基于用户反馈信息可信传播的社会推荐方法
2021-10-20於跃成左华煜
於跃成,谷 雨,左华煜,李 慧
(江苏科技大学 计算机学院,镇江 212100)
随着社交网络的出现,在线社交对人们生活所产生的影响越来越大.而如今微博、Twitter和豆瓣等社交媒体的迅速发展,使得网络逐渐成为人们获取和发布信息的主要途径,这些庞大的用户群体的活跃网络行为,产生了大量可用的社交信息,为分析社交网络提供了大量可用的数据.社会推荐已成为人们从海量信息中快速准确地获取可用信息的有效方法,其中基于矩阵分解的协同过滤算法则是近年来最流行的社会推荐算法之一.作为一类个性化推荐方法,社会推荐方法虽然具有较高的推荐准确性,良好的可伸缩性和较高的灵活性,但是社会推荐中使用的用户评价矩阵仍然具有数据稀疏和分布不均的特点,同样需要面对新用户数据稀疏,冷启动和长尾等问题[1].如何更好地表示和利用稀疏且不平衡的用户信息成为改善社交推荐的主要途径之一.
在现代电子商务和社交网络中,大多数的网站都为用户提供了产品评论和社交网络结构,使在线评论、评分和关注关系的可用性不断提高,而融合社交关系以及用户反馈信息的推荐系统则变得越来越实用[2-3].然而,用户评分或反馈过的项目数远远小于项目总数,用户评分矩阵和反馈矩阵的数据都面临着数据稀疏的问题,而反馈矩阵的稀疏性则更为突出.现实生活中,人们的选择日益趋于理性,不再会因为某个项目被多数人好评就会去尝试.相对于大众的意见,人们都更愿意接受自己认识的熟人或信赖的朋友推荐的信息.为此,利用用户的历史评分和用户之间的信任关系成为改善上述问题的有效途径.文献[4]利用矩阵分解技术,通过“用户-用户”和“项目-项目”的相似性来恢复已评分项目和未评分项目之间的用户偏好,实现了社会信任与隐性用户反馈推荐项目的有效融合.类似地,文献[5]同样利用矩阵分解技术,通过度量信任传播和信任度的相似性,实现了对信任度缺失的有效预测.而对于在线社交网络中用户之间的信任传播,除了融合正则化技术的方法外[6-10],文献[11-12]还提出了通过因式分解来利用社交网络中的信任关系的方法.近两年,文献[12]提出的加权信任指标被用来生成个性化的推荐,文献[13]提出了一种TrustANLF的社交正则化方法,该方法将用户的社交信任信息合并到非负矩阵分解框架中,将信任作为附加信息源以及评分集成到推荐模型中,以处理数据稀疏性和冷启动问题.
到目前为止,矩阵分解仍然是社会推荐算法采用的主要技术框架,其核心是将用户对项目的评分以及用户的反馈信息融入项目评分矩阵,从而实现新用户的有效推荐.事实上,用户反馈信息十分稀疏,特别是反映用户对项目喜好或是厌恶的反馈更加稀疏,现有算法往往通过衡量用户之间偏好的相似性来扩展这类信息的适用人群.然而,这种度量用户相似性的方式仅仅考虑了用户历史行为的相似,模糊了用户在特定项目上的差异,而且通过这种方式扩展的适用人群只是用户的直接近邻.在现实生活中,用户对产品的选择更倾向于听取家人或是朋友的建议,其本质是一种基于信任的信息传递.在社交网络中,用户之间通过关注、点赞、转发等网络行为,形成了社交领域的信任关系.类似于现实生活中亲朋间的信息传递,信息也可以在社交网络中可信用户之间传播.直觉上,借助于社交网络的可信计算,一方面可以通过描述相似人群在特定方面的相似程度,确保用户反馈信息与领域用户偏好相似的准确匹配,提升反馈信息的使用精度;另一方面则可以将反馈信息的适用人群从用户近邻扩展至用户社交链上的可信人群,扩展反馈信息的适用范围.
为此,基于文献[14],文中利用节点出入度信息和用户交互信息,设计同时考虑用户相似和可信用户的关联用户计算方法,在改进的目标函数上实现反映用户好恶的反馈信息在关联用户上的可信传播,以更好地弥补反馈矩阵数据稀疏性的不足,更好地提升用户体验.
1 文献综述
1.1 融合社交信息的推荐方法
为了缓解协同过滤方法面临的数据稀疏和冷启动用户问题[15],社会推荐引入了各种社交网络信息.用户的决策除了受用户自身的特征影响外,还会受到其所信任的朋友的影响,为此,提出了概率矩阵分解的社会信任集成推荐(recommend with social trust ensemble,RSTE)模型.
在RSTE的目标函数中,用户的预测评分由用户对项目的显式评分和用户的朋友对项目的评分两部分构成.通过用户对项目的显式评分可以得到用户评分的条件分布,并可根据贝叶斯推理得到只利用用户特征对项目的预测评分.进而,在评分预测中加入用户朋友的特征矩阵,以便将朋友的偏好融入用户的预测评分.RSTE的目标函数为:
(1)
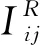
1.2 基于社交信息的信任计算
总体来说,来自不同社交媒体的用户社交信息大致可以分为两类,即朋友关系和信任关系.在微信、QQ、Facebook等社交媒体中,用户之间的关系是双向关系,属于朋友关系.相反,在微博、Twitter和豆瓣等社交媒体中,用户之间的关系是单向关系,这是一种信任关系.尽管社交媒体中的朋友关系与现实世界的关系更加密切,并且这些朋友在现实生活中往往就是家人、同学、同事等,但他们对特定主题的兴趣不一定相同.事实上,社交网络中具有信任关系的用户往往是真正具有相同兴趣爱好的潜在朋友,他们之间的关联通常是基于某个特定主题的相同品味.因此,基于信任的用户信息比来自友谊的用户信息更可靠,在基于信任的推荐系统中的应用也更为普遍.
为了实现信任计算与推荐技术的有效融合,多种信任计算模型被相继提出.典型的信任计算模型包括基于路径的算法TidalTrust[16]、基于信任的协同过滤的算法MoleTrust[17-18]、基于概率的算法Sunny[19]、基于流模型的算法Advagato[20]和基于扩散激活的算法Appleseed[21]等.此外,在进行信任推荐时,用户上下文信息[22]是一类重要的可用信息,随机游走(TrustWalker)[23]则是一种效果较好的推荐策略.在对信任度进行评估时,无论是全局信任度还是局部信任度,一般都采用加权计算的方式.当前的算法通常利用态度、交互经验和行为模式等3种信息来综合建立新的信任评估模型[24-26].
2 基于用户反馈信息可信传播的社会推荐算法
现有的社会推荐算法虽然使用了用户的社交信息,但是忽略了用户在使用社交网络的过程中产生的反馈信息,尤其是哪些反映用户好恶的反馈信息,而这些信息通常隐藏于用户的各种网络行之中.为此,文中在改进RSTE的基础上,构建综合考虑用户相似性和用户可信性的关联用户度量方法,以便将这些稀少而有效的反馈信息以可信传播的方式扩展应用于关联用户,提升反馈信息的使用精度,扩展反馈信息的适用范围,改善反馈信息矩阵的稀疏性.
2.1 可信关联用户度量
目前,包括电商、购物、电影和旅游在在内的各个平台的用户都可以对各种项目进行评分.例如豆瓣电影网站的用户可以用1~5的一个数对电影加以评分.有时候两个不同用户对同一部电影的评分看似只相差了1分,但是却可能反映了用户对这部电影的不同感受.实际上,给4分的用户可能喜欢这部电影,给3分的用户仅仅觉得这部电影一般,而给2分的用户可能就有点讨厌这部电影了.这意味着,具有相似评分的用户看起来有着相似的表现,但实际反映的可能是用户对同一项目截然不同的感受.由此可见,直接根据用户评分来度量用户相似程度的方法在一些特定场景并不合适.此外,相比于数量庞大的项目书,用户评分过的项目远远不及项目总数.这样,用户之间对同一项目进行评分的数据记录更为稀少且宝贵,但却更为精准地反映了用户间的相似程度.需要注意的是,如果两个用户中只有一个人对项目j进行了评分,而另一个人并没有对该项目加以评分,此时并不能说这两个用户的相似度很低.这是因为那个没有对项目j评分的用户很可能只是没有与项目j有过交互,并不能说明该用户不喜欢项目j.
为此,选用皮尔逊相关系数[27](Pearson correlation coefficient,PCC)来计算用户间的相似度.在计算用户相似度时,只考虑那些对相同项目进行了评分的用户.皮尔逊相关系数为:
(2)
式中:ij为用户i对项目j的评分;kj为用户k对项目j的评分;n为用户i和用户k共同评分的项目数.
由于社交网站上用户众多,故只计算具有直接社交关系的用户间的相似度.然而,用户间的相似度还不足以说明用户之间的信任程度.在社交网中,用户之间的信任关系可以用一个有向图来表示,图中的节点表示用户,节点之间的边表示了用户之间的各种直接关系.假设用户i关注了m个用户,那么这m个用户发布的信息被用户i看见的可能性以及用户i采纳这m个用户的意见的可能性存在差异性.也就是说,在用户i关注的m个用户中,他们对目标用户i的影响力有差异.
从社交媒体上可以直接观察到的用户间的社交关系通常都是二值型的,即在网站上只显示两个用户间存在着信任关系或者不存在信任关系.这种二值型的定性描述用户信任关系的方式并不能体现用户间具体的信任程度.事实上,如果一个用户关注的人越多,那么该节点的出度越高,这就意味着该用户对每个关注对象的信任度也就越低.如果目标用户关注了较多的用户,而每个人用于浏览信息的时间有限,这很可能导致该用户无法浏览完所有信息,从而降低这些信息对目标用户决策的影响.相反,如果一个用户被越多的人关注,这就意味着该用户很可能是某个方面的领袖,关注他的人对其具有更高的信任度.显然,节点的出度和入度定量描述了用户i与其关注的m个用户之间的信任程度.为此,采用基于节点出入度的方法来度量用户间的信任程度[28],假设用户i关注了用户k,则trust(i,k)就表示了用户i对用户k的信任度为:
(3)
式中:Indegree(k)为用户节点k的入度;Outdegree(i)为用户节点i的出度.用户i的出度越高,意味着用户i关注的用户数越多,用户i对每个用户的信任度就也越低.
式(2)通过定量计算不同用户所共同评分的项目,准确度量了相似用户在特定方面的相似程度,而式(3)则从用户信任的角度描述了可信用户之间决策影响的程度.为了确保用户反馈信息与领域用户偏好相似的准确匹配,提升反馈信息的使用精度,文中采用复合信任度来描述社交网络中具有直接关系的用户间的可信用户关联度Sik为:
Sik=β·trust(i,k)+
(4)
式中:same_pearson_r(i,k)为用户i与用户k共同评分的项目的皮尔逊相似度;trust(i,k)为用户i对用户k的信任度;β为处于区间[0,1]之间的调整系数.由于皮尔逊相似度的值域是[-1,1],为了方便计算,因此需要将其映射到[0,1].
2.2 反馈信息可信传播模型
社交媒体中的用户通过关注、转发、评论等网络行为形成了一个社交网络,用户间的信任便可以沿着网络,从一个成员传递到另一个成员.这意味着,借助于网络中用户间的信任关系,少数用户拥有的反映自身好恶的反馈信息,不仅可以影响自身的喜好预测,还可以辅助预测其信任用户的喜好.显然,在社交网络中存在着直接关联和间接关联的用户,即使他们的相似程度相同,但他们之间的信任程度还是存在差异的.为了确保这些反馈信息能够最大程度的用于网络用户喜好的预测,将这些反映少数用户的期望能够在与这些用户关联的用户中可信传播.也就是说,根据用户的相似程度和可信程度,使得这些反馈信息能够在一定范围内作用于可信用户的偏好预测.
设矩阵S为用户间的信任关系矩阵,Sik为用户i和用户k之间的可信关联度.令F=[Fij]m×n表示用户反馈信息矩阵,Fi= {Fi1,Fi2,…,Fin}描述每个项目中来自第i个用户的反馈信息的值.为了实现用户反馈信息在可信关联用户上传播,减少用户不喜欢项目在推荐列表中出现的概率,改善用户体验,在RSTE模型的基础上,引入新的用户可信关联度矩阵和反馈信息矩阵,将目标函数由式(1)修改为:
L(R,S,U,V,F)=
(5)
类似于RSTE模型,目标函数式(5)仍然采用梯度下降的方法求解.将用户隐式反馈信息加入用户评分预测之中,并采用社交网络信任度计算来改善隐式反馈信息的数据稀疏性.根据反馈行为的不同,反馈值的取值是不同的.要注意的是,不同社交媒体系统中的评分标准是不一致的.例如,有些平台采用10分系统,而有的则采用5分系统.为了对反馈信息进行统一度量,文中使用f(x)=x/Rmax对评分进行归一化处理,其中x为实际的评分值,Rmax为该平台的满分值.
在此方法中,直接关联用户之间属于直接信任,其值通过计算可信关联度Sik的方式获得.而对于那些没有直接关联的用户,他们之间的信任属于间接信任.间接信任通过信任的传递性推导出用户间隐含的信任关系,并结合矩阵分解方法去预测间接关联的用户间的信任度,从而算出了所有用户间的信任度,得到了用户间信任关系矩阵S.借助用户间信任关系矩阵S,可以将用户的评分、反馈等稀少但是宝贵的信息,通过用户间的信任关系传播给其他用户.这样,当对用户未评分项进行评分预测时,借助于信任计算便可以将用户的好恶信息传播给这些通过信任产生的关联用户,充分利用这些稀少但有效的反馈信息来降低关联用户的推荐列表中出现用户反感的内容的概率.
就复分解反应而言,酸、碱、盐、氧化物之间的转化要求非常熟练,这在最新的高考考试大纲中也是“理解”的能力层次要求,从其中还可以深挖出“强酸制弱酸”“强碱制弱碱”和竞争反应等基本规律。
在现实生活中人们会听取朋友的建议,但是对于朋友的朋友的建议,采纳的可能性会明显下降.类似地,社交网络中用户间的信任关系也会随着传播而逐渐衰减,而当衰减到一定程度以后不仅无法为用户提供有效影响,反而还会对推荐产生干扰.因此,文中为矩阵分解预测得到的用户间信任度设置了一个阈值,其选取由实验得到,当阈值选取为0.5时,目标损失函数最小.因此当信任度低于0.5时,视这两个用户之间不存在任何的信任关系,并将两个用户间的信任度设置为0,不再考虑这些用户间相互产生的影响.
文中提出的算法具体步骤如下:

算法:融合信任用户反馈信息的推荐算法输入:用户集U,项目集V,评分矩阵R,用户反馈F,信任用户集合T,信任用户的评分Tr,用户节点入度Indegree,用户节点出度Outdegree,迭代次数Iter,步长γ,参数α,β,λU,λV输出:预测评分矩阵P方法:1随机初始化U,V2节点出入度计算trust(u,k)=sqrt(Indegree(k)/(Out-degree(i)+ Indegree(k)))3节点相似度计算same_pearson_r(i,k)4 用户间可信关联度Sik=βtrust(u,k)+(1-β) same_pearson_r(i,k)5矩阵分解预测得到用户信任矩阵S=[Sik]6for iteration=1,2,…,Iter do:7 for useri in U do:8 for itemj in V do:9 更新Tr10 predict_rating←αUTiVj+(1-α)Tr+Fb11 更新Ui←Ui-γ(∂L/∂Ui)12 更新Vj←Vj-γ(∂L/∂Vj)13 end for14 end for15 P←α×U×V+(1-α)×S×U×V+F+S×F16 end for
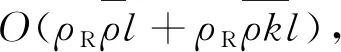
3 实验
3.1 实验运行环境
硬件配置:3.60GHz Inter(R)Core(TM)i7-9700K CPU,16GB内存
操作系统:Windows10企业版(64位操作系统)
开发工具:PyCharm2018.3,Navicat Premium
环境配置:Python3.6.9
数据库:MySQL
第三方类库:numpy,metric,matplotlib,BeautifulSoup
3.2 实验数据获取
实验数据集是通过自己编写的爬虫程序从豆瓣网(www.douban.com)爬取而得.豆瓣网是一个社区网站,提供有关书籍,电影,音乐等的信息.使用站内的网络搜寻器,在用户和电影之间搜寻信息,包括电影的用户评分,用户之间的关系以及用户对电影的注释.用户之间的关系是单向关注关系.当用户标记电影时,如果将其标记为“想要”,则此标签将被视为来自用户的正面反馈.如果用户看过电影但未对电影评分,则该电影将被视为用户不感兴趣的电影.
在对爬取的数据进行清洗时删除了独立节点,即没有关注任何人的用户.清洗后的数据集中总共有2 003个用户,用户关系数为2 240条.这些用户共计评论了63 895部电影,其中电影评分数为620 991条,用户反馈信息119 752条.在这些用户中,他们各自评分的电影数量并不相同,表1显示了与不同评分数量相对应的用户数量.表1可以看出,极少数的用户观影数量很高,他们往往是某一领域的领袖用户,而评分数为0的冷启动用户也很多,在用户集中占了不低的比例,说明在现实场景下,冷启动问题对推荐效果有着较大的影响.

表1 对应用户数和电影评分的统计表
实验时,数据集被随机划分为2个数据子集,即训练集和测试集.训练集包含了80%的数据,测试集则包含了20%的数据,采取五折交叉验证的方法对实验结果取平均值,以减少外部因素对实验结果的影响.
3.3 实验评价标准
文中通过实验对模拟平台为新用户进行推荐时的推荐效果进行考察,并与其他传统方法进行对比.假设新用户在注册登录时,根据自己的兴趣,采纳了平台为他推荐的一些用户的选择,那么就成为了一个没有评分但存在社交关系的用户.由于他没有任何的评分信息,也没有反馈信息,因此推荐什么项目给他全部依赖于他的社交关系.因此,为了验证社交关系在推荐中起到了不可或缺的重要作用,从原本的数据集中选取了10个用户,保留他们的社交关系信息,去掉评分、反馈信息,然后对他们进行推荐,并根据推荐的结果与原来的结果进行对比.但是由于电影数目十分庞大,推荐中同一部电影的可能性并不是很大,用户喜欢的不应该是某一部电影,而是某一类电影.因此可以对比推荐的电影类型,与该用户实际喜欢的电影类型是不是相同.在爬取的电影信息的数据中,电影标签主要包括年代、导演&演员、电影类型、拍摄国家等等,并且在爬取下来的数据中都是以单独的词出现.例如,《中国机长》的标签为:张涵予/欧豪/杜江/袁泉/张天爱/李沁/雅玫/杨祺如/高戈/黄志忠/朱亚文/李现/焦俊艳/吴樾/阚清子/李岷城/冯文娟/陈数/杨颖/余皑磊/关晓彤/刘浩/伊拉尔·帕萨/亚历克斯·皮希汀/莎伦·张/赵亮/周波/刘伟强/孟子义/余沛杉/李梓琳/中国大陆/刘伟强/111分钟/剧情/灾难/于勇敢YongganYu/汉语普通话/藏语/英语.而对某个用户观看的223部电影的标签进行了高频词提取,其中,前十的高频词如下:剧情 142/美国 122/汉语105/普通话 104/英语 95/中国香港 73/爱情 61/喜剧 52/迈克尔 38/英国 36,可以看出用户更关心电影类型、拍摄国家等信息.
因此,对平台新用户推荐效果的考察,采取对比推荐的电影的标签的高频词recommend_tag和该用户实际喜欢的和想看的电影标签的高频词real_tag的相同程度,并根据人们普遍的观念,将3分及3分以上的视为是用户喜欢的.式(6)是表示有多少个recommend_tag在real_tag中,以此作为对平台新用户进行推荐的评价标准.
(6)
3.4 实验结果及分析
首先对参数进行选取,由于不同用户构建的社交网络复杂程度不同,并且不同的应用场景也会对参数产生影响.参照文献[29],参数β应该是一个自适应的参数,根据不同的用户、应用场景而变化,通过多次实验来选择适应于当前应用场景最优的权重系数.
表2是随机从用户集中选取的某名用户,通过文中算法得到的推荐列表,和不考虑信任用户的偏好产生的影响得到的推荐列表的对比.
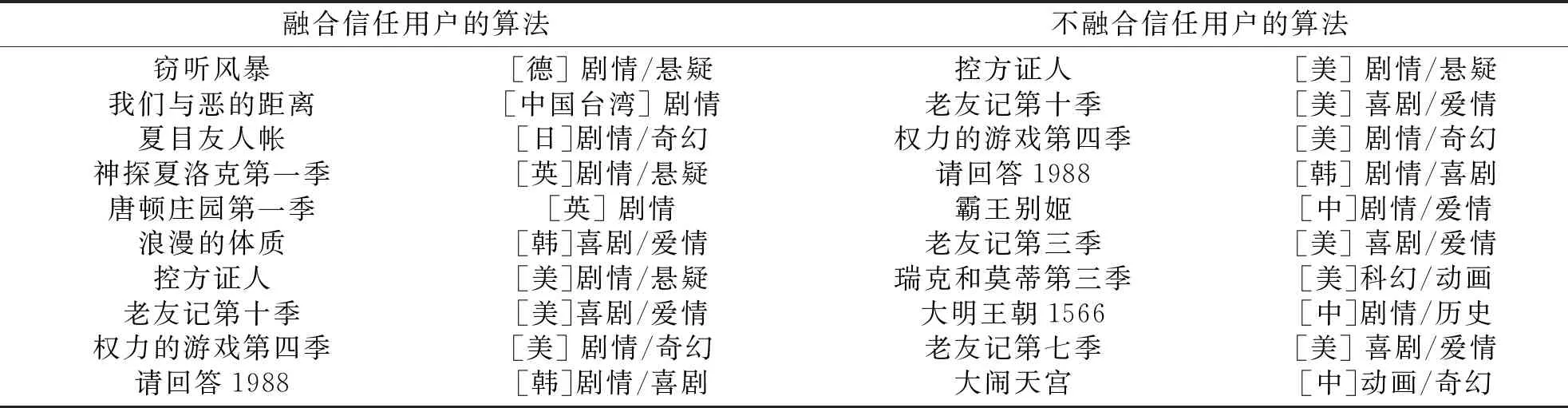
表2 不同推荐方法的推荐结果对比
该名用户的历史评分如下:“流浪地球”3分、“蝴蝶效应”4分、“实习生”5分等,被标记为“想看”的电影有:“浪漫的体质”、“彗星来的那一夜”、“查理和巧克力工厂”等,可以看出这名用户比较注重剧情,偏向于欧美国家的作品.显然,表2中的两个推荐列表,该名用户会更偏向融合了信任用户的算法进行的推荐结果一些.
表3显示的是从用户集中随机抽取的10名用户,删去他们的评分与反馈信息,只保留信任关系,为他们进行推荐后,将推荐的项目与他们实际喜欢的项目是同一类型的概率Same_Ratio,在5种不同方法下的实验结果.其中,概率矩阵分解模型(probabilistic matrix factorization,PMF)[30]是一种仅仅使用用户-项目矩阵进行推荐的经典概率矩阵分解推荐算法,而基于用户的协同过滤(user-based collaborative filtering,UserCF)[31]则是采用协同过滤为用户推荐与其兴趣相似的其他用户所喜欢的项目的经典算法.基于信任的奇异值分解(trust-based singular value decomposition,TrustSVD)[32]作为一种基于信任的矩阵分解方法,在对项目进行推荐的时候,同时考虑了项目评分和信任产生的显性影响及其隐性影响.协作用户网络嵌入社交推荐系统(collaborative user network embedding for social recommender systems,CUNE)[33]则从用户反馈中提取隐含的、可靠的社交信息,并为每个用户识别top-N语义朋友,并将这些语义好友信息整合到矩阵分解框架中,以改善评分预测的性能.

表3 Same_Ratio在不同Top-N下的值
通过表3可以看出,文中方法SoRFI在不同Top-N的情况下,Same_Ratio的值均优于其他几种算法.这意味着当用户只有社交信息,但是没有评分、反馈信息的时候,通过信任关系将用户的喜好传递给关联用户,可以较好地为这类用户进行推荐,从而为各平台缓解冷启动用户问题提供了一个可行的办法.
4 结论
以社会推荐模型RSTE为基础,文中将用户反馈信息和可信关联用户信息引入目标函数,一方面利用反馈信息降低了用户厌恶信息在推荐列表中出现的概率,另一方面通过反馈信息在关联用户之间的可信传播,扩大了反馈信息的使用人群,改善了反馈信息的稀疏性,改善了用户体验.真实数据集上的实验表明,文中算法的用户体验要优于PMF、UserCF、TrustSVD、CUNE和RSTE等多种社会推荐算法.
