融合空间及通道注意网络的古籍汉字图像检索
2021-10-22田学东杨琼杨芳
田学东,杨琼,杨芳
(1. 河北大学 网络空间安全与计算机学院,河北 保定 071002;2. 河北大学 智能图文信息处理研究所,河北 保定 071002)
汉字是中华民族历史文化的重要载体,研究古籍汉字对于了解中华文明具有重要意义.信息技术的发展,为古籍汉字研究提供了更多有效的途径和依据.借助计算机实现古籍汉字图像检索,不仅可以有效解决人工查阅古籍文献带来的效率低、准确性差等问题,还可以避免对古籍文献的二次损伤.
古籍汉字字形笔画繁杂,结构多样,且包含大量未收入编码字符集的汉字,难以利用现有的输入关键词查询相关内容的全文检索技术.将传统的字形图像检索技术与识别技术应用于古籍汉字图像检索是开展此类汉字研究的重要辅助手段.
实现古籍汉字图像检索的关键是特征的选择与提取.常用的特征包括结构特征和统计结构2种[1].结构特征主要是指汉字的笔画、部件等特征.祁俊辉等[2]提出将汉字的笔画顺序进行编码,再转化为特征向量的方法,有效解决现代汉字形近字的准确性问题.马海云等[3]提出将古汉字的部件特征与全局和局部点密度融合的识别方法,提高古汉字的识别准确率.统计特征对于字形符号而言是最常用的,如方向特征[4].针对手写汉字字形多变问题,相关学者采用弹性技术对原汉字图像进行网格划分,提高了汉字图像的笔画[5]、方向[6]、Gabor[7]等特征的鲁棒性.为解决汉字结构关系不稳定的问题,部分学者将模糊集理论引入到手写图像特征中,进一步提高手写汉字图像的表征性[8-9].同时,在与古籍汉字相似的书法字图像检索研究中,部分学者利用书法字的轮廓几何形状特征[10]、笔画密度特征[11]、骨架信息[12]等,实现书法字图像的快速检索.
传统人工提取汉字特征的适应性较差.因此,利用深度卷积神经网络[13-14]自动提取汉字特征成为热点.Zhong等[15]提出将传统手写汉字特征提取方法和GoogLeNet[16]相结合提高识别性能.Liu等[17]提出将字符图像的方向分解特征与卷积网络相结合,实现字符识别.相关研究者在改进inception结构或利用残差思想上,通过特征融合技术进行汉字特征的提取,保证汉字特征的完整性[18-20].Chen等[21]设计更深的卷积神经网络,并结合三维随机变形技术对手写汉字进行笔画轻重的模拟,提高识别准确度.徐清泉[22]提出了一种多对比通道注意力机制的方法,通过2个并行的通道注意区域丰富手写汉字字符的局部特征信息,提高模型的鲁棒性.Yang等[23]提出一种RNN(recurrent neural network)结合注意力的手写汉字识别方法,通过不断更新特征关注点来提高识别精度.近年来出现的VGGNet[24]、Inception系列[25-26]和Resnet[27]模型在ImageNet数据集上取得优异的成绩,这些经典神经网络模型为古籍汉字图像检索提供了良好的方法基础和借鉴.
上述深度学习算法主要利用汉字的整体特性,忽略了汉字部首和空间结构信息[28],往往会导致图像检索准确性不高.本文提出一种基于注意力机制[29]的古籍汉字图像检索方法.该方法根据古籍汉字的多种空间结构,通过结合空间注意力[30]与通道注意力[31]提取古籍汉字的高低层特征,学习并融合多个注意力区域特征,提高古籍汉字图像特征的表征性.同时,采用加权交叉熵函数代替交叉熵函数,平衡了正负样本不均衡问题,提高网络性能和模型的鲁棒性,实现古籍汉字图像检索.
1 古籍汉字空间结构注意力机制
古籍汉字字形结构复杂,相似字形多,且相似字形之间的区别往往仅在于某些笔画或笔画的局部.若采用传统的单一卷积神经网络,由于缺乏对于古籍汉字字形结构的针对性,对于古籍汉字字形相似部分的区分能力有所欠缺.因此,本文将注意力机制引入到古籍汉字图像检索模型中的特征提取阶段,结合古籍汉字的特点,通过选取12种常见的古籍汉字字形结构并将该信息融入到网络模型中,提取古籍汉字图像的整体和细节特征,增强特征鲁棒性,解决难以找到古籍汉字图像关键特征信息的问题.同时,本文从空间域和通道域上对古籍汉字图像特征进行选择性的关注,融合高层语义信息和低层信息,有效避免因对比度低、细节特征丢失等对汉字提取特征的影响,出现错检漏检等造成检索精度不高的问题.
注意力机制如同人类视觉注意力一样,在计算机视觉领域多用来捕捉信息依赖关系.本文采用CBAM(convolutional block attention module)[32]并进行适合于古籍汉字字形结构特点的改进,通过并行融合通道和空间上的区域信息强化古籍汉字图像关键特征.本文注意力融合机制分为2部分:第1部分将低层特征图S∈C×H×W作为空间注意力模块的输入,生成二维空间注意力图MSAt∈1×H×W;第2部分将高层特征图C∈C×H×W作为通道注意力模块的输入,生成一维通道注意力MCAt∈C×1×1图.完整的注意力过程如下:
S′=MSAt(S)⊗S,
(1)
C′=MCAt(C)⊗C,
(2)
N=Sigmoid(S′⊕C′),
(3)
其中,⊗表示矩阵中逐元素相乘[32]; ⊕表示对应元素相加.古籍汉字图像的中间特征图沿着通道维度生成二维空间权重系数MSAt并与S相乘;高层特征映射沿着空间维度生成一维通道权重系数MCAt并与C相乘;最后将新的空间和通道注意力图相加,得到新的特征信息N作为卷积层的输入.通过对注意力机制进行双重融合,获得丰富的古籍汉字图像语义信息.注意力融合机制方法如图1所示.

图1 注意力融合机制Fig.1 Attention fusion mechanism
1.1 空间注意力(spatial attention, SAt)
与自然图像不同的是,古籍汉字单字图像没有复杂的前景和背景信息.通过对数据去噪、归一化等预处理,利用空间注意力模块关注古籍汉字的轮廓、纹理、空间结构等有用的细节信息部分,更加关注古籍汉字的多种二维结构,提取有效的空间特征.本文归纳12种古籍汉字字形结构如图2所示.

a. 上下结构;b.左右结构;c.上中下结构;d.左中右结构;e.全包围结构;f.上包围结构;g.下包围结构;h.左上包围结构;i.左下包围结构;j.右上包围结构;k.左包围结构;l.独体结构.图2 古籍汉字字形结构Fig.2 Spatial structure of ancient Chinese character
该注意力模块采用非对称卷积的思想,提取需要关注的古籍汉字空间结构特征以及边缘轮廓信息,以更好拟合空间上的相关性.最后使用Sigmoid激活函数,获取每个元素的二维空间特征映射,经过式(1)获取最终的空间注意力特征图.空间注意力模块如图3所示,图3中S、S′分别为低层中间特征图和空间注意力特征映射图.

图3 空间注意力模块Fig.3 Spatial attention module
1.2 通道注意力(channel attention, CAt)
通道注意力模块帮助模型关注什么样的特征是有意义的.利用通道之间的信息依赖关系,压缩空间维度,但容易丢失有用信息,因此,本文在SE(squeeze-and-excitation)[31]中通道注意力模块的基础上进行面向古籍汉字字形特征的改进.为了减少判别信息的损失,对特征映射图分别进行最大池化(Max-pool)、平均池化(Average-pool)、随机池化(Stochastic-pool)的3种采样方式,更多地保留图像背景信息、纹理信息、细节语义信息,有效避免单一全局平均池化有可能造成的有用特征信息缺失问题.同时,为了捕获完整的通道特征信息,采用了3个连续的全连接层.使用Leaky Relu规避了当输入为负值时,学习速度降低导致一些神经元无效的现象.通道注意力模块如图4所示,图4中C、C′分别对应高层特征图和通道注意力特征图.
网络模型中还添加了BN(batch normalization)层,BN层作用于神经网络某层时,对每一批次的古籍汉字图像作标准化处理,并将输出归一化为标准正态分布,避免发生梯度消失现象[33].
S1=Normal(x,α),
(4)
其中,x为任意给定的古籍汉字图像训练集;α为古籍汉字图像集合.
对于任意维度的输入x=(x1,x2,…,xn),进行如下归一化:

图4 通道注意力模块Fig.4 Channel attention module
(5)
通过式(5)加快网络的训练速度.对任意xn,参数γ、β,经过平移缩放后得到
S3=γ·S2+β.
(6)
将S3经过激活函数激活之后作为下一层的输入.同时,网络模型选择SGD(stochastic gradient descent)[34]优化网络参数,把损失降到最低.当每层的输入分布发生变化时,会通过BN层来解决该问题.
2 古籍汉字空间结构注意力检索模型
根据古籍汉字的空间结构特点和模仿人类视觉特性的机制,将注意力机制应用到古籍汉字图像的特征提取阶段,提高特征的有效性和丰富性;并引入1×1卷积,减少网络参数量,提高网络性能.采用融合空间和通道注意力机制的古籍汉字图像特征提取网络的古籍汉字图像检索模型如图5所示.

图5 古籍汉字图像检索模型示意Fig.5 Schematic diagram of ancient Chinese character image retrieval model
古籍汉字图像检索框架主要包括离线特征提取阶段和在线检索阶段.离线特征提取阶段:首先,构建并训练融合空间和通道注意力机制的古籍汉字图像检索(spatial channel ancient image network,SCAINet)模型;然后,利用该模型从古籍汉字图像数据集中提取特征并进行差异哈希编码,建立哈希编码特征向量库.在线检索阶段:首先,利用训练好的模型提取待查询的古籍汉字图像特征并进行哈希编码;然后,对待查询图像和特征库中图像的哈希编码进行汉明距离匹配;最后,排序得到检索结果.
图5采用如图6所示的基础网络结构进行多尺度卷积核间的级联操作,提高多级传递的古籍汉字图像特征信息的多样性,丰富语义信息,增强特征提取能力.
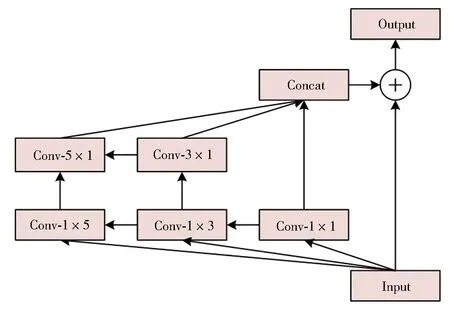
图6 Inception_Residual结构Fig.6 Inception_Residual structure
3 实验分析
实验采用GPU版本的PyTorch深度学习框架,开发语言为python3.6,在Intel(R)Core (TM)i5-9300HCPU@2.40 GHz处理器,GeForce GTX 1650 GPU显卡上进行.所设计的方法将平均准确率MAP和模型准确率作为性能评价指标.MAP计算方法如下:
(7)
其中,AP1、AP2、…、APm分别是每次查询图像与查询结果相对位置的平均检索精度;m是查询次数;MAP越高表明模型检索性能越好.
3.1 数据集及参数设置
本实验采用根据古籍文献研究领域公认的典型文献《四库全书》建立的古籍汉字数据集GJHZ作为实验数据集.按照1.1中的12种古籍汉字结构,将古籍汉字图像数据集进行类别划分,包括经过数据增强(旋转、翻转、缩放等)生成的64×64像素古籍汉字图像.经过数据增强的方法,增加了训练样本的多样性,也有效避免了过拟合的现象.共包括48 000幅古籍汉字图像,其中38 400幅图像作为训练数据集,9 600幅图像作为测试数据集,部分样本如表1所示.

表1 部分古籍汉字样本
训练过程中,将Batch Size设置为4,并行提高内存的利用率.初始学习率的大小设置为0.000 1.优化器采用Adam(adaptive moment estimation)[35]算法来更新模型参数.
3.2 损失函数
古籍汉字图像因其结构复杂,在制作数据集时会存在某些字的样本数较少,出现类别不均衡问题,影响模型效果.因此,模型训练时采用加权交叉熵损失函数[36]作为优化目标.加权损失函数计算方法为
(8)
其中,x∈RN;M为x的特征维度;n为古籍汉字图像数据集对应的标签;λ为对应标签的权重.本文中对样本少的汉字类别,将考虑适当增加权重大小,其中,λ=weight[n]·1{n1not_index}.
3.3 结果及分析
3.3.1 不同算法的检索结果
分别构造SE[31]、残差注意迭代网络[23]、CBAM[32]、传统人工设计特征方法[6]、传统卷积神经网络[13]的仿真系统,与本文方法进行对比实验.随机选取待查询图像“”(GJHZ_0000010030159),图7为对比算法中检索结果相似度最高的前5幅图像.检索结果分别对应图7中的a~f.

图7 古籍汉字图像“”的检索结果Fig.7 Search results of ancient Chinese character image“”
图7a为采用通道注意力机制方法进行古籍汉字图像检索的结果,可以看出,该方法虽然可以重点关注古籍汉字信息量最大的通道特征,但忽略了空间位置特征信息,易造成古籍汉字图像空间信息的丢失,检索效率较低;图7b中设计残差注意模块迭代更新特征点,提高了网络计算速度,但古籍汉字图像结构较复杂,因此检索精度不高;图7c中结合通道与空间的特征信息,丰富了古籍汉字图像的语义信息,但忽略了浅层网络的视觉信息,导致古籍汉字图像的细节特征不够完善,特征区分度不够明显;图7d为传统人工选择与提取特征的方法,在特征全面性与适应性方面的不足,导致采用此类特征的方法所得到的古籍汉字图像检索结果的相似度略低;图7e为经典卷积神经网络方法,由于网络层数较少,高层语义信息提取不够丰富且未考虑低层特征,降低了有用信息使用率,导致此类方法提取的古籍汉字图像特征信息不充分;图7f为本文方法,融合了高低卷积层的特征信息,使古籍汉字图像特征更具判别性,改进的注意力机制在保留语义信息的同时,丰富了特征的细节信息,检索结果更符合古籍汉字字形的实际情况.需要注意的是,由于对文献方法的理解和所采用的实验数据样本存在差异,本文在对比方法上的仿真实验结果只在一定程度上反映文献方法的效果.
3.3.2 不同模型结果分析
为了验证本文方法的有效性,在相同训练方法下,与Googlenet、Alexnet、VGG16模型进行对比实验,得到的损失(loss)与准确率(accuracy)结果如图8所示.
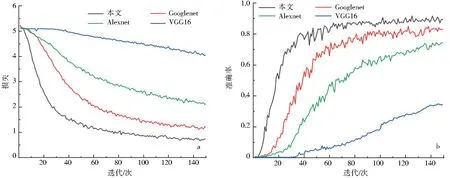
a.损失;b.准确率.图8 不同模型的损失与准确率Fig.8 Loss and accuracy of different models
从图8可以看出,在相同迭代次数内,本文方法的训练损失值降低速率较快,并趋于稳定,提高了模型的准确率,训练结果如表2所示.本文模型的准确率高于对比模型,可以获取更多的古籍汉字细节信息和语义信息,能有效克服部分信息缺失的影响,表明SCAINet模型具有较好的鲁棒性.

表2 各模型的损失与准确率
图8表明本文模型在训练古籍汉字图像数据集时存在一定优势.将本文方法与现有不同方法分别在古籍汉字图像数据集上进行检索.得到“上下”、“左右”、“包围”、“独体”4类结构的评价结果,将全包围结构、上包围结构、下包围结构、左上包围结构、左下包围结构、右上包围结构、左包围结构归类为包围结构.4类结构的MAP如表3所示.
由表3的实验结果可以看出,基于CNN(convolutional neural network)模型的检索算法的效果略优于传统方法;CNN中添加注意力机制的检索算法效果在4类不同字形结构上,整体略优于只利用CNN的检索算法.本文设计的SCAINet模型,其MAP基本略高于对比算法,是因为该方法考虑了古籍汉字的多种空间结构,提高了古籍汉字图像特征在空间和通道映射的显著性,增强了图像语义特征的丰富性,可以聚焦输入图像的不同区域,以区分视觉上相似的古籍汉字.综合分析检索结果可知,本文方法对于不同字形的古籍汉字图像的检索效果优于对比方法,说明本文方法更适合古籍汉字的特性,提取的特征对于古籍汉字字形更具表征性,对区分形近字的效果较好,提高了古籍汉字图像检索精度.

表3 字形结构的MAP
4 结论
在古籍汉字图像检索中引入空间和通道注意力机制,是提取古籍汉字细节特征和语义信息的有效手段.本文将空间域的通道特征信息与通道域的空间特征信息进行层级交互,充分提取古籍汉字图像特征并重点关注古籍汉字图像间的相似之处,加强了特征间的交互性,提高了古籍汉字间的辨别精度.同时,所设计的基于古籍汉字空间结构的注意力网络检索模型,通过将空间与通道提取的高低特征进行融合,有效地捕捉古籍汉字图像的细节特征,增加特征的区分度,也避免丢失部分有价值的信息.最后,采用加权交叉熵损失函数确保样本的均衡性,提高模型性能.在古籍汉字图像数据集中的实验结果验证了本文方法的有效性和可行性,且相比于其他方法,在训练准确度和检索精度上都有所提高.该方法能为查阅古籍文献的研究者带来一定的帮助.可是本文训练样本较小,且网络结构较复杂,今后工作中会继续完善数据集,探索更好的特征提取与索引方法,增强网络模型的泛化能力.
