铁路调度集中系统智能运维构建探讨
2021-10-19晏子峰
晏子峰
2020 年国铁集团发布《新时代交通强国铁路先行规划纲要》,至2035 年,全国铁路网要达到20 万 km 左右,其中高铁 7 万 km 左右,20 万人口以上城市实现铁路覆盖,50 万人口以上城市高铁通达[1]。目前我国形成了具有独立自主知识产权的高铁建设、装备制造、安全运营、维护管理的技术体系。随着高速铁路的快速发展,铁路调度集中(Centralized Traffic Control,CTC)系统担负着确保列车安全、稳定、可靠运行的重任,以调度集中系统为基础的运维智能化也是我们面临的一个重要课题[2]。本文对以调度集中系统为基础的铁路智能运维系统的构建进行探讨。
1 智能运维的必要性
以调度集中系统为基础的铁路智能运维系统,是适应新技术应用而产生的,有别于传统以人工维护为主的一种新兴维护模式。该模式的关键策略是通过深度学习、机器学习等人工智能算法,对获取的海量数据自动进行智能分析处理,挖掘出其中有价值的潜在信息,进而对设备运用与维护提供优化的指导方案。该模式旨在通过智能化手段更经济有效地进行铁路调度指挥系统设备全寿命周期的健康管理,增强设备运营的可靠度和风险预知能力,提高运营服务效率,减少运维压力,助力实现管理成本最优化,助推铁路高质量可持续健康发展[3]。
铁路智能运维系统能够随着运营规模的不断增长、新技术的迭代更新,更精准地掌握设备的健康状态,提高设备运行稳定性;有效减轻维修人员工作强度,提高运维精准性;提高维护效率,降低维护成本。该系统的核心内容包含安全、质量、成本、效率,最终实现关键绩效指标KPI (Key Performance Indicator) 的整体量化提升[4]。铁路智能运维系统的结构关系见图1。

图1 铁路智能运维系统的结构关系
安全:通过标准化的流程保证设备安全、人身安全,做到风险可控,应急响应及时。
质量:以可靠性为中心,全员生产维护,降低故障率,保证设备正常运行。
成本:通过量化的KPI 达到资源配置的合理最优。
效率:延长平均无故障时间MTBF,减少故障修复时间MTTR,优化信息获取、故障判断时间等。
随着物联网、大数据以及AI技术的不断成熟,设备运维从人工化、自动化向智能化演进,智能运维逐步在运维领域发挥积极的作用。
2 智能运维系统总体架构
铁路智能运维系统主要由设备资产、设备健康、生产管理及分析决策四大功能模块组成。设备资产模块实现电务资产全层次精细化实时跟踪,管理资产一目了然;设备健康模块实现全生命周期动静结合的设备健康评估,提前发现设备隐患;生产管理模块实现全流程生产管控监督,提升生产质量及效率;分析决策模块实现基于大数据的全方位生产及投资决策建议。
铁路智能运维系统总体逻辑架构可以分为4 个层次[5],见图2。数据层:从设备监控、专业维修等业务系统中进行数据汇总,从人、物两方面建立统一、完整、规范的数据层。平台层:包括设备运维中所必须的基础能力,如设备状态及故障的管理、作业计划的调度管理、设备状态的实时维护管理等。业务层:通过对通信、信号、车辆、供电等专业领域的业务评估及建模,提供智能化的业务分析方案。管控层:一方面通过数据指标的汇聚,形成总体态势的可视化应用;另一方面形成集约高效的智慧调度中心[6]。
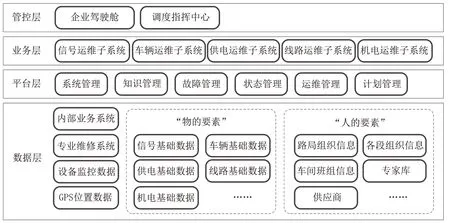
图2 智能运维系统总体逻辑架构
运维过程从数据流的角度又包含数据采集、数据存储和数据使用3个部分。
1) 数据采集。支持各类异构数据源、结构化或非结构化数据的同步,如基于ETL 工具从业务系统的各类异构数据库中抽取结构化数据[7];基于IOT技术从各类设备直连、网关、上位机抽取实时监测数据;基于Flume等文件同步手段,提取设备日志数据等[8]。
2) 数据存储。随着所辖设备和系统的增加,数据存储主要解决几类问题。一是持续存储海量的异构数据,除了结构化的数据库数据,还包含非结构化的数据,如图片、日志、视频等;二是保证数据的规划一致性。这需要数据治理的支撑,数据治理能够自动提取元数据信息,并统一存储,对元数据贴上标签并进行分类,建立统一的数据目录、数据血缘,梳理上下游的脉络关系。这种方式有助于数据问题定位分析、数据变更影响范围评估、数据价值评估,最终对于接入的数据进行质量管控,提供数据字段校验、数据完整性分析。
3) 数据使用。数据使用包括数据的离线计算、流式计算和数据搜索。数据的离线计算:通过sparksql、impala 等计算引擎,以及指标体系的构建,在海量数据中快速计算出业务所需要的指标[9]。流式计算:通过flink、spark 等大数据流式计算引擎,针对设备上报数据的异常判断、健康诊断给出实时结果[10]。数据搜索:各专业用户以及系统能够快速从数据湖中查到自己所需的数据和指标结果,同时保证对数据的使用进行安全管控、对敏感数据进行脱敏处理。
3 智能运维的推进
为推进智能运维工作,在监测分析与标准化、维修模式与修程修制、生产组织与管理模式以及行业运维能力的建设等方面,应制定智能运维的技术标准,加强数据共享指导修程修制优化,强化数据应用提升管理效能,并培育专业化的运维服务企业,围绕电务设备“检”、“维”、“修”、“管”4个核心内容,搭建平台结构,提高智能运维的综合效益。
检:通过机器、设备检测代替人工检查。运用机器学习和大数据分析技术,对设备运行状态和变化趋势进行实时跟踪分析,提前发现设备状态变化及隐患。
维:通过人工智能实现设备故障诊断,准确定位故障发生范围,自动匹配历史同类故障的处理过程和建议方案,实现智能抢修,提高故障应急处置效率。根据设备预警自动下发作业工单和设备维护建议,实现设备“状态修”。同时对作业执行全过程进行自动监督,通过监测设备状态对问题是否被解决、处理状态是否被关闭进行卡控。
修:建立关键设备和零部件的健康度评价模型,通过设备报警预警、监测数据、维护维修等动态数据和设备设计等静态数据结合,科学计算设备健康度和剩余寿命,提供大、中维修建议,避免设备过度修,延长设备使用寿命。
管:根据国铁集团《铁路信号设备单元划分、编码及表征规范》的规定,建立统一的设备编码,并与供应商定期将安装设备的名称、数量、序列号、出厂日期、返修记录等关键数据同步,同时对接入设备在运营过程中进行数据监测,实现设备全生命周期内数据的有效管理[11]。
通过运营单位、系统供应商和智能运维解决方案提供者的共同努力,加强数据共享,推动制定相关技术标准,建立统一的智能运维系统,研发具备产业化的技术装备,必将进一步推进智能化运维的有效落地。
4 智能运维的趋势
4.1 基于深度学习的多指标异常检测
多指标异常检测技术[12]指对业务日志统计数据、设备上报的多个采集数据进行综合分析。这类数据通常具备较为复杂和相互耦合的特性,因此无法用传统的四则运算规则处理。尤其是对具有时序特性或周期特性的数据进行检测时,传统的技术方法无法满足业务需求。深度学习算法对多维度特征的分类提取具有先天优势,其关注特征包括时间序列周期、上下行趋势特性、差分指数等。
4.2 基于设备固有特征和相似度的海量指标异常定位
针对铁路现场的大量设备以及不同设备的采集项,当故障问题发生时,能够通过设备之间的固有特征关系以及指标采集影响因子,利用相似度等算法,定位出当前上报各个异常指标中的根因指标,由此帮助维护人员快速定位需要排查的真正故障系统,缩短排障时间,再从实时调用关系和时序指标数据出发,并结合报警数据分析,构造出故障传播图并找出根因。
4.3 基于自然语言处理的日志分析
不同设备每天都在积累海量的日志数据,且日志记录方式千差万别,形成典型的日志大数据。基于自然语言处理(NLP)[13]和大数据分析技术,可以准确地从海量日志中提取有决策意义的信息,发现日志所代表的事件,应对日志规模巨大、设备变更后新类型日志的产生、日志结构复杂且多样带来的挑战。通过日志异常检测机制,能够准确、高效地解析日志,且自动、准确地检测,主动发现设备的异常,及时采取应对措施。
4.4 基于智能感知的采集
目前的运维监测采集对象比较单一,采集频率及精度低,不具备智能化自主能力,而智能感知采集可具备如下特点。
1)多元化:监测对象由电气特性为主向多元化转变,为运维人员提供更全面的在线监测范围。
2)精细化:提高采集频率、提升采集精度,为运维分析提供更精细化的高质量数据。
3)智能化:加强感知设备的智能化、自主化处理能力,有利于局部专业化的快速诊断及处理。
5 结束语
智能运维不仅是当前行业的发展热点之一,而且是铁路运营各级单位安全生产管理的迫切需求。目前铁路通信、信号、车辆、供电等各专业虽然已经将智能化运维的建设提到了新的高度,但仍存在难点。
1)由于智能运维的运用还在起步阶段,目前行业中无相关标准,这即给供应商提供了自由度,同时也增加了难度。伴随着海量的业务需求涌现,尽早完善相关标准,规范智能运维系统的功能和方向,使得不同供应商研制出的智能运维系统在功能和标准上保持一致,结构上保持统一,十分必要。
2)现阶段各专业的智能运维系统基础数据不够完善。为了获得更多的数据,如果只通过增加更多辅助设备,如传感器等来实现目标,一方面会导致数据更加庞大,另一方面也使得系统更加复杂,不仅在信息安全方面带来了新的挑战,而且也增加了系统成本和维护难度。
3)目前面向深度学习或者机器学习的特征数据提取、故障诊断等,仍然需要技术人员的经验知识和离线分析[14]。如何有效实现在线的高准确度、智能化分析,仍然还有很多的技术难点需要攻克。
随着信息化系统的不断迭代升级,铁路调度系统也会跟随不断更新,基础部件将面向智能化发展,设备的监测数据获取也逐渐无需增加额外的数据采集、传输设备。在降低系统复杂性的同时,增加智能运维功能,将为智能运维的规模化应用、智能维保综合效益的实现提供关键条件。
