基于机器学习和图像处理的路面裂缝检测技术研究
2021-10-25张伟光钟靖涛于建新马涛毛硕石艺兰
张伟光,钟靖涛,于建新,马涛,毛硕,石艺兰
(1.东南大学交通学院,江苏南京,210096;2.河南理工大学土木工程学院,河南焦作,454003)
传统的路面病害检测以人工为主,对同一路面状况的评价存在极大的主观性,并且效率很低,不能够处理大量的信息。因此,考虑实时、高效、泛化性能强、识别准确率高的检测方法,对路面养护工作具有重要意义。伴随着计算机技术的快速发展,机器学习和图像处理技术快速发展,并在一些领域得到应用,为路面裂缝信息的识别和处理提供了重要的方法。机器学习使用大量的数据进行训练模型,并能够对图像给予客观的评价,效率远高于传统检测方法。
ZHANG 等[1]设计了一种路面裂缝检测算法,通过图像的预处理,包括图像增强、图像分割等手段对裂缝特征信息进行了提取,计算了裂缝的几何特征信息。OLIVEIRA 等[2]提出了一种利用高速行驶时采集的测量图像进行裂纹自动检测和分类的新框架,将得到的图像使用形态学滤波器进行预处理来减少像素强度差异,将阈值图像分割成非重叠块进行熵计算,对产生的熵块矩阵进行二次动态阈值处理,收到了良好效果。SALMAN等[3]基于Gabor 滤波,提出设计了一种自动识别图像裂缝的方法,能够对路面纹理层次高、裂缝检测困难的路面图像进行自动识别。哈尔滨国畅智能交通技术有限公司与哈尔滨工业大学联合研制出了道路路面检测车“哈工大国畅”[4],能够在较高的行驶速度下采集到质量较高的路面图片,进行路面的快速识别。
在路面裂缝识别和图像处理的相关算法方面,高建贞等[5]使用传统图像处理的方法对裂缝进行自动检测,该方法使用灰度差来校正图像灰度,并进行图像增强,能够解决图像光照不均匀的问题。陈利利[6]提出了一种基于多尺度图像分析的路面病害研究方法,该方法能够有效地去除图像中的噪声,并保持图像的边缘和细节,抑制边界移动。CEYLAN等[7]介绍了神经网络在道路工程中的最新应用。ELDIN等[8]提出了一种用于评估公路路面状况的人工神经网络模型。ROBERTS 等[9]使用不同类型的人工神经网络对路面性能进行了预测,而KIRBAŞ等[10]将人工神经网络与回归分析和多自适应回归等方法进行了比较,提出了一种路面性能的评价模型。ATTOH-OKINE[11]采用人工神经网络模型对不同相关路面条件变量的窘迫路面条件进行了评估,SAM[12]提出了一种预测裂缝演变的程序。PLATI等[13]用神经网络对FWD数据进行分析,评估了路面结构状况。TORRE 等[14]通过神经网络预测公路路面的粗糙度,也可用于裂缝识别[15]。
以上方法为传统学习方法,与传统学习方法不同的是,深度学习方法不需要人工进行特征提取就能够自动根据原始图像的特征进行抽象表达和分析,并且深度学习的识别精度远远高于传统的机器学习图像识别算法的精度,为道路裂缝的自动检测提供了新途径。
ZHANG[16]首次将深度学习算法和卷积神经网络(convolutional neural network,CNN)的方法应用于道路裂缝的检测中,结果表明,深度卷积神经网络在很强的噪声环境下仍然能够很好地识别裂缝。CHA 等[17]设计了一个用来检测隧道中混凝土裂缝的深度学习网络,并使用CNN 对结构中的多种视觉损伤类型进行检测,结果表明,与传统的检测算法相比,CNN具有更好的稳定性。XIE等[18]通过手机收集的500 张分辨率为3 264×2 448 的图像数据集上应用卷积层,证明了基于深度学习的路面裂缝检测具有很大潜力。FENG等[19]使用深度残留网络训练带有缺陷标签的图像,可以显著减少分析前标记所有样品所涉及的时间和资源,但准确率并不高。
在神经网络结构中,卷积神经网络(CNN)已经成为深度学习领域最具代表性的人工神经网络[20]。CNN 特别适用于图像识别、分类领域,无需人工对图像进行预处理和额外的特征抽取等复杂操作,操作简单、识别率高,目前广泛应用于各视觉领域。在路面裂缝的识别中,传统的裂缝识别算法采用图像处理的方法,先对裂缝图像进行灰度化、二值化等操作,然后基于裂缝二值化图像进行裂缝边缘检测,常用Canny 和Roberts 等边缘检测算子进行裂缝的定位与分类,其中包括大量的图像处理过程,耗时多并且识别准确率不高。但是采用CNN 网络模型,不需要进行大量的图像处理过程,一般只需要进行裂缝图像的灰度化即可,灰度图像可以直接作为输入进行训练,CNN 能够自动学习不同裂缝病害的像素差异,从而完成分类目标,不需要复杂的图像处理过程,并且能快速地获得准确的分类。
综上,本文作者基于深度学习的卷积神经网络模型,按照经典的网络结构进行设计,收集4种路面裂缝图像,通过建立数据集和验证集,测试训练模型的准确率,基于高精度的卷积神经网络识别算法,实现正确识别路面裂缝类型的目标,并在识别裂缝类型的基础上,进行路面裂缝的长度、宽度以及面积的计算,为养护评价奠定基础。
1 卷积神经网络
卷积神经网络(CNN)是一种受生物自然视觉认知机制启发而来的多层感知器[21]。20世纪90年代,LECUN 等[22]确立了卷积神经网络。近些年,卷积神经网络在图像识别领域得到广泛应用。在路面裂缝图像的识别上,CNN 比使用传统特征进行分类结果更优[23]。图1所示为神经网络模型,包含输入层、隐藏层和输出层。其中,x1~xn为输入层的输入参数值,y1~yn为输出层对应于输入层的预测值。
图1 神经网络模型Fig.1 Neural network model
1.1 卷积神经网络结构
卷积神经网络是包含卷积层、池化层和全连接层的神经网络。卷积层作用就是通过卷积,将图像中的特征进行提取出来,然后交给高层的神经元进行处理。一层的卷积学到的东西往往是局部的,通过添加卷积层的层数,逐渐到全局进行掌握,实际中卷积层往往有多层[24]。通过加入池化层,能够降低图像大小,对特征压缩,对数据降维,提取主要特征,同时降低过拟合的风险。全连接层的作用是将经过卷积、池化后的结果进行全连接起来,即将变厚的图像连接起来,其输入必须是一维的,因此,必须将上层输入的多维向量变成一维的并连接起来,一个神经网络可以有多个全连接层。
1.2 激活函数的选取
输入值在经过神经元后,还要经过激活函数才能进行输出。激活函数存在的主要目的是增加非线性因素。若不存在激活函数,则输入和输出只能是简单的线性关系。常用的激活函数有Sigmoid,Tanh和Relu等。激活函数工作原理如图2所示,输入层输入参数x,经过突触权值wk相乘后,与偏置bk进行累加求和,通过激活函数Φ,得到激活值yk。
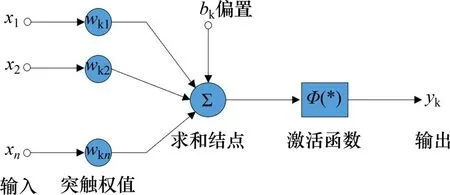
图2 激活函数Fig.2 Activation function
Sigmoid 函数值的范围在0~1 之间,当输入值大于5 或者小于-5,该函数就已经趋于1 和0,映射的范围太小,非常容易饱和,训练效果明显降低,会产生欠拟合,分类效果会很差。Tanh 函数值范围在-1~1,当输入值是比较大的正数时,将被映射成1,当输入值为较小的负数时,被映射成-1,均值为0。Tanh 函数避免了Sigmoid 函数可能会导致的梯度下降产生锯齿状波动的问题,但当输入值过大或过小时,梯度为0,同样会存在欠拟合的问题。Relu函数不存在这个问题,Relu函数的数学形式为:f(x)=max(0,x),如图3所示。
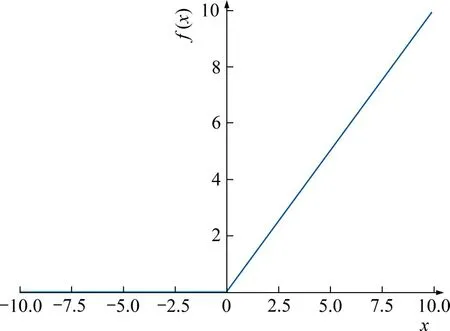
图3 Relu函数Fig.3 Relu function
Relu函数非常简单,当输入值大于0时,直接输出该值,当输入值小于0 时,输出0。只需要设置一个阈值便可以进行计算,相比前两种激活函数需要复杂的指数计算,Relu 函数计算速度更加快速。反向传播的过程就是不断更新参数的过程,Relu 函数相比Sigmoid 和Tanh,导数更容易计算,可以使网络训练地更快,而且Relu 可以防止梯度消失,因此本文采用Relu激活函数。
1.3 优化器的选取
为了更好地训练模型,减小训练时间,提高训练效率,必须选择合适的优化器,常用的优化器主要分为3 类:梯度下降算法和动量优化算法、自适应学习率优化算法,本文选择自适应学习优化算法。由于学习率对模型有着显著的影响,需要采取一些方法来更新学习率,从而提高训练速度。目前,自适应学习率优化算法主要有:Adagrad 算 法、RMSprop 算 法、Adam 算 法 和AdaDelta算法,通过比较分析,本文选择RMSprop算法。
2 裂缝识别算法设计
为设计出一种能够对路面裂缝图像进行分类识别和对路面基本特征信息进行提取和计算的方法,采用多层感知机和深度卷积神经网络2种模型对路面裂缝数据进行学习,算法设计主要借助Python 语言,使用比较便捷的Keras 作为开发框架。首先,采集大量路面裂缝图像并进行灰度化、标签化和尺寸归一化处理,形成足够的训练集。然后,使用训练后的模型对测试集数据进行裂缝有无判断和裂缝种类预测,并将2个模型的效果进行对比。对于判断结果为横向裂缝和纵向裂缝的数据,为了进一步获取裂缝宽度信息,将其进行一系列图像处理,使裂缝突出并减少背景中的噪声。最后,对处理后裂缝图像的宽度和长度信息进行提取,为路面状况评价提供数据。
2.1 数据收集及整理
2.1.1 原始数据收集
使用机器学习进行图像识别需要大量的数据集训练模型。一般来说,训练神经网络所需要的数据量至少在500以上,但相比其他复杂的图像如人脸,裂缝图像比较简单,特征较少,识别相对简单。实验结果证明,500左右的数据量基本可以满足训练模型的要求。本文设计训练的模型主要对横向裂缝、纵向裂缝、龟裂、无裂缝等4类路面裂缝图像进行分类识别,每类裂缝均采集600张图像用于训练。
裂缝图像数据通过手机进行采集,并严格控制图像质量:路面不存在影响裂缝观察的污迹,比如轮胎印记或者车道线;拍摄时光照均匀;路面裂缝处不存在积水等。
2.1.2 数据预处理
收集到的各类裂缝图像不能直接用来训练模型,必须进行处理后生成具有标签的数据集后才能使用。为了减少计算量,加快卷积神经网络的训练速度,需要对数据进行尺寸归一化和灰度化处理。
1)图像尺寸归一化。由于手机所采集的数据图像分辨率不同,而卷积神经网络的输入层需要大小一致的数据,必须进行归一化处理。为减少训练时间,提高模型训练速度,将裂缝图像进行缩放[25],尺寸归一化为80×80。分辨率降低后,不会影响图像中灰度相对低的像素点群的分布特征,以及是否存在裂缝与裂缝类型的判定,满足训练要求。
2)灰度化。收集路面裂缝图像是彩色图片,训练时收敛速度较慢。为了加快神经网络模型的收敛,查阅文献[26],裂缝图像的灰度化对裂缝识别准确率的影响很小。观察处理后的裂缝图像并读取灰度发现,处理后裂缝的特征和分布状态并没有较大改变,结果如表1所示,因此,对原始路面裂缝均进行灰度化处理。

表1 原始图像和经过预处理后的样本对比Table 1 Comparison of original image and sample after preprocessing
3)标签化。采集到的数据并不能够直接用于训练,必须对每类裂缝打上各自类别的标签,才能将训练结果与真实的分类结果进行比对,并不断更新参数。使用windows自带的批处理程序对图像进行打标签。对横向裂缝图像重命名为1_x.jpg,前缀名的第一位表示裂缝类型,x为序号,表明同一类裂缝的数目。使用同样的方法,纵向裂缝图像、龟裂图像、无裂缝图像的重命名格式分别为2_x.jpg,3_x.jpg和4_x.jpg,如图4所示。

图4 裂缝标签化Fig.4 Crack label
4)生成数据集。经过标签化的图像为jpg图像格式,需要对图像中的点阵数据进行读取。使用OpenCV提供的接口,对图像数据进行读取,将图像的标签与图像数据信息对应起来,写入一个csv文件,当训练卷积神经网络时,可直接读取该csv文件。
2.2 多层感知机模型搭建
多层感知机(multilayer perceptron,MLP)是至少含有一个隐层的由全连接层组成的神经网络。在这个网络中,每一个节点都是一个人工神经元,一个人工神经元的输出可以作为另一个人工神经元的输入,且每个隐层神经元的输出通过激活函数进行变换。MLP 的一个显著特点是,在网络足够大的情况下,模型能够表示任意数学函数。
2.2.1 模型参数
多层感知机结构有输入层、隐层和输出层,层与层之间都通过全连接的方式,前一层的输出值即为后一层的输入值。选择隐层共3层的多层感知机:输入层输入尺寸为80×80×1 的二维灰度图片,将其展开变成一维张量后传入隐层;各隐层中神经元个数分别是256,512 和256 个,输出层输出4个分类结果。
2.2.2 训练结果
将训练集数据随机抽取固定个数,作为一个批次(batch)进行训练,每个batch 训练后都将模型参数进行一次更新,直到所有的数据都进行参数更新,这一过程称为一轮训练(epoch)。batch 的尺寸定为32 个数据,进行3 000 个epoch 后结束训练和参数更新,训练结果如图5所示。
从图5可知:随着训练的进行,训练集的损失值越来越小,而准确率基本稳步上升。但是模型在验证集上的损失值和准确率波动较大。训练最初的准确率最低,为32.31%,损失值为1.603 4;训练过程中准确率起伏很大;训练结束时,模型在验证集上的准确率达到86.32%,损失值为0.457 1。
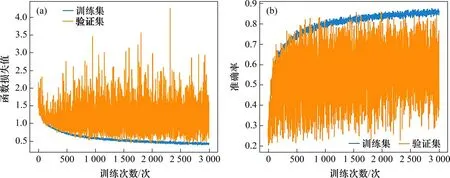
图5 多层感知机训练集和验证集损失值和训练准确率随训练次数的变化折线图Fig.5 Line chart of loss value and training accuracy of training set and verification set of multilayer perceptron with epoch
2.3 卷积神经网络结构搭建
一般来说,卷积神经网络的层数越多,对数据拟合的效果越好,但计算时间越长,而且出现过拟合现象的概率也越大,对于小批量的数据,层数不需要过高。本文选择5层网络结构模型用于训练。
2.3.1 具体网络结构参数
建立5层卷积神经网络,各层的参数如表2所示,其中前三层是卷积层(Conv 层),用于提取裂缝图像特征,每一个卷积层后连一个池化层;后两层为全连接层(Fc 层),在全连接层后连一个SoftMax分类器,实现图像分类。为防止训练出现过拟合,在每一个池化层后接一个dropout 层,使部分神经元随机失活,以保证测试集的良好结果。

表2 神经网络模型参数Table 2 Parameters of neural network model
输入数据在经过卷积神经网络各层后的维度变化如图6所示。
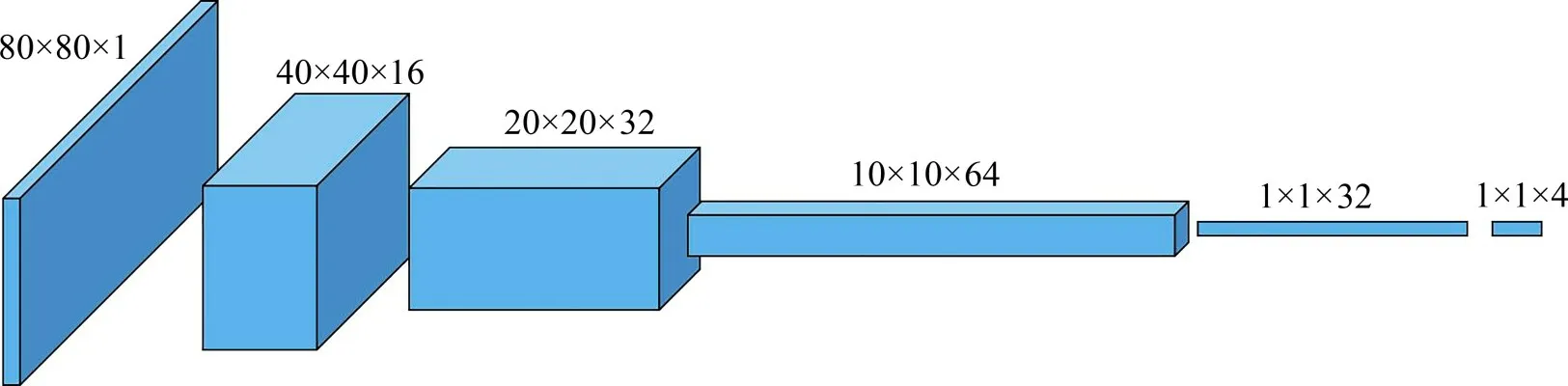
图6 各层维度变化示意图Fig.6 Schematic diagram of dimension change of each layer
2.3.2 神经网络训练
经过处理4 类裂缝图像共2 400 张,作为模型训练的数据集,从中随机选取20%的数据作为验证集,以提高模型的泛化能力。训练环境为:Windows10 操作系统,i5-5200U 处理器,主频2.2 GHz,内存8 G,python3.0,Keras框架。
为选择合适的优化器,对不同的优化器进行测试,在统一的epoch和batch size下进行测试,结果如表3所示。
从表3可以看出:使用RMSprop 优化器的模型损失值最低,准确率最高,因此,选用RMSprop 算法优化神经网络模型。当模型进行训练时,为防止模型出现过拟合,提高模型的泛化能力,在每个卷积层后面添加一个dropout 层,考虑dropout 的参数对模型训练结果的影响,进行随机失活参数(即总的数据集中不参与训练的占比)的确定,实验结果如表4所示。
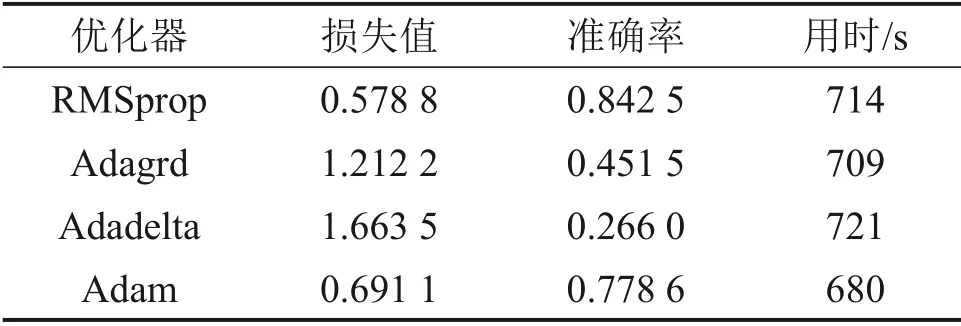
表3 各类优化器的训练效果Table 3 Training effects of various optimizers

表4 随机失活参数确定Table 4 Determination of random deactivation parameters
从表4可以看出:随机失活参数数量过大或过小,模型在验证集上表现均较差,故将随时失活参数设置为0.2。
优化器选择为RMSprop,初始学习率设置为0.000 1,batch size 的大小为32,epoch 设置为50,得到的损失值和准确率分别如图7和图8所示。
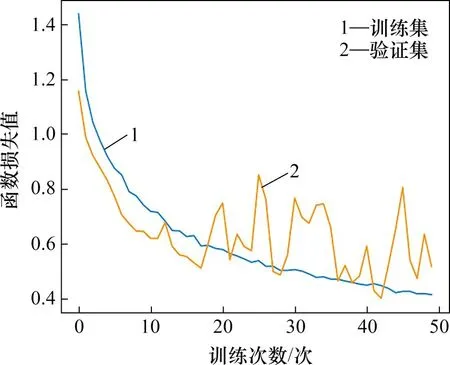
图7 训练集和验证集的损失值随训练次数的变化情况Fig.7 Change of loss value of training set and verification set with training times
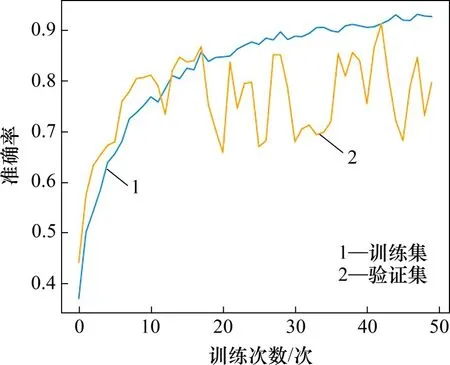
图8 训练集和验证集的准确率随训练次数的变化情况Fig.8 Change of accuracy of training set and verification set with training times
通过50个epoch的训练,卷积神经网络模型在训练集的准确率最高为97.5%,损失值不断降低。虽然验证集的准确率和损失值波动较大,但整体趋势和验证集的表现相同,具有较好的训练效果。
2.3.3 2种模型识别结果对比
为得到准确率高的识别模型,对2种模型进行实验验证。验证集随机选取400 张裂缝图像(其中横向裂缝图像数量为82 张,纵向裂缝图像数量为105 张,龟裂图像数量为106 张,无裂缝路面图像数量为107张),使用模型对这400张裂缝图像进行预测,将识别结果通过混淆矩阵绘制出来,结果如图9所示。
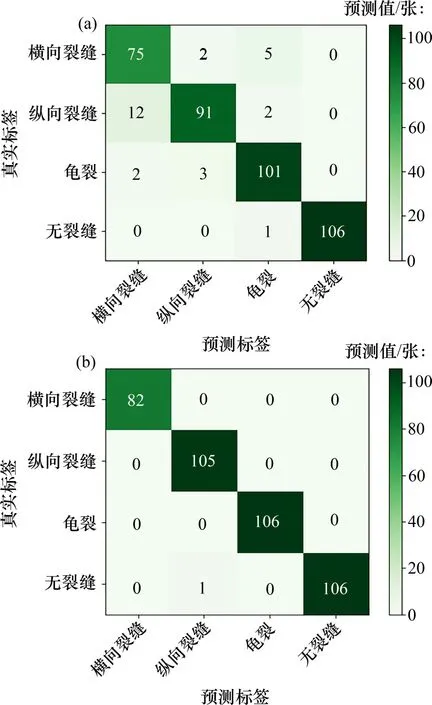
图9 2种模型识别结果Fig.9 Recognition results of two models
多层感知机模型对于横向裂缝图像的预测正确率达到91.46%,对于纵向裂缝图像的预测正确率为86.67%,对于龟裂图像的预测正确率为95.28%,而对无裂缝路面的预测有99.07%的正确率。综上,经过训练后的多层感知机在测试集上,对于4类沥青路面裂缝图像的预测和分类准确率平均为93.25%。
卷积神经网络模型对于横向裂缝、纵向裂缝以及龟裂的图像预测全部正确;而对无裂缝路面的预测有99.07%的正确率,预测错误的一例被模型判断为纵向裂缝。经过训练后的卷积神经网络在测试集上,对于4类沥青路面图像的预测和分类准确率平均为99.75%。
经过训练的多层感知机和卷积神经网络模型,对4类路面裂缝的分类和预测比较准确,能够很好地完成分类任务,但卷积神经网络模型的性能优于多层感知机模型的性能。
3 路面裂缝几何特性
在完成路面裂缝分类后,需进一步获取裂缝的其他信息,如纵向和横向裂缝的最大宽度、长度、面积等,才能评估路面的破损程度。路面图像包含了路面的绝大部分信息,使用图像处理技术能够对图像中的有效信息进行提取,一般操作方法包括灰度化、二值化、图片降噪、图像细化等。
3.1 图像处理
提取裂缝特征信息对图像质量要求较高,为减少图像处理过程中造成的裂缝信息损失,提高信息提取的准确率,将图片分辨率调整为3 500×3 500,进行二值化、图片降噪等处理。
3.1.1 二值化
二值化就是按照某种规则首先确定图像的阈值,然后将原始图像各像素处的灰度与该阈值对比,再按照某种规则对该灰度重新赋值。二值化处理后的图像只有黑白2种颜色,每个像素点的灰度为0 或255,能够比较好地突出裂缝特征。阈值的确定方法分为全局阈值二值化和局部阈值二值化。局部阈值法,是对图像进行分块,按照某种规则计算出每一块的阈值,对该块内的像素自动进行调节,能够比较好地处理图像光照不均匀的情况。此次实验的对象均是在光照均匀环境下获取的路面裂缝图像,故不考虑使用局部阈值的处理方法。
全局阈值二值化是在整个图像中统一为一个阈值,在该值下对像素进行操作,阈值获取方法分为指定阈值和手动获取阈值2 类。对于指定阈值,OpenCV中有5种常用的方法:
1)THRESH_BINARY 方法,对高于阈值的灰度设为最大值,低于像素的灰度设为0;
2)THRESH_BINARY_INV 方法,正好相反,将高于阈值的灰度设为0,低于阈值的灰度设为最大值;
3)THRESH_TRUNC 方法,将超过阈值的灰度设为阈值,而对低于阈值的灰度不变;
4)THRESH_TOZERO 方法,将超过阈值的灰度保持不变,其他的灰度变为0;
5)THRESH_TOZERO_INV方法,将超过阈值的灰度变为0,其他灰度不变。指定阈值设为127,使用以上5种方法处理后结果如图10所示。
从图10可以看出:使用THRESH_BINARY和THRESH_BINARY_INV 方法处理后,裂缝特征比较明显,因此选择这2个方法对裂缝图像进行二值化处理。
图10 二值化方法处理结果Fig.10 Processing results of binarization method
3.1.2 路面图像降噪
由于沥青路面中沥青与集料性质不同,会出现较多离散分布的噪声,即图像中孤立的像素点或者像素块。它们不属于裂缝,但对于裂缝宽度、长度和面积的计算会产生影响,因此在计算裂缝的几何特性之前,需要去除其中的噪声。
1)高斯滤波。高斯滤波是通过一个卷积核对图像进行卷积,该卷积核的权重服从高斯函数的二维分布,其中心是高斯函数的原点。对卷积核进行归一化处理,保证卷积核的和为1。高斯滤波适合处理噪声分布为高斯分布的白噪声,能够保留比较多的细节。高斯滤波对图像的处理效果与高斯卷积核有关,不同卷积核处理后的结果如图11所示。
从图11可以看出:随着卷积核的增大,裂缝细节不断被模糊,为了达到良好的去噪效果,选取的高斯内核大小为5×5。

图11 高斯卷积核确定Fig.11 Determination of Gaussian convolution kernel
2)形态学滤波。形态学滤波是基于形态学对图像处理的算法,使用特殊领域运算形式:结构元素,在每个像素位置上与二值图像对应的区域进行特定的逻辑运算。使用形态学滤波算法对图像进行处理的难点是:设计结构元素的大小、结构元素的形态和运算的性质。最常用的形态学滤波算法有腐蚀和膨胀,这2种算法相互组合还可以进行开运算和闭运算。
腐蚀是通过结构元素在图像上平移,若该结构元素包含于图像,则该结构元素的中心点会被修改。膨胀与腐蚀相反,结构元素在图像上平移,若结构元素集中于图像,则结构元素所在的中心会被修改。
先腐蚀后膨胀操作称之为开运算,与开运算相反,闭运算先膨胀再腐蚀,闭运算能够连接图像中那些紧紧相邻却又没有连接的区域,2种运算处理的结果如图12所示。

图12 形态学滤波处理结果Fig.12 Morphological filtering results
通过以上实验发现,闭运算处理后的图片有很多孤立点,而开运算能够有效去除图像中的孤立噪声,而且图像的位置和形态不会改变,在处理噪声方面效果较好,以此选取开运算来进行滤波处理。
3)算法设计。本文设计2种滤波算法对图像进行降噪处理:第一种算法是使用高斯滤波结合二值化进行迭代,高斯内核为5×5;第二种算法是形态学滤波开运算结合中值滤波算法,对图像进行降噪。2种算法处理后的结果如图13所示。
从图13可以看出:第一种算法不仅不能对图像完成降噪处理,反而使得图像中的噪声越来越多,裂缝的特征逐渐消失。而第二种方法,在进行100 次迭代后,图像中的噪声明显降低。因此,采用中值滤波结合开运算,进行路面裂缝的图像处理来计算裂缝的几何特征。

图13 高斯滤波迭代及中值滤波迭代计算对比Fig.13 Comparison of Gauss filter iteration and median filter iteration
3.2 裂缝几何特征提取
经过图像处理以后,噪声得到有效去除,裂缝特征已非常明显,近似认为图片中灰度大于0的像素点均属于裂缝,统计分析这些白色的像素点便可计算裂缝的几何信息。通过对实际拍摄路面的测量和图片大小的比例换算,可以得到每个像素的实际长度和每个像素点的实际面积,通过比例尺可以计算裂缝的宽度、面积和长度等信息。
路面裂缝特征信息计算需要对图像进行标定,以保证后面程序的准确可靠,因此需要固定采集的设备的高度、角度,此次实验数据采集时,固定相机高度为30 cm,角度为垂直拍摄,照片长宽比调整为1:1,分辨率为3 500×3 500,现场采集如图14所示。
经测量,图14中实际路面裂缝长度为20.5 cm,照片中的长度为3 500个像素长度,换算成单个像素对应的实际长度为0.058 6 mm。本文是以手机拍摄的路面裂缝图像进行标定的,也可以采用道路检测车采集的照片进行标定,只需要保证标定后采用的图像都是相同的数据来源。

图14 测量照片对应的实际路面尺寸Fig.14 Actual pavement dimensions corresponding to measured photos
3.2.1 裂缝宽度和面积计算
在进行裂缝宽度计算时,需要对裂缝形态进行确认,以区分纵、横向裂缝。纵、横向裂缝在卷积神经网络模型预测时已经得到分类结果,完成裂缝形态的分类。本文在2.1节处对于纵、横向裂缝进行了不同的命名标记,通过读取带标签的裂缝图像的像素,批处理生成横纵向裂缝像素的CSV 文件,该文件保存了横纵向裂缝的像素排列的矩阵。将此像素数据输入卷积神经网络进行学习,从而能够进行纵、横向裂缝的分类。
在完成了线性裂缝(纵、横向裂缝)的分类后,进行裂缝的宽度和面积信息的获取。对于纵向裂缝,统计每一行的灰度为255的像素点信息,记录裂缝最大宽度,并计算裂缝的平均宽度;对于横向裂缝,则是统计每列的像素信息。计算路面裂缝面积时,只需统计图像中灰度为255的像素点数目(即白像素点数目),在得到像素信息后乘以相应的比例,便可以得到实际的路面裂缝宽度和面积。
3.2.2 裂缝长度计算
计算裂缝长度需要对图像进行细化,即将裂缝细化成一条单位像素的骨架,然后统计图像中像素的数目,再乘以相应的比例得到实际的裂缝长度。
1)寻找最大轮廓。裂缝长度计算需要去除所有的噪声,只保留裂缝区域。OpenCV提供了搜索连通区域的接口,统计处理后的裂缝图像连通区域,对于仅有单个裂缝的图像,搜索记录图像中的所有连通区域,去除其中的孤立点,处理效果如图15所示。

图15 裂缝填充处理Fig.15 Crack filling treatment
2)提取裂缝骨架。提取裂缝骨架就是对裂缝进行细化操作,不断进行腐蚀的过程,最终将裂缝细化成一条连续宽度为1 个像素的线。采用Hilditch 算法对裂缝进行细化,对于一条直线,它的骨架就是本身,而对于一个具有宽度的线,它的骨架就是它的中轴线。对于圆,骨架是它的圆心,对于孤立的点来说,本身就是骨架。
细化是从原来的图中去掉一些点,但仍要保持原来的形状,实际上是保持原图的骨架。判断一个点是否能去掉,以8个相邻点(八连通)的情况作为判据:内部点则不能删除,删除后会出现孔洞;孤立点不能删除;直线端点不能删除;若存在边界点,去掉该边界点后,连通分量不增加,则该边界点可删除。使用上面方法,分别对横向裂缝和纵向裂缝进行细化,细化结果如图16所示。

图16 线性裂缝细化Fig.16 Linear crack refinement
细化操作后,裂缝变为宽度为1 个像素的线条,统计其中灰度为255像素的数目便可得到裂缝长度。
3.3 多裂缝特征信息提取计算
对于图像中含有多个裂缝的情况,处理步骤与单个裂缝相同,同样需要进行图像预处理,将裂缝的特征表现出来。所不同的是,在进行裂缝特征计算时,需要对每个裂缝独自进行处理,并对预处理后的图片进行连通区域查找,本文将连通区域面积大于图像面积1%的视为裂缝,其他连通区域则为噪声。单独对每个连通区域进行提取,分别计算几何特性。双裂缝图像处理如图17所示。从图17可知:对2条纵向裂缝进行分离和识别,2条裂缝编号为裂缝1和裂缝2,然后分别单独处理,将裂缝特征提取后乘以比例得到的具体裂缝几何数据如表5所示。

图17 双裂缝图像处理Fig.17 Image processing of double cracks
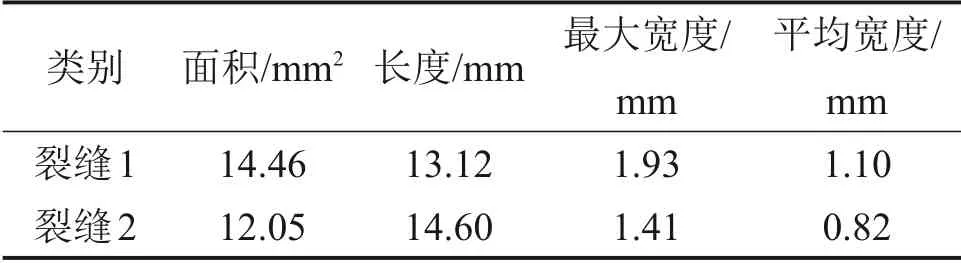
表5 裂缝的几何特性Table 5 Crack geometry characteristic information
基于上面的提取方法,能够进行多裂缝的几何特性提取。在此研究的基础上,可以将此处理思路结合道路检测车进行检测使用,达到批处理提取路面裂缝图像几何特性的目的。
4 结论
1)搭建了包含3层卷积层和2层全连接层的卷积神经网络模型,并与多层感知机模型进行对比分析。卷积神经网络模型和多层感知机模型对4类沥青路面图像的预测和分类准确率分别为99.75%和93.25%,因此,搭建的该卷积神经网络模型能很好地识别路面裂缝类型。
2)THRESH_BINARY 和THRESH_BINARY_INV算法能够将路面裂缝特征明显表现出来。进一步提出了高斯滤波结合二值化迭代算法和开运算结合中值滤波算法,分别进行路面图像降噪,对比分析后得出,开运算结合中值滤波算法能够很好地处理路面裂缝,并突出裂缝的几何特性。
3)经过滤波处理到了比较理想的二值化图片,进行路面裂缝几何特征信息提取计算,提出了将多条线性裂缝分离为单个裂缝进行处理,最后累加计算单个裂缝信息的方法,结合路面双裂缝实例进行了验证,能够统计多条裂缝的信息,效果良好。
