的效果;②多角度池化能为模型带来更好的效果;③交互模块多次循环能够有效地提升模型的效果,但若循环次数过多,则会导致模型的网络结构过于复杂,会降低模型效率和效果。
从模型总体实验效果来看,DITM 在WikiQA、Quora 和SciTail 数据集上均取得了最优效果,在SOCC 数据集上与表现最优的BERT 模型效果相近,证明了DITM 的有效性和普适性。从模型的计算成本和效率来看,DITM 模型拥有较快的运行速度和适中的参数量,在计算能力有限的情况下,面对不同场景和任务都能够取得良好的效果,证明其具有较好的普适性。从模型的可解释性来看,DITM 充分考虑了文本上下文信息和文本对之间的交互信息,在编码层使用1D 卷积和多头注意力机制对句子表示进行编码,既能保留句子中相邻词的融合信息,又能捕捉到远距离的词信息;在共注意力层,基于注意力机制为两段文本分别生成交互信息矩阵;最后经过池化层,从多个角度提取信息并作为预测的依据。
从模型的推广来看,相较于应用在单一场景下的文本匹配模型,DITM 模型能够在多种场景下应用并取得了良好的效果。 本文的实验结果表明,DITM 在观点检索、答案挑选、释义识别和自然语言推理四种文本匹配任务上的表现优越,具有较好的竞争力。除了实验中用到的四种任务,DITM 模型还可以推广到其他自然语言处理任务中,如阅读理解、机器翻译和信息抽取等。此外,从理论上看,DITM 模型的实质是计算文本对之间的语义相似度,当研究对象是医学领域的文本信息时,该模型可推广到针对医学问题的答案推荐中;当研究对象是法律文书时,可推广到针对法律案例的条款推荐中;当研究对象是电子商务领域的产品评论或属性时,可推广到评论情感分析或个性化推荐研究中。除此之外,DITM 模型在学术论文、地理信息系统或社交平台等领域的研究中也具有重要的使用价值。
5 结 语
文本匹配是许多自然语言处理任务的核心部分,其要解决的问题是如何判断两段文本句子的关系。针对文本匹配中长距离依赖、交互信息不充足和泛化能力弱等问题,本文提出了一种基于深度交互的文本匹配模型。该模型以1D 卷积和多头注意力作为编码器,既注重邻近词的信息,又兼顾远距离词的作用;通过多次循环以编码层、共注意力层和融合层组成的交互模块,充分获取两个句子间的交互信息;通过使用多角度池化提取关键信息,从而可以更好地预测两个句子的关系。研究结果表明,DITM 在 观 点 检 索(SOCC)、 答 案 挑 选(WikiQA)、释义识别(Quora) 以及自然语言推理(SciTail) 这四个文本匹配任务上,均取得了最好的效果,并且具有较好的泛化能力。
在后续的研究中,我们将进一步探究基于深度交互的文本匹配模型在阅读理解、对话等更多任务,以及医疗、电商等更多应用场景的效果。此外,我们将在深度交互的基础上,进一步引入外部知识库信息以增强对文本的语义理解,从而提升文本匹配效果。
