基于ResNet网络的红绿灯智能检测算法研究
2021-10-19郭瑞香
郭瑞香
(闽南师范大学信息化建设与管理办公室,福建漳州363000)
据英国《柳叶刀·全球卫生》新刊载的研究报告预计,若不加强盲人的眼疾治疗,全球盲人数量2050年将增至1.15 亿,比现有的4 500 万多1.76 倍.在交通如此发达的情况下,盲人由于视觉缺失,无法直接观察周围的环境,必须借助导盲基建和辅助设备进行户外活动,但现有导盲辅助设备对红绿灯设备信息获取能力有限,盲人在单独出行时将隐藏极大的不便性和危险性.基于深度学习提出红绿灯目标检测方法.利用PaddlePaddle 深度学习平台对红绿灯目标检测模型进行训练并调整参数进行优化,得到红绿灯准确检测结果.
1 目标检测方法
目标检测算法分为单阶段模型和两阶段模型.单阶段检测算法有SSD 和Yolo模型,它们只需要使用一个网络就能在图像上产生候选区域,并预测出候选区域中包含物体的类别和位置.两阶段RCNN[1]和SPPnet算法则是先在图像上产生候选区域,再对候选区域进行分类并预测目标物体位置.2015年,Joseph等提出Yolo(You Only Look Once,Yolo)算法,也被称为Yolo V1;2016年,他们对算法进行改进,又提出Yolo V2版本;2018年发展出Yolo V3版本.Yolo V3[2]的推理速度快于SSD 3倍,如表1.基于Yolo V3单阶段算法,分别使用DarkNet53、ResNet34单个网络结构提取特征网络,产生一个正的候选区域,比RCNN产生候选框数量较少,精度速度性价比较高,能达到实时响应的水平.

表1 Yolo MAP&FPSTab.1 Yolo Map&FPS
2 Yolo-V3模型设计思想
Yolo V3模型借鉴了金字塔特征图思想,使用小尺寸特征图来检测图像中大尺寸物体,使用大尺寸特征图检测小物体.其算法使用了多个标签分类方法,根据候选框与真实框的接近程度进行分类,把足够接近真实框的候选区域标注为正样本,并通过卷积网络预测候选框的位置和类别,同时获得真实框相对预测框的标签值;把偏离真实框的候选区域标注为负样本.再将网络预测值和标签值进行比较建立损失函数.
2.1 候选框
按一定的规则在图像上产生一系列位置固定的锚框[3],锚框中检测出包含目标物体时,这时锚框转为预测框,并预测出预测框中所包含目标物体的类别和位置,预测出预测框相对锚框位置需要调整的幅度大小.
在生成预测框之前,我们将图像划分多个相同大小的网格,然后以每个小方块的中心点生成3个不同大小的锚框.图像中物体在哪个小方块中心点上,则由这个小方块中心点所在的网格负责检测物体.生成的锚框是固定的,且与物体边界框有一定的偏差,需要在锚框的基础上根据预测出来的幅度大小进行位置的微调,并生成预测框.预测框相对于锚框会有不同的中心位置和大小,考虑如何生成其中心位置坐标.
2.2 预测框
锚框的大小按规则预先设定好,根据锚框与边界框来确定预测框[4],把图像320*240 划分为16*16 大小的网格后,得到m*n个小区域,m==20,n==15,即20*15 个小方块.小方块区域左上角的位置坐标是:cx=5cy=11.
此锚框的区域中心坐标是center_x=cx+0.5=5.5,center_y=cy+0.5=11.5.
可以通过下面的方式生成预测框的中心坐标:bx=cx+σ(tx)by=cy+σ(ty),
其中tx和ty为实数,σ(x)[5]是Sigmoid 函数,其定义如下:σ(x)=,由于函数σ(x)值总是在0∼1 之间,所以预测框中心点总是落在小方块区域内.
当tx=ty=0时,bx=cx+0.5by=cy+0.5,预测框中心与锚框中心重合,都是小区域的中心.
2.3 候选框标注
每个区域生成3钟不同形状大小的锚框,每个锚框里都可能包含目标物体,这里我们把锚框是否包含了物体看作是一个二分类问题,使用标签objectness来表示.当锚框包含了物体时,确定物体的类别,并使用类别标签Lable 来表示具体所属的类别,设置objectness=1,表示预测框属于正类;当物体不在锚框内时,设置objectness=0,表示锚框属于负类.如果物体在锚框内,那么需要确定预测框的中心位置和大小tx,ty,tw,th、objectness和类别标签label.
如图1,Yolo V3模型使用3个不同形状的锚框与真实框计算交并比IoU,取IoU值最大的锚框.IoU是两个框重叠的部分除以两个框的区域集合部分得出结果.即
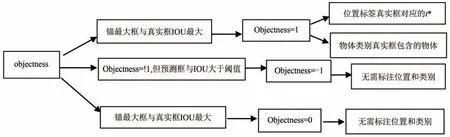
图1 候选框标注流程Fig.1 Annotation process of candidate box
2.4 网络结构改进
Yolo V3 模型引入了Resnet残差学习方法,减轻原模型深层网络训练的困难.在原有设计的基础上,引入了残差模块,每个残差模块包含两条路径,一条是输入特征,一条是正对改特征进行卷积得到特征的残差,最后再对特征进行相加.模型中网络结构包含32个卷积层、输入层、全连接层,使用步幅为2的卷积层替代池化层进行特征图的降采样过程,有效阻止由于池化层导致的低层级特征的损失,最后一层是全连接层,并使用softmax[5-6]函数进行回归0~1 之间.对于输出feature map 相同大小的层,有相同数量的filters,即channel 数相同;当feature map 大小减半时(池化),filters 数量翻倍.对于残差网络,使用维度匹配的shortcut连接,维度不匹配时,同等映射使用zero padding.其网络结构[9]如表2.

表2 Resnet 34架构Tab.2 RESNET 34 architecture

续表2
Resnet 34 网络结构中添加了恒等映射后,神经网络训练的函数[7-9]变为F(X)+X,F(X)为残差[10],即修正的幅度,这里把网络结构设计为H(X)=F(X)+X,F(X)=H(X),若F(X)=0,H(X)=X就构成同等映射,拟合网络残差更加容易些.残差网络结构如图2.

图2 残缺网络结构Fig.2 Incomplete network structure
2.4 模型算法
Yolo v3 的网络结构包含基础特征提取网络、multi-scale 特征融合层和输出层组成.整个模型算法步骤如下:
1)数据集分析.构建数据集,包含annotations和JPEGImages两个文件夹.采用标注软件对图片进行标注,annotations/xmls 目录下存放图片的标注.每个xml 文件是对一张图片的说明,包括图片尺寸、包含的红绿灯名称、在图片上出现的位置等信息.
2)数据预处理.对本地图片数据做预处理,采用按一定比例随机分组,一部分用于训练,一部分用于验证,并产生图片对应的标签文件.模型训练时将图片压缩为224*224,并对图像做一些随机的变化处理,如外接矩形框、旋转、颜色增强、随机裁剪等,产生不同角度且相似但又不完全相同的样本,扩大训练数据集,抑制过度拟合,提升模型的泛化能力.
3)特征提取网络.模型中引入了残差网络思想,使用Resnet残差网络结构,使用shortcut保持转换输入和输出一致,采用压缩方式先降维,卷积后再升维,在Resnet 34通过浅层网络函数F(X)+X构造同等映射深层模型,用步长为2的卷积层下采样对图像进行提取特征,通过转换结构将输入图片转成瓶颈卷积一样的尺寸大小,再进行逐位相加,完成链接.
4)特征融合层.Yolo v3 采用了3 种不同尺度大小的特征图来进行目标检测,分别为13*13,26*26,52*52,特征融合层选取3 种尺度特征图作为输入,通过一系列的卷积层和上采样对各尺度的特征图进行融合,骨干网络输出的特征图与预测框对应起来.
5)输出层.通过网络结构提取的特征融合,每个网格预测B 个边界框和这个边界框是物体的概率Objectness,每个边界框预测出5个值x、y、w、h和置信度Pr*IoU[11-12],并输出2个类的概率.
3 实验结果分析
实验使用的是全国大学生智能车竞赛线上组赛题红绿灯数据集,采用PaddlePaddle X、AI STUDIO平台对数据进行训练,首先使用官方配置修改后得出best 模型,并使用best model 作为下一次的预训练模型,调用detection release0.3 中余弦learning_rate 进行学习,学习后再使用best作为新一轮预训练模型,迭代轮数减半,learning_rate、批次大小适度调整.
这里直接采用34层的残差网络ResNet,并且采用预训练模式.用预训练模型能够较快地得到较好的准确度,如表3.

表3 红绿灯对象框信息Tab.3 Traffic light object box information
Resnet 34网络结构训练过程打印出来的参数信息,如表4.

表4 Resnet 34 网络结构部分参数信息Tab.4 Parameter information of RESNET 34 network structure
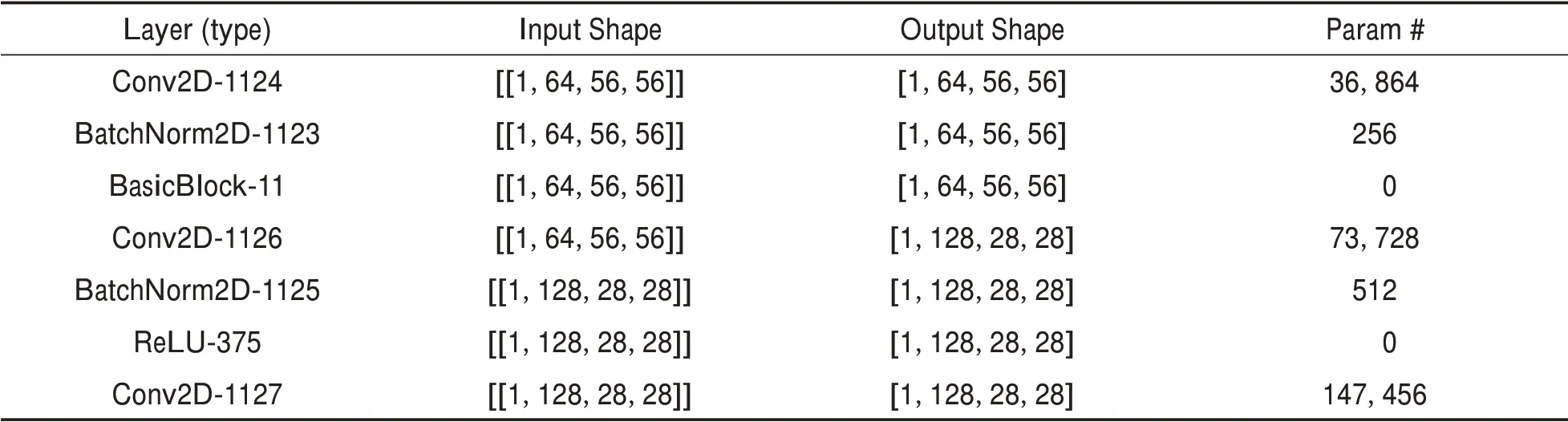
续表4
由上可知,模型训练参数Total params:21,302,722,Trainable params:21,268,674,Non-trainable params:34,048训练参数得到较大的优化.训练中对图像进行裁剪,经过数据增强,采用Mixup策略、图像填充、随机裁剪、随机水平翻转、多尺度训练、随机亮度等优化策略,具体裁剪输入参数训练图见图3.
图3 图像裁剪训练输入参数Fig.3 Input parameters of image clipping training
实验中使用平均精准率(MAP)、准确率P、召回率R评估检测模型的准确性.准确率为P,Tp为模型正确检测到的红或绿灯数量;Tf为模型错误检测到的红或绿灯数量,Fn为模型检测错误、漏检的数量.准确率公式[11-12]如下:

召回率R如下:

根据式(1)-式(2),以DarkNet53 网络结构的YOLO V3 模型进行训练,得出红绿灯检测评估结果如表5.

表5 红绿灯检测结果Tab.5 Test results of traffic lights
平均精准率(MAP)为0.865 9.
实验中通过改变Yolo V3的网络结构,以ResNet34作为Yolo V3模型的网络结构,通过对图片进行裁剪,学习率为0.000 015 63,置信度阈值设为0.6,交并比(IoU)阈值设为0.5,整体检测评估结果达到最优,如表6.

表6 红绿灯检测结果Tab.6 Test results of traffic lights
模型在第8个eporch时,bbox_map达到最优值为89.664 7,平均精准率的均值(MAP)达到0.896 6.
在训练时,最初使用较小的学习率来启动,并很快切换到大学习率.Warm up初始学习率为0,训练在Warm up步数为800前,逐步增大学习率为0.000 015 63,具体学习率变化如图4所示.

图4 学习率变化Fig.4 Changes in learning rate
在训练时,保存各轮模型bbox_map变化曲线,如图5.
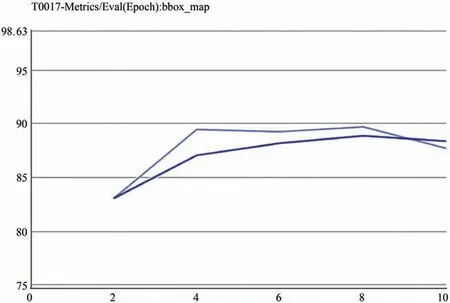
图5 各轮模型bbox_map变化Fig.5 The bbox of each round model_Map changes
bbox_map变化T0017-Metrics/Training(Step):loss,如图6.

图6 模型训练集Loss变化Fig.6 Loss change of model training set
图片测试见图7-图8.

图7 绿灯检测结果Fig.7 Green light detection results

图8 红灯检测结果Fig.8 Red light detection results
在模型算法中,通过改变Yolo V3模型的网络结构,从实验结果看,模型的精度得到了提高,模型性能得到了优化,模型平均精准率从原来的0.865 9提高到0.896 6,提升了3个百分点.实验证明通过改变网络结构来提取特征网络可以提升模型的精度,缩短训练时间.
4 总结与展望
本实验使用Yolo V3 模型,引入残差网络学习方法,采用Resnet 34残差网络结构,对模型裁剪进行改进,优化网络结构的深度,不断优化参数进行训练,平均精准率(MAP)由0.865 9 提高到0.896 6,同时缩短了训练时间.残差网络结构更容易优化,通过增加网络的深度来提高准确率.下一步实验将使用zero padding 的同等映射,不断优化网络结构,加深网络结构,如resnet50、resnet101、resnet152,优化模型性能,提高红绿灯模型检测准确率,保障盲人弱势群体更加安全地过马路.
