混合信息双数组的未登录词动态识别模型
2021-10-18陈皓宇洪嘉伟陈致然
陈皓宇 洪嘉伟 陈致然

摘要:未登录词是影响命名实体识别效果的重要因素,现有分词工具在处理未登录词时不仅识别效果欠佳,且存在识别时间較长等问题。为提高分词效果,在现有分词器基础上结合未登录词识别模型,提出了一种基于改进双数组Trie的混合信息未登录词动态识别模型MIDAT,将双数组Trie扩展为字符双数组与概率双数组,利用字符双数组存储字符串词段信息,概率双数组存储字符串节点间的成词概率信息,通过不断识别未登录词,动态更新两个双数组Trie。实验结果表明,在相同的数据集下,结合MIDAT的分词器后对于未登录词的分词效果要优于结巴等常用分词器,同时在时间效率上相比传统的未登录词识别模型提升约8倍。
关键词: 未登录词; 双数组Trie; 互信息; 信息熵 ; N-gram
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2021)26-0001-05
开放科学(资源服务)标识码(OSID):
Dynamic Recognition Model of Unknown Words Based on Mixed Information Double Array Trie
CHEN Hao-yu,HONG Jia-wei,CHEN Zhi-ran
(Faculty of Computer, Guangdong University of Technology, Guangzhou 510006, China)
Abstract:Unknown words are an important factor affecting the recognition effect of named entities. When existing word segmentation tools deal with unknown words which not only have poor recognition results, but also have problems such as longer recognition time. In order to improve the effect of word segmentation,combined the unregistered word recognition model on the basis of the existing word segmenter, and proposes a dynamic unregistered word recognition model MIDAT based on the improved double array trie. On the basis of expanding the double array trie into a character double array and a probability double array, the character double array is used to store the word segment information of the string, and the probability double array is used to store the word formation probability information between the string nodes. Through continuous identification of unknown words , dynamically update the two double array trie. The experimental results show that under the same data set, the word segmentation effect of the word segmenter combined with MIDAT is better than that of common word segmenters such as stuttering. At the same time, the time efficiency is improved by about 8 times compared with the traditional unknown word recognition model.
Key words:unknown words ;double array trie ;mutual information ; nformation entropy ; N-gram
随着互联网的快速发展,网络新闻媒体中的热点话题与重大新闻层出不穷,其中蕴含着丰富的未登录词[1],然而现有的分词器并不能有效地识别出这些词,分词后容易产生字符串碎片,而大量的未登录词和字符串碎片会导致命名实体识别[2]的准确率降低,因此在自然语言处理任务中,如何有效识别出未登录词便成为一个热点和难点问题。
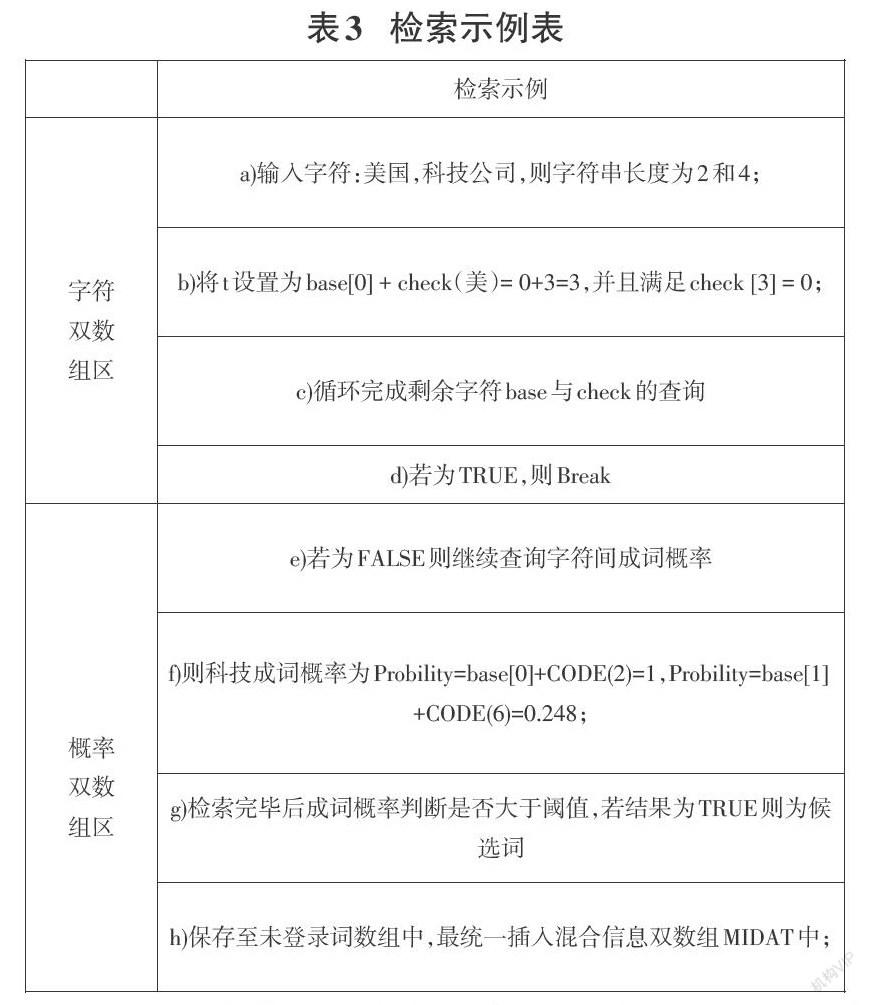
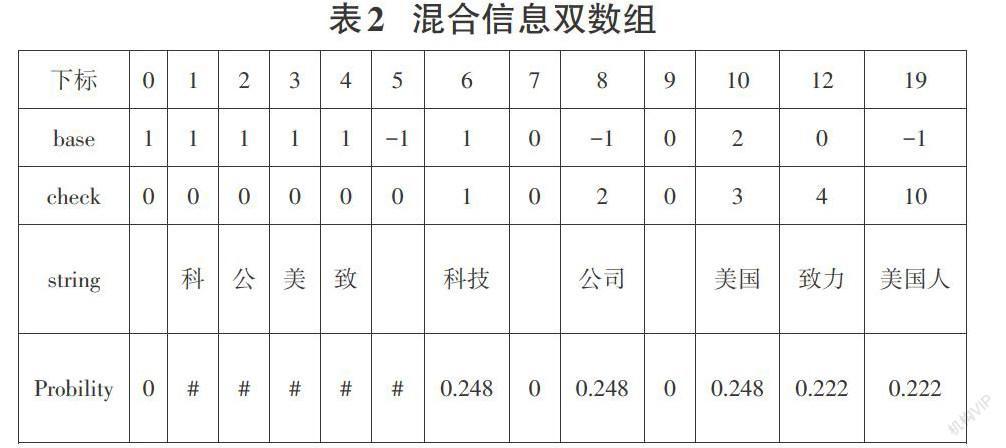
其根本体现在下述两个方面,一方面现有的未登录词发现算法效果不太理想,算法在实体识别过程中存在一定的偏差。另一方面,由于文本数据中存在大量的重复前缀,使得原有识别算法的时间复杂度非常高,进行识别需要花费大量时间。故本文在改进双数组Trie的基础上提出了一种基于改进混合双数组、互信息和信息熵的混合信息双数组未登录词识别模型MIDAT。
1 相关工作
目前未登录词识别[3]的研究方法大致有两类:基于规则的方法和基于统计学的方法。基于规则的方法是通过字符串词段间的结构与构词原理,结合词性与语义信息[4]来进行匹配,对文本语料中的未登录词进行识别[5]。这种方法精确率较高,但是针对性较强,适用的领域较为单一,适用度受限,并且维护十分困难。而基于统计的方法,通过使用统计模型对语料中的各种信息[6]进行未登录词识别,这种方法灵活性较高,具有较好的普适性,但需提前对统计模型进行大量的训练,准确率也有待提高。
