标签关联与学习模型相结合的用户兴趣变化识别算法
2021-10-19白杨
白 杨
(辽东学院 信息工程学院,辽宁 丹东 118003)
随着新媒体服务的蓬勃发展,社交网络中的用户生成内容(User Generated Content,UGC)出现了爆发式的增长。海量的UGC数据反映着用户的观点、态度、情感、行为习惯和兴趣偏好。微博是中国使用人数最多、流行度最高、数据量最丰富的社交网络平台之一。微博用户可以发表微博信息表达自己的心声,可以关注其他用户获得对方的最新动态,也可以通过标签标注自己的兴趣爱好,但这种用户标签相对匮乏。此外,微博数据还具有文本短和时效性强的特点,同时在数据处理上又具有高稀疏性和上下文强依赖性。将一个用户发布的所有微博内容看作该用户的全局描述文档,通常采用VSM(Vector Space Model)方法,通过TF-IDF(Term Frequency-Inverse Document Frequency) 提取特征词,根据特征词的共现程度进行用户特征向量之间的相似度计算,但针对短文本,此种方法计算效果并不理想。如何有效挖掘文本和词之间语义关联,进而描述用户兴趣特点是微博UGC挖掘的难点问题。微博文本语义的挖掘通常采用主题模型如LDA(Latent Dirichlet Allocation)方法,但往往忽略了微博的时效性特征。采用LDA方法提取文档主题有一个前提,即文档语料库必须足够大。虽然目前没有文献讨论应用LDA方法的文档语料库准确大小,但通过对不同数量级的微博进行多次实验,也验证了这一点。因此,构建用户兴趣模型的方法对微博发表数量较少的“新用户”(本文称为“冷启动”用户)不适宜采用LDA方法。针对以上问题,本文将针对社交网络的UGC进行分析,采用标签关联的空间向量法构建用户兴趣模型。同时,结合一种学习模型来识别用户的兴趣及其变化,构建用户兴趣更新模型并给出用户兴趣变化识别算法。最后,以微博数据集为实验数据集,对构建的用户兴趣模型进行应用,并最终获得社交网络的主题、网络主题的核心用户及其在兴趣主题上的概率分布。
1 相关工作
1.1 LDA主题模型
主题模型被主要应用于文本挖掘中,如主题抽取、信息检索、社会网络等多个领域。尤其在社交网络文本挖掘中,主题模型发挥了重要作用。Xu S等人[1]利用时间窗法改进LDA主题模型,捕捉用户的兴趣变化。Liu X等人[2]采用主题模型对设定的时间窗口内的新闻语料进行分析,得出用户兴趣的主题概率。刘建勋等人[3]提出一种基于主题模型的方法进行Mashup标签的自动推荐。
将主题模型应用于标签主题的识别研究,通常从“资源-标签”的二元关系展开,如Krestel R等人[4]将资源及其标注标签视为“文档-词频”的结构,利用LDA建立标签主题模型,采用吉布斯采样算法,通过迭代学习识别标签潜在的主题。Mao X L等人[5]增加文本类别因素,提出了半监督的分层主题模型,结合标签主题生成文本,获得主题的层级结构。Schwartz C[6]通过对主题的时间变化因素,对标签主题分析工具和实例进行重新挖掘,以适应新的用户个性化需求。由于用户的标注行为受用户自身知识、背景和习惯的影响,标注的随意性、自由性都会使标签具有歧义性、同义性等特点,分析资源-标签二元关系,比如寻找同一类资源的标签共现关系,对挖掘隐藏的标签语义信息具有重要意义。因此,从用户标注行为、标签与资源的关系视角来识别标签主题是必要且可行的。
1.2 用户兴趣模型
用户兴趣建模的核心思想是通过对用户行为及用户关注资源内容的挖掘,提取用户的兴趣偏好,并用一定的形式表示出来。用户模型不仅是用户兴趣特征的描述,也是具有特定数据结构的、面向算法的、形式化的知识的表征。
1.2.1 用户行为模式挖掘
用户行为模式挖掘是用户个性特征提取的过程,通过记录和分析用户浏览行为、访问内容及反馈等信息对用户兴趣特征进行提取。特征提取一般基于统计的方法,主要包括以下2种。TF-IDF文本关键词提取方法[7-9]采用文本逆词频IDF值对文本高频词TF值加权,提取权值大的作为候选关键词。由于TF-IDF的结构简单,易于实现,因此得到广泛应用,但并不能有效反映词语的重要度和特征词的分布情况,所以算法的精度并不是很高。LDA主题提取方法是一种非监督学习的机器学习方法,用以获取大规模文档中潜在的主题分布情况,因此能够发现用户关注的隐性主题,有助于提高用户兴趣模型的精确性。
1.2.2 用户兴趣偏好表示
用户兴趣偏好表示选用合适的方法表示用户兴趣偏好,并随用户兴趣变化动态更新用户兴趣模型。用户兴趣模型建立的主要依据是用户感兴趣的资源以及用户对于资源的关注程度,用户对资源内容兴趣的程度不同,其对用户兴趣模型的贡献也不同,因此,用户兴趣模型通常表示成用户感兴趣的资源以及兴趣强度的函数,产生能表示用户特有背景知识或兴趣的用户兴趣模型。比较成熟的用户兴趣表示是向量空间模型方法[10-11],如基于领域本体的向量空间模型、层次向量空间模型。
1.2.3 用户兴趣变化的识别
用户兴趣变化的识别可以在用户兴趣模型建立之后,对模型增加新获取的用户兴趣知识或者删除过时不用的用户兴趣知识。用户兴趣模型构建之初,由于用户信息不够完备,提取的特征信息与用户的兴趣关联度不强,导致模型的准确性较低。另一方面,用户的兴趣随着时间的推移会有所变化:旧的兴趣逐渐淡化,新的兴趣逐渐产生,这一现象被称为兴趣漂移(Interest Drift)[12]。用户兴趣识别通常采用数据挖掘、概率论模型、信息推荐和检索等多种混合型方法,从用户的日志、用户反馈信息中挖掘有用信息。
用户是标注行为的主体,网络资源是标注行为的客体,用户标签是标注行为的核心。基于标签的用户兴趣建模存在一些问题:一是由于社会化标注具有自由化和公开性的特点,用户标注的标签存在着语义模糊、歧义等问题,造成标签使用的混乱和无序。需要对标签做一些预处理及扩展工作,并通过识别标签的潜在主题发现标签隐藏的语义、概念和知识,对精确表征用户的兴趣提供帮助。二是随着时间的变化,用户的兴趣偏好和关注点可能发生转移,而现有基于标签累计频次表示用户兴趣强度的方式并不能很好地反映出这种变化。将不同标注时间的标签信息等同对待,缺乏对标签时效量化的分析。根据用户在不同时间标注行为构建用户兴趣识别模型,以捕捉和识别用户的兴趣变化,是一个可行的方法。但如何有效地将标签时间因素融入用户兴趣变化的追踪中,为保证和提高用户兴趣模型的时效性,仍是一个研究难点问题。标签的时序特征亦能反映出用户的兴趣漂移,距离当前时刻越近的标注信息在用户兴趣建模中具有更高的效用,反之,距离当前时刻越远的标注信息效用越低,即时效性随着时间的推移将发生衰减[13-14]。
2 用户兴趣变化识别算法
采用LDA方法分析用户的微博内容信息,适用于用户微博语料库比较大的情况,语料库数据越大,效果越好,但是对于新用户来说,发表的微博数量并不多,如果直接采用LDA方法对微博内容进行处理,将不会获得好的效果。对于这类“冷启动”用户,本文采用基于标签关联的空间向量相似度计算方法,获取用户-主题相关性。然后,根据学习模型识别用户的兴趣变化,建立用户兴趣更新模型,构建流程如图1所示,包括网络主题获取模块、空间向量相似度计算模块及用户兴趣模型及更新模型构建模块。
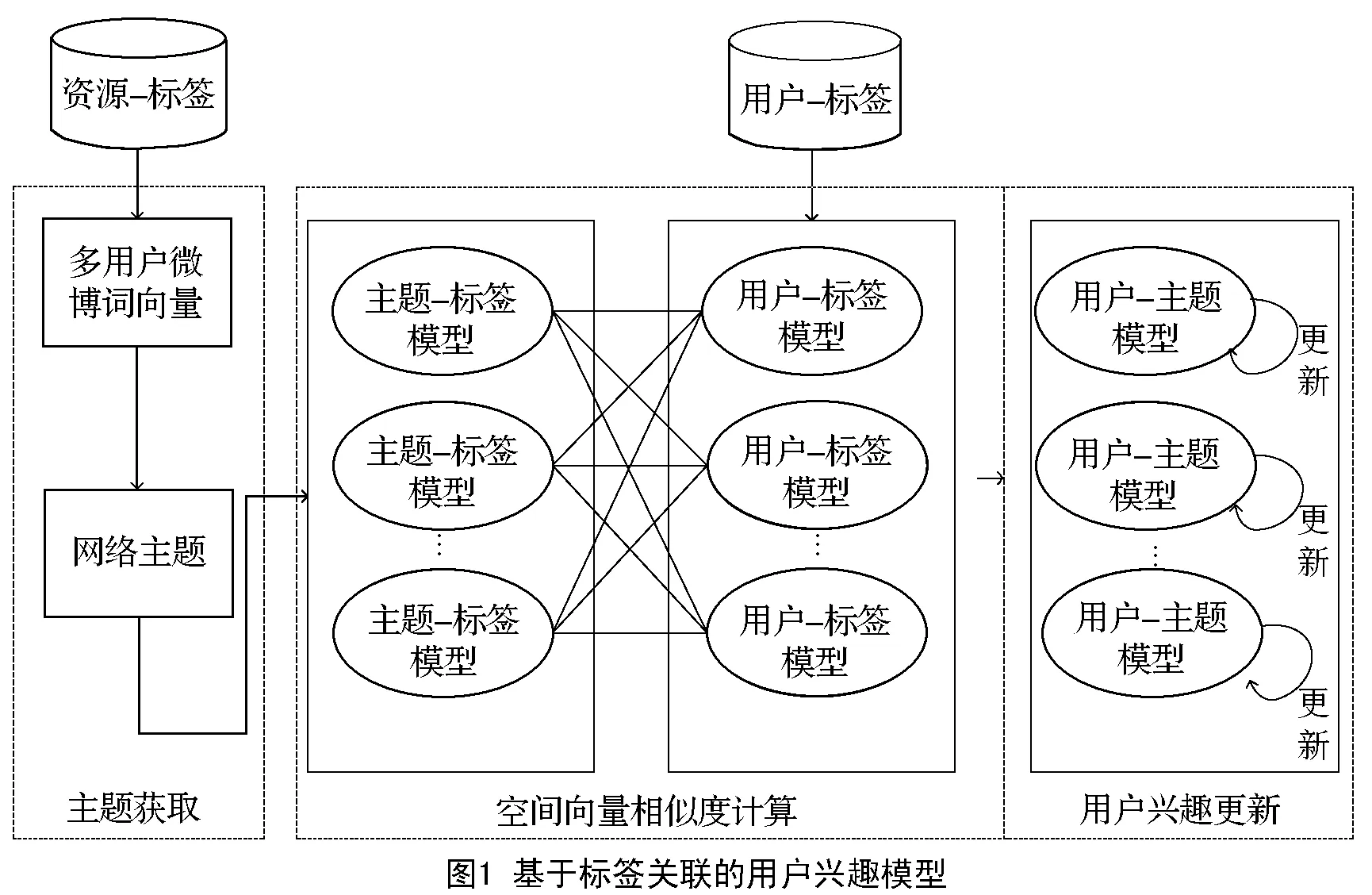
2.1 基于LDA的网络主题获取
如果将一段时间内的用户发布的微博内容汇总,形成多用户的微博内容语料库。采用LDA主题模型对其进行训练,得到的热点主题分类,网络微博的主题向量形式化表示如式(1):
(1)
其中,Ti是根据汇总的微博内容产生主题i的概率,k是产生的主题分类的数目。同时,可以获得不同主题分类中的关键词(标签)的概率分布。在每个主题分类中,主题-标签的向量的形式化表示如式(2):
(2)
其中,tj是根据主题Ti产生标签j的概率,s是产生的主题分类的数目。
为了下文的空间向量相似度计算,采用VSM模型表示LDA方法获得的主题-标签模型,该模型由m个主题组成m×k维向量空间,每个主题T可用一个k维的特征向量来表示Tj={(t1,ηj1),(t2,ηj2),…,(tk,ηjk)}。其中ηji表示属性标签ti对主题Tj的相关度(i=1,2,…,k),即获得了标签-主题分布。ηji值越大,表示当前标签与此主题的相关性越大;反之,ηji值越小,表示当前标签与此主题的相关性越小。
2.2 标签关联的相似度计算
对单用户的微博内容进行分析,得到用户-标签模型,且每个标签具有时间维l(标签所属微博的发表时间),构成m×n×l的空间向量形式的特征项,并采用TF-IDF方法确定特征项权重;进行空间向量相似度计算,得出用户标签在不同网络主题上的隶属概率,以及用户与不同主题的关联度。
以标签为中间媒介,将向量空间模型表示的用户-标签相关度rij与主题-标签相关度ηij进行综合,形成用户-主题相关度δij。虽然描述的都是基于标签在不同维度空间中的权重,但描述的对象和权值的计算方法都不相同。因此,为了将两个权值保持平衡,并遵守收敛原则,采用离差标准化对两个权值分别做以处理,如式(3):

(3)

(4)
计算结果的范围在0~1内,δij结果值越大,表示此主题与当前用户的相关性越大;反之,δij结果值越小,表示此主题与当前用户的相关性越小。
2.3 考虑兴趣度和活跃度的学习模型
借鉴Lam和Mostafa的机器学习模型(learning model)[15],本文引入学习模型来识别用户兴趣的变化。算法基于这样的假设:用户使用某一标签次数越多,该标签越能体现用户的兴趣,标注次数较多的标签反映用户的固定兴趣。由此假设,算法将依据用户标注行为提取标签时序特征,按照每个标签标注时间的先后顺序建立一个用户标签序列,m以一次标注视为用户的一次反馈。具体做法是:将第一层节点作为主题类的集合,用户对叶节点标签的一次标注将加入学习模型中,从而改变所属主题类的兴趣度。
用户对每个主题类的兴趣由两个因素θ和q衡量,其中:θ表示用户对主题类T的活跃度,初始值为0;q表示用户将对主题类T的选择概率,即兴趣度,初始值为已知用户兴趣模型中的用户-主题相关度值,变化范围为[0,1]。θ和q分别按照式(5)和式(6)计算:
θT(t+1)=(θTt×t+rT/(t+1) ,
(5)

(6)
其中,t是用户的标注次数,初始值为0,每次标注递增1。θT(t+1)表示前(t+1)次标注迭代的活跃度变化的平均值。rT表示当前主题类的叶子节点的标注反馈值,rT=0或1,当某个叶子节点被标注时,则对应的主题类标识rT=1,其余主题类的标识rT=0,0<λ<1表示学习参数。由式(6)可知,当用户使用某个标签节点标注时,它对应的主题类的选择概率将增加,反之将降低。
2.4 用户兴趣变化识别算法
将用户标签关联的相似度计算模型与学习模型相结合,设计用户兴趣识别算法,描述如下:
输入:目标用户ui的主题模型,包括m个主题类别T,用户-主题相关度集{δi1,δi2,…,δim},用户ui的z个标签的按照标注时间排序的标签序列{ti1,ti2,…,tiz}。
输出:目标用户的各个主题类兴趣度。
步骤:
① 初始化,令qT=ηij,θT=0,t=0,j=1,2,…,m;
② 根据用户ui标签序列{ti1,ti2,…,tiz},构建各个主题类的标注序列RT,再根据式(5),对用户的各个主题类的活跃度θT(T=1,2,…,m)做识别处理;
③ 根据式(6),对用户的各个主题类的兴趣度qT(T=1,2,…,m)做识别处理;
④ 根据获得的主题类Ti的兴趣度q值,修改用户兴趣模型的用户-主题相关度。
2.5 用户兴趣更新模型的表示
在主题模型训练完成后,一个用户u的兴趣模型可以用式(7)的向量形式化表示:
(7)
其中,Ti是根据用户所有微博内容提取的主题的概率,k是主题的数目。进而表示用户兴趣更新模型,如式(8):
(8)
其中,Vnl表示在e时刻的更新模型,Vol表示更新之前的旧模型,N表示用户发表微博的总数,Vp表示e时刻用户发表的微博特征模型,如果用户在e时刻没有发微博,则取离e时刻最近的发表微博。对此条微博采用简单的词频统计方法,表示特征项的权值。引入遗忘因子进行更新的用户兴趣可以用式(9)的主题向量进行表示:
(9)

3 实验
3.1 实验准备数据统计及预处理
通过网络爬虫技术从微博上采集5个月的微博信息,用户数总量为150 728个,微博数量约897万条。采集到的微博原始数据,包括微博ID、微博内容、用户ID、用户昵称、来源、时间、原始微博ID、转发链中上一条微博ID、转发数、评论数、点赞数等内容。
将数据清洗后得到最终实验数据集合。该集合包括用户数7 531个,微博数864 177条,用户标签数17 439个。跟本实验相关的信息主要包括用户ID、微博ID、微博内容、微博发布时间、用户标签等。
3.2 LDA网络主题抽取实验
经过多次反复实验,LDA主题模型的主要参数设置如表1时,实验效果最好。

表1 LDA实验参数设置
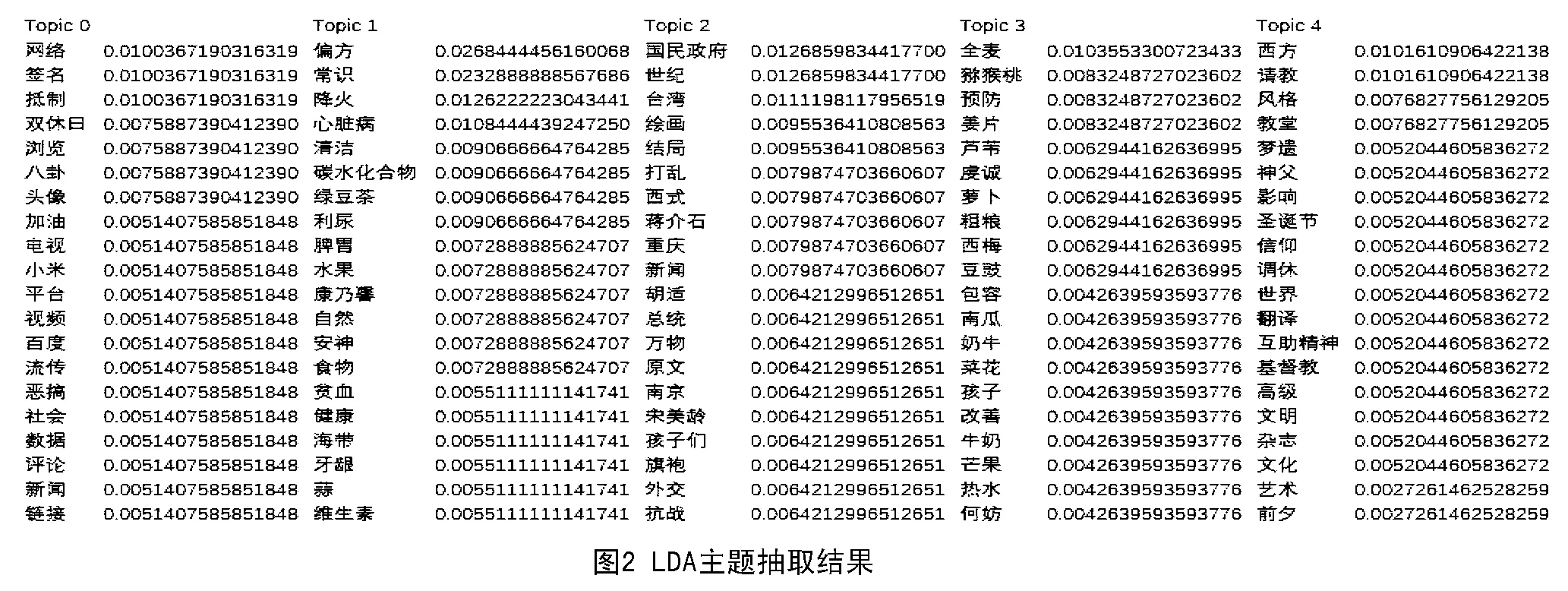
实验结果包括5个主题,每个主题选择概率值排序在前20位的标签集合,每个标签具有跟此主题相关的概率值,如图2所示。分析这5个主题 (Topic 0~Topic 4)和标签内容可知:Topic 0为“网络媒体”,内容大多跟网络术语相关;Topic 1为“健康养生”,关注绿色、保健之类的话题;Topic 2为“国民抗战”,内容有关抗战时期的地点、人物,具有时代特色;Topic 3为“营养食品”,内容包括一些食品的名词;Topic 4为“西方宗教”,内容有关文明和信仰。
3.3 用户兴趣获取实验
针对“冷启动”用户的划分问题,将每个用户发表的微博集分词处理后的结果作为考虑对象,经过多次反复实验,设置2 000为阈值,即将分词数量少于2 000条的用户当作“冷启动”用户。实验结果见表2,每个主题选择Top-5核心用户为代表(为保护用户隐私,用户名已采用化名)。

表2 主题-用户概率分布
通过对实验结果和用户微博内容的观察,可以获知用户主题概率值大于0.05时,视该主题为用户的兴趣。用户主题概率值越大,说明此用户对这个主题越感兴趣,比如用户名为“健康常识”的用户,对Topic 1表示“健康养生”的主题概率值高达0.917 39。有些用户在不同主题下都具有较高的概率,如“固518”用户在Topic 0中的概率是0.283 90,而在Topic 4的概率是0.257 62,说明此用户对这两个主题都很感兴趣,兴趣相对广泛。
将图3和表2的数据相结合,就可以得出用户的确切兴趣。从每个主题中任意选出一位用户,其兴趣主题及其标签概率分布见表3,将标签概率小于0.05的兴趣度视为0。

表3 用户兴趣概率分布
观察表3发现,除了“固518”之外,只有“江风尚”还具有两个兴趣主题,其余用户在5个兴趣主题上的都仅占一席,即属于兴趣单一用户。分析原因,由于在表2中的用户在各自主题上均属于Top-5用户,具有与此主题的强相关性,因此对其他主题的兴趣度相对较弱,这与生活中一个人如果对某一领域具有浓厚的兴趣,对其他领域关注度相对会较少的实际情况相符。
4 结语
本文利用LDA主题模型抽取用户兴趣和网络主题,对“冷启动”用户引入空间向量相似比较,使得针对不同特征的用户,其建模方法有所不同,更好地拟合了实际情况。引入标签时序特征的学习模型对用户兴趣变化进行识别,并未在计算复杂度上提升数量级,因此对模型的计算时间以及计算资源上并未有跨越式的消耗量,仅仅以消耗小部分计算时间以及计算资源识别用户的兴趣变化,较好地解决了建模中用户兴趣变化识别的难点问题。
