利用依存句法关系改进神经译文质量估计
2021-10-19黎天宇蔡东风
叶 娜,黎天宇,蔡东风,徐 佳
(沈阳航空航天大学 人机智能研究中心,辽宁 沈阳 110136)
0 引言
近年来,基于深度学习的神经机器翻译取得了迅速发展,目前神经机器翻译已取代传统统计机器翻译成为学术界和工业界新的主流方法。尽管神经机器翻译取得令人瞩目的进步,然而现有的自动机器翻译技术还远没有完全达到实用的地步,仍然需要人工进行后编辑工作。机器译文的质量通常是使用BLEU值来进行评价,但在实际场景中参考译文的获取往往是非常困难的,所以使用BLEU值来评价译文质量的方法便显得不够实用。因此在没有参考译文的情况下,对机器译文进行质量评价的译文质量估计技术开始受到越来越多的关注。
译文质量估计技术从评价粒度上主要划分为句子级和词级,其中句子级质量估计任务是对每个句子的整体翻译质量进行评分,并通过译文质量分数估计后编辑的工作量。词级译文质量估计任务是对机器译文中的每个词进行评价,根据每个词的翻译对错进行标注。译文质量估计任务不依赖于人工参考译文,因此在实际应用中能够更好地辅助人工翻译,其研究更具现实意义。
早期传统的译文质量估计研究大多基于特征工程,将句子级分数或单词级标签预测分别表述为一个约束回归或序列标注问题。特征的提取一般从句子翻译难度、生成译文的流利度和忠实度3个方面进行,常用的机器学习算法有支持向量回归[1]、条件随机场[2]等,这些方法使用的特征多为浅层双语特征。自深度学习流行以来,许多研究人员尝试使用深度神经网络自动提取质量特征并进行评价[3-7]。与传统的译文质量估计方法相比,基于神经网络的译文质量估计模型具有更强的自学习特征能力,能够发现句中的隐式双语信息,并取得相对较好的性能[8-11]。
神经译文质量估计模型将语句看作一个词序列,并从中学习到一定的隐式句法信息。但该方法很难有效捕捉语句中更深层次的结构细节,忽略了外部知识。所以本文使用额外语言学知识去补充源语句的深层句法信息。
依存句法分析是句法分析中一个重要的分支,能够充分表现源语句中词与词之间的相互联系。因此,本文显式地引入源语句的依存句法关系,帮助提升质量向量所蕴含的深层句法信息,使预测结果更加准确。在WMT2017句子级译文质量估计任务的实验中表明,源语句的依存句法信息可以被有效地、显式地融入到模型中,以提供进一步的改进。此外,本文还使用神经网络模型对多个不同层面的语言学特征进行融合,并对实验结果进行深入分析,揭示不同特征对译文质量估计所产生的影响。最后,为提升模型泛化能力,本文使用集成学习算法将多个模型融合,结果表明集成模型相比于单个模型获得了更好的效果。
1 相关研究
在神经译文质量估计的研究中,语言学知识在传统的译文质量估计研究中得到了广泛应用,并取得了不错的效果。
Hardmeier等人[12]从双语依存树中提取了树核特征并加入QE系统。实验表明该特征无论是单独使用还是与其他显式特征相结合,都有助于系统性能的提升。Rubino等人[13]提取包含源语言和目标语言语法的多个特征用于QE任务,更加证明了语法对该任务的有效性。Specia等人[14]将依存语法和成分语法的POS特征和句法特征结合起来用于QE任务。Kaljahi等人[15]发现了语法信息在英法机器翻译中的效用,认为树核是编码语法知识便捷有效的方法,并从源语言和目标语言的成分树和依存树中选择144个特性,与QE任务的基线特性和树核特性相结合。Kozlova 等人[16]使用成分树中的最大树深、树的平均深度、树中内部节点的比例等数字句法特征来提升实验效果,同时也用来判断该句子的复杂程度,便于后期编辑工作的进行。Martins等人[17]使用句法特征来检测机器翻译中的句法错误。
上述方法都是基于传统的机器学习算法进行译文质量估计。随着深度学习的发展,人们开始在译文质量估计任务中使用神经网络模型,因为神经网络具有很好的特征学习能力,能够缓解过去研究对人工特征过分依赖的情况。
基于深度学习的神经译文质量估计方法通常是将双语句对输入到神经网络中的词嵌入层得到词向量,而后通过神经网络自学习提取特征。但这样的方法由于QE语料的缺乏,模型在训练过程中很容易出现过拟合的情况。Kim等人[18]提出了一种“完全”的神经网络模型,该方法使用词预测模型来增强双语的信息表示,并应用到译文质量估计任务中。其中词预测模型是由大规模双语平行语料进行训练并经过QE语料进行调整得到的,很大程度上缓解了传统神经网络模型因为语料匮乏而产生的影响。该方法也是首次将其他领域的模型与质量估计模型相结合,对该任务的后续研究有着很大的帮助。
后来,Kim等人[19]在上述工作的基础上又建立了预测器-估计器的体系结构概念,并提出了一种更加精细的QE特征提取方法。孙潇等人[20]针对句子级译文质量估计任务提出了一种融合机器翻译知识的特征提取算法,训练了两个翻译方向相反的机器翻译模型,然后利用两个编码器编码得到向量作为特征,该方法相比于直接使用语句中的词向量得到的预测效果更好。
语言学知识在早期的研究中都是使用机器学习算法来提取特征应用于译文质量估计领域,但这样的方式很难获取深层的句法信息。随着深度学习的出现和发展,这个问题慢慢得到解决,句法知识也被越来越多的研究人员应用到神经译文质量估计模型中。Chris Hokamp[21]将句法和词性等语言学特征用于后编辑和词级译文质量估计任务中,基于神经机器翻译系统,将后编辑和词级译文质量估计任务相结合,并依靠后编辑结果在模型训练过程中优化参数。Ye等人[22]使用依存句法中心词信息对译文质量估计进行改进,从源语句的依存句法树中提取每个词的中心词,并与词预测特征进行融合来提升实验效果。近年来优秀的预训练语言模型越来越多,陆金梁等人[23]使用多语言预训练模型来提升译文质量估计的效果,文中使用联合编码的方法完成句子级任务,并通过平行语料改进了跨语言词汇的表示,相比于原模型得到了更好的效果。
本文为了解决神经译文质量估计模型不能充分学习到源语句中句法信息的问题,显式引入源语句内部的依存句法关系作为特征,建立源语言依存句法结构和译文质量之间的联系,使模型能够从更深入的句法角度去分析译文的错误,进而提升准确率。根据源语言生成的依存句法树,显式地提取了依存关系特征,并将该特征与词预测、中心词和预训练语言模型等多个不同层面的语言学特征进行融合,构建了一个神经译文质量估计模型,并进行了多组对比实验,分析了不同特征组合所产生的利弊。最后使用集成学习算法得到集成模型,相比单个模型获得了更好的泛化性能。
2 特征提取
2.1 依存句法关系特征
自然语言的基础分析技术大致可以分为三个层面: 词法分析、句法分析和语义分析。依存句法分析是句法分析的一种常用方式,它用词与词之间的依存关系来描述语言结构的框架。在依存句法分析中,“依存”是指词与词之间的交互关系,这样的关系是不对等的,具有方向性。准确地说,处于支配地位的成分称为核心词(中心词),而处于被支配地位的成分称为依存词。这两个词组成一个“依存对”,它们之间的从属关系被称为依存关系。这样的结构可以通过依存句法树的形式表现出来。我们使用句法分析工具Stanford Parser(1)https://nlp.stanford.edu/software/lex-parser.shtml对源语句进行依存句法分析得到依存句法树,具体结构如图1所示。
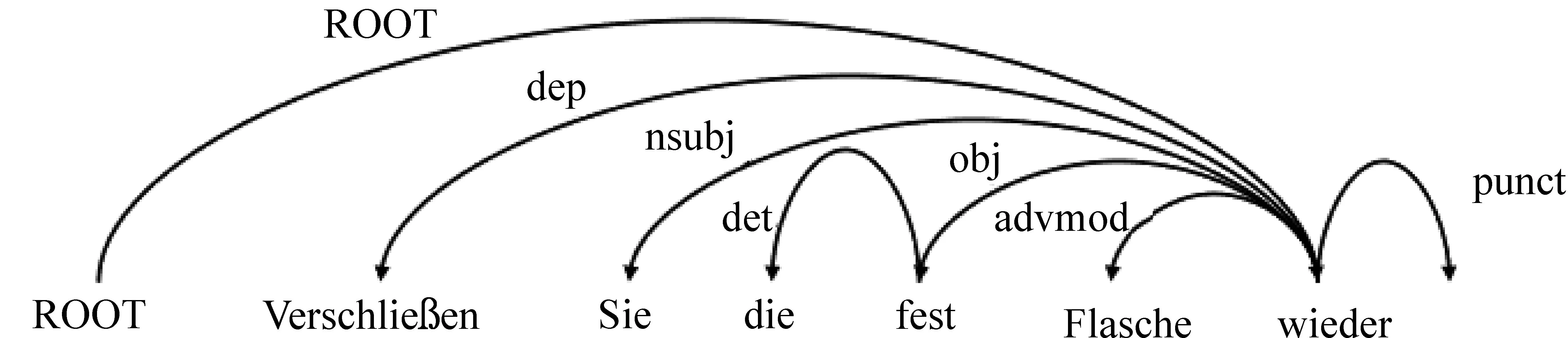
图1 依存句法树结构
通过依存句法树可以清晰地得到句中每个依存对和对应的依存关系。考虑到序列的长度问题,而且神经网络模型有很好的自学习特征的能力,因此本文将每个依存对中的依存关系作为标签提取出来,对该特征进行序列编码,并与词预测特征进行融合,让模型能够学到源语句中词与词之间的依存关系,进而获取句中深层的句法信息。表1给了一个依存关系标签特征表示的实例。

表1 依存关系标签实例
将源语句的依存句法树线性化,得到标签序列。然后将每组依存对所对应的依存关系提取出来,按照依存词在句中的先后顺序进行排列,得到依存关系标签。
2.2 词预测特征
词预测特征的提取,需要构建一个词预测模型,通过给予目标词的源语言和目标词的上下文信息来预测该词。该过程和质量估计模型高度相关,它能够传递有效的信息来完成译文质量估计任务。该模型采用了基于双向RNN的编码器-解码器框架。编码器将源语句编码成句子向量cj,放入到解码器中,结合目标句上下文信息得到目标单词yj的概率,计算如式(1)所示。
(1)

而后将提取到的词预测特征与其他特征一起作为评估模型的输入,通过神经网络模型来计算译文质量。词预测模型整体结构如图2所示。

图2 词预测模型整体结构
2.3 中心词特征
依存语法的结构没有非终结点,词与词之间直接发生依存关系,构成一个依存对,其中一个是中心词,也叫核心词;另一个是依存词,也叫修饰词。
中心词(Head-Word,HW)特征参考了Ye等人[22]的研究成果,从树中可以得到句中的每一个依存对,并将其线性表示,提取标签。依存句法树如图1所示。
为了获取源语句词与词之间的从属关系,我们将源语句中每个依存词所对应的中心词作为标签并提取出来,表2给出了一个中心词特征表示的实例。

表2 中心词标签表示的实例

续表
2.4 预训练语言模型特征
随着EMLo(Embeddings from Language Models)[24]、BERT(Bidrectional Encoder Representations form Transformers)[25]等预训练模型的出现,人们研究发现将这些模型应用在很多自然语言处理任务中都有着积极效果,因为它们并不是给一个词以固定的向量表示,而是在一个经过预训练的编码器网络中,根据句子语境的不同,动态地给予每一个词不同的向量表示。这样可以使句子内词汇之间得到充分的交互,进而得到更好的词向量表示。
本文在融合依存句法关系特征的基础上,同时也融合了预训练模型特征来进一步提升实验效果。本文采用了目前效果很好的预训练语言模型XLNet[26]对语料进行向量表示。XLNet是针对自回归语言模型单向编码以及BERT类自编码语言模型的有偏估计的缺点,提出的一种广义自回归语言预训练方法,使用Transformer-XL[27]代替传统的Transformer[28]网络,能够获取更长的文本信息,并引入了一个排列语言模型能够学习到更多的上下文信息,且不需要使用Mask符号。该模型在部分NLP任务中相比于BERT模型效果有明显提升。
本文使用的XLNet模型是在大规模语料上训练得到,所以其词嵌入向量能够携带更多的句法信息去辅助其他特征增强双语表示获得更好的效果。
2.5 基线特征
除了上述特征外,本文还使用了WMT官方提供的17个基线特征,其中包含源语句、目标语句的词数、语言模型概率、句中的标点符号个数、目标句中各个目标词的出现次数及平均值、源语言中每个词对应译文词数的平均值和加权平均值、源语言词占源语言训练语料中频率四分位数1(频率较低的单词)的百分比、源语言词占源语言训练语料中频率四分位数4(频率较高的单词)的百分比、在SMT训练语料库中看到的源句中的一元组百分比等。
这些特征虽然只是双语句对的表层特征,但是与神经网络特征相比解释性更强,能够更加直观地反映双语信息,因此将这些特征与上述特征相融合,进行更加全面的表示。
3 神经译文质量估计模型
3.1 特征融合模型框架
在整个译文质量估计框架中,本文使用特征提取模型来对多个特征进行序列编码、提取信息,而后放入评估模型进行训练、融合并输出。
对于特征提取模型,词预测特征向量由词预测模型输出得到。依存关系、中心词特征使用词预测模型中编码器进行编码后得到序列向量,预训练模型特征向量由XLNet模型直接进行提取。而后将上述得到的特征向量分别放入评估模型中进行训练。
评估模型由一个双向LSTM网络构成。句子级评估任务,其最终结果是得到译文句子的HTER值,所以可以将该任务视为一个回归问题。使用双向LSTM网络对词预测特征向量进行训练,并取前向和后向LSTM网络的最后一个隐状态进行拼接作为最终向量。
依存关系、中心词、预训练模型特征采用和词预测特征一样的处理方式,经过训练后取最后一个隐状态作为序列向量,然后将多个特征的隐状态向量进行融合,得到包含源语言句法信息更丰富的质量向量,但为了避免融合后向量的模过大,采用对该向量取平均的方式,计算方法如式(2)所示。
H1=(HW+HD+HH+HX)/4
(2)
其中,HW、HD、HH、HX分别表示词预测特征隐状态、依存关系特征隐状态、中心词特征隐状态和预训练模型隐状态。然后将融合后的特征向量与17个其他特征进行拼接,最后使用Sigmoid函数计算出译文质量分数。整体融合结构如图3所示。

图3 特征融合模型框架
3.2 特征提取模型
特征提取模型是利用神经网络的自学习能力去将获得的多个特征进行信息提取并编码,不同神经网络对不同特征的表征能力也各不相同。所以本文使用深度学习中常用的LSTM和Transformer网络进行对比。
3.2.1 Bi-LSTM
RNN是递归神经网络,在深度学习中已经成为标准组件。RNN具有如此吸引力的原因在于,其网络中每一步的输出,不仅与当前信息有关,也与当前时刻之前的信息有关,这样的结构在一些NLP任务中经常会用到。但不幸的是,随着需要学习的序列变长,RNN会逐渐弱化这种捕捉历史信息的“能力”。后来有研究人员提出了长短时记忆网络(Long Short-Term Memory,LSTM)[29],通过在神经元中引入输入门、输出门和遗忘门的方式,很好地解决了RNN所存在的问题。
本文使用Bi-LSTM网络对多个特征进行编码得到高维向量,然后放入评估模型进行训练,输出预测值。
3.2.2 Transformer
Transformer是谷歌于2017年发布的一个用来替代RNN和CNN的新型网络结构,RNN是以递归方式进行的,适合序列建模任务。Transformer本质上就是一个Attention结构,它能够直接获取全局信息,不像RNN需要逐步递归才能获得全局信息,也不像CNN只能获取局部信息,并且该网络能进行并行运算,所以要比RNN快上很多倍,在WMT 2018机器翻译任务中成为效果最好的模型。
该架构不仅在源语言和目标语言之间进行注意力机制的计算,而且还在源语言和目标语言内部也进行注意力机制的计算,使得句中词与词之间的交互关系能够很好地被学习到。
本文使用Bi-LSTM和Transformer网络对相同特征进行多组对比实验,并分析实验结果,具体结论在实验阶段给出。
3.3 系统集成
在机器学习的有监督学习算法中,目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况却没有这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现得比较好)。集成学习就是组合多个弱监督模型以期望得到一个更好、更全面的强监督模型。集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。该算法在各个规模的数据集上都有很好的效果。
在本文研究中,我们提取词预测、预训练语言模型、依存句法关系等多个特征进行实验,生成多个模型。在句子级任务中我们使用平均法对多个模型的预测结果进行集成,来进一步提高模型评分与人工评分之间的相关性。
4 实验
4.1 语料说明
本文实验在WMT2017句子级译文质量估计任务中进行。整个译文质量估计模型需要使用两个数据集,分别是训练词预测模型所需的大型双语平行语料和训练评估模型所需的QE数据集。
大型双语平行语料来自WMT2017机器翻译任务,由Europarl v7、Common Crawl Corpus、 News Commentary v11等部分组成。为了提升实验效果,我们对该数据集进行如下处理,过滤句子长度超过70、源/目标语句长度比例超过1/3、含有特殊符号或重复词过多的句对,最后得到双语句对430万,验证集2 489对。
QE数据集来自WMT2017句子级译文质量估计任务,训练集25 000对,验证集1 000对,测试集2 000对。实验数据集信息如表3所示。

表3 平行语料和QE语料数据信息
4.2 实验设置
整个实验模型使用Tensorflow框架进行搭建,网络参数如表4所示。
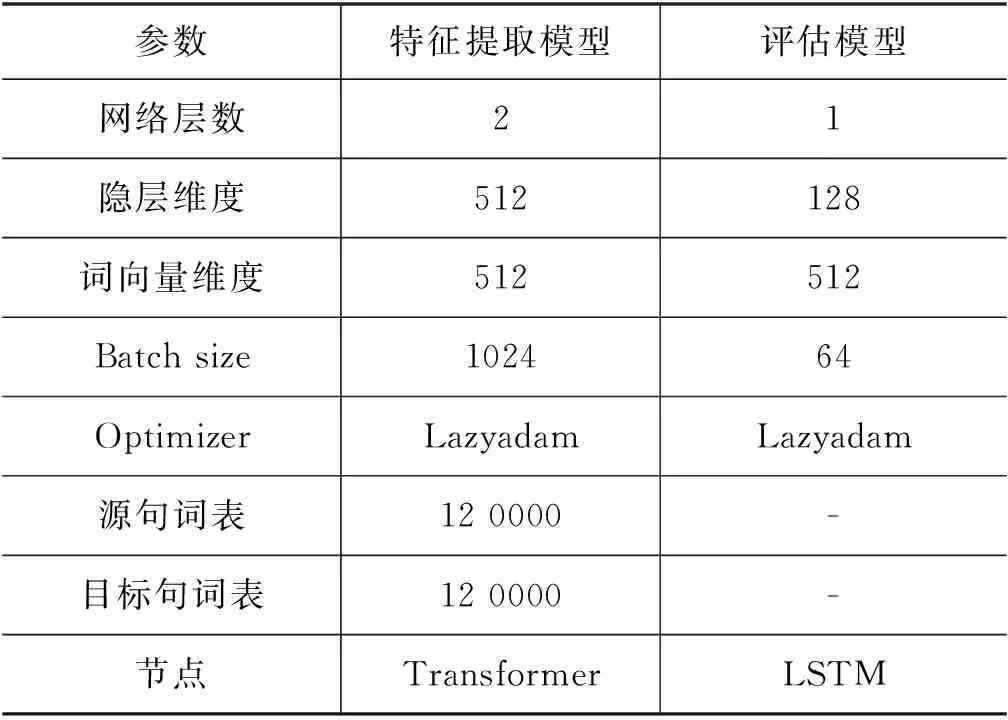
表4 实验参数设置
4.3 评价指标
对于句子级任务,目标是评估整个译文的翻译质量,也就是计算机器译文与人工后编辑译文之间的差异,即HTER(Human-targeted Translation Edit Rate)值,计算如式(3)所示。
HTER[30]=NUM_MODIFY/LEN(PE)
(3)
其中,NUM_MODIFY表示机器译文需要修改的次数,LEN(PE)表示人工后编辑译文的句子长度。
模型性能的评价指标一般通过皮尔逊相关系数(Pearson)、斯皮尔曼相关系数(Spearman)、平均绝对误差(Mean Absolute Error,MAE)和均方差(Root Mean Squared Error,RMSE)等四个数值来判断,其中皮尔逊相关系数是最主要的衡量系统性能的指标,它反映了模型评价分数和人工评价分数之间的相关性,具体数值计算可通过式(4)求得。
(4)
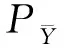
(5)
其中,dTi表示在N个机器输出译文中,机器译文Ti的模型预测分值排名与人工打分排名之间的差值。同皮尔逊相关系数一样,该值越高,说明二者排名越相关,则模型性能越好。
平均绝对误差和均方差作为辅助评价指标,与上述两种评价指标相反,数值越低说明模型性能越好。
4.4 实验结果与分析
实验包含德-英和英-德两个语言方向,特征提取模型分别使用Transformer和LSTM两种网络来进行对比,实验结果如表5~表8所示。以德-英方向为例,表5中“W-P”“DSG”“HW”“XLNet”“other”分别表示词预测特征、依存句法关系特征、中心词特征、预训练语言模型特征和基线特征。两个表中的实验分别表述为实验一(Transformer)和实验二(LSTM)。表中最后三个模型是WMT2017评测前三名[31]。

表5 WMT2017德-英句子级任务(Transformer)实验结果
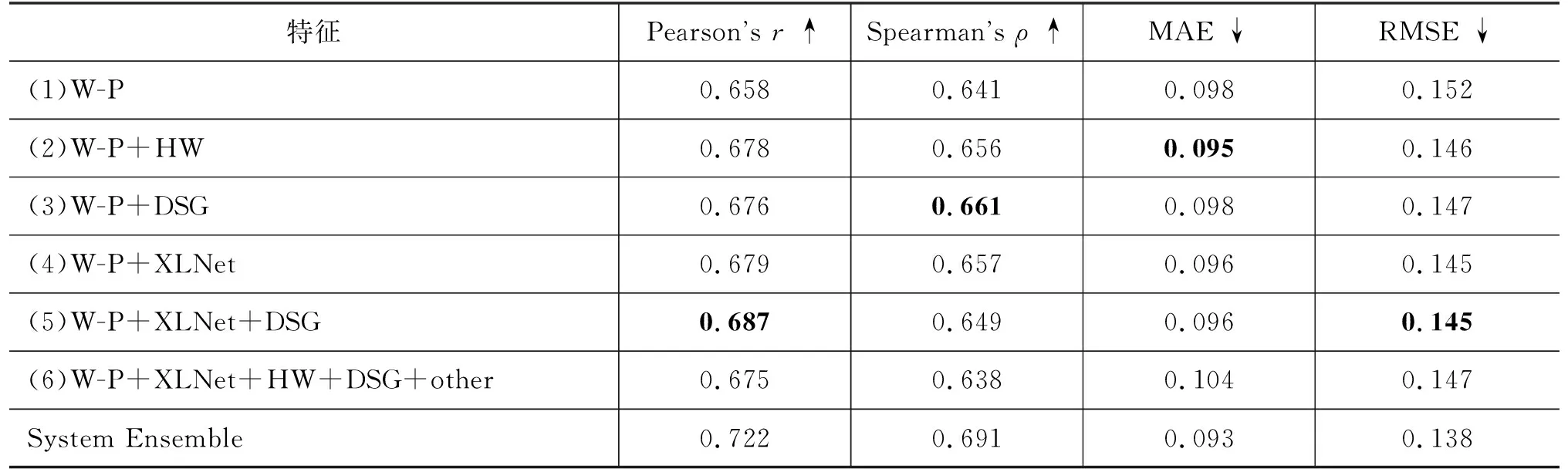
表6 WMT2017德-英句子级任务(LSTM)实验结果
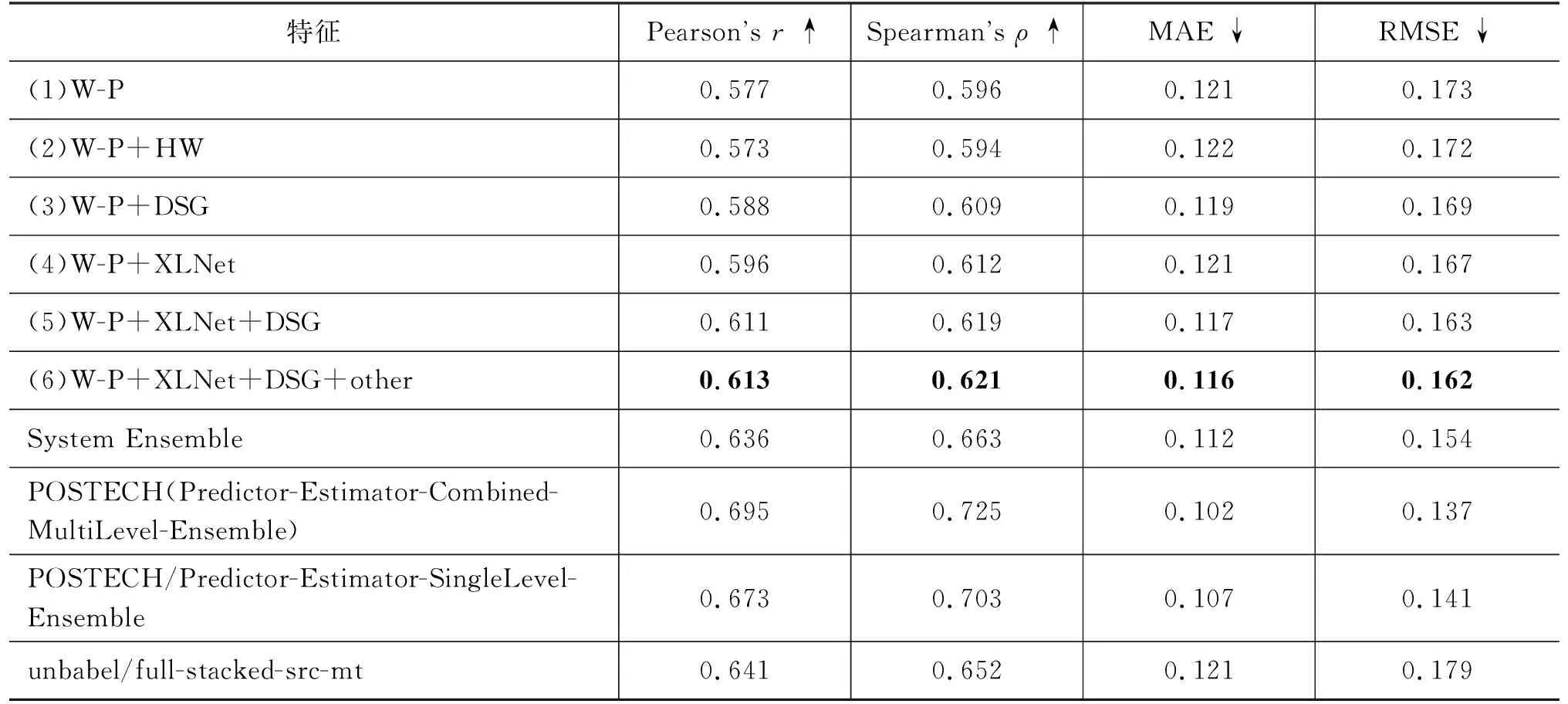
表7 WMT2017英-德句子级任务(Transformer)实验结果

表8 WMT2017英-德句子级任务(LSTM)实验结果
从两个实验的对比结果来看,Ye[22]等人所提出的中心词特征如其在论文中所述,在实验二中取得了很好的效果,但在实验一中效果不佳,我们认为是因为加入的中心词特征只能体现依存对之间存在联系,而Transformer中基于注意力机制的网络结构相比于LSTM的递归网络结构能够更好地学到句中词与词之间的相互联系,与加入的特征发生了信息冗余,导致融合的效果变差。而本文提出的依存关系特征在两个实验中都有很好的表现。
无论Transformer还是LSTM网络,都使用双语平行语料库来训练,并从中学到一定的句法信息,但都无法捕捉句中深层次的结构细节,缺乏显式的语言学知识。与中心词特征不同,本文提出的依存句法关系特征是将源语句所对应的依存句法树中的依存句法信息提取出来,并以外部知识的形式补充到神经网络中,丰富了质量向量所蕴含的句法信息,在两个网络中都能起到很好的作用。
预训练语言模型是在大规模无标注语料上进行训练的,而且根据句中上下文语境的不同,动态地生成词嵌入向量,进而能够很好地辅助词预测特征生成更好的质量向量。从表中的实验结果可以看出,该特征在两个模型中都有很好的表现。
接下来将产生正向影响的特征进行融合,在实验一中将词预测特征、预训练模型特征、依存句法关系特征进行融合。预训练语言模型可以很好地编码单词及其上下文信息,甚至学习到一定的依存句法关系,但从实验结果来看显然是不充分的,依存句法关系特征是编码语句对应依存句法树中的结构上下文信息,与预训练模型特征融合后,信息得到互补,学到了语句中深层的句法信息,使预测效果得到进一步提升。基线特征是一个17维的数值型特征,虽然能够很直观地反映语料的基本信息,但蕴含的深层信息很少,并不能有效提升实验效果。实验二中的效果与实验一类似,加入的依存关系特征同样使实验效果得到提升,但是在加入中心词特征后效果变差,原因是该特征和预训练模型特征类似,都能够提升句中词与词之间的交互关系,但融合到一起后两个特征所包含的信息发生冲突,导致效果变差。在英-德实验中可以得到与上述相同的实验结论。
实验一中融入依存句法关系特征的模型相比于单个词预测特征模型的Pearson相关系数提高了1.97%,在实验二中提高了1.75%,对于融合多特征模型的方法,在实验一中最好的效果提高了3.81%,实验二中提高了2.85%,英-德方向也有不同程度的效果提升。
最后,我们将实验一中得到的(1)、(3)、(4)、(5)共四个模型进行集成,达到了最佳的实验效果。实验二中将(1)、(2)、(3)、(4)、(5)共五个模型进行集成,同样取得了最佳效果,可见集成学习算法可以将多个模型中不足的地方进行改进,集成多个子模型的优点,得到泛化效果最好的集成模型。与2017年WMT参评模型相比,如表5所示的两个数据集所得到单模型相较Baseline均有较高提升,德-英单模型在整体排名第一,英-德排名第二。德-英集成模型与POSTECH取得相同分数,排名第一。英-德模型排名第四。
本文在WMT2020英-中句子级译文质量估计语料中同样进行实验,得到结论与WMT2017相同,证明了依存句法关系特征和特征融合的有效性。实验结果如表9、表10所示。

表9 WMT2020英-中句子级任务(Transformer)实验结果

表10 WMT2020英-中句子级任务(LSTM)实验结果
从机器翻译的角度来考虑,Seq2Seq模型虽然能够从平行语料库中学习到一定的隐式源语言句法信息,但不能捕捉到很多深层的结构细节,翻译结果可能会产生对句法不尊重的情况。可以通过加入源语言句法信息的方式来缓解该问题。译文质量估计也是如此,通过加入依存句法信息,让模型学习到有用的信息,去更好地判断目标句的错误,表11中我们列举了一个例子来证明依存句法关系特征的有效性。

表11 WMT2020英-中句子级数据实验结果对比
从上述例子中可以看到,源语句和目标句之间单词的互译并不存在任何问题,但目标句体现了对句法的不尊重(“一个愉快的利夫”这样的表述以及前后子句的先后关系从语言学角度是不恰当的),导致整个句子的语序和结构出现了问题,HTER值较高。在加入依存句法关系后,模型能够更精准地分析出目标语言的错误,结果也更接近正确值。
5 结论与未来工作
本文研究了源语句中的依存句法关系能否以及如何帮助句子级译文质量估计任务提升准确率,我们将源语句中的依存句法关系显式地提取出来,转化为一个序列标签,融入到模型中,加深了模型所学到源语言的句法知识,丰富了质量向量所携带的信息,进而提升了实验效果。同时使用多特征融合的方式将词预测特征、中心词特征、预训练模型特征和基线特征加入到模型中来,通过多个对比实验分析了不同特征对不同神经网络模型所产生的影响。最后使用集成学习算法,得到集成模型达到了最佳性能。
下一步的研究工作将从以下两个方面进行: ①文中所提出方法只在句子级任务中进行了相关实验,可以尝试将该特征应用到词级任务中,查看是否能取得好的效果。②对于语言学知识还有很大的空间去进行研究,我们会尝试提取其他语言学特征,融入到网络模型中并观察效果。
