基于双维注意力机制的事件要素识别方法
2021-10-25张顺香
廖 涛,宋 杨,张顺香
(安徽理工大学计算机科学与工程学院,安徽 淮南 232001)
作为事件研究领域的基本任务,事件要素识别被广泛应用于信息检索、文本翻译、推荐系统等自然语言处理任务中。因此,事件要素识别技术及其理论研究受到越来越多研究机构和研究者的关注。如MUC(Message Understanding Conference)会议和ACE(Automatic Content Extraction)会议都是典型的含有事件要素识别任务的评测会议。
根据ACE会议和LIU等的定义,事件由事件触发词(或标志词)和描述事件结构的其他要素构成。事件要素识别旨在从非结构化的含有事件的文本中自动识别其中的时间、地点、动作等重要信息,并给予其准确的角色标注。以下给出一个事件要素识别的实例。
S1:下午3点,救援组官兵使用破拆工具对长安车进行破拆。
对于事件句S1,事件要素识别任务需识别出该句中第二个“破拆”为标志词,时间为“下午3点”,人物为“救援组官兵”,对象为“长安车”,工具或方法为“破拆工具”。
传统的机器学习方法将事件要素识别建模成分类任务,侧重于设计有效特征或核函数。基于特征的算法,如决策树等,在特定领域内可以取得较好效果,但规则的可移植性差,难以获取复杂句或跨句的模式。为此提出了基于核函数的方法,在英文数据集上取得了一定效果,但不适合结构相对英文更加松散的中文数据集。
基于深度学习的神经网络方法,如RNNs和CNNs等,逐渐成为机器学习的主流技术。尤其是近几年,随着注意力机制和Transformer架构被用于深度学习,注意力机制并行速度快且能直接建立长距离依赖关系,在一定程度上加速了神经网络对特征的提取,特别是事件要素识别等自然语言处理领域。但是,注意力机制依赖于嵌入层语言模型对上下文特征的提取,缺乏对文本上下文特征的独立提取能力,因此在小数据集上表现稍差。
本文针对Transformer框架特征提取层(Encoder层)依赖于嵌入层(Embedding层)对上下文特征的提取,提出了一种基于注意力机制的双维注意力机制用于特征提取层,并针对本文所用中文语料相对结构松散和数据稀疏的问题,使用了基于软目标的动态目标损失函数。文本将这些结合起来构建了事件要素识别方法。实验结果表明,本文方法在CEC2.0中文突发事件语料库上表现出优于当前主流模型的性能。
1 相关工作
2006a文献[3]提出把事件要素识别当作多元分类任务,在ACE英文语料上取得了不错效果,但不适用于中文语料。文献[4]对此进行了改进,通过构造多元分类模型的方法进行事件要素识别,在ACE中文语料上效果有所提高。文献[5]针对监督方法依赖于语料的质量和规模,提出了基于特征加权的无监督聚类算法进行事件要素识别,在生语料上取得了不错的效果。文献[6]针对数据稀疏问题,提出一种基于事件本体的文本事件要素提取方法,大大降低了对语料的依赖。
文献[7]利用动态多池化的卷积神经网络方法抽取一个句子中多个事件触发词。文献[8]利用双向长短期记忆神经网络(Bi-LSTM)进行事件检测。文献[9]使用Bi-LSTM提取文本中的语义信息,并联合文本结构特征进行事件要素识别。
谷歌AI团队在2017a提出了结合自注意力机制的Transformer文本架构,并于2018a在此基础上提出了BERT语言模型,在多项NLP任务中取得优异效果。文献[12]提出一种结合注意力机制与Bi-LSTM的中文事件检测模型,将事件要素识别任务看作一种序列标注任务,在ACE中文数据集上获得了非常好的效果。文献[13]提出了动态掩蔽注意力机制,与常规注意力机制相比能够捕捉更丰富的上下文表示。文献[14]提出一种结合双向门控单元和多头注意力的序列标注方法,用于预测电子病例中的命名实体,并结合条件随机场预测全局最优的标签序列,该方法在标准数据集上取得了良好的结果。
本文提出了结合双维注意力机制和动态目标损失函数的神经网络模型(BDAtt-DT模型)用于事件要素识别,本文贡献如下:
1)把事件要素识别作为序列标注任务处理;
2)提出并使用了双维注意力机制加强了对文本上下文特征的提取;
3)使用了动态目标损失函数一定程度上缓解了数据稀疏和中文结构相对松散带来的模型泛化不足问题;
4)将双维注意力机制和动态目标损失函数等结合使用,构建了神经网络模型用于事件要素识别。
2 BDAtt-DT模型
本文将事件要素识别当作序列标注问题,即为句子中每一个字或符号确定一个相应的标签。并提出了BDAtt-DT(双维注意力机制和动态目标)模型,结合双维注意力机制和动态目标损失函数等用于事件要素识别,模型整体结构如图1所示。

图1 BDAtt-DT模型结构图
该模型大体分为四个部分:
1)特征嵌入层 经过预处理后的语料以句为单位通过Embedding网络,映射成特征矩阵,输入到下一层中;2)特征提取层 该层结合双向注意力机制从矩阵行和列两个方向提取特征,得到文本矩阵;3)输出层 该层使用上一层得到的文本矩阵,通过分类网络得到预测的训练标注结果;4)反向传播层 该层结合输出层得到的预测结果,使用动态目标机制得到动态目标,并经过损失函数运算后得到损失值,从而进行误差反向传播,更新模型参数。
(1) 特征嵌入层
语料库中的文本数据首先经过BIO标注和数据清洗等预处理工作,经过文本预处理后的文本数据更适合下一层的预训练语言模型处理。
本文使用了Albert中文预训练语言模型得到文本特征矩阵,并经过归一化处理和dropout防止过拟合,Albert是基于BERT语言模型的改进,同样使用Transformer进行模型训练。(2) 特征提取层
该层结合了双维注意力机制用于从特征矩阵行和列两个维度提取有效特征,双维注意力机制是对注意力机制的改进。注意力机制能很好地提取字粒度的特征,但缺少了对上下文特征的提取。注意力机制依赖于特征嵌入层对上下文特征的嵌入,所以注意力机制在事件要素识别这类依赖上下文特征的任务中无法取得较好效果。双维注意力机制整体架构如图2所示。

图2 双维注意力机制
其中上下文注意力网络进一步提取文本的上下文特征,该网络首先将特征矩阵转置,再通过3个不同的线性变换将矩阵映射成矩阵、和,再利用式(1)计算注意力得分,作为上下文矩阵。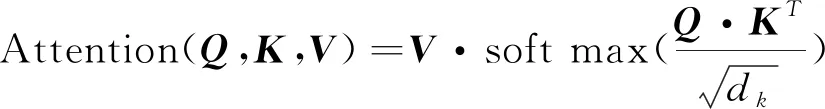
(1)


(2)
然后将h
次的放缩点积Attention结果h
进行拼接,再进行一次线性变换,得到字粒度矩阵,如式(3)所示。MH
(,,)=Concat(h
,...
,h
)(3)
输出时将上下文矩阵的转置和字粒度矩阵进行列拼接,得到文本矩阵,如式(4)所示。
(4)
(3) 输出层
输出层中分类网络由线性全连接网络,激活函数和Softmax函数组成,激活函数的计算公式如式(5)所示。

(5)
(4) 反向传播层
该层在计算损失函数时使用了动态目标机制。通常的目标函数使用one-hot编码,这种目标函数也称为硬目标(hard target),硬目标只有在目标位置的值为1,其余为0.而软目标(soft target)在其余部分也会有概率,所以比硬目标包含的信息熵更高。

T
为标签类别数,目标的损失函数定义为交叉熵和均方误差的加权平均,如式(6)所示。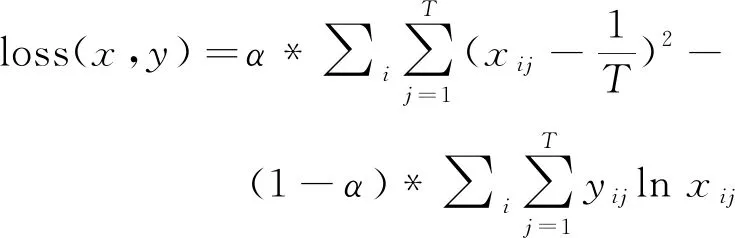
(6)
式中:x
为预测值,y
为实际值,α
根据经验设定,可以防止模型过拟合,本文中α
= 0.
8。3 实验与分析
(1) 数据集及评价指标
本文中使用的是CEC2.0中文突发事件语料库。CEC2.0收集了5类合计332篇(地震、火灾、交通事故、恐怖袭击和食物中毒)突发事件新闻报道,采用了XML格式进行标注,其中事件要素标注包括时间、地点、对象、参与者、工具或方法,各要素含义及其BIO标注数量如表1所示。

表1 CEC2.0语料库上定义的事件要素
通过F
1值(F
1-Measure)评价序列标注的效果。F
1值为准确率和召回率的调和平均值。精确率是计算正确标注某要素数占该要素实际总数的比例。 召回率用来计算正确标注某要素数占该要素预测总数的比例。此外,非要素类标签,如Other和标注句子边界的标签不纳入计算。
(2) 实验结果和分析
在实验中,本文选用当前命名实体识别主流模型双向长短期记忆网络(Bi-LSTM)作为参照模型。LSTM作为RNN的一种变体,相比较于RNN可以学习到文本中的长期依赖关系。Bi-LSTM在LSTM的基础上,可以从前后两个方向提取文本上下文特征。相关研究表明,Bi-LSTM是序列标注任务中的主流模型。
本文使用的部分参数设置如表2所示,其中词向量维度由预训练模型决定,其他参数根据实验经验设定。
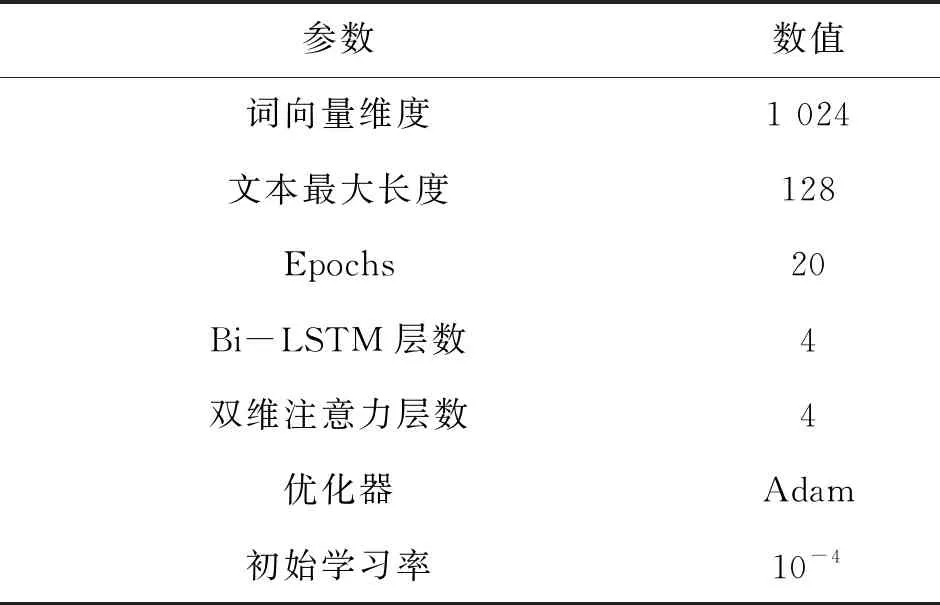
表2 参数设置
本实验每次将数据集随机打乱后按照4∶1划分为训练集和测试集,各进行10次实验后将结果取平均值。各模型事件要素识别的F
1值比较如表3所示。
表3 各模型要素识别效果F1值比较
实验结果表明,使用双维注意力机制的模型与使用Bi-LSTM的模型以及Transformer架构相比能够更好地提取文本的上下文特征,更适合序列标注任务。同样对于前文中提到的事件句“下午3点,救援组官兵使用破拆工具对长安车进行破拆”进行要素识别,使用Bi-LSTM的模型错误地将“破拆工具”中的“破拆”标注为标志词,而本文中的模型则没有出现这样的错误。
其次,双维注意力机制加上双向长短期记忆网络并不能带来模型整体性能的提高,反而导致模型过拟合。模型在测试集上的精确率有所提升,但召回率有所下降,最后导致F
1值反而下降。各模型加入动态目标后的要素识别效果如表4所示。
表4 动态目标对各模型要素识别效果F1值的影响
因为训练语料中样本分布不均匀,导致模型偏向于样本数多的标签。表中的实验结果表明,动态目标机制在一定程度上缓解了这一问题。尤其是对于样本量最少的Means要素和第二少的Object要素,使用了动态目标机制之后,模型对于这两种要素的识别效果提升显著。
研究还发现,降低某要素标签分数s
后,该要素自身精确率提高,其他要素精确率下降,自身召回率下降,其他召回率提高,反之亦反。所以,可以通过调整基本分数改变对不同事件要素的学习程度。4 结论
本文针对传统事件要素识别方法所存在的缺点,提出了一种基于双维注意力机制特征提取模型,并结合动态目标损失函数用于事件要素识别。实验结果表明,使用双维注意力机制使得模型能够更好地提取文本的上下文特征,更适合序列标注任务。其次,本文使用的动态目标损失函数,能够一定程度上提高模型的泛化能力。
本文提出的方法还有很多不足,例如该方法对于语料库中专有名词的识别仍然存在难度,以及该方法尚未在英文语料库中验证有效性。这些问题都亟待进一步深入研究和验证。
