基于Neo4j的用户阅读数据图数据库的应用
2021-10-16柴源

摘要:为了实现一维用户阅读数据的关联化与可视化,分析了图数据库在数据挖掘方面的优势,以西安航空学院2020年的202 941条用户阅读数据为数据源,基于图数据模型,采用Neo4j技术,定义了7类实体、6类关系及其属性,构建了用户阅读数据图数据库。结合查询功能,讨论了Neo4j用户阅读数据图数据库在数据查询、图书推荐等方面的应用,希望为图书馆资源与服务建设等提供有效的数据支持及技术指导。
关键词:Neo4j图数据库;用户阅读数据;数据库设计;可视化
中图分类号:TP311.13 文献标识码:A 文章编号:2096-4706(2021)07-0095-07
Application of User Reading Data Graph Database Based on Neo4j
CHAI Yuan
(Library of Xian Aeronautical University,Xian 710077,China)
Abstract:In order to realize the association and visualization of one-dimensional user reading data,the advantages of graph database in data mining are analyzed. Taking 202 941 pieces of user reading data of Xian Aeronautical University in 2020 as the data source,based on the graph data model,Neo4j technology is used to define 7 types of entities,6 types of relationships and their attributes,build a user reading data graph database. Combined with the query function,this paper discusses the application of Neo4j user reading data graph database in data query,book recommendation,etc.,hoping to provide effective data support and technical guidance for the construction of library resources and services.
Keywords:Neo4j graph database;user reading data;database design;visualization
收稿日期:2021-03-21
基金項目:2019陕西省教育厅科研计划项目(19JK0334);陕西省教育厅2020年度一般专项科学研究计划项目(20JK0199)
0 引 言
图数据库(Graph Database)是基于图论实现的一种新型的非关系型数据库(NoSQL)[1],在图数据库中,数据与数据之间的关系通过节点和关系构成一个图结构并在此结构上实现数据的创建、读取、更新、删除等[2]。因此,只要是反映节点和关系的任何数据,都可以用图数据库技术重构与分析。
图书馆用户阅读数据属于一维线性组织,只描述学生、图书等信息,不区分实体和关系,关联化和可视化程度较低。鉴于此,本文应用Neo4j图数据库技术,构建了用户阅读数据图数据库,并进行了应用分析。
1 Neo4j图数据库的优势
1.1 Neo4j的基本术语
Neo4j是由Java实现的开源NoSQL图数据库,是图数据库中较为流行的一款,它提供了完整的数据库特性,包括ACID事务的支持、集群支持、备份与故障转移等[3]。Neo4j的数据模型主要由节点、关系及其属性构成。
节点(Node):用以表示一个实体记录,在图数据库中用○表示。
关系(Relationship):用以表示节点之间的联系,在图数据库中用-表示无向关系,->表示有向关系。
属性(Property):用以表示节点和关系的特征,它以key-value对的形式存在。例如,ISBN、题名、出版社、分类号是图书的属性。
1.2 Neo4j图数据库的主要优势
1.2.1 图结构式存储
关系型数据库将数据存储在一个预定义好的、结构固定的二维表格中,数据之间的关系靠各个表格行列之间的相互关联实现。Neo4j采用图存储结构,节点和关系记录由指向联系和属性列表的指针ID构成,且都用固定大小记录,任何记录都可以根据指针ID快速计算出来。
1.2.2 免索引邻接式查询
关系型数据库使用全局索引连接各个节点,这些索引对每个遍历都会增加一个中间层,因此会导致非常大的计算成本。Neo4j图数据库具有免索引邻接特性,每个节点都会维护与它相邻节点的引用,即每个节点相当于与它相邻节点的微索引,查询时间和图的整体规模无关,只与它附近节点的数量成正比。
1.2.3 Cypher声明式查询语言
关系型数据库采用命令式的SQL查询语言,复杂性会随着连接数据查询所需的join操作的数量而增加。Cypher是一种声明式的模式匹配查询语言,提供了描述关系查询的最有效表达方式。
1.2.4 图数据可视化
关系型数据库中,一般通过列表、表格、结构化报告和汇总分析与数据交互,需要阅读和认知所有的数据才能完全理解数据的整体模式。Neo4j图数据库用可视化的方式对数据应用进行建模和管理[4],可以更加直观地与数据交互。
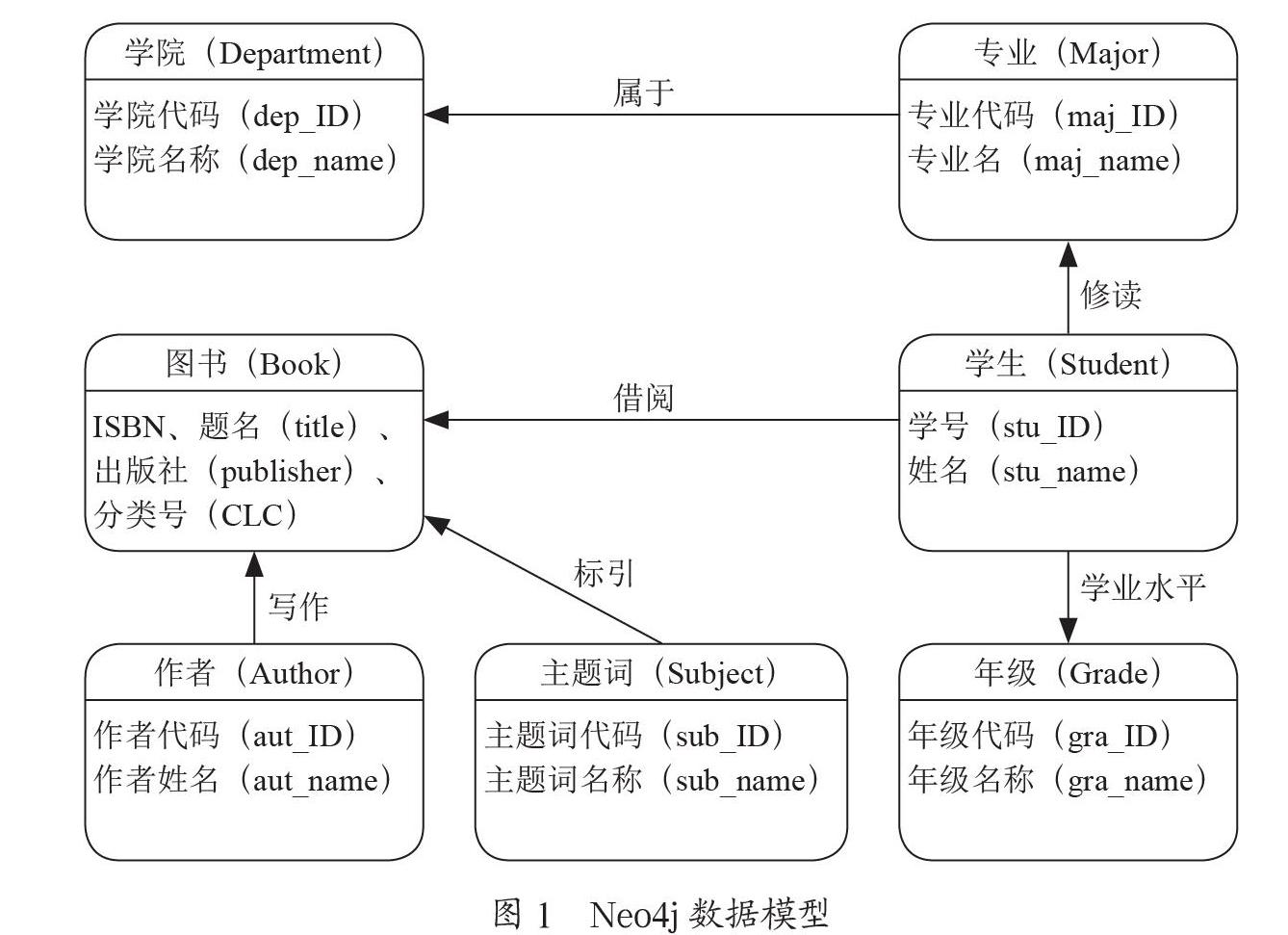
2 图书馆用户阅读数据图数据库的设计
2.1 数据来源
以西安航空学院2020年的用户阅读数据为数据源,共202 941条记录,包括7类、123 268个实体,涉及学生13 659个、年级4类、图书63 124种、图书作者44 613个、主题词1 822个、专业34个、学院12个;包含6类、429 074个实体关系,涉及借阅关系202 941个、属于关系34个、修读关系13 659个、学业水平关系13 659个、标引关系122 941个、写作关系75 840个。本文的构建图数据模型如图1所示。
2.2 实体的构建
2.2.1 数据编码
数据编码主要是为每一节点赋予一个唯一确定的指针ID,学生、专业、学院采用学号、专业代码、学院代码作为ID。年级ID为gra_01、gra_02、gra_03、gra_04,名称分别对应为大一、大二、大三、大四;对图书主题词、作者进行编码时,分别提取所有图书的主题词、作者,经过去重,按照sub_0001、sub_0002、…sub_1822的顺序赋予主题词ID,按照aut_00001、aut_00002、…、aut_44613的顺序赋予图书作者ID。
2.2.2 实体定义
抽取所有节点信息,分别创建student、book、grade、major、department、subject、author數据集,并以CSV格式存放到neo4j的import文件夹中。使用LOAD CSV WITH HEADERS FROM "file:///URL" AS line命令加载,URL即数据集的位置,“line”为指定变量。使用MERGE语句,创建节点并指定标签和属性。
例如,创建学生节点的命令为:
(s:Student{stu_ID:line.stu_ID,stu_name:line.stu_name})
命令中,()表示节点,s表示节点变量,Student表示节点标签,用于节点分类并创建子图,{}中的命令是节点的属性。文中的部分节点创建如表1所示。
2.3 关系的构建
创建student_to_book、major_to_department、student_to_major、student_to_grade、author_to_book数据集,并以CSV格式存放到neo4j的import文件夹中。确定(from)->(to)模
式,即将前一个节点的ID作为起点(from),后一个节点的ID作为终点(to),使用match语句检索数据库。使用MERGE语句,创建关系并指定标签和属性。
例如,借阅关系命令为:
match (from:Student{stu_ID:line.stu_ID}),(to:Book{ISBN: line.ISBN}) merge (from)-[r:借阅{stu_ID:line.stu_ID,ISBN:line. ISBN}]->(to)
命令中,(from:Student{stu_ID:line.stu_ID})表示起点节点,(to:Book{ISBN:line.ISBN})表示终点节点,from、to表示变量,Student、Book表示节点标签,{}中的命令表示属性,[]中的命令表示关系,r表示关系变量,借阅表示关系标签。本文部分关系创建如表2所示。
实体、关系构建完成后,使用Cypher查询语言运行并可视化显示,部分结果如图2所示。
图2包括查询命令和显示区域,它提供了图形(Graph)、表格(Table)、文本(Text)、代码(Code)四种显示方式。节点、关系可以设置不同的颜色及大小。点击任意元素可以查看其属性、关系网络等,也可以进行拖动、隐藏、锁定等功能操作,如点击学生项子轶的姓名,可以查看其借阅的图书《易》理,以及该书的作者陶有浩、标引的主题词先秦哲学等。
3 图书馆用户阅读数据图数据库的应用
3.1 数据查询
3.1.1 单一关系查询
Neo4j用户阅读数据图数据库将学生、年级、专业、学院、图书、主题、作者等节点通过借阅、修读、学业水平、属于、标引、写作等关系连接起来,既可以通过单一关系、多维度关系查询节点的直接关系,又可以通过路径查询发现节点间的潜在关系:
(1)查询学生的借阅情况,了解阅读偏好,分析阅读兴趣。例如,查询“蒋啸龙”所借阅的图书,统计图书的分类号,并按降序排列,命令为:
match (b{stu_name:'蒋啸龙'})-[:借阅]->(n:Book)
return n.CLC,count(n.CLC) as q
order by q DESC
查询结果如图3、表3所示。
由图3、表3可见,蒋啸龙共借阅图书14种,分类号主要集中在B-4(哲学教育与普及)、B82伦理学(道德哲学)、B0哲学理论、B2中国哲学、I267(中国当代作品)、A75(毛泽东)、H319.4(外文读物)等,可见,蒋啸龙的阅读兴趣集中在中国哲学、当代文学及相关英文读物方面。
(2)查询图书的被借阅情况,统计图书的利用率。例如,查询“译林出版社”出版的《资本论》(中)的借阅情况,命令为:
match (n)-[:借阅]->(b:Book{title:资本论(中)',publisher:'译林出版社'})
return n,b
查询结果如图4所示,这本书被借阅过15次。
统计题名中含有“资本论”的图书被借阅的次数,命令为:
match (n:Student)-[:借阅]->(b:Book)
where b.title contains '资本论'
return count(n)
结果显示,共计75次,则《资本论》(中)在同类书中的利用率是20%,略低。
3.1.2 多维度关系查询
查询“计算机科学与技术”专业各年级学生借阅图书的主题,大一年级的查询命令如下,其他年级类似:
match (g{gra_name:大一})<-[:学业水平]-(n)-[:修读]-> (m{maj_name:'计算机科学与技术'}), (n)-[:借阅]->(b)<—[:标引]-(l:Subject)
return l.sub_name, count(*) as q
order by q DESC limit 10
3.1.3 路径查询
(1)最短路径查询。通过shortestPath函数发现两个节点之间的最短路径[5],例如,寻找张凯与《平凡的世界》间的最短路径,命令如下,限制输出3条:
match (s:Student{stu_name:'张凯'}),(b:Book{title:'平凡的世界'}),p=allShortestPaths((s)-[*]-(b))
return p limit 3
查询结果如图5所示。
由图5可见,路径1:张凯—飞行器设计与工程—王佳翔—走向衰荣·明—小说集—平凡的世界。路径2:张凯—大二—王佳翔—走向衰荣·明—小说集—平凡的世界。路径3:张凯—大二—赵超—走向衰荣·明—小说集—平凡的世界。
(2)变长路径查询。如果节点或关系的属性发生变化,联系也发生变化。Neo4j提供变长路径查询,表示方式是:[*N..M],N和M表示路径长度的最小值和最大值[6]。例如,查询与《深度学习的数学》路径长度的最大值是4的学生及专业,限制输出5个。命令为:
MATCH (b:Book {title:"深度学习的数学" })-[*..4]-(n: Student)-[:修读]-(m)
return n.stu_name,m.maj_name limit 5
查询结果,如表4所示。
3.2 资源推荐
3.2.1 基于借阅记录的推荐
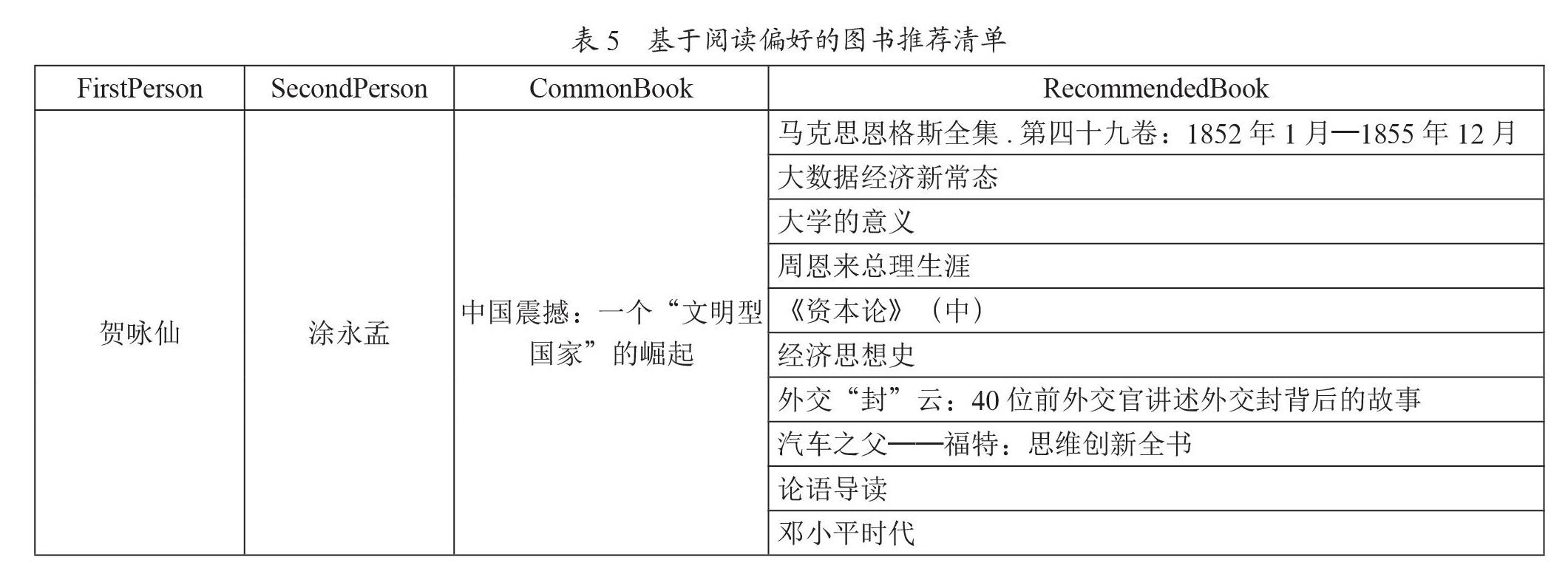
根据读者的借阅历史,发现相同的阅读偏好,进行图书推荐。例如,s1、s2的借阅记录中有相同的图书,则将s1(s2)借阅记录中s2(s1)没有借阅的图书推荐给s2(s1)。查询命令为:
match (s1:Student)-[:借阅]->(b1:Book)<-[:借阅]-(s2:Student)- [:借阅]->(b2:Book)
where not ((s1)-[:借阅]->(b2))
return s1.stu_name as FirstPerson,s2.stu_name as Second Person,b1.title as CommonBook,b2.title as RecommendedBook limit 1
命令中,match语句查询s1、s2的借阅记录b1、b2;where not添加约束条件,即過滤掉b2中s1借阅的图书;返回s1、s2的姓名并指定标签为FirstPerson、SecondPerson,返回b1的题名作为相同图书(CommonBoo),b1的题名作为推荐图书(RecommendedBook),数据量比较大,所以限制输出1行,查询结果如表5所示。
由表5可见,贺咏仙与涂永孟都借阅了图书《中国震撼:一个“文明型国家”的崛起》,推断出二者可能具有相似的阅读偏好,所以将涂永孟借阅过的而贺咏仙没有借阅的《周恩来总理生涯》等10种图书推荐给后者,实现基于借阅记录的图书个性化推荐。
3.2.2 基于主题或作者忠诚度的推荐
在借阅行为中,读者多次表现出来对某个主题或作者有偏向性的(而非随意的)行为反应。例如,读者s已借阅了一本“航空”主题的图书,那么他很可能对这一主题的其他图书也感兴趣。查询命令为:
match (s:Student)-[:借阅]->(b1:Book)<-[:标引]-(y:Subject {sub_name:'航空'})-[:标引]->(b2:Book)
with s,y,b2,count(b1) as f
where not ((s)-[:借阅]->(b2)) and f>2
return s.stu_name as Student,collect(b2.title limit 5) as RecommendedBooks
order by student DESC limit 5
命令中,统计s借阅的航空类图书,设定阈值f>2,提高s与“航空”主题的相似性,增强推荐图书对s的吸引力。应用collect函数将推荐的图书(RecommendedBooks )以列表的形式返回,限制推荐5种。s按f降序排列,限制输出5个。查询结果如表6所示。
表6中,student借阅了航空类图书,推断出可能是专业学习需要或者兴趣使然,所以将相關图书推荐给他们。
3.2.3 基于社交网络的推荐
读者所在的年级、专业、学院等元素构成一个社交网络,相同社交网络中相同的元素具有相似的阅读偏好和阅读行为。例如,找出借阅过某本书的学生,发现没有借阅过这些图书并对此图书感兴趣的学生。命令为:
match (b1:Book)<-[:借阅]-(s1:Student)-[:修读]->(m:Major {maj_name:'计算机科学与技术'})<-[:修读]-(s2:Student)-[:借阅]->(b2:Book),(s1)-[:学业水平]->(g:Grade{gra_name:'大二'})<-[:学业水平]-(s2)
where not((s2)-[:借阅]->(b1))
return s1.stu_name as Student,b1.title as RecommendedBook, collect(s2.stu_name limit 5) as ForS2 limit 5
命令中,s1、s2都是计算机科学与技术专业中大二的学生,s1、s2的借阅集合分别是b1、b2,过滤掉b1中s2的借阅记录,发现对b1中其他图书感兴趣的学生集合ForS2,进行图书推荐,如表7所示。
4 结 论
Neo4j图数据库采用图结构式存储、免索引邻接查询、图可视化显示、Cypher声明式查询语言等,提供高效的查询和数据关系处理功能。本文以西安航空学院2020年的202 941条用户阅读数据为数据源,采用Neo4j技术构建了相关图数据库,实现了一维用户阅读数据的关联化与可视化。结合查询功能,深入分析了Neo4j用户阅读数据图数据库在数据查询、Jaccard相似度计算、图书推荐等方面的作用,希望为图书馆资源建设、阅读推广、学科服务等提供有效的数据支持及技术指导。
参考文献:
[1] ROBINSON I,WEBBER J,EIFREM E. Graph Databases [M].2th ed.Cambridge:OReilly Media,2015.
[2] HANS M,CHRISTIAN B,DRAGOS S D,et al. Using Graph Databases to Investigate Trends in Structure-Activity Relationship Networks [J].Journal of chemical information and modeling,2020,60(12):6120-6134.
[3] VUKOTIC A,WATT N,ABEDRABBO T,et al. Neo4j in Action [M].张秉森,孔倩,张晨策,译.北京:机械工业出版社,2016.
[4] SHI Cheng,JIA JieShen,QUAN Shi,et al. Xianyi Cheng. Research on the construction of three level customer service knowledge graph [J].IOP Conference Series:Materials Science and Engineering,2017,242(1):1-6.
[5] 于娟,黄恒琪,席运江,等.基于图数据库的人物关系知识图谱推理方法研究 [J].情报科学,2019,37(10):8-12.
[6] 李金阳.图数据库在图书馆的应用研究 [J].图书馆,2020(11):109-115.
作者简介:柴源(1985—),男,汉族,陕西西安人,馆员,硕士,研究方向:知识组织与知识管理。
