动态代价敏感的海量物流调度数据挖掘研究
2021-10-25刘春英黄玉文于继江
刘春英 黄玉文 于继江
1、绪论
近年来,信息技术越来越广泛地应用于现代物流企业的各种物流环节中,物流企业在运输、储存、搬运、流通加工、配送等物流业务运行和实施过程中产生与物流调度相关的海量数据[1,2]。海量物流调度数据多以时间序列的形式存在,能够对物流调度正在发生的和未来状况进行描述,是处于动态变化中的数据。对海量动态物流调度数据中隐含深层次信息进行挖掘,从而获取到商品移动过程的情况和其表现出来的移动趋势信息,用这些信息可以对物流调度进行优化,最终实现降低物流调度成本,故对物流调度数据挖掘的研究越来越多的引起物流企业的重视[3]。目前对物流调度数据挖掘的相关研究,多是探讨与分析针对静态数据源的传统数据挖掘技术在物流调度数据分析中的应用,难以处理异构数据源、动态数据源和分散数据源,存在着数据处理瓶颈;目前研究构建的海量数据挖掘模型,难以处理海量动态增长的数据,无法满足海量数据挖掘对计算能力的需求,很难从海量流动数据中发现可理解和有用的知识[4]。大数据时代必须创新数据挖掘理论与方法,将数据挖掘技术应用于分析物流调度数据,研究和探索适应物流企业处理大规模、实时化、动态性物流调度数据的方法和模式,能够有效配置物流资源和辅助物流决策,提高物流企业运行速度和执行效率,促进物流运作的智能化发展进程,这已成为物流企业十分关注和重视的问题。当面对的挖掘任务涉及不同类型的代价时,现有数据挖掘方法并不能满足挖掘要求,代价敏感数据挖掘考虑不同类型数据代价,挖掘的目的在于使得所采取的行为代价最小或产生最优决策行为,对海量动态物流调度数据进行代价敏感数据挖掘,有助于提高物流企业的目标针对性和传输效率,降低物流运输的成本和总投资成本,能够极大地提高物流企业的经济效益,具有非常重要的应用价值和实际意义。
2.动态代价敏感的海量物流调度数据挖掘模型
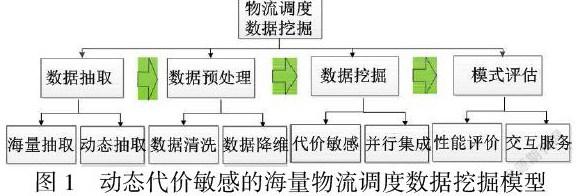
为了有效的对海量物流调度数据进行挖掘,本课题设置如图1 所示的挖掘模型,从数据抽取、数据预处理、数据挖掘和模式评估四个步骤研究动态代价敏感的海量物流调度数据挖掘,具体研究模型如下:
2.1海量动态物流调度数据的抽取
针对海量物流调度数据的海量性,首先利用代价敏感对海量物流数据进行并行抽取。本文首先利用云计算平台对海量数据流进行划分用于并行学习,从海量物流数据中抽取和车辆调度相关的车辆信息、货物信息、道路交通信息、装卸数据、配送数据等海量物流调度数据。然后,针对物流调度数据的动态性特点,利用基于增量式学习的代价敏感抽取技术对海量物流调度数据进行抽取。最后,从异构多数据源中抽取和物流调度相关的历史数据和当前数据。
2.2海量动态物流调度数据的预处理
针对海量物流调度数据含有缺失数据、不确定数据、冗余数据和噪声数据等,对海量物流调度数据的数据清洗。利用代价敏感数据数据清洗模型对海量物流调度数据进行预处理。首先,把海量动态物流调度数据进行分类,针对连续型数据和离散性数据采用不同的数据预处理技术。然后,对海量物流调度数据维度较高的数据,结合代价敏感学习思想,对海量物流调度数据的代价敏感进行降维。最后,获取含有较少噪声并且维度低的海量物流调度数据。
2.3 海量物流调度数据的动态代价敏感挖掘模型
综合考虑车辆行驶路径、顾客对货物的时间要求、调用车辆花费费用和货物的库存费用等各种代价因素,结合动态代价敏感学习思想、并行技术和集成技术,本文提出面向海量物流调度数据的基于增量式学习的代价敏感并行挖掘模型,该挖掘模型能够对配车方案、行车路线和货物组合等物流调度方案提供有效的决策支持。物流调度数据挖掘模型的自适应性,不断对挖掘模型更新力求适应动态海量物流调度数据的变化,选择综合代价最小的调度方案作为最优调度方案,最大化服务顾客的同时降低物流企业调度成本,提高运输资源的利用率。
本文采用分布式并行数据处理方法来挖掘与分析海量物流调度数据,能够有效处理和利用分布在各节点的数据和计算设备,能够对多模块、多源、多格式、多结构的数据进行存储和挖掘,实现实时高效的动态海量物流数据代价敏感挖掘。
2.4挖掘模式评估和交互服务
首先,深入物流调度数据挖掘的不同层次中,结合代价敏感学习思想,对海量物流调度数据的不同处理阶段的模式进行性能评估。挖掘模式评估利用全新的数据对挖掘结果进行检测和评价,如果不满足要求,就要利用动态数据收集调整及处理重新挖掘,从而将用户感兴趣的知识进行挖掘。然后,构建海量物流调度数据的动态代价敏感挖掘交互服务,允许用户通过交互服务功能模块定制物流调度数据挖掘对象、物流调度数据挖掘任务、物流调度数据挖掘方法,并将数据挖掘结果以可视化的形式提交给用户。
3 动态代价敏感的海量物流调度数据挖掘模型的设计
3.1 海量物流调度数据计算环境层的设计
海量物流调度数据计算环境层属于物流信息分析模型的基础,本设计选择分布式计算环境,其主要包括分布式编程环境、分布式文件系统和分布式系统管理等。分布式计算平台利用分布式存储数据,利用冗余存储的方式使数据备份,并且通过分布式数据处理还动态海量物流调度数据挖掘算法,自主分配物流调度数据计算资源,实现动态数据的海量物流调度数据挖掘计算,有效调用動态海量物流调度数据挖掘算法,从而使其能够为服务提供海量物流调度环境。
3.2海量物流调度数据采集层和预处理的设计
海量物流调度数据采集层的主要目的就是实现物流调度数据收集,包括历史数据、当前数据和后续数据。海量物流调度数据采集层的收集的既要实现历史数据和当前数据的转移、集成;又要利用变动物流调度数据捕捉技术收集数据,从而能够实现海量物流调度数据的全面、快速及精准收集和预处理[5]。
3.3 代价敏感海量动态物流调度数据挖掘算法
实现代价敏感海量动态物流调度数据挖掘,通过代价敏感海量动态物流调度数据挖掘算法进行,创建并行代价敏感数据挖掘算法库,无论是代价敏感挖掘算法或者是的深度学习的挖掘算法,都能够实现优化升级和扩充。
代价敏感海量动态物流调度数据挖掘的步骤为:
1)利用代价敏感的FP-Tree算法实现物流调度数据频繁项集挖掘,在 Hadoop 计算平台中进行分布式运算的时候上传到分布式文件系统中;
2)用户能够重写动态代价敏感函数对频繁项挖掘算法进行改写,利用HDFD 存储的物流调度数据流划分成为多个不相交数据分块,之后将数据分块对执行挖掘操作 Datanode 中发送,在接收到指令之后挖掘频繁项集,从而得出局部频繁项集;
3)集合 Datanode 中的局部频繁项集,从而得到全局候选频繁项集。对物流调度数据流进行遍历,得到最终的频繁项集。
4.结论
物流调度为我国经济的主要组成部分,也是实现经济发展转变和提高竞争力的基础。目前的物流调度数据日益呈现出信息量大、数据类型复杂、数据异构性、地理分布广、高度动态性、时效性等特点,而现有研究所提出的相关模型存不足,本文就将物流调度信息作为基础,在物流信息分析过程中融合动态数据挖掘技术,提出了动态代价敏感的海量物流调度数据挖掘智能挖掘,使物流调度智能化程度及信息化效率得到提高,实现企业物流使用范围的扩展,以此使物流信息分析优势朝着现实核心竞争力进行转变。
参考文献
[1]Weihua Liu,Qian Wang,Qiaomei Mao,Shuqing Wang,Donglei Zhu.A scheduling model of logistics service supply chain based on the mass customization service and uncertainty of FLSP’s operation time.Transportation Research Part E:Logistics and Transportation Review,2015,83:189-215.
[2]孙玉砚,杨红,刘卓华,皇甫伟.基于无线传感器网络的智能物流跟踪系统.计算机研究与发展,2011,48:343-39.
[3]张玉峰,曾奕棠.基于动态数据挖掘的物流信息分析模型研究.情报科学,2016,34(1):15-19.
[4]赵强利,蒋艳凰,卢宇彤.具有回忆和遗忘机制的数据流挖掘模型与算法.软件学报,2015,26(10):2567-2580.
[5]馬百皓.基于动态数据挖掘的物流信息分析模型设计分析.电子设计工程,2019,27(3):16-25.
基金项目:本论文受菏泽学院科研基金科技计划项目(编号:XY16KJ01)支持,在此表示感谢。
作者简介:刘春英,女,山东成武县人,副教授,研究方向:数据挖掘,计算机教育。
