适于长短文本分类的CBLGA和CBLCA混联模型
2021-10-26王得强王立平
王得强, 吴 军, 王立平
(清华大学 机械工程系, 北京 100084)
0 引 言
如今随着数字信息技术的发展, 各行业中的文本信息数据量飞速增长。这些数据中蕴含着丰富的信息资源, 有着巨大的潜在可挖掘价值, 但其中仍存在着许多信息杂乱无序的问题, 如何从这些潜在信息量巨大的散乱文本数据中提取到可用的资源已成为各行业研究中高度关切的问题。而作为解决该问题的一项关键技术----文本分类, 通过对行业文本数据进行规范归类, 有助于更好地管理与挖掘文本信息, 从而促进行业信息的挖掘利用, 推动行业发展。近年来, 研究人员对文本分类的研究也取得了一定的进展, 但仍然存在准确率和分类速度难以兼备的问题。
现在常用的文本分类技术有支持向量机(SVM: Support Vector Machines)[1]、 朴素贝叶斯、 K最近邻(KNN: K-Nearest Neighbor)[2]、 隐马尔可夫模型(HMM: Hidden Markov Model)[3]等。而随着近几年深度学习算法在自然语言处理领域取得越来越多的优秀成果, 利用神经网络进行文本分类成为一个重要的研究方法, 目前使用较多的模型有循环神经网络(RNN: Recurrent Neural Network)[4]和卷积神经网络(CNN: Convolution Neural Networks)等模型。而对在计算机视觉领域表现尤佳的卷积神经网络(CNN)在文本分类领域中, CNN可充分发挥自身含有的多层感知器的拟合功能, 在文本分类过程中发挥了很好的非线性关系映射能力和高维复杂数据学习能力, 在语音识别、 计算机视觉等领域中发挥了重要且效果显著的作用[5]。针对英文文本, Kim等[6]提出了一种适用的分类模型, 主要方法是先对词向量进行数据的预处理, 然后将其输入到CNN中, 经模型处理后输出句子类别。胡荣等[7]基于文本分类技术提出了一种针对课程评论的隐式评价对象的识别方法; 高云龙等[8]考虑不同的数字特征, 提出一种改进CNN的短文本分类模型; 齐玉东等[9]在原有的CNN文本分类模型上进行了改进, 提出了一种适用于海军军事文本的分类模型, 改进后的分类模型在准确率和召回率等方面比K近邻算法、 SVM、 TextCNN等模型相比均有所改善。梁斌等[10]则在CNN模型中引入了Attention机制, 这样构建的新的混合模型不仅如期地加快了模型的训练速度, 而且在一定程度上提升了模型分类的精确性; 颜亮等[11]提出了一种混合模型结构方法, 结合VDCNN(Very Deep Convolutional Neural Networks)及BiGRU的特点和优势构建了文本分类模型, 最终实现了模型分类精度的有效提升; 张玉环等[12]将LSTM(Long Short-Term Memory)神经网络和GRU(Gated Recurrent Unit)神经网络相结合构建新的情感分类模型, 在降低训练时间的同时, 提升了分类的精确性。此外, 在手术病例中由于不直接包含切口数量, 导致切口数量无法被直接抽取, 卢淑祺等[13]结合文本分类的思路, 将切口数量抽取问题转换为文本分类问题, 利用双向LSTM神经网络与Attention机制构建了分句切口数目提取模型。Qiao等[14]在研究文本分类时提出了单词本身嵌入和与局部上下文交互的区域嵌入方法, 提高了对文本的表示能力, 并在多个数据集上获得了优于以往模型的效果。
通过调研发现, 目前在文本分类方面的深度学习模型应用基本上可以达到较高的准确率或令人满意的分类效率(训练速度、 分类速度等), 但由于各分类模型在准确率和效率方面无法兼得, 即目前有不少深度学习模型在文本分类方面实现了较高的准确率, 但训练速度仍有待提升; 有些模型的表现则恰恰相反。综上, 如何设计一种模型, 使其在实现较高的文本分类准确率的同时, 依然可以具有较高的效率, 成为由于当今在文本分类方面的一项需要深入研究的重点工作。笔者针对当前各行业中文本信息的准确快速分类需求进行了模型设计, 旨在进一步提高模型分类准确率的同时, 使模型的训练和分类速度获得提升。
笔者主要贡献有如下3个方面。
1) 构建了基于Attention的改进CNN-BiLSTM/BiGRU混联文本分类模型(简称CBLGA), 即首先并联不同卷积核的卷积神经网络(CNN)同时提取多种不同文本向量的局部特征, 并利用BiLSTM和BiGRU并联保证模型在不同的数据集上均可以有不错的运行效果, 通过BiLSTM和BiGRU组合提取了与文本中的上下文有密切关系的全局特征, 综合利用文本的局部特征和全局特征信息。
2) 构建了基于Attention的改进CNN-BiLSTM/CNN混联文本分类模型(简称CBLCA), 即首先利用CNN对文字序列的局部特征进行挖掘, 再将CNN的输出分为两部分, 其中一部分输入BiLSTM网络中, 用于对文字序列的整体特征进行挖掘。另一部分则保留文字序列的局部特征, 并通过调整输出大小直接匹配BiLSTM网络的输出, 最后整合两部分的模型结构以获取文本序列的局部特征和全局特征。
3) 建立一套针对不同长度的文本采取相应措施的分类流程。即针对短文本则采用一种混合模型进行分类处理, 此时模型的选择重点偏向于分类的准确率; 根据1)、 2)所述模型的结构特点, 此时选用1)中的模型即可在实现很高准确率的同时保证训练速度。而针对较长的文本时, 则采用两种混合模型“分工参与”的方法进行分类处理, 此时考虑长文本的内容分布特点, 在重点内容部分, 模型的选择重点偏向于分类的准确率, 而在较长篇幅的细节内容部分, 模型的选择重点偏向于分类的速度。两种模型结合, 即使面对长文本, 模型也可以在提升准确率的同时保证训练速度仍有一定程度的提升。
1 该研究的相关技术
考虑到笔者在设计文本分类模型时引入了神经网络结构和注意力机制, 所以首先在本节引出神经网络结构和注意力机制的相关知识。
1.1 卷积神经网络
适于文本分类的CNN结构如图1所示。对中文文本进行数据清洗、 过滤等预处理操作后, 采用jieba分词机制进行分词, 拆分训练集、 验证集和测试集后输入CNN通过训练得到词向量, 进而映射成二维句子矩阵, 之后采用大小分别为1、3、5的卷积核对映射形成的二维矩阵进行卷积运算, 提取特征向量, 若用f代表Relu激活函数, 当卷积核的权重向量为W、 输入数据为X时, 则卷积层的运算特征图C可表示为
C=f(X⊗W+b)
(1)
其中⊗为卷积运算;b为偏移量。

图1 适于文本分类的CNN模型结构Fig.1 The model structure of convolutional neural network (CNN) applied to text classification
采样操作可以筛选出强特征。在下采样后进行连接, 之后生成特征向量, 再经softmax分类器输出二分类的结果。可以看出, CNN借助卷积运算操作的优势可实现对多层网络结构进行监督学习, 在卷积运算时设计不同尺寸的卷积核提取不同的文本特征, 不仅降低了整个神经网络模型参数的个数, 同时也提升了模型训练的性能。
1.2 长短时记忆神经网络(LSTM)

图2 LSTM模型结构Fig.2 The model of LSTM
LSTM是由循环神经网络(RNN)衍生的, 相比RNN, LSTM引入了多个门控制器, 配合设计的跨层连接, 增强了模型对位于远近时刻的信息的记忆能力, 有效削减了梯度消失造成的影响, 可以解决传统的RNN不具备记忆能力的缺陷, 增强网络对长期序列信息的记忆能力。其结构如图2所示。
LSTM在t时刻有隐藏状态h(t)和细胞状态C(t)。可以看出, LSTM与普通RNN明显不同的是它引入了输入门、 遗忘门和输出门3种门结构, 前一时刻的隐藏细胞状态在经过遗忘门时按照一定概率被忘记, 输入门和遗忘门的结果共同形成细胞状态C(t), 输出门则会根据长期记忆和短期记忆决定输出状态。当用于分类情景时, 在LSTM顶部加入softmax层即可使模型输出分类结果。
由上可见, LSTM中设计巧妙的门控机制使其可以有效缓解梯度消失问题, 但较复杂的模型结构使模型的占用资源较大、 运行时间更长。
1.3 门循环单元网络(GRU)
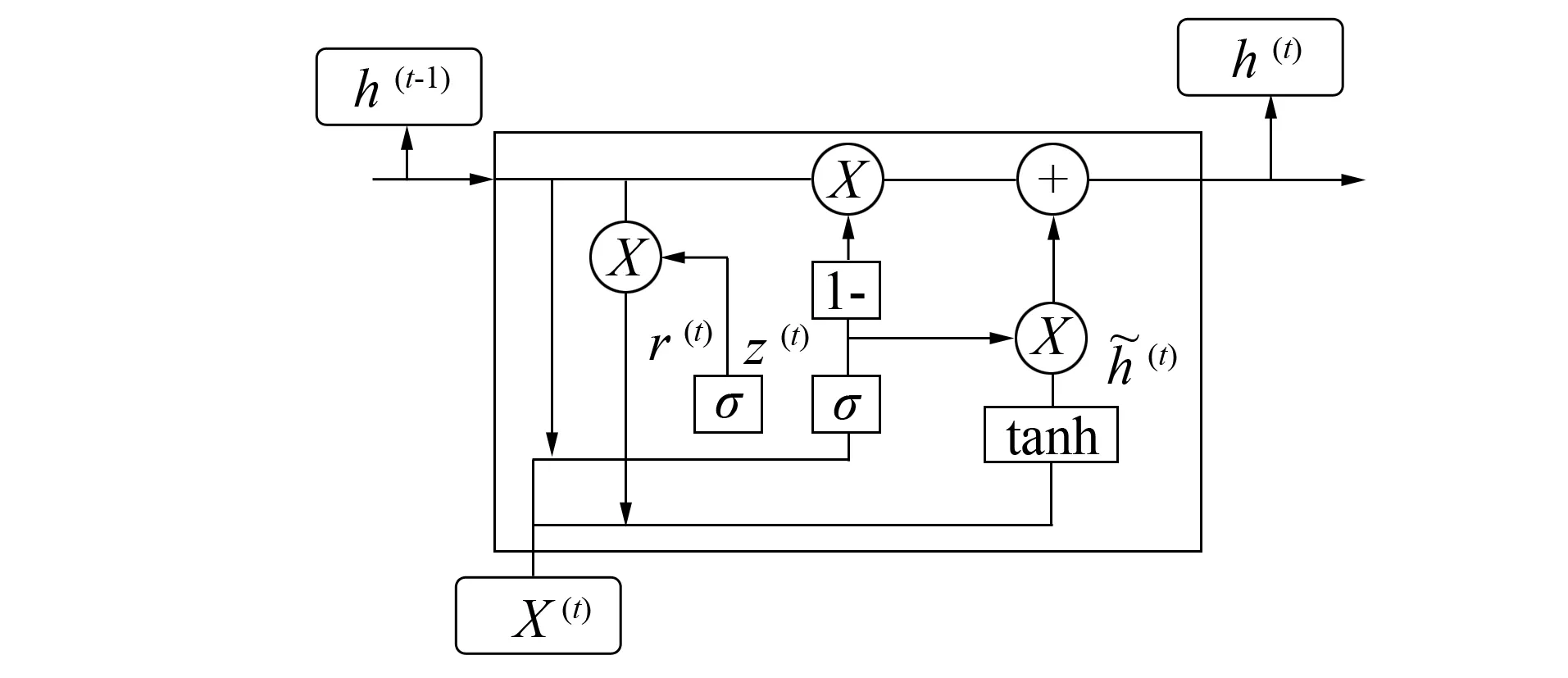
图3 GRU模型结构Fig.3 The model of GRU
GRU作为LSTM的改进, 在整体思路上对序列数据的处理模式与LSTM类似, 主要从模型结构上对LSTM进行了改进: 将LSTM中的输入门、 遗忘门和输出门3种门结构整合成了更新门和重置门2种门结构, 如图3所示, 不变的处理思路和简化的结构使GRU在保持长效记忆能力的同时降低了参数量和计算量。

1.4 注意力机制
“注意力”最早起源于人们对视觉的研究, 由此迁移到信息技术领域并产生了注意力机制[15], 提高了对数据资源的处理能力。在笔者的应用中, 具体是在输入序列进入神经网络后, 由Attention机制对网络的中间层输出结果进行暂存, 之后将暂存的中间结果送入模型中进行训练与选择, 在模型的输出部分, 将训练后暂存的中间结果与输出序列进行关联, 经过此运算, 对神经网络的输出序列, 其中每个输出项的生成概率都会取决于注意力机制在输入序列中的选择, 进而形成目标性更强的模型。
从数学模型视角看, Attention机制的本质可以用一个映射函数“f:v→R”表示: 一个查询“query”到一系列“键key-值value对”的映射。这个映射函数的目的就是调节分配重要的权重给更重要的部分, 由此可以看出, Attention机制会帮助人们理解和分析模型在关注什么, 以及它在多大程度上关注特定的输入-输出对[15]。注意力机制的基本概念依赖于在到达输出时能访问输入句子的所有部分, 使模型对序列中的不同部分施加不同的注意力, 进而可以推导出依赖关系。
2 新型混联文本分类模型
2.1 新型混联文本分类模型CBLGA
如图4所示, 笔者构建的第1个特征融合模型由CNN并联组合和BiLSTM/BiGRU并联组合共两个组合串联融合组成, 可称为CNN-BiLSTM/BiGRU-Attention模型(简称CBLGA模型), 设计词嵌入层作为其中CNN部分的第1层, 生成句子矩阵后, 作为后续层的输入以表征句子的语义信息, 之后进入第2层进行卷积运算操作, 提取局部特征。
在进行卷积操作时, 设置了不同大小的卷积核尺寸以实现同时提取多种不同文本向量的局部特征, 此处设置3种卷积核的尺寸分别为1、3、5, 数量均为256个, 选择步长stride大小为2, 选择padding为same模式, 使输出长度等于输入长度, 对其进行卷积运算, 提取文本中多种特征词向量的局部特征; 第3层进行下采样操作, 这里采用的是最大值采样方法提取突出特征。经采样生成的固定维度的特征向量进入到用于防止过拟合的Dropout层, 笔者对神经元以20%的概率随机丢弃, 之后将3个Dropout层输出的特征拼接, 作为BiLSTM和BiGRU并联组合模型输入特征的一部分。
作为融合了3种不同CNN网络输出的Concatenate层, 同时也是BiLSTM/BiGRU部分的第1层, 此时其每个词向量的维度设置为256×3=768维; 下面两层均是维度为64的隐藏层, 输入BiLSTM和BiGRU模型时采取两个方向共同进行的方式, 之后对产生的双向时序信息进行保存, 对BiLSTM和BiGRU输出的特征进行融合, 随后将Attention机制引入到融合后的特征中, 输入全连接层, 最后经过softmax层输出文本类别名称。由于在新模型中设计了CNN结构对文本进行卷积操作, 加快了文本特征的提取速度, 同时多种尺度的CNN网络结合BiLSTM与BiGRU模型, 在Attention机制的影响下, 有力地保证了新模型具有高分类精度。

图4 CBLGA模型结构简图Fig.4 The model of CBLGA
2.2 混联文本分类模型CBLCA
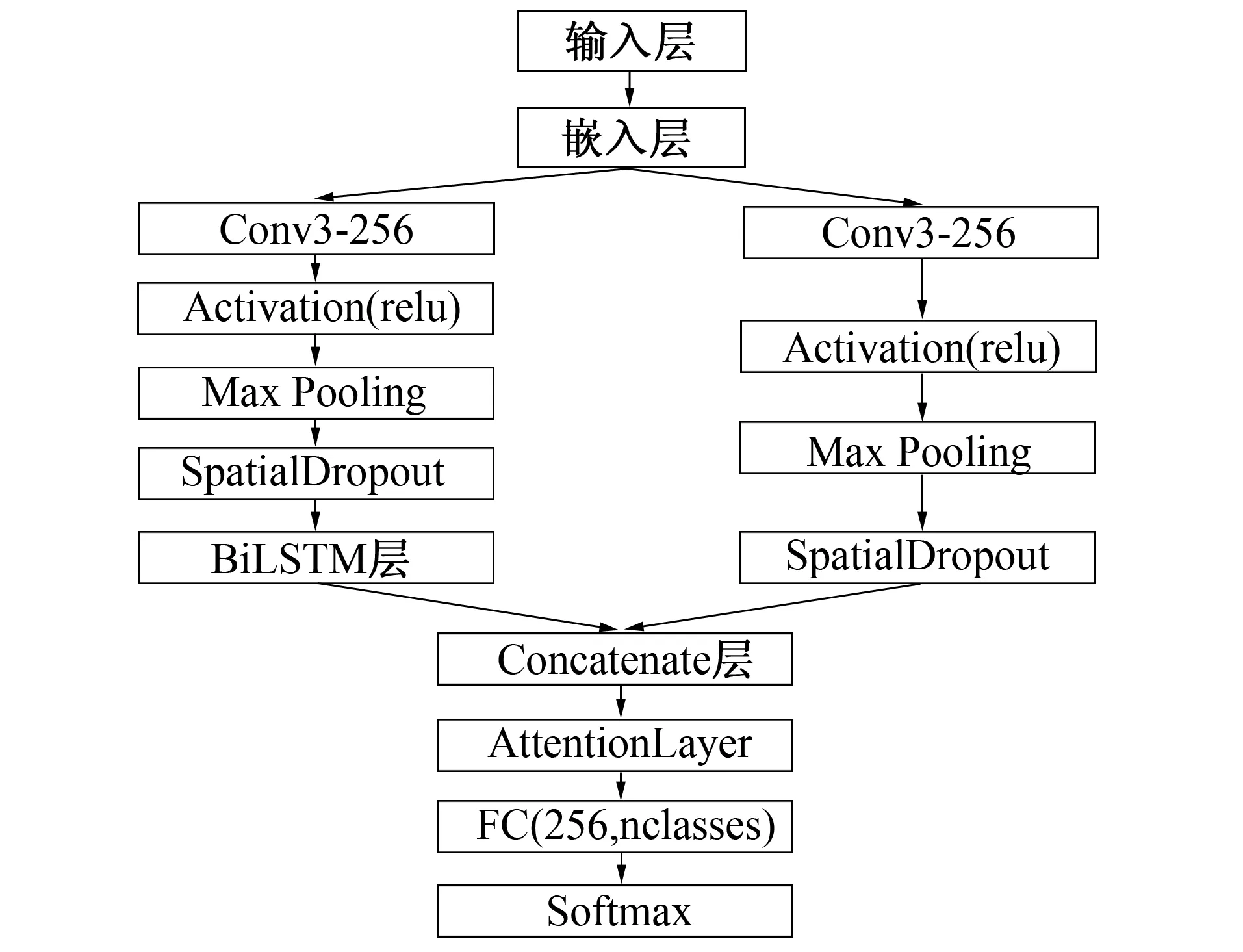
图5 CBLCA模型结构简图Fig.5 The model of CBLCA
除了文本分类模型CBLGA外, 笔者构建的第2个混联文本分类模型是一种基于Attention的改进(CNN-BiLSTM)/CNN混联文本分类模型(简称CBLCA模型), 模型结构如图5所示。
该模型由卷积神经网和BiLSTM串联后再与卷积神经网络并联组合而成, 设计词嵌入层作为其中CNN部分的第1层, 之后进入第2层进行卷积操作, 提取局部特征。此处只有一种卷积核, 设置其尺寸大小为3, 一共256个, 选择步长stride大小为2, 并选择padding为same模式, 以这种结构提取文本中多种特征词向量的局部特征; 第3层进行下采样操作, 并采用最大值采样方法以提取关键特征。然后进入用于防止过拟合的Dropout层, 经Dropout机制处理后, 将输出的特征向量复制为两份, 其中一份作为BiLSTM网络输入特征的一部分, 另一份则直接与BiLSTM的输出进行融合。
综上, 本模型的思路是首先关注文本序列的局部特征, 通过CNN网络实现, 考虑到卷积操作在提取文本特征时可通过调整步长提高速度, 因而可以赋予模型一定的快速性优势; 同时重点关注文本的整体特征, 再将CNN的输出分为两部分, 其中一部分输入BiLSTM网络中, 以提取与文本内容的上下文有关联的全局特征。另一部分用于保留CNN提取的文本内容的局部特征, 直接与BiLSTM网络的输出进行融合, 局部特征与全局特征进行融合, 有助于提高模型的分类精度。其中CNN的文本分类原理如2.1节中所述, 此处不再赘述。
3 笔者构建的长短文本适应性处理机制
笔者建立了一套针对不同长度的文本进行相应预处理和后续分类工作的预处理方法, 主要流程结构如图6所示。以文本长度300作为分界线, 当文本长度小于300时, 视为短文本, 此时采用一种混合模型进行分类处理, 模型的选择重点偏向于分类的准确率; 根据2)、 3)所述模型的结构特点, 此时选用2)中的模型即可在实现很高准确率的同时保证训练速度。

图6 针对不同长度文本进行相应处理的流程图Fig.6 Processing for different length of textHT
当文本长度大于300时, 视为长文本, 此时采用两种混合模型“分工参与”的方法进行分类处理, 考虑到长文本的内容分布特点, 即行业文本的重要内容或者中心思想大多分布在整篇文本的头部和尾部, 占整篇文章的比例大约各为20%, 剩下的60%内容较长、 位置处于中间的文本主要发挥对主体内容的解释作用, 所以在提取行业文本序列中的特征时, 笔者对输入文本的序列的头部和尾部进行了更加精细地分析和处理, 对以上两个区域采用更注重准确率的模型进行分类处理; 而对中间部分的处理过程可以相对弱化, 这一部分篇幅较长, 多数是细节内容, 如果对长文本一律采用注重细节结构的、 准确率高的模型, 则会使模型的训练时间增加和分类速度下降, 增加了计算机运行负担。所以本方案对文本的中间部分采用更注重分类效率的模型进行分类处理; 两种模型相互配合, 则可以在把握文本重点的信息和全局特征的同时提高分类效率。
4 实验与分析
4.1 实验数据
为检验模型在制造行业中的应用效果, 实验时笔者在中国知网上选取了30 000条“并联机构”和“生产线”两类行业数据作为数据集, 考虑到乱码数据、 无标签数据等其他指标不合格数据对模型训练的不利影响, 在经过数据清洗和特征处理环节后, 最终的数据集中剩下27 814条数据, 其中包含“并联机构”类13 983条, “生产线”类13 831条, 对清洗后的原始数据集的顺序进行随机打乱处理, 任意抽取其中10项数据如图7所示, 其中“cat”代表文本类别, “review”代表文本简介, “cat_id”代表类别代号。
按照1 ∶1 ∶8的比例将原数据集划分成测试集、 验证集和训练集, 分别用于模型的测试、 验证和训练工作。

图7 数据集中的部分数据展示Fig.7 Display of partial data in dataset
4.2 实验环境与实验设置
该研究的实验环境为Windows10操作系统, CPU型号为Intel Core i5-6300, 采用Nvidia GeForce GTX 950M(2GByte)的显卡驱动, 模型搭建采用Python语言, 开发工具使用Jupyter-notebook。实验迭代5次, 评价标准主要考虑准确率、 损失率和迭代时间。
对于文本向量, 该实验模型可视为一个由3层网络组成的模型结构, 分别是输入层、 隐藏层和分类层。在实验测试时, 笔者对模型中的多个超参数进行了适当地调整和设置, 通过多次实验, 在每次迭代完成后, 根据实验的准确率和损失率对超参数进行选择和设置。最终在多次实验结果比较后, 选择模型的各项超参数如表1所示。

表1 各神经网络的参数
4.3 实验对比与结果分析
将笔者提出的CNN-BiLSTM/BiGRU-Attention(简称CBLGA)模型和基于Attention的改进(CNN-BiLSTM)/CNN混联文本分类模型(简称CBLCA模型)与其他典型模型进行对比实验, 除了考虑LSTM、 BiLSTM模型外, 还选择了以下常见的3种模型进行对比。
1) GRU。它主要是由Collobert等[16]提出的, 可看作是对LSTM的进一步改进, 其参数更少, 理论上具有更好的收敛效果。
2) BiGRU。它主要是由Feng等[17]提出的, 借助双向GRU网络的全局特征获取能力, 实现了特定文本信息的快速抽取。
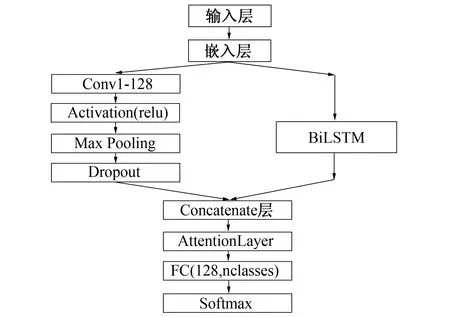
图8 CNN-BiLSTM-Attention模型结构简图Fig.8 Structure of CNN-BiLSTM-Attention model
3) CNN-BiLSTM-Attention。经调研发现, 该模型结构在许多文本分类的研究中出现, 借助CNN和BiLSTM对文本进行特征提取和融合, 最终取得了较好的分类效果, 模型结构简图如图8所示。
本实验中各模型采用的损失函数均为“交叉熵”损失函数, 在选取优化器时, 考虑SGD(Stochastic Gradient Descent)、 AdaGrad、 RMSProp和Adam优化器, 其中由于Adam优化器在运算时对梯度的均值和方差进行了综合考虑, 这是由于其在设计时综合吸收了AdaGrad和RMSProp两种优化器的优点, 基于此而不断迭代更新网络参数, 很适合应用于大规模的数据及参数的场景, 所以笔者选取Adam作为各个模型的优化函数。
此外, 各个模型的训练次数“Epoch”均为5次, 激活函数均采用“Relu”函数, 下采样均为“Maxpooling”方法。实验共进行了5次迭代, 以准确率为指标, 最终选用在测试集上表现最好的结果作为该模型的准确率, 其对应的损失率则作为该模型的损失率, 取5次迭代的平均训练时间作为该模型的训练时间, 同时记录模型的测试时间, 各模型与笔者所提的新型混联模型结果对比如表2所示。
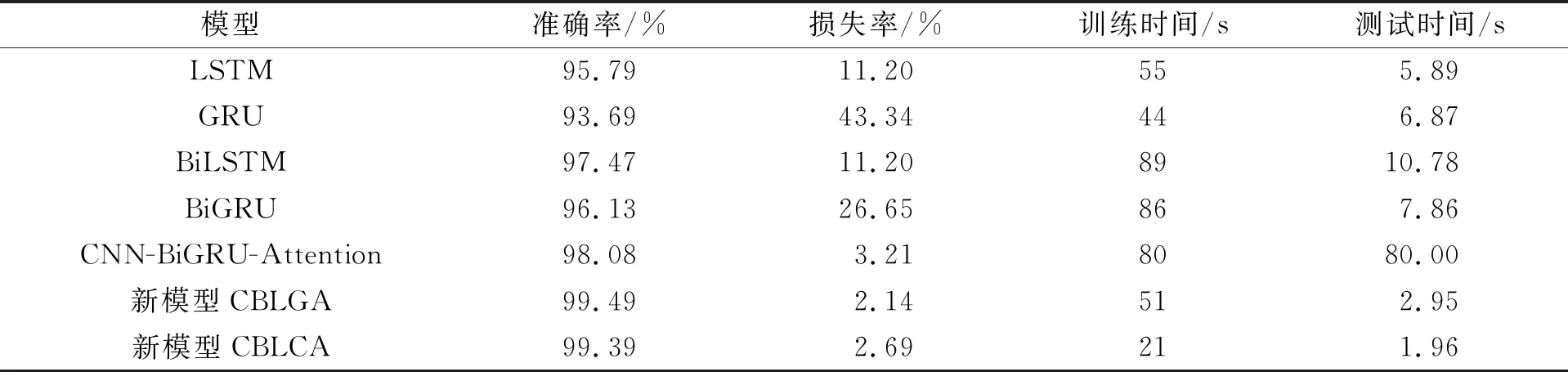
表2 模型与笔者所提的新型混联模型结果对比
从表2可看出, 相比单一的LSTM或GRU模型, BiLSTM或BiGRU模型不仅具有更高的分类准确率, 而且损失率也大大减小, 只是由于模型结构更复杂, 其训练时间更长; 进一步地, 融合CNN模型和Attention机制的CNN-BiGRU-Attention模型则在准确率、 损失率、 训练速度和测试速度方面表现的更好, 说明了该模型的有效性。笔者提出的新模型CBLGA, 即使对比各方面表现均不错的CNN-BiGRU-Attention模型, 新模型CBLGA仍然表现出了更高的准确率、 更低的损失率、 更快的训练速度和测试速度, 除了在训练时间上比单一结构的GRU稍微长外, 新模型CBLGA在各项指标上的表现均优于其他5种典型的传统文本分类模型, 有力地说明了笔者所提的新模型CBLGA在保证训练速度的情况下有效提升了文本分类的准确率、 降低了损失率。另外也可以看到, 相比新模型CBLGA, 新模型CBLCA虽然准确率和损失率表现得稍差, 但其训练速度和测试速度有了明显的提升, 而且新模型CBLCA在各项指标上的表现均优于表中前3种典型的文本分类模型, 有力地说明了该方案所提的新模型CBLCA在保证训练速度的情况下有效提升了文本分类的准确率、 降低了损失率。
在长文本适应性处理方法的验证方面, 笔者融合CBLGA和CBLCA模型对长文本的不同位置进行相应地处理, 结果表现出了更高的效率和准确率, 说明了该方案的提出对于解决分类模型在建立时对输入文本长度的过敏问题有很好的效果。
5 结 语
笔者在行业文本分类技术中引入了CNN网络进行特征抽取、 提出了两种新型混联神经网络模型----CNN-BiLSTM/BiGRU-Attention(简称CBLGA)和基于Attention的改进(CNN-BiLSTM)/CNN混联文本分类模型(简称CBLCA模型), 针对短文本数据, 相比结构较简单的LSTM、 GRU分类模型, 新型模型在迭代时间没有显著增加的基础上, 在准确率和损失率方面均有明显的效果改善; 相比BiGRU分类模型, 新型模型不仅在准确率和损失率方面均有明显的效果改善, 而且大大缩短了迭代时间; 而与另一种使用较为广泛的基于Attention机制的BiLSTM神经网络相比, 新型模型则不仅进一步地提高了准确率, 而且在损失率指标上也有所改善, 同时可以看出, 新型模型的训练时间也得到了明显的降低。说明了该模型既能充分发挥卷积神经网络快速抓取文本部分特征的优势, 又能比较好地发挥BiLSTM/BiGRU模型对较长文本序列的全文特征的抽取, 综合二者可以发现, 新型模型在快速抽取文本局部特征的同时充分考虑了词的上下文语义信息, 因此可以在提高分类准确率的同时也可以保证模型的训练速度。
而针对长文本数据, 笔者提出了长文本适应性处理方法----融合CBLGA和CBLCA模型对长文本的不同位置进行相应地处理, 该方案的提出不仅使文本分类的效率大大提高, 同时也解决了分类模型在建立时对输入文本长度的过敏, 即模型建立时需要给定可处理的文本长度len(txt), 在单一模型结构下, 当len(txt)过大时, 无疑加重了模型的训练和处理负担, 占用资源过大, 容易造成资源浪费; 而当len(txt)过小时, 无疑减小了模型的可使用范围和处理能力, 当面对长文本输入时, 虽然也可以处理, 但由于模型的自动限制, 使只有部分文本进入模型, 很容易造成“一知半解”, 分类结果也不准确。而笔者提出的长文本适应性处理方法则解决了这个问题。对各有数据分类需求的行业提供了有价值的可参考方案。
未来将继续探索适用于行业应用的高效文本分类模型, 并将文本分类模型应用于多个行业的实际应用中, 为促进行业信息的挖掘利用、 推动行业发展做出贡献。
